前言:作为一名常年和 GitLab 打交道的运维工程师,备份是我每周例行的"固定动作"。直到有一次,我盯着服务器上的备份文件陷入了困惑:第一次备份生成了 128M 的完整包,后续备份却只有 3M 大小。最开始我下意识以为这是增量备份------但我用的明明是 GitLab 社区版,官方文档明确写着社区版不支持依赖历史的增量备份功能。
带着这个疑问,我翻遍了 GitLab 的官方文档和开源代码,终于搞懂了这个"从 128M 到 3M"的黑科技:它不是偷工减料的增量备份,而是 GitLab 基于 Git 原生机制做的完整备份优化。这个设计既解决了全量备份体积过大的问题,又避免了增量备份依赖历史的风险,堪称运维效率与数据安全的完美平衡。
我把整个探索过程和技术原理整理成了这篇文章,希望能帮到和我一样有过困惑的同行,也让大家更深入地理解 GitLab 的备份机制。如果你也在为 GitLab 备份的大小变化而疑惑,或者想优化自己的备份策略,相信这篇文章会给你一些启发。
🕵️♂️ 我的发现:备份包的"跳水式"体积变化
最近在给 GitLab 做例行备份时,我发现了一个有意思的现象:
第一次备份生成了 128M 的包,后续备份却只有 3M 大小------明明是"完整备份",为什么体积能差这么多?
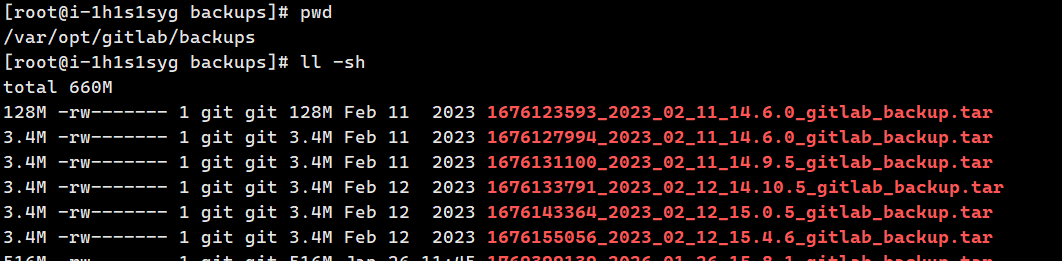
# 示例截图说明
128M 1676123593_2023_02_11_14.6.0_gitlab_backup.tar
3.4M 1676127994_2023_02_11_14.6.0_gitlab_backup.tar
3.4M 1676131100_2023_02_11_14.9.5_gitlab_backup.tar最开始我以为 3M 的包是"增量备份",但我的 GitLab 是社区版(CE),官方明确说明社区版不支持依赖历史备份的增量备份功能。深入研究后才明白,这其实是 GitLab 基于 Git 原生机制的巧妙优化------增量式对象打包(非增量备份)。
🔧 核心原理:Git Bundle + 增量式对象打包 + Tar 压缩
GitLab 社区版的备份机制,底层依赖 Git 原生的 git bundle 命令,通过**增量式对象打包(仅选择新增 Git 对象,非增量备份)**和压缩优化,实现了"完整备份,极小体积"的效果。
1. 第一次备份:基础快照的生成
第一次备份时,GitLab 没有任何历史备份记录,因此需要执行"全量打包":
- 对每个 Git 仓库执行
git bundle create,打包所有 Git 对象(代码文件、提交历史、分支标签等) - 同时打包数据库、上传文件、CI/CD 配置等非仓库数据
- 最终将所有内容压缩成一个 Tar 包,体积较大(如 128M)
这个包相当于"基础快照",包含了截至备份时刻的所有原始数据。
官方出处 :GitLab 官方文档《Backup and restore GitLab》
https://docs.gitlab.com/ee/raketasks/backup_restore.html#backup-restore-for-gitlab-self-managed
2. 后续备份:增量式对象打包的优化
后续备份时,GitLab 会为每个仓库维护一个"上次备份的 Commit 指针",并执行以下优化:
- 增量对象检测 :对比当前仓库的 HEAD 和上次备份的指针,通过
git bundle create --since=<上次备份的Commit>仅打包自上次备份以来新增的 Git 对象(如新代码提交、新分支) - 空场景优化:如果仓库没有任何提交(HEAD 未变化),则生成"空的 Git Bundle"------仅包含指针,没有实际数据
- 元数据压缩:此时备份包仅包含"空 Bundle"、备份元数据(时间戳、校验信息)和数据库的微小变化,经过 Tar 压缩后体积仅 3M 左右
技术实现出处 :GitLab 开源代码仓库中备份模块的核心实现
https://gitlab.com/gitlab-org/gitlab/-/tree/master/lib/backup
Git Bundle 官方说明 :Git 官方文档《git-bundle》
https://git-scm.com/docs/git-bundle
🎯 关键误区:不是增量备份,是"完整备份的优化"
很多人会把这种 3M 的备份包误认为是"增量备份",但它和真正的增量备份(如 GitLab 企业版的 --incremental)有本质区别:
| 特性 | GitLab 社区版 3M 备份包 | GitLab 企业版增量备份 |
|---|---|---|
| 独立性 | 完全独立,无需依赖任何旧包即可恢复 | 依赖之前的完整备份,否则无法恢复 |
| 完整性 | 包含所有数据的完整备份 | 仅包含增量变化,需结合完整备份使用 |
| 适用场景 | 数据变化小时的完整备份 | 频繁备份时减少带宽和存储占用 |
| 备份命令示例 | gitlab-rake gitlab:backup:create |
gitlab-rake gitlab:backup:create INCREMENTAL=yes |
简单来说,3M 的备份包就像一张"极简照片":它没有重复拍摄所有内容,但依然可以独立还原整个场景,而不是需要依赖第一次的"全景照片"。
官方区分依据 :GitLab 官方文档《Incremental backups》
https://docs.gitlab.com/ee/raketasks/backup_restore.html#incremental-backups
🛠️ 对运维的实用价值
理解这个机制后,你可以更好地优化备份策略:
- 空间优化:如果 GitLab 数据变化较少,后续备份会自动压缩到极小体积,无需手动清理旧备份
- 恢复保障:每个备份包都是独立的完整备份,即使某一个包损坏,其他包仍可单独恢复
- 版本一致性:恢复时只需确保新服务器安装了与备份包版本一致的 GitLab,无需依赖其他历史备份
📚 功能出处与官方依据汇总
为了方便你验证,这里整理了核心功能的官方来源:
- GitLab 备份机制整体说明 :https://docs.gitlab.com/ee/raketasks/backup_restore.html
- GitLab 备份模块代码实现 :https://gitlab.com/gitlab-org/gitlab/-/tree/master/lib/backup
- Git Bundle 命令官方文档 :https://git-scm.com/docs/git-bundle
- 增量备份与完整备份的官方区分 :https://docs.gitlab.com/ee/raketasks/backup_restore.html#incremental-backups
📌 总结
GitLab 社区版从 128M 到 3M 的备份包变化,不是"偷工减料",而是基于 Git 原生机制的聪明优化。它通过增量式对象打包减少冗余数据,同时保证每个备份包的独立性和完整性,让运维人员在备份效率和数据安全之间找到了完美的平衡。
下次再遇到 3M 的备份包,你可以自信地说:"这不是增量备份,这正是 GitLab 对完整备份的极致优化,也是其备份机制里的 "优化魔法"!"