
又是发布OCR模型的一天。
这一次,是 LightOnOCR-2 ------ 一个基于VLM的10亿参数OCR模型,它直接挑战该领域更成熟的玩家,如 OLM OCR、DeepSeek OCR 和 dots.ocr。
这些声明是雄心勃勃的:尽管模型规模相对较小,但具有更好的速度和准确性。
声称比Chandra OCR快3.3倍,比OlmOCR快1.7倍,比dots.ocr快5倍,比PaddleOCR-VL-0.9B快2倍,比DeepSeekOCR快1.73倍
因此,我想验证这些声明,看看它是否真的在这个领域表现出色。
在本文中,我将介绍:
- 我在实地测试中观察到的情况
- 该模型的亮点所在
- 仍然需要改进的地方
让我们开始吧
1、关于该模型
LightOnOCR-2-1B 是一个紧凑的、端到端的视觉-语言OCR模型,在最近的研究论文(arXiv:2601.14251)中有详细描述。与传统的OCR管道不同,传统的OCR管道将检测、识别、表格解析和布局分析的多个专门组件拼接在一起,而LightOnOCR-2-1B被训练为单一统一模型,直接从图像像素到结构化的、自然排序的文本。
以下是我从研究论文中得出的关键特征:
-
端到端设计
该模型设计为在一次传递中直接从像素到结构化文本处理文档页面,而不依赖于单独的布局检测、文本检测或文本识别组件。
-
紧凑且高效
大约10亿参数,作者声称在OlmOCR-Bench等基准测试中具有最先进的性能,同时比许多更大的OCR模型更小、更快。
-
强大的真实世界性能
根据论文的说法,在一个大型且多样化的蒸馏数据集上训练 ------ 包括扫描文档和科学PDF ------ 可以提高复杂、真实世界文档布局的鲁棒性。
-
边界框支持
该模型的某些变体设计为输出图像和嵌入图形的标准化边界框,实现OCR和布局提取的联合。
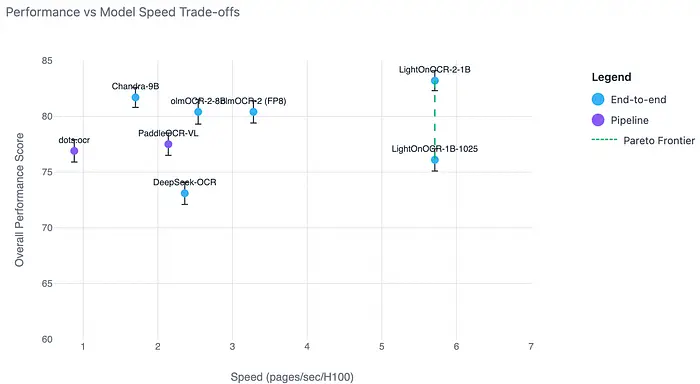
2、模型家族和变体
该发布包括多个检查点,专注于纯OCR、边界框感知OCR和混合功能,使模型适应不同的文档处理工作流程。
- LightOnOCR-2-1B:基础模型,适合微调
- LightOnOCR-2-1B-bbox:具有图像边界框的最佳模型
- LightOnOCR-2-1B-bbox-base:基础bbox模型,适合微调
- LightOnOCR-2-1B-ocr-soup:合并变体,具有额外鲁棒性
- LightOnOCR-2-1B-bbox-soup:OCR + bbox组合
3、我的评估标准
这些是我在真实世界场景中评估OCR模型时使用的关键质量和指标。
文本准确性模型准确地提取文本内容并区分标题、章节标题和正文文本的能力。
布局感知模型是否理解文档结构,例如页眉、页脚和不同的内容类型,如段落、图像、表格和图形。
阅读顺序提取的文本是否遵循跨列、章节和页面的自然人类阅读顺序。
表单和结构化数据模型在结构化和半结构化文档中提取键值对和表单字段的能力。
手写和多语言处理在手写文本和包含多种语言的文档上的性能。
鲁棒性在噪声、倾斜、模糊和低质量文档上的性能。
4、使用vLLM部署
我在配备两块NVIDIA RTX 5070 Ti GPU(每块16 GB)的单GPU服务器上使用vLLM部署了该模型。
我的部署非常简单,使用Docker Compose。
compose.yml
services:
vllm-server:
image: vllm/vllm-openai:v0.12.0
command: >
--model lightonai/LightOnOCR-2-1B
--trust-remote-code
--enable-prefix-caching
--gpu-memory-utilization 0.2
--port 8005
--max-num-seqs 2
--tensor-parallel-size 2
environment:
- VLLM_ATTENTION_BACKEND=FLASH_ATTN
volumes:
- ~/.cache:/root/.cache
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
network_mode: host
ipc: host
restart: "unless-stopped"然后运行 docker compose up;vLLM服务器启动并暴露一个OpenAI兼容的API。
由于我分配了总GPU内存的20%,该模型一致地使用了约6 GB,表明它可以在小得多的内存占用下舒适地运行。

nvtop命令显示GPU利用率## 5、详细评估反馈
以下是该模型在真实文档工作流程中的重要事项上的表现的更仔细观察。
A) 布局和阅读顺序感知
该模型在布局检测和阅读顺序保持方面表现良好。
在近20种不同的文档类型 中,我观察到布局理解的准确率约为85%。标题、正文文本和结构区域通常被正确识别。
对于阅读顺序,行为是可靠的。该模型通常以类似人类的流程处理文档:
- 首先是标题
- 然后是正文内容
- 对于多列布局,它遵循正确的列次序,不会打乱行
这使得输出可直接用于下游NLP和摘要任务。
B) 表格重建为HTML
表格检测和重建是模型最强的领域之一。
该模型能够:
- 准确识别表格边界
- 保留行和列结构
- 以HTML格式重建表格,便于后续可视化
对于大多数表格密集型文档,几乎没有需要后处理。
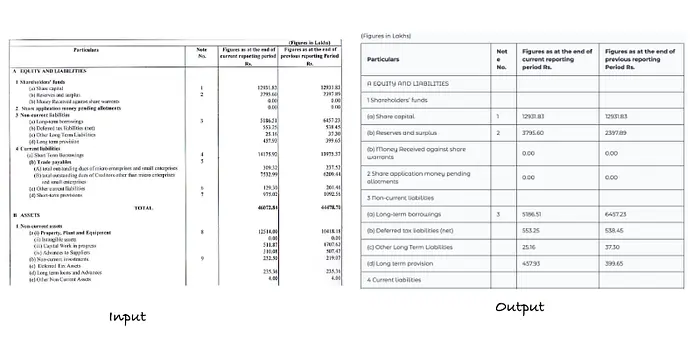
以HTML格式提取的示例表格数据
C) 文本准确性(打印和扫描文档)
对于打印和扫描的文档,文本准确性始终很强。
与Paddle OCR VL 或dots.ocr等系统相比,该模型:
- 更可靠地从噪声扫描中提取文本
- 保持更好的行和段落连续性
正如预期的那样,在干净的数字PDF上的性能非常出色,转录错误很少。
D) 多语言支持
除英语外,我还用包含印地语和孟加拉语打印文本的文档测试了该模型。
在这些情况下,该模型:
- 正确检测了脚本
- 保留了文本而没有中断或破坏转录
虽然这不是详尽的多语言评估,但初步结果对印度语言文档处理很有希望。
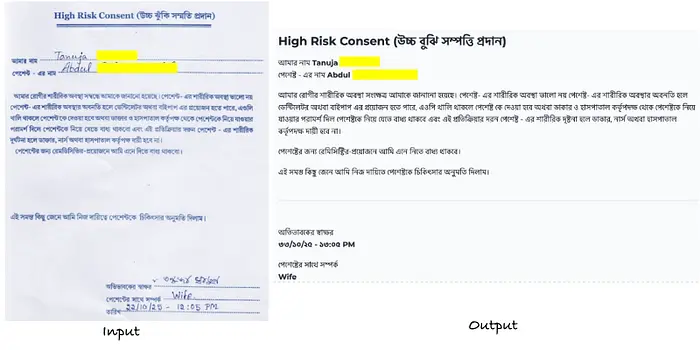
多语言提取的示例(我已经屏蔽了PII)。来源:作者
E) 手写输入
手写文本识别的表现超出预期。
该模型处理了:
- 半连笔手写
- 数字字段
- 混合手写和打印文档
虽然它不完美,但基线性能足够强,适用于表单和标注文档。
F) 表单输入理解
对于结构化表单,该模型展示了良好的理解:
- 字段分组
- 标签和值之间的逻辑分离
这使其适用于表单繁重的工作流程,如应用程序、声明和KYC文档。
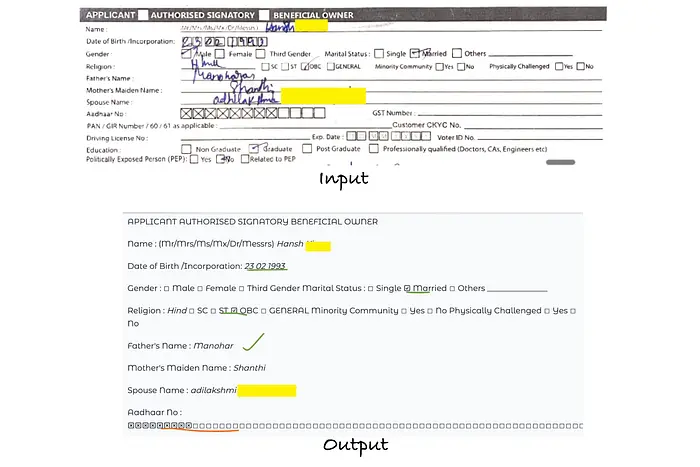
来自扫描应用程序表单的手写和表单键值理解的样本。(我已经屏蔽了PII)。来源:作者
G) 鲁棒性和稳定性
一个需要改进的领域是生成稳定性。
在少数情况下,我观察到模型陷入无限或过度长的生成。这主要是解码时间行为,而不是基本的建模问题。
在实践中,这可以通过调整几个生成参数来缓解:
- Temperature :严格将温度保持在
0有时会导致模型陷入重复循环。在我的经验中,设置一个小但非零值(大约0.2-0.3)会导致更稳定的完成。然而,确切的值取决于文档类型,应该在测试期间进行验证。 - 重复惩罚:应用温和的重复惩罚有助于防止长文档中的令牌循环,特别是表格繁重或多页输入。
- Top-k / Top-p采样 :使用保守的top-k或top-p值约束采样空间进一步提高了输出稳定性,而不损害结构保真度。
这些都不是阻塞问题,而是实际部署考虑因素。通过合理的解码默认值,稳定性问题在生产设置中大多可以管理。
6、结束语
我没有想到一个轻量级OCR模型能表现得这么好。
这次评估清楚地表明:今天的OCR不仅仅是关于文本提取。它是关于理解文档 ------ 布局、上下文,以及不同元素如何相互关联。
对于任何构建文档智能或文档解析系统或RAG应用程序的人来说,仍然是最关键的一步。下游一切的质量都取决于它。
这些结果基于初步测试,但它们足够扎实,让我们开始将模型集成到我们的 Kriyam.ai文档AI管道中,进行更深入的真实世界验证。
我将继续在生产工作负载上测试此模型,并随着我了解更多而分享更新。