以 Spring AI 框架为例,学习 AI 应用开发的核心特性 ------ 工具调用,大幅增强 AI 的能力,并实战主流工具的开发,熟悉工具的原理和高级特性。
工具调用介绍
什么是工具调用?
工具调用(Tool Calling)可以理解为让 AI 大模型 借用外部工具 来完成它自己做不到的事情。
跟人类一样,如果只凭手脚完成不了工作,那么就可以利用工具箱来完成。
工具可以是任何东西,比如网页搜索、对外部 API 的调用、访问外部数据、或执行特定的代码等。
比如用户提问 "帮我查询上海最新的天气",AI 本身并没有这些知识,它就可以调用 "查询天气工具",来完成任务。
目前工具调用技术发展的已经比较成熟了,几乎所有主流的、新出的 AI 大模型和 AI 应用开发平台都支持工具调用。
工具调用的工作原理
其实,工具调用的工作原理非常简单,并不是 AI 服务器自己调用这些工具、也不是把工具的代码发送给 AI 服务器让它执行,它只能提出要求,表示 "我需要执行 XX 工具完成任务"。而真正执行工具的是我们自己的应用程序,执行后再把结果告诉 AI,让它继续工作。
举个例子,假如用户提问 "知乎有哪些热门文章?",就需要经历下列流程:
- 用户提出问题:"知乎有哪些热门文章?"
- 程序将问题传递给大模型
- 大模型分析问题,判断需要使用工具(网页抓取工具)来获取信息
- 大模型输出工具名称和参数(网页抓取工具,URL 参数为 codefather.cn)
- 程序接收工具调用请求,执行网页抓取操作
- 工具执行抓取并返回文章数据
- 程序将抓取结果传回给大模型
- 大模型分析网页内容,生成关于知乎热门文章的回答
- 程序将大模型的回答返回给用户
工具调用和功能调用
大家可能看到过 Function Calling(功能调用)这个概念,别担心,其实它和 Tool Calling(工具调用)完全是同一概念!只是不同平台或每个人习惯的叫法不同而已。
Spring AI 工具调用文档 的开头就说明了这一点:
需要注意的是,不是所有大模型都支持工具调用。有些基础模型或早期版本可能不支持这个能力。可以在 Spring AI 官方文档 中查看各模型支持情况。
Spring AI 工具开发
首先我们通过 Spring AI 官方 提供的图片来理解 Spring AI 在实现工具调用时都帮我们做了哪些事情?
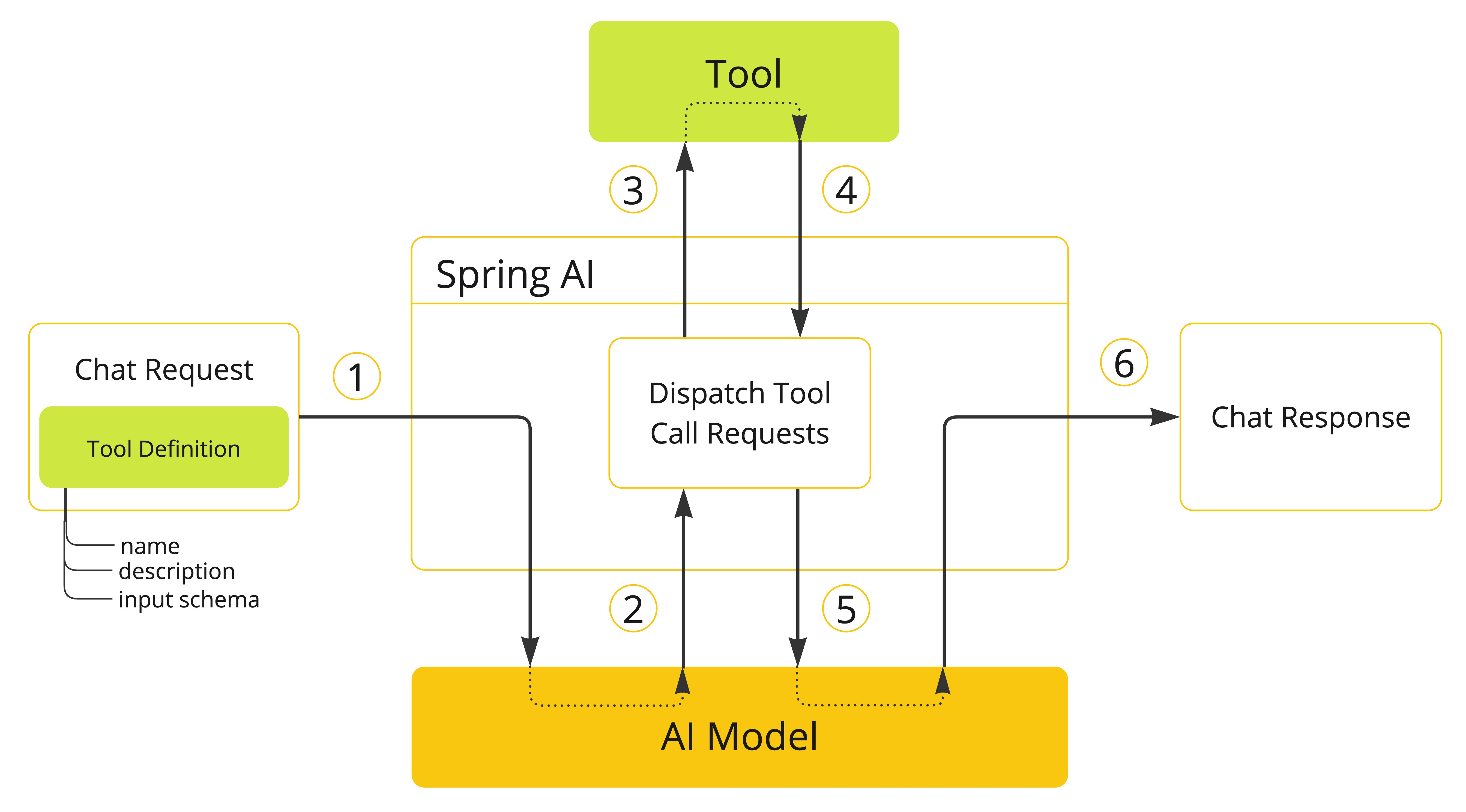
- 工具定义与注册:Spring AI 可以通过简洁的注解自动生成工具定义和 JSON Schema,让 Java 方法轻松转变为 AI 可调用的工具。
- 工具调用请求:Spring AI 自动处理与 AI 模型的通信并解析工具调用请求,并且支持多个工具链式调用。
- 工具执行:Spring AI 提供统一的工具管理接口,自动根据 AI 返回的工具调用请求找到对应的工具并解析参数进行调用,让开发者专注于业务逻辑实现。
- 处理工具结果:Spring AI 内置结果转换和异常处理机制,支持各种复杂 Java 对象作为返回值并优雅处理错误情况。
- 返回结果给模型:Spring AI 封装响应结果并管理上下文,确保工具执行结果正确传递给模型或直接返回给用户。
- 生成最终响应:Spring AI 自动整合工具调用结果到对话上下文,支持多轮复杂交互,确保 AI 回复的连贯性和准确性。
SpringAI自定义工具
SpringAI 工具调用的两种核心模式
SpringAI 提供的工具调用能力主要分为 声明式(注解驱动) 和 编程式(手动控制) 两种模式,前者主打 "低代码、高效率",后者主打 "高灵活、全可控",适配不同的开发场景。
1. 声明式工具调用(Declarative Tool Calling)
这是 SpringAI 推荐的极简模式,核心是基于注解自动注册工具,AI 模型会根据用户输入自动判断是否需要调用工具,无需你手动处理工具调用的流程逻辑。
核心特点
- 注解驱动:通过
@Tool(核心注解)标记工具方法,SpringAI 自动扫描并注册为可调用工具 - 自动触发:AI 模型根据用户提问的意图,自主决定是否调用工具及调用哪个工具
- 低代码:无需手动处理工具调用的解析、执行、结果回传等流程
2. 编程式工具调用(手动控制)
(承接声明式,补充编程式的核心场景和核心差异)声明式模式虽简洁,但无法满足动态场景(比如运行时动态添加 / 移除工具、动态修改 Function 参数、同一个 Function 绑定不同执行方法),此时需要编程式模式:
核心适用场景
- 动态调整工具:比如根据用户权限动态显示 / 隐藏部分工具;
- 复杂参数处理:比如 AI 返回的参数需要手动校验、转换后再执行方法;
- 多模型适配:同一套工具逻辑适配不同大模型(OpenAI、通义千问等)的 Function 格式差异;
- 工具调用监控:手动拦截工具调用过程,记录日志、统计耗时等。
开发主流工具实战
如果社区中没找到合适的工具,我们就要自主开发。需要注意的是,AI 自身能够实现的功能通常没必要定义为额外的工具,因为这会增加一次额外的交互,我们应该将工具用于 AI 无法直接完成的任务。
下面我们依次来实现需求分析中提到的 6 大工具,开发过程中我们要 格外注意工具描述的定义,因为它会影响 AI 决定是否使用工具。
先在项目根包下新建 tools 包,将所有工具类放在该包下;并且工具的返回值尽量使用 String 类型,让结果的含义更加明确。
文件操作
文件操作工具主要提供 2 大功能:保存文件、读取文件。
由于会影响系统资源,所以我们需要将文件统一存放到一个隔离的目录进行存储
1.新建AI操作的统一目录
2.配置目录路径
为了能让工具可以使用到此路径,我们需要配置到application.yml中。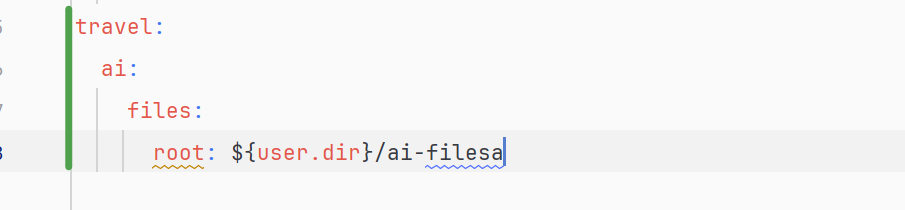
实现文本内容读写工具
在Tools包下创建TextFileTool类,实现文本内容读写
java
@Slf4j
@Component
public class TextFileTool {
@Value("${travel.ai.files.root}")
private String root;
/*
* 读取文本文件
* */
@Tool(description = "Read the content a text file")
public String readTextFile(@ToolParam(
description = "The name of text file to be read.", required = true
) String fileName, ToolContext toolContext){
// 获取当前会话的ID
String chatId = toolContext.getContext().get("chatId").toString();
log.info("AI 调用readTextFile工具读取'{}'文件,charId:{}", fileName, chatId);
if(chatId == null){
chatId = "";
}else {
chatId = chatId + "/";
}
String filePath = root +"/"+ chatId + fileName;
try{
// 读取文件并返回内容
String context = FileUtil.readUtf8String(filePath);
log.info("读取文件成功,文件内容:{}", filePath);
return context;
} catch (IORuntimeException e) {
log.error("读取文件失败,文件路径:'{}',错误信息:{}", filePath, e.getMessage());
return "Failed to read the file. Please check if the file path is correct" + e.getMessage();
}
}
@Tool(description = "Write the content a text file")
public String writeTextFile(
@ToolParam(description = "The name of text file to be written.", required = true)
String fileName,
@ToolParam(description = "The content to be written to the text file.", required = true)
String context,
ToolContext toolContext
){
// 获取当前会话的ID
String charId = toolContext.getContext().get("chatId").toString();
log.info("AI 调用writeTextFile工具写入'{}'文件", fileName);
if(charId == null){
charId = "";
}else {
charId = charId + "/";
}
String filePath = root +"/"+ charId + fileName;
try{
// 创建父目录
FileUtil.mkParentDirs(filePath);
// 写入文件
FileUtil.writeString(context, filePath, "utf-8");
log.info("写入文件成功,文件路径:{}", filePath);
return "The content has been successfully written to the file:"+ fileName;
} catch (IORuntimeException e) {
log.error("写入文件失败,文件路径:'{}',错误信息:{}", filePath, e.getMessage());
return "Failed to write to the file. Please check if the file path is correct" + e.getMessage();
}
}
}这是一个基于 SpringAI声明式工具调用实现的文件操作工具类,核心为 AI 模型提供「文本文件读取」和「文本文件写入」两个可调用工具,且会根据会话 ID(chatId)区分文件存储路径,实现不同会话的文件隔离,同时包含完善的异常处理和日志记录。
核心方法拆解
-
readTextFile(读取文本文件)
- 被
@Tool标记为 AI 可调用工具,描述为 "Read the content a text file"(告知 AI 该工具的用途); - 接收
fileName(必填文件名)和ToolContext(工具上下文),从上下文提取chatId(会话 ID); - 拼接文件路径:
根目录(root)/chatId/文件名(无 chatId 则直接为root/文件名); - 以 UTF-8 编码读取文件内容并返回,读取失败时捕获 IO 异常,记录错误日志并返回友好的失败提示。
- 被
-
writeTextFile(写入文本文件)
- 被
@Tool标记为 AI 可调用工具,描述为 "Write the content a text file"; - 接收
fileName(必填文件名)、context(必填写入内容)和ToolContext; - 同样按
root/chatId/文件名拼接路径,自动创建文件父目录(避免路径不存在报错); - 以 UTF-8 编码将内容写入文件,写入失败时捕获 IO 异常,记录错误日志并返回失败提示。
- 被
测试工具是否可用
创建一个单元测试,编写生成的测试方法:
java
@SpringBootTest
class TestFileToolTest {
@Resource
private TextFileTool textFileTool;
// 读写同一个文件
private final String fileName = "旅游建议.txt";
// 同一个会话ID
private final String chatId = "123456";
@Test
void readTextFile() {
// 创建一个自己的工具上下文
ToolContext toolContext = new ToolContext(Map.of("chatId",chatId));
String content = textFileTool.readTextFile(fileName, toolContext);
System.out.println(content);
assertNotNull(content); // 断言内容不为空
}
@Test
void writeTextFile() {
ToolContext toolContext = new ToolContext(Map.of("chatId",chatId));
String content = textFileTool.writeTextFile(fileName, "测试写入", toolContext);
System.out.println(content);
assertNotNull(content);
}
}然后我们先运行witeTextFile()方法写入文件,查看控制台日志,写入成功
查看项目目录中的ai-files,成功创建了以chatId为目录的文本文件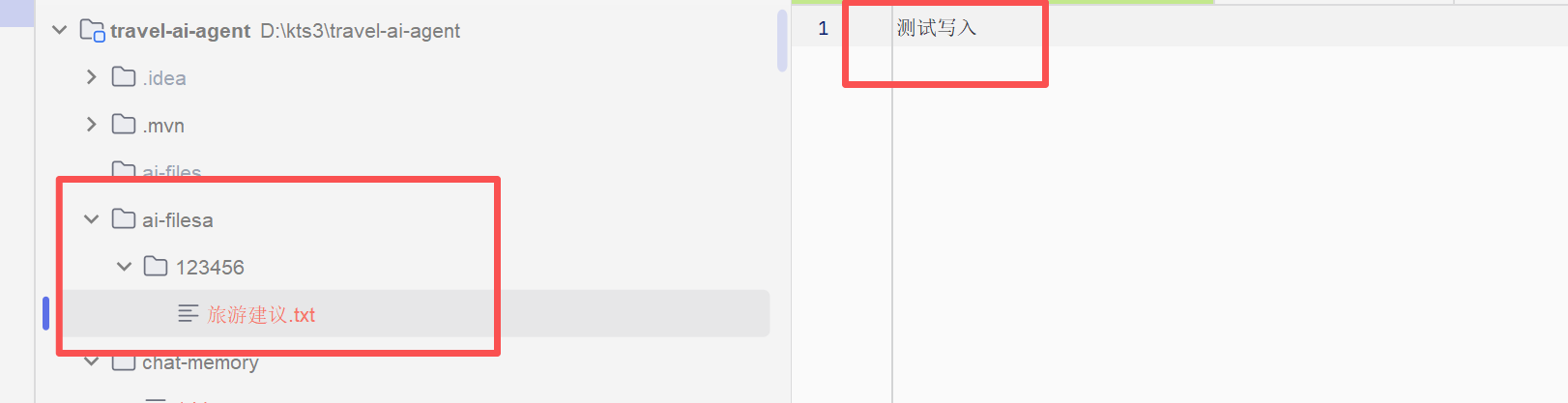
然后我们继续运行readTextFile()测试方法
正确读取内容,这样我们就编写了一个完整的工具了
联网搜索工具
联网搜索工具的作用是根据关键词搜索网页列表。
我们可以使用专业的网页搜索 API,如 Search API 来实现从多个网站搜索内容,这类服务通常按量计费。当然也可以直接使用 Google 或 Bing 的搜索 API(甚至是通过爬虫和网页解析从某个搜索引擎获取内容)。
注册并获得API Key
进入官网,注册以及登录
点击进去填写用户名,邮箱,密码,注册好之后进行登录
登录成功进入控制台我们可用看到Your API Key 点击Copy按钮复制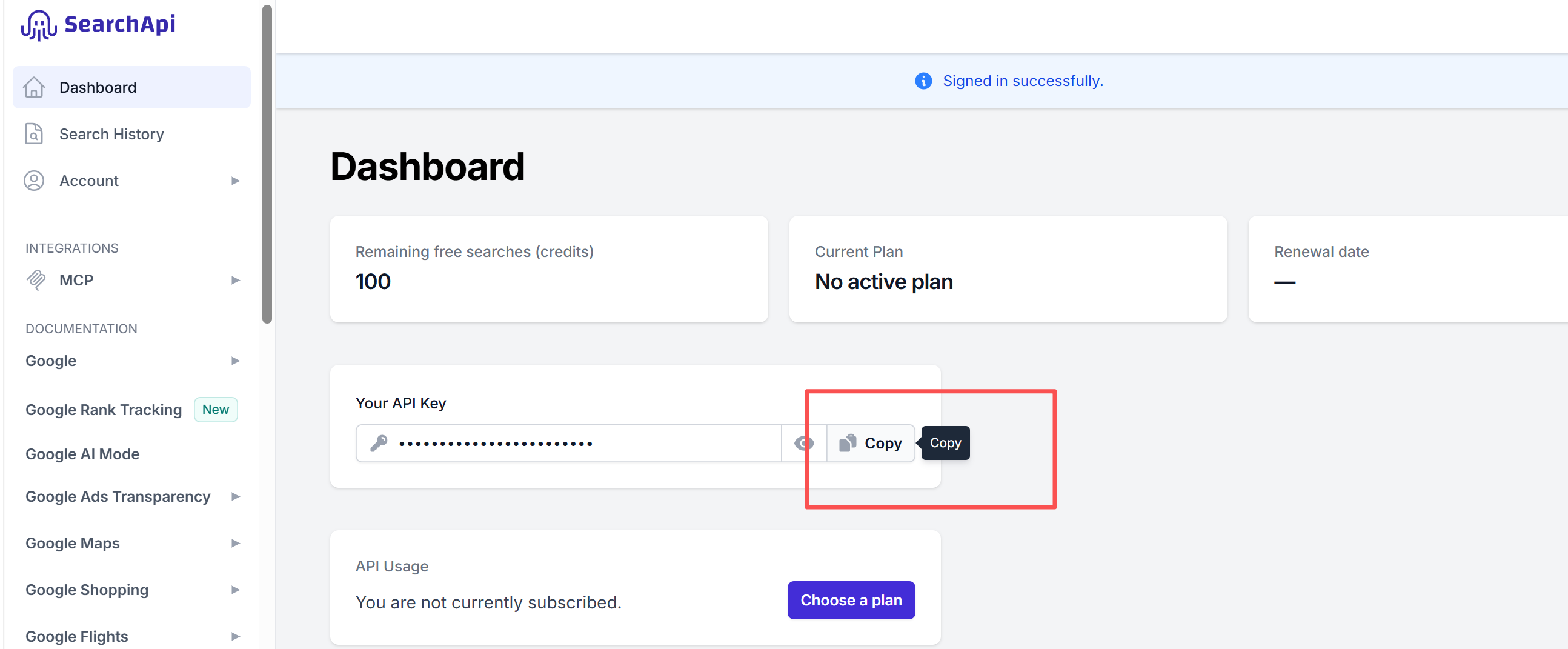
配置API Key
为了方便统一管理,我们在application.yml中添加统一的前缀:travel.ai.tools.api: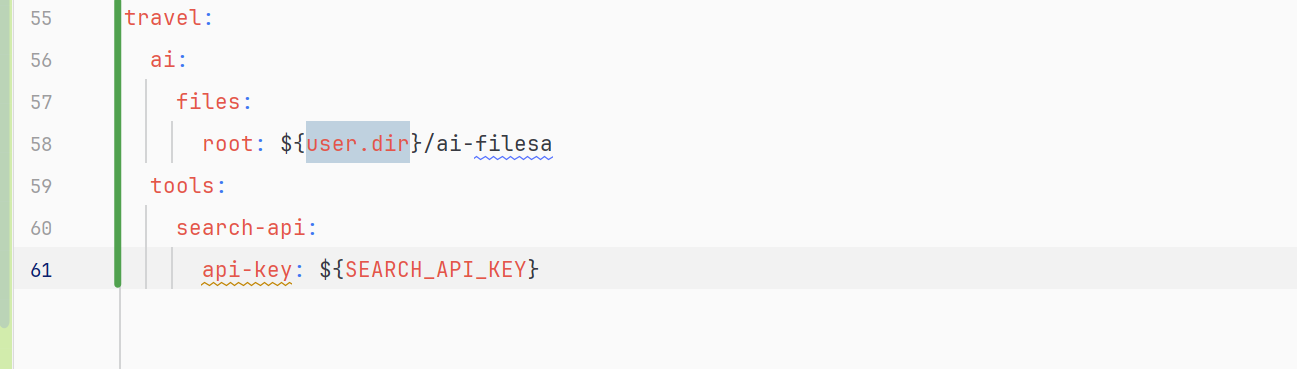
复制真实的API-KEY到application-dev.yml中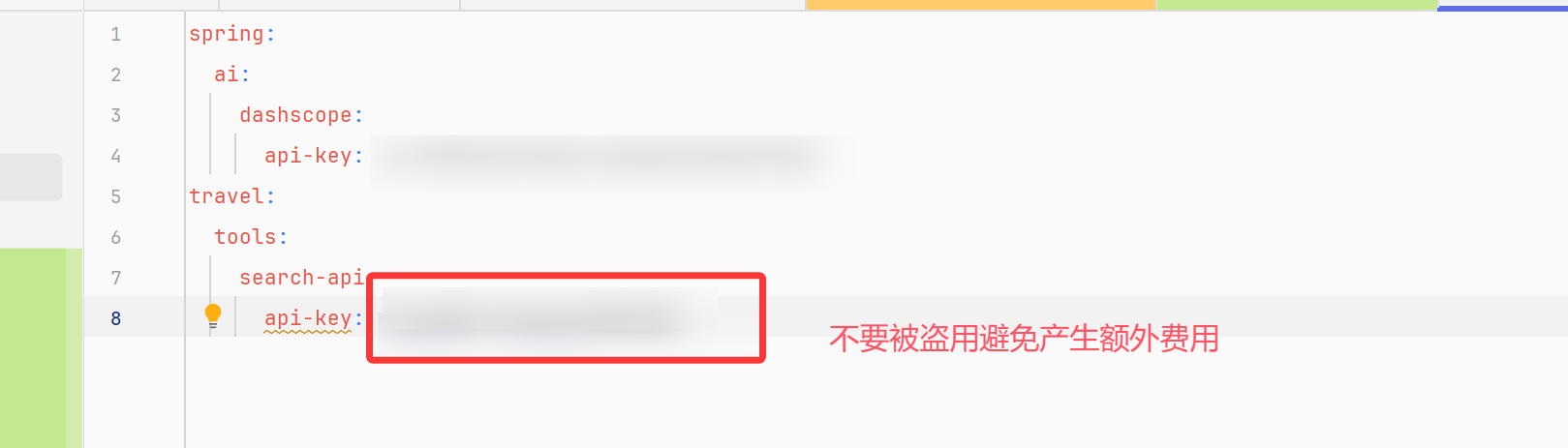
在SearchAPI控制台左侧菜单可用看到很多搜索引擎,我们主要是搜索国内的旅游景点,推荐使用baidu(就是广告较多)如果业务扩展到全球,我们可用使用Google搜索引擎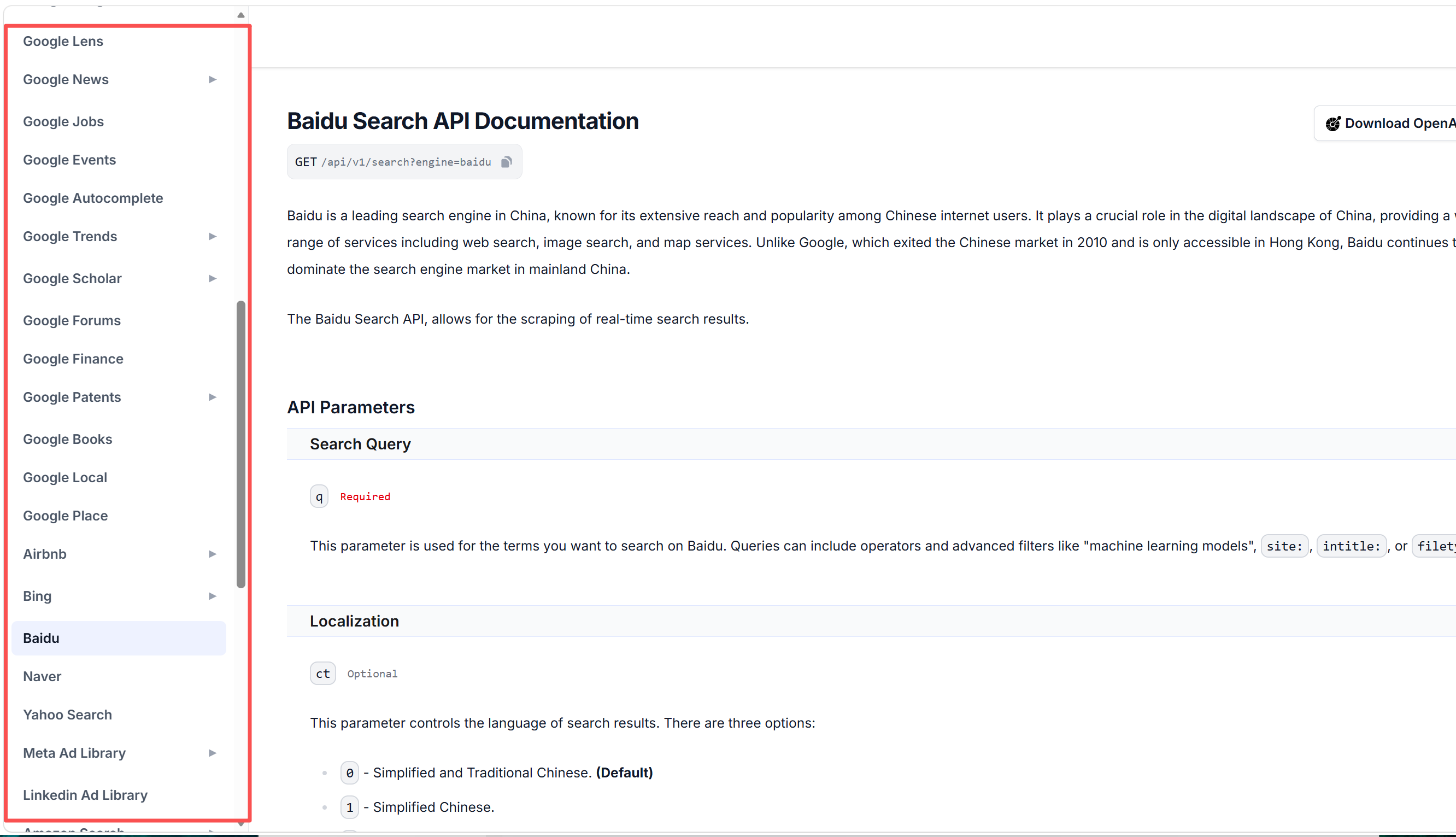
利用AI编程工具生成工具代码
理解了工具编写的方式,我们没必要每个功能都自己写,只需要将需求告知AI,让AI完成工具的编写,我们只需要保证工具正常使用即可,可用使用cursor,或其他AI工具这里我使用Qorde
1.使用Qorder打开项目
2.在tools包中新建WebSearchTool工具类
在新建的WebSearchTool类中添加apiKey的引入,避免AI工具自己联想胡编乱写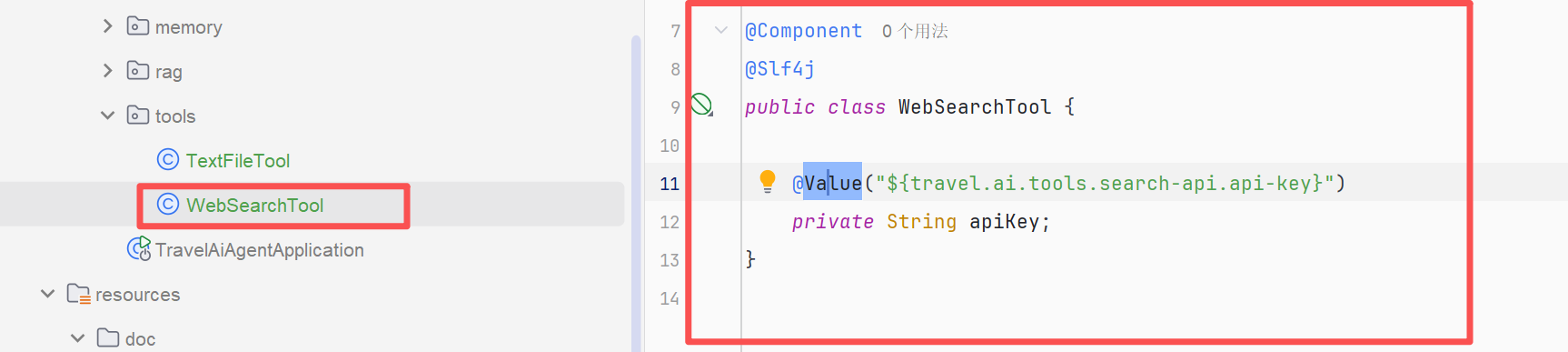
3.编写提示词,让ai工具帮我们阅读文档并生成方法
参考提示词:
参考源代码: @TextFileTool.java API文档https://www.searchapi.io/docs/baidu帮我实现一个能够执行搜索功能的Tool Calling 工具类 @WebSearchTool.java 要求
1.只提供一个方法,方法名searchWeb
2.返回字符串内容,包括搜索到的相关信息
3.方法尽量精简易懂,注释详细
4.利用已有的Hutoll工具包不添加依赖
5,最后提供单元测试不要修改其他内容
Qoder会根据你的提示词,并生成工具类和测试类

然后我们运行测试可看到正确的搜索结果: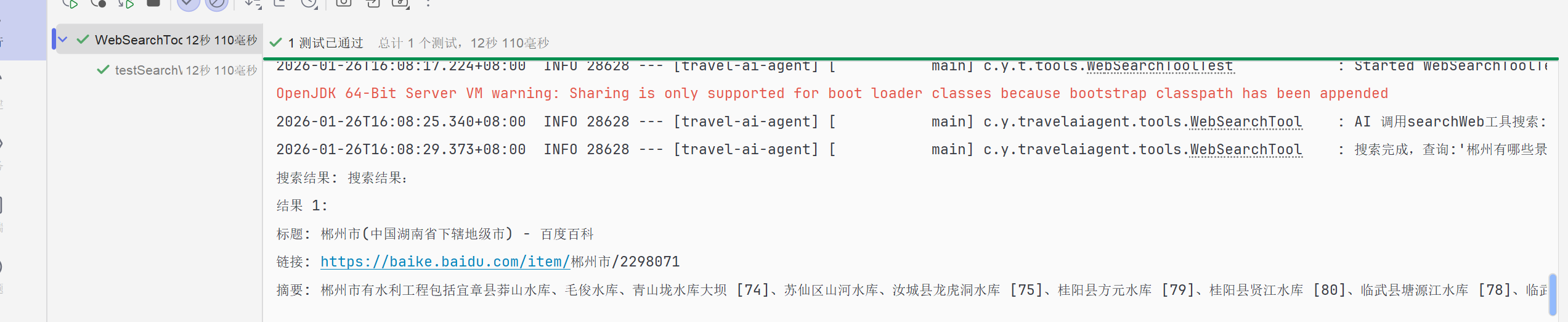
使用AI大模型进行工具测试
新增或修改WebSearchTool代码:
java
@SpringBootTest
public class WebSearchToolTest {
@Resource
private WebSearchTool webSearchTool;
@Resource
private TextFileTool textFileTool;
@Resource
private ChatModel dashscopeChatModel;
@Test
void searchWebAndSave(){
// 创建一个ChatClient
ChatClient chatClient = ChatClient.builder(dashscopeChatModel).build();
// 请求大模型获得结果
ChatResponse chatResponse = chatClient.prompt()
.user("帮我搜索长沙的景点,并保存到"长沙景点.txt"")
.tools(webSearchTool, textFileTool)
.toolContext(Map.of("chatId", "123456"))
.call()
.chatResponse();
String result = chatResponse.getResult().getOutput().getText();
System.out.println(result);
}
}上述代码中将webSearchTool, textFileTool,都注入了只对单个请求生效,如果要对所有请求生效的话可以匹配中ChatClient.builder.defaultTools进行默认工具注册
运行测试方法,我们会方式报错了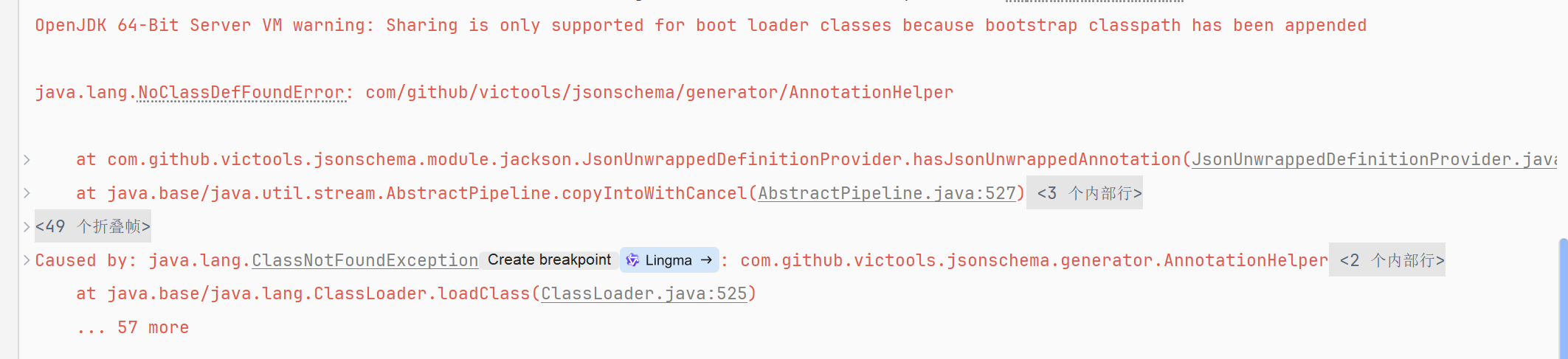
NoClassDefFoundError本质 :JVM 运行时找不到编译期依赖的AnnotationHelper类,该类属于victools/jsonschema-generator库 ------SpringAI 在生成工具调用的 JSON Schema(用于告诉 AI 模型工具的参数结构、必填项等元信息)时,核心依赖这个库;
在pom.xml文件中添加这个依赖
XML
<dependency>
<groupId>com.github.victools</groupId>
<artifactId>jsonschema-generator</artifactId>
<version>4.37.0</version>
</dependency>我们再次运行测试方法,得到了正确的响应: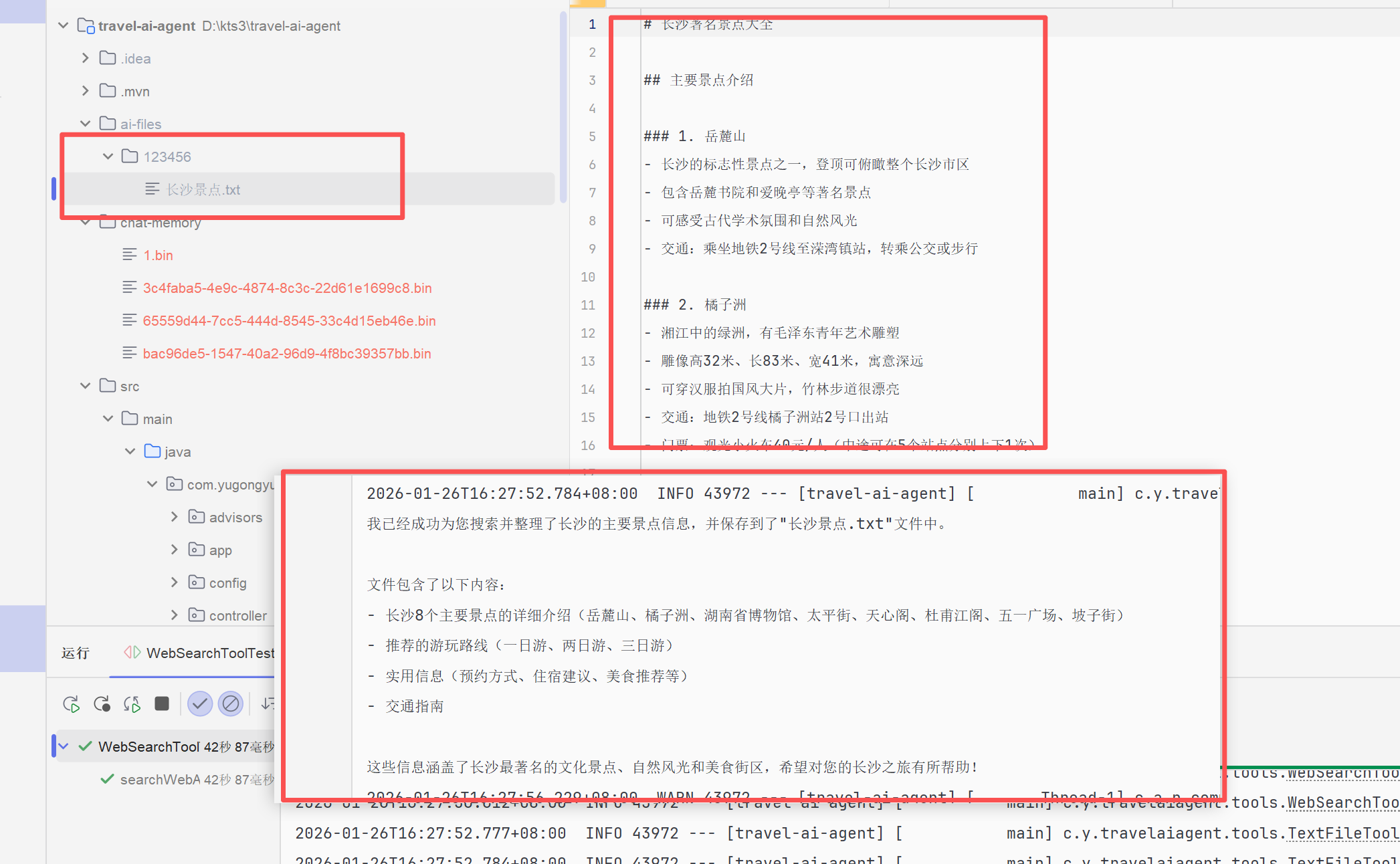
成功的搜索并且将内容保存为文本文件
对应代码:
java
@Component
@Slf4j
public class WebSearchTool {
@Value("${travel.ai.tools.search-api.api-key}")
private String apiKey;
/**
* 使用SearchAPI进行网络搜索
*
* @param query 搜索查询词
* @param toolContext 工具上下文
* @return 搜索结果字符串
*/
@Tool(description = "Search the web for information using SearchAPI")
public String searchWeb(
@ToolParam(description = "The search query to find information on the web.", required = true)
String query,
ToolContext toolContext) {
log.info("AI 调用searchWeb工具搜索:'{}'", query);
try {
// 构建请求参数
Map<String, Object> params = new HashMap<>();
params.put("q", query);
params.put("api_key", apiKey);
params.put("engine", "baidu");
// 发送HTTP GET请求到SearchAPI
String response = HttpUtil.get("https://www.searchapi.io/api/v1/search", params);
// 解析响应并提取相关信息
Map<String, Object> jsonResponse = JSONUtil.toBean(response, Map.class);
StringBuilder result = new StringBuilder();
result.append("搜索结果:\n");
// 提取搜索结果中的标题和链接
if (jsonResponse.containsKey("organic_results")) {
@SuppressWarnings("unchecked")
java.util.List<Map<String, Object>> organicResults =
(java.util.List<Map<String, Object>>) jsonResponse.get("organic_results");
for (int i = 0; i < Math.min(organicResults.size(), 5); i++) { // 只取前5个结果
Map<String, Object> resultItem = organicResults.get(i);
String title = (String) resultItem.getOrDefault("title", "");
String link = (String) resultItem.getOrDefault("link", "");
String snippet = (String) resultItem.getOrDefault("snippet", "");
result.append("结果 ").append(i + 1).append(":\n");
result.append("标题: ").append(title).append("\n");
result.append("链接: ").append(link).append("\n");
result.append("摘要: ").append(snippet).append("\n\n");
}
} else {
result.append("未找到相关搜索结果");
}
log.info("搜索完成,查询:'{}'", query);
return result.toString();
} catch (Exception e) {
log.error("搜索失败,查询:'{}', 错误信息: {}", query, e.getMessage());
return "搜索失败,请检查API密钥或网络连接:" + e.getMessage();
}
}
}实现网页抓取工具
我们已经掌握了编写工具和AI编写工具的方式剩下的都交给AI打工
搜索到网址我们还需要能够读取到网页的内容,让AI大模型能掌握最新的信息
1.在tools包下创建一个WebScrapingTool工具类型
2.使用AI工具打开项目参考提示词如下:
参考源代码: TextFileTool.java 帮我实现一个能够读取网页内容的Tool calling工具类 WebScrapingTool.java` 要求
1.只提供一个方法,方法名scrapeWebContent,参数必须添加ToolContent
2.返回字符串内容,包括Html中的关键内容,忽略样式和脚本等无关内容
3.方法尽量精简易懂,注释详细
4.可以依赖开源的jsoup工具读取网页,不增加其他依赖
5.最后提供单元测试
最后他会生成对应的单元测试以及工具
对应代码:
java
/**
* 网页内容抓取工具类
* 用于读取网页内容并提取关键信息
*/
@Component
@Slf4j
public class WebScrapingTool {
/**
* 抓取网页内容
*
* @param url 网页URL地址
* @param toolContext 工具上下文
* @return 网页中的关键内容,忽略样式和脚本等无关内容
*/
@Tool(description = "Scrape web content from a URL and extract key information")
public String scrapeWebContent(
@ToolParam(description = "The URL of the web page to scrape", required = true)
String url,
ToolContext toolContext) {
log.info("AI 调用scrapeWebContent工具抓取网页: '{}'", url);
try {
// 使用jsoup连接并获取网页文档
Document document = Jsoup.connect(url)
.userAgent("Mozilla/5.0") // 设置用户代理,模拟浏览器请求
.timeout(10000) // 设置超时时间为10秒
.get();
// 移除样式和脚本内容
Elements styleElements = document.select("style");
styleElements.remove();
Elements scriptElements = document.select("script");
scriptElements.remove();
// 提取标题
String title = document.title();
// 提取正文内容(优先获取main、article、div.content等主要内容区域)
StringBuilder content = new StringBuilder();
content.append("网页标题: ").append(title).append("\n\n");
content.append("网页内容:\n");
// 尝试获取主要内容区域
Elements mainContent = document.select("main, article, .content, .article-content");
if (!mainContent.isEmpty()) {
// 如果找到主要内容区域,提取其文本
for (Element element : mainContent) {
String text = element.text();
if (!text.isEmpty()) {
content.append(text).append("\n\n");
}
}
} else {
// 如果没有找到主要内容区域,提取body中的文本
String bodyText = document.body().text();
if (!bodyText.isEmpty()) {
content.append(bodyText);
} else {
content.append("未找到网页内容");
}
}
// 限制返回内容长度,避免内容过长
String result = content.toString();
if (result.length() > 3000) {
result = result.substring(0, 3000) + "\n\n...(内容过长,已截断)";
}
log.info("网页抓取成功,URL: '{}'", url);
return result;
} catch (IOException e) {
log.error("网页抓取失败,URL: '{}', 错误信息: {}", url, e.getMessage());
return "网页抓取失败,请检查URL是否正确或网络连接是否正常:" + e.getMessage();
} catch (Exception e) {
log.error("网页抓取异常,URL: '{}', 错误信息: {}", url, e.getMessage());
return "网页抓取异常:" + e.getMessage();
}
}
}资源下载工具
资源下载工具的作用是通过链接下载文件到本地
1.在tools包下创建DownloadTool,最好参考TextFileTool
2.使用AI工具打开项目参考提示词如下:
参考源代码: `TextFileTool.java` 帮我实现一个能够下载网络资源的Tool calling工具类 DownloadTool.java`
要求:
1.只提供一个方法,方法名download,提供下载url,参数必须添加ToolContent
2下载后文件名需要重命名避免重复,返回文件名
3.方法尽量精简易懂,注释详细
4.如无必要,不要增加其他依赖,充分利用Hutool工具包
5.最后提供单元测试,不要修改其他文件
AI生成对应的工具以及单元测试: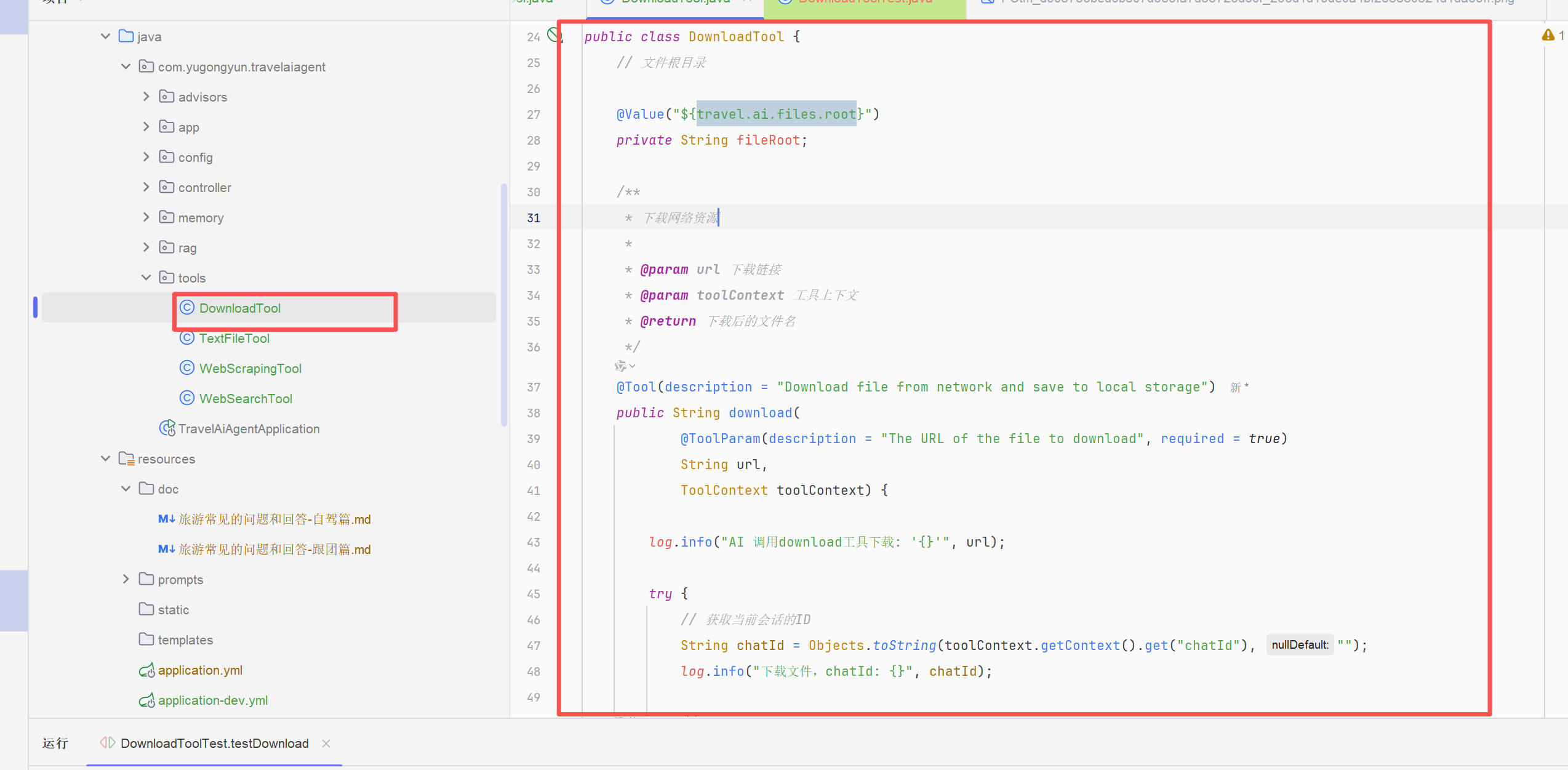
可以看到他成功将百度的logo下载到了本地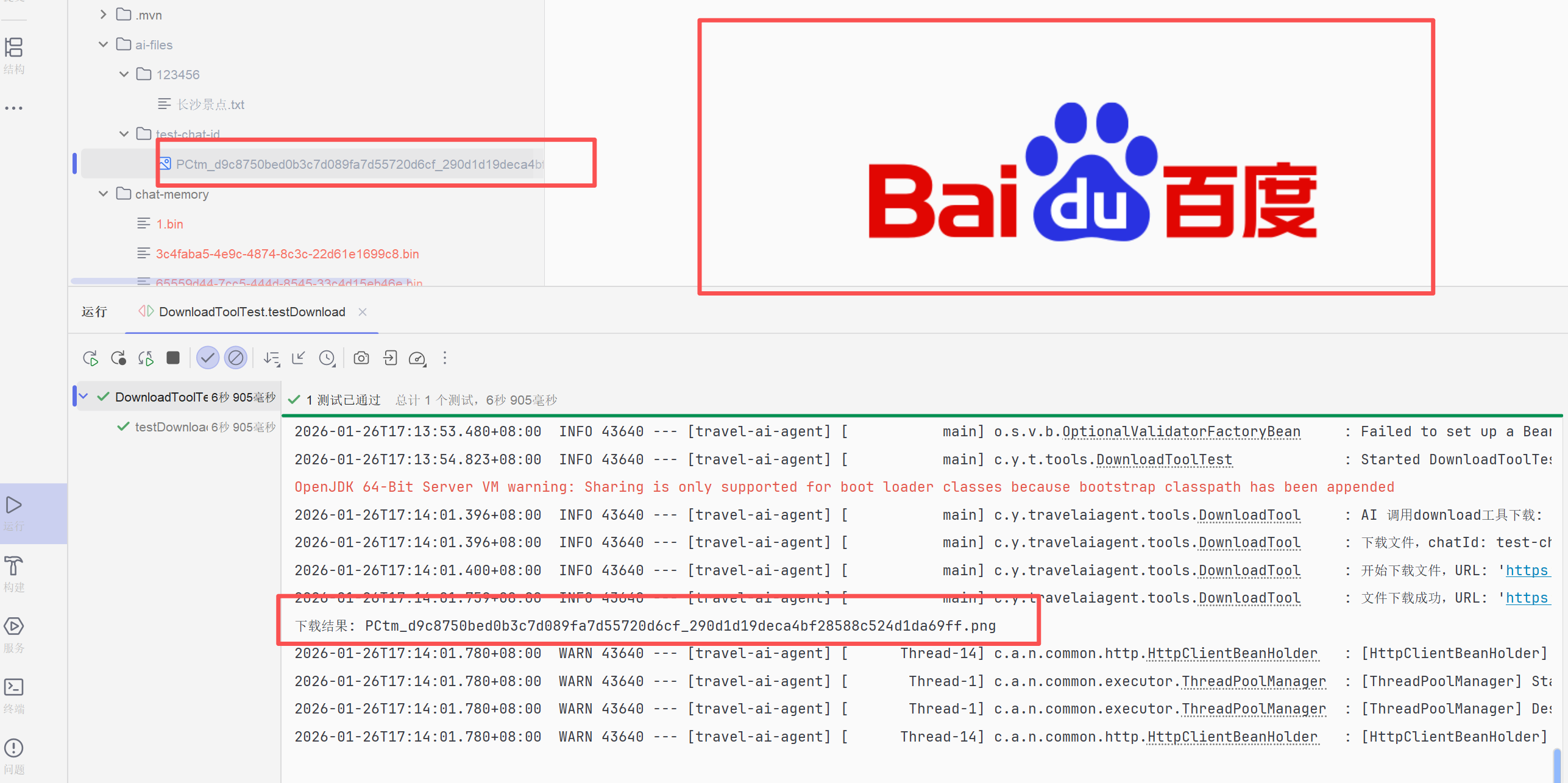
对应代码
java
@Component
@Slf4j
public class DownloadTool {
// 文件根目录
@Value("${travel.ai.files.root}")
private String fileRoot;
/**
* 下载网络资源
*
* @param url 下载链接
* @param toolContext 工具上下文
* @return 下载后的文件名
*/
@Tool(description = "Download file from network and save to local storage")
public String download(
@ToolParam(description = "The URL of the file to download", required = true)
String url,
ToolContext toolContext) {
log.info("AI 调用download工具下载: '{}'", url);
try {
// 获取当前会话的ID
String chatId = Objects.toString(toolContext.getContext().get("chatId"), "");
log.info("下载文件,chatId: {}", chatId);
// 构建存储目录路径
String directoryPath = fileRoot;
if (!chatId.isEmpty()) {
directoryPath = directoryPath + "/" + chatId;
}
// 创建存储目录
FileUtil.mkdir(directoryPath);
// 从URL中提取原始文件名
String originalFileName = getFileNameFromUrl(url);
// 生成唯一文件名,避免重复
String uniqueFileName = generateUniqueFileName(originalFileName);
// 构建完整的文件路径
String filePath = directoryPath + "/" + uniqueFileName;
// 下载文件
log.info("开始下载文件,URL: '{}', 保存路径: '{}'", url, filePath);
HttpUtil.downloadFile(url, filePath);
// 验证文件是否下载成功
File downloadedFile = new File(filePath);
if (downloadedFile.exists() && downloadedFile.length() > 0) {
log.info("文件下载成功,URL: '{}', 保存路径: '{}'", url, filePath);
return uniqueFileName;
} else {
log.error("文件下载失败,URL: '{}', 文件不存在或为空", url);
return "文件下载失败:下载的文件不存在或为空";
}
} catch (IORuntimeException e) {
log.error("文件下载失败,URL: '{}', 错误信息: {}", url, e.getMessage());
return "文件下载失败,请检查URL是否正确或网络连接是否正常:" + e.getMessage();
} catch (Exception e) {
log.error("文件下载异常,URL: '{}', 错误信息: {}", url, e.getMessage());
return "文件下载异常:" + e.getMessage();
}
}
/**
* 从URL中提取文件名
*
* @param url 下载链接
* @return 文件名
*/
private String getFileNameFromUrl(String url) {
try {
URL urlObj = new URL(url);
String path = urlObj.getPath();
if (path != null && !path.isEmpty()) {
int lastSlashIndex = path.lastIndexOf('/');
if (lastSlashIndex != -1 && lastSlashIndex < path.length() - 1) {
return path.substring(lastSlashIndex + 1);
}
}
// 如果无法从URL中提取文件名,使用默认文件名
return "download_" + System.currentTimeMillis();
} catch (Exception e) {
// 如果URL解析失败,使用默认文件名
return "download_" + System.currentTimeMillis();
}
}
/**
* 生成唯一文件名,避免重复
*
* @param originalFileName 原始文件名
* @return 唯一文件名
*/
private String generateUniqueFileName(String originalFileName) {
// 提取文件扩展名
String extension = "";
int lastDotIndex = originalFileName.lastIndexOf('.');
if (lastDotIndex != -1 && lastDotIndex < originalFileName.length() - 1) {
extension = originalFileName.substring(lastDotIndex);
originalFileName = originalFileName.substring(0, lastDotIndex);
}
// 生成唯一标识符
String uniqueId = IdUtil.fastSimpleUUID();
// 构建唯一文件名
return originalFileName + "_" + uniqueId + extension;
}
}实现PDF生成工具
PDF 生成工具的作用是根据文件名和内容生成 PDF 文档并保存。
可以使用 itext 库 实现 PDF 生成。需要注意的是,itext 对中文字体的支持需要额外配置,不同操作系统提供的字体也不同,如果真要做生产级应用,建议自行下载所需字体。
实现步骤:
1.在tools包下创建PdfGenerateTool工具类型
2.参考提示词:
参考源代码:@TextFileTool.java
帮我实现一个能够"PDF 生成"的 Tool Calling 工具类@PdfGenerateTool.java
要求:
1、提供生成PDF的工具方法generatePdf(注意中文字体处理),传递参数:【文件名】,【文本类型】(支持:text、markdown,html三种格式),【文本内容】和ToolContext。将生成的PDF文件参考TextFileTo0l.java的保存路径进行保存,最终文件名需要拼接时间等信息,避免重复,方法返回最终文件名。
2、在描述中明确告知:可用于生成旅游报告,只允许引用图片源,可通过markdown和html生成图
文并茂的PDF报告,资源需先通过下载工具DownloadTool下载到指定目录通过相对路径进行引用3、如果是markdown和html格式,需可生成图文并茂的PDF,注意图片资源的处理(设置基础路径)4、检查引用的图片资源,相对路径则检查工作路径(参考TextFileTool.java的保存路径),存在则直接使用,网络地址则下载使用
5、允许增加辅助私有方法,方法尽量精简易懂,注释详细
6、增加itext依赖,注意一定要确定依赖存在不要杜撰,并充分利用己有的hutool工具包
7、最后提供单元测试,不要修改其他文件
生成的代码:
java
@Slf4j
@Component
public class PdfGenerateTool {
@Value("${travel.ai.files.root}")
private String root;
/**
* 生成PDF文件的工具方法
* <p>可用于生成旅游报告,只允许引用图片源,可通过markdown和html生成图文并茂的PDF报告</p>
* <p>资源需先通过下载工具DownloadTool下载到指定目录通过相对路径进行引用</p>
*
* @param fileName 文件名
* @param contentType 文本类型,支持:text、markdown、html三种格式
* @param content 文本内容
* @param toolContext 工具上下文
* @return 生成的PDF文件名
*/
@Tool(description = "Generate a PDF file from text content. Supported formats: text, markdown, html. Can be used for generating travel reports with images. Images should be referenced via relative paths after being downloaded with DownloadTool.")
public String generatePdf(
@ToolParam(description = "The name of the PDF file to be generated.", required = true)
String fileName,
@ToolParam(description = "The content type, supports: text, markdown, html.", required = true)
String contentType,
@ToolParam(description = "The content to be converted to PDF.", required = true)
String content,
ToolContext toolContext) {
try {
// 获取当前会话的ID
String chatId = toolContext.getContext().get("chatId").toString();
log.info("AI 调用generatePdf工具生成'{}'文件,内容类型:{},charId:{}", fileName, contentType, chatId);
if (chatId == null) {
chatId = "";
} else {
chatId = chatId + "/";
}
// 确保目录存在
String basePath = root + "/" + chatId;
FileUtil.mkdir(basePath);
// 生成唯一的文件名
String uniqueFileName = generateUniqueFileName(fileName);
String outputPath = basePath + uniqueFileName;
// 根据内容类型生成PDF
if ("text".equalsIgnoreCase(contentType)) {
generateTextPdf(content, outputPath, basePath);
} else if ("markdown".equalsIgnoreCase(contentType)) {
// 将markdown转换为html
String htmlContent = convertMarkdownToHtml(content);
generateHtmlPdf(htmlContent, outputPath, basePath);
} else if ("html".equalsIgnoreCase(contentType)) {
generateHtmlPdf(content, outputPath, basePath);
} else {
throw new IllegalArgumentException("Unsupported content type: " + contentType);
}
log.info("PDF生成成功,文件路径:{}", outputPath);
return uniqueFileName;
} catch (Exception e) {
log.error("PDF生成失败", e);
return "Failed to generate PDF: " + e.getMessage();
}
}
/**
* 生成唯一的文件名,避免重复
*
* @param originalFileName 原始文件名
* @return 唯一的文件名
*/
private String generateUniqueFileName(String originalFileName) {
String timestamp = DateUtil.format(DateUtil.date(), "yyyyMMddHHmmssSSS");
String fileNameWithoutExt = FileUtil.mainName(originalFileName);
return fileNameWithoutExt + "_" + timestamp + ".pdf";
}
/**
* 生成纯文本PDF
*
* @param content 文本内容
* @param outputPath 输出路径
* @param basePath 基础路径
* @throws Exception 异常
*/
private void generateTextPdf(String content, String outputPath, String basePath) throws Exception {
// 创建PDF文档
PdfDocument pdfDoc = new PdfDocument(new PdfWriter(outputPath));
Document document = new Document(pdfDoc, PageSize.A4);
try {
// 添加内容
Paragraph paragraph = new Paragraph(content);
paragraph.setTextAlignment(TextAlignment.LEFT);
paragraph.setFontSize(12);
document.add(paragraph);
} finally {
document.close();
pdfDoc.close();
}
}
/**
* 生成Markdown PDF
*
* @param markdownContent Markdown内容
* @param outputPath 输出路径
* @param basePath 基础路径
* @throws Exception 异常
*/
private void generateMarkdownPdf(String markdownContent, String outputPath, String basePath) throws Exception {
// 创建PDF文档
PdfDocument pdfDoc = new PdfDocument(new PdfWriter(outputPath));
Document document = new Document(pdfDoc, PageSize.A4);
try {
// 直接解析Markdown内容
String[] lines = markdownContent.split("\\n");
for (String line : lines) {
line = line.trim();
if (line.startsWith("# ")) {
// 一级标题
String text = line.substring(2).trim();
document.add(new Paragraph(text).setFontSize(20).setBold());
} else if (line.startsWith("## ")) {
// 二级标题
String text = line.substring(3).trim();
document.add(new Paragraph(text).setFontSize(16).setBold());
} else if (line.startsWith("### ")) {
// 三级标题
String text = line.substring(4).trim();
document.add(new Paragraph(text).setFontSize(14).setBold());
} else if (line.startsWith("- ")) {
// 列表项
String text = line.substring(2).trim();
document.add(new Paragraph("- " + text).setFontSize(12).setMarginLeft(20));
} else if (line.startsWith("! `")) {
// 特殊格式的图片链接:! `url`
int start = line.indexOf("`") + 1;
int end = line.lastIndexOf("`");
if (start > 0 && end > start) {
String src = line.substring(start, end).trim();
document.add(new Paragraph("[图片: " + src + "]").setFontSize(12));
}
} else if (line.startsWith("
int altEnd = line.indexOf("]", 2);
if (altEnd > 2 && line.startsWith("(", altEnd + 1)) {
int srcEnd = line.indexOf(")", altEnd + 2);
if (srcEnd > altEnd + 2) {
String alt = line.substring(2, altEnd);
String src = line.substring(altEnd + 2, srcEnd);
document.add(new Paragraph("[图片: " + src + "]").setFontSize(12));
}
}
} else if (!line.isEmpty()) {
// 普通文本
document.add(new Paragraph(line).setFontSize(12));
}
}
} finally {
document.close();
pdfDoc.close();
}
}
/**
* 生成HTML PDF
*
* @param htmlContent HTML内容
* @param outputPath 输出路径
* @param basePath 基础路径
* @throws Exception 异常
*/
private void generateHtmlPdf(String htmlContent, String outputPath, String basePath) throws Exception {
// 处理图片路径
String processedHtml = processImagePaths(htmlContent, basePath);
// 直接使用HtmlConverter.convertToPdf方法
try (FileOutputStream fos = new FileOutputStream(outputPath)) {
// 设置基础URI,用于处理相对路径的图片
com.itextpdf.html2pdf.ConverterProperties properties = new com.itextpdf.html2pdf.ConverterProperties();
properties.setBaseUri(basePath);
// 直接转换HTML为PDF文件
HtmlConverter.convertToPdf(processedHtml, fos, properties);
}
}
/**
* 处理HTML中的图片路径
*
* @param htmlContent HTML内容
* @param basePath 基础路径
* @return 处理后的HTML内容
*/
private String processImagePaths(String htmlContent, String basePath) {
// 使用Jsoup解析HTML
org.jsoup.nodes.Document doc = Jsoup.parse(htmlContent);
// 处理所有img标签
for (org.jsoup.nodes.Element img : doc.select("img")) {
String src = img.attr("src");
if (StrUtil.isNotEmpty(src)) {
// 检查是否是网络地址
if (src.startsWith("http://") || src.startsWith("https://")) {
// 网络地址,保留原样,iText会自动下载
log.info("Found network image: {}", src);
} else {
// 相对路径,检查文件是否存在
String imagePath = basePath + src;
File imageFile = new File(imagePath);
if (imageFile.exists()) {
log.info("Found local image: {}", imagePath);
} else {
log.warn("Local image not found: {}", imagePath);
}
}
}
}
return doc.html();
}
/**
* 将Markdown转换为HTML
*
* @param markdown Markdown内容
* @return HTML内容
*/
private String convertMarkdownToHtml(String markdown) {
// 简单的markdown到html转换
StringBuilder html = new StringBuilder();
html.append("<!DOCTYPE html><html><head>");
html.append("<meta charset='UTF-8'>");
html.append("<style>");
html.append("body { font-family: Arial, sans-serif; line-height: 1.6; padding: 20px; color: #000; }");
html.append("h1, h2, h3 { color: #000; font-weight: bold; margin: 10px 0; }");
html.append("p { color: #000; margin: 10px 0; }");
html.append("ul { color: #000; margin: 10px 0 10px 20px; }");
html.append("li { color: #000; margin: 5px 0; }");
html.append("img { max-width: 100%; height: auto; margin: 10px 0; }");
html.append("</style>");
html.append("</head><body>");
// 确保内容不为空
if (markdown == null || markdown.trim().isEmpty()) {
html.append("<p>无内容</p>");
} else {
// 按行处理
String[] lines = markdown.split("\\n");
for (String line : lines) {
String originalLine = line;
line = line.trim();
// 记录处理的行
log.info("Processing line: '" + originalLine + "' -> trimmed: '" + line + "'");
if (line.startsWith("# ")) {
// 一级标题
String title = line.substring(2).trim();
log.info("Processing h1: '" + title + "'");
html.append("<h1>").append(title).append("</h1>");
} else if (line.startsWith("## ")) {
// 二级标题
String title = line.substring(3).trim();
log.info("Processing h2: '" + title + "'");
html.append("<h2>").append(title).append("</h2>");
} else if (line.startsWith("### ")) {
// 三级标题
String title = line.substring(4).trim();
log.info("Processing h3: '" + title + "'");
html.append("<h3>").append(title).append("</h3>");
} else if (line.startsWith("- ")) {
// 无序列表
String item = line.substring(2).trim();
log.info("Processing list item: '" + item + "'");
html.append("<ul><li>").append(item).append("</li></ul>");
} else if (line.startsWith("![")) {
// 图片
int altEnd = line.indexOf("]", 2);
if (altEnd > 2 && line.startsWith("(", altEnd + 1)) {
int srcEnd = line.indexOf(")", altEnd + 2);
if (srcEnd > altEnd + 2) {
String alt = line.substring(2, altEnd);
String src = line.substring(altEnd + 2, srcEnd);
log.info("Processing image: alt='" + alt + "', src='" + src + "'");
html.append("<img src='").append(src).append("' alt='").append(alt).append("'>");
}
}
} else if (line.startsWith("! `")) {
// 处理特殊格式的图片链接:! `url`
int start = line.indexOf("`") + 1;
int end = line.lastIndexOf("`");
if (start > 0 && end > start) {
String src = line.substring(start, end).trim();
log.info("Processing special image: src='" + src + "'");
html.append("<img src='").append(src).append("' alt='图片'>");
}
} else if (line.contains("http://") || line.contains("https://")) {
// 处理直接的图片链接
log.info("Processing direct image link: '" + line + "'");
html.append("<img src='").append(line).append("' alt='图片'>");
} else if (!line.isEmpty()) {
// 普通文本
log.info("Processing plain text: '" + line + "'");
html.append("<p>").append(line).append("</p>");
} else {
// 空行
log.info("Processing empty line");
}
}
}
html.append("</body></html>");
// 记录生成的HTML
log.info("Generated HTML: '" + html.toString() + "'");
return html.toString();
}
}工具注册使用
开发好了这么多工具类后,结合我们自己的需求,可以AI一次性提供所有工具,可以给AI一次性提供所有工具,让他自己决定何时调用。所以我们可以创建AI工具配置类,方便统一管理和绑定所有工具
创建AI工具配置类
创建config包,新建Tools4AIConfig配置类,代码:
java
@Configuration
public class Tools4AIConfig {
@Resource
private TextFileTool textFileTool;
@Resource
private WebScrapingTool webScrapingTool;
@Resource
private WebSearchTool webSearchTool;
@Resource
private DownloadTool downloadTool;
@Resource
private PdfGenerateTool pdfGenerateTool;
@Bean
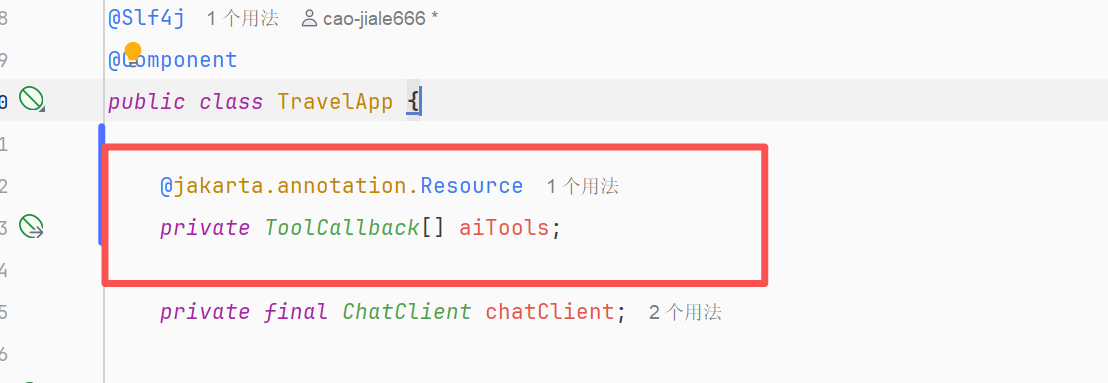
public ToolCallback[] aiTools(){
return ToolCallbacks.from(
textFileTool,
webScrapingTool,
webSearchTool,
downloadTool,
pdfGenerateTool
);
}
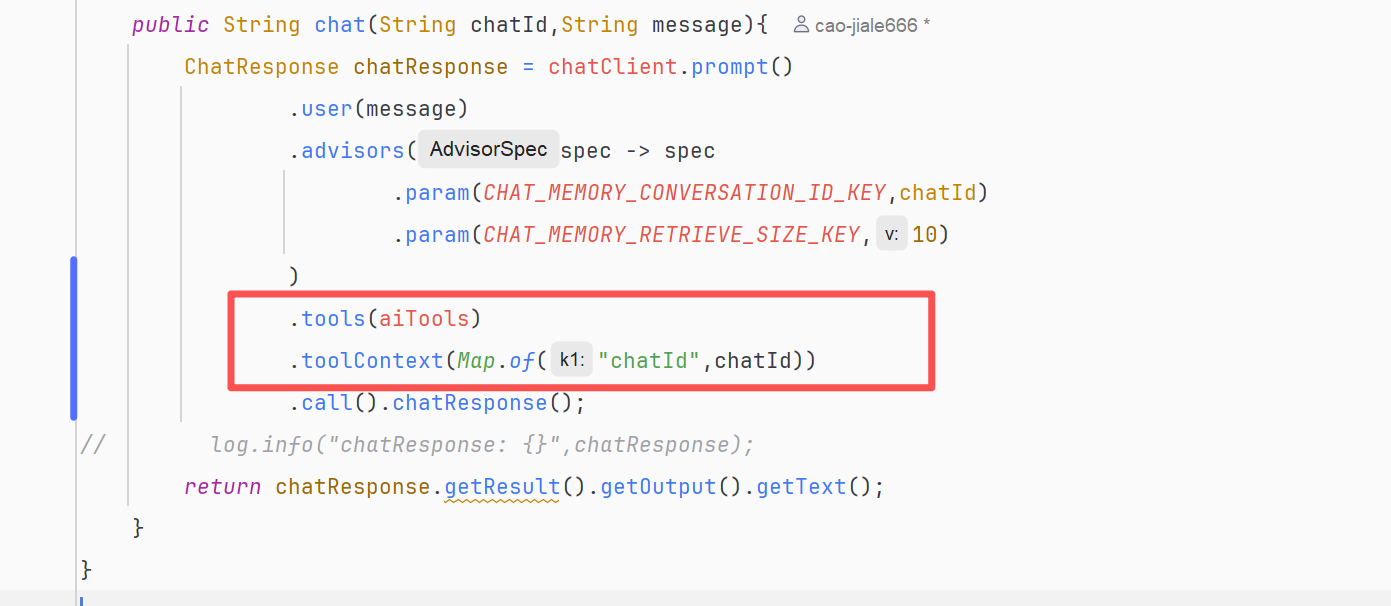
}修改TravelApp支持工具
测试使用
在测试类TravelAppTest中新增testTool:
java
@Test
void testTool(){
String chatId = UUID.randomUUID().toString();
String result = travelApp.chat(chatId,"我想去长沙玩3天,预算3000,帮我查询资料规划行程,并生成旅游计划PDF");
System.out.println(result);
}