文章目录
- 1.http
- 2.url
- 3.HTTP协议请求与响应格式
-
- [3.1 请求Request](#3.1 请求Request)
- [3.2 响应Response](#3.2 响应Response)
- [3.3 浏览器F12查看](#3.3 浏览器F12查看)
- 4.请求头常见方法
- 5.http常见状态码
- 6.http常见Header
- 7.http服务器代码示例
- 8.http发展历程
- 希望读者们多多三连支持
- 小编会继续更新
- 你们的鼓励就是我前进的动力!
1.http
🤔什么是http?
HTTP 是一个基于请求与响应模式的、应用层 的协议。
- 请求(
Request): 当你在浏览器输入网址时,你的电脑(客户端)向服务器发送一个请求 - 响应(
Response): 服务器接收请求后,返回网页内容、图片或其他数据给你的电脑
HTTP 的传输层依赖 TCP,但 HTTP 本身不是 TCP------HTTP 是应用层协议,TCP 是传输层协议,HTTP 是基于 TCP 实现的 "上层规则"
2.url

1. 协议方案名 (Scheme) :告诉浏览器使用什么协议来访问资源。这里使用的是 http,如果是加密链接则是 https
2. 登录信息/认证 (Login/Authentication) :这是一种旧式的在 URL 中直接包含用户名和密码的写法。现在的浏览器出于安全考虑,很少再这样直接显示或使用它了,但在某些特定脚本或内部系统中可能还会见到
3. 服务器地址 (Server Address) :这是网站的"门牌号",通常是域名(如 https://www.google.com/search?q=google.com)或者是 IP 地址。它告诉网络要把请求发给哪台计算机
4. 服务器端口号 (Port):如果服务器地址是"大楼",端口就是"具体的房门"
HTTP默认使用80端口HTTPS默认使用443端口- 如果使用默认端口,通常可以省略不写(例如我们平时访问网站都不输
:80)
5. 带层次的文件路径 (Hierarchical File Path) :这表示资源在服务器硬盘上的具体位置。就像你在电脑里打开 C盘 -> dir文件夹 -> index.htm文件 一样
6. 查询字符串 (Query String) :以 ? 开头。这是发给服务器的"额外参数"。
- 例如:你在淘宝搜索"手机",
URL里就会带有一个类似?q=手机的参数,告诉服务器你想搜什么
7. 片段标识符 (Fragment Identifier) :以 # 开头。这通常用于页面内部跳转(锚点)。
- 注意 :这部分不会 发送给服务器,只在浏览器端起作用。比如点击目录跳转到文章的"第一章",浏览器会自动滚动到
id="ch1"的位置
像 / ? 等这样的字符,已经被 url 当做特殊意义理解了,因此这些字符不能随意出现,比如,某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义
转义的规则如下:
将需要转码的字符转为 16 进制,然后从右到左,取 4 位(不足 4 位直接处理),每 2 位做一位,前面加上 %,编码成 %XY 格式
3.HTTP协议请求与响应格式
3.1 请求Request
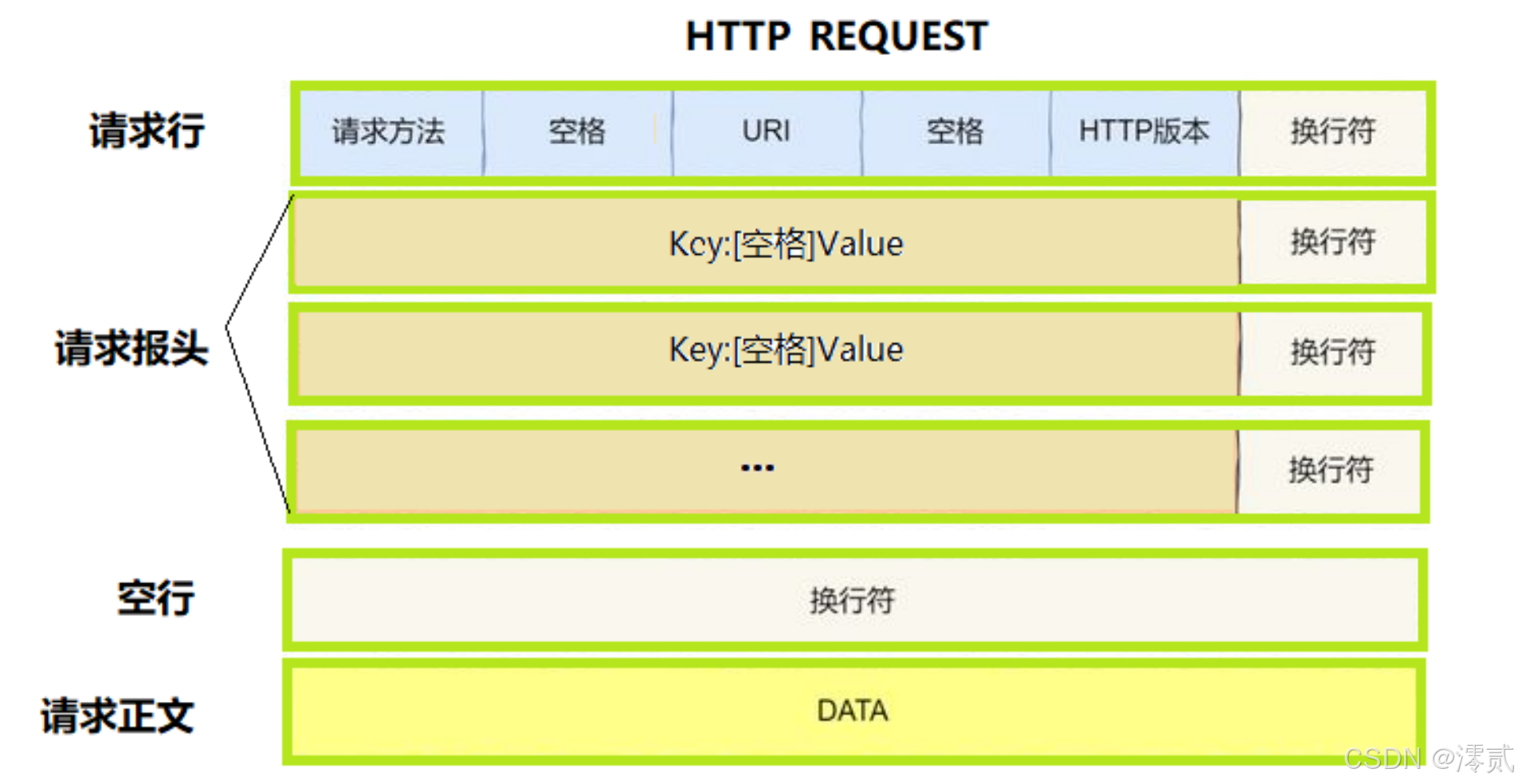
为了保证各个机器在互联网上互相访问时保持统一格式,定义了浏览器和服务器之间如何沟通,一个正确的请求格式通常包含这三部分:
-
请求行
- 包含请求方法 (
Method): 告诉服务器你想做什么。比如GET(我要看)、POST(我要存) URI: 告诉服务器你要"找什么"。比如 /index.htmlHTTP版本: 告诉服务器你"讲什么语言"。比如HTTP/1.1
- 包含请求方法 (
-
请求报头:
- 紧接着请求行,是一系列的键值对 (
Key:Value),每行一个属性,用冒号隔开
- 紧接着请求行,是一系列的键值对 (
-
请求正文:
- 这是实际要传输的内容,也就是你要传给服务器的实际数据
- 请求正文和请求报头之间隔着一行空行
cpp
POST /login HTTP/1.1 <-- 1. 请求行
Host: www.example.com <-- 2. 请求报头 (开始)
Content-Type: application/x-www-form-urlencoded
Content-Length: 27 <-- 2. 请求报头 (结束)
<-- 3. 空行 (必须有!)
username=tom&pwd=123456 <-- 4. 请求正文 (你的账号密码)请求通常是当我们输入网址之后,浏览器充当客户端会让正文附带上请求行、请求报头
3.2 响应Response

响应主要是返回浏览器请求的页面或文件,响应格式和请求格式差不多,也分为三个部分:
-
状态行:
HTTP版本- 状态码: 这是最核心的信息,用
3位数字表示结果。200:成功、404:没找到、500:服务器崩了 - 状态码描述: 状态码的简单文字解释,比如
OK或Not Found
-
响应报头:
- 服务器通过键值对信息告诉浏览器关于需要的网页的详细属性
-
响应正文:
- 如果你请求的是百度首页,这里就是很长的一段
HTML代码 - 如果你请求的是一张猫图,这里就是图片的二进制数据
- 如果你请求的是接口,这里可能是
JSON数据
- 如果你请求的是百度首页,这里就是很长的一段
cpp
HTTP/1.1 200 OK <-- 1. 状态行
Date: Sat, 17 Jan 2026 12:00:00 GMT <-- 2. 响应报头
Content-Type: text/html; charset=utf-8
Content-Length: 52
Server: Apache <-- 2. 响应报头 (结束)
<-- 3. 空行
<html><body><h1>Hello!</h1></body></html> <-- 4. 响应正文3.3 浏览器F12查看
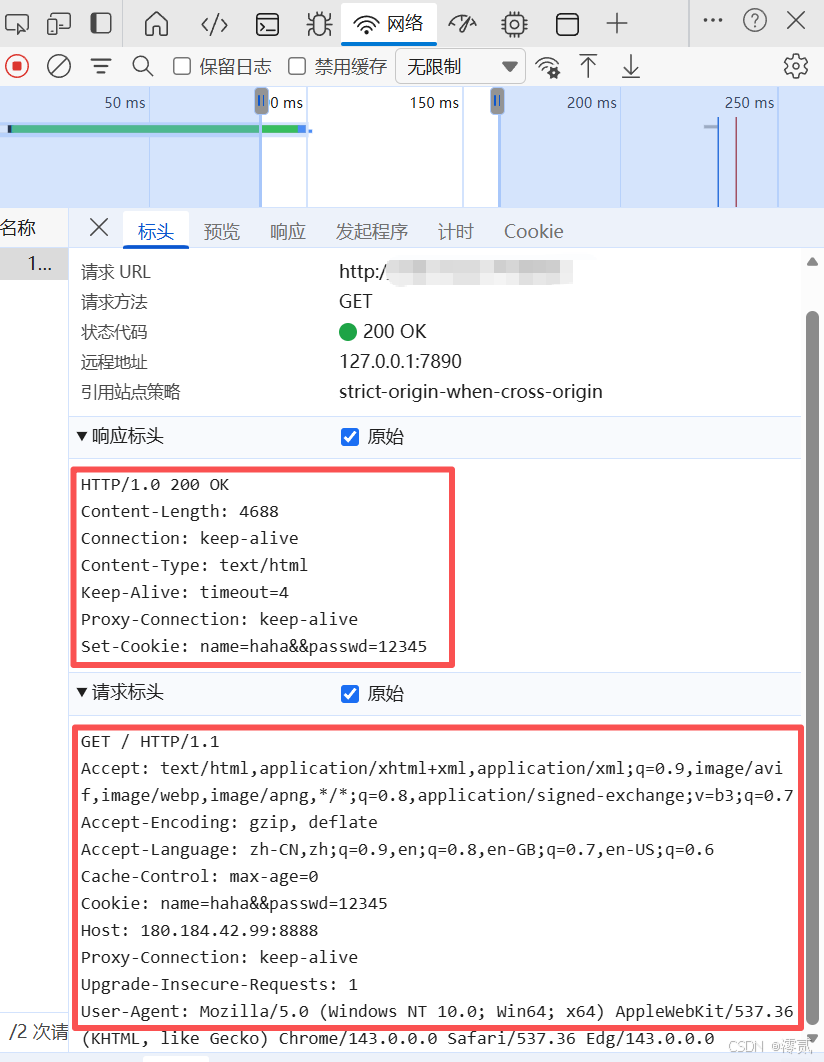
可以看到响应和请求是可以在 F12 工具的网络部分看到的
4.请求头常见方法
这几个 HTTP 方法(Verbs)是定义客户端(如浏览器)与服务器交互意图的核心
1. GET
请求指定的资源。它是最常用的方法,用于获取数据,不应产生副作用(即不修改服务器数据)
示例 :
浏览器访问网页,或调用 API 获取用户信息
http
GET /users/123 HTTP/1.1
Host: api.example.com特性:
- 安全性 (Safe):是。只读取数据,不改变服务器状态
- 幂等性 (Idempotent):是。无论请求多少次,结果资源应该是相同的
- 参数传递 :数据通常附加在
URL中,长度受限,且不适合传输敏感信息(如密码) - 缓存:默认可以被缓存
2. POST
向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。通常导致在服务器上新建一个从属资源
示例 :
用户注册、发表评论
http
POST /users HTTP/1.1
Host: api.example.com
Content-Type: application/json
{
"username": "zhangsan",
"email": "zhangsan@example.com"
}特性:
- 安全性:否。会修改服务器状态
- 幂等性 :否 。这是
POST与PUT的最大区别。如果你重复发送两次相同的POST请求,服务器可能会创建两个相同的资源(例如发了两条一样的帖子) - 参数传递:数据放在请求体中,理论上无大小限制
- 缓存:默认不缓存
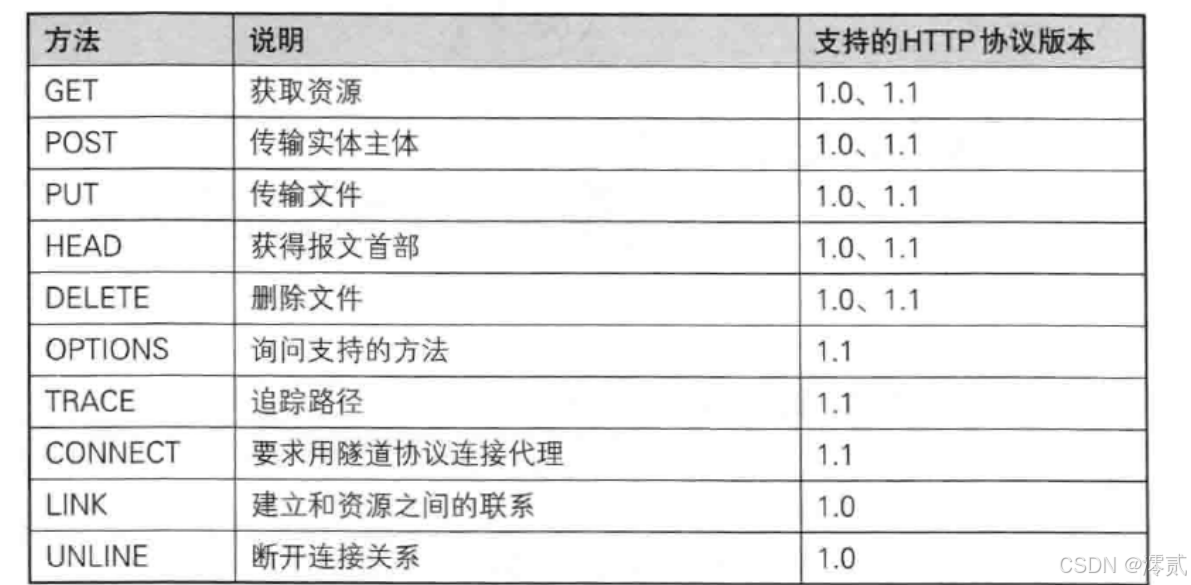
GET、POST 在这些方法里使用占比几乎为百分之八九十,其他选项用的很少,就不过多解释,可以自行百度了解
5.http常见状态码
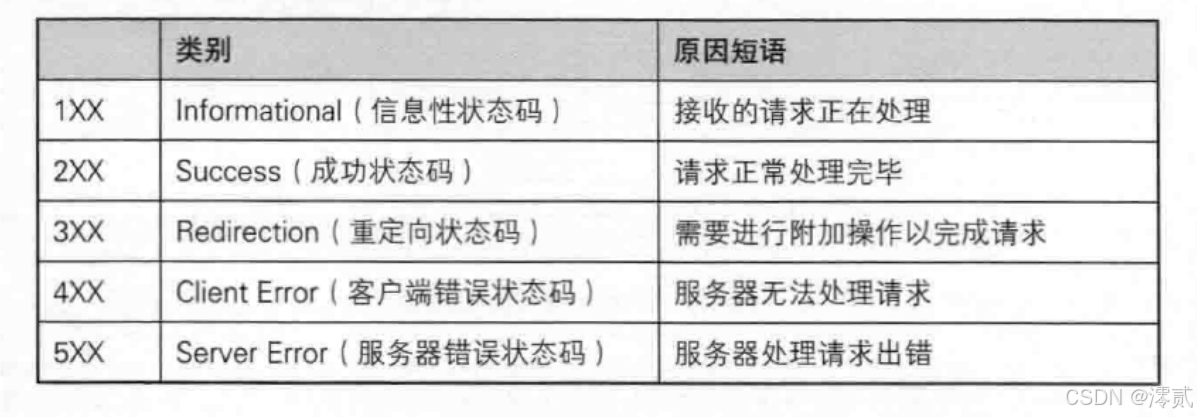
其中 301 状态码是永久重定向,表示请求的资源已经被永久移动到新的位置。302 是临时重定向,表示请求的资源临时被移动到新的位置,在这种情况下,服务器会在响应中添加一个 Location 头部,用于指定资源的新位置。这个 Location 头部包含了新的 URL 地址,浏览器会自动重定向到该地址
6.http常见Header
| 字段名 | 含义 | 样例 |
|---|---|---|
Accept |
客户端可接受的响应内容类型 | Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 |
Accept-Encoding |
客户端支持的数据压缩格式 | Accept-Encoding: gzip, deflate, br |
Accept-Language |
客户端可接受的语言类型 | Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 |
Host |
请求的主机名和端口号 | Host: www.example.com:8080 |
User-Agent |
客户端的软件环境信息 | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 |
Cookie |
客户端发送给服务器的 HTTP cookie 信息 |
Cookie: session_id=abcdefg12345; user_id=123 |
Referer |
请求的来源 URL |
Referer: http://www.example.com/previous_page.html |
Content-Type |
实体主体的媒体类型 | Content-Type: application/x-www-form-urlencoded(对于表单提交)或 Content-Type: application/json(对于 JSON 数据) |
Content-Length |
实体主体的字节大小 | Content-Length: 150 |
Authorization |
认证信息,如用户名和密码 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==(Base64 编码后的用户名:密码) |
Cache-Control |
缓存控制指令 | 请求时:Cache-Control: no-cache 或 Cache-Control: max-age=3600;响应时:Cache-Control: public, max-age=3600 |
Connection |
请求完后是关闭还是保持连接 | Connection: keep-alive 或 Connection: close |
Date |
请求或响应的日期和时间 | Date: Wed, 21 Oct 2023 07:28:00 GMT |
Location |
重定向的目标 URL(与 3xx 状态码配合使用) |
Location: http://www.example.com/new_location.html(与 302 状态码配合使用) |
Server |
服务器类型 | Server: Apache/2.4.41 (Unix) |
Last-Modified |
资源的最后修改时间 | Last-Modified: Wed, 21 Oct 2023 07:20:00 GMT |
ETag |
资源的唯一标识符,用于缓存 | ETag: "3f80f-1b6-5f4e2512a4100" |
Expires |
响应过期的日期和时间 | Expires: Wed, 21 Oct 2023 08:28:00 GMT |
🤔为什么我们每次登陆网站会自动识别身份呢?
浏览器第一次访问某服务器时,发送的
HTTP请求中没有Cookie字段,服务器处理请求后,在HTTP响应头中通过Set-Cookie字段(注意:不是Cookie,响应头用Set-Cookie),将Cookie数据发送给浏览器,浏览器接收到Set-Cookie响应头后,会按照规则将Cookie数据保存在本地,区分不同域名(避免跨域混淆,如baidu.com的Cookie不会被发送给google.com),浏览器后续再次向同一服务器(同一域名、同一路径)发送请求时,会自动在HTTP请求头的Cookie字段中,携带本地保存的该服务器Cookie数据,服务器接收到Cookie请求头后,解析其中的数据(如session_id),就能识别出该客户端的身份、之前的会话状态(如是否已登录),无需客户端重复提交身份信息
7.http服务器代码示例
这里做一个简单的 http 服务器,只展示核心代码,能够完整看到请求到响应的过程,具体代码可查看 Gitee:https://gitee.com/zhang-zhanhua-000/linux/tree/master/http
cpp
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
#include <fstream>
#include <vector>
#include <sstream>
#include <sys/types.h>
#include <sys/socket.h>
#include <unordered_map>
#include "Socket.hpp"
#include "log.hpp"
const std::string wwwroot="./wwwroot"; // web 根目录
const std::string sep = "\r\n";
const std::string homepage = "index.html";
static const int defaultport = 8082;
class HttpServer;
class ThreadData
{
public:
ThreadData(int fd, HttpServer *s) : sockfd(fd), svr(s)
{
}
public:
int sockfd;
HttpServer *svr;
};
class HttpRequest
{
public:
void Deserialize(std::string req)
{
while(true)
{
std::size_t pos = req.find(sep);
if(pos == std::string::npos) break;
std::string temp = req.substr(0, pos);
if(temp.empty()) break;
req_header.push_back(temp);
req.erase(0, pos+sep.size());
}
text = req;
}
// .png:image/png
void Parse()
{
std::stringstream ss(req_header[0]);
ss >> method >> url >> http_version;
file_path = wwwroot; // ./wwwroot
if(url == "/" || url == "/index.html") {
file_path += "/";
file_path += homepage; // ./wwwroot/index.html
}
else file_path += url; // /a/b/c/d.html->./wwwroot/a/b/c/d.html
auto pos = file_path.rfind(".");
if(pos == std::string::npos) suffix = ".html";
else suffix = file_path.substr(pos);
}
void DebugPrint()
{
for(auto &line : req_header)
{
std::cout << "--------------------------------" << std::endl;
std::cout << line << "\n\n";
}
std::cout << "method: " << method << std::endl;
std::cout << "url: " << url << std::endl;
std::cout << "http_version: " << http_version << std::endl;
std::cout << "file_path: " << file_path << std::endl;
std::cout << text << std::endl;
}
public:
std::vector<std::string> req_header;
std::string text;
// 解析之后的结果
std::string method;
std::string url;
std::string http_version;
std::string file_path; // ./wwwroot/a/b/c.html 2.png
std::string suffix;
};
class HttpServer
{
public:
HttpServer(uint16_t port = defaultport) : port_(port)
{
content_type.insert({".html", "text/html"});
content_type.insert({".png", "image/png"});
}
bool Start()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
for (;;)
{
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accept(&clientip, &clientport);
if (sockfd < 0)
continue;
logger(Info, "get a new connect, sockfd: %d", sockfd);
pthread_t tid;
ThreadData *td = new ThreadData(sockfd, this);
pthread_create(&tid, nullptr, ThreadRun, td);
}
}
static std::string ReadHtmlContent(const std::string &htmlpath)
{
// 坑
std::ifstream in(htmlpath, std::ios::binary);
if(!in.is_open()) return "";
in.seekg(0, std::ios_base::end);
auto len = in.tellg();
in.seekg(0, std::ios_base::beg);
std::string content;
content.resize(len);
in.read((char*)content.c_str(), content.size());
//std::string content;
//std::string line;
//while(std::getline(in, line))
//{
// content += line;
//}
in.close();
return content;
}
std::string SuffixToDesc(const std::string &suffix)
{
auto iter = content_type.find(suffix);
if(iter == content_type.end()) return content_type[".html"];
else return content_type[suffix];
}
void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0); // bug
if (n > 0)
{
buffer[n] = 0;
std::cout << buffer << std::endl; // 假设我们读取到的就是一个完整的,独立的 http 请求
HttpRequest req;
req.Deserialize(buffer);
req.Parse();
//req.DebugPrint();
//std::string path = wwwroot;
//path += url; // wwwroot/a/a/b/index.html
// 返回响应的过程
std::string text;
bool ok = true;
text = ReadHtmlContent(req.file_path); // 失败?
if(text.empty())
{
ok = false;
std::string err_html = wwwroot;
err_html += "/";
err_html += "err.html";
text = ReadHtmlContent(err_html);
}
std::string response_line;
if(ok)
response_line = "HTTP/1.0 200 OK\r\n";
else
response_line = "HTTP/1.0 404 Not Found\r\n";
//response_line = "HTTP/1.0 302 Found\r\n";
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size()); // Content-Length: 11
response_header += "\r\n";
response_header += "Content-Type: ";
response_header += SuffixToDesc(req.suffix);
response_header += "\r\n";
response_header += "Set-Cookie: name=haha&&passwd=12345";
response_header += "\r\n";
//response_header += "Location: https://www.qq.com\r\n";
std::string blank_line = "\r\n"; // \n
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
static void *ThreadRun(void *args)
{
pthread_detach(pthread_self());
ThreadData *td = static_cast<ThreadData *>(args);
td->svr->HandlerHttp(td->sockfd);
delete td;
return nullptr;
}
~HttpServer()
{
}
private:
Sock listensock_;
uint16_t port_;
std::unordered_map<std::string, std::string> content_type;
};首先创建指定端口的HttpServer服务器实例,随后调用该实例的Start()方法启动服务器,Start()方法内部会依次执行套接字创建(Socket())、端口绑定(Bind())、监听客户端连接(Listen())这三个步骤,完成服务器的初始化准备工作
初始化完成后,服务器会通过Accept()方法阻塞等待客户端的连接请求,当成功接收到客户端连接并获取到通信套接字后,会创建一个新的子线程(入口函数为ThreadRun)来处理该客户端的请求,避免阻塞主线程的连接监听
子线程的ThreadRun函数会调用服务器的HandlerHttp()核心业务方法,首先通过recv()函数接收客户端发送的原始 HTTP 请求数据,接着创建HttpRequest对象,先后调用其Deserialize()方法拆分 HTTP 请求头、Parse()方法从请求首行中提取URL并拼接出服务器本地对应的静态资源文件路径
之后调用ReadHtmlContent()方法根据拼接好的文件路径读取本地静态资源内容(若读取失败则读取404错误页面),再按照 HTTP 协议规范构造完整的 HTTP 响应(包含响应状态行、响应头、空行以及读取到的资源内容作为响应体),构造完成后通过 send() 方法将该 HTTP 响应发送给客户端
最后调用 close() 方法关闭与该客户端的通信套接字,释放连接资源,子线程完成所有处理工作后正常结束,而服务器主线程则始终在 Accept() 方法处循环等待下一个客户端的连接请求
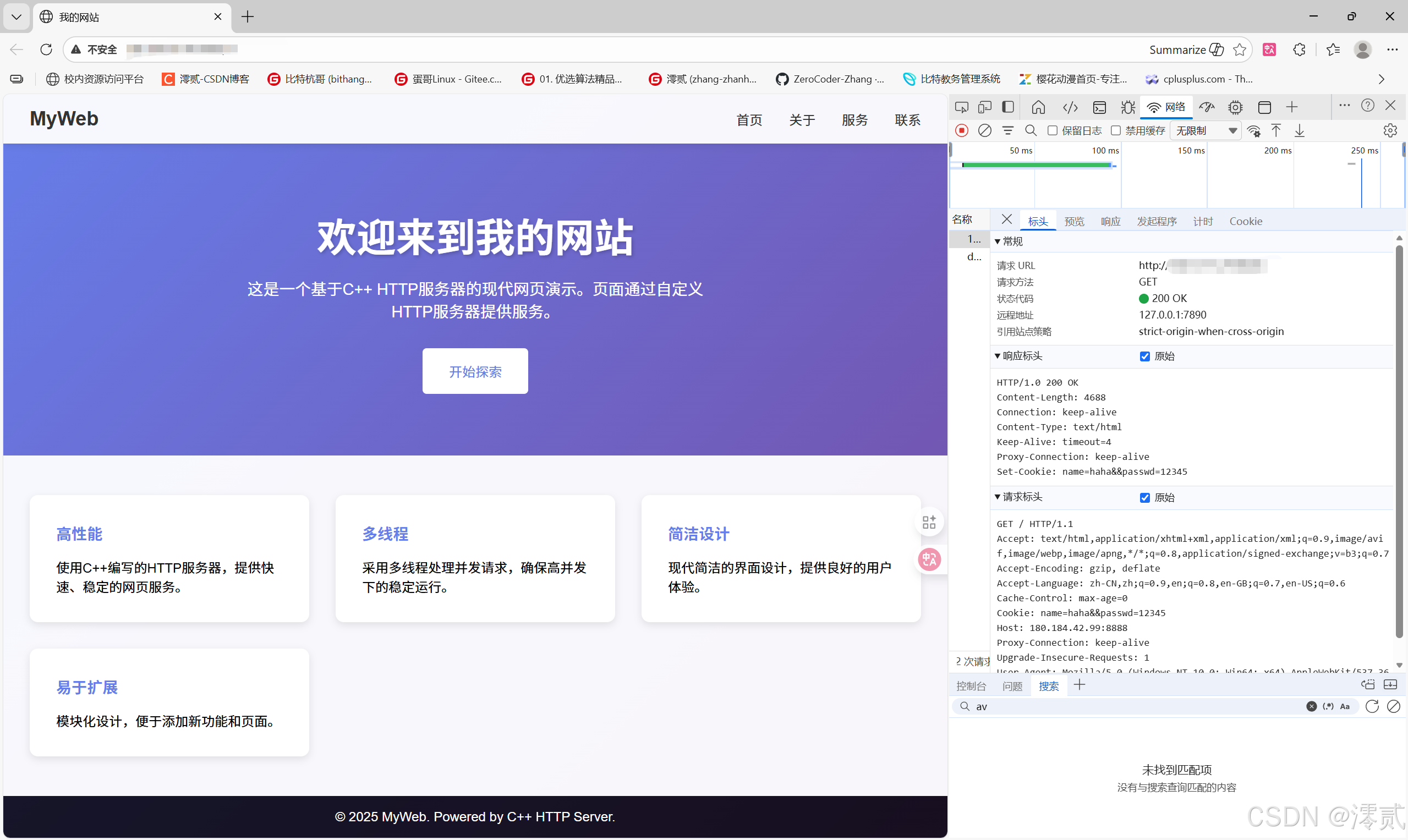
可以看到测试页面成功打开,请求响应也有对应报头显示
8.http发展历程
-
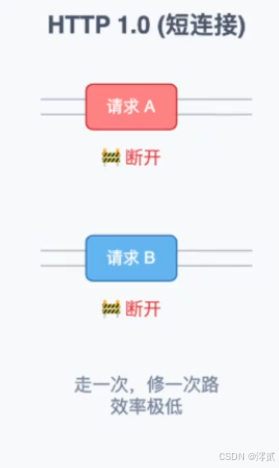
HTTP/1.0: 每发一个请求都要新建一次
TCP连接(三次握手),传输完立即断开。加载一个包含10张图片的网页,需要建立11次TCP连接,效率极低,这叫短连接
-
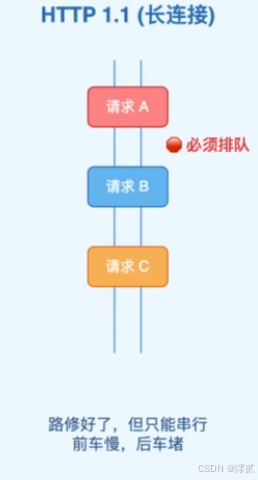
HTTP/1.1: 允许在一个
TCP连接上发送多个HTTP请求,不用频繁握手,连接复用了,但请求必须排队,这叫长连接 。如果第一个请求处理很慢(比如数据库查询慢),后面的所有请求(哪怕是张小图片)都得等着,导致页面加载卡顿,这叫串行独木桥 ,也叫队头阻塞
-
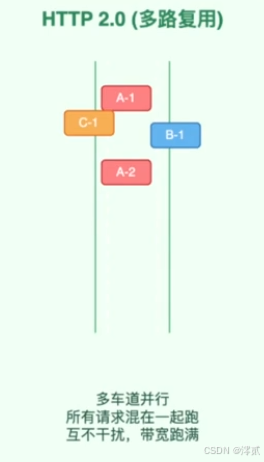
HTTP/2.0: 为了解决
HTTP/1.1的队头阻塞和性能瓶颈,推出了多路复用的方法,把请求拆成一个个带编号的二进制帧,这些帧可以交错并发的在同一个TCP里流动。但是如果TCP丢了一个包,操作系统会暂停后续所有包的传递等待重传,导致整个连接上的所有Stream都被阻塞,依然存在部分队头阻塞问题
- HTTP/3.0:
TCP有个固有原则,叫做按需到达,一旦网络抖动丢了一个包,那么就会一直阻塞在内核里,直到那个包重传回来。于是对UDP进行改进衍生出QUIC解决了该问题,受限于网络设备对UDP的限制,完全取代HTTP/2.0尚需时日
希望读者们多多三连支持
小编会继续更新
你们的鼓励就是我前进的动力!
