一、抢占机制核心概念与前置知识
在深入解析抢占原理前,需明确Kubernetes(以下简称K8S)中与抢占相关的核心概念,这是理解流程的基础:
1.1 核心角色定义
抢占者 (Preemptor):因资源不足无法调度的Pod,触发抢占逻辑以释放资源。
受害者 (Victim):被抢占机制选中、需被删除以释放资源的现有Pod。
调度器 (Scheduler):负责Pod调度的核心组件,内置`DefaultPreemption`插件实现抢占逻辑。
控制器 (Controller):如Deployment、StatefulSet、ReplicaSet等,负责维护Pod的期望副本数,在Pod被删除后会触发重建。
Pod优先级 (Pod Priority):通过`priorityClassName`关联的优先级值(0~1000000000),值越高优先级越高,低优先级Pod更易成为受害者。
抢占容忍度(Preemption Toleration):Pod通过`tolerations`字段声明是否容忍被抢占(对应`PreemptionVictim`污点),若不容忍则不会被选为受害者。
1.2 抢占的触发条件
K8S调度器在以下场景会触发抢占逻辑:
新Pod(抢占者)进入调度队列,经`Filter`阶段(如节点资源检查、亲和性匹配)后无满足条件的节点;
抢占者的优先级高于当前节点上的部分Pod;
抢占者的资源请求量可通过删除部分低优先级Pod得到满足。
1.3 K8S关于优先级的规定
优先级是 32 bit 的整数,最大值不能超过 1 000 000 000(10 亿)。值越大优先级越高。
系统Pod优先级 :超出 10 亿的值,是给"系统 Pod"使用的,保证系统 Pod 不被用户抢占掉。
0优先级 :如果 Pod 没有指定 priorityClassName,那么集群会把它的 priority 字段当成 0 处理(代码里 hard-code 为 0)。此时它处于"无优先级"状态,调度器把它当成最低优先级对待。
PriorityClass设置优先级 :如果 Pod 显式引用了某个 PriorityClass,那就使用那个 PriorityClass 里定义的 value 值(可以是正数,也可以是负数,甚至可以是 10⁹ 级别的超大值)。
如果集群里启用了 PodPriority 特性门控(1.14+ 默认开启),但给 Pod 指定了一个不存在的 PriorityClass,该 Pod 会被拒绝创建(APIServer 直接返回 422)。
Controller 维护着调度队列,高优先级 Pod 可以出队优先调度
二 在K8S集群中建立有优先级的pod
(1)在集群中声明一个PriorityClass
bash
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods only."(2)创建了 PriorityClass 对象之后,Pod 就可以声明使用它了
bash
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority当这个 Pod 被提交给 Kubernetes 之后,PriorityAdmissionController 就会自动将这个 Pod 的 spec.priority 字段设置为 1000000。
Controller 维护着调度队列,高优先级 Pod 可以出队优先调度。
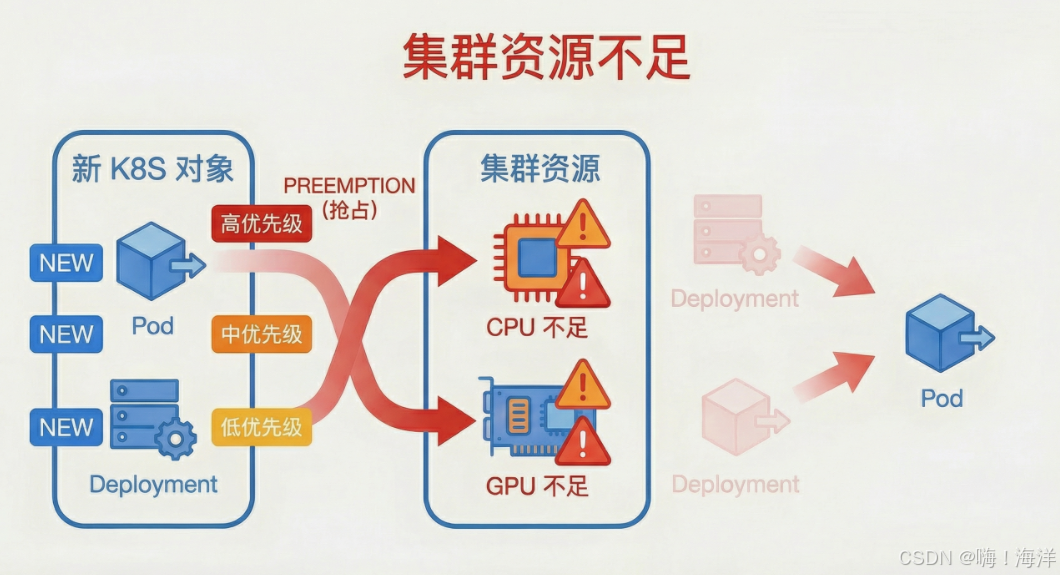
三、Kubernetes控制器抢占机制整体架构
调度器核心组件职责划分
调度器队列 :分为`activeQ`(待调度Pod队列)和`backoffQ`(调度失败重试Pod队列),抢占者通常来自`activeQ`。
Filter阶段:调度器先尝试为抢占者寻找"直接可用"节点(无需抢占),仅当失败后才进入抢占流程。
DefaultPreemption插件:调度器的核心插件,负责:
(1)识别可抢占的节点(节点上存在低优先级Pod);
(2)选择最优的受害者组合;
(3)执行受害者删除与抢占者绑定。
控制器:受害者Pod被删除后,其对应的控制器(如ReplicaSet)会检测到副本数不足,立即创建新的Pod副本(重建的Pod会重新进入调度队列)。
四、抢占机制详细流程
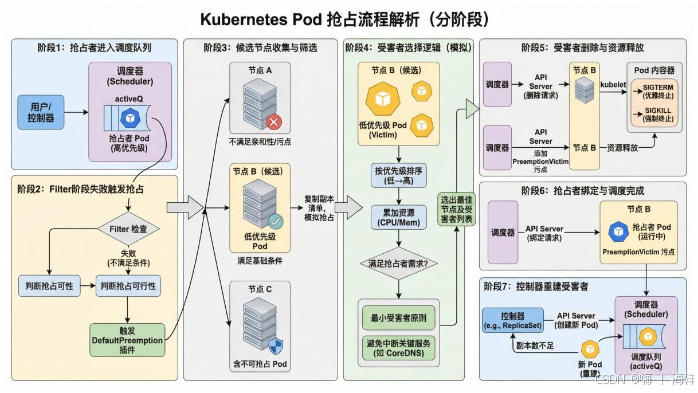
4.1 分阶段流程解析
判断是否抢占:
阶段1 :抢占者进入调度队列
用户或控制器创建高优先级Pod(抢占者),该Pod进入调度器的`activeQ`队列等待调度。
阶段2:Filter阶段失败触发抢占
调度器对抢占者执行`Filter`阶段(检查节点资源、亲和性、污点容忍等),若所有节点均不满足条件,调度器会检查此次失败时间的原因。判断抢占是否可以解决问题。(存在一系列的算法检查)
确认抢占可以发生,则触发`DefaultPreemption`插件。
选择出执行抢占的节点:
阶段3:候选节点收集与筛选
(3.1)调度器遍历所有节点,筛选出"可通过抢占释放资源"的候选节点,筛选条件包括:
(3.2)节点上存在低优先级Pod(优先级低于抢占者);
(3.3)抢占者满足节点的亲和性、污点容忍等基础条件(排除因非资源因素无法调度的节点);
节点上的Pod无"禁止被抢占"的容忍度(即未容忍`PreemptionVictim`污点)。
(3.4)候选节点选择后,调度器会复制一份副本清单。使用这个副本模拟抢占流程。
阶段4:受害者选择逻辑
调度器遍历每个节点模拟执行以下步骤选择受害者:
优先级排序:将节点上的Pod按优先级从低到高排序;
资源计算:累加低优先级Pod的资源(CPU、内存、GPU等),直到释放的资源满足抢占者的请求;
遍历完成后,调度器在所有抢占结果中找出最佳结果:判断原则如下:
最小受害者原则:优先选择删除最少数量的Pod,以减少对集群的影响;
避免中断关键服务:排除`CriticalAddonsOnly`优先级的Pod(如CoreDNS),避免影响集群基础功能。
此时最适合做抢占的node已经选出
开始抢占:
阶段5:受害者删除与资源释放
(1)调度器会检查牺牲者列表,清理这些 Pod 所携带的 nominatedNodeName 字段。
(2)调度器会把抢占者的 nominatedNodeName,设置为被抢占的 Node 的名字。
(3)调度器会开启一个 Goroutine,同步地删除牺牲者。
调度器向API Server发送删除受害者Pod的请求,同时为目标节点添加`PreemptionVictim`污点(防止其他Pod在资源释放前调度到该节点)。受害者Pod的删除流程如下:
API Server标记受害者Pod为`Terminating`状态;
kubelet收到删除请求后,向Pod内的容器发送`SIGTERM`信号(默认等待30s优雅终止);
若优雅终止超时,kubelet发送`SIGKILL`信号强制终止容器;
容器终止后,kubelet释放节点上的对应资源。
抢占完成:
阶段6:抢占者绑定与调度完成
调度器等待目标节点资源释放后,将抢占者Pod绑定到该节点,并移除节点上的`PreemptionVictim`污点。抢占者Pod随后被kubelet创建并运行。
灾后重建:
阶段7:控制器重建受害者
受害者Pod被删除后,其对应的控制器(如Deployment的ReplicaSet)检测到当前副本数低于期望副本数,立即触发重建逻辑:
控制器向API Server发送创建新Pod的请求(新Pod的优先级与原受害者一致);
新Pod进入调度队列,等待调度器为其寻找新的节点(可能再次触发抢占,或调度到其他有资源的节点)。
五、控制器在抢的核心作用
控制器是抢占机制中"受害者重建"的关键角色,不同类型的控制器在重建逻辑上存在差异,以下以常见控制器为例解析:
3.1 Deployment控制器的交互流程
Deployment通过ReplicaSet管理Pod,其与抢占机制的交互流程如下:
调度器->>API Server: 删除受害者Pod(属于ReplicaSet A)
API Server->>ReplicaSet控制器: 通知Pod删除事件
ReplicaSet控制器->>API Server: 检测到ReplicaSet A副本数不足(期望3,当前2)
ReplicaSet控制器->>API Server: 创建新Pod(受害者重建)
API Server->>调度器: 新Pod进入调度队列
调度器->>目标节点: 尝试调度新Pod(若资源不足可能触发新抢占)
Deployment的重建特点:
基于ReplicaSet的声明式管理,重建速度快;
新Pod的模板与原受害者一致(优先级、资源请求等);
支持滚动更新,但抢占导致的重建不影响滚动更新策略。
3.2 StatefulSet控制器的交互流程
StatefulSet管理有状态Pod,其重建逻辑需保证Pod的顺序性和唯一性,交互流程如下:
调度器->>API Server: 删除受害者Pod(web-0,属于StatefulSet web)
API Server->>StatefulSet控制器: 通知Pod删除事件
StatefulSet控制器->>API Server: 检测到web-0缺失(StatefulSet要求有序重建)
StatefulSet控制器->>API Server: 创建新Pod web-0(保持原名称、网络标识)
API Server->>调度器: web-0进入调度队列
调度器->>目标节点: 调度web-0(优先调度到原节点,若不可用则选择其他节点)
```
StatefulSet的重建特点:
按Pod名称顺序重建(如web-0删除后先重建web-0,再处理web-1);
保留Pod的稳定网络标识(如DNS名称`web-0.web.service.default.svc.cluster.local`);
若使用PersistentVolumeClaim(PVC),则新Pod会重新挂载原PVC,保留数据。
3.3 DaemonSet控制器的交互流程
DaemonSet确保每个节点(或匹配节点)运行一个Pod,其与抢占机制的交互流程如下:
调度器->>API Server: 删除节点A上的DaemonSet Pod(受害者)
API Server->>DaemonSet控制器: 通知节点A Pod删除事件
DaemonSet控制器->>API Server: 检测到节点A缺失DaemonSet Pod
DaemonSet控制器->>API Server: 在节点A上创建新的DaemonSet Pod
API Server->>调度器: 新Pod进入调度队列
调度器->>节点A: 调度新Pod到节点A(DaemonSet要求节点唯一性)
```
DaemonSet的重建特点:
仅在原节点重建(除非节点不可用);
若节点资源不足,新Pod可能再次成为受害者;
通常用于运行日志收集、监控等节点级服务,抢占需避免频繁中断。
六、抢占机制的约束与优化
4.1 关键约束
优先级反转:若低优先级Pod绑定了不可抢占的资源(如独占GPU),高优先级Pod可能无法抢占,需通过资源配额避免;
重建延迟:受害者重建需时间,若控制器重建速度慢,可能导致服务中断;
集群稳定性:频繁抢占会导致Pod频繁重建,影响集群性能,需合理设置Pod优先级。
4.2 优化建议
合理设置优先级:避免过度使用高优先级,将核心服务(如数据库、API网关)设为高优先级,非核心服务设为低优先级;
配置抢占容忍度:对关键Pod设置`PreemptionVictim`污点容忍度(`tolerations: {key: "PreemptionVictim", operator: "Exists", effect: "NoExecute"}`),防止被抢占;
调整控制器重建参数:如Deployment的`progressDeadlineSeconds`(设置重建超时时间)、StatefulSet的`podManagementPolicy`(调整重建顺序);
使用节点亲和性:为高优先级Pod设置节点亲和性,引导其调度到特定节点,减少抢占频率;
监控抢占事件:通过Prometheus监控`scheduler_pod_preemption_victims`(受害者数量)、`scheduler_pod_preemption_attempts`(抢占尝试次数)等指标,及时发现资源瓶颈。
七、典型场景示例
7.1高优先级Deployment抢占低优先级Deployment场景
场景描述:集群有1个节点,资源为2核CPU、4GB内存;
低优先级Deployment(`priority: 100`)运行2个Pod,每个请求1核CPU、2GB内存;
高优先级Deployment(`priority: 1000`)创建1个Pod,请求1核CPU、2GB内存(此时节点资源不足)。
抢占流程:高优先级Pod进入调度队列,Filter阶段失败触发抢占;
调度器选择低优先级Deployment的1个Pod作为受害者;
删除受害者Pod,释放1核CPU、2GB内存;
高优先级Pod绑定到该节点;
低优先级Deployment的ReplicaSet检测到副本数不足,重建1个新Pod;
新Pod进入调度队列,因节点资源不足(剩余1核CPU、2GB内存被高优先级Pod占用),需等待其他节点释放资源或触发新抢占。
7.2 StatefulSet Pod被抢占后的重建场景
场景描述:StatefulSet `web`管理3个有状态Pod(`web-0`、`web-1`、`web-2`),每个请求1核CPU、1GB内存;
节点资源为2核CPU、3GB内存,`web-0`和`web-1`运行在该节点;
高优先级Pod(`priority: 2000`)请求1核CPU、1GB内存,触发抢占。
抢占流程:高优先级Pod Filter阶段失败,选择`web-2`(若`web-2`在其他节点则选择`web-1`)作为受害者;
删除`web-2`,释放1核CPU、1GB内存;
高优先级Pod绑定到节点;
StatefulSet控制器检测到`web-2`缺失,按顺序重建`web-2`;
`web-2`进入调度队列,因节点资源不足,调度器为其寻找其他节点(若存在)或等待资源释放。
八、总结
Kubernetes控制器抢占机制是解决资源瓶颈的关键手段,其核心逻辑由调度器的`DefaultPreemption`插件实现,通过选择低优先级受害者Pod释放资源,再由控制器重建受害者以保证服务可用性。理解抢占的流程、控制器的交互逻辑及优化策略,有助于构建稳定、高效的K8S集群,避免因资源不足导致的服务中断。
在实际集群管理中,需结合业务场景合理配置Pod优先级、抢占容忍度及控制器参数,同时通过监控及时发现抢占事件,优化资源分配,平衡集群稳定性与资源利用率。