
Langchain_v1.0|middleware中间件
[@Overview 概述](#@Overview 概述)
- [@The agent loop 代理循环](#@The agent loop 代理循环)
- [@Additional resources 其他资源](#@Additional resources 其他资源)
[@Built-in middleware 内置中间件](#@Built-in middleware 内置中间件)
[@内置中间件(Built-in Middleware)](#@内置中间件(Built-in Middleware))
[@通用中间件(Provider-Agnostic Middleware)](#@通用中间件(Provider-Agnostic Middleware))
[@Custom middleware 自定义中间件](#@Custom middleware 自定义中间件)
[@Hooks 钩子](#@Hooks 钩子)
- [@节点式钩子(Node-style hooks)](#@节点式钩子(Node-style hooks))
- [@Wrap-style hooks 包式挂钩](#@Wrap-style hooks 包式挂钩)
[@Create middleware 创建中间件](#@Create middleware 创建中间件)
- [@基于装饰器的中间件 Decorator-based middleware](#@基于装饰器的中间件 Decorator-based middleware)
- [@基于类的中间件 Class-based middleware](#@基于类的中间件 Class-based middleware)
[@自定义状态 Schema(Custom State Schema)](#@自定义状态 Schema(Custom State Schema))
[@Execution order 执行顺序](#@Execution order 执行顺序)
- [@智能体跳转(Agent Jumps)](#@智能体跳转(Agent Jumps))
[@Best practices 最佳实践](#@Best practices 最佳实践)
[@Examples 示例](#@Examples 示例)
- [@Dynamic model selection 动态模型选择](#@Dynamic model selection 动态模型选择)
- [@Tool call monitoring 工具调用监控](#@Tool call monitoring 工具调用监控)
- [@Dynamically selecting tools 动态选择工具](#@Dynamically selecting tools 动态选择工具)
中间件
Overview 概述
控制和自定义智能体的执行的每个步骤
中间件提供了一种方法,可以更严格地控制智能体内部发生的事情。中间件对于以下情况非常有用:
- 跟踪智能体的行为(日志记录、分析、调试)。
- 转换提示、工具选择和输出格式。
- 添加重试、回退和早期终止逻辑。
- 应用速率限制、护栏和 PII 检测。
通过将中间件传递给 create_agent 来添加中间件:
python
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware, HumanInTheLoopMiddleware
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
SummarizationMiddleware(...),
HumanInTheLoopMiddleware(...)
],
)The agent loop 代理循环
核心代理循环涉及调用模型,让模型选择要执行的工具,然后在调用不再有工具时完成:
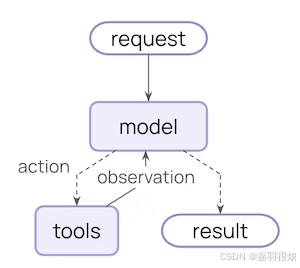
中间件在每个步骤之前和之后都提供钩子:
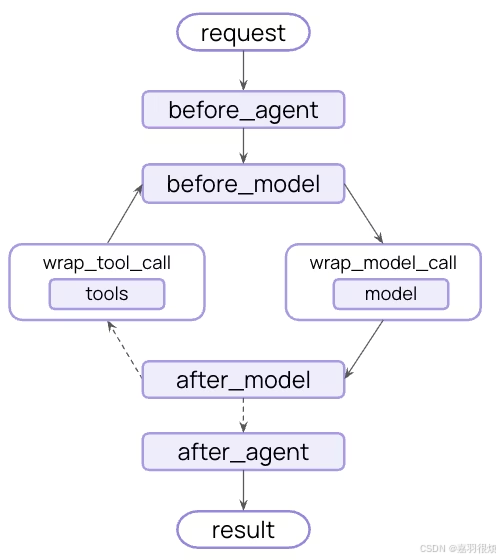
Additional resources 其他资源
- Built-in middleware 内置中间件
- Custom middleware 自定义中间件
- Middleware reference 中间件参考
- Middleware testing 中间件测试
Built-in middleware 内置中间件
用于常见代理用例的预构建中间件
LangChain 提供了用于常见用例的预构建中间件。每个中间件都已准备好生产,可以根据您的特定需求进行配置。
无提供商的中间件
The following middleware work with any LLM provider:
以下中间件与任何 LLM 提供商配合工作:
以下是 LangGraph 中间件(Middleware)及其功能的清晰表格整理:
| 中间件(Middleware) | 描述(Description) |
|---|---|
| Summarization(摘要) | 当接近令牌限制时,自动总结对话历史记录,以节省上下文长度。 |
| Human-in-the-loop(人机交互) | 暂停执行流程,等待人工批准工具调用(例如敏感操作)。 |
| Model call limit(模型调用限制) | 限制模型调用的最大次数,防止产生过高成本或无限循环。 |
| Tool call limit(工具调用限制) | 通过设置调用次数上限,控制特定工具的执行频率。 |
| Model fallback(模型回退) | 当主模型调用失败时,自动切换到预设的备用模型继续执行。 |
| PII detection(PII 检测) | 自动检测对话中的个人身份信息(如姓名、电话、身份证号),并进行脱敏或拦截处理。 |
| To-do list(待办事项) | 为智能体赋予任务规划与进度跟踪能力,支持分解和管理多步骤目标。 |
| LLM tool selector(LLM 工具选择器) | 在调用主模型前,先用一个轻量级 LLM 选择最相关的工具,提升效率与准确性。 |
| Tool retry(工具重试) | 对失败的工具调用自动重试,采用指数退避策略(如 1s、2s、4s...)提高成功率。 |
| Model retry(模型重试) | 对失败的模型调用自动重试,同样使用指数退避机制增强鲁棒性。 |
| LLM tool emulator(LLM 工具模拟器) | 使用 LLM 模拟工具的输出,用于开发和测试阶段,无需真实调用外部服务。 |
| Context editing(上下文编辑) | 动态管理对话上下文,例如修剪过期工具调用记录或清除冗余信息,优化 token 使用。 |
| Shell tool(壳工具) | 向代理提供一个持久化的 shell 会话,允许其执行系统命令(需谨慎授权)。 |
| File search(文件搜索) | 提供基于文件系统的搜索能力,支持 Glob 模式匹配和 Grep 正则搜索,便于访问本地文件内容。 |
💡 使用建议:
- 生产环境中建议启用 PII detection 和 Model/Tool call limits 以保障安全与成本可控。
- 开发调试时可结合 LLM tool emulator 快速验证逻辑,避免依赖真实 API。
- 长对话场景推荐使用 Summarization + Context editing 组合维持上下文有效性。
以下是根据 LangChain 官方文档 - Built-in Middleware 提取并整理的 Markdown 格式内容,重点以表格形式清晰呈现所有内置中间件的功能、适用场景及关键配置。
内置中间件(Built-in Middleware)
LangChain 提供了一系列开箱即用、生产就绪的中间件,用于处理智能体开发中的常见需求。这些中间件分为 通用型(Provider-agnostic) 和 特定于 LLM 提供商(Provider-specific) 两类。
通用中间件(Provider-Agnostic Middleware)
以下中间件适用于任何 LLM 提供商(如 OpenAI、Anthropic、Ollama 等)。
| 中间件名称 | 描述 | 典型应用场景 | 关键配置参数示例 |
|---|---|---|---|
| Summarization(对话摘要) | 当对话接近模型上下文长度限制时,自动压缩历史消息为摘要,保留最新消息。 | 长时间对话、多轮交互、上下文窗口受限的应用 | model="gpt-4o-mini"``trigger={"tokens": 4000}``keep={"messages": 20} |
| Human-in-the-loop(人工介入) | 在执行高风险工具前暂停流程,等待人工批准、编辑或拒绝。 | 金融交易、数据库写入、邮件发送等需人工审核的操作 | interrupt_on={"send_email": {"allowed_decisions": ["approve", "edit", "reject"]}}⚠️ 需配合 checkpointer 使用 |
| Model Call Limit(模型调用限制) | 限制单次运行或整个线程中模型调用的最大次数。 | 防止无限循环、控制 API 成本、测试预算约束 | thread_limit=10``run_limit=5``exit_behavior="end" |
| Tool Call Limit(工具调用限制) | 限制全局或特定工具的调用次数(支持 per-thread / per-run)。 | 限制昂贵 API 调用(如搜索、爬虫)、防止滥用 | tool_name="search"``thread_limit=5``run_limit=3``exit_behavior="error" |
| Model Fallback(模型回退) | 主模型失败时,自动切换到备用模型(可链式配置多个)。 | 提高系统容错性、实现成本优化(主贵备廉)、多提供商冗余 | ModelFallbackMiddleware("gpt-4o-mini", "claude-3-haiku") |
| PII Detection(个人身份信息检测) | 检测输入/输出中的 PII(如邮箱、信用卡号),并执行脱敏、屏蔽或阻断。 | 医疗、金融、客服等合规敏感场景 | PIIMiddleware("email", strategy="redact")``PIIMiddleware("ssn", detector=my_ssn_validator, strategy="hash") |
| To-do List(待办事项) | 自动为智能体注入任务规划能力,提供 write_todos 工具和系统提示。 |
复杂多步骤任务(如代码生成、报告撰写) | 无必需参数,可选 system_prompt、tool_description |
| LLM Tool Selector(LLM 工具选择器) | 使用轻量级 LLM 在主模型调用前筛选出最相关的工具子集。 | 智能体拥有大量工具(>10 个)但每次只需少数几个 | model="gpt-4o-mini"``max_tools=3``always_include=["search"] |
| Tool Retry(工具重试) | 对失败的工具调用自动重试,支持指数退避、异常过滤和失败处理策略。 | 应对外部服务临时故障(网络超时、限流等) | max_retries=3``retry_on=(ConnectionError, TimeoutError)``on_failure="return_message" |
| Model Retry(模型重试) | 对失败的模型调用自动重试,机制与 Tool Retry 类似。 | 提高 LLM 调用鲁棒性(尤其在高负载或不稳定网络下) | 同 ToolRetryMiddleware 参数 |
| LLM Tool Emulator(LLM 工具模拟器) | 使用 LLM 模拟真实工具的输出,不实际执行工具逻辑。 | 开发测试、原型验证、避免调用真实服务产生费用 | tools=["get_weather"]``model="claude-3-haiku" |
| Context Editing(上下文编辑) | 动态清理旧的工具调用结果,仅保留最近 N 条,减少 token 占用。 | 长对话中频繁使用工具导致上下文膨胀 | ClearToolUsesEdit(trigger=2000, keep=3) |
| Shell Tool(Shell 工具) | 为智能体提供持久化 Shell 会话,可执行系统命令。 | 自动化脚本、文件操作、环境部署(⚠️ 高风险!) | workspace_root="/workspace"``execution_policy=DockerExecutionPolicy(...) |
| File Search(文件搜索) | 注入 glob_search 和 grep_search 工具,支持在指定目录中搜索文件。 |
代码库分析、日志检索、大型项目导航 | root_path="/project"``use_ripgrep=True |
python
## 使用示例
from langchain.agents import create_agent
from langchain.agents.middleware import (
SummarizationMiddleware,
HumanInTheLoopMiddleware,
ToolCallLimitMiddleware,
PIIMiddleware
)
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model="gpt-4o",
tools=[send_email, search_web, query_db],
checkpointer=InMemorySaver(), # Human-in-the-loop 必需
middleware=[
# 自动摘要长对话
SummarizationMiddleware(
model="gpt-4o-mini",
trigger={"tokens": 6000},
keep={"messages": 10}
),
# 邮件发送需人工批准
HumanInTheLoopMiddleware(
interrupt_on={"send_email": {"allowed_decisions": ["approve", "reject"]}}
),
# 限制搜索工具调用
ToolCallLimitMiddleware(tool_name="search_web", run_limit=2),
# 脱敏用户输入中的邮箱
PIIMiddleware("email", strategy="redact", apply_to_input=True),
]
)最佳实践建议
- 安全优先 :在生产环境中务必启用
PII Detection和Tool Call Limit。 - 成本控制 :结合
Model Call Limit+Model Fallback(主模型贵,备模型便宜)。 - 长对话优化 :
Summarization+Context Editing组合可有效管理上下文长度。 - 高风险操作 :涉及数据修改或外部系统调用时,强制使用
Human-in-the-loop。 - 开发效率 :使用
LLM Tool Emulator快速迭代逻辑,无需依赖真实 API。
ℹ️ 所有中间件均支持通过
create_agent(..., middleware=[...])注册,且可组合使用。更多细节请参考 LangChain Middleware API 文档。
Custom middleware 自定义中间件
Hooks 钩子
通过实现钩子(hooks),在智能体执行流程的特定阶段注入自定义逻辑,构建灵活、可复用的中间件。
中间件提供两种方式来拦截代理执行:
- Node-style hooks 节点式钩子 : 在特定执行点顺序运行。用于日志记录、验证和状态更新。
- Wrap-style hooks 包式挂钩
节点式钩子(Node-style hooks)
在特定执行点顺序运行,适用于日志记录、验证、状态更新等场景。
可用钩子:
- before_agent:智能体启动前(每次调用执行一次)
- before_model:每次模型调用前(每次调用执行一次)
- after_model:每次模型响应后(每次调用执行一次)
- after_agent:智能体完成时(每次调用执行一次)
python
from langchain.agents import AgentState,create_agent
from langchain.agents.middleware import ModelRequest,ModelResponse,after_model,before_agent,after_agent,before_model,after_model,before_model
from langchain.messages import AIMessage
from typing import TypedDict,Any
from langgraph.runtime import Runtime
from langgraph.checkpoint.memory import InMemorySaver
@before_model(can_jump_to="end")
def check_message_limit(state:AgentState,runtime:Runtime) -> dict[str,Any] |None:
messages = state["messages"]
if len(messages) >2:
return {
"messages": [AIMessage(content="Message limit exceeded")],
"jump_to": "end",
}
return None
@after_model(can_jump_to="end")
def log_response(state:AgentState,runtime:Runtime) -> dict[str,Any] |None:
print(f"Model return : {state['messages'][-1].content}")
return None
from langchain_01.models.scii_deepseekv3 import model
agent = create_agent(
model,
tools=[],
middleware=[check_message_limit,log_response],
checkpointer=InMemorySaver(),
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "Hi! My name is Bob."}]},
{"configurable": {"thread_id": "1"}},
)
print(result["messages"][-1].content)
print("----")
result = agent.invoke(
{"messages": [{"role": "user", "content": "What is my name?"}]},
{"configurable": {"thread_id": "1"}},
)
print(result["messages"][-1].content)Model return : Hi Bob! Nice to meet you! How can I help you today?
Hi Bob! Nice to meet you! How can I help you today?
----
Message limit exceeded
python
# 使用class 定义middleware
from langchain.agents.middleware import AgentMiddleware,hook_config,AgentState
class MessageLimitMiddleware(AgentMiddleware):
def __init__(self,max_messages = 2 ):
super().__init__()
self.max_messages = max_messages
@hook_config(can_jump_to=["end"])
def before_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
if len(state["messages"]) > self.max_messages:
return {
"messages":[AIMessage(content=f"你已经超过了最大消息数 {self.max_messages}")],
"jump_to":"end"
}
return None
def after_model(self, state: AgentState, runtime: Runtime) -> None:
print(f"Log Model Response : {state['messages'][-1].content}")
agent = create_agent(
model,
tools=[],
checkpointer=InMemorySaver(),
middleware=[MessageLimitMiddleware(max_messages=2)]
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "Hi! My name is Bob."}]},
{"configurable": {"thread_id": "1"}},
)
print(result["messages"][-1].content)
print("----")
result = agent.invoke(
{"messages": [{"role": "user", "content": "What is my name?"}]},
{"configurable": {"thread_id": "1"}},
)
print(result["messages"][-1].content)Log Model Response : Hi Bob! Nice to meet you! How can I help you today?
Hi Bob! Nice to meet you! How can I help you today?
----
你已经超过了最大消息数 2Wrap-style hooks 包式挂钩
环绕每个模型或工具调用执行,可控制是否/何时调用处理器(handler),适用于重试、缓存、转换等。
您可以决定是否一次(正常流程)或多次(重试逻辑)调用处理程序。
- wrap_model_call - 环绕每次模型调用
- wrap_tool_call - 环绕每次工具调用
python
# 装饰器
from langchain.agents.middleware import wrap_model_call,ModelRequest,ModelResponse
from typing import Callable
@wrap_model_call
def retry_call(
request:ModelRequest,
handler : Callable[[ModelRequest],ModelResponse],
)-> ModelResponse:
for attempt in range(3):
try:
response = handler(request)
# 模拟模型调用失败
if attempt < 2:
raise Exception("测试异常")
# python 异常是可以被捕获的
# 但是我们在重试前已经抛出了异常,所以重试时捕获不到异常
return response
except Exception as e:
# 为何要捕获异常?
# 因为我们要在异常发生时进行重试,而不是直接抛出异常
# 捕获不了为什么?
# 因为我们在重试前已经抛出了异常,所以重试时捕获不到异常
# 重试时捕获不到异常的原因是因为重试是在一个新的线程中进行的,而抛出异常的线程已经退出了
# 所以重试时捕获不到异常
print(f"Attempt {attempt + 1} failed with error: {e}")
if attempt == 2:
print("All attempts failed.")
print(f"Retry {attempt + 1}/3 after error: {e}")
# class
class RetryMiddleware(AgentMiddleware):
def __init__(self,max_attempts:int = 3 ):
super().__init__()
self.max_attempts = max_attempts
def wrap_model_call(self, request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse]) -> ModelResponse:
for attempt in range(self.max_attempts):
try:
response = handler(request)
# 模拟模型调用失败
if attempt < self.max_attempts - 1:
raise Exception("测试异常")
return response
except Exception as e:
print(f"Attempt {attempt + 1} failed with error: {e}")
if attempt == self.max_attempts - 1:
print("All attempts failed.")
print(f"Retry {attempt + 1}/{self.max_attempts} after error: {e}")
agent = create_agent(
model,
tools=[],
checkpointer=InMemorySaver(),
# middleware=[retry_call]
middleware=[RetryMiddleware(max_attempts=3)]
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "Hi! My name is Bob."}]},
{"configurable": {"thread_id": "1"}},
)
print(result["messages"][-1].content)
print("----")
result = agent.invoke(
{"messages": [{"role": "user", "content": "What is my name?"}]},
{"configurable": {"thread_id": "1"}},
)
print(result["messages"][-1].content)Attempt 1 failed with error: 测试异常
Retry 1/3 after error: 测试异常
Attempt 2 failed with error: 测试异常
Retry 2/3 after error: 测试异常
Hi Bob! Nice to meet you! How can I help you today?
----
Attempt 1 failed with error: 测试异常
Retry 1/3 after error: 测试异常
Attempt 2 failed with error: 测试异常
Retry 2/3 after error: 测试异常
Your name is Bob, as you introduced yourself earlier. It's nice to meet you, Bob! Is there something I can help you with today?Create middleware 创建中间件
基于装饰器的中间件 Decorator-based middleware
适用于单钩子、快速原型开发。
可用装饰器:
- 节点式:@before_agent, @before_model, @after_model, @after_agent
- 包装式:@wrap_model_call, @wrap_tool_call
- 便捷工具:@dynamic_prompt(动态生成系统提示)
适用场景:单一钩子、无需复杂配置、快速验证。快速原型制作
基于类的中间件 Class-based middleware
对于具有多个钩子或配置的复杂中间件,它更强大。当需要为同一个钩子定义同步和异步实现时,或者当需要组合多个钩子时,使用类。
适用场景:
- 同一中间件需多个钩子
- 需要初始化配置(如阈值、模型实例)
- 需同时支持 sync/async
- 跨项目复用
自定义状态 Schema(Custom State Schema)
中间件可扩展智能体状态,添加自定义字段。
这使得中间件能够:
- 跟踪执行期间的状态 :维护计数器、标志或其他在整个代理执行生命周期中持续存在的值
- 在钩子之间共享数据 :将信息从 before_model 转发到 after_model 或在不同的中间件实例之间
- 实现跨切面问题 :无需修改核心代理逻辑即可添加速率限制、使用跟踪、用户上下文或审计日志等功能
- 做出有条件决策 :使用累积状态来确定是否继续执行、跳转到不同的节点或动态修改行为
python
from langchain.agents import create_agent
from langchain.messages import HumanMessage
from langchain.agents.middleware import AgentState, before_model, after_model
from typing_extensions import NotRequired
from typing import Any
from langgraph.runtime import Runtime
class CustomState(AgentState):
model_call_count: NotRequired[int]
user_id: NotRequired[str]
@before_model(state_schema=CustomState, can_jump_to=["end"])
def check_call_limit(state: CustomState, runtime: Runtime) -> dict[str, Any] | None:
count = state.get("model_call_count", 0)
if count > 10:
return {"jump_to": "end"}
return None
@after_model(state_schema=CustomState)
def increment_counter(state: CustomState, runtime: Runtime) -> dict[str, Any] | None:
return {"model_call_count": state.get("model_call_count", 0) + 1}
# class
from langchain.agents import create_agent
from langchain.messages import HumanMessage
from langchain.agents.middleware import AgentState, AgentMiddleware
from typing_extensions import NotRequired
from typing import Any
class CustomState(AgentState):
model_call_count: NotRequired[int]
user_id: NotRequired[str]
class CallCounterMiddleware(AgentMiddleware[CustomState]):
state_schema = CustomState
def before_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
count = state.get("model_call_count", 0)
if count > 10:
return {"jump_to": "end"}
return None
def after_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
return {"model_call_count": state.get("model_call_count", 0) + 1}Execution order 执行顺序
在使用多个中间件时,了解它们是如何执行的:
python
agent = create_agent(
model="gpt-4o",
middleware=[mw1, mw2, mw3],
tools=[...],
)before_*钩子:按列表顺序执行
mw1.before_agent() → mw2.before_agent() → mw3.before_agent()
wrap_*钩子:嵌套执行(最外层最先)
mw1.wrap → mw2.wrap → mw3.wrap → model → mw3.unwrap → mw2.unwrap → mw1.unwrap
after_*钩子:逆序执行
mw3.after_model() → mw2.after_model() → mw1.after_model()
after_agent钩子:逆序执行
mw3.after_agent() → mw2.after_agent() → mw1.after_agent()
关键规则:
- before_*:从左到右
- after_*:从右到左(反向)
- wrap_*:洋葱模型(先注册的在外层)
智能体跳转(Agent Jumps)
在中间件中提前终止或跳转执行流程,返回含 jump_to 的字典:
- 'end':跳至智能体结束(触发 after_agent)
- 'tools':跳至工具节点
- 'model':跳回模型节点(重新进入 before_model)
python
from langchain.agents.middleware import AgentMiddleware, hook_config, AgentState
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
from typing import Any
# 检查模型输出是否包含 "BLOCKED" 内容
# 装饰器
@after_model
@hook_config(can_jump_to=["end"])
def check_for_blocked(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
last_message = state["messages"][-1]
if "BLOCKED" in last_message.content:
return {
"messages": [AIMessage("I cannot respond to that request.")],
"jump_to": "end"
}
return None
# class 跳转到 end 节点
class BlockedContentMiddleware(AgentMiddleware):
@hook_config(can_jump_to=["end"])
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
last_message = state["messages"][-1]
if "BLOCKED" in last_message.content:
return {
"messages": [AIMessage("I cannot respond to that request.")],
"jump_to": "end"
}
return NoneBest practices 最佳实践
-
单一职责:每个中间件只做一件事。
-
错误处理:避免中间件异常导致整个智能体崩溃。
-
钩子选型:
- 顺序逻辑(日志、验证)→ 节点式钩子
- 控制流(重试、缓存、降级)→ 包装式钩子
-
文档化:清晰说明自定义状态字段含义。
-
独立测试:在集成前对中间件进行单元测试。
-
顺序敏感:将关键中间件(如安全检查)放在列表靠前位置。
-
优先内置:若功能已被内置中间件覆盖,优先使用。
Examples 示例
Dynamic model selection 动态模型选择
python
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain.chat_models import init_chat_model
from typing import Callable
complex_model = init_chat_model("gpt-4o")
simple_model = init_chat_model("gpt-4o-mini")
@wrap_model_call
def dynamic_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
# Use different model based on conversation length
if len(request.messages) > 10:
model = complex_model
else:
model = simple_model
return handler(request.override(model=model))Tool call monitoring 工具调用监控
python
from langchain.tools.tool_node import ToolCallRequest
from langchain.agents.middleware import AgentMiddleware
from langchain.messages import ToolMessage
from langgraph.types import Command
from typing import Callable
class ToolMonitoringMiddleware(AgentMiddleware):
def wrap_tool_call(
self,
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command],
) -> ToolMessage | Command:
print(f"Executing tool: {request.tool_call['name']}")
print(f"Arguments: {request.tool_call['args']}")
try:
result = handler(request)
print(f"Tool completed successfully")
return result
except Exception as e:
print(f"Tool failed: {e}")
raiseDynamically selecting tools 动态选择工具
在运行时选择相关工具以提高性能和准确性。本节介绍预注册工具的过滤。对于在运行时发现的工具(例如来自 MCP 服务器),请参见 运行时工具注册 。
Benefits: 好处:
- 更短的提示 - 通过只显示相关工具来降低复杂度
- 更高的准确性 - 模型从更少的选择中正确选择
- 权限控制 - 基于用户访问动态过滤工具