为了更快的上手文章数据采集及发布到Zblog博客网站,总结了一些新手常常遇到问题和使用技巧,以期大家更快地熟练使用,详情如下:
免费Zblog采集发布插件下载,兼容火车头、八爪鱼、简数采集器等
1. 发布到Zblog指定分类
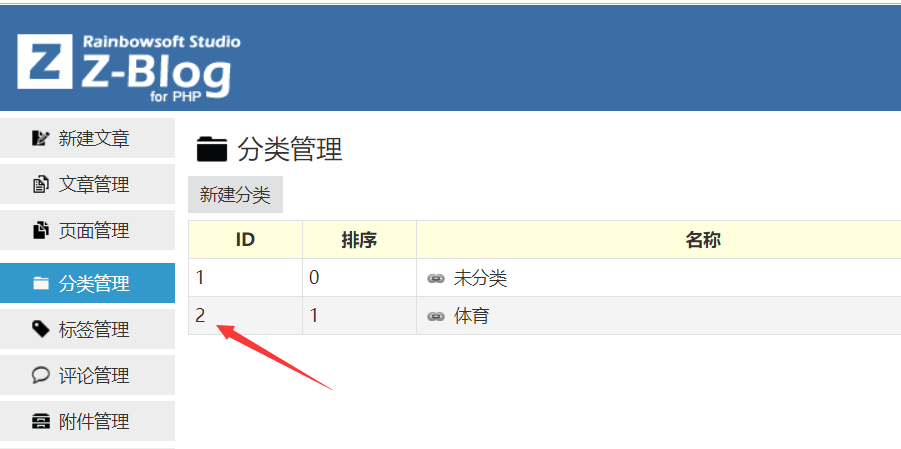
打开简数的发布目标 "字段映射配置" ,在 "分类" 选项的值来源2列处,填写Zblog系统指定分类的数字ID或名称。
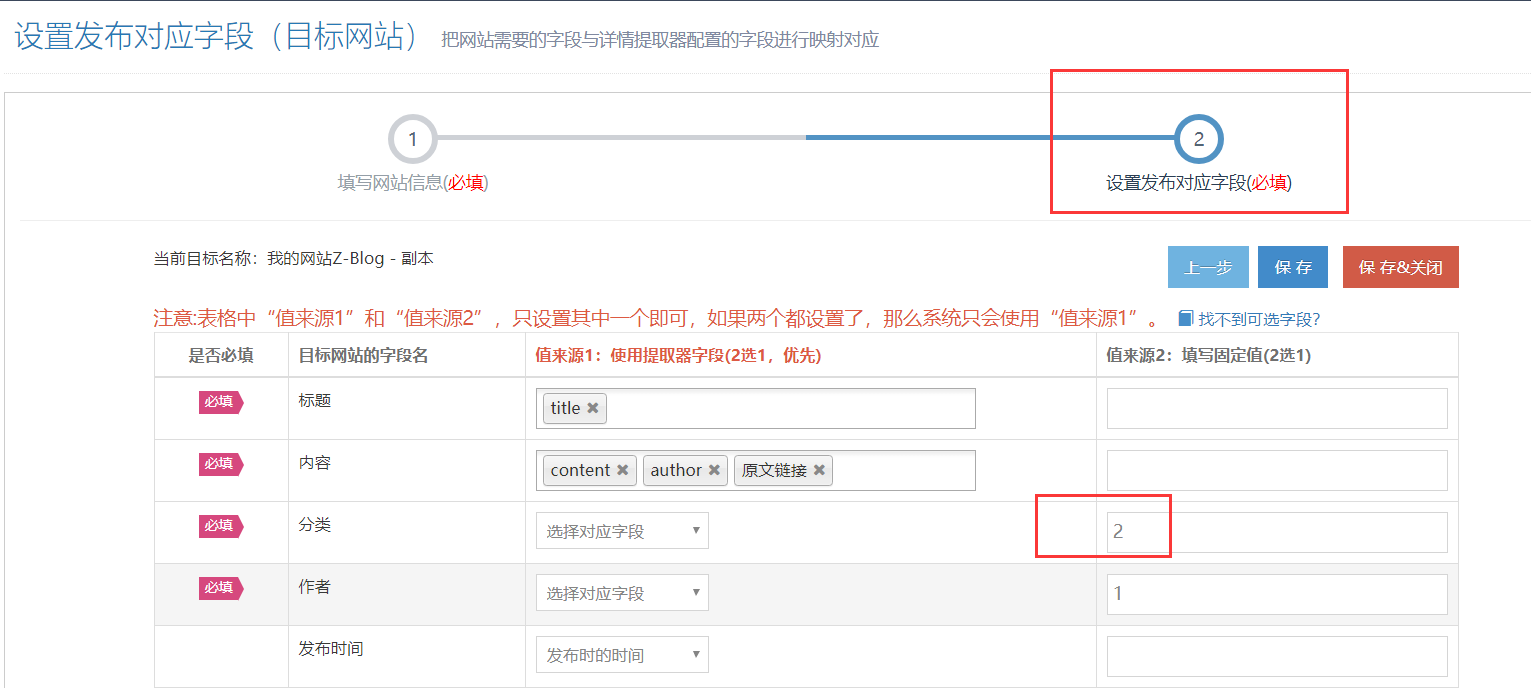
Zblog的分类相关信息可在分类管理处获取。
2. 发布文章到Zblog,一键完成发布字段映射配置
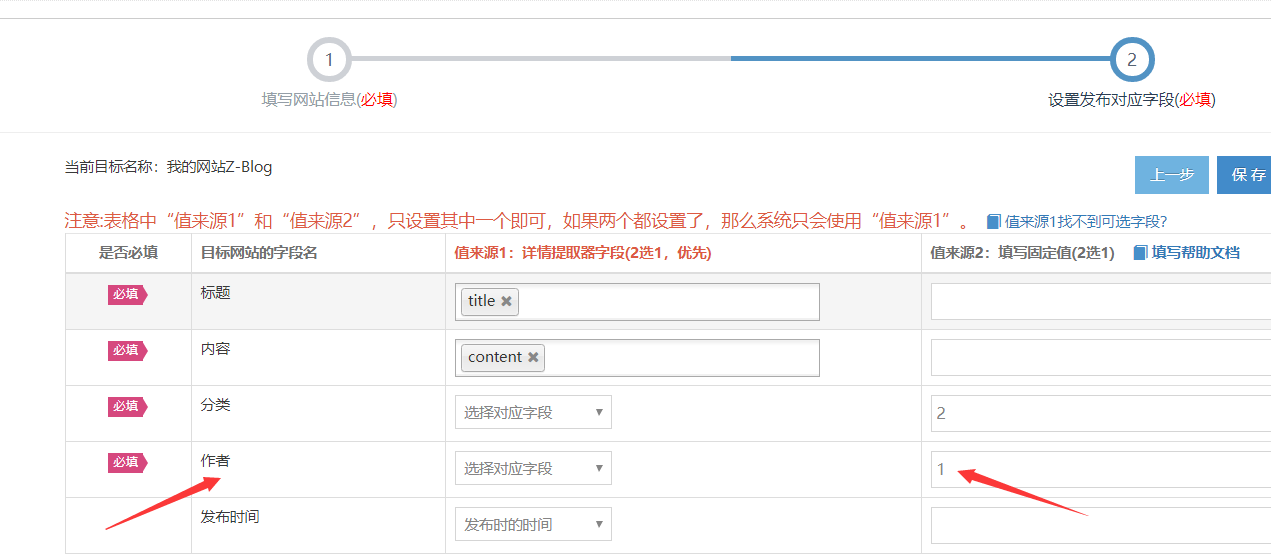
简数采集文章数据发布到zblog网站非常简单,发布字段配置默认按常用的方式自动映射好,用户只需补充分类即可。
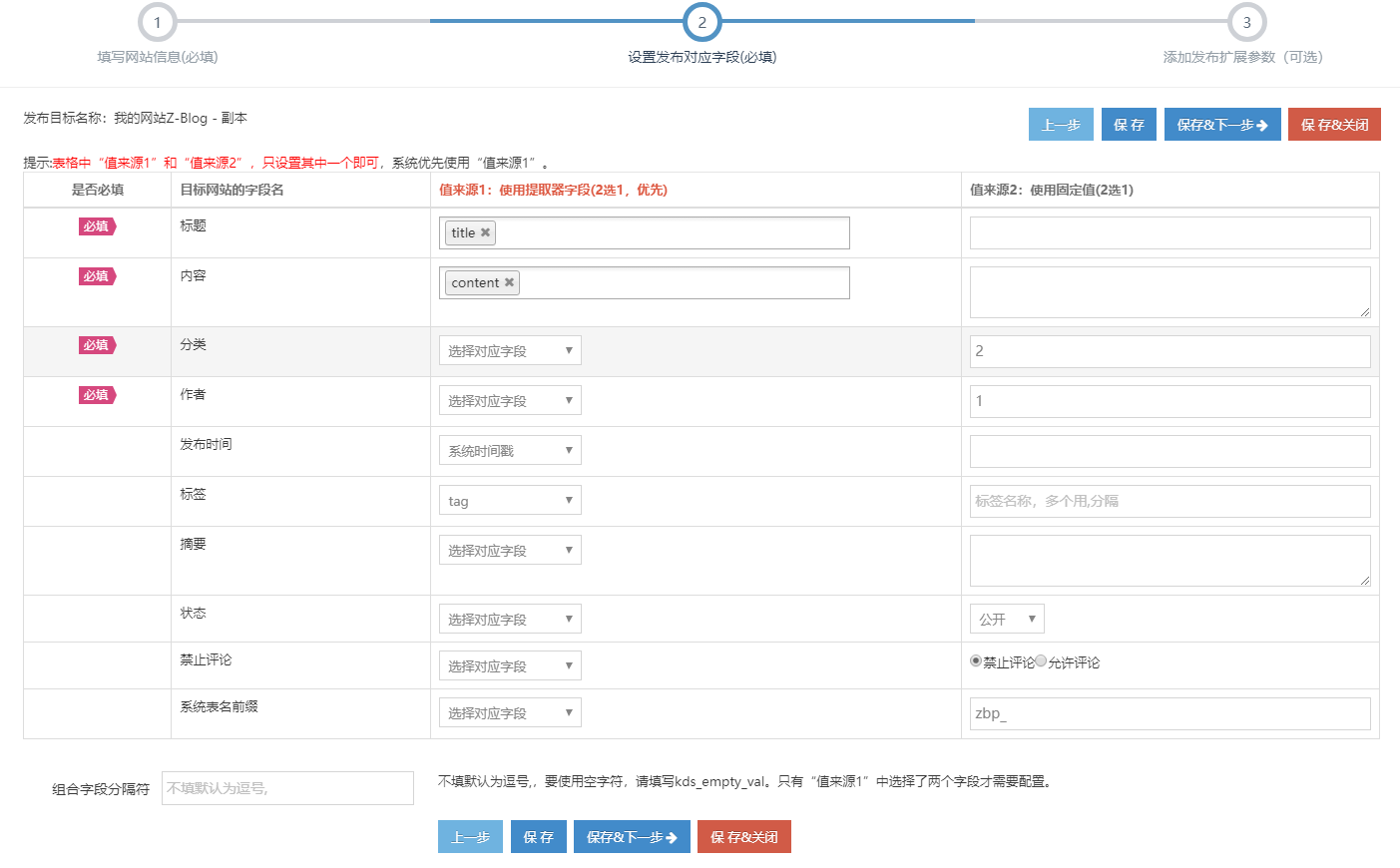
下面为重要字段说明:
- 标题(必填):一般对应采集字段title,在 '来源值1' 中选择即可;(可多选组合字段);
- 内容(必填):为正文部分,一般对应采集字段content, 在 '来源值1' 中选择即可;(可多选组合字段);
- 分类(必填):设置发布数据的所属分类,值是zblog中已存在的分类ID或名称。
- 作者(必填):设置文章的发布者,值是zblog中已存在的用户数字ID,不能是名称,且只能一个作者;
- 发布时间:默认发布时的时间(什么时候发布,就显示什么时间);
3. zblog安装异常Cannot modify header information
Cannot modify header information - headers already sent by (output started at /xxxx/zb_users/plugin/keydatas/main.php:30)
Warning: Cannot modify header information - headers already sent by ......解决办法:
打开 php.ini 然后把 output_buffering 设为 on 。重启网站即可。
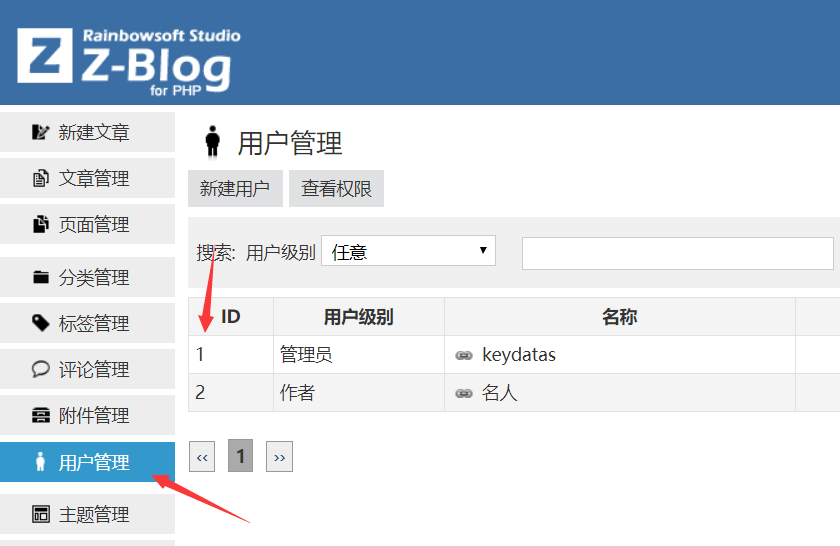
4. 发布指定作者
设置文章的发布者,值是zblog中已存在的用户数字ID,不能是名称,且只能填写一个作者。
在Zblog的用户管理,可获取作者数字ID。