文章目录
-
- 一、核心定义总览
- [二、TTFT(Time To First Token)- 首Token延迟](#二、TTFT(Time To First Token)- 首Token延迟)
-
- [1. 定义与重要性](#1. 定义与重要性)
- [2. TTFT的关键组成](#2. TTFT的关键组成)
- [3. 影响TTFT的因素矩阵](#3. 影响TTFT的因素矩阵)
- [4. 行业标准参考](#4. 行业标准参考)
- [三、TPOT(Time Per Output Token)- Token生成速率](#三、TPOT(Time Per Output Token)- Token生成速率)
-
- [1. 定义与计算](#1. 定义与计算)
- [2. TPOT的技术本质](#2. TPOT的技术本质)
- [3. TPOT性能影响因素](#3. TPOT性能影响因素)
- [四、TTFT 与 TPOT 的对比分析](#四、TTFT 与 TPOT 的对比分析)
-
- [1. 性能指标对比表](#1. 性能指标对比表)
- [2. 实际场景中的表现](#2. 实际场景中的表现)
-
- [3. 两者关系图示](#3. 两者关系图示)
- 五、在AI大模型应用中的重要性
-
- [1. SSE流式传输中的关键作用](#1. SSE流式传输中的关键作用)
- [2. 性能测试中的测量方法](#2. 性能测试中的测量方法)
- 六、优化策略与实践
-
- [1. TTFT优化技术](#1. TTFT优化技术)
- [2. TPOT优化技术](#2. TPOT优化技术)
- [3. Dify应用中的配置建议](#3. Dify应用中的配置建议)
- 七、性能测试与监控
-
- [1. 测试场景设计](#1. 测试场景设计)
- [2. 监控指标看板](#2. 监控指标看板)
- 八、行业最佳实践
-
- [1. 不同应用场景的指标要求](#1. 不同应用场景的指标要求)
- [2. 优化优先级决策框架](#2. 优化优先级决策框架)
- 九、总结
-
- [TTFT(Time To First Token)](#TTFT(Time To First Token))
- [TPOT(Time Per Output Token)](#TPOT(Time Per Output Token))
- 在Dify/大模型应用中的意义
- 性能测试建议
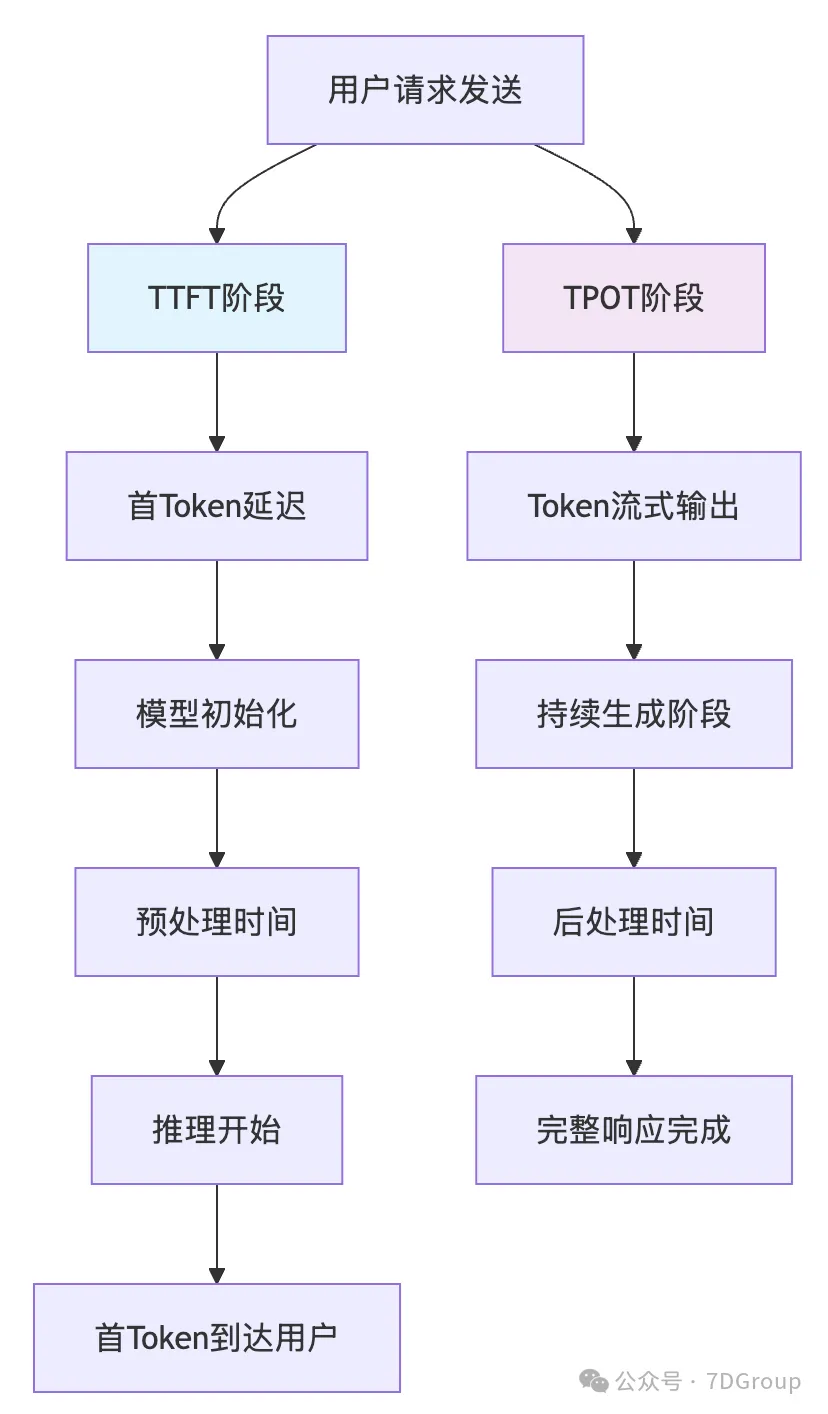
一、核心定义总览
这两个指标专门衡量大模型流式响应性能,是评估用户体验的关键指标。
| 阶段 |
核心内容 |
时间节点范围 |
| TTFT阶段 |
模型初始化、预处理、推理开始 |
用户请求发送 → 首Token到达用户 |
| TPOT阶段 |
Token流式输出、持续生成 |
首Token到达 → 完整响应完成 |
二、TTFT(Time To First Token)- 首Token延迟
1. 定义与重要性
T T F T = 从用户发送请求到接收到第一个输出 T o k e n 的时间间隔 TTFT = 从用户发送请求到接收到第一个输出Token的时间间隔 TTFT=从用户发送请求到接收到第一个输出Token的时间间隔
用户: "请介绍一下量子计算"
↓ 请求发送 (t=0)
服务器: [接收→预处理→模型推理→生成第一个字]
↓ 首Token生成 (t=TTFT)
用户看到: "量..."
2. TTFT的关键组成
# TTFT 分解示意图
TTFT = (
network_latency + # 网络传输延迟
queue_delay + # 服务排队时间
preprocessing_time + # 请求预处理时间
model_initialization + # 模型初始化
first_token_generation # 生成第一个token的推理时间
)
3. 影响TTFT的因素矩阵
| 影响因素 |
具体说明 |
优化策略 |
| 模型大小 |
大模型加载和初始化慢 |
模型量化、模型分片、缓存预热 |
| 输入长度 |
长Prompt需要更多预处理时间 |
Prompt压缩、上下文优化 |
| 硬件性能 |
GPU/TPU算力直接影响推理速度 |
使用更强大硬件、GPU优化 |
| 并发压力 |
高并发导致排队延迟 |
请求队列管理、自动扩缩容 |
| 网络延迟 |
用户到服务器的距离 |
CDN加速、边缘计算节点 |
4. 行业标准参考
用户体验感知阈值:
- < 100ms: 即时响应(优秀)
- 100-300ms: 轻微延迟(良好)
- 300-1000ms: 明显等待(可接受)
- > 1000ms: 体验差(需要优化)
大模型典型TTFT范围:
- 小模型(<7B): 50-200ms
- 中模型(7B-70B): 200-800ms
- 大模型(>70B): 800ms-3s
三、TPOT(Time Per Output Token)- Token生成速率
1. 定义与计算
T P O T = 生成每个输出 T o k e n 的平均时间 TPOT = 生成每个输出Token的平均时间 TPOT=生成每个输出Token的平均时间
数学公式:TPOT = (总生成时间 - TTFT) / (输出Token数 - 1)
示例:
总生成时间:4.2秒
TTFT:0.8秒
输出Token数:100个
TPOT = (4.2 - 0.8) / (100 - 1) = 3.4 / 99 ≈ 34ms/token
2. TPOT的技术本质
// 大模型生成过程的流水线示意
生成过程 = {
阶段1: "首Token生成" // 包含完整计算
阶段2: "后续Token生成" // 使用KV缓存加速
KV缓存机制: {
第一次推理: 计算所有token的注意力
后续推理: 重用已计算的KV缓存
效果: 后续token生成更快
}
}
3. TPOT性能影响因素
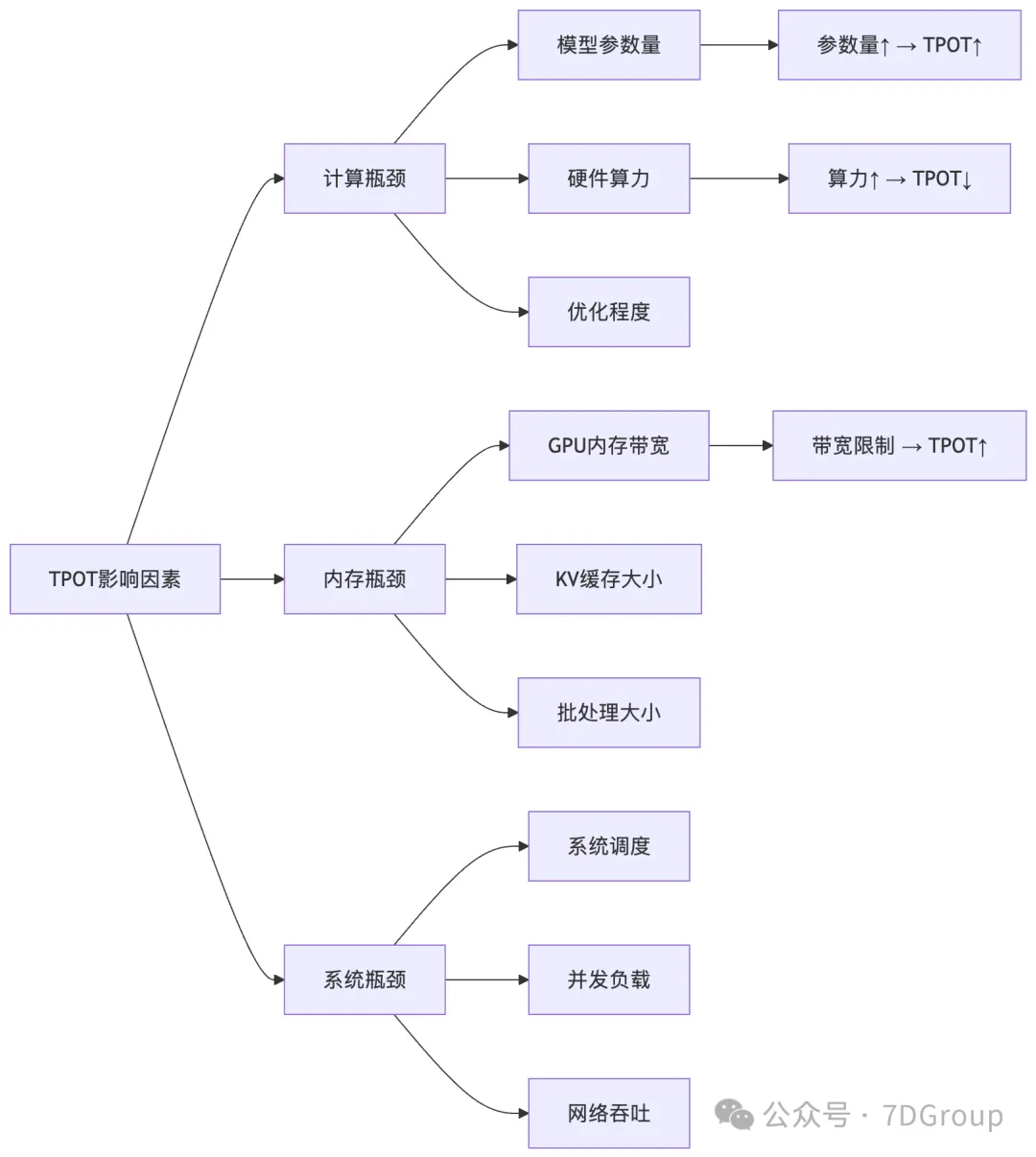
| 瓶颈类型 |
核心影响因素 |
关联逻辑 |
| 计算瓶颈 |
硬件算力、模型参数量 |
算力↑→TPOT↓;参数量↑→TPOT↑ |
| 内存瓶颈 |
GPU内存带宽、KV缓存大小 |
带宽限制→TPOT↑;缓存不足→TPOT↑ |
| 系统瓶颈 |
批处理大小、并发负载、网络吞吐 |
批处理不合理→TPOT波动 |
四、TTFT 与 TPOT 的对比分析
1. 性能指标对比表
| 维度 |
TTFT(首Token延迟) |
TPOT(Token生成速率) |
| 测量对象 |
从请求到第一个输出的时间 |
每个输出Token的平均生成时间 |
| 用户体验 |
影响初始响应感知 |
影响流式输出流畅度 |
| 技术焦点 |
冷启动性能、预处理优化 |
持续生成效率、内存带宽 |
| 优化方向 |
模型加载、Prompt处理、缓存 |
推理引擎、批处理、内存优化 |
| 典型值 |
200ms-2s |
10-100ms/token |
| 影响因素 |
模型大小、输入长度、并发 |
模型架构、硬件、批处理大小 |
2. 实际场景中的表现
场景1:Dify流式对话场景示例
对话开始:
用户提问:"帮我写一首关于春天的诗"
TTFT表现:"春"(800ms后出现)
TPOT表现:后续每个字约50ms
用户体验:
-等待0.8秒看到第一个字
-之后以每秒20字的速度流出
-总等待时间:0.8+(20字×0.05)=1.8秒
场景2:代码生成场景示例
代码生成:
用户请求:"实现快速排序的Python代码"
TTFT:"def"(1.2秒后出现)
TPOT:后续每token约30ms
特点: 代码生成通常TPOT更低,因为token更可预测
3. 两者关系图示
时间轴分析:
┌────────── TTFT ──────────┐ ┌───────── TPOT区域 ─────────┐
用户: 请求发送 首Token到达 完整响应
时间: 0ms 800ms 4800ms
├──────────────────────────┤ ├───────────────────────────┤
包含:网络+预处理+首次推理 包含:后续推理×N个token
五、在AI大模型应用中的重要性
1. SSE流式传输中的关键作用
// SSE流式响应中的TTFT/TPOT影响
SSE_Event_Stream = {
连接建立: "HTTP/2, WebSocket等",
事件流: [
{ time: 0ms, event: "连接建立" },
{ time: TTFT, event: "data: 第一个token" },
{ time: TTFT+TPOT, event: "data: 第二个token" },
{ time: TTFT+2*TPOT, event: "data: 第三个token" },
// ... 持续到生成完成
],
用户体验指标: {
首字延迟: "TTFT决定",
阅读流畅度: "TPOT决定(TPOT<300ms较佳)",
总等待时间: "TTFT + (token数×TPOT)"
}
}
2. 性能测试中的测量方法
# JMeter测试脚本示例 - 测量TTFT和TPOT
import time
class SSEMetricsCalculator:
def __init__(self):
self.start_time = None
self.first_token_time = None
self.token_count = 0
self.total_generation_time = None
def on_request_start(self):
self.start_time = time.time()
def on_first_token(self):
self.first_token_time = time.time()
self.token_count = 1
self.ttft = self.first_token_time - self.start_time
def on_token_received(self):
self.token_count += 1
def on_stream_end(self):
end_time = time.time()
self.total_generation_time = end_time - self.start_time
# 计算TPOT(排除第一个token)
if self.token_count > 1:
generation_time_after_first = self.total_generation_time - self.ttft
self.tpot = generation_time_after_first / (self.token_count - 1)
else:
self.tpot = 0
return {
"TTFT_ms": round(self.ttft * 1000, 2),
"TPOT_ms_per_token": round(self.tpot * 1000, 2),
"total_tokens": self.token_count,
"total_time_ms": round(self.total_generation_time * 1000, 2)
}
六、优化策略与实践
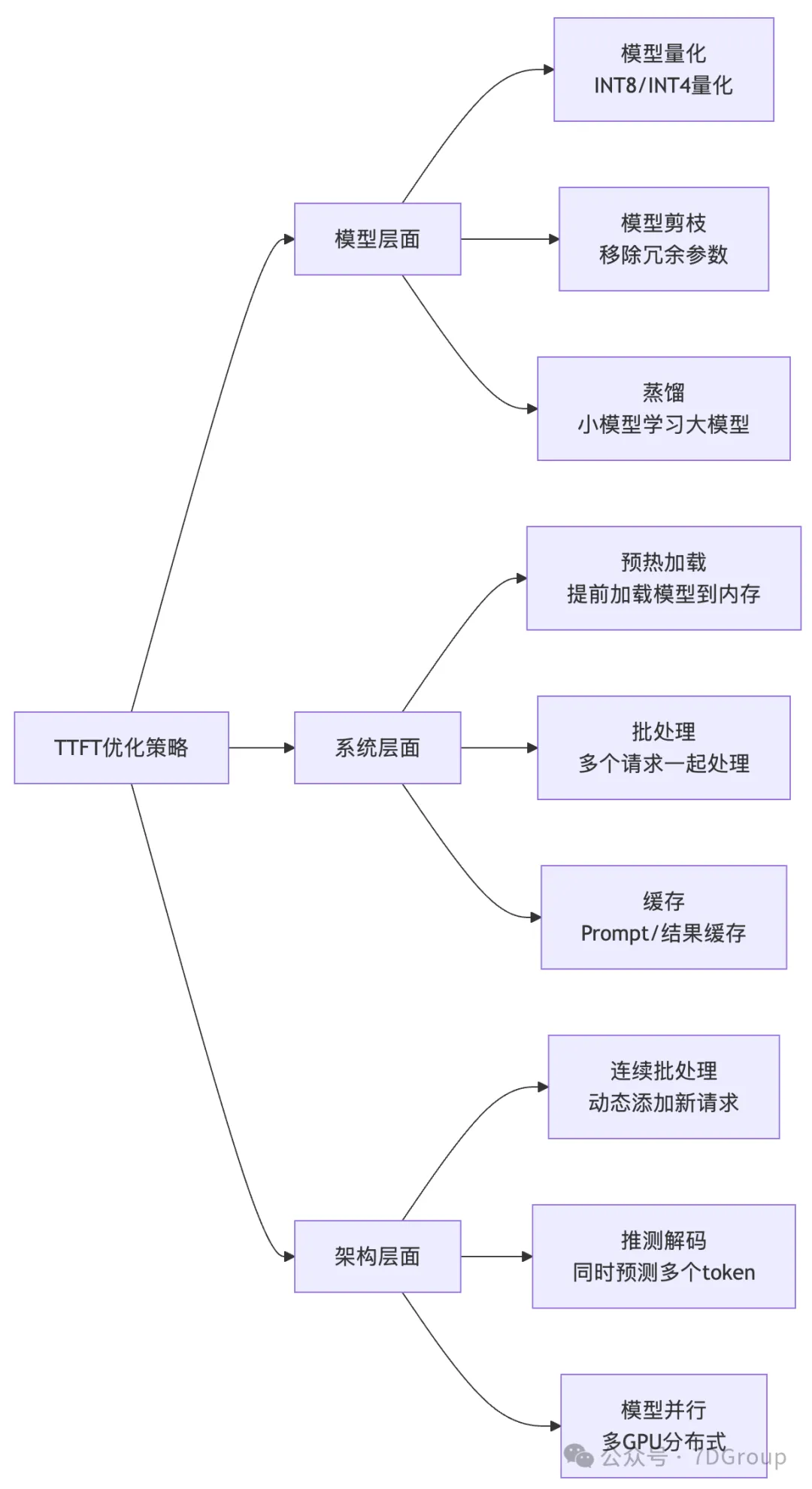
1. TTFT优化技术
| 优化层面 |
具体技术措施 |
| 模型层面 |
- 量化(INT8/INT4量化) - 模型剪枝(移除冗余参数) - 蒸馏(小模型学习大模型) |
| 系统层面 |
- 预热加载(提前加载模型到内存) - 批处理(多个请求一起处理) - Prompt/结果缓存 |
| 架构层面 |
- 连续批处理(动态添加新请求) - 推测解码(同时预测多个token) - 多GPU分布式(模型并行) |
2. TPOT优化技术
| 优化技术 |
原理 |
TPOT提升效果 |
适用场景 |
| KV缓存优化 |
复用已计算的键值对 |
30-70% |
所有自回归模型 |
| 连续批处理 |
动态合并请求 |
2-5倍(高并发时) |
多用户流式场景 |
| FlashAttention |
优化注意力计算 |
20-50% |
长上下文生成 |
| 量化推理 |
低精度计算 |
40-200% |
边缘部署/成本敏感 |
| 推测解码 |
小模型预测,大模型验证 |
2-3倍 |
高算力环境 |
3. Dify应用中的配置建议
# dify_config.yaml - 性能优化配置示例
performance_optimization:
ttft_optimization:
model_warmup: true # 启动时预热模型
preload_models: ["gpt-4", "claude-3"]
cache_prompts: true # 缓存常见prompt
max_prompt_length: 4096 # 限制输入长度
tpot_optimization:
kv_cache_size: 2048 # KV缓存大小
continuous_batching: true # 连续批处理
max_batch_size: 32 # 最大批处理大小
quantization: "int8" # 量化策略
streaming_config:
chunk_size: 50 # 每批发送的token数
min_ttft_target: 500ms # TTFT目标值
max_tpot_target: 50ms # TPOT目标值
monitoring:
metrics_collection: true
alert_thresholds:
ttft_warning: 1000ms
ttft_critical: 2000ms
tpot_warning: 100ms/token
tpot_critical: 200ms/token
七、性能测试与监控
1. 测试场景设计
# 性能测试矩阵 - 覆盖不同场景
test_scenarios = {
"短文本生成": {
"prompt_length": "50-100 tokens",
"expected_output": "100-200 tokens",
"ttft_target": "< 500ms",
"tpot_target": "< 30ms/token"
},
"长文档生成": {
"prompt_length": "500-1000 tokens",
"expected_output": "1000-2000 tokens",
"ttft_target": "< 1500ms",
"tpot_target": "< 50ms/token"
},
"代码生成": {
"prompt_length": "100-300 tokens",
"expected_output": "200-500 tokens",
"ttft_target": "< 800ms",
"tpot_target": "< 25ms/token"
},
"高并发场景": {
"concurrent_users": 50,
"ttft_p95_target": "< 2000ms",
"tpot_degradation": "< 20%" # 并发下TPOT退化限制
}
}
2. 监控指标看板
实时监控看板示例:
┌───────────────── 大模型性能监控 ─────────────────┐
│ 实例: dify-prod-01 时间范围: 最近1小时 │
├─────────────────────────────────────────────────┤
│ TTFT (首Token延迟) │
│ P50: 420ms P95: 890ms P99: 1450ms │
│ 趋势: ▼12% (相比上一小时) │
│ │
│ TPOT (Token生成速率) │
│ P50: 34ms/token P95: 68ms/token │
│ 平均输出速度: 29 tokens/秒 │
│ │
│ 并发性能 │
│ 当前并发: 38 最大并发: 52 错误率: 0.2% │
│ TTFT vs 并发: R²=0.78 (强相关) │
└─────────────────────────────────────────────────┘
八、行业最佳实践
1. 不同应用场景的指标要求
| 应用类型 |
推荐TTFT |
推荐TPOT |
关键考量 |
| 实时对话 |
< 300ms |
< 50ms/token |
低延迟优先,保证对话流畅 |
| 内容创作 |
< 800ms |
< 100ms/token |
质量优先,可接受稍长等待 |
| 代码助手 |
< 500ms |
< 40ms/token |
准确性+速度平衡 |
| 翻译服务 |
< 200ms |
< 30ms/token |
极速响应需求 |
| 批处理任务 |
< 2000ms |
< 150ms/token |
吞吐量优先,延迟次要 |
2. 优化优先级决策框架
在这里插入图片描述
性能问题分析
├─ TTFT>目标值?
│ ├─ 是 → 优化TTFT(分析瓶颈:网络→CDN/边缘节点;预处理→Prompt优化;模型→量化/预热)
│ └─ 否 → 检查TPOT
└─ TPOT>目标值?
├─ 是 → 优化TPOT(分析瓶颈:计算→硬件升级/量化;内存→KV缓存优化;系统→批处理调整)
└─ 否 → 性能达标
九、总结
TTFT(Time To First Token)
- 是什么:从请求到第一个输出的等待时间
- 为什么重要:决定用户的第一印象和响应感知
- 优化方向:模型加载、预处理、冷启动优化
- 行业标准:最好<500ms,可接受<1.5s
TPOT(Time Per Output Token)
- 是什么:每个输出token的平均生成时间
- 为什么重要:决定流式输出的流畅度和总完成时间
- 优化方向:推理引擎、内存带宽、批处理优化
- 行业标准:最好<50ms/token,可接受<100ms/token
在Dify/大模型应用中的意义
- 用户体验核心:直接决定用户是否愿意持续使用
- 技术选型依据:帮助选择适合的模型和部署方案
- 成本优化关键:性能优化可降低算力成本
- 容量规划基础:基于TTFT/TPOT计算系统承载能力
性能测试建议
测试重点:
- 测量不同并发下的TTFT/TPOT变化
- 监控长时运行的性能稳定性
- 测试不同输入长度的影响
- 验证优化措施的实际效果
报告指标:
- TTFT: P50, P90, P95, P99
- TPOT: 平均值, 分布情况
- 吞吐量: tokens/秒
- 错误率: 超时/失败比例
理解并优化TTFT和TPOT,是大模型应用性能调优的核心,直接影响用户体验和系统效率。