
您有没有过这样的时刻:将公司代码粘贴到 ChatGPT 中,脑海中一个小声音低语着,"我应该这样做吗?"
我忽略了那个声音好几个月。然后我的经理转发了一封来自法务部门的关于"AI 工具使用政策"的电子邮件。突然间,那个小声音变得非常响亮。
这里没有人告诉您关于云 AI 服务的事情。您发送的每条消息都会传输到其他人的服务器。每个代码片段。每次私人对话。每次您太害羞而不敢问同事的尴尬问题。
对于个人事务?没问题。但对于工作代码、私人项目,或任何您不希望第三方看到的事情?那就是另一回事了。
所以我使用两个开源工具构建了自己的私有 AI。两个小时的设置。每月零美元。老实说?这比我预期的要好。
这就是我是如何做到的完整故事 ------ 包括每个错误、每个修复、每个"顿悟"时刻。
1、改变一切的两个工具
我的私有 AI 在两个完美协作的开源项目上运行。
Ollama 是引擎。它直接在您的计算机上运行 AI 模型。没有云。没有 API 调用。没有数据离开您的机器。将其视为"AI 模型的 Docker" ------ 您拉取一个模型,在本地运行,完成。社区使其变得 incredibly easy to use。
Clawdbot 是接口。它是一个开源网关,将 Ollama 连接到您实际使用的应用程序 ------ Slack、Web 浏览器、命令行,甚至 Discord。如果没有 Clawdbot,您将被困在终端窗口中打字。有了它,您可以从任何地方与您的 AI 聊天。
它们共同创建了这种架构:
Slack/Web/CLI → Clawdbot Gateway → Ollama → AI Model
↑ ↑
您的应用程序 您的计算机
(没有任何东西离开)魔力在于最后一行。没有任何东西离开。 您的问题、您的代码、您的私人想法 ------ 它们从未接触互联网。它们从未到达其他人的服务器。它们正好停留在您放置它们的地方。
2、为什么我选择这个而不是云 AI
让我诚实地说。ChatGPT 和 Claude 是惊人的。我仍然将它们用于个人事务。它们设置更快,并且拥有前沿模型。
但这里是我的成本计算:
云 AI 成本(我的实际支出):
- ChatGPT Plus:每月 20 美元
- Claude Pro:每月 20 美元
- 偶尔的 API 使用:每月 30-50 美元
这大约是每月 70-90 美元。每年超过 800 美元。
我的 Clawdbot + Ollama 设置:
- 一次性硬件:已经有 GPU
- 电力:7x24 小时操作每月约 10-15 美元
- 软件:0 美元(开源)
- API 成本:永远 0 美元
盈亏平衡时间: 大约 2 个月。
但这里有个事情 ------ 金钱并不是我切换的真正原因。
真正的原因:我需要询问工作代码而不用担心。
每次我为工作使用云 AI,问题困扰着我。这些数据去哪里了?谁可以看到它?它是否被用于训练未来的模型?我是否违反了公司政策?这段代码是否最终会出现在其他人的自动完成中?
使用我的本地设置,我确切地知道一切去向。无处可去。它在我的机器上处理并停留在我的机器上。就是这样。
这种平静的心态彻底改变了我使用 AI 的方式。
3、硬件问题(并非您所想)
在我们深入设置之前,让我们谈谈硬件。这是大多数人被吓退的地方。
您不需要超级计算机。
这是实际工作的:
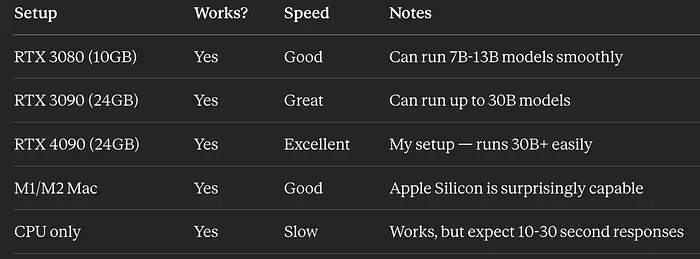
我有双 RTX 4090(总共 48GB),这是过度的。但我开始在较旧的 RTX 3080 上测试,它对于较小的模型工作良好。
诚实的事实: 如果您有过去 3-4 年的任何游戏 GPU,您可以运行本地 AI。它可能比云慢,但它可以工作。
4、我的设置旅程(诚实版本)
我希望我可以说这很容易。第一次尝试并不是。但错误教会了我什么是真正重要的。
4.1 安装 Ollama(简单部分)
这部分实际上很简单:
curl -fsSL https://ollama.ai/install.sh | sh然后我拉取了我的第一个模型:
ollama pull qwen3:30b-a3b为什么是这个特定模型?我稍后会解释。现在,只需知道下载 18GB 大约花了 10 分钟。
快速测试:
ollama run qwen3:30b-a3b "What is 2+2?"它在大约 2 秒内回复"4"。Ollama 正在工作。到目前为止一切顺利。
4.2 安装 Clawdbot(也很简单)
npm install -g clawdbot@latest
clawdbot onboard入门向导询问我关于要使用哪个 AI 提供商的问题。我选择了 Ollama 并将其指向 localhost。
一切看起来都很好。然后我的第一个真正的问题来了。
4.3 上下文窗口陷阱
我用 8,192 令牌上下文窗口配置了我的模型。这是像原始 GPT-3.5 这样的云 API 的常见默认值。
Clawdbot 拒绝启动。
Error: Model context window too small (8192 tokens).
Minimum is 16000.我尴尬地困惑了一个小时。为什么 Clawdbot 需要这么大的上下文窗口?我的模型坏了吗?
然后我实际检查了我模型的真正能力:
curl -s http://127.0.0.1:11434/api/show \
-d '{"name":"qwen3:30b-a3b"}'结果震惊了我:
- Qwen3 30B → 262,144 令牌
- Llama 3.3 70B → 131,072 令牌
- DeepSeek Coder → 163,840 令牌
我将模型限制为其实际能力的 3%。没有理由。只是因为我假设云默认值在本地适用。
修复很简单。 我更新了配置以匹配现实:
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama-local",
"models": [
{
"id": "qwen3:30b-a3b",
"contextWindow": 262144,
"maxTokens": 32768
}
]
}
}
}
}吸取的教训: 永远不要假设。本地模型在上下文窗口方面通常比其云对应物更有能力。始终检查实际规格。
4.4 Slack 的静默失败模式
Clawdbot 运行后,我将其连接到 Slack。创建了应用程序。添加了令牌。机器人在线显示绿点。
我向它发送了一条消息:"Hello, are you there?"
什么也没发生。
没有错误消息。没有响应。没有迹象表明任何错误。只是沉默。
我检查了 Clawdbot 的日志。没有错误。我检查了 Slack 的应用程序仪表板。一切看起来都连接了。我多次重新启动所有内容。
在一个小时越来越沮丧的调试后,我在日志文件中发现了埋藏的问题。我忘记了一个 Slack 权限:groups:read。
没有它,机器人无法看到私有频道中的消息。而我的测试频道是私有的。
残酷的部分?Slack 不会告诉您。它不显示错误。它不警告您。它只是静默地忽略机器人无法看到的消息。
这是您实际需要的所有权限:
权限
为什么您需要它
app_mentions:read
当人们 @mention 机器人时查看
chat:write
发回响应
im:read + im:write
处理直接消息
groups:read + groups:history
查看私有频道
channels:read + channels:history
查看公共频道
错过任何一个,您的机器人将在没有警告的情况下失败。我以艰难的方式学到了这一点,这样您就不必了。
吸取的教训: 预先添加每个权限。调试静默失败将窃取您数小时的生命。
5、为什么我选择了一个"奇怪"的模型
这是我终于做出正确决定的地方。
大多数指南说"选择适合您 GPU 的最大模型。"有道理,对吗?更大的模型 = 更好的响应。
我做了相反的事情。我选择了 Qwen3 30B-A3B 而不是 70B 模型。
"A3B" 部分是秘密。此模型使用"混合专家"(MoE) 架构。它总共有 300 亿个参数,但任何给定的响应只激活 30 亿。
将其想象成拥有 30 位专家的医院。当您有心脏问题时,您不需要房间里的所有 30 位医生。您需要心脏病专家。也许一位护士。MoE 模型以相同的方式工作 ------ 它们将您的问题路由到正确的"专家"参数。
这是真正的世界差异:
指标
Llama 70B
Qwen3 30B MoE
响应时间
5-10 秒
1-3 秒
所需 VRAM
40GB+
15-20GB
质量
优秀
几乎一样好
适合单个 4090?
勉强
容易
对于聊天机器人,速度比边际质量改进更重要。没有人想等待 10 秒来获得 Slack 回复。70B 模型给出稍微更好的答案,但 MoE 模型给出足够好的答案快三倍。
我两者都测试了一周。MoE 模型轻松赢得了我的用例。
6、我的私有 AI 现在实际上做什么
经过两周的日常使用,这是我的 Clawdbot 设置如何融入我的工作流程:
没有偏执的代码审查。 我粘贴整个文件并询问"这里可能会出什么问题?"或"你能发现任何错误吗?"代码从未离开我的网络。我不必清理任何内容或担心专有逻辑泄漏。
快速技术问题。 我不是打开浏览器并上下文切换到 Google,而是问我的 AI。"useEffect 和 useLayoutEffect 之间有什么区别?"它在几秒钟内回答并记住我们在对话中早些时候讨论的内容。
写作协助。 文档、提交消息、PR 描述、技术电子邮件 ------ 我的 AI 起草它们,我编辑。它并不完美,但比从头开始要快。
橡皮鸭调试。 有时我只是向 AI 解释我的问题。一半的时间,我在打字时想出答案。另一半,它将我指向正确的方向。
双语支持。 我在韩语和英语中工作。Qwen 模型无缝处理两者。我测试了:"안녕, 오늘 날씨 어때?" 响应在 2 秒内以自然的韩语回来。
心理差异: 我不再考虑成本了。没有运行中的计费器。没有"我使用了太多令牌吗?"的焦虑。没有每月账单悄悄上升。我随时问我想问的任何东西。
6、Web 仪表板(隐藏的宝石)
我没想到的一件事:Clawdbot 有一个令人惊讶的良好的 Web 界面。
通过 SSH 隧道访问它:
ssh -L 18789:127.0.0.1:18789 your-server然后在浏览器中打开 http://localhost:18789。
您获得完整的聊天界面、对话历史、配置编辑器、实时日志和健康监控。对于大多数任务,它比命令行更容易。
老实说,我现在使用 Web 仪表板比 Slack 多。
7、快速入门指南
想要构建自己的吗?这是最快的路径:
步骤 1:安装 Ollama
curl -fsSL https://ollama.ai/install.sh | sh
ollama pull qwen3:30b-a3b步骤 2:安装 Clawdbot
npm install -g clawdbot@latest
clawdbot onboard步骤 3:测试它
clawdbot agent --local --message "Hello, what's 2+2?"如果它回复"4",您有一个工作的私有 AI。整个过程大约需要 30 分钟。
其他一切 ------ Slack 集成、Web 仪表板、systemd 服务 ------ 都是可选的润色。核心立即工作。
8、您应该构建这个吗?
对自己诚实地回答这些问题:
如果您符合以下情况,请构建自己的私有 AI:
-
您定期处理敏感或专有代码
-
您厌倦了每月的 AI 订阅不断累积
-
您有不错的 GPU(RTX 3080 或更好,或 Apple Silicon)
-
您喜欢自己托管工具的修补
-
隐私对您的工作真正重要
如果您符合以下情况,请坚持使用云 AI: -
您需要绝对前沿的模型(GPT-4o、Claude Opus)
-
两个小时的设置时间不值得长期节省
-
您没有合适的硬件并且不想购买任何硬件
-
您的用例是随意的,隐私不是问题
对我来说,仅隐私就证明了努力是合理的。成本节省是一个不错的奖励。速度令人惊讶地有竞争力。
9、下次我会做得不同
如果今天我重新开始这个项目,这是我会改变的:
在配置之前检查模型规格。 因为我假设而不是验证,上下文窗口错误浪费了一个小时。五分钟的研究将节省六十分钟的调试。
从一开始就添加所有 Slack 权限。 静默失败是最糟糕的错误类型。只需预先添加每个推荐的权限并避免头痛。
立即从 MoE 模型开始。 我首先测试了 70B 模型,因为"更大更好"感觉直观上是正确的。错了。对于聊天应用程序,响应速度比边际质量收益更重要。
从第一天起使用 Web 仪表板。 我花了太长时间与命令行工具斗争,当时一个完美的 GUI 在那里等待。
更早设置 systemd 服务。 Clawdbot 在启动时自动启动可以避免记住手动启动它的麻烦。
10、还有一件事:实际上适用于所有事情的模型
在我确定当前设置之前,我测试了超过 20 种不同的模型。我不仅是在检查它们是否能回答问题。我有三个严格的要求:工具调用 (它可以使用搜索或计算等功能吗?)、韩语语言 (当用韩语询问时它是否用韩语回复?)和准确性(答案实际上正确吗?)。
大多数模型至少通过了一个测试。一些大名鼎鼎的模型以它们表现糟糕的方式让我惊讶。
这就是我发现的:
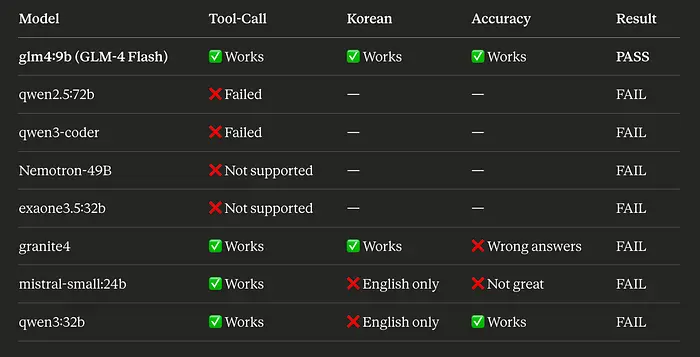
这个模式令人沮丧。一些模型完美地处理了工具调用但拒绝用韩语回复。其他的用美丽的韩语说话但给出了完全错误的答案。Granite4 是最烦人的 ------ 除了答案是无意义之外,它做的一切都正确。
经过数周的测试,只有一个模型通过了每一个测试:GLM-4 9B Flash。它毫不费力地处理了韩语、英语、中文和混合语言对话。工具调用完美工作。答案准确。
如果您需要一个真正多语言的私有 AI 实际上可以工作,这就是一个。用 ollama pull glm4:9b 拉取它并稍后感谢我。
11、我构建这个的真正原因
这是我在一切正常工作后意识到的。
技术并不难部分。Ollama 和 Clawdbot 使技术设置出奇地直接。文档很好。社区有帮助。
困难的部分是决定隐私和控制足够重要,值得花几个小时在设置上。
大多数开发人员毫不犹豫地将代码粘贴到云 AI 工具中。这没关系 ------ 直到您的公司问"那段代码去哪里了?"直到法务部门发送政策更新。直到您意识到您一直在与您不控制的服务器共享专有算法。
构建私有 AI 并不是关于偏执。它是关于有一个清晰、简单的答案:"它从未离开我的机器。"
当有人问我的 AI 对话去哪里时,我不必阅读服务条款或隐私政策。我不必希望公司保持其承诺。我只是指向我的服务器并说"那里。"
这种清晰度比我每年节省的 800 美元更有价值。