
✨道路是曲折的,前途是光明的!
📝 专注C/C++、Linux编程与人工智能领域,分享学习笔记!
🌟 感谢各位小伙伴的长期陪伴与支持,欢迎文末添加好友一起交流!

-
- 前言:技术变革的双重面向
- 一、AI内容创作技术架构解析
-
- [1.1 整体技术流程](#1.1 整体技术流程)
- [1.2 核心技术模块](#1.2 核心技术模块)
- 二、实战代码:构建轻量级AI创作助手
-
- [2.1 基础配置类](#2.1 基础配置类)
- [2.2 提示词模板引擎](#2.2 提示词模板引擎)
- [2.3 AI客户端实现](#2.3 AI客户端实现)
- [2.4 内容创作助手主类](#2.4 内容创作助手主类)
- [2.5 使用示例](#2.5 使用示例)
- 三、流式响应处理的实现细节
-
- [3.1 SSE数据解析器](#3.1 SSE数据解析器)
- 四、质量检测与内容优化
-
- [4.1 简易质量检测实现](#4.1 简易质量检测实现)
- 五、AI时代创作者的成长路径
-
- [5.1 核心能力迁移模型](#5.1 核心能力迁移模型)
- [5.2 创作者需要的三大核心能力](#5.2 创作者需要的三大核心能力)
- 六、与AI创作者社区共同成长
- 七、完整项目结构
- 八、总结与展望

当ChatGPT掀起全球狂潮,当AI绘画让设计师恐慌,当自动化开始威胁传统职业------我们不禁要问:AI时代,究竟是赋能未来,还是一场颠覆性的科技革命?
前言:技术变革的双重面向
人工智能技术的飞速发展正在重塑内容创作的边界。传统的创作模式------从构思、素材收集、初稿到打磨------往往需要数小时甚至数天的时间。而今天,借助AI工具,这一过程可以被压缩到几分钟。
但这并不意味着创作的贬值,恰恰相反,创作的价值正在从"执行"转向"决策"与"审美"。在这篇文章中,我们将从技术角度探讨AI内容创作的实现路径,并分享一个值得参与的交流平台。
一、AI内容创作技术架构解析
1.1 整体技术流程

1.2 核心技术模块
一个典型的AI内容创作系统包含以下核心模块:
| 模块 | 功能 | 技术实现 |
|---|---|---|
| 提示词管理 | 优化输入质量 | 模板引擎 + 上下文注入 |
| 模型调用层 | 与AI服务交互 | RESTful API / WebSocket |
| 流式处理 | 实时内容生成 | SSE / Server-Sent Events |
| 质量检测 | 内容合规性检查 | 规则引擎 + NLP分类 |
| 缓存系统 | 减少重复调用 | Redis / 本地存储 |
二、实战代码:构建轻量级AI创作助手
下面我们用Python实现一个简单的AI内容创作助手框架:
2.1 基础配置类
python
import os
import json
import requests
from typing import Generator, Optional
from dataclasses import dataclass
from enum import Enum
class ModelProvider(Enum):
"""支持的AI模型提供商"""
OPENAI = "openai"
ANTHROPIC = "anthropic"
MODELSCOPE = "modelscope" # 魔搭社区
LOCAL = "local"
@dataclass
class AIConfig:
"""AI配置类"""
provider: ModelProvider
api_key: str
model_name: str
base_url: Optional[str] = None
max_tokens: int = 2000
temperature: float = 0.7
@classmethod
def from_env(cls, provider: str) -> 'AIConfig':
"""从环境变量加载配置"""
api_key = os.getenv(f"{provider.upper()}_API_KEY")
if not api_key:
raise ValueError(f"Missing API key for {provider}")
return cls(
provider=ModelProvider(provider),
api_key=api_key,
model_name=os.getenv(f"{provider.upper()}_MODEL", "default"),
base_url=os.getenv(f"{provider.upper()}_BASE_URL"),
max_tokens=int(os.getenv("MAX_TOKENS", "2000")),
temperature=float(os.getenv("TEMPERATURE", "0.7"))
)2.2 提示词模板引擎
python
class PromptTemplate:
"""提示词模板管理器"""
def __init__(self):
self.templates = {
"content_creator": """你是一个专业的AI内容创作助手。
## 角色定位
你擅长创作各种类型的内容,包括但不限于:
- 技术文章和教程
- 营销文案和广告语
- 社交媒体内容
- 产品描述和评测
## 创作原则
1. **精准性**:准确理解用户需求,不偏离主题
2. **创意性**:在保持准确的前提下,提供新颖的视角
3. **可读性**:使用清晰、流畅的语言表达
4. **结构化**:合理组织内容层次
## 用户需求
{user_input}
请根据以上要求创作内容:""",
"tech_article": """你是一位经验丰富的技术博主。
## 写作风格
- 深入浅出,兼顾技术深度与可读性
- 适当使用代码示例和图表说明
- 结构清晰,包含引言、主体、总结
## 主题
{topic}
## 目标受众
{audience}
请撰写一篇技术文章:""",
}
def get_template(self, name: str, **kwargs) -> str:
"""获取并渲染模板"""
template = self.templates.get(name)
if not template:
raise ValueError(f"Template '{name}' not found")
return template.format(**kwargs)
def add_template(self, name: str, content: str):
"""添加自定义模板"""
self.templates[name] = content2.3 AI客户端实现
python
class AIClient:
"""AI客户端基类"""
def __init__(self, config: AIConfig):
self.config = config
self.session = requests.Session()
self.session.headers.update({
"Authorization": f"Bearer {config.api_key}",
"Content-Type": "application/json"
})
def generate(self, prompt: str, stream: bool = False) -> Generator[str, None, None]:
"""生成内容(支持流式输出)"""
raise NotImplementedError
def chat(self, messages: list, stream: bool = False) -> Generator[str, None, None]:
"""多轮对话"""
raise NotImplementedError
class ModelScopeClient(AIClient):
"""魔搭社区API客户端"""
def __init__(self, config: AIConfig):
super().__init__(config)
self.base_url = config.base_url or "https://api.modelscope.cn/v1"
def generate(self, prompt: str, stream: bool = False) -> Generator[str, None, None]:
"""调用魔搭API生成内容"""
endpoint = f"{self.base_url}/chat/completions"
payload = {
"model": self.config.model_name,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": self.config.max_tokens,
"temperature": self.config.temperature,
"stream": stream
}
if stream:
# 流式响应处理
response = self.session.post(endpoint, json=payload, stream=True)
response.raise_for_status()
for line in response.iter_lines():
if line:
line = line.decode('utf-8')
if line.startswith('data: '):
data = line[6:]
if data == '[DONE]':
break
try:
chunk = json.loads(data)
delta = chunk['choices'][0]['delta']['content']
yield delta
except (KeyError, json.JSONDecodeError):
continue
else:
# 非流式响应
response = self.session.post(endpoint, json=payload)
response.raise_for_status()
result = response.json()
yield result['choices'][0]['message']['content']2.4 内容创作助手主类
python
class ContentCreationAssistant:
"""AI内容创作助手"""
def __init__(self, config: AIConfig):
self.client = ModelScopeClient(config)
self.template_engine = PromptTemplate()
self.conversation_history = []
def create_content(
self,
user_input: str,
template: str = "content_creator",
stream: bool = True,
**template_kwargs
) -> str:
"""创作内容"""
# 1. 构建完整提示词
if template:
prompt = self.template_engine.get_template(
template,
user_input=user_input,
**template_kwargs
)
else:
prompt = user_input
# 2. 记录对话历史
self.conversation_history.append({
"role": "user",
"content": user_input
})
# 3. 调用AI生成
full_response = ""
print("\n🤖 AI生成中:\n")
for chunk in self.client.generate(prompt, stream=stream):
print(chunk, end='', flush=True)
full_response += chunk
print("\n")
# 4. 记录响应
self.conversation_history.append({
"role": "assistant",
"content": full_response
})
return full_response
def improve_content(self, original_content: str, feedback: str) -> str:
"""根据反馈改进内容"""
improvement_prompt = f"""
请根据以下反馈改进内容:
## 原始内容
{original_content}
## 改进反馈
{feedback}
请输出改进后的内容:
"""
return self.create_content(improvement_prompt, template=None)
def export_conversation(self, filepath: str):
"""导出对话历史"""
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(self.conversation_history, f, ensure_ascii=False, indent=2)
print(f"✅ 对话历史已导出到: {filepath}")2.5 使用示例
python
# 初始化助手
config = AIConfig(
provider=ModelProvider.MODELSCOPE,
api_key="your_modelscope_api_key",
model_name="qwen-turbo",
max_tokens=2000,
temperature=0.7
)
assistant = ContentCreationAssistant(config)
# 方式1:使用默认模板创作
content = assistant.create_content(
user_input="写一篇关于AI数字人技术的技术文章",
template="content_creator"
)
# 方式2:使用特定模板
article = assistant.create_content(
topic="WebAssembly技术详解",
audience="前端开发者",
template="tech_article"
)
# 方式3:改进已有内容
improved = assistant.improve_content(
original_content=content,
feedback="增加更多代码示例,减少理论描述"
)
# 导出对话历史
assistant.export_conversation("creation_history.json")三、流式响应处理的实现细节
流式响应是AI交互体验的关键技术之一。以下是完整的流式处理流程图:
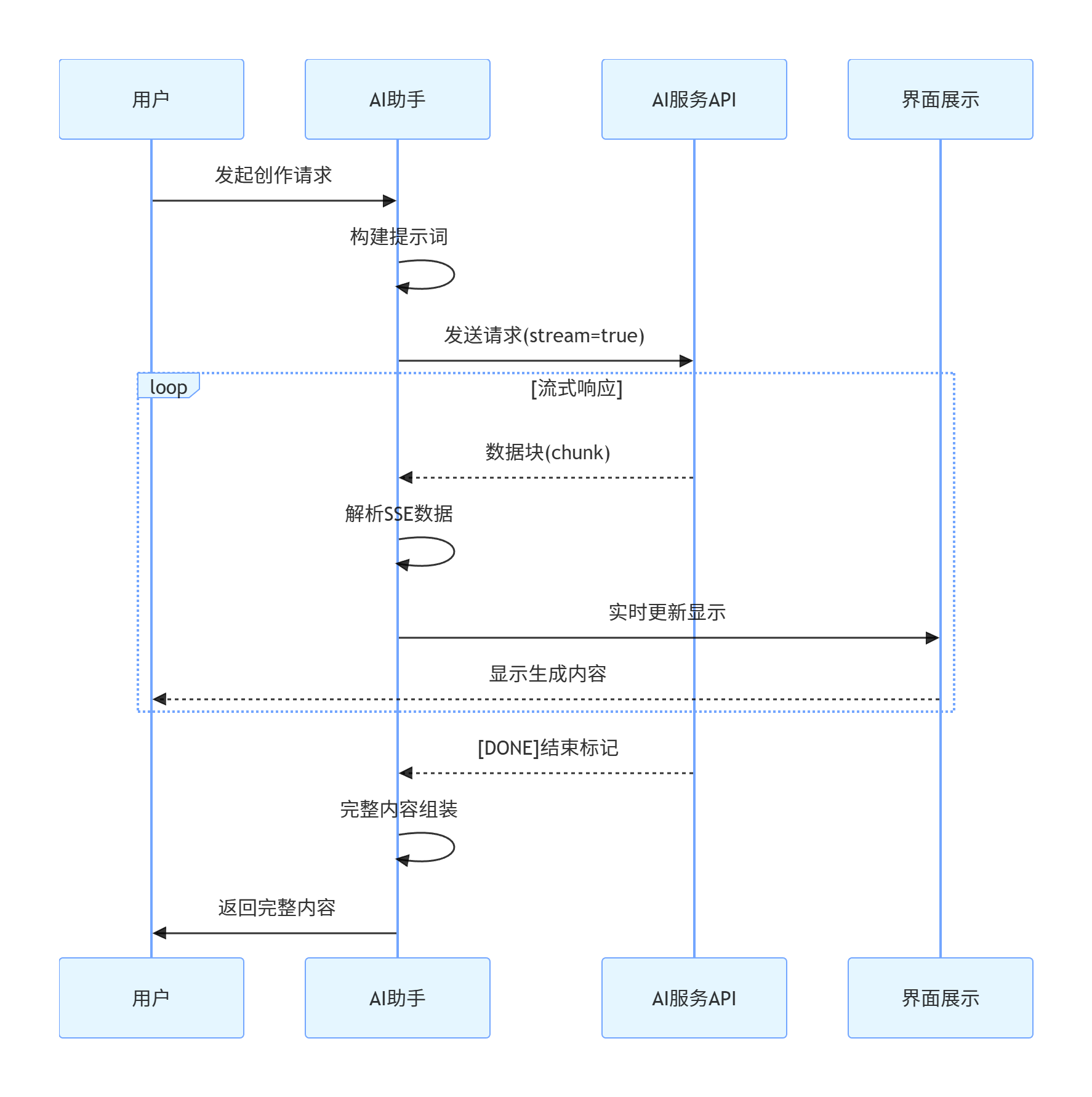
3.1 SSE数据解析器
python
class SSEParser:
"""Server-Sent Events数据解析器"""
@staticmethod
def parse_line(line: str) -> Optional[dict]:
"""解析单行SSE数据"""
if not line or line.strip() == "":
return None
if line.startswith('data: '):
data = line[6:].strip()
if data == '[DONE]':
return {'type': 'done'}
try:
return {'type': 'chunk', 'data': json.loads(data)}
except json.JSONDecodeError:
return {'type': 'error', 'message': f'Invalid JSON: {data}'}
if line.startswith('event: '):
return {'type': 'event', 'event': line[7:].strip()}
return None
@classmethod
def parse_stream(cls, stream) -> Generator[dict, None, None]:
"""解析完整的SSE流"""
buffer = ""
for chunk in stream.iter_lines():
if not chunk:
continue
buffer += chunk.decode('utf-8')
lines = buffer.split('\n')
buffer = lines.pop() # 保留最后一个不完整的行
for line in lines:
parsed = cls.parse_line(line)
if parsed:
yield parsed四、质量检测与内容优化
AI生成的内容需要经过质量检测才能投入使用。以下是完整的检测流程:
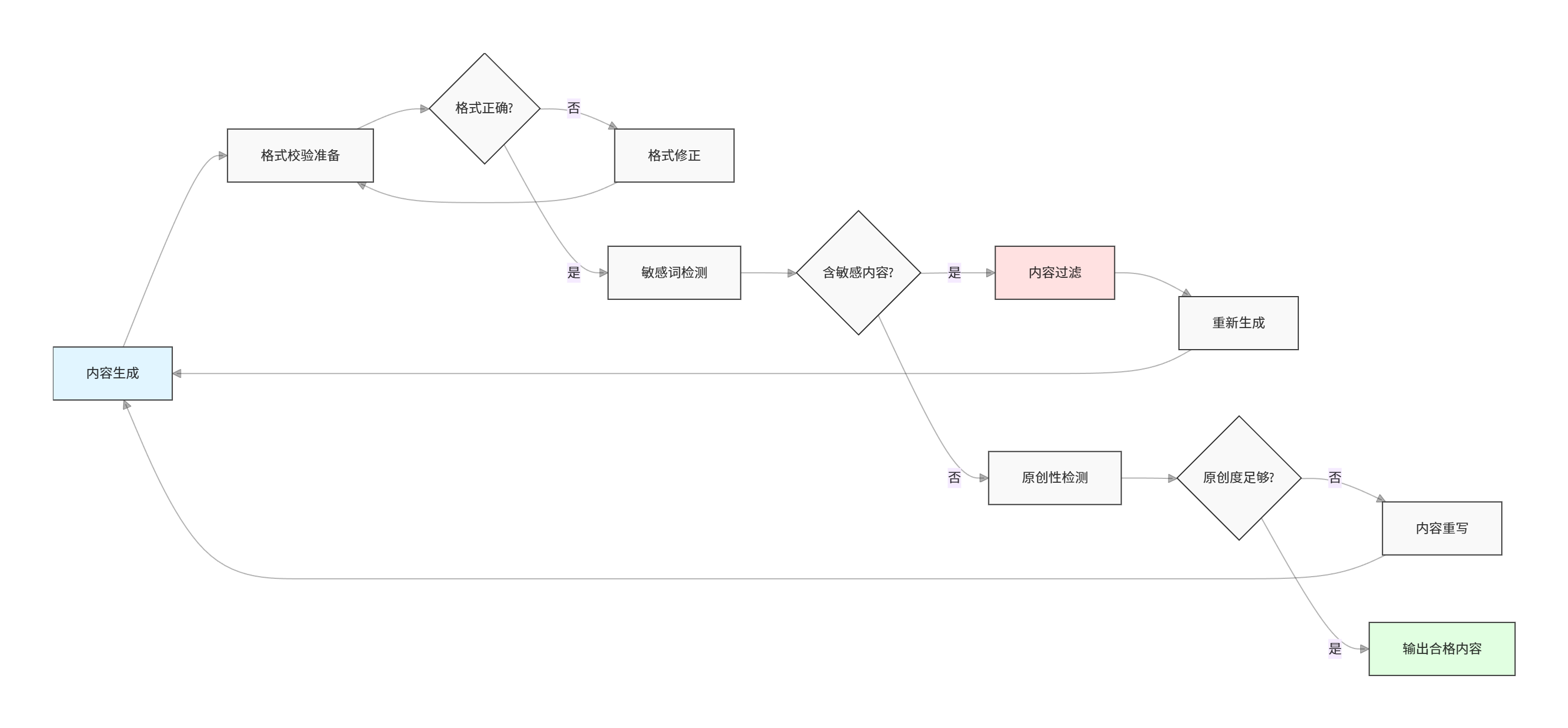
4.1 简易质量检测实现
python
import re
from typing import List, Tuple
class ContentQualityChecker:
"""内容质量检测器"""
def __init__(self):
# 敏感词库(示例)
self.sensitive_words = [
"暴力", "欺诈", "赌博", "色情"
# 实际应用中应使用更完整的词库
]
# 质量指标
self.min_length = 50
self.max_repetition_rate = 0.3
def check(self, content: str) -> Tuple[bool, List[str]]:
"""
检测内容质量
Returns:
(是否通过, 问题列表)
"""
issues = []
# 1. 长度检查
if len(content) < self.min_length:
issues.append(f"内容过短({len(content)}字符,至少需要{self.min_length}字符)")
# 2. 敏感词检查
found_sensitive = self._check_sensitive_words(content)
if found_sensitive:
issues.append(f"包含敏感词:{', '.join(found_sensitive)}")
# 3. 重复率检查
repetition_rate = self._check_repetition(content)
if repetition_rate > self.max_repetition_rate:
issues.append(f"重复率过高({repetition_rate:.1%},不超过{self.max_repetition_rate:.1%})")
# 4. 结构检查
if not self._has_proper_structure(content):
issues.append("内容结构不完整")
return len(issues) == 0, issues
def _check_sensitive_words(self, content: str) -> List[str]:
"""检查敏感词"""
found = []
for word in self.sensitive_words:
if word in content:
found.append(word)
return found
def _check_repetition(self, content: str) -> float:
"""计算内容重复率"""
sentences = re.split(r'[。!?]', content)
sentences = [s.strip() for s in sentences if s.strip()]
if len(sentences) < 2:
return 0
unique_sentences = set(sentences)
return 1 - len(unique_sentences) / len(sentences)
def _has_proper_structure(self, content: str) -> bool:
"""检查是否有基本结构"""
# 检查是否有标题
has_title = bool(re.search(r'^#{1,3}\s', content, re.MULTILINE))
# 检查是否有分段
has_paragraphs = content.count('\n\n') >= 1
return has_title or has_paragraphs
# 使用示例
checker = ContentQualityChecker()
# 检测AI生成的内容
test_content = """
# AI技术发展
人工智能正在快速发展。人工智能正在快速发展。
我们需要关注AI的伦理问题。
"""
passed, issues = checker.check(test_content)
if not passed:
print("❌ 质量检测未通过:")
for issue in issues:
print(f" - {issue}")
else:
print("✅ 内容质量检测通过")五、AI时代创作者的成长路径
技术的民主化正在重新定义创作的门槛。当每个人都能通过AI工具生成内容时,差异不再源于"能做什么",而源于"想做什么"和"如何选择"。
5.1 核心能力迁移模型
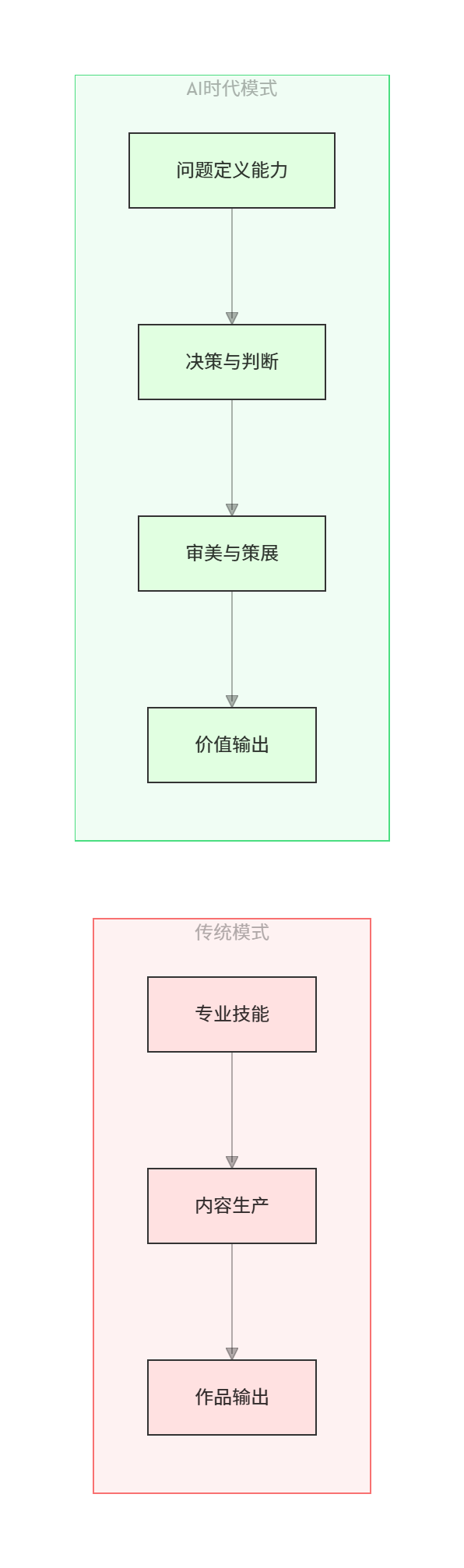
5.2 创作者需要的三大核心能力
| 能力维度 | 传统模式 | AI时代 | 关键差异 |
|---|---|---|---|
| 生产能力 | 手工创作,周期长 | AI辅助,快速产出 | 效率提升10-100倍 |
| 决策能力 | 经验驱动 | 数据+AI驱动 | 决策质量取决于认知深度 |
| 价值能力 | 隐形价值 | 显性化、可量化 | 需要主动构建影响力 |
六、与AI创作者社区共同成长
在技术快速迭代的今天,个人的认知积累速度往往落后于技术演进速度。这也是为什么参与高质量的技术社区变得尤为重要。
💡 推荐活动 :脉脉平台正在举办的 【AI创作者xAMA第二期】 活动值得关注。这是一个专为AI创作者和技术人设计的交流平台,提供了以下价值:
- 与超级创作者互动:向AI领域的头部创作者提问,获取第一手经验
- 实战经验分享:涵盖AI变现、内容创作、职业转型等核心议题
- 积分激励机制:参与讨论得积分,优质内容更有机会获得推荐
- 高质量人脉网络:连接行业专家、企业决策者和技术同行

参与方式 :在脉脉APP搜索话题 #AI创作者AMA知无不言# ,发布你的观点或问题。
这个活动的核心价值在于------它不是在教你怎么使用工具,而是在探讨 "AI时代,创作者应该成为什么样的人"。
七、完整项目结构
plain
ai-content-creator/
├── config/
│ ├── __init__.py
│ ├── settings.py # 配置管理
│ └── templates.json # 提示词模板库
├── core/
│ ├── __init__.py
│ ├── client.py # AI客户端
│ ├── parser.py # SSE解析器
│ └── quality.py # 质量检测
├── models/
│ ├── __init__.py
│ └── schemas.py # 数据模型
├── utils/
│ ├── __init__.py
│ ├── logger.py # 日志工具
│ └── cache.py # 缓存管理
├── examples/
│ ├── basic_usage.py # 基础使用示例
│ ├── advanced_usage.py # 高级用法
│ └── custom_template.py # 自定义模板
├── tests/
│ ├── test_client.py
│ ├── test_parser.py
│ └── test_quality.py
├── main.py # 入口文件
├── requirements.txt # 依赖清单
└── README.md # 项目文档八、总结与展望
AI技术正在重塑内容创作的每一个环节。从技术实现的角度看,我们需要掌握:
- 提示词工程:构建高质量的输入模板
- 流式处理:实现流畅的交互体验
- 质量检测:确保输出内容的可靠性
- 持续学习:跟进快速演进的技术栈
但从创作者发展的角度看,更重要的是:
- 从"怎么做"转向"做什么":技术执行门槛降低,决策判断能力变得稀缺
- 从"个人创作"转向"网络协作":单打独斗难以持续,需要融入高质量社区
- 从"技能积累"转向"认知升级":静态知识贬值速度加快,动态学习能力成为核心竞争力
AI时代最残酷的真相或许是:技术能力正在民主化,但思考深度、表达力与连接力正在成为新的稀缺资源。
参考资料:
📝 文章作者:我不是呆头
🔗 活动:脉脉AI创作者xAMA第二期
💬 参与讨论:#AI创作者AMA知无不言
✍️ 坚持用 清晰易懂的图解 + 可落地的代码,让每个知识点都 简单直观!
💡 座右铭 :"道路是曲折的,前途是光明的!"
