2026 年 1 月 29 日,阿里千问团队抛出了一枚语音识别领域的 "重磅开源炸弹"------Qwen3-ASR 系列模型。作为深耕语音技术的开发者,我第一时间研读了官方文档,发现这套模型不仅覆盖了多语种、方言等基础需求,更在复杂场景(如强噪声、歌唱)和效率(高并发吞吐)上实现了突破,甚至自带 "语音强制对齐" 这一实用功能。今天就带大家全方位拆解这套开源模型的价值。
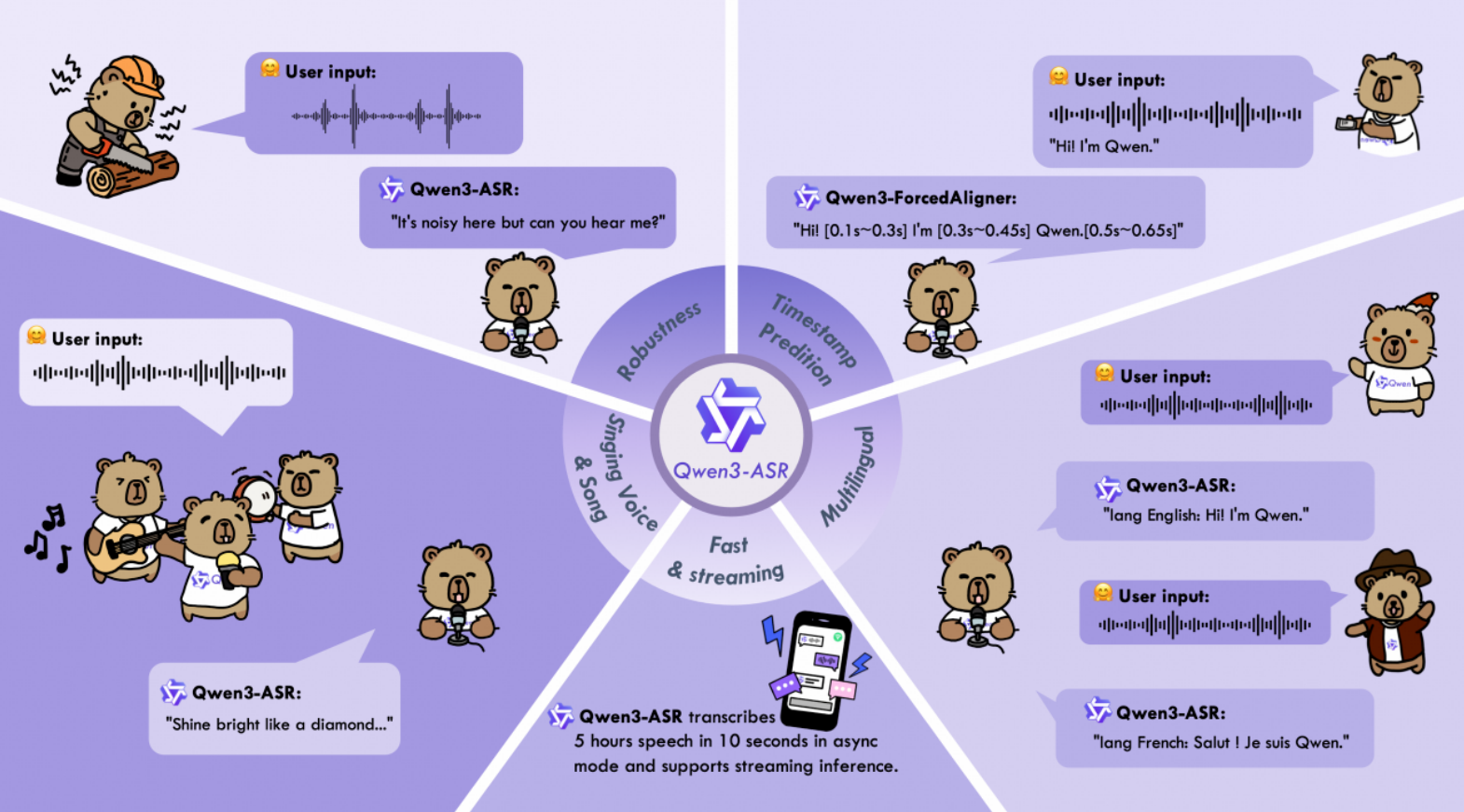
一、先搞懂:Qwen3-ASR 是个 "模型家族",三剑客各司其职
和单一模型不同,Qwen3-ASR 直接开源了三个功能互补的模型,覆盖从 "高精度识别" 到 "高效部署" 再到 "时间戳对齐" 的全需求,开发者可以按需选择,不用再为 "性能 vs 效率" 纠结。
1. 旗舰款:Qwen3-ASR-1.7B------ 追求极致精准的 "全能选手"
-
定位 :高性能语音识别主力,适合对准确率要求高的场景(如专业转录、方言识别)。
-
核心能力:
-
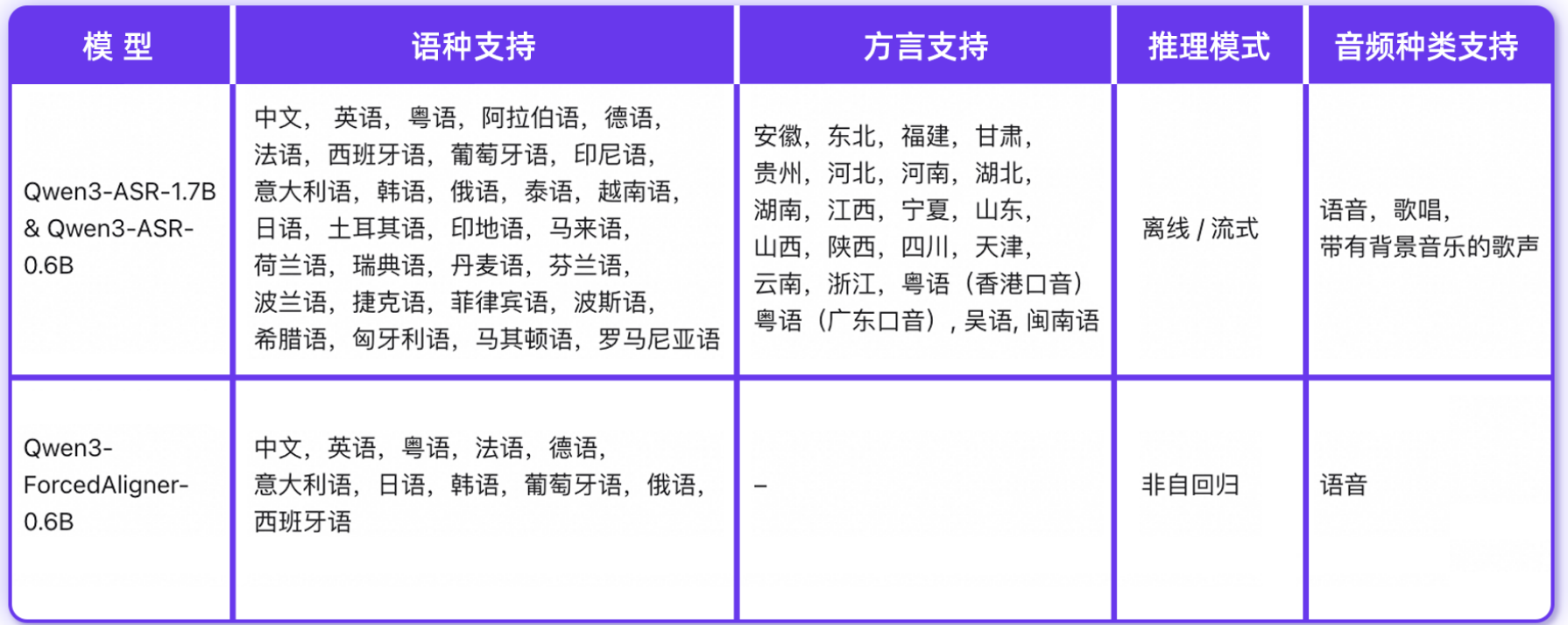
支持52 种语种与方言:不仅包含中、英、法、德等 30 种主流语言,还覆盖 22 种中文方言(安徽、东北、福建、粤语等,甚至区分香港 / 广东口音),以及多国家英文口音(如印度、澳洲口音)。
-
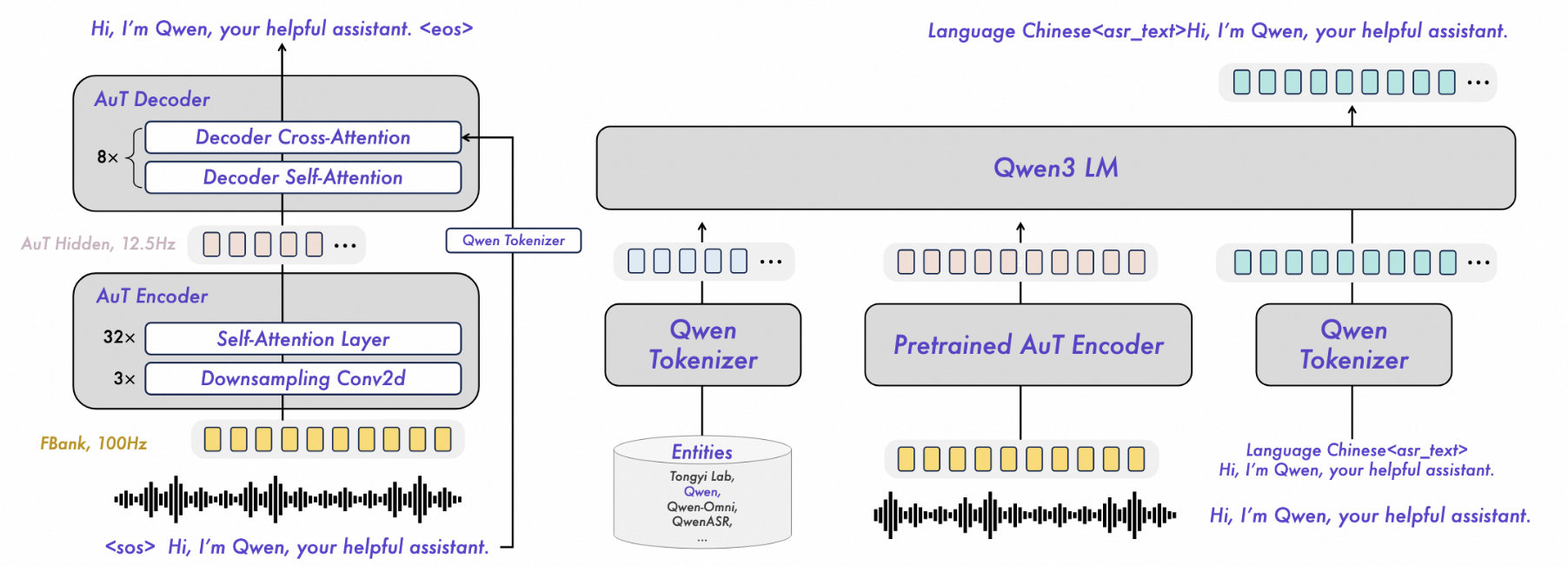
复杂场景 "稳如老狗":依托自研的AuT 语音编码器和 Qwen3-Omni 多模态基座,在强噪声(如菜市场、工地)、低信噪比、老人 / 儿童语音、甚至 "鬼畜重复" 的极端场景下,仍能保持极低的字错误率(CER)。
-
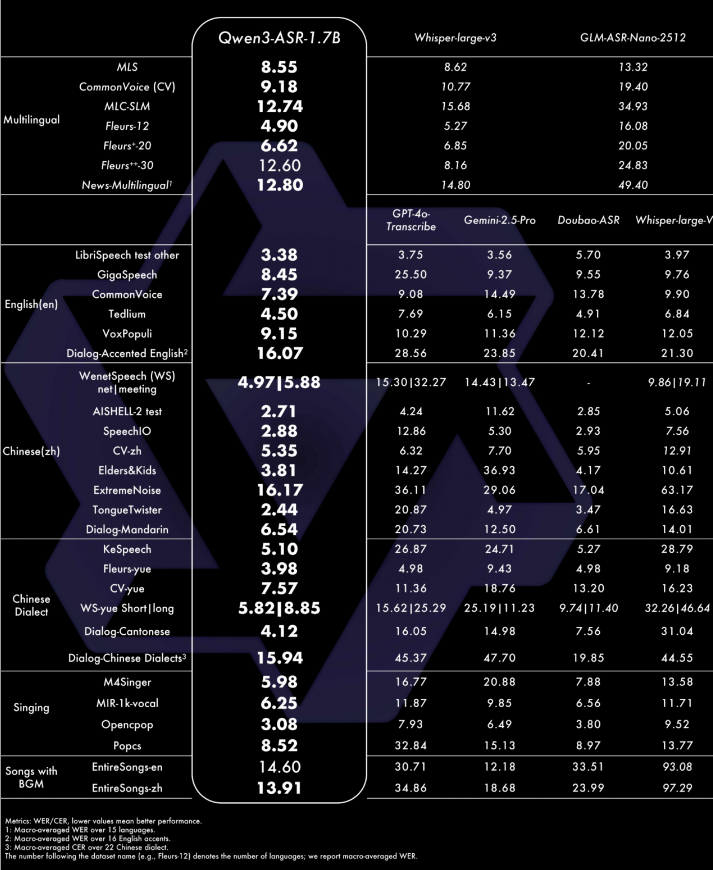
歌唱识别 "拿捏了":支持带背景音乐的整首歌曲转写,中文歌唱 WER(词错误率)低至 13.91%,英文 14.60%------ 要知道传统模型面对 BGM 早就 "听不清" 了。
-
-
性能天花板:在中文方言识别上,比主流商用 API(如 Doubao-ASR)平均错误率再降 20%;英文场景更 "能打",在覆盖 16 个国家口音的测试集上,全面优于 GPT-4o Transcribe、Gemini 系列和 Whisper-large-v3(当前开源领域标杆)。
2. 轻量款:Qwen3-ASR-0.6B------ 效率优先的 "速度选手"
-
定位 :平衡性能与资源消耗,适合高并发、端侧部署(如智能硬件、大规模云服务)。
-
核心优势:
-
高并发下 "起飞":128 并发异步服务推理时,吞吐能力达到2000 倍------ 简单说,10 秒钟能处理 5 小时以上的音频,这对需要批量处理录音的场景(如客服质检、会议归档)太友好了。
-
低延迟不卡顿:单并发推理时,实时因子(RTF)低于 0.01(RTF 越小越快),1 秒能转写约 2 分钟音频;同时支持流式 / 非流式一体化推理,最长可一次性处理 20 分钟音频(不用切分文件)。
-
-
适用场景:AI 音箱、智能手表等端侧设备(资源有限),或需要同时处理上千路音频的云服务(如直播平台实时字幕)。
3. 特色款:Qwen3-ForcedAligner-0.6B------ 精准到毫秒的 "时间戳大师"
-
定位:语音强制对齐工具,解决 "音频对应文字位置" 的需求(如字幕生成、语音标注)。
-
突破点:
-
基于非自回归 LLM 推理(传统模型多是自回归,慢且不准),支持 11 种语种的任意位置时间戳预测,精度超越 WhisperX、Nemo-Forced-Aligner 等主流工具。
-
快到 "离谱":单并发推理 RTF 低至 0.0089,5 分钟内的音频能瞬间完成对齐 ------ 比如一句话里 "Hi" 对应 0.1\++0.3 秒,"Qwen" 对应 0.5\++0.65 秒,精准到毫秒级。
-
二、核心亮点:为什么 Qwen3-ASR 能 "出圈"?
看完模型参数,更值得关注的是这套方案的 "差异化优势"------ 很多细节都是开发者实际落地时的 "痛点杀手"。
1. "All-in-one" 单模型搞定所有:不用来回切换模型
传统语音识别需要:"语种检测模型→对应语言识别模型→时间戳模型",而 Qwen3-ASR 的 1.7B/0.6B 单模型就能同时搞定 "语种识别 + 语音转录",配合强制对齐模型,一套组合拳覆盖全流程 ------ 减少部署复杂度,还能避免模型切换带来的延迟。
2. 声学鲁棒性拉满:不怕 "嘈杂环境" 的真实场景
官方特意强调了 "复杂声学环境" 的表现:比如在 "背景噪声比人声还大" 的场景(如演唱会后排),Qwen3-ASR-1.7B 的 WER 仍能控制在 16% 以内,而传统模型早就突破 50% 了;甚至 "语速快到嘴瓢" 的饶舌 RAP,也能准确转写(比如 "蹦出来之后,左手、右手接一个慢动作" 这种连续动作描述)。
3. 开源生态 "拎包即用":降低开发者门槛
阿里这次不仅开源了模型权重,还配套了全面的推理框架:
-
支持基于 vLLM 的批量推理(提高效率)、异步服务(应对高并发)、流式推理(实时场景)、时间戳预测(字幕生成)。
-
多平台可获取:GitHub(https://github.com/QwenLM/Qwen3-ASR)、HuggingFace、ModelScope(魔搭社区)均有托管,还提供在线 Demo(HuggingFace Spaces、ModelScope Studios)------ 不用下载模型,浏览器里传个音频就能试效果。
-
license 友好:基础功能基于 GPL 开源,商用可申请试用 license(15 分钟试用 / 1 个月长试用),对中小企业和个人开发者很友好。
三、谁该用?典型场景落地建议
Qwen3-ASR 的灵活性让它几乎能覆盖所有语音识别需求,这里列举几个高频场景:
|---------------|------|----------------------------------------|
| 场景 | 推荐模型 | 核心价值 |
| 多语言会议记录 | 1.7B | 自动识别参会者语种(如中英混说),生成多语言字幕,支持方言(如粤语参会者)。 |
| 直播 / 短视频字幕 | 0.6B | 高并发下实时生成字幕,覆盖多语种观众,10 秒处理 5 小时历史回放。 |
| 智能客服质检 | 0.6B | 批量处理上千路客服通话,快速提取关键信息(如客户投诉、坐席话术问题)。 |
| 方言文化保护 | 1.7B | 精准转录方言语音(如闽南语、吴语),助力方言数据归档与研究。 |
| 音乐歌词转写 | 1.7B | 带 BGM 的整首歌曲转写,适合音乐平台、K 歌 APP 生成歌词。 |
| 智能硬件(音箱 / 手表) | 0.6B | 端侧部署资源占用低,实时响应语音指令(如 "播放粤语新闻")。 |
四、快速上手:3 步体验 Qwen3-ASR
如果你想立刻试试效果,推荐先从在线 Demo 开始:
-
打开 HuggingFace Demo:https://huggingface.co/spaces/Qwen/Qwen3-ASR(或 ModelScope Demo:https://modelscope.cn/studios/Qwen/Qwen3-ASR)。
-
上传音频文件(支持常见格式,如 MP3、WAV),或直接录制语音(比如用方言说一句话)。
-
点击 "识别",等待几秒就能看到结果 ------ 还能选择是否显示时间戳(需勾选强制对齐功能)。
如果需要部署到自己的项目,可直接从 GitHub 克隆代码:
bash
# 克隆仓库
git clone https://github.com/QwenLM/Qwen3-ASR.git
# 安装依赖
pip install -r requirements.txt
# 运行推理示例(参考官方文档)
python inference.py --model_path Qwen/Qwen3-ASR-0.6B --audio_path your_audio.wav五、总结:开源语音识别的 "新里程碑"
Qwen3-ASR 的开源,给语音识别领域带来了两个关键价值:
-
打破 "精度 vs 效率" 的两难:1.7B 满足专业需求,0.6B 适配高并发 / 端侧,开发者不用再 "二选一";
-
降低多场景落地门槛:从方言到歌声,从实时流到批量处理,一套方案覆盖几乎所有需求,尤其对中小企业和个人开发者来说,不用再投入巨资研发模型。
如果你正在做语音相关的项目,无论是需要精准转录的工具,还是高并发的云服务,Qwen3-ASR 都值得一试 ------ 毕竟这是当前开源领域少有的 "既能打又好用" 的语音识别方案。
原文链接
https://mp.weixin.qq.com/s/gE0D-oKWQuES31FVriFDrg
END
如果觉得这份基础知识点总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多有关开发问题的干货技巧,同时一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟