常用的Mysql与Redis缓存方案:延迟双删
业务代码
读:读取缓存,命中直接返回;不命中,读取数据库,读取到回写缓存
写:删除缓存,写数据库,延迟删除缓存
延迟双删的核心问题:
| 问题 | 严重程度 | 影响 |
|---|---|---|
| 延迟时间难以确定 | 🔴 高 | 仍可能产生脏数据 |
| 第二次删除失败无感知 | 🔴 高 | 缓存不一致 |
| 进程重启丢失 | 🟠 中 | 缓存残留脏数据 |
| 资源开销 | 🟡 低 | 性能下降(耦合:在业务逻辑中增加该逻辑,加剧RPC接口耗时) |
| 与事务不兼容 | 🟠 中 | 业务逻辑复杂 |
解决方案:高一致性要求、解耦:使用Canal订阅Binlog更新缓存
Canal订阅Binlog的主要坑:
| 问题类型 | 严重程度 | 解决 | |
|---|---|---|---|
| 顺序问题 | 1. Canal接入的kafka如果是多分区,同一个ID会路由到不同的分区,消费者处理顺序会乱 2. 即使是单分区单消费者,如果消费者程序开启了go并发处理,也可能会乱序 | 🔴 高 | 性能高 + 不乱序 1. 性能高:kafka还是使用消费者组的多分区,但是生产者按照hash(id)选择分区,确保相同的id永远路由到一个分区(一个分区在同一个时刻只能被一个消费者处理,就能保证一个id只能被一个消费者处理) 2. 不乱序:消费者不开启go并发处理 |
| Canal故障 | 1. Canal单点故障 2. Canal重启期间的Binlog丢失或延迟消费 3. 缓存中的脏数据可能长期存在 | 🟡 低 | |
| DDL变更 | DDL变更需要重启Canal或重新配置 字段类型变更可能导致解析错误 重命名表/字段需要修改Canal配置 | 🟡 低 | 低(运维规范) |
| 业务逻辑 | 细节 |
| 写 | 创建、更新、删除:都是只操作mysql,不操作缓存(不删除Redis、也不更新Redis) |
| 读 | Redis ==> Mysql ==> 更新Redis(和市面上老的流程一样) 为什么读流程还要保留更新缓存逻辑?是为了防止Canal挂了,那么Redis就永远没有最新的缓存数据了!因此,还要保留该逻辑,相当于给Canal挂了做了一个兜底。 查询Redis成功 1. 查询到:直接返回 2. 查询不到:降级查询Mysql,然后更新Redis |
| Canal | 删除:直接删除 创建、更新:更新Redis |
|---|
上面【更新Redis】的操作,是升级的版本,因为Canal和读流程中都会更新Redis,这里要处理并发问题!
缓存数据结构
Go
// 缓存数据结构
type CachedData struct {
Data interface{} `json:"data"` // 实际业务数据
UpdatedAt time.Time `json:"updated_at"` // 数据更新时间
BinlogFile string `json:"binlog_file"` // Binlog文件名
BinlogPos int64 `json:"binlog_pos"` // Binlog位置
CachedAt time.Time `json:"cached_at"` // 缓存写入时间
Source string `json:"source"` // 数据来源: "canal" or "read"
}| 优先级类型 | 具体类型 | 【更新Redis】原则 |
| 缓存来源Source | 读操作Read Canal | 只能Canal覆盖Read,反之不可以 |
| 时间戳 | | 只能新的时间戳覆盖老的 |
| Binlog位置 | 只能新的位置覆盖老的 |
|---|
| 代码逻辑 | 解释 |
| 业务读 | 只能Canal覆盖Read,反之不可以 优先级:Source > timestamp 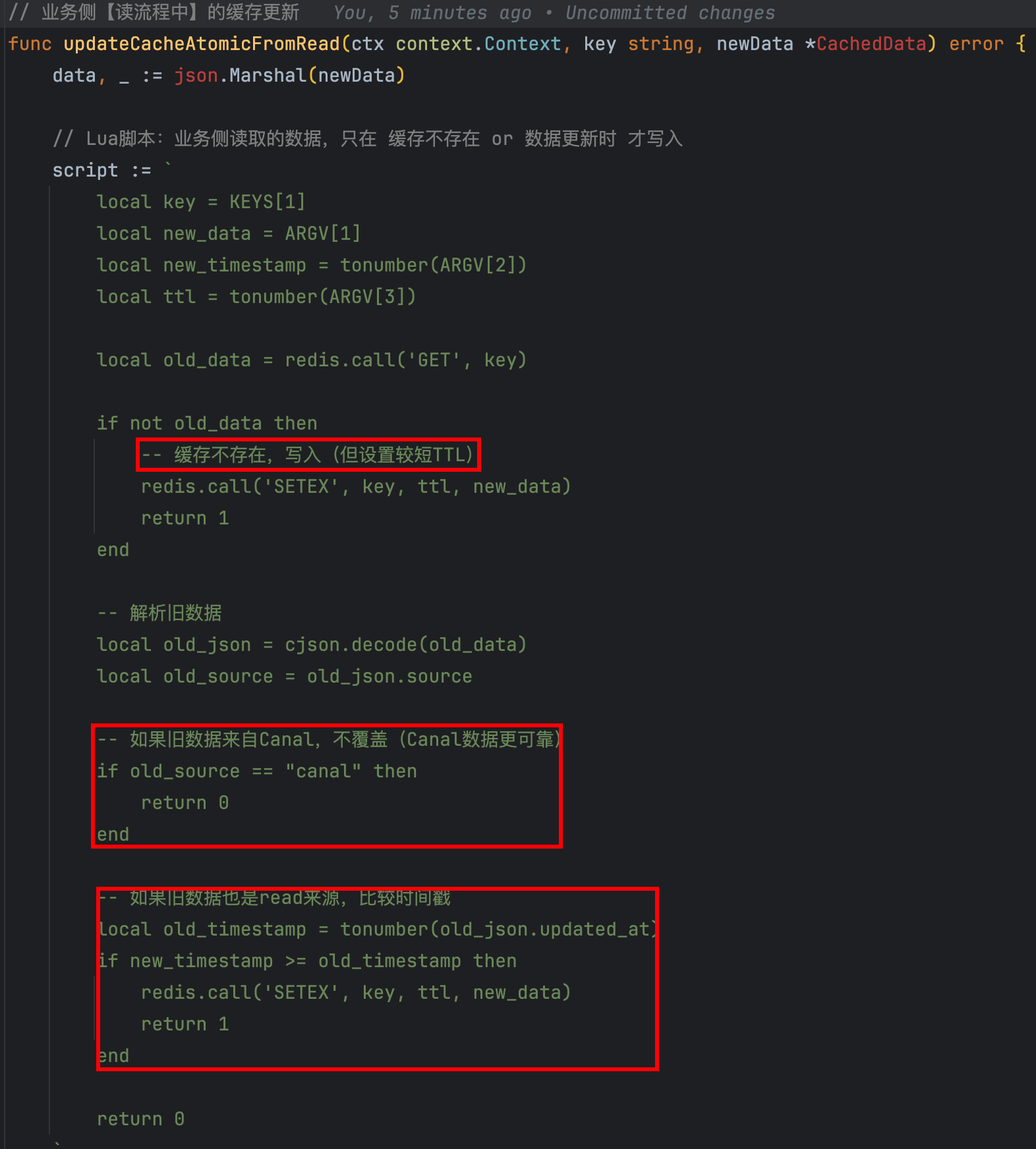 |
|
| Canal处理事件 | 优先级:Source > timestamp > Binlog 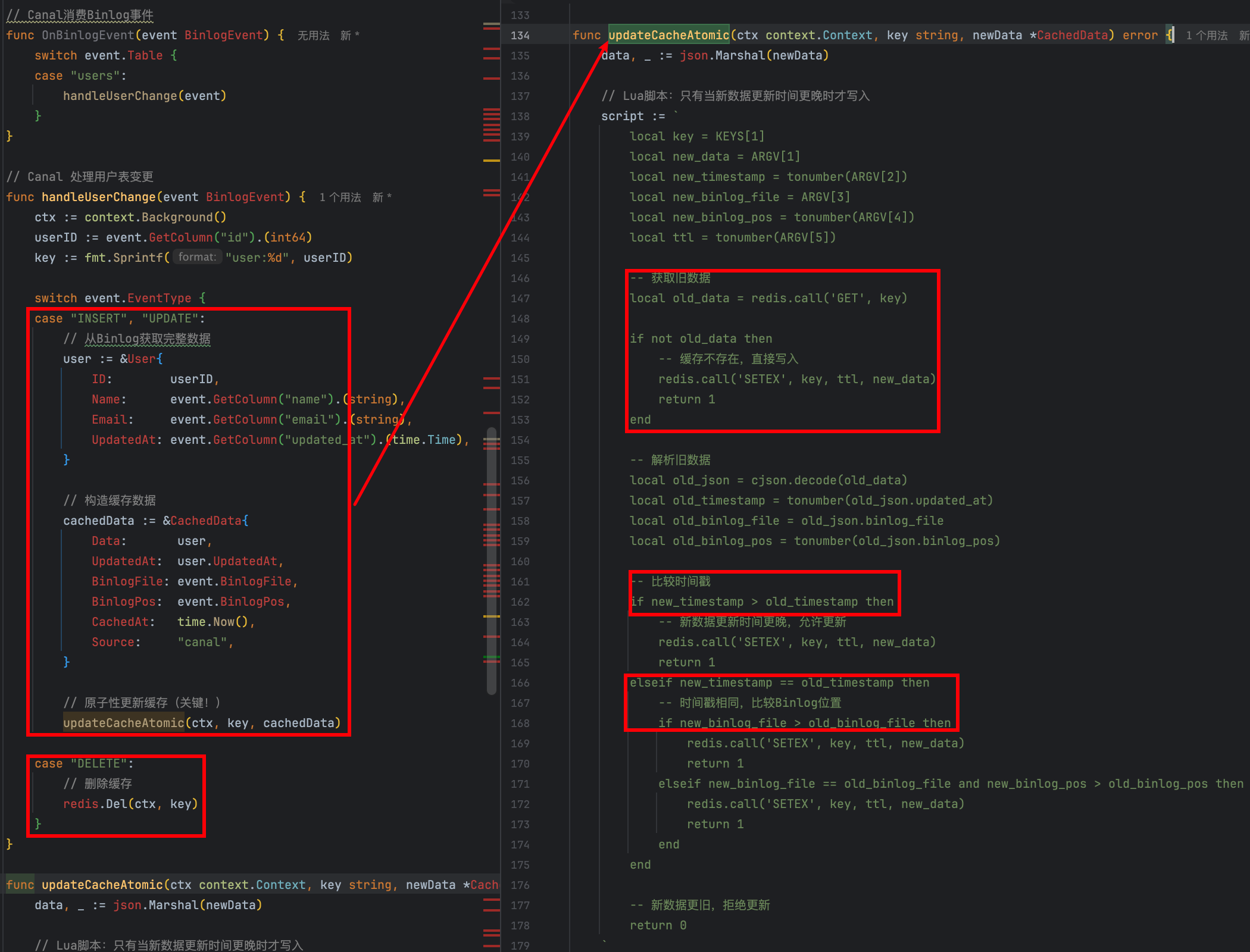 |
|---|