大家好,我是Java烘焙师。本文结合笔者的经验和思考,对灰度方案做个总结,重点介绍AB实验。
灰度在开发流程中非常普遍。先做小流量验证,确认无误后再推全,灰度过程中一旦发现系统异常、或业务指标异常,应立刻回滚。
灰度场景
- 代码灰度:是最典型的灰度,灰度内做新逻辑,灰度外做旧逻辑
- 既可以提供v2版本新接口给调用方服务,由调用方来做灰度切换
- 也可以内部切灰度,做到调用方无感
- 发版灰度:上线过程中,新版本服务实例不断增加,需考虑兼容新旧协议
- 配置灰度:修改配置时,按服务实例灰度推送配置变更
灰度模式
- 数字id尾号灰度:取id最后2位(百分比)、最后3位(千分比)、最后4位(万分比)等
- 实现方式:id取模,例如
id % 100 < 灰度百分比,则命中灰度 - 特点:简单,适用于绝大部分技术优化场景
- 实现方式:id取模,例如
- 随机灰度:取一部分随机流量做灰度
- 实现方式:
ThreadLocalRandom.current().nextInt(100) < 灰度百分比 - 之所以使用ThreadLocalRandom、而不是Random,是为了避免多线程竞争用于生成随机数的seed
- 实现方式:
- A/B实验
- 实现方式:分层实验、实验数据收集、离线统计
- 特点:适用于小流量验证新业务功能的效果,整体方案相对复杂,需要技术基建
id选取
- 业务id:如用户id、商品id等
- 设备id:未注册/未登录用户,此时没有用户id,只能取设备的唯一标识
下面重点介绍一下A/B实验。
A/B实验
目的
- 小流量验证新业务功能,正向显著则推至全量,否则继续迭代优化、或下线,避免功能过于臃肿
- 用数据作为依据,避免想当然、拍脑袋决策
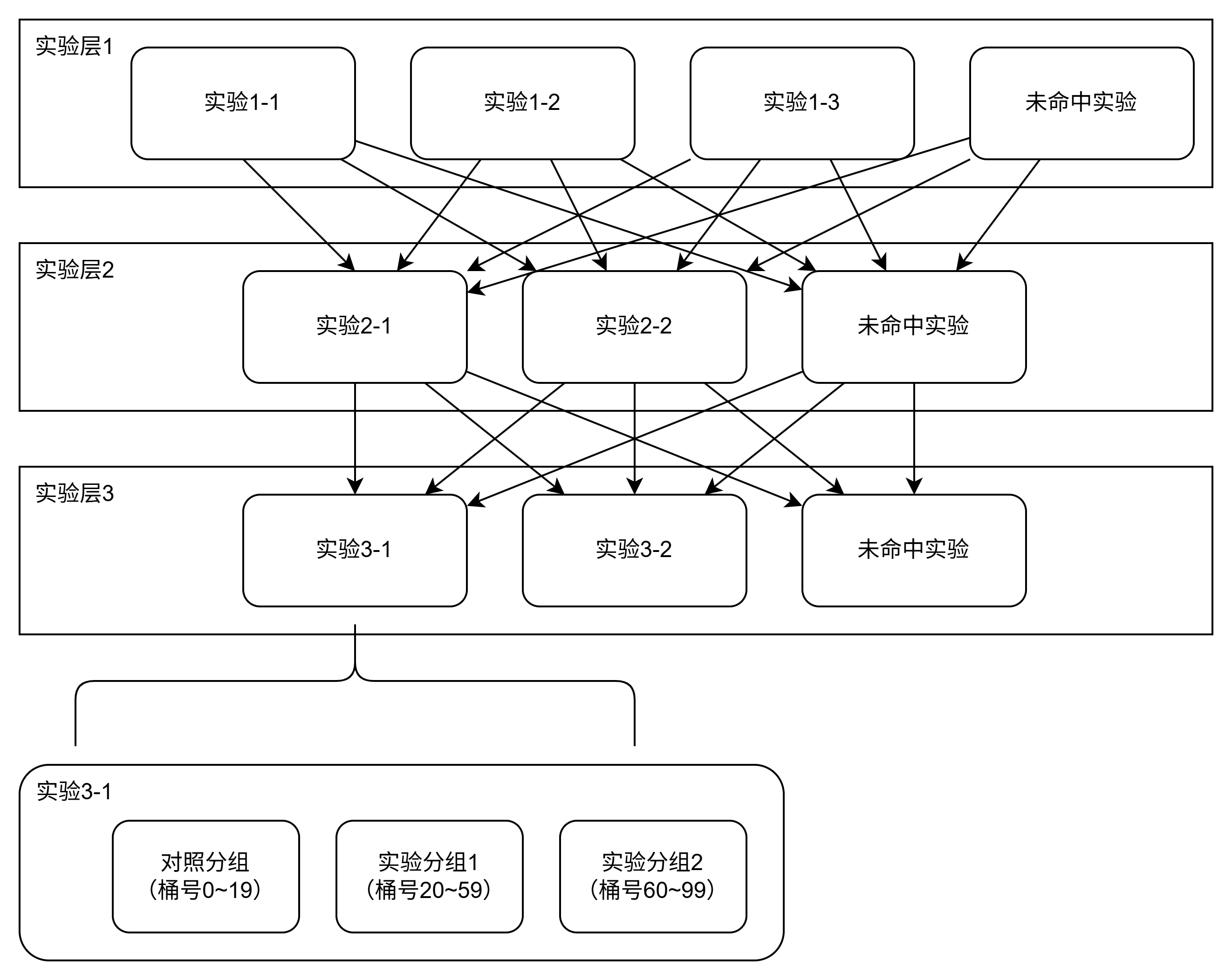
分层实验
主要目的是为了同时做多个实验,而不是给每个实验均分一部分流量。因为当同时进行的实验变多时,组合数量成倍增加,每个实验分到的流量就很少了。
有这几层结构:实验层、实验、分组
- 实验层之间正交,可同时进行多个实验层的实验
- 同一实验层的实验之间互斥,比如命中了实验1-1,就不会命中实验1-2。实验持有0到多个分桶,根据业务id可计算出桶号,进而知道命中哪个实验
- 同一实验内有多个分组,包括1个对照组,和1到多个实验组,只会命中其中一个分组。分组持有0到多个分桶,根据业务id可计算出桶号,进而知道命中哪个分组
实验层、实验举例:
- 展示实验层:根据页面进行划分,如首页、搜索页、推荐页、详情页等。每个页面作为一个实验层,每个实验层里可同时做多个展示实验
- 算法实验层:根据场景进行划分,如相似推荐、搭配购推荐、个性化推荐、搜索排序、广告排序等。每个场景作为一个实验层,每个实验层里可同时做多个算法实验
哈希算法打散
要同时支持多个分层实验,核心在于通过哈希算法将每一层的流量打散,用于实现"均匀分流"和"层间正交",使得流量在各个实验的效果正负抵消,才能得到真实的对比结果。
以下是计算实验层桶号的代码示例,实验桶号同理:
java
import com.google.common.hash.Hashing;
import java.nio.charset.StandardCharsets;
public class ABTestRouter {
/**
* 根据用户ID和实验层ID(实验层ID充当盐的角色),计算桶号 (0-99)
*/
public static int getBucket(String userId, String layerId) {
// 1. 拼接 Key: "layerId:userId"
String key = layerId + ":" + userId;
// 2. 使用 MurmurHash3 (32-bit)
// Guava 的 murmur3_32_fixed 是线程安全的
int hash = Hashing.murmur3_32_fixed()
.hashString(key, StandardCharsets.UTF_8)
.asInt();
// 3. 取模并确保结果为正数
// Math.abs(Integer.MIN_VALUE) 会返回负数,所以推荐使用位运算去除符号位
return (hash & Integer.MAX_VALUE) % 100;
}
public static void main(String[] args) {
String uid = "user_123456";
// 不同层的流量是正交的(打散重新分配)
System.out.println("展示层桶号: " + getBucket(uid, "layer_ui"));
System.out.println("算法层桶号: " + getBucket(uid, "layer_algo"));
}
}之所以用murmurhash,而非md5,是因为md5是加密算法,计算开销更大,在AB实验中仅需均匀打散即可,无需担心根据哈希结果反推原文。
之所以把实验层id作为盐,是因为微小的输入差异都会导致哈希结果相差巨大,实现打散的效果。
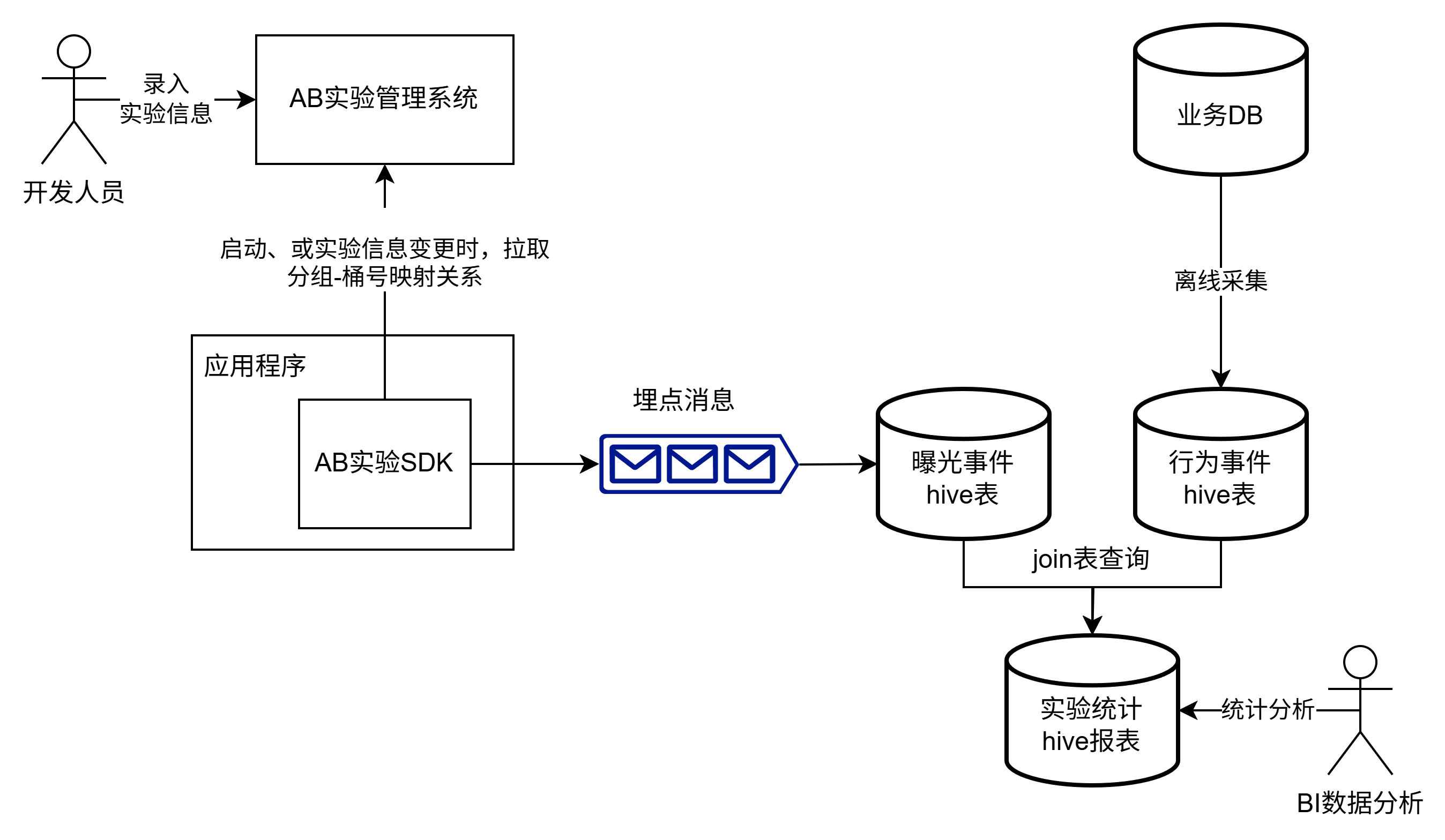
实验数据收集
实验数据收集流程如下:
- 在AB实验管理系统中配置实验信息:如实验盐值、桶号与实验组的映射关系等,可动态修改
- 代码逻辑开发:
- 引入实验sdk,sdk在启动、或配置变更时拉取实验信息,本地计算业务id的桶号,进而得到命中的分组
- 对照组做当前逻辑,实验组1做逻辑1,实验组2做逻辑2
- 在正式开始AB实验之前,先做AA分桶实验,模拟实验组、对照组的结果,判断是否均匀,避免分桶不均匀带来错误的实验结果
- 实验开始,后端埋点:sdk发出后端埋点消息
- 消息格式举例:
业务id, 实验层id, 实验id, 分组id, 桶号, 触发时间
- 消息格式举例:
- 实验过程:实验持续时间至少一周,覆盖工作日、周末/假期,避免受时间周期带来的波动影响
- 离线统计实验效果:
- 后端埋点数据导入曝光事件hive表
- 业务DB数据导入行为事件hive表,如注册、登录、浏览、点击、收藏、加购、下单、支付等,取决于实验关注的业务指标
- 把曝光事件、行为事件join起来,对比实验组、对照组的业务指标差异
以下是sql示例,代表从实验曝光后24小时内各个分组的转化率对比。
sql
SELECT
e.group_id,
COUNT(DISTINCT e.user_id) as exposed_users,
COUNT(DISTINCT a.user_id) as converted_users,
COUNT(DISTINCT a.user_id) / COUNT(DISTINCT e.user_id) as conversion_rate
FROM exposure_events e
LEFT JOIN action_events a ON e.user_id = a.user_id
AND a.event_time BETWEEN e.event_time AND (e.event_time + INTERVAL 24 HOUR)
WHERE e.experiment_id = 'ui_test_001'
GROUP BY e.group_id;实验报表分析
评估实验结果是否正向、是否显著。了解统计学里的核心概念,能看懂实验报表即可。
p值
用来衡量实验结果是否显著,p值的含义是:假设实验组与对照组没有区别,此时观察到实验有差异的概率。一般要求 p < 0.05,也就是说实验结果显著的概率大于95%(1 - 0.05 = 95%)
置信区间
在显著的前提下,用来衡量实验结果是否正向,代表业务指标的可能范围分布。
比如:实验结果里业务指标提升了1%,95%置信区间在0.8%, 1.2%,则代表有95%的把握可以把业务指标提升至少0.8%、至多1.2%,效果正向。如果置信区间的下界是负数,就有可能是负向效果了,需要警惕。
以上就是灰度方案的总结了,欢迎讨论交流。