在科技作图中,单一配色仅能满足基础分组对比需求,而面对连续型梯度数据、多维度关联数据、数值分布数据(如热力图、等高线图、散点密度图、地理空间数据)时,需要通过颜色映射(Colormap,简称 cmap) 将数值大小转化为渐变的色彩层次,实现 "数值量化→视觉具象" 的精准转换。Matplotlib 内置丰富的颜色映射体系,是科研中展示数据分布、梯度变化、相关性强弱的核心工具,广泛应用于基因组学、气象学、材料科学、机器学习等领域的可视化场景。
一、科研级颜色映射的核心认知与分类选型
1. 颜色映射的科研价值
颜色映射并非简单的 "色彩装饰",而是科技作图中量化展示连续数据的关键手段,其核心价值体现在三方面:一是将抽象的数值大小转化为直观的色彩深浅 / 冷暖,让读者快速捕捉数据的梯度变化、极值分布与区域关联;二是提升高维数据的信息密度,在单张图表中呈现多维度数值分布(如相关性热力图、基因表达量热图);三是符合学术定量展示要求,相比单一配色,颜色映射能更精准地反映数据的连续变化特征,是国际期刊中高维数据可视化的标准形式。
2. Matplotlib 颜色映射的三大核心分类
Matplotlib 将颜色映射分为顺序型、发散型、定性型三大类,各类别适配不同的科研数据场景,无优劣之分,核心是与数据特征精准匹配,这是颜色映射选型的根本原则。
-
顺序型(Sequential):单一色调随数值增大呈现从浅到深 / 从暗到亮的渐变,适配非负连续型数据,重点展示数值的 "大小梯度" 与 "分布趋势",如基因表达量、温度分布、误差值、相关性系数(0~1)等;
-
发散型(Diverging):以中间色(多为白色 / 浅灰色)为分界,向两侧呈现两种对比色调的渐变,适配有中心基准的连续型数据,重点展示数值 "偏离基准的程度与方向",如相关性系数(-1~1)、数据偏差值、温度异常值、基因表达差异(上调 / 下调)等;
-
定性型(Qualitative):无渐变规律,由多种高区分度的离散颜色组成,本质是 "多类别配色方案",非严格意义上的颜色映射,仅用于离散类别与连续数值的结合场景(如带类别标注的密度散点图),前文分组可视化已详细讲解,本文不做重点。
3. 科研优选颜色映射与选型原则
Matplotlib 内置超 80 种颜色映射,科研中无需追求小众配色,优先选择期刊推荐、色觉友好、无视觉误导的经典配色,避免使用易导致色觉混淆的映射(如默认的jet,存在色彩断层与亮度不均问题)。
(1)科研常用优选配色
-
顺序型:viridis(万能优选,色觉友好,亮度随数值同步提升)、plasma(暖色调渐变)、Blues/Greens/Oranges(单色调渐变,适配单组数据);
-
发散型:RdBu(红 - 蓝渐变,科研最常用,适配正负偏差 / 相关性)、coolwarm(冷 - 暖渐变,视觉对比鲜明)、seismic(红 - 绿渐变,慎用,色弱人群易混淆)。
(2)核心选型原则
-
匹配数据特征:非负梯度选顺序型,有中心基准的正负数据选发散型;
-
色觉友好优先:优先选择viridis、RdBu等经优化的配色,避免红绿色盲敏感配色;
-
与图表类型适配:热力图优先单色调 / 经典渐变,散点密度图优先亮度渐变明显的配色;
-
同一研究统一:同一篇论文中,同类型数据使用相同的颜色映射,避免读者认知混乱。
二、基础实战 1:热力图与颜色条(Colorbar)核心配置
热力图(Heatmap)是颜色映射最经典的应用场景,通过二维网格的色彩渐变展示两个离散变量与一个连续变量的关联分布(如基因 × 样本的表达量、时间 × 浓度的反应速率、特征 × 特征的相关性系数),搭配颜色条(Colorbar) 实现 "色彩→数值" 的精准对应,是科研中高维数据可视化的基础形式。
Matplotlib 中通过imshow()绘制热力图,colorbar()配置颜色条,核心是把控颜色映射选型、数值归一化、颜色条标注规范三大要点。
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import pearsonr
# 加载系列统一科研标准化样式
def set_scientific_plot_style():
plt.rcParams.update({
'font.family': 'serif',
'font.serif': ['Times New Roman', 'DejaVu Serif'],
'font.sans-serif': ['SimHei', 'Arial Unicode MS'],
'axes.unicode_minus': False,
'font.size': 10,
'axes.titlesize': 12,
'axes.labelsize': 10,
'xtick.labelsize': 9,
'ytick.labelsize': 9,
'legend.fontsize': 9,
'axes.linewidth': 0.8,
'xtick.major.width': 0.8,
'ytick.major.width': 0.8,
'savefig.dpi': 300,
'savefig.facecolor': 'white'
})
set_scientific_plot_style()
# ===================== 1. 模拟科研数据(特征相关性矩阵) =====================
np.random.seed(42)
n_feat = 8 # 8个特征,生成8×8相关性矩阵
# 生成随机特征数据,模拟实验指标
feat_data = np.random.normal(0, 2, (100, n_feat)) # 100个样本×8个特征
# 计算皮尔逊相关性矩阵(-1~1,适配发散型颜色映射)
corr_mat = np.zeros((n_feat, n_feat))
for i in range(n_feat):
for j in range(n_feat):
corr_mat[i, j], _ = pearsonr(feat_data[:, i], feat_data[:, j])
# 特征名称(科研规范:清晰标注变量)
feat_names = [f'Feature {chr(65+i)}' for i in range(n_feat)]
# ===================== 2. 颜色映射与画布配置 =====================
fig, ax = plt.subplots(figsize=(3.94, 3.54)) # 单栏适配,接近正方形避免拉伸
# 选型:发散型RdBu,适配-1~1的相关性数据,cmap='RdBu_r'表示颜色反转(蓝→红对应-1→1)
cmap = 'RdBu_r'
# 数值范围:固定为-1~1,保证相关性展示的统一性
vmin, vmax = -1.0, 1.0
# ===================== 3. 绘制热力图 =====================
im = ax.imshow(
corr_mat,
cmap=cmap,
vmin=vmin,
vmax=vmax,
aspect='equal', # 网格为正方形,避免色彩拉伸误导
interpolation='none' # 无插值,保证原始数据的准确性,科研必选
)
# ===================== 4. 配置科研级颜色条(核心) =====================
# cbar:颜色条对象,shrink:缩放比例(适配图表尺寸),aspect:颜色条宽高比
cbar = fig.colorbar(
im,
ax=ax,
shrink=0.85,
aspect=20,
pad=0.05 # 颜色条与热力图的间距
)
# 颜色条标注:科研规范,含物理量+单位/说明
cbar.set_label('Pearson Correlation Coefficient', fontsize=9)
cbar.ax.tick_params(labelsize=8) # 颜色条刻度字号适配
# ===================== 5. 热力图标注与样式优化 =====================
# 设置坐标轴刻度与标签
ax.set_xticks(np.arange(n_feat))
ax.set_yticks(np.arange(n_feat))
ax.set_xticklabels(feat_names, rotation=45, ha='right') # 横轴标签旋转,避免重叠
ax.set_yticklabels(feat_names)
# 标题:明确展示内容与实验条件
ax.set_title('Feature Correlation Matrix with Colormap', fontsize=12)
# 移除多余边框,保持简洁
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
# ===================== 6. 期刊级导出 =====================
plt.tight_layout()
plt.savefig('colormap_heatmap.pdf', bbox_inches='tight', pad_inches=0.1)
plt.savefig('colormap_heatmap_300dpi.png', bbox_inches='tight', pad_inches=0.1)
plt.show()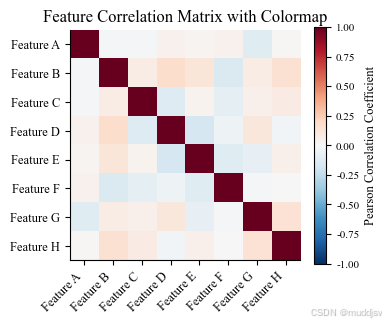
核心要点与参数解析
-
热力图核心参数:
-
interpolation='none':禁止色彩插值,保证每个网格的颜色严格对应数值,科研可视化必选,避免插值导致的数值失真与视觉误导;
-
aspect='equal':设置热力图网格为正方形,防止色彩拉伸改变视觉感受,适配多数科研场景;
-
vmin/vmax:固定颜色映射的数值范围,保证同类型数据可视化的对比基准统一,避免因数据范围不同导致的配色偏差。
-
-
颜色条(Colorbar)科研规范:
-
颜色条是颜色映射的 "定量标尺",不可省略,否则读者无法将色彩与数值对应;
-
通过shrink/aspect/pad精准控制尺寸与间距,避免过大遮挡图表或过小难以识别;
-
必须添加明确的标签,标注颜色对应的物理量、单位或数值含义(如 "Pearson Correlation Coefficient""Gene Expression (FPKM)"),刻度字号适配图表尺寸。
-
-
标注优化:横轴标签旋转(45°/60°)避免重叠,移除多余边框,保持科研图表的简洁性。
三、基础实战 2:散点图 + 颜色映射(梯度着色)
散点图结合颜色映射,可在二维散点分布的基础上叠加第三个连续变量的梯度信息(如散点的密度、样本的浓度、数据的置信度),实现 "二维分布 + 一维梯度" 的三维信息展示,是科研中展示多变量关联的常用形式,广泛应用于散点密度图、样本分布散点图、特征关联散点图等场景。
核心实现通过plt.scatter()的c参数传入连续数值、cmap指定颜色映射,搭配颜色条实现定量展示,核心是保证散点大小均匀、颜色梯度与数值匹配、无视觉遮挡。
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import gaussian_kde
set_scientific_plot_style()
# ===================== 1. 模拟科研数据(双变量+密度梯度) =====================
np.random.seed(42)
n_sample = 500 # 500个样本,保证分布的平滑性
# 生成双变量正态分布数据,模拟两个实验指标的关联
x = np.random.normal(5, 2, n_sample)
y = 1.2 * x + np.random.normal(0, 1.5, n_sample) + 2
# 计算散点密度(第三个连续变量,适配顺序型颜色映射)
xy = np.vstack([x, y])
density = gaussian_kde(xy)(xy) # 核密度估计,得到每个点的密度值
# ===================== 2. 画布与颜色映射配置 =====================
fig, ax = plt.subplots(figsize=(3.94, 2.76)) # 单栏适配
# 选型:顺序型viridis,万能优选,色觉友好,适配非负的密度值
cmap = 'viridis'
# 散点大小:统一设置s=30,避免大小干扰颜色梯度的视觉判断
s = 30
# ===================== 3. 绘制颜色映射散点图 =====================
scatter = ax.scatter(
x, y,
c=density, # 核心:传入连续数值,实现颜色梯度着色
cmap=cmap,
s=s,
alpha=0.8, # 透明度0.8,解决高密度区域的重叠遮挡问题
edgecolors='none' # 无轮廓,让颜色梯度更连贯
)
# ===================== 4. 配置颜色条 =====================
cbar = fig.colorbar(
scatter,
ax=ax,
shrink=0.8,
aspect=15,
pad=0.05
)
# 颜色条标注:明确密度含义
cbar.set_label('Sample Density', fontsize=9)
cbar.ax.tick_params(labelsize=8)
# ===================== 5. 样式优化与科研标注 =====================
ax.set_title('Scatter Plot with Density Colormap', fontsize=12)
ax.set_xlabel('Experimental Index X', fontsize=10)
ax.set_ylabel('Experimental Index Y', fontsize=10)
# 网格仅保留纵轴,减少视觉干扰
ax.grid(axis='y', alpha=0.2)
# 合理设置轴范围,避免散点紧贴边框
ax.set_xlim(0, 10)
ax.set_ylim(2, 14)
# ===================== 6. 导出 =====================
plt.tight_layout()
plt.savefig('colormap_scatter.pdf', bbox_inches='tight', pad_inches=0.1)
plt.show()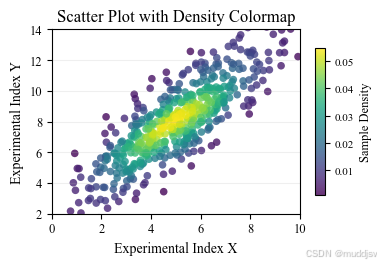
核心要点
-
核心参数:c参数为颜色映射的关键,必须传入与散点数量一致的连续数值数组,而非单一颜色;edgecolors='none'移除散点轮廓,让颜色梯度更连贯,提升视觉效果。
-
散点与透明度优化:统一散点大小,避免大小维度干扰颜色梯度的判断;高密度散点图设置alpha=0.7~0.9,解决重叠遮挡问题,清晰展示密度分布。
-
颜色映射选型:非负的密度、浓度、置信度等数据,优先选择viridis等顺序型配色,保证视觉上 "数值越大,色彩越醒目"。
四、科研级颜色映射定制化与高级优化
1. 自定义颜色映射(适配期刊指定配色)
部分期刊会指定论文配色方案,此时可通过matplotlib.colors.LinearSegmentedColormap创建自定义顺序型 / 发散型颜色映射,精准匹配期刊要求,保证论文图表的风格统一性。
from matplotlib.colors import LinearSegmentedColormap
# 定义颜色节点:(数值位置, 颜色值),数值位置0~1对应数据的vmin~vmax
colors = [(0, '#e6f7ff'), (0.5, '#4fc3f7'), (1, '#0288d1')] # 浅蓝→天蓝→深蓝
# 创建自定义颜色映射,name为映射名称,N为颜色渐变的阶数(N=256为平滑渐变)
custom_cmap = LinearSegmentedColormap.from_list('custom_blue', colors, N=256)
# 使用:在imshow/scatter中指定cmap=custom_cmap即可2. 数值归一化(适配非均匀分布数据)
当数据存在极值偏态分布(如少数超大值导致颜色梯度集中在低数值区间)时,可通过matplotlib.colors的归一化方法,将数值映射到 0~1 区间,优化颜色梯度的视觉展示,让低数值区间的细节更清晰。
常用归一化方法
-
Normalize:线性归一化,适配均匀分布数据(默认使用);
-
LogNorm:对数归一化,适配指数分布 / 偏态分布数据(如基因表达量);
-
PowerNorm:幂次归一化,灵活适配各类偏态分布数据。
from matplotlib.colors import LogNorm
绘制热力图时添加归一化,vmin需大于0(对数归一化要求)
im = ax.imshow(data, cmap='viridis', norm=LogNorm(vmin=1, vmax=1000))
3. 颜色条刻度定制(精准定量标注)
科研中常需在颜色条上标注关键数值、阈值、基准值,可通过cbar.set_ticks()和cbar.set_ticklabels()定制刻度,实现精准的定量展示。
# 自定义颜色条刻度与标签
cbar.set_ticks([-1.0, -0.5, 0, 0.5, 1.0]) # 标注关键数值
cbar.set_ticklabels(['-1.0', '-0.5', '0 (baseline)', '0.5', '1.0']) # 标注基准值
cbar.ax.tick_params(labelsize=8)五、科研级颜色映射常见误区与避坑指南
-
配色选型误区:用顺序型配色展示正负梯度数据、用红绿色盲敏感配色(如seismic)做核心对比、盲目使用jet等存在视觉缺陷的配色。避坑方案:严格按数据特征选型(非负→顺序型,有基准→发散型),优先选择viridis、RdBu等色觉友好的经典配色,同一研究统一配色体系。
-
省略颜色条:仅做颜色渐变可视化,未添加颜色条,导致读者无法将色彩与数值对应,属于 "信息缺失"。避坑方案:所有颜色映射可视化必须搭配颜色条,并添加明确的物理量标注,这是科研可视化的基本要求。
-
插值与拉伸误区:热力图使用interpolation='bilinear'导致数据失真、设置aspect='auto'导致网格拉伸,色彩与数值的对应关系被破坏。避坑方案:科研热力图固定interpolation='none'和aspect='equal',保证数据的准确性与视觉的客观性。
-
多维度干扰误区:散点图同时使用 "颜色梯度 + 大小梯度",两个维度相互干扰,读者无法快速聚焦核心信息。避坑方案:单一图表仅用一种颜色映射,如需展示多维度信息,可拆分为子图或使用联合可视化,避免视觉混乱。
-
数值范围误区:未固定vmin/vmax,同类型数据的颜色映射范围不同,导致跨图表对比时出现视觉误导。避坑方案:同一篇论文中,同类型数据的颜色映射需设置统一的 vmin/vmax,保证对比基准的一致性。
六、总结
颜色映射(Colormap)是 Matplotlib 中处理连续型梯度数据、多维度关联数据的核心工具,也是科研可视化中实现 "数值量化→视觉具象" 的关键手段,其应用场景覆盖热力图、散点图、等高线图、密度图等多种高频图表。掌握科研级颜色映射的核心,在于 "精准选型、规范配置、定制优化"------ 根据数据特征(非负梯度 / 正负基准)选择顺序型 / 发散型配色,优先使用色觉友好的经典映射;所有颜色映射可视化必须搭配规范的颜色条,实现色彩与数值的精准对应;针对期刊要求、数据分布特征做定制化优化,保证可视化的准确性与专业性。
本文从颜色映射的分类选型、基础实战(热力图 / 散点图)、定制化优化到避坑指南,形成了完整的科研应用体系,所有代码均基于系列统一的标准化样式,可直接复用并适配期刊投稿要求。颜色映射的核心原则是 "色彩服务于数据,视觉服务于解读",无需追求复杂的配色方案,只需让色彩精准反映数值特征,让读者快速捕捉数据的核心规律,就是高质量的科研级颜色映射可视化。