YOLO11中的OBB(Oriented Bounding Boxes Object Detection)即旋转边界框目标检测 ,输出是一组旋转的边界框 ,这些边界框能够精确地包围图像中的目标,同时还包含每个边界框的类别标签和置信度分数。
可以使用 X-AnyLabeling 标注工具对新数据集进行标注。
YOLO OBB数据集格式 :使用边界框的四个角点来表示边界框,其坐标被归一化到0到1之间。其格式如下:
bash
class_index x1 y1 x2 y2 x3 y3 x4 y4Python训练代码如下:
python
def parse_args():
parser = argparse.ArgumentParser(description="YOLOv8/YOLO11 train")
parser.add_argument("--task", required=True, type=str, choices=["detect", "segment", "classify", "obb"], help="specify what kind of task")
parser.add_argument("--yaml", required=True, type=str, help="yaml file or datasets path(classify)")
parser.add_argument("--epochs", type=int, default=1000, help="number of training")
parser.add_argument("--imgsz", type=int, default=640, help="input net image size")
parser.add_argument("--patience", type=int, default=100, help="number of epochs to wait without improvement in validation metrics before early stopping the training")
parser.add_argument("--batch", type=int, default=16, help="batch size")
parser.add_argument("--optimizer", type=str, default="auto", help="choice of optimizer for training")
parser.add_argument("--lr0", type=float, default=0.01, help="initial learning rate")
parser.add_argument("--lrf", type=float, default=0.01, help="final learning rate as a fraction of the initial rate=(lr0*lrf)")
parser.add_argument("--dropout", type=float, default=0.0, help="dropout rate for regularization in classification tasks")
parser.add_argument("--pretrained_model", type=str, default="", help="pretrained model loaded during training")
parser.add_argument("--gpu", type=str, default="0", help="set which graphics card to use. it can also support multiple graphics cards at the same time, for example 0,1")
parser.add_argument("--augment", action="store_true", help="augment inference")
args = parser.parse_args()
return args
def train(task, yaml, epochs, imgsz, patience, batch, optimizer, lr0, lrf, dropout, pretrained_model, augment):
if pretrained_model != "":
model = YOLO(pretrained_model)
else:
if task == "detect":
model = YOLO("yolov8n.pt") # load a pretrained model, should be a *.pt PyTorch model to run this method, n/s/m/l/x
elif task == "segment":
model = YOLO("yolov8n-seg.pt")
elif task == "classify":
model = YOLO("yolov8n-cls.pt")
elif task == "obb":
model = YOLO("yolo11n-obb.pt") # yolov8n-obb.pt
else:
raise ValueError(colorama.Fore.RED + f"Error: unsupported task: {task}")
# petience: Training stopped early as no improvement observed in last patience epochs, use patience=0 to disable EarlyStopping
model.train(data=yaml, epochs=epochs, imgsz=imgsz, patience=patience, batch=batch, optimizer=optimizer, lr0=lr0, lrf=lrf, dropout=dropout, augment=augment) # train the model, supported parameter reference, for example: runs/segment(detect)/train3/args.yaml
metrics = model.val() # It'll automatically evaluate the data you trained, no arguments needed, dataset and settings remembered
if task == "classify":
print(f"Top-1 Accuracy:{metrics.top1:.6f}") # top1 accuracy
print(f"Top-5 Accuracy: {metrics.top5:.6f}") # top5 accuracy
elif task == "obb":
print(f"map50-95(B):", metrics.box.map)
print(f"map50(B):", metrics.box.map50)
print(f"map75(B):", metrics.box.map75)
model.export(format="onnx", opset=12, simplify=True, dynamic=False, imgsz=imgsz) # onnx, export the model, cannot specify dynamic=True, opencv does not support
model.export(format="torchscript", imgsz=imgsz) # libtorch
model.export(format="engine", imgsz=imgsz, dynamic=False, verbose=False, batch=1, workspace=2) # tensorrt fp32
# model.export(format="engine", imgsz=imgsz, dynamic=False, verbose=False, batch=1, workspace=2, half=True) # tensorrt fp16
# model.export(format="engine", imgsz=imgsz, dynamic=False, verbose=False, batch=1, workspace=2, int8=True, data=yaml) # tensorrt int8
# model.export(format="openvino", imgsz=imgsz) # openvino fp32
# model.export(format="openvino", imgsz=imgsz, half=True) # openvino fp16
# model.export(format="openvino", imgsz=imgsz, int8=True, data=yaml) # openvino int8, INT8 export requires 'data' arg for calibration
def set_gpu(id):
os.environ["CUDA_VISIBLE_DEVICES"] = id # set which graphics card to use: 0,1,2..., default is 0
print("available gpus:", torch.cuda.device_count())
print("current gpu device:", torch.cuda.current_device())
if __name__ == "__main__":
colorama.init(autoreset=True)
args = parse_args()
if torch.cuda.is_available():
print("Running on GPU")
set_gpu(args.gpu)
else:
print("Running on CPU")
train(args.task, args.yaml, args.epochs, args.imgsz, args.patience, args.batch, args.optimizer, args.lr0, args.lrf, args.dropout, args.pretrained_model, args.augment)
print(colorama.Fore.GREEN + "====== execution completed ======")训练结果截图如下所示:
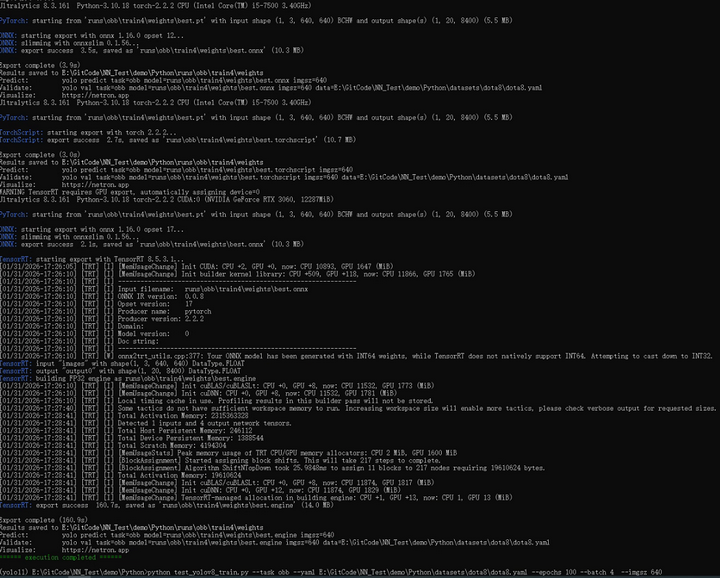
Python预测代码如下:
python
def parse_args():
parser = argparse.ArgumentParser(description="YOLOv8/YOLO11 predict")
parser.add_argument("--model", required=True, type=str, help="model file")
parser.add_argument("--task", required=True, type=str, choices=["detect", "segment", "classify", "obb"], help="specify what kind of task")
parser.add_argument("--dir_images", type=str, default="", help="directory of test images")
parser.add_argument("--verbose", action="store_true", help="whether to output detailed information")
parser.add_argument("--dir_result", type=str, default="", help="directory where the image or video results are saved")
args = parser.parse_args()
return args
def get_images(dir):
# supported image formats
img_formats = (".bmp", ".jpeg", ".jpg", ".png", ".webp")
images = []
for file in os.listdir(dir):
if os.path.isfile(os.path.join(dir, file)):
# print(file)
_, extension = os.path.splitext(file)
for format in img_formats:
if format == extension.lower():
images.append(file)
break
return images
def predict(task, model, verbose, dir_images, dir_result):
model = YOLO(model) # load an model, support format: *.pt, *.onnx, *.torchscript, *.engine, openvino_model
# model.info() # display model information # only *.pt format support
if task == "detect" or task =="segment" or task == "obb":
os.makedirs(dir_result, exist_ok=True)
device = "cuda" if torch.cuda.is_available() else "cpu"
images = get_images(dir_images)
for image in images:
results = model.predict(dir_images+"/"+image, verbose=verbose, device=device)
if task == "detect" or task =="segment" or task == "obb":
for result in results:
print("result:", result)
result.save(dir_result+"/"+image)
else:
print(f"class names:{results[0].names}: top5: {results[0].probs.top5}; conf:{results[0].probs.top5conf}")
if __name__ == "__main__":
colorama.init(autoreset=True)
args = parse_args()
if args.dir_images == "":
raise ValueError(colorama.Fore.RED + f"dir_images cannot be empty:{args.dir_images}")
print("Running on GPU") if torch.cuda.is_available() else print("Running on CPU")
predict(args.task, args.model, args.verbose, args.dir_images, args.dir_result)
print(colorama.Fore.GREEN + "====== execution completed ======")C++ OpenCV DNN推理代码如下:
cpp
int test_yolo11_obb_opencv()
{
namespace fs = std::filesystem;
auto net = cv::dnn::readNetFromONNX(onnx_file);
if (net.empty()) {
std::cerr << "Error: there are no layers in the network: " << onnx_file << std::endl;
return -1;
}
if (cuda_enabled) {
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
}
else {
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
}
if (!fs::exists(result_dir)) {
fs::create_directories(result_dir);
}
for (const auto& [key, val] : get_dir_images(images_dir)) {
cv::Mat frame = cv::imread(val, cv::IMREAD_COLOR);
if (frame.empty()) {
std::cerr << "Warning: unable to load image: " << val << std::endl;
continue;
}
cv::Mat bgr = modify_image_size(frame);
cv::Mat blob;
cv::dnn::blobFromImage(bgr, blob, 1.0 / 255.0, cv::Size(input_size[1], input_size[0]), cv::Scalar(), true, false);
net.setInput(blob);
std::vector<cv::Mat> outputs;
net.forward(outputs, net.getUnconnectedOutLayersNames());
if (outputs.empty()) {
std::cerr << "Error: no output from model" << std::endl;
continue;
}
auto rows = outputs[0].size[2];
auto dimensions = outputs[0].size[1];
outputs[0] = outputs[0].reshape(1, dimensions);
cv::transpose(outputs[0], outputs[0]);
float* data = (float*)outputs[0].data;
float x_factor = bgr.cols * 1.f / input_size[1];
float y_factor = bgr.rows * 1.f / input_size[0];
post_process2(data, rows, dimensions, x_factor, y_factor, obb_class_names, key, frame);
}
return 0;
}后处理代码如下:
cpp
void draw_rotated_rect(const std::vector<std::string>classes, const std::vector<int>& ids, const std::vector<float>& confs, const std::vector<cv::RotatedRect>& boxes, const std::string& name, cv::Mat& frame)
{
std::cout << "image name: " << name << ", number of detections: " << ids.size() << std::endl;
//std::random_device rd;
std::mt19937 gen(66); // gen(rd())
std::uniform_int_distribution<int> dis(100, 255);
std::vector<cv::Scalar> colors;
for (auto i = 0; i < classes.size(); ++i)
colors.emplace_back(cv::Scalar(dis(gen), dis(gen), dis(gen)));
for (auto i = 0; i < ids.size(); ++i) {
auto rotated_rect = boxes[i];
cv::Point2f pts[4];
rotated_rect.points(pts);
for (auto j = 0; j < 4; ++j)
cv::line(frame, pts[j], pts[(j + 1) % 4], colors[ids[i]], 2);
auto center = boxes[i].center;
std::string text = classes[ids[i]] + "," + std::to_string(confs[i]).substr(0, 4);
cv::Size text_size = cv::getTextSize(text, cv::FONT_HERSHEY_DUPLEX, 1, 2, 0);
cv::Point text_org(static_cast<int>(center.x - text_size.width / 2), static_cast<int>(center.y + text_size.height / 2));
cv::putText(frame, text, text_org, cv::FONT_HERSHEY_DUPLEX, 1, colors[ids[i]], 2);
}
std::string path(result_dir);
cv::imwrite(path + "/" + name, frame);
}
void post_process2(const float* data, int rows, int stride, float xfactor, float yfactor, const std::vector<std::string>classes, const std::string& image_name, cv::Mat& frame)
{
const double PI{ std::acos(-1) }; // 3.1415926...
std::vector<int> class_ids{};
std::vector<float> confidences{};
std::vector<cv::RotatedRect> boxes{};
for (auto i = 0; i < rows; ++i) {
const float* classes_scores = data + 4;
cv::Mat scores(1, classes.size(), CV_32FC1, (float*)classes_scores);
cv::Point class_id{};
double max_class_score{};
cv::minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
if (max_class_score > confidence_threshold) {
confidences.push_back(max_class_score);
class_ids.push_back(class_id.x);
float x = data[0] * xfactor;
float y = data[1] * yfactor;
float w = data[2] * xfactor;
float h = data[3] * yfactor;
float angle = data[stride - 1];
if (angle >= 0.5 * PI && angle <= 0.75 * PI)
angle = angle - PI;
cv::RotatedRect box = cv::RotatedRect(cv::Point2f(x, y), cv::Size2f(w, h), angle * 180 / PI);
boxes.push_back(box);
}
data += stride;
}
std::vector<int> nms_result{};
cv::dnn::NMSBoxes(boxes, confidences, confidence_threshold, iou_threshold, nms_result);
std::vector<int> ids;
std::vector<float> confs;
std::vector<cv::RotatedRect> result{};
for (size_t i = 0; i < nms_result.size(); ++i) {
ids.emplace_back(class_ids[nms_result[i]]);
confs.emplace_back(confidences[nms_result[i]]);
result.emplace_back(boxes[nms_result[i]]);
}
draw_rotated_rect(classes, ids, confs, result, image_name, frame);
}结果示例图如下所示:

C++ ONNX Runtime推理代码如下:
cpp
int test_yolo11_obb_onnxruntime()
{
try {
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "YOLO11");
Ort::SessionOptions session_option;
if (cuda_enabled) {
OrtCUDAProviderOptions cuda_option;
cuda_option.device_id = 0;
session_option.AppendExecutionProvider_CUDA(cuda_option);
}
session_option.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
session_option.SetIntraOpNumThreads(1);
session_option.SetLogSeverityLevel(3);
Ort::Session session(env, ctow(onnx_file).c_str(), session_option);
Ort::AllocatorWithDefaultOptions allocator;
std::vector<const char*> input_node_names, output_node_names;
std::vector<std::string> input_node_names_, output_node_names_;
for (auto i = 0; i < session.GetInputCount(); ++i) {
Ort::AllocatedStringPtr input_node_name = session.GetInputNameAllocated(i, allocator);
input_node_names_.emplace_back(input_node_name.get());
}
for (auto i = 0; i < session.GetOutputCount(); ++i) {
Ort::AllocatedStringPtr output_node_name = session.GetOutputNameAllocated(i, allocator);
output_node_names_.emplace_back(output_node_name.get());
}
for (auto i = 0; i < input_node_names_.size(); ++i)
input_node_names.emplace_back(input_node_names_[i].c_str());
for (auto i = 0; i < output_node_names_.size(); ++i)
output_node_names.emplace_back(output_node_names_[i].c_str());
Ort::RunOptions options(nullptr);
std::unique_ptr<float[]> blob(new float[input_size[0] * input_size[1] * 3]);
std::vector<int64_t> input_node_dims{ 1, 3, input_size[1], input_size[0] };
for (const auto& [key, val] : get_dir_images(images_dir)) {
cv::Mat frame = cv::imread(val, cv::IMREAD_COLOR);
if (frame.empty()) {
std::cerr << "Warning: unable to load image: " << val << std::endl;
continue;
}
cv::Mat rgb;
auto resize_scales = image_preprocess(frame, rgb);
image_to_blob(rgb, blob.get());
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU), blob.get(), 3 * input_size[1] * input_size[0], input_node_dims.data(), input_node_dims.size());
auto output_tensors = session.Run(options, input_node_names.data(), &input_tensor, input_node_names.size(), output_node_names.data(), output_node_names.size());
Ort::TypeInfo type_info = output_tensors.front().GetTypeInfo();
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
std::vector<int64_t> output_node_dims = tensor_info.GetShape();
auto output = output_tensors.front().GetTensorMutableData<float>();
int stride_num = output_node_dims[1];
int signal_result_num = output_node_dims[2];
cv::Mat raw_data = cv::Mat(stride_num, signal_result_num, CV_32F, output);
raw_data = raw_data.t();
const float* data = (float*)raw_data.data;
post_process2(data, signal_result_num, stride_num, resize_scales, resize_scales, obb_class_names, key, frame);
}
}
catch (const std::exception& e) {
std::cerr << "Error: " << e.what() << std::endl;
return -1;
}
return 0;
}注:
-
对YOLOv8 OBB和YOLO11 OBB,以上C++代码通用。
-
OBB角度限制在0-90度范围内(不包括90度)。不支持90度或更大的角度。
-
使用的是未启用NMS(nms=false)的导出模型,则角度在最后存放:cx, cy, w, h, cls0, cls1, ..., cls14, angle