一、输入预处理阶段:标准化清洗,剔除检索噪声
核心目标:将用户非标准化输入转换为统一、干净的检索文本,为后续分词和权重计算奠定基础
- 问题接收:获取用户原始查询问题
- 中英文分隔:调用
add_space_between_eng_zh方法,在中英文词汇间自动添加空格,避免连写误判 - 特殊字符清理:通过正则
re.sub(r"[ :|\r\n\t,,。??/!!&^%%(){}<>]+"," ", ...)`,将所有标点、空白符、特殊符号统一替换为单个空格 - 文本归一化:执行
rag_tokenizer.tradi2simp(rag_tokenizer.strQ2B(txt.lower())),完成小写转换 + 全角转半角 + 繁简转换 - 分词处理:调用
rag_tokenizer.tokenize(question).split(),将清洗后的文本拆解为独立词汇列表tks
二、权重计算阶段:量化词汇重要性,聚焦核心检索词
核心目标:为分词结果分配权重,区分核心词汇与辅助词汇,让检索系统优先聚焦关键信息
2.1 初始权重计算
通过self.tw.weights(tks, preprocess=False)计算每个分词的重要性权重,输出[(token, weight)]格式的权重列表 tks_w
2.2 权重优化与噪声过滤
对初始权重列表进行多轮清洗,剔除无效词汇、清理残留字符,核心代码如下:
python
运行
python
# 清理词汇内引号、空格等特殊字符
tks_w = [(re.sub(r"[ \\\"'^]", "", tk), w) for tk, w in tks_w]
# 过滤单个字母/数字(无实际检索价值)
tks_w = [(re.sub(r"^[a-z0-9]$", "", tk), w) for tk, w in tks_w if tk]
# 清理词汇前导加减号
tks_w = [(re.sub(r"^[\+-]", "", tk), w) for tk, w in tks_w if tk]
# 首尾去空格并过滤空值
tks_w = [(tk.strip(), w) for tk, w in tks_w if tk.strip()]
python
import logging # 导入日志模块,用于记录程序运行信息
import math # 导入数学模块,提供数学运算功能
import json # 导入JSON模块,用于处理JSON格式数据
import re # 导入正则表达式模块,用于字符串匹配和替换
import os # 导入操作系统接口模块,用于文件路径操作
import numpy as np # 导入numpy库并重命名为np,用于数值计算
from rag.nlp import rag_tokenizer # 从rag.nlp模块导入rag_tokenizer分词器
from common.file_utils import get_project_base_directory # 从common.file_utils导入项目根目录获取函数
class Dealer: # 定义词项权重计算器类
def __init__(self): # 初始化方法
# 定义停用词集合,包含常见的无意义词语
self.stop_words = set(["请问",
"您",
"你",
"我",
"他",
"是",
"的",
"就",
"有",
"于",
"及",
"即",
"在",
"为",
"最",
"有",
"从",
"以",
"了",
"将",
"与",
"吗",
"吧",
"中",
"#",
"什么",
"怎么",
"哪个",
"哪些",
"啥",
"相关"])
def load_dict(fnm): # 内部函数:加载字典文件
res = {} # 创建空字典用于存储结果
f = open(fnm, "r") # 打开指定文件
while True: # 无限循环读取文件
line = f.readline() # 读取一行
if not line: # 如果没有更多行
break # 跳出循环
arr = line.replace("\n", "").split("\t") # 移除换行符并按制表符分割
if len(arr) < 2: # 如果分割后少于2个元素
res[arr[0]] = 0 # 设置第一个元素的值为0
else:
res[arr[0]] = int(arr[1]) # 设置第一个元素对应第二个元素的整数值
c = 0 # 初始化计数器
for _, v in res.items(): # 遍历字典的所有值
c += v # 累加所有值
if c == 0: # 如果总和为0
return set(res.keys()) # 返回键的集合
return res # 返回原始字典
fnm = os.path.join(get_project_base_directory(), "rag/res") # 构建资源文件夹路径
self.ne, self.df = {}, {} # 初始化命名实体和文档频率字典
try: # 尝试加载NER词典
self.ne = json.load(open(os.path.join(fnm, "ner.json"), "r")) # 加载NER JSON文件
except Exception: # 捕获异常
logging.warning("Load ner.json FAIL!") # 记录NER文件加载失败警告
try: # 尝试加载术语频率文件
self.df = load_dict(os.path.join(fnm, "term.freq")) # 加载术语频率文件
except Exception: # 捕获异常
logging.warning("Load term.freq FAIL!") # 记录术语频率文件加载失败警告
def pretoken(self, txt, num=False, stpwd=True): # 预分词函数,处理文本去除标点和停用词
# 定义标点符号模式列表,用于识别需要过滤的字符
patt = [
r"[~---\t @#%!<>,\.\?\":;'\{\}\[\]_=\(\)\|,。?》•●○↓《;'':""【¥ 】...¥!、·()×`&\\/「」\\]"
]
# 定义正则表达式替换规则列表(当前为空)
rewt = [
]
for p, r in rewt: # 遍历替换规则
txt = re.sub(p, r, txt) # 执行正则替换
res = [] # 初始化结果列表
# 对输入文本进行分词并遍历每个词元
for t in rag_tokenizer.tokenize(txt).split():
tk = t # 当前词元赋值给tk
# 如果启用停用词过滤且词元在停用词表中,或者词元是数字且不保留数字
if (stpwd and tk in self.stop_words) or (
re.match(r"[0-9]$", tk) and not num):
continue # 跳过此词元
for p in patt: # 遍历标点模式
if re.match(p, t): # 如果词元匹配标点模式
tk = "#" # 替换为占位符
break # 跳出循环
# tk = re.sub(r"([\+\\-])", r"\\\1", tk) # 注释掉的转义特殊字符代码
if tk != "#" and tk: # 如果不是占位符且非空
res.append(tk) # 添加到结果列表
return res # 返回预处理后的词元列表
def token_merge(self, tks): # 词元合并函数,将单字符词元合并成多字符词
def one_term(t): # 内部函数:判断是否为单字符词
return len(t) == 1 or re.match(r"[0-9a-z]{1,2}$", t) # 单字符或1-2位数字字母
res, i = [], 0 # 初始化结果列表和索引
while i < len(tks): # 遍历词元列表
j = i # 设置结束索引
# 如果首词是单字符且下一个词非单字符,则合并前两个词
if i == 0 and one_term(tks[i]) and len(
tks) > 1 and (len(tks[i + 1]) > 1 and not re.match(r"[0-9a-zA-Z]", tks[i + 1])):
res.append(" ".join(tks[0:2])) # 合并前两个词
i = 2 # 更新索引
continue # 继续循环
# 查找连续的单字符词元
while j < len(
tks) and tks[j] and tks[j] not in self.stop_words and one_term(tks[j]):
j += 1
if j - i > 1: # 如果找到多个连续单字符词
if j - i < 5: # 如果数量小于5
res.append(" ".join(tks[i:j])) # 合并所有词元
i = j # 更新索引
else: # 如果数量大于等于5
res.append(" ".join(tks[i:i + 2])) # 只合并前两个
i = i + 2 # 更新索引
else: # 如果没有连续单字符词
if len(tks[i]) > 0: # 如果当前词非空
res.append(tks[i]) # 添加当前词
i += 1 # 索引递增
return [t for t in res if t] # 返回非空词元列表
def ner(self, t): # 命名实体识别函数
if not self.ne: # 如果NER字典为空
return "" # 返回空字符串
res = self.ne.get(t, "") # 获取词元的NER标签
if res: # 如果存在标签
return res # 返回标签
def split(self, txt): # 文本分割函数,处理相邻的英文字词合并
tks = [] # 初始化词元列表
for t in re.sub(r"[ \t]+", " ", txt).split(): # 规范化空白字符并分割
# 如果上一个词和当前词都是英文字母,且都不是函数类型
if tks and re.match(r".*[a-zA-Z]$", tks[-1]) and \
re.match(r".*[a-zA-Z]$", t) and tks and \
self.ne.get(t, "") != "func" and self.ne.get(tks[-1], "") != "func":
tks[-1] = tks[-1] + " " + t # 合并两个词
else:
tks.append(t) # 添加新词
return tks # 返回处理后的词元列表
def weights(self, tks, preprocess=True): # 计算词元权重函数
# 数字模式:匹配2位及以上数字、逗号、点号
num_pattern = re.compile(r"[0-9,.]{2,}$")
# 小写字母模式:匹配1-2位小写字母
short_letter_pattern = re.compile(r"[a-z]{1,2}$")
# 数字空格模式:匹配2位及以上数字、点号、空格、横线
num_space_pattern = re.compile(r"[0-9. -]{2,}$")
# 字母模式:匹配小写字母、点号、空格、横线
letter_pattern = re.compile(r"[a-z. -]+$")
def ner(t): # 内部函数:命名实体权重计算
if num_pattern.match(t): # 如果是数字
return 2 # 权重为2
if short_letter_pattern.match(t): # 如果是短字母串
return 0.01 # 权重为0.01
if not self.ne or t not in self.ne: # 如果不在NER字典中
return 1 # 权重为1
# 定义NER类型权重映射
m = {"toxic": 2, "func": 1, "corp": 3, "loca": 3, "sch": 3, "stock": 3,
"firstnm": 1}
return m[self.ne[t]] # 返回对应NER类型的权重
def postag(t): # 内部函数:词性标注权重计算
t = rag_tokenizer.tag(t) # 获取词性标签
if t in set(["r", "c", "d"]): # 如果是代词、连词、副词
return 0.3 # 权重较低
if t in set(["ns", "nt"]): # 如果是地名、机构名
return 3 # 权重较高
if t in set(["n"]): # 如果是名词
return 2 # 权重中等
if re.match(r"[0-9-]+", t): # 如果是数字序列
return 2 # 权重中等
return 1 # 默认权重
def freq(t): # 内部函数:词频权重计算
if num_space_pattern.match(t): # 如果是数字空格模式
return 3 # 返回固定权重
s = rag_tokenizer.freq(t) # 获取词频
if not s and letter_pattern.match(t): # 如果词频为0且符合字母模式
return 300 # 返回高权重
if not s: # 如果词频为0
s = 0 # 设置为0
if not s and len(t) >= 4: # 如果词频仍为0且长度>=4
# 获取细粒度分词结果
s = [tt for tt in rag_tokenizer.fine_grained_tokenize(t).split() if len(tt) > 1]
if len(s) > 1: # 如果有多个子词
s = np.min([freq(tt) for tt in s]) / 6. # 计算最小词频除以6
else:
s = 0 # 否则设为0
return max(s, 10) # 返回最大值,最小为10
def df(t): # 内部函数:文档频率权重计算
if num_space_pattern.match(t): # 如果是数字空格模式
return 5 # 返回固定权重
if t in self.df: # 如果在文档频率字典中
return self.df[t] + 3 # 返回频率加3
elif letter_pattern.match(t): # 如果符合字母模式
return 300 # 返回高权重
elif len(t) >= 4: # 如果长度>=4
# 获取细粒度分词结果
s = [tt for tt in rag_tokenizer.fine_grained_tokenize(t).split() if len(tt) > 1]
if len(s) > 1: # 如果有多个子词
return max(3, np.min([df(tt) for tt in s]) / 6.) # 返回最小DF除以6的最大值
return 3 # 默认返回3
def idf(s, N): # 内部函数:逆文档频率计算
return math.log10(10 + ((N - s + 0.5) / (s + 0.5))) # IDFs平滑计算公式
tw = [] # 初始化词权重列表
if not preprocess: # 如果不进行预处理
# 计算基于词频的IDF值数组
idf1 = np.array([idf(freq(t), 10000000) for t in tks])
# 计算基于文档频率的IDF值数组
idf2 = np.array([idf(df(t), 1000000000) for t in tks])
# 计算综合权重:0.3*词频IDF + 0.7*文档频率IDF,乘以NER权重和词性权重
wts = (0.3 * idf1 + 0.7 * idf2) * \
np.array([ner(t) * postag(t) for t in tks])
wts = [s for s in wts] # 转换为列表
tw = list(zip(tks, wts)) # 将词元和权重配对
else: # 如果进行预处理
for tk in tks: # 遍历每个词元
# 预处理词元并合并
tt = self.token_merge(self.pretoken(tk, True))
# 计算词频IDF
idf1 = np.array([idf(freq(t), 10000000) for t in tt])
# 计算文档频率IDF
idf2 = np.array([idf(df(t), 1000000000) for t in tt])
# 计算综合权重
wts = (0.3 * idf1 + 0.7 * idf2) * \
np.array([ner(t) * postag(t) for t in tt])
wts = [s for s in wts] # 转换为列表
tw.extend(zip(tt, wts)) # 扩展词权重列表
S = np.sum([s for _, s in tw]) # 计算所有权重的总和
return [(t, s / S) for t, s in tw] # 返回归一化的词元权重对三、同义词扩展阶段:打破表述限制,提升检索鲁棒性
核心目标:解决用户提问表述多样性问题,通过同义词扩展扩大召回范围,同时保证检索精准度
-
同义词查找:遍历权重列表前 256 个词汇(兼顾效率与效果),调用
self.syn.lookup(tk)获取每个词汇的同义词 -
同义词分词:对同义词列表执行
rag_tokenizer.tokenize(" ".join(syn)).split(),保持与原分词格式统一 -
同义词权重分配:将同义词权重设定为原词权重的 1/4 ,避免稀释核心词汇重要性,核心代码:
python
运行
syn = ["\"{}\"^{:.4f}".format(s, w / 4.) for s in syn if s.strip()]
四、查询构建阶段:构建 ES 可执行查询,组合单词 + 词组检索
核心目标:将权重词汇与同义词转换为 Elasticsearch(ES)可识别的检索语句,兼顾词汇级和短语级匹配
4.1 单词查询构建
结合原词权重与同义词,构建格式为(token^weight syn1^0.25 syn2^0.25)的单词检索语句:
python
运行
q = ["({}^{:.4f}".format(tk, w) + " {})".format(syn) for (tk, w), syn in zip(tks_w, syns) if tk and not re.match(r"[.^+\(\)-]", tk)]4.2 词组查询构建
构建二元连续词组,提升短语匹配精准度,词组权重为两词最大权重的 2 倍(强化核心短语优先级):
python
运行
for i in range(1, len(tks_w)):
q.append('"%s %s"^%.4f' % (tks_w[i - 1][0], tks_w[i][0], max(tks_w[i - 1][1], tks_w[i][1]) * 2,))五、ES 多字段检索配置:差异化字段权重,聚焦高价值信息
核心目标:针对文档不同字段的信息价值,分配差异化检索权重,让 ES 优先匹配核心字段
5.1 核心字段权重配置(权重越高,检索优先级越高)
python
运行
self.query_fields = [
"title_tks^10", # 标题词汇
"title_sm_tks^5", # 标题细粒度词汇
"important_kwd^30", # 重要关键词(最高优先级)
"important_tks^20", # 重要词汇
"question_tks^20", # 问题词汇
"content_ltks^2", # 内容词汇
"content_sm_ltks", # 内容细粒度词汇(默认权重1,最低)
]5.2 多字段查询构建
通过MatchTextExpr将构建好的检索语句与字段权重结合,生成 ES 多字段匹配查询,ES 将按字段权重 + 词汇权重进行综合评分。

python
GET /ragflow_b9ab746cfcc511f0beaf1ae1f88af9af/_search
{
"query": {
"bool": {
"must": [
// 用 query_string 替换原 multi_match,实现词级加权+短语加权
{
"query_string": {
"query": "(背景)^0.5094773480212931 (项目)^0.49052265197870687 (\"项目 背景\"~2)^1.5",
"fields": [
"title_tks^10",
"title_sm_tks^5",
"important_kwd^30",
"important_tks^20",
"question_tks^20",
"content_ltks^2",
"content_sm_ltks"
],
"minimum_should_match": "30%" // 对应 extra_options 里的 0.3
}
}
],
"filter": [
// 保留你原有的 kb_id 过滤
{
"term": {
"kb_id": "187a8b30000011f19ace1ae1f88af9af"
}
}
]
}
},
"size": 10 // 对应 topn = 100
}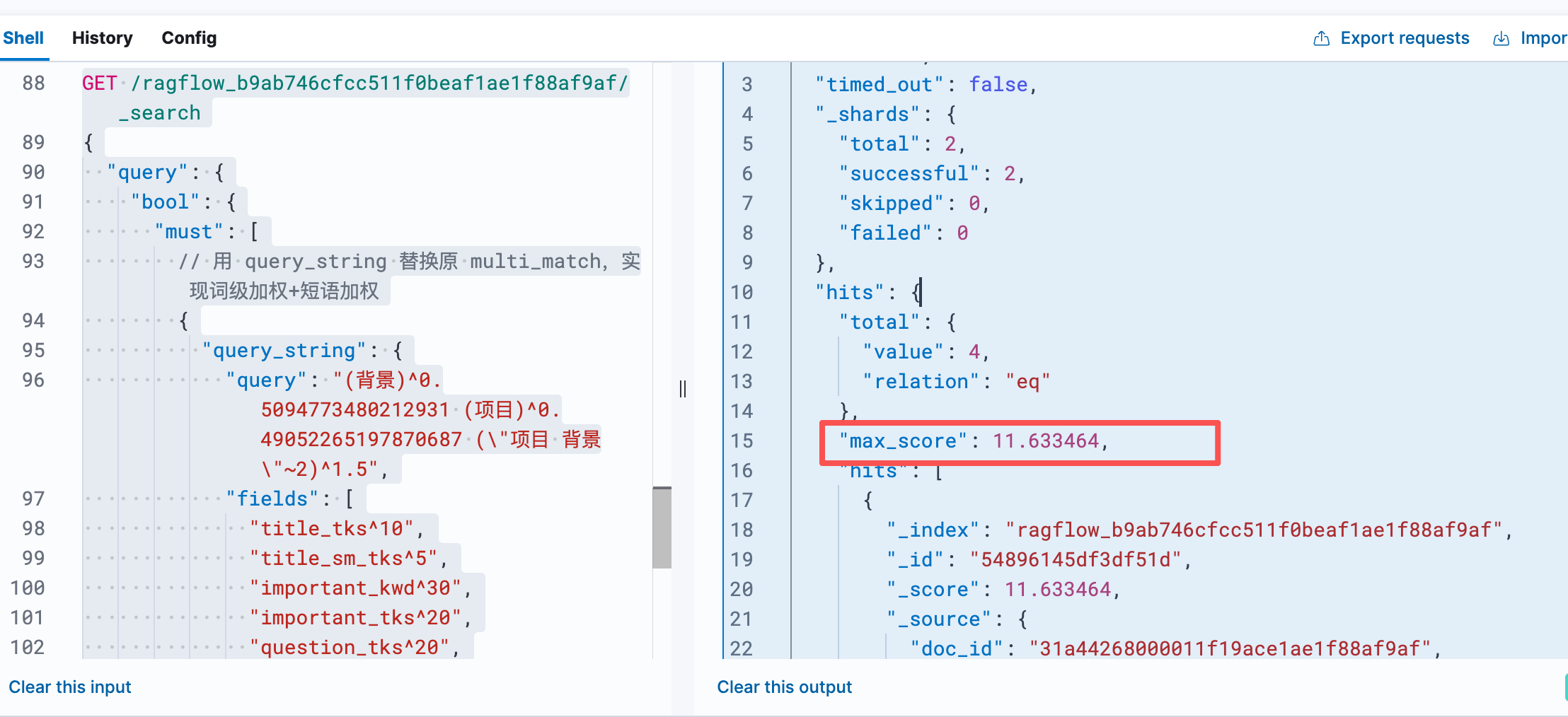
注意:这是只是初步检索阶段计算 ,其实本质上面是没有用这个分分数, 是基于下面的排序,自定义的分数计算规则
六、向量检索构建:捕捉语义相关性,弥补关键词检索短板
核心目标:将用户问题转换为语义向量,通过向量相似度匹配,解决关键词检索 "语义脱节" 问题
6.1 问题向量编码
通过嵌入模型将文本转换为低维稠密向量,为向量检索提供基础:
python
运行
qv, _ = emb_mdl.encode_queries(txt)
embedding_data = [get_float(v) for v in qv]
vector_column_name = f"q_{len(embedding_data)}_vec"6.2 文本 + 向量融合查询
采用加权融合方式组合文本检索与向量检索,突出语义相关性的核心地位,核心配置:
python
运行
# 构建向量检索表达式(余弦相似度匹配)
matchDense = MatchDenseExpr(vector_column_name, embedding_data, 'float', 'cosine', topk, {"similarity": similarity})
# 融合配置:文本检索0.05,向量检索0.95
fusionExpr = FusionExpr("weighted_sum", topk, {"weights": "0.05,0.95"})
matchExprs = [matchText, matchDense, fusionExpr]检索流程:
1、ES执行多字段文本检索
2、向量数据库执行语义检索
3、融合算法合并两种结果
4、重排序生成最终结果
七、ES 检索执行:执行融合查询,获取初始检索结果
核心目标:调用 ES 检索接口,执行文本 + 向量融合查询,返回原始匹配结果
- 执行检索:调用
self.dataStore.search()方法,传入文本匹配、向量匹配及融合表达式 - 结果提取:从 ES 返回结果中提取三大核心信息:
ids:匹配文档 / 片段的唯一 ID 列表field:匹配内容的各类字段数据(标题、正文、关键词等)highlight:检索结果的高亮匹配标注,定位核心匹配位置
八、重排序阶段:二次优化排序,提升结果贴合度
核心目标:对 ES 初始结果进行二次重排序,结合词项相似度与向量相似度,让结果更贴合用户需求
8.1 文本词汇权重二次调整
强化核心字段词汇的重要性,重新分配词汇权重(按字段价值加权):
python
运行
python
for i in sres.ids:
# 获取内容词汇,使用OrderedDict去重但保持顺序
content_ltks = list(OrderedDict.fromkeys(sres.field[i][cfield].split()))
# 获取标题词汇,过滤掉空字符串
title_tks = [t for t in sres.field[i].get("title_tks", "").split() if t]
# 获取问题词汇,过滤掉空字符串
question_tks = [t for t in sres.field[i].get("question_tks", "").split() if t]
# 获取重要关键词
important_kwd = sres.field[i].get("important_kwd", [])
# 构建词汇列表,给不同类型的词汇分配不同权重:内容词汇*1, 标题词汇*2, 重要关键词*5, 问题词汇*6
tks = content_ltks + title_tks * 2 + important_kwd * 5 + question_tks * 6
# 将词汇列表添加到文本权重列表
ins_tw.append(tks)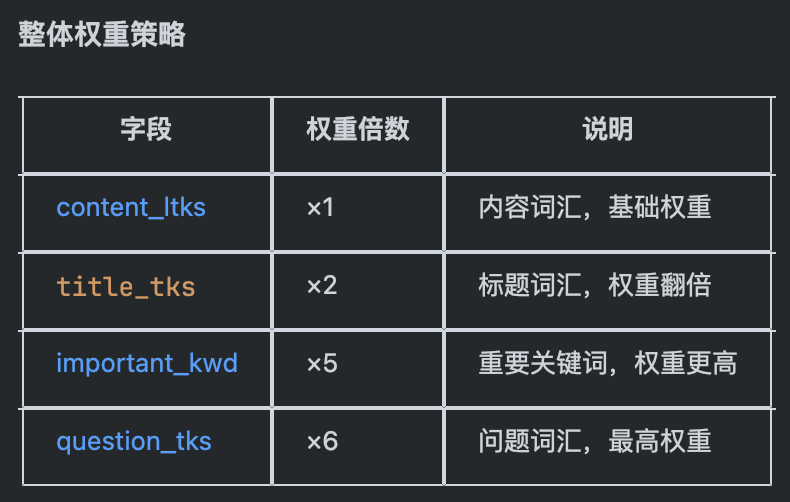
8.2 混合相似度计算(核心重排序逻辑)
融合向量相似度 (语义)与词项相似度 (关键词),计算公式:混合相似度 = 向量相似度 ×0.7 + 词项相似度 ×0.3,核心代码:
python
运行
python
def hybrid_similarity(self, avec, bvecs, atks, btkss, tkweight=0.3, vtweight=0.7):
# 导入余弦相似度计算函数,用于计算向量之间的相似度
from sklearn.metrics.pairwise import cosine_similarity
# 导入numpy库,用于数值计算
import numpy as np
# 计算查询向量(avec)与多个目标向量(bvecs)之间的余弦相似度
sims = cosine_similarity([avec], bvecs)
# 计算基于关键词的文本相似度,atks是查询的关键词列表,btkss是目标文本的关键词列表
tksim = self.token_similarity(atks, btkss)
# 检查向量相似度是否全为0(即没有有效的向量相似度计算结果)
if np.sum(sims[0]) == 0:
# 如果向量相似度全为0,则只返回基于关键词的相似度结果
return np.array(tksim), tksim, sims[0]
# 将向量相似度和关键词相似度按权重进行加权求和,返回综合相似度得分、关键词相似度和向量相似度
return np.array(sims[0]) * vtweight + np.array(tksim) * tkweight, tksim, sims[0]8.3 词项相似度计算
以 "查询词汇匹配权重和 / 查询词汇总权重" 为核心,计算关键词匹配度(添加 1e-9 避免除零):
python
运行
def similarity(self, qtwt, dtwt):
s = 1e-9
for k, v in qtwt.items():
if k in dtwt:
s += v # 累加匹配权重
q = 1e-9
for k, v in qtwt.items():
q += v # 累加查询总权重
return s / q # 词项相似度值九、最终结果处理:过滤 + 分页 + 标准化,输出可用结果
核心目标:将重排序后的结果进行最终处理,确保输出结果的有效性、规范性和可用性
- 相似度阈值过滤:剔除低于阈值的低相关结果,
valid_idx = [int(i) for i in sorted_idx if sim_np[i] >= similarity_threshold] - 结果排序:按混合相似度降序排列过滤后的结果
- 分页处理:根据用户需求计算索引范围,返回指定页面结果
- 标准化输出:每个结果包含统一结构,便于后续调用:
- 基础标识:
chunk_id(块 ID) - 相似度指标:
similarity(综合)、vector_similarity(向量)、term_similarity(词项) - 内容字段:标题、正文、关键词等原始字段数据
- 基础标识:
十、特殊处理机制:应对边缘场景,提升系统鲁棒性
核心目标:解决检索过程中的边缘问题,避免无结果、结果偏差等情况,提升系统稳定性
10.1 空结果重试机制
当初次检索无结果时,自动降低检索阈值重新执行,尽可能召回相关内容:
- 降低
min_match(最小匹配数)阈值至 0.1 - 调整
similarity(相似度)阈值至 0.17 - 重新执行完整检索流程
10.2 排名特征补充计算
在混合相似度基础上,补充额外特征得分,优化最终排序:
- PageRank 得分:评估文档的权威度和关联性
- 标签特征得分:结合文档标签与用户问题的匹配度
- 将特征得分融入最终相似度计算,让权威、贴合的结果排名更靠前