大模型实战 03预备 云端炼丹房 2:Kaggle 上手指南
核心摘要 (TL;DR)
- 痛点:Colab 免费额度耗尽,或者单张 T4 显存(16GB)无法满足更大参数模型的微调需求。
- 方案 :利用 Kaggle 提供的 每周 30 小时免费双路 T4 GPU (T4 x2) 算力。
- 技巧 :通过 手机号验证 解锁联网权限,利用 Kaggle Datasets 实现模型的持久化存储。
- 目标:作为 Colab 的强力替补(甚至上位),搭建备用云端炼丹环境。
前言
上一篇中,本来想直接写到Google Colab的大模型推理脚本,让各位友人们感受一下在全参数7B模型的能力,但是折腾了很久,Colab读driver老是失败,当我想直接下载到云端主机而不是driver的时候,GPU的额度已经耗尽。索性今天在Kaggle的这篇博文中来讲,应该之后也主要用Kaggle来进行云端开发,毕竟Colab额度少,还得盯着,长时间不看会断掉连接。
好,我们来先介绍一下今天的主角,Google 旗下的另一个神器:Kaggle。Colab如果说其本职就是模型训练,那Kaggle 本身其实是一个数据科学的竞赛平台,毕竟是数据科学竞赛嘛,那自然得需要算力资源,Kaggle为了方便,也发挥了谷歌大善人的优良品质,免费提供了大方的计算资源。跟Colab对比起来,Kaggle的优势就是,更稳定,更方便,资源给的额度更多。
1. Kaggle Notebooks 核心概念
Kaggle 的核心编程环境叫 Kernels (现在统称 Notebooks) ,不用害怕,诶,它就是我们昨儿刚认识的熟人云端服务器版 的Jupyter Notebook,但是和Colab不太相同的是Kaggle的文件结构,它明显得区分了输入区域,输出区域,暂存区域, 这是也我们刚上手容易懵的地方:
- Input (
/kaggle/input) :只读区域。这里存放你上传的数据集或挂载的模型。读取速度极快,但无法写入。 - Output (
/kaggle/working) :可读写区域。这是你的主工作区,代码运行结果、下载的模型必须存在这里。但注意,重启 Session 后,这里的内容如果不保存为 Dataset 也会消失。 - Temp (
/kaggle/temp) :临时暂存区。空间较大(只有当前会话有效),适合下载解压临时的大文件。
2. 快速上手:注册与"解锁"
2.1 注册与关键验证 (必做)
我们新用户登录创建notebook后会发现,我们没有硬件加速设备可选。
根本原因就是咱们没有进行手机验证,哈哈哈,可以理解,毕竟本身kaggle就不用绑卡,加上手机验证可能会杜绝掉一大部分计算资源滥用。
- 访问 Kaggle 官网 并注册账号。
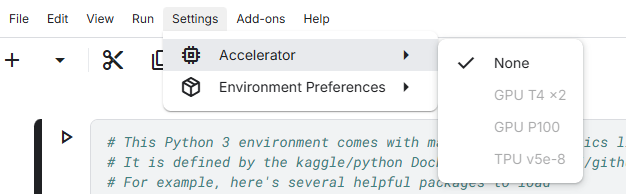
- 关键步骤 :点击右上角头像 -> Settings。
- 找到 Phone Verification (手机验证)。必须完成这一步 ,否则无法开启 GPU 和 Internet(联网)功能。
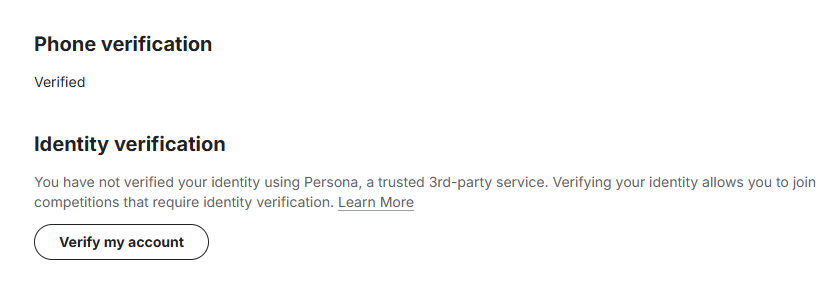
认证完毕就可以使用GPU资源了
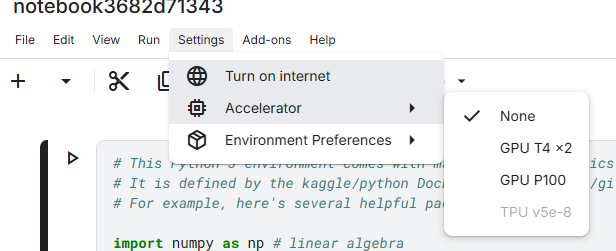
如果继续做了Identity verification之后,可以使用TPU资源,不过我们暂时用不到,目前的GPU资源已经够咱们大玩一场了。
2.2 创建笔记本
- 点击左侧菜单栏的 Create -> New Notebook。
- 进入编辑器界面,你会发现界面布局比 Colab 更加紧凑且功能分区明确。
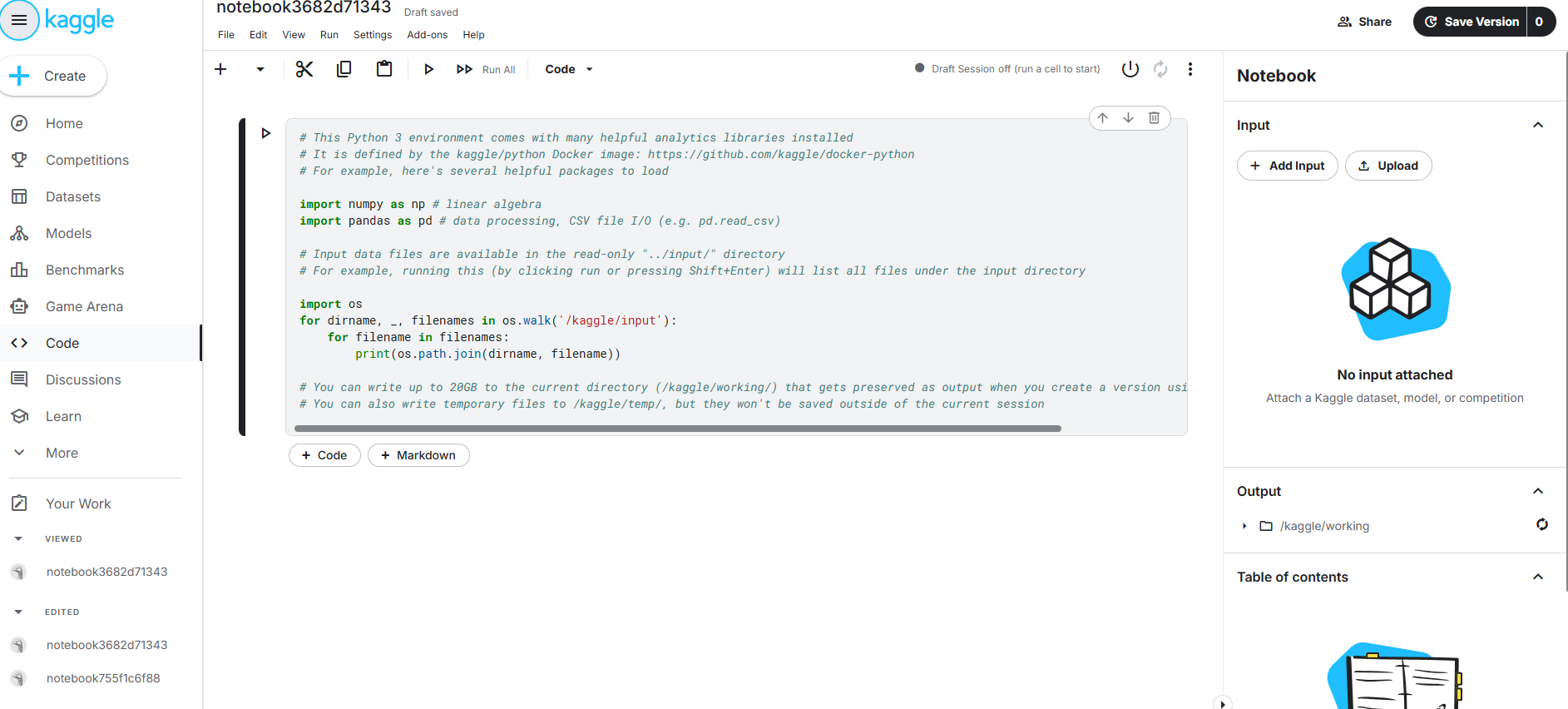
2.3 界面布局速览
- 工作区 :位于右侧,显示了Input->我们的挂载资源,上传的数据集和模型等等,Output->我们输出的结果资源。notebook内容速览,以及下面的session options环境快捷配置等等
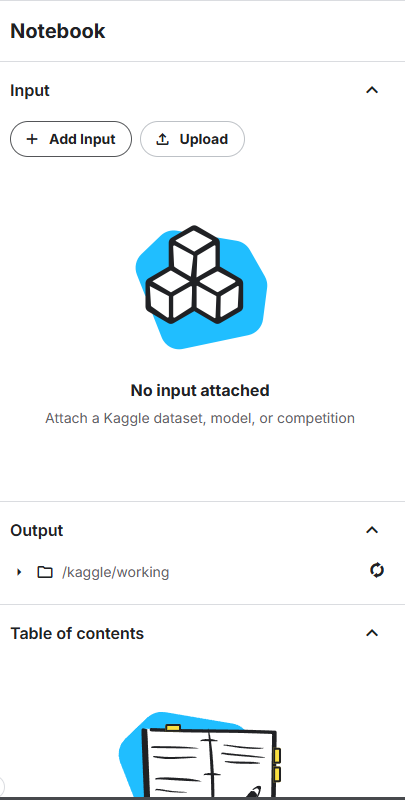
- 快捷操作栏 : 在代码区上方,和Colab差别不大,可以快速运行,插入单元格,复制粘贴等等

- 代码区:和Colab一样, 标准的 Jupyter 单元格。
注意,
- 和Colab不一样的是,Kaggle的文件名没有后缀,不用加ipynb后缀
- 咱们的硬件加速(GPU/TPU计算资源)被放到了顶部菜单栏的Settings 中的accelerator中了
- 和Colab不同,因为Kaggle是为竞赛服务,很多竞赛是要求模型不联网的,所以我们在训练模型的时候,需要手动开启网络,也在顶部菜单栏的Settings 中,点击Turn On Internet 打开即可联网下载模型或者数据集。
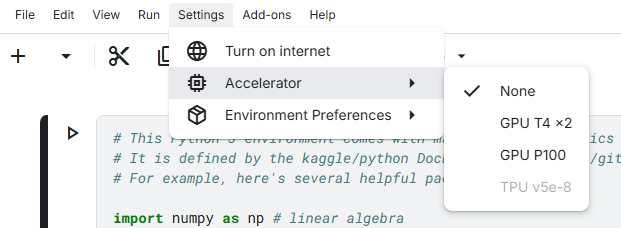
- 密钥管理被放到了顶部菜单栏的Add-ons 下了
3. 环境配置:开启双显卡与联网
Kaggle 默认环境是 CPU 且 断网 的。我们需要手动"解除封印"。
3.1 开启联网 (Internet On)
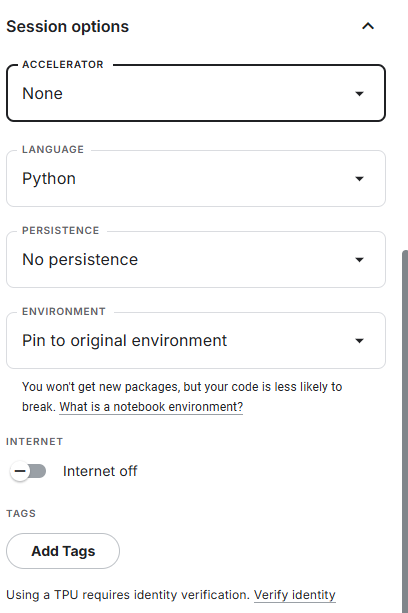
可以按照刚才说的在顶部菜单栏打开,也可以在右侧边栏的 Session Options 中,找到 Internet 选项。将开关拨到 On 。
注意:如果没有手机验证,此选项为灰色不可用。
3.2 开启 GPU 加速 (T4 x2)
-
在右侧边栏找到 Accelerator。
-
下拉选择 GPU T4 x2。
- GPU T4 x2:两张显卡,约 30GB 显存,适合大模型推理和微调。
- GPU P100:单张旧架构卡,虽然速度快但显存仅 16GB,通常不推荐。
-
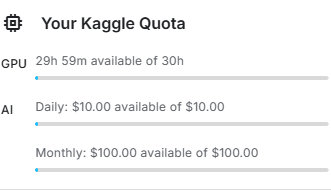
开启后,顶部会显示 Session Storage 和 GPU Quota (每周 30 小时额度,通常周六刷新)。
点击自己的头像,可以看见自己的额度GPU Quata
3.3 验证双卡环境
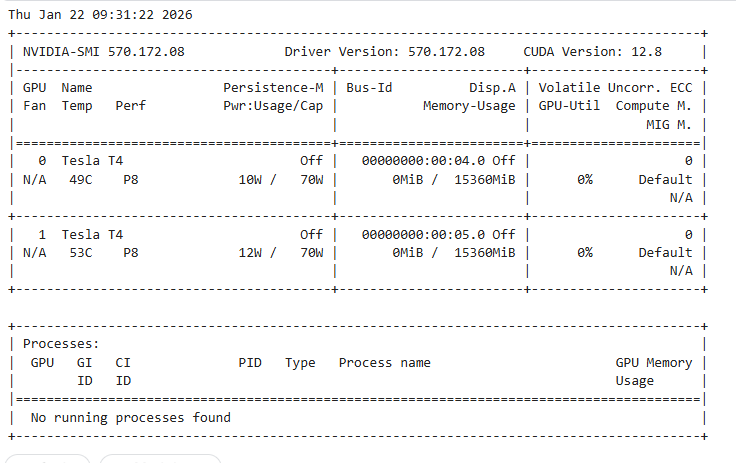
输入并运行以下代码,确认我们是否真的拥有了两张显卡:
python
!nvidia-smi你应当能看到 两张 Tesla T4 显卡的列表 (GPU 0 和 GPU 1)。
4. 实战:下载并运行大模型
在 Kaggle 上使用模型主要有两种"流派":代码下载派 和 原生挂载派。
方式一:利用 HuggingFace CLI 下载 (工程化推荐)
这种方式最灵活,适合需要精确控制模型版本的情况。由于 Kaggle 没有 Google Drive,我们将模型下载到 /kaggle/working/ 目录。
步骤 1:安装与配置
python
# Kaggle 预装库很多,但 transformers 版本可能滞后,建议更新
!pip install -U transformers huggingface_hub accelerate bitsandbytes点击顶部菜单 Add-ons -> Secrets ,添加 HF_TOKEN(你的 HuggingFace 访问令牌)。
步骤 2:下载脚本
python
import os
from huggingface_hub import login, snapshot_download
from kaggle_secrets import UserSecretsClient
# 1. 登录 (自动读取 Secrets)
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HF_TOKEN")
login(token=hf_token)
# 2. 定义下载路径 (注意:必须在 /kaggle/working 下)
model_dir = "/kaggle/working/model_cache"
os.makedirs(model_dir, exist_ok=True)
# 3. 下载模型
model_id = "Qwen/Qwen2.5-7B-Instruct"
print(f"开始下载 {model_id} ...")
# Kaggle 建议下载实文件 (local_dir_use_symlinks=False)
snapshot_download(
repo_id=model_id,
local_dir=model_dir,
local_dir_use_symlinks=False,
token=hf_token
)
print("下载完成!")
方式二:Add Input (Kaggle 原生方式)
这是 Kaggle 最强大的功能。你可以直接在网页端搜索现成的模型,像挂载 U 盘一样挂载进来,不消耗下载流量和时间。
- 点击右侧边栏的 Add Input。
- 选择 Models 标签页。
- 搜索
Qwen2.5。 - 点击 + 号添加。
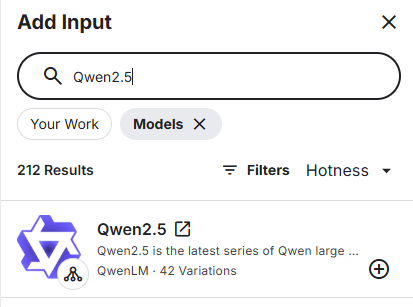
- 选择FRAMEWORK选择Transformers 架构, VARIATION选择7b-instruct , 之后的博文会跟各位友人解释这些参数的差别
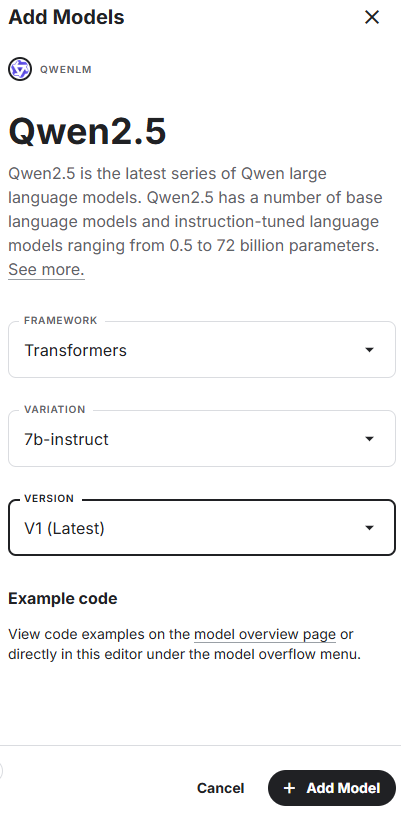
- 模型会直接出现在
/kaggle/input/目录下(只读),路径通常长得像/kaggle/input/qwen2.5/transformers/7b-instruct/1。
5. 加载模型与双卡推理
拥有双卡 T4 后,加载模型时有一个关键参数:device_map="auto"。它会自动将模型切分到两张显卡上,从而让我们能运行更大的模型。
python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 路径根据你的下载方式调整
# 方式一路径: "/kaggle/working/model_cache"
# 方式二路径: "/kaggle/input/qwen2.5/transformers/7b-instruct/1/" (具体可以运行默认创建的第一个单元格,查看input目录结构,到能看见config.json的目录即可)
model_path = "/kaggle/working/model_cache"
print("正在加载模型 (双卡模式)...")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 关键:device_map="auto" 会自动利用两张 T4
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True
)
print(f"模型加载成功!显存分布: {model.hf_device_map}")
# 测试对话
prompt = "你好,请用一句话形容 Kaggle 的双 T4 显卡有多香?"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
with torch.no_grad():
generated_ids = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"Qwen: {response.split('assistant')[-1].strip()}")6. 进阶:如何持久化保存?(Save Version)
Kaggle 没有 Google Drive,那怎么保存下载好的模型或训练结果呢?
答案:把 Output 变成 Dataset。
- 当你的代码运行完毕,模型保存在
/kaggle/working后。 - 点击右上角的 Save Version 按钮。
- 选择 Save & Run All (重新跑一遍),必须等到下方弹出的保存任务完成。

- 保存成功后,你可以去主页的Your Work 点击刚才的Notebook,进入Output 标签页里,点击最右边的Output的三个点,然后点击 New Dataset 。
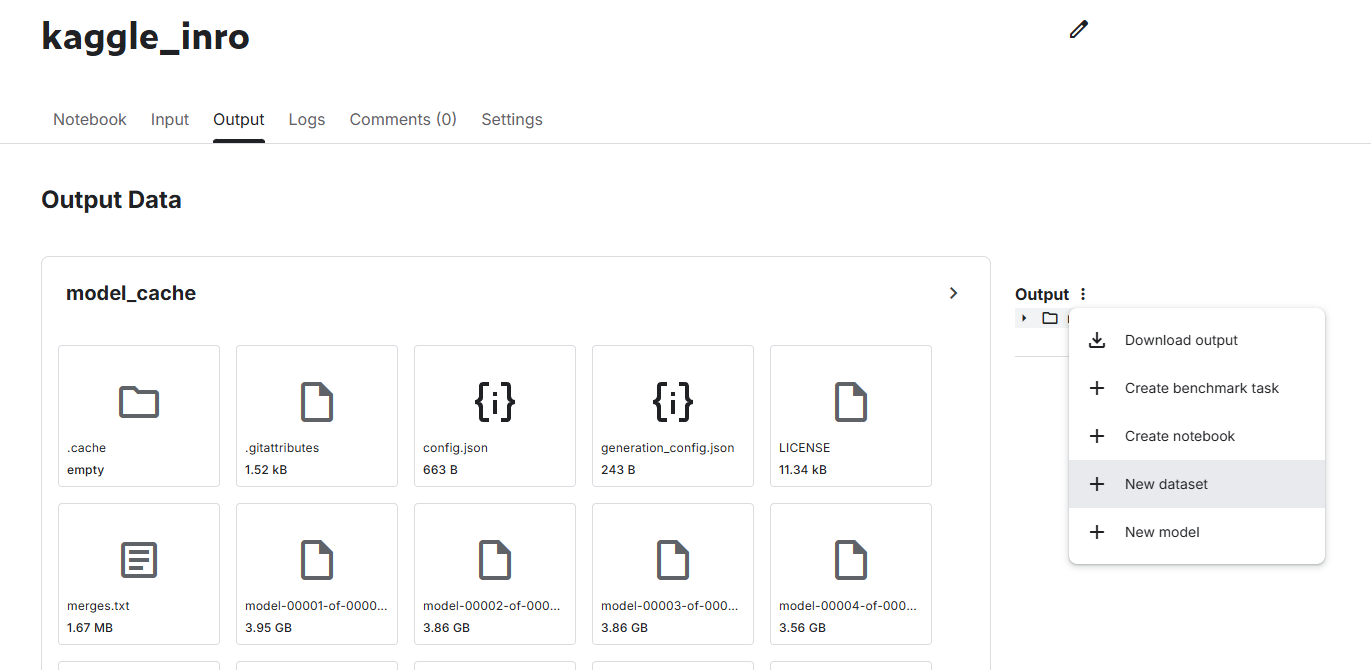
- 这样,我们刚才的模型就变成了一个可以在其他 Notebook 里直接 Add Input 的数据集了!
PS:除开自训练的特殊模型和一些在Input找不到的模型,最好都直接使用Input导入更为快捷
7. 常见问题 (Q&A)
Q: Colab 和 Kaggle 我该选谁?
A:
- Colab: 适合快速实验、挂载 Google Drive 方便。但 T4 只有一张,且最近封号较严。
- Kaggle: 适合需要大显存(T4 x2)的任务。环境更稳定,且有 30 小时/周的明确额度,不用担心用到一半被踢下线。
Q: 为什么我的代码报错 Internet connection is closed?
A: 这是一个经典错误。请检查右侧边栏的 Internet 开关是否为 On。如果开关是灰色的,请检查是否完成了账号的 手机号验证。
Q: /kaggle/working 里的文件重启后还有吗?
A: 没有了。Kaggle 的 Session 也是临时的。如果需要持久化,请务必使用 Save Version 功能将其保存为 Dataset,或者在代码最后加一段上传到 HuggingFace Hub 的代码。
本文作者: Algieba
本文链接: https://blog.algieba12.cn/llm02-2-online-environment-kaggle/
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!