一、研究背景
该模型属于智能优化算法与神经网络结合的研究方向,旨在解决传统BP神经网络易陷入局部最优、收敛慢的问题。通过引入PSO(粒子群优化算法)对神经网络的初始权重进行全局寻优,提升模型的预测精度和稳定性。
二、主要功能
- 数据预处理:加载数据、划分训练集与测试集、归一化处理。
- PSO优化BP神经网络:使用PSO优化神经网络的初始权重与偏置。
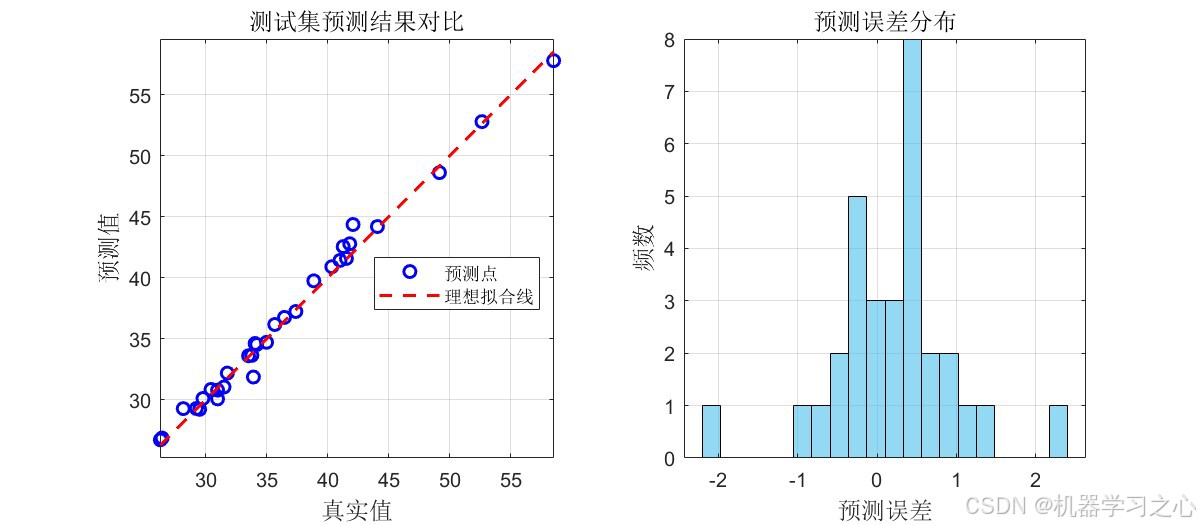
- 模型训练与预测:使用优化后的网络进行训练,并在测试集上评估性能。
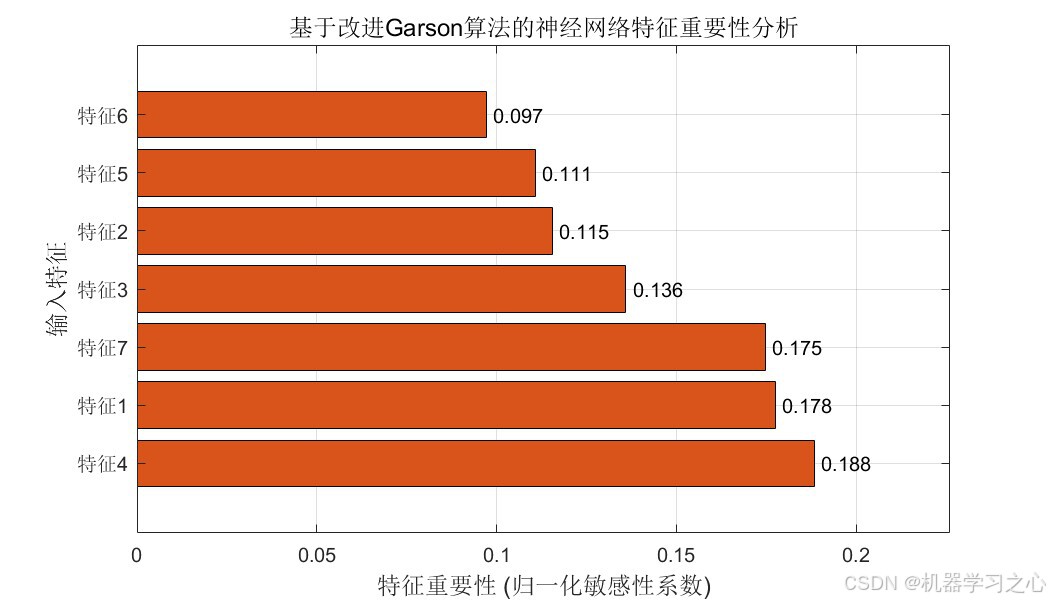
- 特征重要性分析:采用改进的Garson算法分析输入特征对输出的影响。
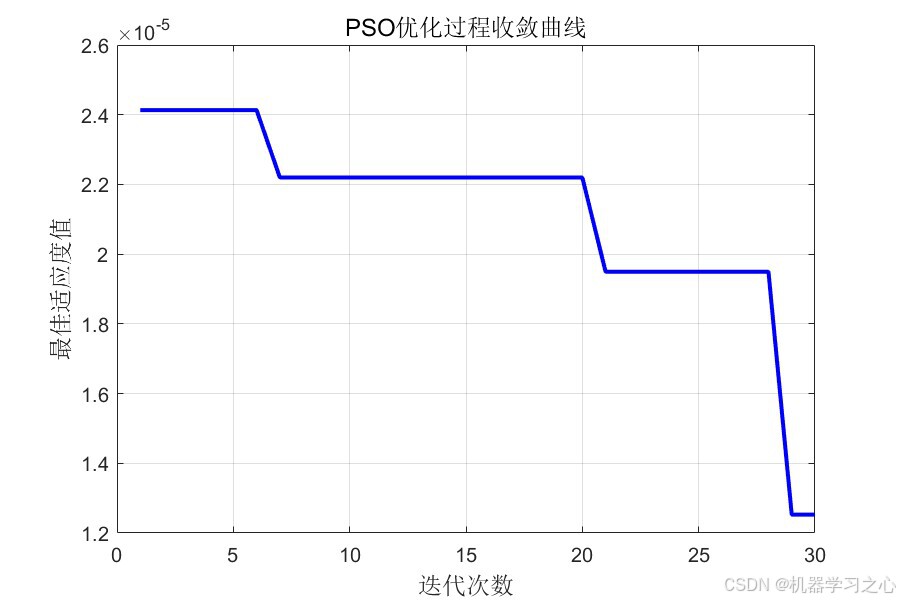
- 可视化分析:包括预测结果对比图、误差分布图、PSO收敛曲线、特征重要性条形图。
三、算法步骤
- 数据准备 → 划分训练/测试集 → 归一化。
- PSO参数初始化 → 粒子群初始化。
- PSO迭代优化 :
- 计算每个粒子的适应度(BP网络训练误差)
- 更新个体最优与全局最优
- 更新粒子速度与位置
- 解码最优粒子为网络权重 → 训练最终BP网络。
- 测试集预测 → 性能评估。
- 特征重要性计算 → 可视化。
四、技术路线
PSO + BP神经网络 + Garson特征分析- 优化算法:PSO(粒子群优化)
- 预测模型:前馈神经网络(Feedforward Neural Network)
- 特征分析:改进Garson算法(基于权重敏感性)
- 评估指标:MSE、RMSE、MAE、R²
五、公式原理
1. PSO更新公式:
v i d t + 1 = w ⋅ v i d t + c 1 r 1 ( p i d − x i d t ) + c 2 r 2 ( p g d − x i d t ) v_{id}^{t+1} = w \cdot v_{id}^t + c_1 r_1 (p_{id} - x_{id}^t) + c_2 r_2 (p_{gd} - x_{id}^t) vidt+1=w⋅vidt+c1r1(pid−xidt)+c2r2(pgd−xidt)
x i d t + 1 = x i d t + v i d t + 1 x_{id}^{t+1} = x_{id}^t + v_{id}^{t+1} xidt+1=xidt+vidt+1
2. 神经网络输出计算(前向传播):
y = f 2 ( W 2 ⋅ f 1 ( W 1 ⋅ X + b 1 ) + b 2 ) y = f_2(W_2 \cdot f_1(W_1 \cdot X + b_1) + b_2) y=f2(W2⋅f1(W1⋅X+b1)+b2)
3. Garson特征重要性:
Q i = ∑ j = 1 L ∣ W i j ⋅ V j ∣ ∑ r = 1 n ∣ W r j ∣ ∑ r = 1 n ∑ j = 1 L ∣ W r j ⋅ V j ∣ ∑ k = 1 n ∣ W k j ∣ Q_i = \frac{\sum_{j=1}^{L} \frac{|W_{ij} \cdot V_j|}{\sum_{r=1}^{n} |W_{rj}|}}{\sum_{r=1}^{n} \sum_{j=1}^{L} \frac{|W_{rj} \cdot V_j|}{\sum_{k=1}^{n} |W_{kj}|}} Qi=∑r=1n∑j=1L∑k=1n∣Wkj∣∣Wrj⋅Vj∣∑j=1L∑r=1n∣Wrj∣∣Wij⋅Vj∣
六、参数设定
| 参数 | 说明 | 默认值 |
|---|---|---|
train_ratio |
训练集比例 | 0.7 |
num_particles |
粒子数 | 10 |
max_iter |
PSO最大迭代次数 | 30 |
num_hidden |
隐含层节点数 | 15 |
w |
PSO惯性权重 | 0.729 |
c1, c2 |
学习因子 | 1.49445 |
epochs |
最终网络训练轮数 | 1000 |
七、运行环境
- 平台:MATLAB R2018a 或更高版本
- 工具箱 :需安装 Neural Network Toolbox
- 数据格式 :Excel 文件(
.xlsx),最后一列为输出变量
八、应用场景
- 预测建模:房价预测、股票趋势、销售量预测等回归问题
- 特征重要性分析:识别关键影响因素,辅助决策
- 优化研究:可作为智能优化算法与神经网络结合的实验框架
- 教学与研究:适用于机器学习、优化算法、神经网络相关课程或课题
matlab
%% 清空环境,加载数据
clc; clear; close all;
warning off;
% 1. 加载数据 (请替换为你的数据文件)
filename = 'data.xlsx'; % 请修改为你的文件名
data = xlsread(filename);
input = data(:, 1:end-1)'; % 输入特征矩阵 [特征数, 样本数]
output = data(:, end)'; % 输出标签 [1, 样本数]
% 2. 数据预处理:划分训练集和测试集 (70%训练,30%测试)
train_ratio = 0.7;
num_samples = size(input, 2);
num_train = round(train_ratio * num_samples);
indices = randperm(num_samples);
train_idx = indices(1:num_train);
test_idx = indices(num_train+1:end);
input_train = input(:, train_idx);
output_train = output(:, train_idx);
input_test = input(:, test_idx);
output_test = output(:, test_idx);