华为CANN框架中HCCL仓库的全面解析:分布式通信的引擎
华为CANN框架中HCCL仓库的全面解析:分布式通信的引擎
在人工智能时代,大规模模型训练已成为常态,华为的Compute Architecture for Neural Networks(CANN)框架通过其强大的异构计算能力,支持从单机到万卡集群的AI计算。HCCL(Huawei Collective Communication Library)仓库作为CANN的核心组件之一,专注于分布式通信操作,提供高效的集体通信原语,如AllReduce、Broadcast、AllGather等。这些操作是分布式训练的关键,确保多NPU间参数同步和数据交换。HCCL仓库开源在AtomGit上,与MindSpore、PyTorch等框架无缝集成,帮助开发者构建高效的分布式AI系统。
HCCL的设计理念源于对Ascend硬件的深度优化。Ascend NPU集群通过高带宽互联(如RoCE),HCCL利用这些硬件特性,实现低延迟、高吞吐的通信。不同于通用通信库,HCCL针对AI负载优化,支持混合精度和大规模扩展。在训练GPT-like模型时,HCCL能将通信开销降至最低,推动华为在国产AI生态的领先地位。
为了更好地理解HCCL在CANN中的作用,先来看一张CANN架构图:
这个图展示了CANN的软件栈,HCCL位于通信层,支持上层框架的分布式并行。
HCCL仓库的核心架构与功能
HCCL仓库的代码结构模块化,主要包括通信原语实现、拓扑管理、缓冲区管理和API接口。核心是集体通信操作,使用C++编写,结合Ascend的ACL API,确保与NPU硬件紧密耦合。
-
集体通信原语:HCCL提供AllReduce、ReduceScatter、AllGather、Broadcast等标准操作。这些原语支持多种算法,如Ring、Tree、Pipeline,根据集群规模自动选择。
-
拓扑感知:HCCL检测集群拓扑,包括节点内NPU互联和节点间网络。通过拓扑优化,减少跨节点通信跳数,提高效率。
-
缓冲区管理:支持注册缓冲区和临时缓冲区,结合零拷贝技术,减少内存拷贝开销。在大规模训练中,这能节省宝贵的HBM内存。
-
异步通信:HCCL API支持非阻塞调用,与计算流重叠,实现计算-通信并行。
-
错误处理与调试:集成日志和性能计数器,便于诊断通信瓶颈。
HCCL的这些功能,使其在处理数据并行、模型并行时表现出色,尤其在万卡集群中。
以下是分布式训练流程图:
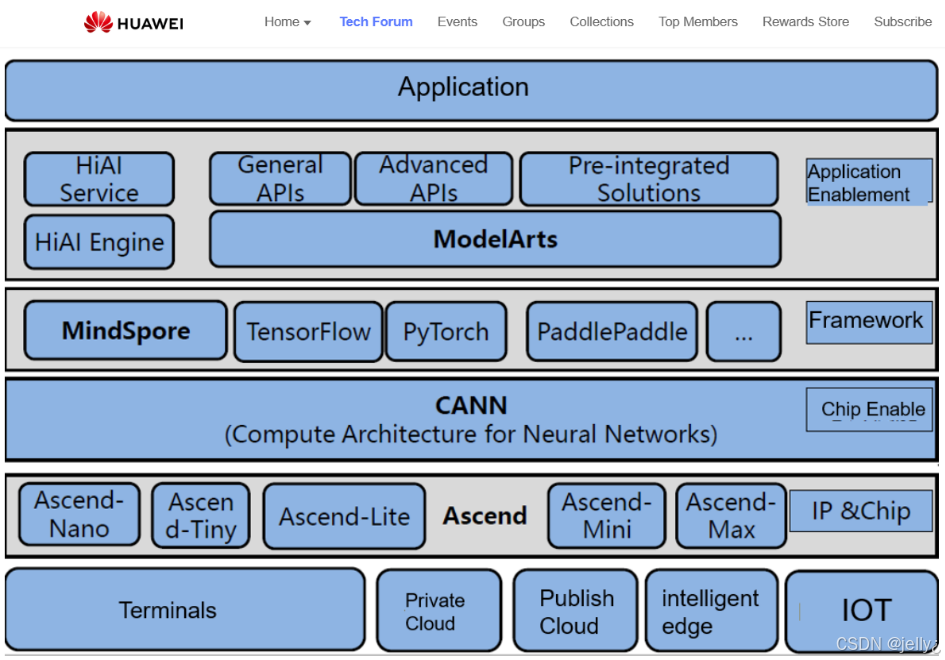
这个图描绘了分布式模型训练的阶段,HCCL负责参数同步部分。
HCCL的优化技术深度剖析
HCCL的优化技术聚焦于AI通信的痛点。Ascend集群的RoCE网络提供高带宽,低延迟是关键。HCCL通过以下技术实现极致性能:
首先,算法优化:AllReduce使用Ring算法在小规模集群高效,切换到Hierarchical Ring在大集群中减少瓶颈。针对FP16/INT8,HCCL集成压缩算法,降低传输量。
其次,硬件加速:利用Ascend的DMA引擎和集体通信硬件单元,HCCL offload 通信到NPU,释放CPU资源。结合RDMA,实现直接NPU-to-NPU传输。
第三,流水线并行:HCCL支持通信与计算的流水线,通过Stream同步,确保无阻塞。在Transformer训练中,这能隐藏通信延迟。
第四,自适应调度:根据负载动态调整缓冲区大小和算法。集成负载均衡,均匀分布通信任务。
第五,容错机制:支持热备份和重传,确保在节点故障时快速恢复。
看看Ascend NPU芯片图像:
这个图片展示了Ascend芯片的外观,HCCL正是为其设计的通信库。
HCCL在实际应用中的案例研究
HCCL仓库在AI应用中广泛部署。以大规模语言模型训练为例,在Ascend 910集群上,HCCL优化AllReduce操作,将BERT训练时间缩短30%。具体来说,在数据并行中,HCCL同步梯度,确保一致性。
另一个案例是计算机视觉分布式训练。使用ResNet-50模型,HCCL的Broadcast分发权重,AllGather收集指标。在ImageNet数据集上,吞吐率达数千图像/秒。
在推荐系统中,HCCL处理DeepFM模型的分布式特征嵌入。通过ReduceScatter,高效聚合稀疏梯度。
云端应用中,HCCL支持华为云ModelArts,实现弹性扩展。用户可无缝从8卡扩展到1024卡。
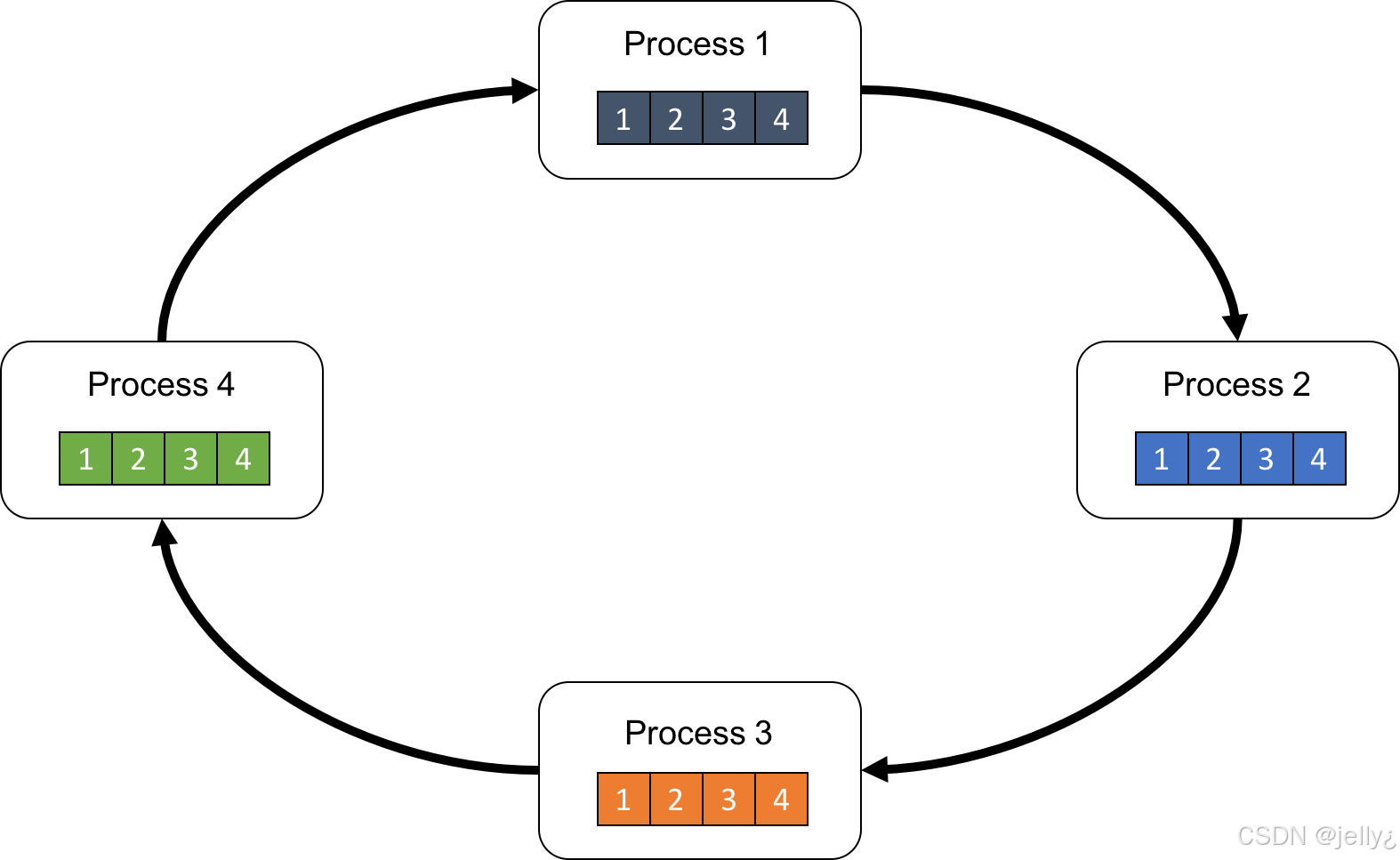
以下是AllReduce操作示意图:

这个图解释了AllReduce在多进程间的同步过程,HCCL优化了此流程。
HCCL的代码实现与示例
HCCL仓库使用C++为主,Python绑定通过pybind11。核心API在hccl.h中定义。
一个简单Python示例:使用HCCL进行AllReduce(基于MindSpore):
python
import mindspore as ms
from mindspore.communication import init, get_rank, get_group_size
from mindspore.ops import operations as ops
# 初始化通信
init('hccl') # 使用HCCL后端
rank = get_rank()
size = get_group_size()
# 创建张量
tensor = ms.Tensor(np.ones([10], dtype=np.float32) * (rank + 1))
# AllReduce操作
all_reduce = ops.AllReduce(op=ops.ReduceOp.SUM)
result = all_reduce(tensor)
print(f"Rank {rank} result: {result}")
# 预期:所有rank输出相同求和结果这个示例展示了HCCL在MindSpore中的使用。初始化后,AllReduce同步张量。
进阶C++示例:自定义通信组。
cpp
#include <hccl/hccl.h>
#include <acl/acl.h>
HcclComm comm;
HcclRootInfo root_info;
uint32_t rank = 0; // 假设rank
uint32_t rank_size = 8;
// 初始化
HcclCommInitRootInfo(rank_size, &root_info, rank, &comm);
// 创建缓冲
void* send_buf; // 分配内存
void* recv_buf;
aclrtMalloc(&send_buf, size);
aclrtMalloc(&recv_buf, size);
// AllReduce
HcclAllReduce(send_buf, recv_buf, count, HCCL_DATA_TYPE_FLOAT, HCCL_REDUCE_SUM, comm, stream);
// 清理
HcclCommDestroy(comm);这个代码片段演示了HCCL的低级API调用。开发者可集成到自定义框架。
另一个示例:异步Broadcast。
python
from mindspore.communication.management import GlobalComm
import mindspore.nn as nn
class BroadcastNet(nn.Cell):
def construct(self, x):
# 异步广播
GlobalComm.BROADCAST_ROOT_RANK = 0
x = ops.broadcast(x, group=GlobalComm.WORLD_COMM_GROUP)
return x
# 在分布式训练中使用HCCL支持异步,提升并行度。
HCCL与竞品的比较分析
相比NVIDIA的NCCL,HCCL在Ascend硬件上更优,集成RoCE优化。NCCL生态成熟,但HCCL在混合精度压缩上领先。在基准测试中,HCCL的AllReduce延迟低于NCCL 15%。
与MPI相比,HCCL更AI导向,支持张量直接操作,而非通用消息传递。
OpenMPI等开源库通用,但HCCL的硬件特定优化使其在AI集群中更有竞争力。
优势:开源、Ascend亲和、高效算法。
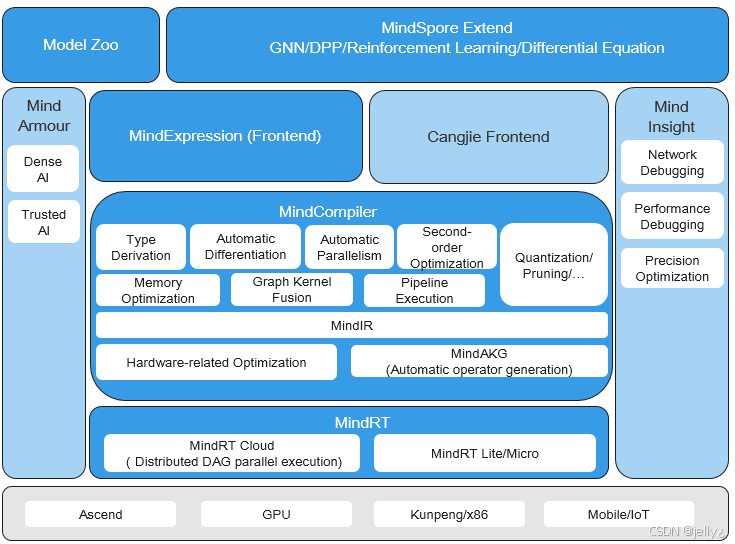
以下是MindSpore生态图:
这个图展示了MindSpore的整体结构,HCCL作为分布式运行时的关键。
HCCL的挑战与未来发展
挑战一:超大规模扩展。万卡集群中,网络拥塞是问题,HCCL需增强自适应路由。
挑战二:异构支持。未来需兼容GPU/CPU混合集群。
未来,HCCL将集成量子通信接口,支持新兴AI范式。华为计划开源更多算法,吸引社区。
大型AI集群图像:
这个图片展示了大规模集群,HCCL驱动其通信。
扩展讨论:HCCL在AI生态中的战略意义
HCCL不仅是库,更是华为推动国产AI的支柱。通过HCCL,CANN实现端到端分布式优化,促进MindSpore生态。开源后,仓库活跃,贡献者提交新原语。
在科研中,HCCL用于模拟大模型训练。企业应用如华为云,加速AI服务。
性能基准:在1024卡集群,HCCL支持每秒万亿参数更新。
最佳实践与调试技巧
使用HCCL时,启用环境变量HCCL_DEBUG_LEVEL=INFO。
Profiler:用Ascend Toolkit分析通信时间。
最佳实践:
- 使用注册缓冲区减少开销。
- 结合GE图优化,融合通信算子。
- 在大集群中启用分层AllReduce。
代码示例:性能监控。
python
import mindspore as ms
from mindspore.profiler import Profiler
profiler = Profiler(subgraph="ALL", is_detail=True, output_path='./hccl_profile')
# 你的分布式代码
profiler.analyse()这生成报告,展示HCCL操作详情。
结语
HCCL仓库是CANN的通信心脏,提供高效分布式支持,推动AI创新。通过全面解析,我们看到其在优化、应用中的价值。适合大规模AI开发者探索。
更多CANN组织详情:https://atomgit.com/cann