在前文中,我们分析了 GPU VM、aperture 以及 libhsakmt 实现的不同类型 apertures。本文将深入探讨更细粒度的地址空间管理单元:vm_object。至此,整个VM空间的层次关系呼之欲出,用图例展示一下。
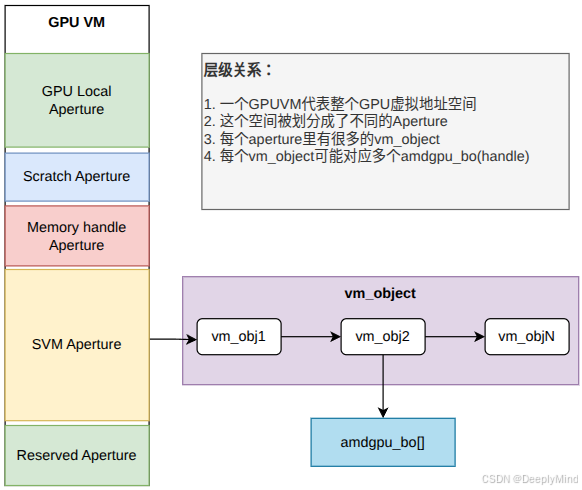
在详细介绍 vm_object 的概念和实现之前,我们首先需要理解 libhsakmt 中定义的内存分配标志结构 HsaMemFlags,以及它如何影响内存的分配、映射和管理。
1. 概述
HsaMemFlags 是一个位域结构体,定义在 hsakmttypes.h 中,用于精确控制异构系统中内存的分配行为和属性。它的设计体现了 ROCm 异构计算环境中对内存管理的细粒度控制需求,涵盖了从基本的分页策略到高级的原子操作支持等多个维度。
1.1 结构定义
c
typedef struct _HsaMemFlags {
union {
struct {
unsigned int NonPaged : 1; // 不可分页内存
unsigned int CachePolicy : 2; // 缓存策略
unsigned int ReadOnly : 1; // 只读内存
unsigned int PageSize : 2; // 页面大小
unsigned int HostAccess : 1; // CPU 访问权限
unsigned int NoSubstitute : 1; // 禁止内存替换
unsigned int GDSMemory : 1; // GDS 内存分配
unsigned int Scratch : 1; // Scratch 内存
unsigned int AtomicAccessFull : 1; // 完整原子操作
unsigned int AtomicAccessPartial: 1; // 部分原子操作
unsigned int ExecuteAccess : 1; // 可执行内存
unsigned int CoarseGrain : 1; // 粗粒度一致性
unsigned int AQLQueueMemory : 1; // AQL 队列内存
unsigned int FixedAddress : 1; // 固定地址分配
unsigned int NoNUMABind : 1; // 不绑定 NUMA 节点
unsigned int Uncached : 1; // 非缓存(细粒度)
unsigned int NoAddress : 1; // 仅分配 VRAM
unsigned int OnlyAddress : 1; // 仅分配地址空间
unsigned int ExtendedCoherent : 1; // 扩展一致性
unsigned int GTTAccess : 1; // GART 映射
unsigned int Contiguous : 1; // 连续 VRAM
unsigned int ExecuteBlit : 1; // Blit 内核对象
unsigned int QueueObject : 1; // 队列对象
unsigned int Reserved : 7; // 预留位
} ui32;
HSAuint32 Value;
};
} HsaMemFlags;2. 标志位详解
2.1 基本内存属性
| 标志位 | 说明 | 使用场景 |
|---|---|---|
NonPaged |
分配不可分页内存,避免页面错误 | GPU 操作需要确定性访问延迟,VRAM 分配 |
CachePolicy |
缓存策略:HSA_CACHING_CACHED、NONCACHED、WRITECOMBINED |
影响 CPU/GPU 访问性能,根据访问模式选择 |
ReadOnly |
标记内存为只读,保护数据不被修改 | 常量缓冲区、代码段、共享只读数据 |
PageSize |
页面大小:4KB/64KB/2MB/1GB | 大页面减少 TLB miss,提升大缓冲区性能 |
2.2 访问控制
| 标志位 | 说明 | 使用场景 |
|---|---|---|
HostAccess |
控制 CPU 是否可访问该内存 | 未设置时内存仅 GPU 可见,提升安全性和性能 |
NoSubstitute |
请求的内存类型不可用时,禁止回退到系统内存 | 严格的内存分配语义,确保使用特定内存类型 |
ExecuteAccess |
标记内存用于可执行代码或队列 | 影响页属性设置,队列内存必须设置此标志 |
2.3 特殊内存区域
| 标志位 | 说明 | 使用场景 |
|---|---|---|
GDSMemory |
从 Global Data Share (GDS) 堆分配 | GPU 间同步、原子操作、跨 CU 通信 |
Scratch |
从 GPU Scratch 区域分配 | 内核执行时的临时数据、寄存器溢出 |
AQLQueueMemory |
标记为 AQL 队列内存 | 确保队列内存最优位置和对齐 |
GTTAccess |
映射到 GART (Graphics Address Remapping Table) | MES、图形或 SDMA 操作需要 GTT 空间 |
2.4 原子操作支持
| 标志位 | 说明 | 使用场景 |
|---|---|---|
AtomicAccessFull |
支持完整原子操作集,APU 使用 ATC 路径 | 需要所有原子操作的系统内存访问 |
AtomicAccessPartial |
支持部分原子操作(PCIe Atomics) | 独立 GPU 通过 PCIe 的有限原子操作(SWAP/CAS/FetchAdd) |
ExtendedCoherent |
原子指令的系统级一致性 | 确保跨所有设备的原子操作一致性 |
2.5 一致性模型
| 标志位 | 说明 | 使用场景 |
|---|---|---|
CoarseGrain |
粗粒度一致性,仅在同步点强制一致性 | 减少同步开销,适合大多数 GPU 计算场景 |
Uncached |
细粒度分配的非缓存内存 | A+A 平台控制缓存行为,细粒度内存访问 |
2.6 高级分配控制
| 标志位 | 说明 | 使用场景 |
|---|---|---|
FixedAddress |
在指定虚拟地址分配内存 | 互操作场景、固定地址布局需求 |
NoNUMABind |
不绑定到特定 NUMA 节点 | OS 灵活分配,负载均衡优化 |
NoAddress |
分配 VRAM 但不分配虚拟地址,返回句柄 | 仅需内存句柄的场景,延迟地址分配 |
OnlyAddress |
仅分配虚拟地址空间,不分配物理内存 | 地址预留、分阶段内存分配 |
Contiguous |
分配连续的 VRAM | 某些硬件特性或 DMA 传输要求 |
ExecuteBlit |
用于 Blit 内核对象 | 图形位块传输操作 |
QueueObject |
AQL 队列对象,用于 CPU 访问读指针 | Windows 平台队列管理 |
3. 典型使用场景与代码示例
3.1 GPU 计算缓冲区
为 GPU 计算分配一个 CPU/GPU 共享的缓冲区:
c
HsaMemFlags flags = {0};
flags.ui32.NonPaged = 1; // 不可分页
flags.ui32.CachePolicy = HSA_CACHING_CACHED; // 启用缓存
flags.ui32.PageSize = HSA_PAGE_SIZE_4KB; // 4KB 页
flags.ui32.HostAccess = 1; // CPU 可访问
flags.ui32.CoarseGrain = 1; // 粗粒度一致性标志位选择说明:
NonPaged = 1:GPU 需要确定性访问,避免页面错误CachePolicy = CACHED:CPU 会频繁访问,启用缓存提升性能HostAccess = 1:CPU 需要读写数据CoarseGrain = 1:减少同步开销,在显式同步点保证一致性
3.2 仅 GPU 访问的 VRAM
分配高性能的纯 GPU 本地内存:
c
HsaMemFlags flags = {0};
flags.ui32.NonPaged = 1; // VRAM 必须不可分页
flags.ui32.HostAccess = 0; // CPU 不访问
flags.ui32.PageSize = HSA_PAGE_SIZE_64KB; // 大页面减少 TLB miss
flags.ui32.CoarseGrain = 1;性能优化点:
HostAccess = 0:避免 CPU aperture 映射开销PageSize = 64KB:大页面提升 GPU 访问效率- VRAM 访问带宽远高于系统内存
3.3 AQL 队列内存
为 HSA 队列分配专用内存:
c
HsaMemFlags flags = {0};
flags.ui32.NonPaged = 1;
flags.ui32.HostAccess = 1; // CPU 写入命令包
flags.ui32.ExecuteAccess = 1; // 可执行内存
flags.ui32.AQLQueueMemory = 1; // 队列专用标志
flags.ui32.CoarseGrain = 1;
flags.ui32.PageSize = HSA_PAGE_SIZE_4KB;关键标志:
ExecuteAccess = 1:队列内存必须设置可执行属性AQLQueueMemory = 1:KFD 确保最优位置和对齐
3.4 原子操作内存(APU)
在 APU 上分配支持完整原子操作的内存:
c
HsaMemFlags flags = {0};
flags.ui32.NonPaged = 1;
flags.ui32.HostAccess = 1;
flags.ui32.AtomicAccessFull = 1; // 完整原子操作支持
flags.ui32.PageSize = HSA_PAGE_SIZE_4KB;APU vs 独立 GPU:
- APU:
AtomicAccessFull使用 ATC 路径,支持所有原子操作 - 独立 GPU:使用
AtomicAccessPartial,仅支持 PCIe 原子操作(SWAP/CAS/FetchAdd)
3.5 固定地址分配(互操作)
在特定地址分配内存,用于与其他组件互操作:
c
HsaMemFlags flags = {0};
flags.ui32.NonPaged = 1;
flags.ui32.FixedAddress = 1; // 固定地址分配
flags.ui32.HostAccess = 1;3.6 两阶段分配(NoAddress + OnlyAddress)
高级场景:分离物理内存和虚拟地址分配
c
// 阶段 1:分配 VRAM,不分配虚拟地址
HsaMemFlags flags1 = {0};
flags1.ui32.NonPaged = 1;
flags1.ui32.NoAddress = 1; // 仅物理内存,返回句柄
// 阶段 2:为句柄分配虚拟地址空间
HsaMemFlags flags2 = {0};
flags2.ui32.OnlyAddress = 1; // 仅虚拟地址4. 标志位组合规则与限制
4.1 互斥标志
以下标志位不能同时设置:
| 组合 | 原因 |
|---|---|
CoarseGrain + ExtendedCoherent |
一致性模型冲突 |
ExtendedCoherent + Uncached |
一致性与缓存策略冲突 |
NoAddress + OnlyAddress |
分配语义冲突 |
实现中的检查:
c
if ((MemFlags.ui32.CoarseGrain && MemFlags.ui32.ExtendedCoherent) ||
(MemFlags.ui32.ExtendedCoherent && MemFlags.ui32.Uncached))
return HSAKMT_STATUS_INVALID_PARAMETER;
if (MemFlags.ui32.OnlyAddress && MemFlags.ui32.NoAddress)
return HSAKMT_STATUS_INVALID_PARAMETER;4.2 特殊内存区域限制
GDS 内存:
- 必须:
GDSMemory = 1 - 禁止:
HostAccess = 1(CPU 不能直接访问 GDS) - 建议:其他标志(除
NoSubstitute)应为 0
Scratch 内存:
- 必须:
Scratch = 1 - 禁止:
HostAccess = 1 - 限制:不支持
Alignment参数
4.3 页面大小与对齐
c
page_size = PageSizeFromFlags(MemFlags.ui32.PageSize);
// 4KB, 64KB, 2MB, 1GB
// 对齐要求
if (Alignment && (Alignment < page_size || !POWER_OF_2(Alignment)))
return HSAKMT_STATUS_INVALID_PARAMETER;对齐值必须:
- ≥ 指定的页面大小
- 是 2 的幂
- 如果为 0,使用最小对齐(页大小)
5. 性能考虑与最佳实践
5.1 页面大小选择
| 页面大小 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| 4KB | 小缓冲区、默认分配 | 灵活、内存利用率高 | TLB miss 率高 |
| 64KB | 中等缓冲区 | 平衡性能和内存使用 | 轻微内存浪费 |
| 2MB | 大缓冲区(几百 MB) | TLB miss 显著减少 | 内存对齐要求高 |
| 1GB | 超大缓冲区(几 GB) | 极少 TLB miss | 内存碎片风险 |
推荐:
- 默认使用 4KB
- 缓冲区 > 64MB 时考虑 64KB 页
- 缓冲区 > 512MB 时考虑 2MB 页
5.2 缓存策略选择
c
// 定义在 hsakmttypes.h
typedef enum _HSA_CACHING_TYPE {
HSA_CACHING_CACHED = 0, // 完全缓存
HSA_CACHING_NONCACHED = 1, // 完全非缓存
HSA_CACHING_WRITECOMBINED = 2 // 写合并
} HSA_CACHING_TYPE;选择指南:
- Cached:CPU 频繁读写、数据局部性好
- NonCached:CPU 很少访问、需要强一致性
- WriteCombined:CPU 主要写入、GPU 主要读取
5.3 一致性模型权衡
CoarseGrain(推荐):
- 优势:性能开销低,适合大多数场景
- 要求:在同步点(fence、barrier)显式同步
- 使用:
flags.ui32.CoarseGrain = 1
FineGrain(谨慎使用):
- 优势:自动保证一致性,编程简单
- 劣势:性能开销高,需要硬件支持(ATC)
- 使用:
CoarseGrain = 0+Uncached = 0
5.4 NUMA 优化
在多 NUMA 节点系统上:
c
// 绑定到特定 NUMA 节点(默认行为)
HsaMemFlags flags = {0};
flags.ui32.NoNUMABind = 0; // 绑定到 PreferredNode
// 允许任意 NUMA 节点
flags.ui32.NoNUMABind = 1; // OS 灵活分配性能影响:
- 绑定:保证局部性,性能可预测
- 不绑定:灵活性高,可能跨节点访问
6. 常见问题与调试
6.1 标志位组合错误
常见错误:
- 同时设置互斥标志(如
CoarseGrain+ExtendedCoherent) - 页面大小与对齐要求不匹配
- 特殊内存区域标志配置错误(如 GDS、Scratch)
解决方法:
- 参考第 4 节的组合规则与限制
- 检查标志位的依赖关系
- 使用简化的标志组合进行测试
6.2 性能问题诊断
TLB miss 过多:
- 症状:GPU 计算性能低于预期
- 解决:增大页面大小(64KB 或 2MB)
缓存一致性开销:
- 症状:频繁同步时性能下降
- 解决:使用
CoarseGrain并优化同步点
跨节点内存访问:
- 症状:APU + dGPU 系统性能不稳定
- 解决:检查
NoNUMABind设置,确保内存靠近访问者
7. 总结
HsaMemFlags 是 ROCm 异构内存管理的核心抽象,它通过 23 个标志位提供了对内存分配行为的精确控制。理解这些标志位的含义、组合规则和性能影响,是深入理解 libhsakmt 内存管理机制的基础。
关键要点:
- 标志位分类:基本属性、访问控制、特殊区域、原子操作、一致性模型、高级控制
- 一致性模型 :优先使用
CoarseGrain以获得更好性能 - 页面大小:根据缓冲区大小选择合适的页面大小
- 原子操作:APU 和独立 GPU 的原子支持机制不同
- 组合规则:注意互斥标志,遵循特殊内存区域的限制
通过合理配置 HsaMemFlags,可以为 ROCm 应用实现高效、灵活的内存管理策略,为后续的内存分配、映射、注册操作奠定基础。