
简介:该项目详细介绍了如何使用DataX框架实现MySQL数据库与Hive数据仓库之间的高效数据同步。DataX支持多种数据源,并在项目"yinian_hive_increase"中详细阐述了配置reader和writer、数据转换、加载以及Java编程和性能优化等关键步骤,为大数据环境下的数据迁移提供了完整解决方案。
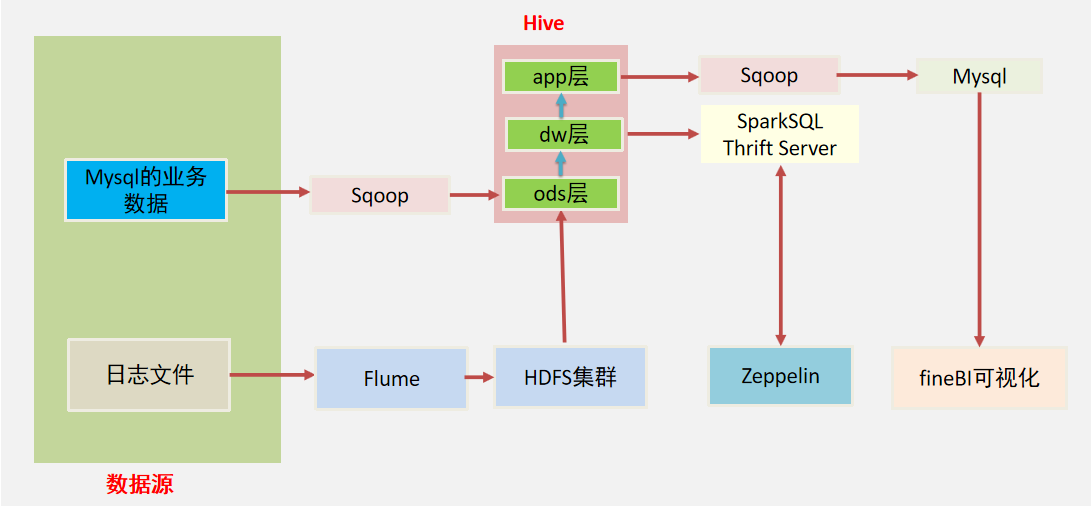
1. DataX框架介绍
DataX是由阿里巴巴开源的一个高效稳定的大数据同步工具,它能够支持多种数据源,如MySQL、Hive等,并按照用户指定的规则进行数据同步。DataX的设计目标是构建一个易于扩展、高效稳定的统一数据同步平台,以满足日益增长的大数据同步需求。
DataX的设计哲学是简单易用、高效稳定和易于扩展。简单易用体现在其提供了简单直观的配置文件,用户只需要编写配置文件,就可以实现数据同步。高效稳定则体现在其优化的数据处理算法和容错机制,确保数据同步的高效性和稳定性。易于扩展则体现在其插件化的架构设计,用户可以编写自定义插件来实现特定的数据同步需求。
DataX的核心组件包括Reader插件、Writer插件和Channel插件。Reader插件负责从源数据源读取数据,Writer插件负责将数据写入目标数据源,而Channel插件则负责Reader插件和Writer插件之间的数据传输。这种插件化的架构设计使得DataX可以支持多种数据源,且易于扩展。
在大数据生态中,DataX作为一个数据同步工具,扮演着重要的角色。它不仅可以用于数据仓库的构建,还可以用于数据备份、数据迁移、数据集成等多种场景。DataX的高效稳定性和易于扩展性,使得它成为了大数据生态中不可或缺的一部分。
2. 数据源介绍
2.1 MySQL数据库介绍
MySQL是一个流行的开源关系型数据库管理系统,其主要特性包括高性能、高可靠性和易用性。作为数据源的一部分,MySQL在数据同步的场景中扮演了关键角色。在深入探索如何将MySQL数据同步到Hive之前,我们需要对MySQL数据库有一个全面的了解。
MySQL架构
MySQL的架构分为多个层次,主要包括:连接层、服务层、引擎层和存储层。每个层次都有其独特的功能,它们共同确保了MySQL能够高效地存储和管理数据。
- 连接层 :负责与客户端建立连接,并管理多线程环境。
- 服务层 :包含查询解析器、优化器和缓存,这些组件共同处理SQL语句的执行。
- 引擎层 :负责与存储引擎交互,MySQL支持多种存储引擎,如InnoDB、MyISAM等。
- 存储层 :涉及数据文件的存储和索引文件的创建。
存储引擎
存储引擎是MySQL的特色之一,它决定了表的存储方式和对数据进行操作的特性。例如:
- InnoDB :支持事务处理、行级锁定和外键,适合于高并发场景。
- MyISAM :文件系统管理,读取速度快,适合分析和报表应用。
索引机制
索引是数据库中用来加速数据检索的结构。MySQL支持多种索引类型,比如B-Tree索引、哈希索引、全文索引等。索引的使用可以显著提高查询效率,但同时也会占用额外的存储空间,并可能影响数据的插入、更新和删除操作。
事务处理
MySQL支持事务,事务是一个或多个操作序列,它们作为一个整体单元执行。事务具有ACID属性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
2.2 Hive数据仓库介绍
Hive是一个建立在Hadoop之上的数据仓库工具,它允许用户使用类似SQL的语言(HiveQL)来查询存储在HDFS上的数据。本节将从Hive的基本概念、架构、执行机制以及数据存储、查询和分析等方面进行详细介绍。
Hive架构
Hive的架构主要分为三个部分:用户接口层、编译器层和执行层。
- 用户接口层 :提供了多种查询接口,如Hive命令行界面、Web界面和JDBC/ODBC等。
- 编译器层 :包括解析器、编译器和优化器,它们负责将HiveQL语句转换为可执行的任务。
- 执行层 :将编译器层生成的执行计划通过Hadoop的MapReduce、Tez或Spark等引擎执行。
执行机制
Hive的数据处理流程通常涉及到以下步骤:
- 用户提交HiveQL查询。
- 解析器对查询进行语法分析,并构建一个抽象语法树(AST)。
- 优化器根据AST生成一个逻辑执行计划,并进行查询优化。
- 编译器将逻辑执行计划转换为MapReduce、Tez或Spark等物理执行计划。
- 执行引擎执行物理执行计划,并将结果返回给用户。
数据存储、查询和分析
Hive将数据存储在Hadoop的分布式文件系统HDFS中,通常以列存储的格式如ORCFile、Parquet等存储,这些格式优化了大数据的存储和查询性能。HiveQL作为一种数据查询语言,支持数据的增删改查操作,同时还提供了内置函数、UDF(用户定义函数)和UDAF(用户定义聚合函数)等来支持复杂的数据分析需求。
Hive的查询操作最终会被编译成MapReduce作业或其他计算框架的任务,以便在Hadoop集群上并行执行。这一过程隐藏了底层的复杂性,使得用户可以像使用传统数据库那样使用Hive进行数据查询和分析。
接下来,我们将继续探索如何将MySQL数据同步到Hive,以满足大数据分析的需求。在下一章节,我们将从同步流程的概览开始,详细探讨整个数据同步的实现细节。
3. MySQL到Hive数据同步流程
3.1 同步流程概览
MySQL到Hive的数据同步是一个将关系型数据库数据迁移到大数据存储系统的典型场景。该过程涉及到数据的提取、转换和加载(ETL),在这一系列操作中,DataX扮演着至关重要的角色。同步流程概览涉及的主要步骤包括:
- 数据源的选择 :首先,需要确定数据源,这里是MySQL数据库,以及目标数据仓库Hive。
- 同步任务的创建 :在DataX中创建一个同步任务,定义源数据库和目标数据库的连接信息,以及需要同步的数据集。
- 数据抽取 :DataX作业启动后,从MySQL数据库中抽取数据。
- 数据转换 :根据需要对数据进行必要的转换处理,以满足Hive表结构的要求。
- 数据加载 :将转换后的数据加载到Hive表中。
- 数据校验 :最后,对同步后的数据进行校验,确保数据的准确性和完整性。
同步流程可以通过DataX的Web界面或者命令行方式启动,用户需要准备好配置文件,指明源端和目标端的配置细节以及同步策略。
3.2 数据同步的实现细节
3.2.1 DataX作业的配置文件编写
DataX作业通过JSON格式的配置文件来指定同步任务的详细信息。配置文件通常包含三个主要部分:任务配置(task)、数据源配置(dataSource)和数据同步规则(reader、writer)。
json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"*"
],
"connection": [
{
"table": [
"your_table"
],
"jdbcUrl": [
"your_mysql_jdbc_url"
],
"password": [
"your_mysql_password"
],
"user": [
"your_mysql_user"
]
}
]
}
},
"writer": {
"name": "hivewriter",
"parameter": {
"defaultFS": "hdfs://your_hdfs_name_node:port",
"path": "/your_hive_table_path",
"table": "your_hive_table",
"column": [
"*"
],
"fieldDelimiter": "\\x01",
"compress": "true",
"encoding": "UTF-8",
"writeMode": "insert"
}
}
}
]
},
"setting": {
"speed": {
"channel": 1
}
}
}3.2.2 任务的调度与管理
DataX提供了一个主控制模块来管理和调度数据同步任务。一旦配置文件准备就绪,用户可以通过DataX提供的命令行接口启动同步任务:
shell
python bin/datax.py job.json3.2.3 错误处理机制
在数据同步过程中,可能会遇到各种错误,比如数据格式不匹配、数据量过大导致的内存溢出等。DataX内部实现了一套错误处理机制,可以指定错误记录的最大数目,超过这个数目后,同步任务失败。同时,DataX也提供了日志记录功能,方便进行问题的跟踪和调试。
3.2.4 同步过程中的问题及解决方案
在数据同步过程中,常见的问题包括:
- 数据一致性问题 :确保从MySQL抽取的数据与Hive中的数据是一致的,需要合理的事务控制和数据校验策略。
- 性能瓶颈问题 :同步大数据量时可能会遇到性能瓶颈,优化策略包括调整DataX作业的并发数、调整Hive的执行器配置等。
- 数据类型转换问题 :不同的数据源支持的数据类型可能不一致,需要在数据同步时进行适当的类型转换。
3.3 数据同步流程的深入分析
3.3.1 数据抽取阶段的深入分析
在MySQL数据库抽取数据时,需要关注读取效率。DataX支持多线程并发读取,通过合理配置 task 中的 channel 参数,可以显著提升抽取速度。
3.3.2 数据转换阶段的深入分析
数据转换阶段是整个同步流程中最为灵活的部分。DataX支持通过 transform 字段在配置文件中定义复杂的数据转换逻辑,例如数据的映射、清洗、过滤等。开发者可以依据具体需求编写对应的转换逻辑。
3.3.3 数据加载阶段的深入分析
数据加载到Hive的过程包括数据的写入和数据的最终存储。DataX的 hivewriter 插件支持多种数据存储策略,包括批量加载和分批加载,以及HDFS的压缩和编码设置等,开发者可以根据实际需要进行选择。
通过上述章节,读者可以对从MySQL到Hive的数据同步流程有了全面而深入的理解,掌握数据同步的每个环节,并对可能出现的问题有了预见性和解决策略。在接下来的章节中,我们将继续深入探讨DataX的配置与数据源配置,以及数据转换与加载过程的详细策略。
4. DataX配置与数据源配置
4.1 DataX配置文件详解
DataX配置文件是整个数据同步任务的灵魂,它包含了从数据源抽取、转换到加载的整个过程的详细配置。配置文件通常由多个JSON对象组成,每个对象定义了一个作业(job)、通道(channel)或者数据源(reader和writer)。
4.1.1 配置文件结构
一个典型的DataX配置文件可以分为以下几个部分:
-
job :定义一个同步作业的配置,比如作业的名称、版本和描述。
-
content :定义了具体的同步任务内容,是同步作业的核心,通常包含多个
reader和writer配置。 -
reader :配置数据源读取器,比如
mysqlreader、hive等。 -
writer :配置数据目标写入器,与读取器对应,比如
mysqlwriter、hive等。 -
channel :定义数据传输的通道,它指定了同步任务中使用的核心线程数。
4.1.2 配置文件编写要点
- 一致性 :配置文件中的数据源、通道、作业配置需要保持一致性。每个
reader与writer需要在channel中找到对应的channel标识。 - 简洁性 :配置尽量简洁明了,避免冗余的配置项。
- 容错性 :合理配置错误处理策略,比如
errorlimit、replace等。
4.1.3 示例配置解析
以下是一个简单的DataX配置文件示例:
json
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"table": ["table1"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/databaseName"],
"username": "username",
"password": "password"
}
]
}
},
"writer": {
"name": "hivewriter",
"parameter": {
"column": ["*"],
"nullMode": "null",
"connection": [
{
"table": ["table1"],
"defaultFS": "hdfs://namenode:9000",
"hdfsConfig": {
"fs.defaultFS": "hdfs://namenode:9000"
},
"path": "/user/hive/warehouse/databaseName.db/table1",
"writeMode": "append"
}
]
}
}
}
]
}
}上述配置定义了一个将MySQL数据库同步到Hive的作业,其中 mysqlreader 读取指定表的数据, hivewriter 将读取到的数据写入到Hive表中。
4.2 MySQL和Hive数据源配置
4.2.1 MySQL配置详细指导
在DataX中配置MySQL数据源需要正确填写 connection 部分,包含如下参数:
jdbcUrl:标准的JDBC连接字符串,用于指定MySQL的访问路径。username:用于访问MySQL数据库的用户名。password:对应用户名的密码。table:指定同步的MySQL表。
4.2.2 Hive配置详细指导
配置Hive数据源时,重要配置项包括:
defaultFS:HDFS的默认文件系统地址。hdfsConfig:用于存放HDFS的配置信息。path:指定HDFS上的文件路径,通常是Hive表所在的路径。writeMode:写入模式,常见的写入模式有append和nonConflict。
4.2.3 示例配置:MySQL到Hive
假设我们有如下配置需求:
- 从MySQL的
database1数据库的table1表同步数据到Hive的database2.table1。
对应的DataX配置文件中的数据源配置如下:
json
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"table": ["table1"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/database1?useUnicode=true"],
"username": "root",
"password": "root"
}
]
}
},
"writer": {
"name": "hivewriter",
"parameter": {
"column": ["*"],
"nullMode": "null",
"connection": [
{
"table": ["table1"],
"defaultFS": "hdfs://namenode:9000",
"hdfsConfig": {
"fs.defaultFS": "hdfs://namenode:9000"
},
"path": "/user/hive/warehouse/database2.db/table1",
"writeMode": "append"
}
]
}
}
}这个配置文件详细地说明了如何将MySQL作为数据源,Hive作为目标仓库进行数据同步。
5. 数据转换与加载过程
5.1 数据转换处理
在大数据同步过程中,数据转换是一个至关重要且复杂的过程。DataX提供了多种数据转换的处理方式,以确保从源数据到目标数据的有效迁移,同时保障数据的准确性和一致性。
字段映射与数据类型转换
数据同步的第一步通常是字段映射,这涉及将源数据中的字段对应到目标数据库中的字段。字段映射可以是一对一的,也可以是一对多或多对一的关系。字段映射通常在DataX的配置文件中进行设置。
json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id", "name", "age"],
"connection": [
{
"table": ["student"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/school?useUnicode=true"]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"path": "/data/hivedata/students",
"defaultFS": "hdfs://localhost:9000",
"fileType": "orc",
"column": [
{"name": "id", "type": "string"},
{"name": "name", "type": "string"},
{"name": "age", "type": "long"}
],
"writeMode": "append"
}
},
"setting": {
"speed": {
"channel": 1
}
},
"channel": {
"readerChannel": {
"name": "channel-0",
"column": ["id", "name", "age"]
}
}
}
]
}
}在上述配置示例中,我们定义了 reader 和 writer ,指定了相应的字段以及它们在MySQL和Hive中的映射关系。此外,DataX支持数据类型转换,当源和目标字段类型不匹配时,可以在此进行转换设置。
数据清洗与数据聚合
数据同步不是简单的数据拷贝,而是需要通过清洗和聚合等操作保证数据的质量。DataX提供了一些内置的转换操作,例如空值处理、类型转换、分组聚合等。对于更复杂的清洗和聚合需求,可以编写自定义的转换脚本。
json
{
"job": {
"setting": {
"errorLimit": {
"record": 100
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id", "name", "age"],
"connection": [
{
"table": ["student"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/school?useUnicode=true"]
}
],
"where": "age > 18"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"path": "/data/hivedata/adults",
"defaultFS": "hdfs://localhost:9000",
"fileType": "orc",
"column": [
{"name": "id", "type": "string"},
{"name": "name", "type": "string"},
{"name": "age", "type": "long"}
],
"writeMode": "append"
}
}
}
]
}
}在上述配置中, reader 配置了 where 条件,这相当于在MySQL中执行了 SELECT * FROM student WHERE age > 18 ,实现了数据清洗。而 writer 的配置指定了数据加载的目标路径。
数据转换的实践应用
为了实现更复杂的数据转换逻辑,DataX支持在配置文件中嵌入自定义的JavaScript脚本进行数据处理。这种机制为开发者提供了极大的灵活性。
json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id", "name", "age"],
"connection": [
{
"table": ["student"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/school?useUnicode=true"]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"path": "/data/hivedata/students",
"defaultFS": "hdfs://localhost:9000",
"fileType": "orc",
"column": [
{"name": "id", "type": "string"},
{"name": "name", "type": "string"},
{"name": "age", "type": "long"},
{"name": "processed_name", "type": "string"}
],
"writeMode": "append"
}
},
"transformer": {
"通道名称": {
"content": [
{
"type": "script",
"parameter": {
"column": ["name", "processed_name"],
"script": "if (record.getName() != null) { record.setProcessedName(record.getName().toUpperCase()); } else { record.setProcessedName(null); }"
}
}
]
}
}
}
]
}
}在上面的配置示例中,我们使用了 transformer 节点来应用JavaScript脚本,将读取的 name 字段转换为大写,存储到新的字段 processed_name 中。
5.2 数据加载策略
数据加载是数据同步的最后一步,它需要将清洗和转换后的数据加载到目标系统中。DataX提供了多种策略,以实现不同的数据加载需求。
批量加载与分批加载
批量加载是将数据一次性加载到目标系统中,它适用于数据量不是特别大的情况。而分批加载则将数据分成多个批次逐步加载,适用于大数据量的场景,能够有效避免大事务导致的性能问题。
json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id", "name", "age"],
"connection": [
{
"table": ["student"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/school?useUnicode=true"]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"path": "/data/hivedata/students",
"defaultFS": "hdfs://localhost:9000",
"fileType": "orc",
"column": [
{"name": "id", "type": "string"},
{"name": "name", "type": "string"},
{"name": "age", "type": "long"}
],
"writeMode": "append"
}
},
"setting": {
"speed": {
"channel": 1,
"bytesPeak": 10485760,
"recordPeak": 10000
}
}
}
]
}
}在上述配置中, setting 节点下的 speed 参数就用于控制批处理的相关设置,例如 channel 、 bytesPeak 和 recordPeak 分别代表通道数量、每批次的字节数峰值和每批次的记录数峰值。
数据分区策略
数据分区是提高数据处理性能和灵活性的有效策略。在数据加载到Hive时,可以利用Hive分区表的功能,按照某些字段进行分区,如按日期分区,从而提高数据查询的效率。
json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id", "name", "age", "register_date"],
"connection": [
{
"table": ["student"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/school?useUnicode=true"]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"path": "/data/hivedata/students",
"defaultFS": "hdfs://localhost:9000",
"fileType": "orc",
"column": [
{"name": "id", "type": "string"},
{"name": "name", "type": "string"},
{"name": "age", "type": "long"},
{"name": "register_date", "type": "string"}
],
"writeMode": "append",
"fieldDelimiter": "\u0001",
"fileIndex": "register_date"
}
}
}
]
}
}在上述示例中, register_date 字段被用作文件索引,这将使得每个分区的数据将被加载到以该日期命名的Hive分区表中。
通过以上的数据转换和加载策略,开发者可以针对不同的场景,灵活地构建高效、稳定的数据同步工作流程。重要的是要理解每种策略的适用场景,并根据实际情况进行优化和调整。
6. Java编程在DataX中的应用及优化
DataX作为一个开源的大数据同步工具,其灵活性不仅体现在配置文件的编写上,还体现在其可编程的特性上。通过Java编程,我们可以实现对DataX的深度定制和功能扩展,进而满足特定的数据同步需求。此外,同步任务的性能优化和监控同样是保证数据同步稳定性和高效性的关键环节。
6.1 Java编程在DataX中的实践
自定义插件开发
DataX框架通过插件机制提供了很强的扩展性。我们可以利用Java编程开发自定义的Reader插件和Writer插件,以支持新的数据源或者特殊的同步逻辑。例如,开发一个新的Reader插件可以包含以下步骤:
- 继承AbstractPlugin类 - 这是所有插件类的基类。
- 实现getPluginName方法 - 返回插件名称。
- 实现prepare方法 - 在这里配置插件。
- 实现split方法 - 将作业分割成多个子任务。
- 实现sync方法 - 实现具体的数据同步逻辑。
java
public class MyCustomReader extends AbstractPlugin {
@Override
public String getPluginName() {
return "mycustomreader";
}
@Override
public void prepare(PluginJobContext context) {
// 插件配置初始化
}
@Override
public List<PluginTask> split(PluginJobContext context, int adviceNumber) {
// 任务分割逻辑
}
@Override
public void sync(PluginTask task) {
// 同步逻辑
}
}编写复杂的转换逻辑
在数据同步过程中,经常会遇到需要进行复杂的数据转换和处理的场景。使用Java编程,我们可以在DataX中编写自定义的Transformer插件,以实现复杂的数据转换逻辑。Transformer插件的实现类似于Reader插件,但主要关注点在于数据行的转换。
利用Java类库丰富DataX的能力
DataX支持Java插件,这意味着我们可以利用Java生态系统中的任何类库来丰富DataX的功能。无论是进行加密、压缩、网络通信还是调用外部API,这些都能通过编写Java插件来实现。
6.2 性能优化与任务监控
硬件资源优化
数据同步任务的性能很大程度上依赖于运行DataX的硬件资源,包括CPU、内存和磁盘I/O。可以通过以下方式进行优化:
- CPU优化 :合理分配CPU资源,减少同步任务之间的资源竞争。
- 内存优化 :优化JVM参数,合理设置内存堆大小。
- 磁盘I/O优化 :使用更快的存储介质,优化磁盘写入策略。
同步策略调整
优化同步策略也是提升DataX性能的关键。可以考虑的策略包括:
- 分批处理 :将大批次的数据同步任务拆分成多个小批次执行,减少单次任务的压力。
- 并行同步 :在可能的情况下,启用多线程或分布式同步,充分利用多核CPU资源。
任务监控和日志分析
监控同步任务的状态,及时发现并解决可能出现的问题,是保证数据同步高效运行的重要环节。使用DataX提供的日志系统和第三方监控工具,可以实现任务的实时监控和历史数据分析。例如:
- 日志级别设置 :合理设置日志级别,记录关键信息的同时避免过量的日志信息干扰。
- 任务状态检查 :定期检查任务的执行状态,及时响应错误和异常。
- 性能指标分析 :分析执行时间、数据吞吐量等指标,找出性能瓶颈。
通过上述实践和优化策略,我们可以进一步挖掘DataX的潜力,使其更好地适应复杂多变的数据同步需求。
简介:该项目详细介绍了如何使用DataX框架实现MySQL数据库与Hive数据仓库之间的高效数据同步。DataX支持多种数据源,并在项目"yinian_hive_increase"中详细阐述了配置reader和writer、数据转换、加载以及Java编程和性能优化等关键步骤,为大数据环境下的数据迁移提供了完整解决方案。