一、概述
在 CFD/FEA 等仿真场景里,我们经常会遇到一种"看起来很朴素、做起来很要命"的需求:
- 一次任务导出上万帧(上万级文件)结果,单帧可能是
.vtu/.vtk; - 需要在浏览器里流畅拖动时间轴、切换物理量、裁剪/切片、对比多视图;
- 数据体量大、用户网络环境复杂,而且还希望多人同时访问。
(这三点,就是我开发时,产品经理提的需求)
【注释:】
1.CFD:Computational Fluid Dynamics,计算流体力学
典型仿真场景:

2.FEA(Finite Element Analysis,有限元分析)
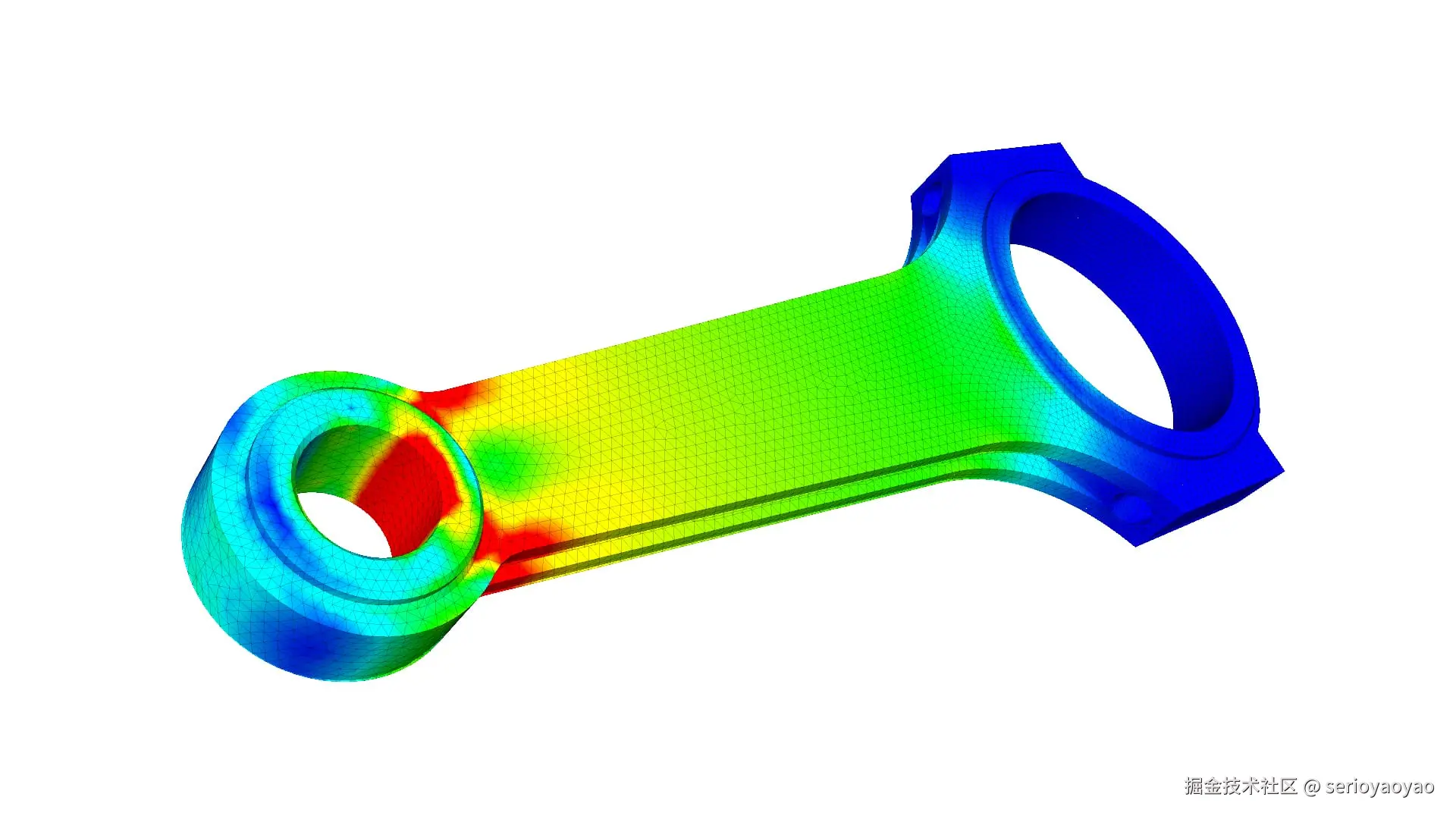
如果把这件事当成"前端把所有文件下载下来,用 WebGL 自己画",基本会踩到:下载、解析、内存、GPU、交互延迟等一系列问题(我最开始接到需求时,就是这样做的,辛辛苦苦做完,遇上上万个文件加载、渲染,直接浏览器卡死😤)
这篇文章分享一个在工程上更稳妥的答案:基于 ParaView 的远程可视化(Remote Rendering)。(遇上浏览器卡顿、卡死后,项目负责人提供了另一个思路,于是开启技术调研、写demo、放入实际项目使用。)
本文基于我在项目中的落地实践:
- 后端使用
pvpython(ParaView 自带 Python)+wslink+paraview.web进行渲染与 RPC; - 前端使用
vite + vue+@kitware/vtk.js的vtkRemoteView接收图像流并转发交互事件; - 对"dev 开发模式"提供了 网关隔离 :每个浏览器连接启动独立的
pvpython子进程,避免多窗口互相覆盖。
你可以把它理解为:
浏览器只负责"看图 + 交互",服务端负责"读数据 + 建管线 + GPU 渲染"。
对"万级文件/时间序列"的科学可视化,最容易规模化的做法往往是:把渲染留在服务端,把交互留在浏览器。
二、为什么"上万级文件"会把常规方案打爆?
先把问题拆开看,"上万级文件可视化"通常同时包含 4 个压力源:
1.I/O 压力
- 文件数量上来以后,目录遍历、排序、打开文件句柄、元数据读取都会变慢。
- 即使单帧不大,上万次打开/关闭也很可观。
2.解析与内存压力
.vtu/.vtk解析成本高,尤其是复杂网格/高阶单元/多数组。- 浏览器内存、GPU 显存都更紧张,稍不注意就崩溃或卡死。
3.网络与带宽压力
- 把数据下发到浏览器意味着:传输成本高、等待时间长、弱网体验差。
4.交互延迟与工程复杂度
- "拖时间轴 + 实时更新画面"对端到端延迟非常敏感。
- 前端自己管理 time steps、颜色映射、裁剪滤镜等,会把可视化系统变成一个"重客户端"。
如果你希望最终体验接近 ParaView 桌面端,同时还要浏览器可用、多人可访问:
把渲染放在服务端(最好有 GPU),让浏览器只做交互与显示,通常是最划算的架构选择。
三、方案:ParaView 远程渲染(Remote Rendering)
-
服务端 :
pvpython进程内运行 ParaView pipeline,离屏渲染,把画面编码为图片流,经 WebSocket 推送。 -
客户端 :
vtkRemoteView接收图像并显示到 canvas;鼠标/键盘事件通过wslink发回服务端。 -
数据留在服务端;
-
浏览器拿到的是"每一帧的渲染结果(图像)";
-
交互是"事件/指令",不是"传模型"。
现在的架构,变成:
-
服务端是"可视化引擎":读数据、建管线、算颜色映射、做裁剪/切片、渲染。
-
浏览器是"远程控制器":渲染结果是图像流;交互就是事件和参数。
四、核心功能
-
万级文件时间序列回放 (目录下
.vtu/.vtk序列):播放/暂停、逐帧切换、循环、帧率。 -
场数据切换:点/单元字段(POINTS/CELLS)自动识别,向量支持 Magnitude/分量选择。
-
交互与相机:旋转/平移/缩放、重置相机、围绕物体中心旋转。
-
裁剪/切片:X/Y/Z 轴切片或裁剪(项目中 demo2/demo5/dev 具备相关能力)。
-
多视图对比:同一数据不同物理量并排渲染(demo6/dev 的 multiview)。
-
远程加载 :支持从网络盘/挂载盘读取任务数据(
DEV_NETWORK_ROOT)。
五、排坑清单
如果你也准备落地 ParaViewWeb,这些坑我建议你在 README 或运维文档里明确写出来:
-
后端必须用
pvpython启动(paraview自带,不是python)。 -
多人访问要考虑隔离(最简单就是每连接一个进程)。
-
图像流带宽/消息大小要提前评估,尤其是 4K/多视图。
-
时间序列一定要做"时间步兜底"(读不到 TimestepValues 就用
0..N-1)。 -
项目部署与文件存储服务器不在一起时,考虑用挂载远程服务器数据进行开发
运行可能需要输入服务器密码,建议配置 SSH 免密登录以实现全自动启动。
六、结语
"上万级文件一起可视化"本质上不是一个前端工程问题,而是一个端到端系统问题:数据存储、I/O、渲染、交互、网络、多人隔离,每一个环节都可能成为瓶颈。
基于 ParaView 的远程可视化,把最重的那部分(读取、管线、GPU 渲染)放回服务端,让浏览器专注"交互 + 显示",在工程上往往是最划算、最可持续的路线(目前来看,是这样,有不有更好的方案,大佬们可以说说~~)。
(yaoyao从技术调研、到项目使用,时间也不长,这个方案有问题,请大佬们指正~~)
本文是纯方案讨论,下期,上代码!!!