单机定时调度一般可以采用SpringTask(@Scheduled注解),Timer(底层单线程),ScheduledThreadPoolExecutor,时间轮,redis zSet配合Java线程轮询等方式实现
集群就需要采用分布式调度框架实现或者SpringTask配合分布式锁实现,分布式调度框架有Quartz、ElasticJob、xxl-job
一、SpringTask的原理及坑
首先我们先看下@Scheduled的原理
通过ScheduledAnnotationBeanPostProcessor这么一个BeanPostProcessor实现的
1.当该bean初始化后,会先根据@Scheduled注解的属性,创建调度任务,加入任务列表
2.Spring容器启动后,查找TaskScheduler类型的Bean作为任务调度器,找到多个,就查找名字为taskScheduler且类型为TaskScheduler的调度器作为任务调度器;没找到,就查找类型为ScheduledExecutorService的调度器,找到多个,就查找名字为taskScheduler且类型为ScheduledExecutorService的调度器。
3.我们没有为SpringTask配置调度器,也没有往容器中添加ScheduledExecutorService的话,上面就没有设置任务调度器,就会设置任务执行器和调度器都是单线程的,最后开始调度任务......
因此,在使用@Scheduled注解的时候,我们要么指定调度器,要么方法是异步的(加上@Async注解,记住@Async注解要指定线程池【这个不指定也是坑哦,会每调用一次创建一个线程执行】)
java@Configuration @Role(BeanDefinition.ROLE_INFRASTRUCTURE) public class SchedulingConfiguration { @Bean(name = TaskManagementConfigUtils.SCHEDULED_ANNOTATION_PROCESSOR_BEAN_NAME) @Role(BeanDefinition.ROLE_INFRASTRUCTURE) public ScheduledAnnotationBeanPostProcessor scheduledAnnotationProcessor() { return new ScheduledAnnotationBeanPostProcessor(); } } public class ScheduledAnnotationBeanPostProcessor implements ScheduledTaskHolder, MergedBeanDefinitionPostProcessor, DestructionAwareBeanPostProcessor, Ordered, EmbeddedValueResolverAware, BeanNameAware, BeanFactoryAware, ApplicationContextAware, SmartInitializingSingleton, ApplicationListener<ContextRefreshedEvent>, DisposableBean { //当前bean初始化后触发 @Override public Object postProcessAfterInitialization(Object bean, String beanName) { Class<?> targetClass = AopProxyUtils.ultimateTargetClass(bean); if (!this.nonAnnotatedClasses.contains(targetClass) && AnnotationUtils.isCandidateClass(targetClass, Arrays.asList(Scheduled.class, Schedules.class))) { Map<Method, Set<Scheduled>> annotatedMethods = MethodIntrospector.selectMethods(targetClass, (MethodIntrospector.MetadataLookup<Set<Scheduled>>) method -> { Set<Scheduled> scheduledMethods = AnnotatedElementUtils.getMergedRepeatableAnnotations( method, Scheduled.class, Schedules.class); return (!scheduledMethods.isEmpty() ? scheduledMethods : null); }); if (annotatedMethods.isEmpty()) { this.nonAnnotatedClasses.add(targetClass); if (logger.isTraceEnabled()) { logger.trace("No @Scheduled annotations found on bean class: " + targetClass); } } else { // 遍历所有的被@Scheduled修饰的方法,调用processScheduled往调度任务集合中添加任务 annotatedMethods.forEach((method, scheduledMethods) -> scheduledMethods.forEach(scheduled -> processScheduled(scheduled, method, bean))); } } return bean; } //ApplicationContext 容器对象创建时触发 @Override public void setApplicationContext(ApplicationContext applicationContext) { //一般Spring容器采用applicationContext这个类型的容器(懒加载),所以会触发这个方法 //触发采用的是除applicationContextl类型外的beanFactory类型 this.applicationContext = applicationContext; if (this.beanFactory == null) { this.beanFactory = applicationContext; } } //Spring容器所有单例实例化后触发 public void afterSingletonsInstantiated() { if (this.applicationContext == null) { //一般不会进来 finishRegistration(); } } //容器refresh启动后触发,这个一定会触发 @Override public void onApplicationEvent(ContextRefreshedEvent event) { if (event.getApplicationContext() == this.applicationContext) { finishRegistration(); } } private void finishRegistration() { //当前类bean初始化后已经添加了调度任务,这里会进来 if (this.registrar.hasTasks() && this.registrar.getScheduler() == null) { try { //查找TaskScheduler类型的任务调度器 this.registrar.setTaskScheduler(resolveSchedulerBean(this.beanFactory, TaskScheduler.class, false)); } catch (NoUniqueBeanDefinitionException ex) { try { //找到多个,就查找名字为taskScheduler且类型为TaskScheduler的调度器 this.registrar.setTaskScheduler(resolveSchedulerBean(this.beanFactory, TaskScheduler.class, true)); } catch (NoSuchBeanDefinitionException ex2) { } } catch (NoSuchBeanDefinitionException ex) { try { //上面都没找到,就查找类型为ScheduledExecutorService的调度器 this.registrar.setScheduler(resolveSchedulerBean(this.beanFactory, ScheduledExecutorService.class, false)); } catch (NoUniqueBeanDefinitionException ex2) { try { //找到多个,就查找名字为taskScheduler且类型为ScheduledExecutorService的调度器 this.registrar.setScheduler(resolveSchedulerBean(this.beanFactory, ScheduledExecutorService.class, true)); } catch (NoSuchBeanDefinitionException ex3) { } } } catch (NoSuchBeanDefinitionException ex2) { } } } //开始真正调度任务 this.registrar.afterPropertiesSet(); } } public class ScheduledTaskRegistrar implements ScheduledTaskHolder, InitializingBean, DisposableBean { protected void scheduleTasks() { //我们没有为SpringTask配置调度器,也没有往容器中添加ScheduledExecutorService的话 //任务调度器为空 if (this.taskScheduler == null) { //任务执行器就是单线程的 this.localExecutor = Executors.newSingleThreadScheduledExecutor(); //将任务执行器传给调度器,调度器和执行器都是单线程的 this.taskScheduler = new ConcurrentTaskScheduler(this.localExecutor); } //开始调度任务...... if (this.triggerTasks != null) { for (TriggerTask task : this.triggerTasks) { addScheduledTask(scheduleTriggerTask(task)); } } if (this.cronTasks != null) { for (CronTask task : this.cronTasks) { addScheduledTask(scheduleCronTask(task)); } } if (this.fixedRateTasks != null) { for (IntervalTask task : this.fixedRateTasks) { addScheduledTask(scheduleFixedRateTask(task)); } } if (this.fixedDelayTasks != null) { for (IntervalTask task : this.fixedDelayTasks) { addScheduledTask(scheduleFixedDelayTask(task)); } } } }
二、SpringTask的正确使用姿势
配置调度器:
加这个配置
javaspring: task: scheduling: pool: size: 10 thread-name-prefix: my-scheduled-task-或者实现SchedulingConfigurer 接口
javaimport org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.scheduling.annotation.SchedulingConfigurer; import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler; import org.springframework.scheduling.config.ScheduledTaskRegistrar; @Configuration @EnableScheduling public class ScheduledConfig implements SchedulingConfigurer { @Override public void configureTasks(ScheduledTaskRegistrar taskRegistrar) { ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler(); // 核心线程池大小 taskScheduler.setPoolSize(10); // 线程名称前缀 taskScheduler.setThreadNamePrefix("scheduled-pool-"); // 设置等待任务完成再关闭(优雅停机) taskScheduler.setWaitForTasksToCompleteOnShutdown(true); // 等待时长 taskScheduler.setAwaitTerminationSeconds(60); // 重要:必须初始化 taskScheduler.initialize(); // 注册调度器 taskRegistrar.setTaskScheduler(taskScheduler); } }配合 @Async 注解(针对单个任务异步)
- 开启异步支持 :在启动类或配置类上加
@EnableAsync。- 在方法上加注解 :在
@Scheduled的方法上同时加上@Async。
三、@Async注解的原理及坑
@Async的原理和@Scheduled的原理差不多,都是通过一个XxxBeanPostProcessor bean实现的,@Async是通过AsyncAnnotationBeanPostProcessor这个BeanPostProcessor实现的,不同的是,AsyncAnnotationBeanPostProcessor对原来的bean加了一层动态代理,这个AsyncAnnotationBeanPostProcessor最后才会处理@enableAsync的order属性默认为Integer.MAX_VALUE
@Async获取执行器的逻辑:
1.从Spring容器获取@Async注解value属性指定的name的线程池bean,没找到就获取默认的
2.默认的先尝试从Spring容器获取TaskExecutor类型的线程池(这个是Spring定义的线程池),没找到就SimpleAsyncTaskExecutor ,每调用一次该方法,就创建一个新线程执行
java@Configuration public class ProxyAsyncConfiguration extends AbstractAsyncConfiguration { @Bean(name = TaskManagementConfigUtils.ASYNC_ANNOTATION_PROCESSOR_BEAN_NAME) @Role(BeanDefinition.ROLE_INFRASTRUCTURE) public AsyncAnnotationBeanPostProcessor asyncAdvisor() { Assert.notNull(this.enableAsync, "@EnableAsync annotation metadata was not injected"); //创建AsyncAnnotationBeanPostProcessor AsyncAnnotationBeanPostProcessor bpp = new AsyncAnnotationBeanPostProcessor(); //配置执行器和异常处理器 //这是一个拓展结点 bpp.configure(this.executor, this.exceptionHandler); //自定义Async注解,这也是一个拓展结点 Class<? extends Annotation> customAsyncAnnotation = this.enableAsync.getClass("annotation"); if (customAsyncAnnotation != AnnotationUtils.getDefaultValue(EnableAsync.class, "annotation")) { bpp.setAsyncAnnotationType(customAsyncAnnotation); } bpp.setProxyTargetClass(this.enableAsync.getBoolean("proxyTargetClass")); bpp.setOrder(this.enableAsync.<Integer>getNumber("order")); return bpp; } } public class AsyncAnnotationBeanPostProcessor extends AbstractBeanFactoryAwareAdvisingPostProcessor { public static final String DEFAULT_TASK_EXECUTOR_BEAN_NAME = AnnotationAsyncExecutionInterceptor.DEFAULT_TASK_EXECUTOR_BEAN_NAME; @Nullable private Supplier<Executor> executor; @Nullable private Supplier<AsyncUncaughtExceptionHandler> exceptionHandler; @Nullable private Class<? extends Annotation> asyncAnnotationType; public AsyncAnnotationBeanPostProcessor() { setBeforeExistingAdvisors(true); } public void configure( @Nullable Supplier<Executor> executor, @Nullable Supplier<AsyncUncaughtExceptionHandler> exceptionHandler) { this.executor = executor; this.exceptionHandler = exceptionHandler; } //bean的初始化前触发 @Override public void setBeanFactory(BeanFactory beanFactory) { super.setBeanFactory(beanFactory); //创建通知(一个切面可以有多个通知【动态代理增强】) AsyncAnnotationAdvisor advisor = new AsyncAnnotationAdvisor(this.executor, this.exceptionHandler); if (this.asyncAnnotationType != null) { advisor.setAsyncAnnotationType(this.asyncAnnotationType); } advisor.setBeanFactory(beanFactory); this.advisor = advisor; } } public abstract class AbstractBeanFactoryAwareAdvisingPostProcessor extends AbstractAdvisingBeanPostProcessor implements BeanFactoryAware {} public abstract class AbstractAdvisingBeanPostProcessor extends ProxyProcessorSupport implements BeanPostProcessor { //AsyncBeanPostProcessor初始化后触发 @Override public Object postProcessAfterInitialization(Object bean, String beanName) { if (bean instanceof Advised) { //如果已经是一个AOP代理对象了 Advised advised = (Advised) bean; if (!advised.isFrozen() && isEligible(AopUtils.getTargetClass(bean))) { //AsyncAnnotationBeanPostProcessor构造时就设置为true了 //将Async这个增强加到切面的增强列表的第一个位置 //Async方法被执行时,先异步调用 if (this.beforeExistingAdvisors) { advised.addAdvisor(0, this.advisor); } else { //默认加到后面 advised.addAdvisor(this.advisor); } //返回 return bean; } } //还不是AOP代理对象,有@Async方法 if (isEligible(bean, beanName)) { ProxyFactory proxyFactory = prepareProxyFactory(bean, beanName); if (!proxyFactory.isProxyTargetClass()) { evaluateProxyInterfaces(bean.getClass(), proxyFactory); } proxyFactory.addAdvisor(this.advisor); customizeProxyFactory(proxyFactory); //创建代理对象 return proxyFactory.getProxy(getProxyClassLoader()); } return bean; } } public class AsyncAnnotationAdvisor extends AbstractPointcutAdvisor implements BeanFactoryAware { //通知(一个切面可以对应多个通知) private Advice advice; //切点 private Pointcut pointcut; public AsyncAnnotationAdvisor( @Nullable Supplier<Executor> executor, @Nullable Supplier<AsyncUncaughtExceptionHandler> exceptionHandler) { Set<Class<? extends Annotation>> asyncAnnotationTypes = new LinkedHashSet<>(2); asyncAnnotationTypes.add(Async.class); this.advice = buildAdvice(executor, exceptionHandler); this.pointcut = buildPointcut(asyncAnnotationTypes); } protected Advice buildAdvice( @Nullable Supplier<Executor> executor, @Nullable Supplier<AsyncUncaughtExceptionHandler> exceptionHandler) { //通知就是这个拦截器 AnnotationAsyncExecutionInterceptor interceptor = new AnnotationAsyncExecutionInterceptor(null); interceptor.configure(executor, exceptionHandler); return interceptor; } protected Pointcut buildPointcut(Set<Class<? extends Annotation>> asyncAnnotationTypes) { ComposablePointcut result = null; for (Class<? extends Annotation> asyncAnnotationType : asyncAnnotationTypes) { Pointcut cpc = new AnnotationMatchingPointcut(asyncAnnotationType, true); Pointcut mpc = new AnnotationMatchingPointcut(null, asyncAnnotationType, true); if (result == null) { result = new ComposablePointcut(cpc); } else { result.union(cpc); } result = result.union(mpc); } return (result != null ? result : Pointcut.TRUE); } } public class AnnotationAsyncExecutionInterceptor extends AsyncExecutionInterceptor {} public class AsyncExecutionInterceptor extends AsyncExecutionAspectSupport implements MethodInterceptor, Ordered { //真正执行的Async通知逻辑 public Object invoke(final MethodInvocation invocation) throws Throwable { //获取被代理类class对象 Class<?> targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null); //获取方法method对象 Method specificMethod = ClassUtils.getMostSpecificMethod(invocation.getMethod(), targetClass); final Method userDeclaredMethod = BridgeMethodResolver.findBridgedMethod(specificMethod); //获取执行器 AsyncTaskExecutor executor = determineAsyncExecutor(userDeclaredMethod); Callable<Object> task = () -> { try { //执行下一个通知,没有就是目标方法 Object result = invocation.proceed(); if (result instanceof Future) { return ((Future<?>) result).get(); } } catch (ExecutionException ex) { handleError(ex.getCause(), userDeclaredMethod, invocation.getArguments()); } catch (Throwable ex) { handleError(ex, userDeclaredMethod, invocation.getArguments()); } return null; }; return doSubmit(task, executor, invocation.getMethod().getReturnType()); } //**重点** protected Executor getDefaultExecutor(@Nullable BeanFactory beanFactory) { //从Spring容器中寻找TaskExecutor类型的bean Executor defaultExecutor = super.getDefaultExecutor(beanFactory); //没找到就用一个每调用一次就创建一个线程的执行器 return (defaultExecutor != null ? defaultExecutor : new SimpleAsyncTaskExecutor()); } } public abstract class AsyncExecutionAspectSupport implements BeanFactoryAware { protected Object doSubmit(Callable<Object> task, AsyncTaskExecutor executor, Class<?> returnType) { if (CompletableFuture.class.isAssignableFrom(returnType)) { return CompletableFuture.supplyAsync(() -> { try { return task.call(); } catch (Throwable ex) { throw new CompletionException(ex); } }, executor); } else if (ListenableFuture.class.isAssignableFrom(returnType)) { return ((AsyncListenableTaskExecutor) executor).submitListenable(task); } else if (Future.class.isAssignableFrom(returnType)) { return executor.submit(task); } else { executor.submit(task); return null; } } protected void handleError(Throwable ex, Method method, Object... params) throws Exception { if (Future.class.isAssignableFrom(method.getReturnType())) { //Future返回值会直接抛出异常 ReflectionUtils.rethrowException(ex); } else { try { this.exceptionHandler.obtain().handleUncaughtException(ex, method, params); } catch (Throwable ex2) { //其它情况下异常不会抛出 logger.warn("Exception handler for async method '" + method.toGenericString() + "' threw unexpected exception itself", ex2); } } } protected AsyncTaskExecutor determineAsyncExecutor(Method method) { AsyncTaskExecutor executor = this.executors.get(method); if (executor == null) { Executor targetExecutor; //获取Async的value属性 String qualifier = getExecutorQualifier(method); if (StringUtils.hasLength(qualifier)) { //从容器中寻找名称为指定名称的bean targetExecutor = findQualifiedExecutor(this.beanFactory, qualifier); } else { //获取默认的 targetExecutor = this.defaultExecutor.get(); } if (targetExecutor == null) { return null; } executor = (targetExecutor instanceof AsyncListenableTaskExecutor ? (AsyncListenableTaskExecutor) targetExecutor : new TaskExecutorAdapter(targetExecutor)); this.executors.put(method, executor); } return executor; } }
javapublic class SimpleAsyncTaskExecutor extends CustomizableThreadCreator implements AsyncListenableTaskExecutor, Serializable { public void execute(Runnable task, long startTimeout) { Assert.notNull(task, "Runnable must not be null"); Runnable taskToUse = (this.taskDecorator != null ? this.taskDecorator.decorate(task) : task); if (isThrottleActive() && startTimeout > TIMEOUT_IMMEDIATE) { this.concurrencyThrottle.beforeAccess(); doExecute(new ConcurrencyThrottlingRunnable(taskToUse)); } else { doExecute(taskToUse); } } protected void doExecute(Runnable task) { Thread thread = (this.threadFactory != null ? this.threadFactory.newThread(task) : createThread(task)); thread.start(); } }
四、@Async注解的正确使用姿势
指定线程池bean名称@Async(xxx),最推荐
配置全局的Async线程池
如果你希望所有的
@Async(如果不指定名字)都使用同一个线程池,可以在application.yml中配置。Spring Boot 会自动利用这些属性配置一个默认的ThreadPoolTaskExecutor。
javaspring: task: execution: pool: core-size: 10 # 核心线程数 max-size: 20 # 最大线程数 queue-capacity: 200 # 队列容量 keep-alive: 60s # 存活时间 thread-name-prefix: my-async- # 线程前缀或者实现AsyncConfigurer接口
javaimport org.springframework.aop.interceptor.AsyncUncaughtExceptionHandler; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.AsyncConfigurer; import org.springframework.scheduling.annotation.EnableAsync; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import java.lang.reflect.Method; import java.util.concurrent.Executor; import java.util.concurrent.ThreadPoolExecutor; @Configuration @EnableAsync public class GlobalAsyncConfig implements AsyncConfigurer { /** * 定义默认的线程池 * 当使用 @Async 不带参数时,将使用此线程池 */ @Override public Executor getAsyncExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(10); executor.setMaxPoolSize(20); executor.setQueueCapacity(200); executor.setThreadNamePrefix("global-async-"); executor.setKeepAliveSeconds(60); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); executor.initialize(); return executor; } /** * 配置异常处理 * 用于捕获 @Async void 方法抛出的异常 */ @Override public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() { return new AsyncUncaughtExceptionHandler() { @Override public void handleUncaughtException(Throwable ex, Method method, Object... params) { System.err.println("异步任务执行出现异常:"); System.err.println("异常信息: " + ex.getMessage()); System.err.println("方法名称: " + method.getName()); // 这里可以接入日志系统或者告警系统 } }; } }
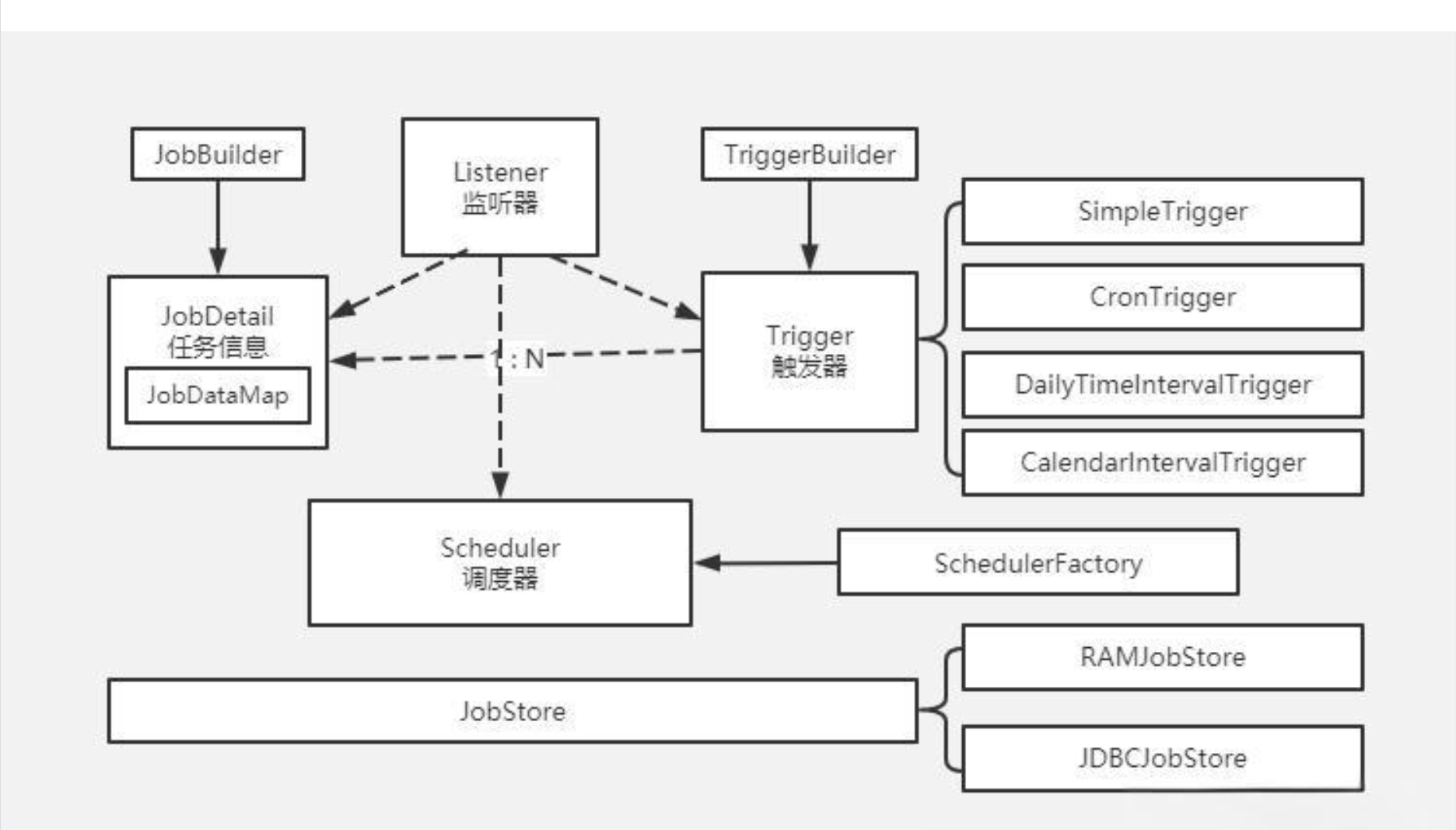
五、Quartz原理
Quartz主要由Scheduler、Job、trigger、listener四部分组成
其中一个Job(作业)可以对应多个trigger(触发器)
Scheduler实际上是一个死循环的线程:
1.阻塞等待执行任务的线程池有空闲的线程
2.从数据库拉取一批trigger(过去60秒,未来30秒的trigger,按触发时间升序,优先级倒序,默认只取一个trigger),遍历trigger获取相应的任务数据,最后往数据库中插入trigger_fired表插入数据状态改为已获取,该过程会根据调度器名称和触发器名称获取数据库行锁,以保证其它线程或进程无法修改trigger数据(例如添加任务),同时也保证了在集群环境下不会重跑任务
3.获取synchronized对象锁wait等待,直到到达触发时间,等待前会先判断是否有新的更早的任务加到数据库了【这个只是通过内存中的对象成员变量实现的通知机制,集群下只有执行添加任务的那台服务器会判断到】,就丢掉上一步获取到的trigger,重新循环
4.遍历triggers, 更新trigger_fired表记录状态为执行中,并获取job信息,返回,该过程会根据调度器名称和触发器名称获取数据库行锁
5.将triggers对应的job封装成JobRunShell【通过作业绑定的类名加载Job类并反射调用无参构造创建Job对象】,将其交给执行任务的线程池中的线程执行
Quartz的问题:
1.锁级别是scheduler + trigger,同一个调度器,当调度器在访问trigger表时,无法添加删除更新任务,锁粒度过大
2.负载均衡是随机的,哪个进程获得数据库行锁,哪个进程就获得调度机会
3.若需要通过页面动态控制任务,需要自己编写接口,操作scheduler
4.若想要任务在项目重新启动时,再次执行,那么需要实现ApplicationRunner或者CommandLineRunner接口,在Spring容器启动后,加载数据库中的Job, 通过scheduler对象绑定Job
5.无法中断正在执行的任务【因为synchronized锁是不可中断的】,提供的暂停任务方法,实际上也只是修改数据库中Job绑定的所有trigger状态为暂停
6.无法在页面上添加脚本任务
7.任务无法分片,多节点执行
SpringBoot Quartz的启动原理:
在注入的SchedulerFactoryBean实现了SmartLifecycle的start方法, 在Spring容器启动时,会启动调度器
Job类可以注入Spring容器中的bean,是因为在SchedulerFactoryBean的自动装配类中,给其设置了SpringJobFactory。将triggers对应的job封装成JobRunShell的时候,会调用其newJob方法,在这个方法里首先就会创建Job类的bean(Spring容器必须是ApplicationContext类型的,也就是需要懒加载,否则直接反射创建)
javaimport org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; import org.springframework.scheduling.quartz.QuartzJobBean; import java.time.LocalDateTime; public class MySampleJob extends QuartzJobBean { // 这里可以注入 Service @Autowired private MyService myService; @Override protected void executeInternal(JobExecutionContext context) throws JobExecutionException { // 获取 JobDetail 传递的参数 String name = (String) context.getJobDetail().getJobDataMap().get("name"); System.out.println("任务执行时间: " + LocalDateTime.now() + ",参数: " + name); // myService.doSomething(); } }
六、ElasticJob原理
elasticJob任务调度与分片的核心功能是用Zookeeper实现的,elasticJob采用Zookeeper实现了任务的动态感知和分片感知,以及故障转移等功能
其底层也有scheduler、Job、JobName(trigger)、listener的概念,利用Zookeeper进行分片leader选举,leader负责分片的分配
监控和日志功能强烈建议使用数据库。
elasticJob提供的管理页面不支持添加作业,代码中写好的Job类会被自动识别
elasticJob对executor和listener提供了Java SPI扩展点
虽然 ElasticJob 3.x(现作为 Apache ShardingSphere 的子项目)在架构上进行了巨大的重构和解耦,但在**"如何解析 Cron 表达式"以及"如何在特定时间点唤醒任务"**这两个核心问题上,它依然依赖成熟稳定的 Quartz。
Job类型有普通的、script、以及数据流,可以对接kafka等等
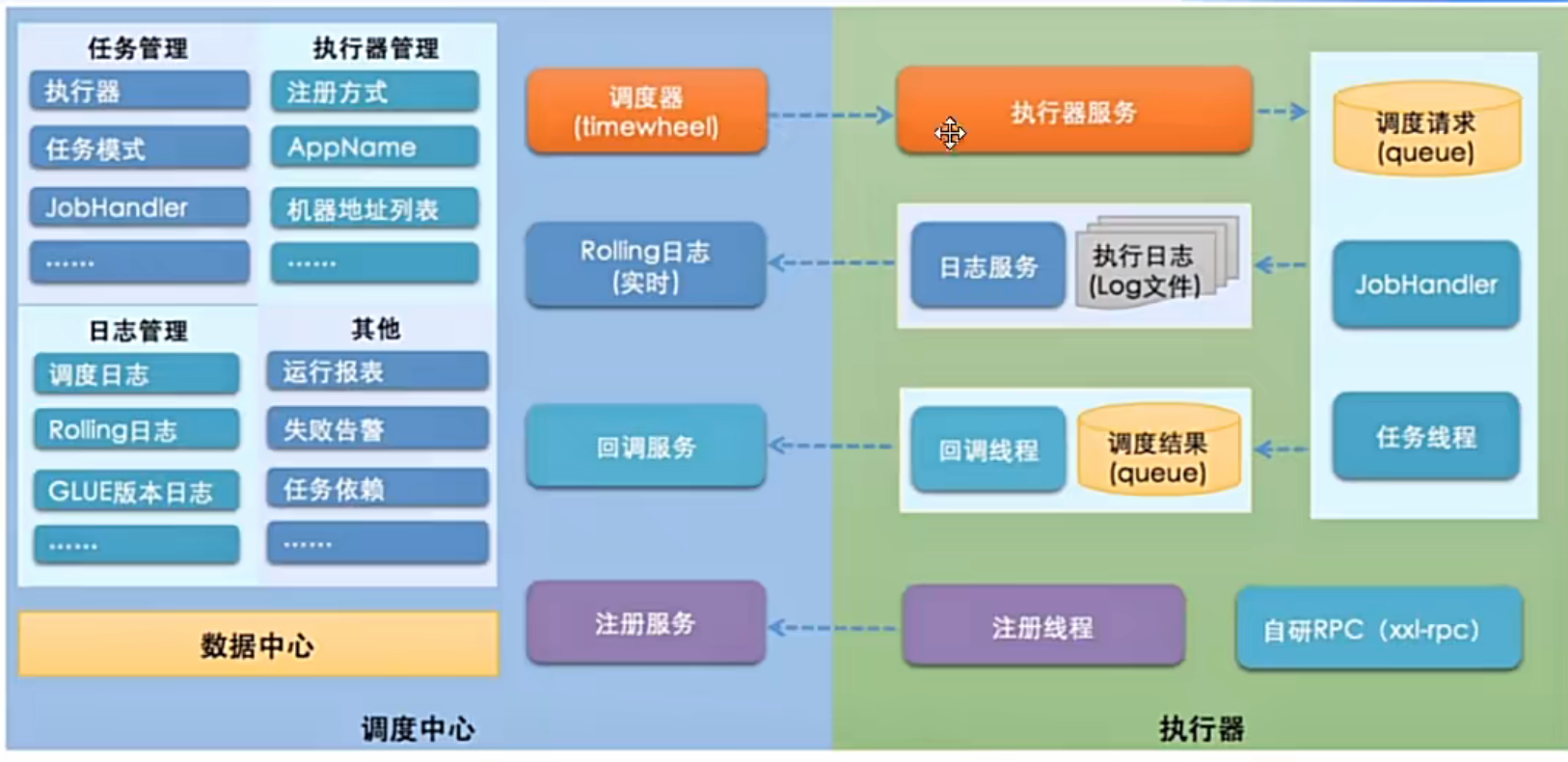
七、xxl-job原理
xxl-job调度器与执行器是分开的,调度器既是调度中心又是注册中心,负责调度任务(负载均衡策略),收集调度结果,失败达到重试上限还有自动告警机制。调度器是通过Netty + http协议与执行器通信的。执行器实际是我们的业务服务器,可以有多个JobHandler。执行器在收到调度器的任务时,会分配线程调用JobHandler方法
xxl-job的分片广播路由策略,与elasticJob的分片策略不一样。elasticJob是由leader节点负责分片逻辑的,而xxl-job是执行器自己负责分片逻辑,调度器只负责将分片总数及广播当前执行器的序号发给所有执行器。
xxl-job的命令行任务是通过RunTime.getRunTime().exec(xxx)执行的,有可能会阻塞,不如Appache的common execute包好用,elasticJob就是用这个实现的script任务执行
xxl-job任务和触发器是1:1的关系,实际就是弱化了trigger的概念
执行器注册示意图
调度器调度示意图
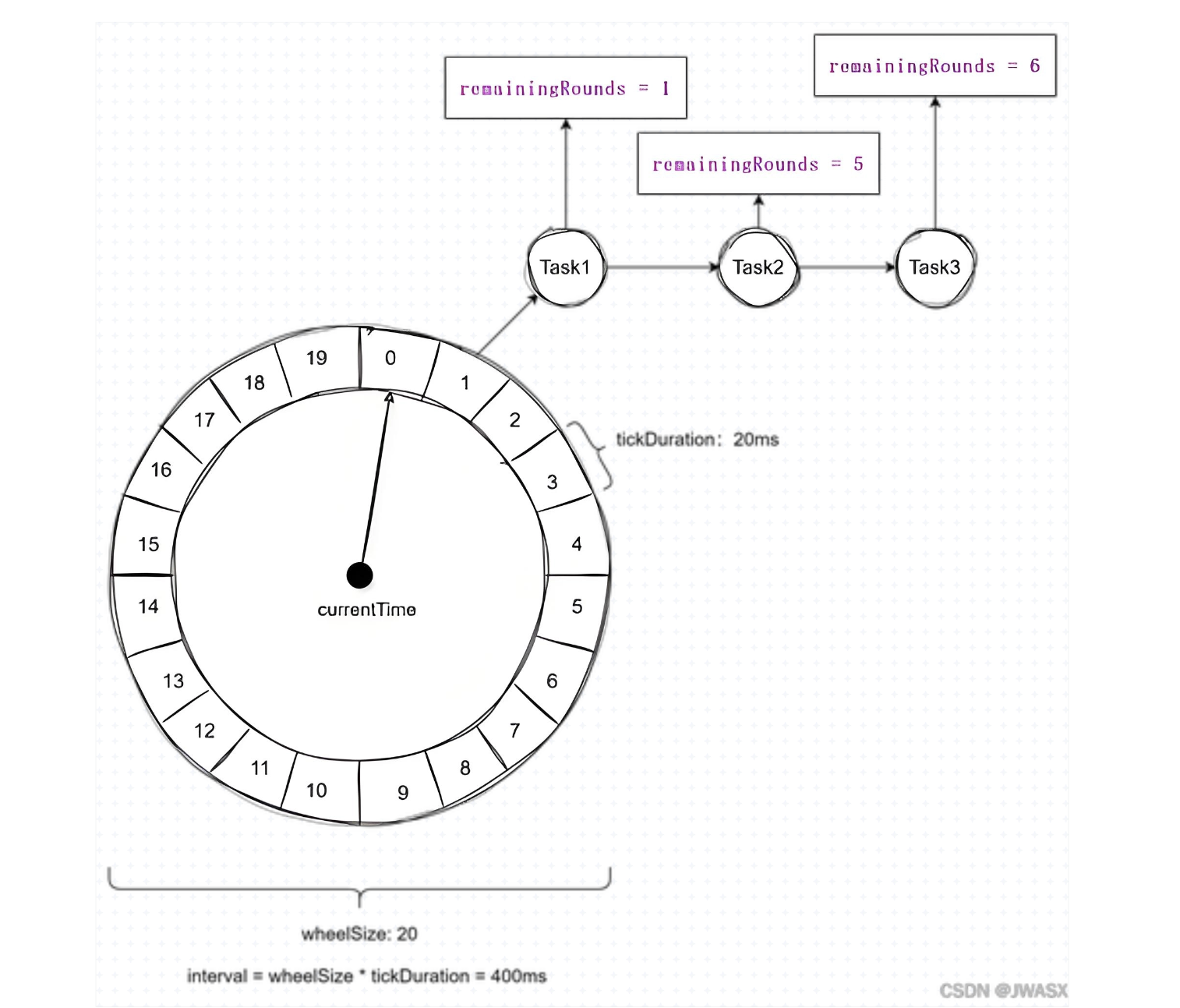
时间轮原理
时间轮解决哈希冲突的原理就是拉链法【数组加链表】,相同时间内要执行的任务挂在同一个链表上,那如果最大触发时间超过了一圈怎么办?有两种解决办法:
1.给每个任务一个轮次标记,例如轮次为0表示当前时间轮,轮次为1表示需要转完这圈,下次时间轮线程扫到才执行。指针每扫到一个槽位,遍历链表。检查每个任务的
round值。如果round > 0,说明时间还没到,将round - 1,跳过该任务。如果round == 0,说明就是本次触发,执行任务并移除。2.多层时间轮,
- 原理: 模拟现实中的钟表(秒针转一圈,分针走一格;分针转一圈,时针走一格)。
- 结构: 存在多个时间轮(层级)。
- 第1层(秒轮): 负责最近 0-60秒 的任务。
- 第2层(分轮): 负责 1分钟-60分钟 的任务。
- 第3层(时轮): 负责 >1小时 的任务。
- 处理流程(降级):
- 当添加一个 150 秒的任务时,它会被放入分轮(或者更高层)的对应槽位。
- 当时间流逝,分轮的指针指向该任务所在的槽位时,任务时间接近了。
- 系统将该任务取出,重新计算 并放入秒轮(这叫"时间轮降级")。
- 最终,所有任务都会流向最底层的秒轮,被秒轮指针触发执行。
任务带时间轮次标记的时间轮【图示每20毫秒执行一次】:
xxl-job任务调度使用的时间轮只有5秒种不存在超过一圈的情况
时间轮本质就是数组+链表,那么又要保证线程安全,所以xxl-job直接用的ConcurrentHashMap实现的
交互原理
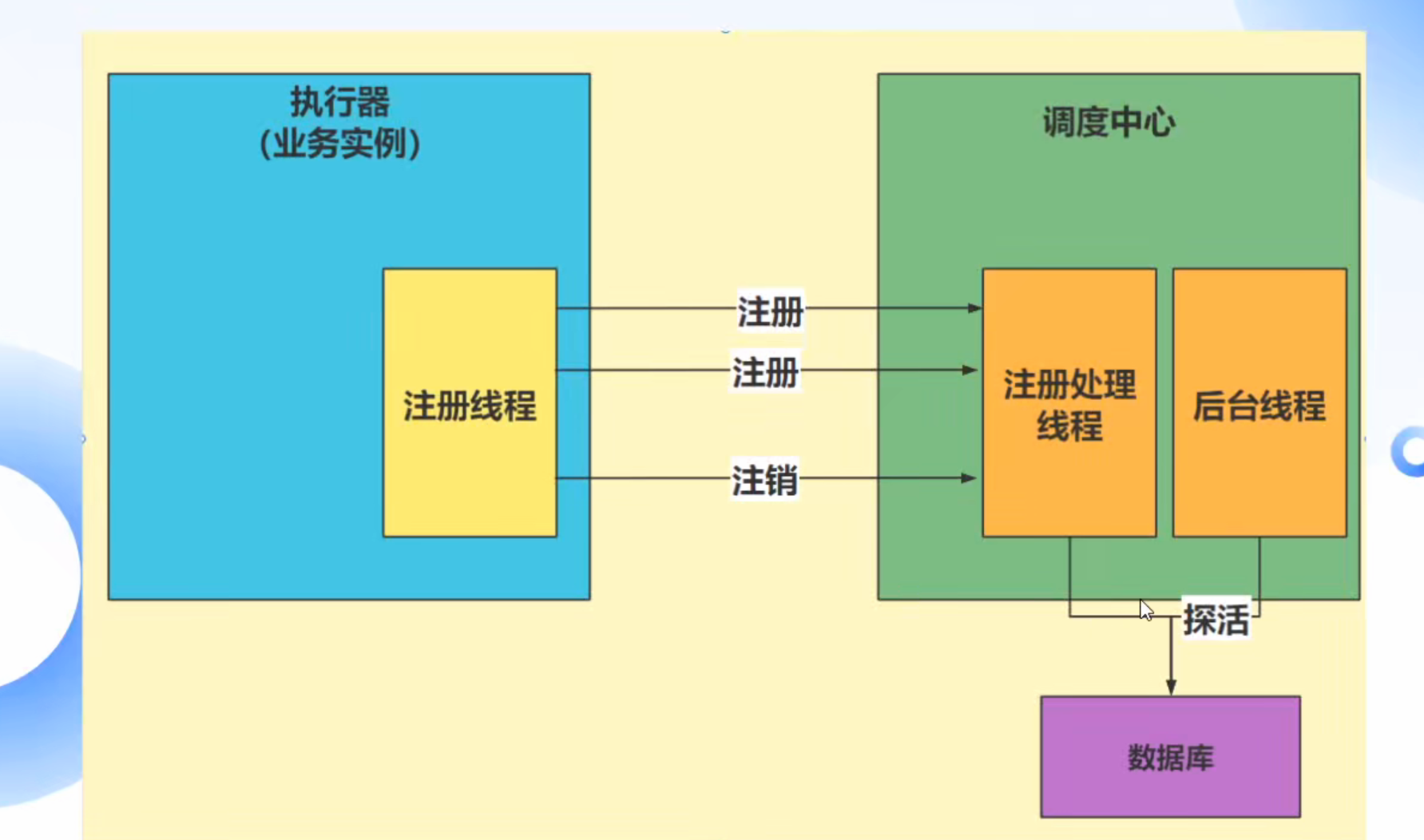
调度中心会启动一个Netty+http的内嵌服务器,用于接收执行器的注册及任务执行结果回调【本质上也是操作数据库,只不过数据库归调度中心管,一般在公司内部,这个调度中心会由一个专门的人管理】。执行器也会启动一个Netty+http的内嵌服务器,用于接收调度中心的调度任务。双方发送请求是通过HttpUrlConnection发送的。
调度中心的管理页面实际上就是通过freeMarker实现的,而界面的所有操作都是调度中心直接暴露的接口,接口内直接操作的数据库。
调度中心提供的FreeMark渲染的管理页面
调度中心给管理界面提供的接口
调度中心给执行器提供的接口
注册和取消注册其实就是更新xxl_job_registry表数据,而执行器的任务执行结果回调就是更新xxl_job_log表数据
注册和取消注册的逻辑执行会交给一个专门的线程池执行,执行器的任务执行结果回调的逻辑执行会交给另一个专门的线程池执行
会有一个监控线程不断循环处理任务结果丢失:调度记录停留在 "运行中" 状态超过10min,且对应执行器心跳注册失败不在线,则将本地调度主动标记失败
java
@Controller
public class OpenApiController {
@Resource
private AdminBiz adminBiz;
/**
* api
*/
@RequestMapping("/api/{uri}")
@ResponseBody
@XxlSso(login = false)
public Object api(HttpServletRequest request,
@PathVariable("uri") String uri,
@RequestHeader(value = Const.XXL_JOB_ACCESS_TOKEN, required = false) String accesstoken,
@RequestBody(required = false) String requestBody) {
// valid
if (!"POST".equalsIgnoreCase(request.getMethod())) {
return Response.ofFail("invalid request, HttpMethod not support.");
}
if (StringTool.isBlank(uri)) {
return Response.ofFail("invalid request, uri-mapping empty.");
}
if (StringTool.isBlank(requestBody)) {
return Response.ofFail("invalid request, requestBody empty.");
}
// valid token
if (StringTool.isNotBlank(XxlJobAdminBootstrap.getInstance().getAccessToken())
&& !XxlJobAdminBootstrap.getInstance().getAccessToken().equals(accesstoken)) {
return Response.ofFail("The access token is wrong.");
}
// dispatch request
try {
switch (uri) {
case "callback": {
List<CallbackRequest> callbackParamList = GsonTool.fromJson(requestBody, List.class, CallbackRequest.class);
return adminBiz.callback(callbackParamList);
}
case "registry": {
RegistryRequest registryParam = GsonTool.fromJson(requestBody, RegistryRequest.class);
return adminBiz.registry(registryParam);
}
case "registryRemove": {
RegistryRequest registryParam = GsonTool.fromJson(requestBody, RegistryRequest.class);
return adminBiz.registryRemove(registryParam);
}
default:
return Response.ofFail("invalid request, uri-mapping("+ uri +") not found.");
}
} catch (Exception e) {
return Response.ofFail("openapi invoke error: " + e.getMessage());
}
}
}
@Service
public class AdminBizImpl implements AdminBiz {
@Override
public Response<String> callback(List<CallbackRequest> callbackRequestList) {
return XxlJobAdminBootstrap.getInstance().getJobCompleteHelper().callback(callbackRequestList);
}
@Override
public Response<String> registry(RegistryRequest registryRequest) {
return XxlJobAdminBootstrap.getInstance().getJobRegistryHelper().registry(registryRequest);
}
@Override
public Response<String> registryRemove(RegistryRequest registryRequest) {
return XxlJobAdminBootstrap.getInstance().getJobRegistryHelper().registryRemove(registryRequest);
}
}
java
public class JobCompleteHelper {
private static final Logger logger = LoggerFactory.getLogger(JobCompleteHelper.class);
// ---------------------- monitor ----------------------
private ThreadPoolExecutor callbackThreadPool = null;
private Thread monitorThread;
private volatile boolean toStop = false;
/**
* start
*/
public void start(){
// for callback
callbackThreadPool = new ThreadPoolExecutor(
2,
20,
30L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(3000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, admin JobLosedMonitorHelper-callbackThreadPool-" + r.hashCode());
}
},
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
r.run();
logger.warn(">>>>>>>>>>> xxl-job, callback too fast, match threadpool rejected handler(run now).");
}
});
// for monitor
monitorThread = new Thread(new Runnable() {
@Override
public void run() {
// wait for JobTriggerPoolHelper-init
try {
TimeUnit.MILLISECONDS.sleep(50);
} catch (Throwable e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
// monitor
while (!toStop) {
try {
// 任务结果丢失处理:调度记录停留在 "运行中" 状态超过10min,且对应执行器心跳注册失败不在线,则将本地调度主动标记失败;
Date losedTime = DateTool.addMinutes(new Date(), -10);
List<Long> losedJobIds = XxlJobAdminBootstrap.getInstance().getXxlJobLogMapper().findLostJobIds(losedTime);
if (losedJobIds!=null && losedJobIds.size()>0) {
for (Long logId: losedJobIds) {
XxlJobLog jobLog = new XxlJobLog();
jobLog.setId(logId);
jobLog.setHandleTime(new Date());
jobLog.setHandleCode(XxlJobContext.HANDLE_CODE_FAIL);
jobLog.setHandleMsg( I18nUtil.getString("joblog_lost_fail") );
XxlJobAdminBootstrap.getInstance().getJobCompleter().complete(jobLog);
}
}
} catch (Throwable e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job fail monitor thread error:{}", e);
}
}
try {
TimeUnit.SECONDS.sleep(60);
} catch (Throwable e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobLosedMonitorHelper stop");
}
});
monitorThread.setDaemon(true);
monitorThread.setName("xxl-job, admin JobLosedMonitorHelper");
monitorThread.start();
}
/**
* stop
*/
public void stop(){
toStop = true;
// stop registryOrRemoveThreadPool
callbackThreadPool.shutdownNow();
// stop monitorThread (interrupt and wait)
monitorThread.interrupt();
try {
monitorThread.join();
} catch (Throwable e) {
logger.error(e.getMessage(), e);
}
}
// ---------------------- helper ----------------------
public Response<String> callback(List<CallbackRequest> callbackParamList) {
callbackThreadPool.execute(new Runnable() {
@Override
public void run() {
for (CallbackRequest callbackRequest: callbackParamList) {
Response<String> callbackResult = doCallback(callbackRequest);
logger.debug(">>>>>>>>> JobApiController.callback {}, callbackRequest={}, callbackResult={}",
(callbackResult.isSuccess()?"success":"fail"), callbackRequest, callbackResult);
}
}
});
return Response.ofSuccess();
}
......
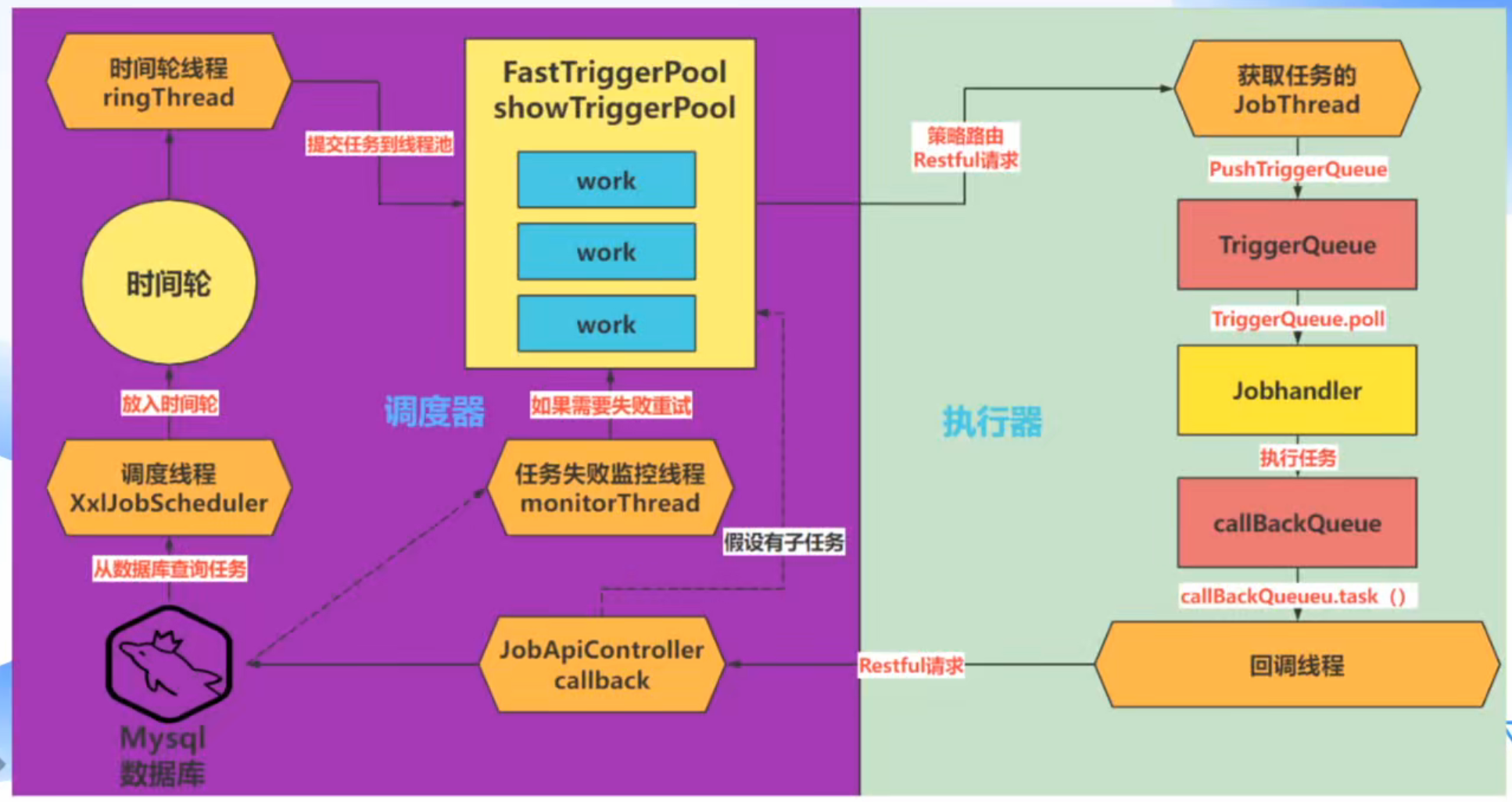
}调度中心线程模型图
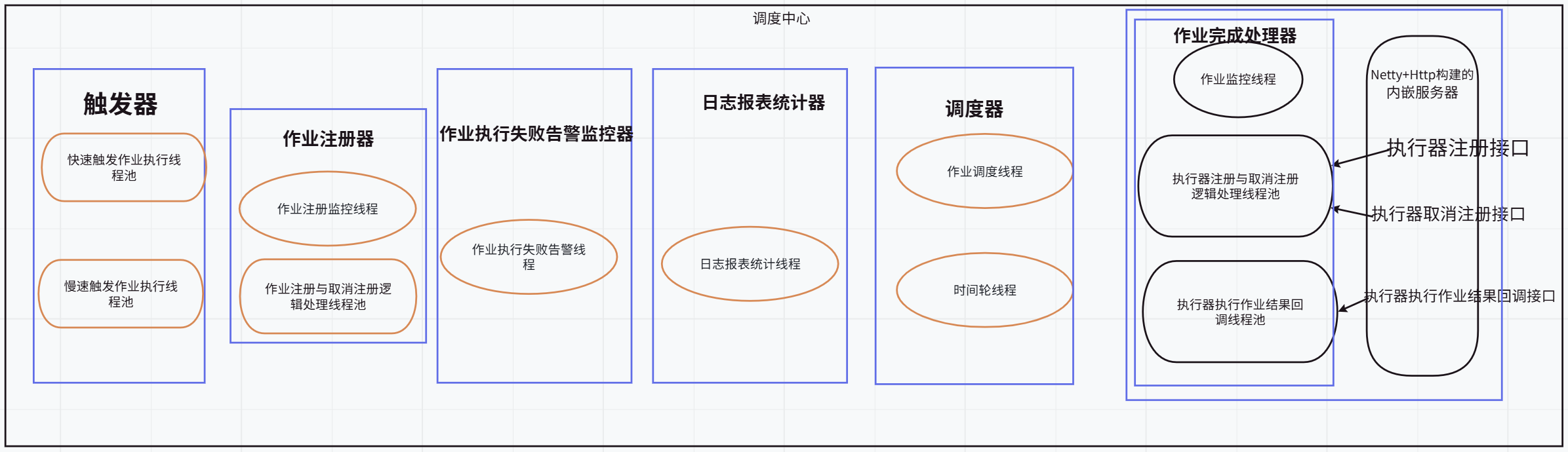
调度中心在启动时,会启动如上图所示的组件
java
@Component
public class XxlJobAdminBootstrap implements InitializingBean, DisposableBean {
// ---------------------- instance ----------------------
private static XxlJobAdminBootstrap adminConfig = null;
public static XxlJobAdminBootstrap getInstance() {
return adminConfig;
}
// ---------------------- start / stop ----------------------
@Override
public void afterPropertiesSet() throws Exception {
// init instance
adminConfig = this;
// start
doStart();
}
private void doStart() throws Exception {
// trigger-pool start
jobTriggerPoolHelper = new JobTriggerPoolHelper();
jobTriggerPoolHelper.start();
// registry monitor start
jobRegistryHelper = new JobRegistryHelper();
jobRegistryHelper.start();
// fail-alarm monitor start
jobFailAlarmMonitorHelper = new JobFailAlarmMonitorHelper();
jobFailAlarmMonitorHelper.start();
// job complate start ( depend on JobTriggerPoolHelper ) for callback and result-lost
jobCompleteHelper = new JobCompleteHelper();
jobCompleteHelper.start();
// log-report start
jobLogReportHelper = new JobLogReportHelper();
jobLogReportHelper.start();
// job-schedule start ( depend on JobTriggerPoolHelper )
jobScheduleHelper = new JobScheduleHelper();
jobScheduleHelper.start();
}
}调度中心作业调度逻辑
调度中心在启动时,会创建很多的线程池和启动很多的线程,其中就包括调度器的作业调度线程和时间轮线程,因此调度逻辑就在调度线程的run方法中
具体逻辑:
1.先随机休眠4到5秒钟,防止调度中心集群内服务间产生数据库行锁竞争
2.计算预读作业数量(批量获取任务)
3.死循环真正开始调度:
3.1 开始计时调度耗时,获取开始时间
3.2 开启数据库事务
3.3 获取调度锁(数据库行记录写锁)
sqlSELECT * FROM xxl_job_lock WHERE lock_name = 'schedule_lock' FOR UPDATE3.4 再次获取当前时间
3.4 从数据库获取触发时间小于等于未来5秒的任务
3.5 循环获取到的任务:
3.5.1 如果任务过期5秒以上,触发错过触发处理逻辑,默认是什么也不做,也可以调成立即触发一次(丢到快速触发线程池执行一次,1分钟内执行超时10次,则丢到慢速线程池执行),并刷新下一次触发时间
3.5.2 如果任务过期5秒以内,立即触发执行(丢到快速触发线程池执行一次,1分钟内执行超时10次,则丢到慢速线程池执行),并刷新下一次触发时间。如果下次触发时间在5秒内,则将其放入时间轮(concurrentHashMap)内,将来由时间轮线程处理,然后刷新下一次触发时间。【这里是防止再次错过执行】
3.5.3 如果任务还没到期,将任务放入时间轮(concurrentHashMap)内,将来由时间轮线程处理,然后刷新下一次触发时间。
3.6 循环获取到的任务,更新任务触发状态
3.7 提交数据库事务(释放调度锁)
3.8 计算3.1-3.8的耗时,如果小于1秒种:前面没拿到任务,就随机休眠0-1秒种,否则随机休眠4-5秒种

java
public class JobScheduleHelper {
public void start(){
// ---------------------- 线程 1:调度扫描线程 (Producer) ----------------------
// 作用:不断扫描数据库,获取未来5秒内要执行的任务,根据情况立即触发或放入时间轮。
scheduleThread = new Thread(new Runnable() {
@Override
public void run() {
// 1. 初始时间对齐
// 刚启动时休眠一段时间,尽量让调度线程在整秒附近开始工作,减少对齐误差
try {
TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 );
} catch (Throwable e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
logger.info(">>>>>>>>> init xxl-job admin scheduler success.");
// 2. 计算预读数量 (pre-read count)
// 根据线程池的大小(快慢线程池)计算一次从数据库拉取多少条任务合适
// 公式:(快线程池最大数 + 慢线程池最大数) * 10
// 目的:避免拉取太多撑爆内存,或者拉取太少导致处理不过来
int preReadCount = (XxlJobAdminBootstrap.getInstance().getTriggerPoolFastMax() + XxlJobAdminBootstrap.getInstance().getTriggerPoolSlowMax()) * 10;
// 3. 进入调度死循环
while (!scheduleThreadToStop) {
// 记录开始时间
long start = System.currentTimeMillis();
// 标记:本轮是否成功读取到了数据
boolean preReadSuc = true;
// 开启数据库事务 (手动管理事务,因为需要加锁)
TransactionStatus transactionStatus = null;
try {
transactionStatus = XxlJobAdminBootstrap.getInstance().getTransactionManager().getTransaction(new DefaultTransactionDefinition());
// 4. 获取分布式锁 (Job Lock)
// 利用 `select * from xxl_job_lock where lock_name = 'schedule_lock' for update`
// 保证在集群部署时,同一时刻只有一台机器能执行调度逻辑
String lockedRecord = XxlJobAdminBootstrap.getInstance().getXxlJobLockMapper().scheduleLock();
long nowTime = System.currentTimeMillis();
// 5. 扫描任务 (Scan Job)
// 查询条件:trigger_next_time <= now + 5000ms (PRE_READ_MS)
// 即:取出当前已经过期,或者未来5秒内将要执行的任务
List<XxlJobInfo> scheduleList = XxlJobAdminBootstrap.getInstance().getXxlJobInfoMapper().scheduleJobQuery(nowTime + PRE_READ_MS, preReadCount);
if (CollectionTool.isNotEmpty(scheduleList)) {
// 6. 遍历查询到的任务进行处理
for (XxlJobInfo jobInfo: scheduleList) {
// ---------------- 场景 A:任务过期超过 5秒 ----------------
// (nowTime > nextTime + 5000)
if (nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS) {
// 2.1、trigger-expire > 5s:pass && make next-trigger-time
// 处理过期策略 (Misfire Strategy)
// 比如:是"立即执行一次"还是"忽略"
MisfireStrategyEnum misfireStrategyEnum = MisfireStrategyEnum.match(jobInfo.getMisfireStrategy(), MisfireStrategyEnum.DO_NOTHING);
misfireStrategyEnum.getMisfireHandler().handle(jobInfo.getId());
// 刷新下一次执行时间
refreshNextTriggerTime(jobInfo, new Date());
}
// ---------------- 场景 B:任务过期但小于 5秒 ----------------
// (nowTime > nextTime)
else if (nowTime > jobInfo.getTriggerNextTime()) {
// 2.2、trigger-expire < 5s:direct-trigger && make next-trigger-time
// 既然只晚了一点点,直接触发一次任务
XxlJobAdminBootstrap.getInstance().getJobTriggerPoolHelper().trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);
logger.debug(">>>>>>>>>>> xxl-job, schedule expire, direct trigger : jobId = " + jobInfo.getId() );
// 刷新下一次执行时间
refreshNextTriggerTime(jobInfo, new Date());
// 特殊情况处理:
// 如果刷新后的"下一次执行时间"仍然在未来5秒内,则需要将其放入时间轮,
// 否则下一次扫描可能就漏掉了(因为本轮循环还在持有锁,如果不处理,等释放锁再扫描可能来不及)
if (jobInfo.getTriggerStatus()== TriggerStatus.RUNNING.getValue() && nowTime + PRE_READ_MS > jobInfo.getTriggerNextTime()) {
// 1. 计算该任务在时间轮中的刻度 (0-59)
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2. 放入时间轮 (ConcurrentHashMap)
// key: 秒数, value: 任务ID列表
pushTimeRing(ringSecond, jobInfo.getId());
logger.debug(">>>>>>>>>>> xxl-job, schedule pre-read, push trigger : jobId = " + jobInfo.getId() );
// 3. 再次刷新下一次执行时间
refreshNextTriggerTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
}
// ---------------- 场景 C:任务是未来的 (5秒内) ----------------
// (nowTime <= nextTime)
else {
// 2.3、trigger-pre-read:time-ring trigger && make next-trigger-time
// 1. 计算时间轮刻度
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2. 放入时间轮,等待 ringThread 到了那一秒去触发
pushTimeRing(ringSecond, jobInfo.getId());
logger.debug(">>>>>>>>>>> xxl-job, schedule normal, push trigger : jobId = " + jobInfo.getId() );
// 3. 刷新下一次执行时间
refreshNextTriggerTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
}
// 7. 更新所有任务的 Trigger 信息回数据库
for (XxlJobInfo jobInfo: scheduleList) {
XxlJobAdminBootstrap.getInstance().getXxlJobInfoMapper().scheduleUpdate(jobInfo);
}
} else {
// 没读到数据
preReadSuc = false;
}
} catch (Throwable e) {
if (!scheduleThreadToStop) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread error:{}", e.getMessage(), e);
}
} finally {
// 8. 提交事务,释放分布式锁
try {
if (transactionStatus != null) {
XxlJobAdminBootstrap.getInstance().getTransactionManager().commit(transactionStatus);
}
} catch (Throwable e) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread transaction commit error:{}", e.getMessage(), e);
}
}
// 计算本轮处理耗时
long cost = System.currentTimeMillis()-start;
// 9. 智能休眠策略
if (cost < 1000) {
try {
// 如果本轮扫描到了数据 (preReadSuc=true):说明业务繁忙,只休眠到下一秒整,希望能尽快处理下一批。
// 如果没扫描到数据 (preReadSuc=false):说明比较空闲,直接休眠 PRE_READ_MS (默认5秒) 的剩余时间,减少数据库查询压力。
TimeUnit.MILLISECONDS.sleep((preReadSuc?1000:PRE_READ_MS) - System.currentTimeMillis()%1000);
} catch (Throwable e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread stop");
}
});
scheduleThread.setDaemon(true); // 设置为守护线程
scheduleThread.setName("xxl-job, admin JobScheduleHelper#scheduleThread");
scheduleThread.start();
// ---------------------- 线程 2:时间轮触发线程 (Consumer) ----------------------
// 作用:负责从时间轮(Map)中取出当前秒需要执行的任务,并触发执行。
ringThread = new Thread(new Runnable() {
@Override
public void run() {
while (!ringThreadToStop) {
// 1. 绝对整秒对齐
// 通过计算当前毫秒数,休眠到下一秒的开始 (例如现在是 12:00:00.100,则休眠 900ms)
try {
TimeUnit.MILLISECONDS.sleep(1000 - System.currentTimeMillis() % 1000);
} catch (Throwable e) {
if (!ringThreadToStop) {
logger.error(e.getMessage(), e);
}
}
try {
// 本秒需要执行的任务ID列表
List<Integer> ringItemData = new ArrayList<>();
// 2. 获取当前秒数 (0-59)
int nowSecond = Calendar.getInstance().get(Calendar.SECOND);
// 3. 刻度补偿逻辑 (关键!)
// 正常情况下,我们取 nowSecond 的数据。
// 但如果机器卡顿、GC暂停等原因导致线程休眠过头了(例如直接睡了2秒),
// 为了防止漏跑任务,这里会向前校验 2个刻度 (nowSecond 和前一秒、再前一秒)。
for (int i = 0; i <= 2; i++) {
// 从 ringData (ConcurrentHashMap) 中移除并取出数据
// (nowSecond + 60 - i) % 60 用于处理秒数回滚(例如 0秒 的前一秒是 59秒)
List<Integer> ringItemList = ringData.remove( (nowSecond+60-i)%60 );
if (CollectionTool.isNotEmpty(ringItemList)) {
// 去重 (distinct)
// 避免同一秒内多次 push 导致重复执行,或者补偿逻辑导致的重复
List<Integer> ringItemListDistinct = ringItemList.stream().distinct().toList();
if (ringItemListDistinct.size() < ringItemList.size()) {
logger.warn(">>>>>>>>>>> xxl-job, time-ring found job repeat beat : " + nowSecond + " = " + ringItemData);
}
// 收集要执行的任务ID
ringItemData.addAll(ringItemListDistinct);
}
}
// 4. 触发任务执行
logger.debug(">>>>>>>>>>> xxl-job, time-ring beat : " + nowSecond + " = " + ringItemData);
if (CollectionTool.isNotEmpty(ringItemData)) {
for (int jobId: ringItemData) {
// 调用触发器执行任务
XxlJobAdminBootstrap.getInstance().getJobTriggerPoolHelper().trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);
}
// 清理临时列表
ringItemData.clear();
}
} catch (Throwable e) {
if (!ringThreadToStop) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread error:{}", e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread stop");
}
});
ringThread.setDaemon(true); // 设置为守护线程
ringThread.setName("xxl-job, admin JobScheduleHelper#ringThread");
ringThread.start();
}
}任务触发逻辑
参数覆盖优先级 :
方法的入参(
executorParam,addressList,failRetryCount)优先级高于数据库中的配置。这允许在"手动执行"或"API调用"时灵活调整运行参数,而不必修改任务本身。分片广播 (Sharding Broadcast) 的特殊处理 :
这是 XXL-JOB 最强大的功能之一。代码中的 分支 A 检测到如果是广播模式,会遍历所有注册节点 ,强行循环调用
processTrigger。
- 例如:有 3 台机器。
- 循环 3 次,分别下发参数
0/3,1/3,2/3。- 每台机器收到请求后,根据 index 判断自己该处理哪部分数据。
普通路由处理 :
分支 B 涵盖了除广播外的所有情况(轮询、随机、第一个等)。
- 它只调用一次
processTrigger,且默认分片参数为0/1。- 具体选哪台机器去执行,是交由
processTrigger内部调用的ExecutorRouter(路由策略模式)去计算的。
java
public class JobTriggerPoolHelper {
triggerPool_.execute(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
try {
// do trigger
XxlJobAdminBootstrap.getInstance().getJobTrigger().trigger(jobId, triggerType, failRetryCount, executorShardingParam, executorParam, addressList);
} catch (Throwable e) {
logger.error(e.getMessage(), e);
} finally {
// check timeout-count-map
long minTim_now = System.currentTimeMillis()/60000;
if (minTim != minTim_now) {
minTim = minTim_now;
jobTimeoutCountMap.clear();
}
// incr timeout-count-map
long cost = System.currentTimeMillis()-start;
if (cost > 500) { // ob-timeout threshold 500ms
AtomicInteger timeoutCount = jobTimeoutCountMap.putIfAbsent(jobId, new AtomicInteger(1));
if (timeoutCount != null) {
timeoutCount.incrementAndGet();
}
}
}
}
@Override
public String toString() {
return "Job Runnable, jobId:"+jobId;
}
});
}
java
@Component
public class JobTrigger {
/**
* 触发任务执行的核心入口
*
* @param jobId 任务ID
* @param triggerType 触发类型 (CRON, MANUAL, API, RETRY 等)
* @param failRetryCount 失败重试次数 (>=0时覆盖DB配置,<0使用DB配置)
* @param executorShardingParam 分片参数 (格式 "0/2",用于手动触发指定分片,为空则由路由策略决定)
* @param executorParam 任务参数 (不为空时覆盖DB配置)
* @param addressList 指定执行机器地址 (不为空时覆盖执行器组配置)
*/
public void trigger(int jobId,
TriggerTypeEnum triggerType,
int failRetryCount,
String executorShardingParam,
String executorParam,
String addressList) {
// ---------------------- 1. 加载并校验基础数据 ----------------------
// 从数据库加载任务信息
XxlJobInfo jobInfo = xxlJobInfoMapper.loadById(jobId);
if (jobInfo == null) {
logger.warn(">>>>>>>>>>>> trigger fail, jobId invalid,jobId={}", jobId);
return;
}
// ---------------------- 2. 处理运行时参数覆盖 ----------------------
// 如果本次触发传入了特定的任务参数(如手动执行输入了参数),覆盖原配置
if (executorParam != null) {
jobInfo.setExecutorParam(executorParam);
}
// 确定失败重试次数:如果传入了有效的 retryCount 则使用,否则使用数据库配置
int finalFailRetryCount = failRetryCount >= 0 ? failRetryCount : jobInfo.getExecutorFailRetryCount();
// 加载执行器组信息(包含该组下注册的机器列表)
XxlJobGroup group = xxlJobGroupMapper.load(jobInfo.getJobGroup());
// 如果本次触发指定了具体的机器地址(如调试模式),覆盖执行器组的默认注册列表
if (StringTool.isNotBlank(addressList)) {
group.setAddressType(1); // 标记为手动录入/指定地址
group.setAddressList(addressList.trim());
}
// ---------------------- 3. 解析分片参数 ----------------------
// shardingParam[0] = 当前分片序号 (index)
// shardingParam[1] = 总分片数 (total)
int[] shardingParam = null;
Date triggerTime = new Date();
// 如果外部传入了分片参数 (例如手动重试某个分片: "1/5")
if (executorShardingParam != null){
String[] shardingArr = executorShardingParam.split("/");
if (shardingArr.length == 2 && StringTool.isNumeric(shardingArr[0]) && StringTool.isNumeric(shardingArr[1])) {
shardingParam = new int[2];
shardingParam[0] = Integer.parseInt(shardingArr[0]);
shardingParam[1] = Integer.parseInt(shardingArr[1]);
}
}
// ---------------------- 4. 路由策略分支处理 ----------------------
// 分支 A:【分片广播】策略 (Sharding Broadcast)
// 条件:
// 1. 路由策略配置为 "分片广播"
// 2. 执行器组内有活跃的注册机器
// 3. 外部没有强制指定分片参数 (shardingParam == null)
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST == ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList() != null && !group.getRegistryList().isEmpty()
&& shardingParam == null) {
// 循环:向该组下的【每一台】机器都发送触发请求
// i 作为当前分片序号,size 作为总分片数
for (int i = 0; i < group.getRegistryList().size(); i++) {
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, triggerTime, i, group.getRegistryList().size());
}
}
// 分支 B:【普通路由】策略 (第一个、轮询、一致性HASH等) 或 【指定分片】
else {
// 如果没有指定分片参数,默认为非分片模式:index=0, total=1
if (shardingParam == null) {
shardingParam = new int[]{0, 1};
}
// 触发单次执行
// 注意:processTrigger 内部会根据具体的路由策略(如轮询),从 group 的机器列表中选出一台机器发送请求
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, triggerTime, shardingParam[0], shardingParam[1]);
}
}
}剩余内容太多,不想写了哈哈哈哈