目录
[1.1 思路](#1.1 思路)
[1.2 代码实现](#1.2 代码实现)
[1.2.1 paeser.cc](#1.2.1 paeser.cc)
[1.2.2 util.hpp](#1.2.2 util.hpp)
[1.3 简单测试](#1.3 简单测试)
[2.1 思路](#2.1 思路)
[2.2 代码实现](#2.2 代码实现)
[2.2.1 index.hpp](#2.2.1 index.hpp)
[2.2.2 util.hpp](#2.2.2 util.hpp)
[3.1 思路](#3.1 思路)
[3.2 代码实现](#3.2 代码实现)
[3.2.1 searcher.hpp](#3.2.1 searcher.hpp)
[3.3 简单测试](#3.3 简单测试)
[4.1 调用cpp-httplib库](#4.1 调用cpp-httplib库)
[4.1.1 http_server_lib.cc](#4.1.1 http_server_lib.cc)
[4.2 自己实现http](#4.2 自己实现http)
[4.2.1 http_server_self.cc](#4.2.1 http_server_self.cc)
[4.2.2 http.hpp](#4.2.2 http.hpp)
[4.2.3 tcp_server.hpp](#4.2.3 tcp_server.hpp)
[4.2.4 socket.hpp](#4.2.4 socket.hpp)
[4.2.5 inet_addr.hpp](#4.2.5 inet_addr.hpp)
[4.2.6 服务器日志编辑](#4.2.6 服务器日志编辑)
1、清洗数据的模块(Parser)
1.1 思路
-
获取数据
- 从Boost官网中,下载并解压boost_1_89_0.tar.gz,将boost_1_89_0/doc/html/中所有的文件拷贝 到原始数据文件夹中。
tar xzf boost_1_89_0.tar.gz cp -rf boost_1_89_0/doc/html/* ./raw_html/ -
-
先 存放每个html的文件名带路径,方便后续的遍历;
-
再读取files_list中所有的html文件 ,进行解析(title+content+url) ;
*cpp// 包含的头文件 #include <boost/filesystem.hpp> // 编译时,带-lfilesystem选项 -
最后将解析完的各个html文件的内容,保存到一个目标文件 (以title**\3** content**\3** url**\n**的形式存放,使getline可以一次读取一个文档(\3,控制字符,本身不可显,几乎不会出现在文本中))。
-
1.2 代码实现
1.2.1 paeser.cc
cpp
#include <iostream>
#include <string>
#include <vector>
#include <boost/filesystem.hpp>
#include "util.hpp"
const static std::string src_path = "./data/raw_html";
const static std::string dst_file = "./data/cleaned_html/cleaned.txt";
typedef struct DocInfo{
std::string title; // 文档标题
std::string content; // 文档内容
std::string url; // 该文档在官网中的url
}DocInfo_t;
// const & : 输入
// * : 输出
// & : 输入输出
bool EnumFile(const std::string& src_path, std::vector<std::string>* files_list);
bool ParseHtml(const std::vector<std::string>& files_list, std::vector<DocInfo_t>* results);
bool SaveHtml(const std::vector<DocInfo_t>& results, const std::string& dst_file);
int main() {
std::vector<std::string> files_list;
// 1. 存放每个html的文件名带路径,方便后续的遍历。
if(!EnumFile(src_path, &files_list)) {
std::cerr << "enum file name error!" << std::endl;
return 1;
}
// 2. 读取files_list中所有的html文件,进行解析
std::vector<DocInfo_t> results(files_list.size()); // 避免频繁扩容
if(!ParseHtml(files_list, &results)) {
std::cerr << "enum parse html error!" << std::endl;
return 2;
}
// 3. 将解析完的各个html文件的内容,保存到一个目标文件,以\3为分隔符
if(!SaveHtml(results, dst_file)) {
std::cerr << "save html error!" << std::endl;
return 3;
}
return 0;
}
bool EnumFile(const std::string& src_path, std::vector<std::string>* files_list) {
namespace fs = boost::filesystem;
fs::path root_path(src_path);
// 判断路径是否存在
if(!fs::exists(src_path)) {
std::cerr << src_path << " does not exist!" <<std::endl;
return false;
}
// 定义一个空的迭代器,作为递归终止的标志
fs::recursive_directory_iterator end;
for(fs::recursive_directory_iterator iter(root_path); iter != end; ++iter) {
if(!fs::is_regular_file(*iter)) continue;
if(iter->path().extension() != ".html") continue;
// std::cout << "debug: " << iter->path().string() << std::endl;
// 当前的路径是一个html文件
files_list->push_back(iter->path().string());
}
return true;
}
bool ParseTitle(const std::string& read_result, std::string* title) {
size_t begin = read_result.find("<title>");
if(begin == std::string::npos) return false;
size_t end = read_result.find("</title>");
if(end == std::string::npos) return false;
begin += std::string("<title>").size();
if(begin > end) return false;
*title = read_result.substr(begin, end - begin);
return true;
}
bool ParseContent(const std::string& read_result, std::string* content) {
enum class Status{
LABEL,
CONTENT
};
Status s = Status::LABEL;
for(char c : read_result) {
switch(s) {
case Status::LABEL:
if(c == '>') s = Status::CONTENT;
break;
case Status::CONTENT:
if(c == '<') s = Status::LABEL;
else {
if(c == '\n') c = ' '; // \n,后面想作为解析后,文档之间的分隔符
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}
bool ParseUrl(const std::string& file_path,std::string* url) {
std::string url_head = "https://www.boost.org/doc/libs/1_89_0/doc/html";
std::string url_tail = file_path.substr(src_path.size());
*url = url_head + url_tail;
return true;
}
// for debug
static void ShowDoc(const DocInfo_t& doc) {
std::cout << "title: " << doc.title << std::endl;
std::cout << "content: " << doc.content << std::endl;
std::cout << "url: " << doc.url << std::endl;
}
bool ParseHtml(const std::vector<std::string>& files_list, std::vector<DocInfo_t>* results) {
for(const std::string& file_path : files_list) {
// 1. 读取文件
std::string read_result;
if(!ns_util::FileUtil::ReadFile(file_path, &read_result)) continue;
DocInfo_t doc;
// 2. 解析指定文件,获取title
if(!ParseTitle(read_result, &doc.title)) continue;
// 3. 解析指定文件,获取content,本质是去标签
if(!ParseContent(read_result, &doc.content)) continue;
// 4. 解析指定文件,获取url
if(!ParseUrl(file_path, &doc.url)) continue;
// 5. 保存doc
results->push_back(std::move(doc)); // move,减少拷贝
// for debug
// ShowDoc(doc);
// break;
}
return true;
}
bool SaveHtml(const std::vector<DocInfo_t>& results, const std::string& output) {
#define SEP '\3'
std::ofstream out(dst_file, std::ios::out | std::ios::binary);
if(!out.is_open()) {
std::cerr << "open file: " << dst_file << " error!" << std::endl;
return false;
}
for(auto& item : results) {
std::string out_string;
out_string += item.title;
out_string += SEP;
out_string += item.content;
out_string += SEP;
out_string += item.url;
out_string += '\n';
out.write(out_string.c_str(), out_string.size());
}
out.close();
return true;
}1.2.2 util.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <fstream>
namespace ns_util {
class FileUtil{
public:
static bool ReadFile(const std::string& file_path, std::string* out) {
std::ifstream in(file_path, std::ios::in);
if(!in.is_open()) {
std::cerr << "open file " << file_path << " error" << std::endl;
return false;
}
std::string line;
// std::getline() 在内部会先清空字符串再填充新内容
// getline() 返回流对象,流对象在布尔上下文中会自动转换
while(getline(in, line)) {
*out += line;
}
in.close();
return true;
}
};
}1.3 简单测试
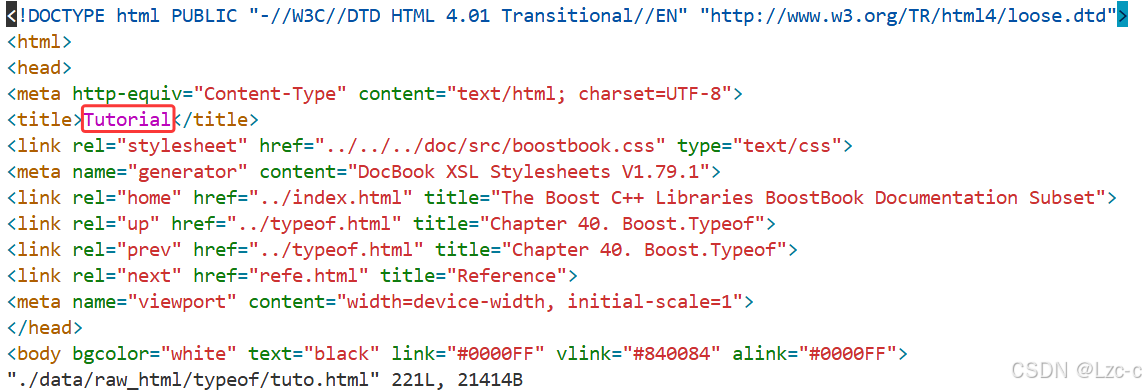
- 存放html文件 测试。
- 解析(title+content+url) 测试:
- 一个解析结果:

- 原html文档:
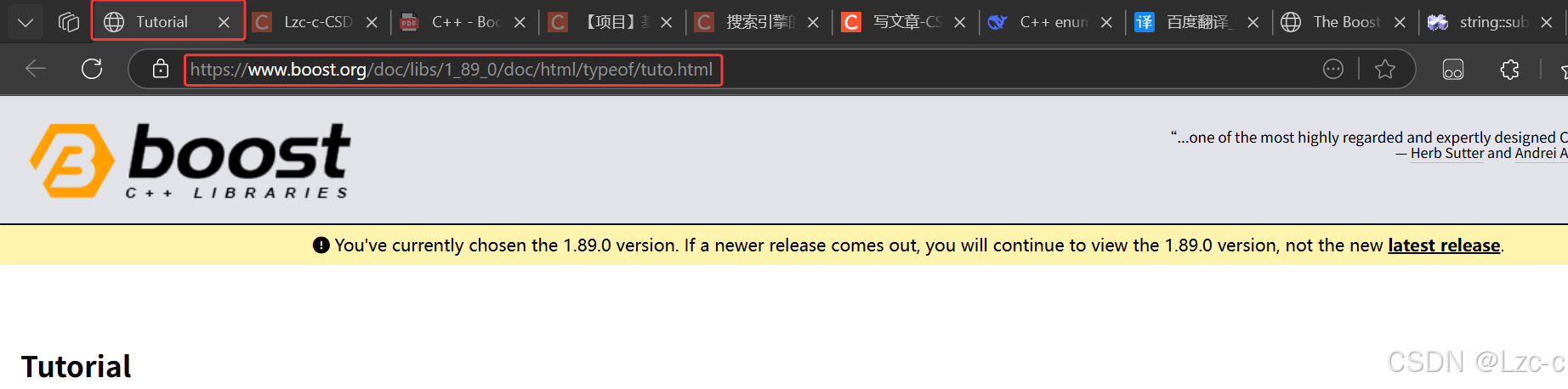
- url正确:
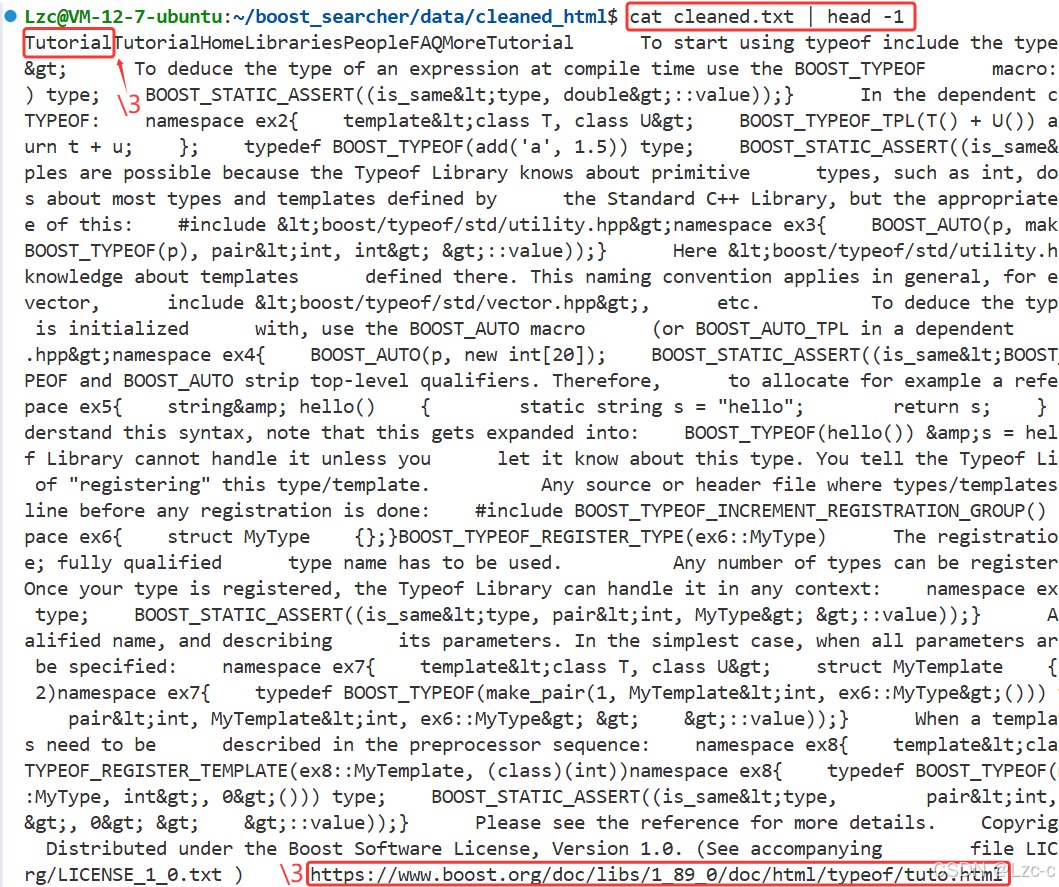
- 解析完的html文档保存到一个目标文件 测试:
- html文档的个数相同。

- 保存的第一个解析结果:
- url正确:
2、建立索引的模块(Index)
2.1 思路
- 构建正排索引 :doc_id -> DocInfo {title, content, url, doc_id}
- 解析line -> title, content, url;
- 填充 DocInfo,并插入正排索引的vector。
- 构建倒排索引 :word**-> 倒排拉链** (一个或多个InvertedElem {doc_id, word, weight})
-
对title&&content分词 (使用第三方库cppjieba),并统计 title和content的词频 ;
*cppgit clone https://gitcode.com/gh_mirrors/cp/cppjieba.git // 下面这个,可能要开一下加速器Watt Toolkit git clone https://github.com/yanyiwu/limonp.git // 把limonp/include/limonp,拷贝到cppjieba/include/cppjieba/ cp -rf limonp/include/limonp cppjieba/include/cppjieba/ // 建立软连接,方便找到头文件。软连接,删除时,使用unlink ln -s ./thirdpart/cppjieba/include/cppjieba cppjieba ln -s ./thirdpart/cppjieba/dict dict // 最后包含头文件 #include "cppjieba/Jieba.hpp"- 如果搜索的词,出现在标题,title_cnt统计一次,内容包含了标题,content_cnt里面也会统计一次,所以内容多统计了一次;当然,是根据cppjieba分词,进行的统计,与分出来词也有关系。总体上来说,问题不大。
-
填充 InvertedElem,计算 weight(认为,词在标题中出现,文章相关性高一些,在内容中出现,文章相关性低一些),并插入倒排索引的vector。
-
2.2 代码实现
2.2.1 index.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
#include <fstream>
#include <mutex>
#include "util.hpp"
namespace ns_index{
struct DocInfo{
std::string title;
std::string content;
std::string url;
uint64_t doc_id; // 哪个doc_id索引过来的;方便构建后面InvertedElem的doc_id
};
struct InvertedElem{
uint64_t doc_id;
std::string word; // 哪个word索引过来的
int weight;
};
using InvertedList = std::vector<InvertedElem>; // 倒排拉链(一个或多个InvertedElem{doc_id, word, weight})
class Index{
private:
Index(){}
Index(const Index& ) = delete;
Index& operator=(const Index& ) = delete;
static std::mutex mutex;
static Index* instance;
public:
~Index(){}
static Index* GetInstance() {
if(nullptr == instance) {
std::lock_guard<std::mutex> lock(mutex);
if(nullptr == instance) {
instance = new Index();
}
}
return instance;
}
// 根据doc_id,获得文档内容
DocInfo* GetDocInfo(uint64_t doc_id) {
if(doc_id >= forward_index.size()) {
std::cerr << doc_id << " is out of range, error!" << std::endl;
return nullptr;
}
return &forward_index[doc_id];
}
// 根据关键字,获得倒排拉链
InvertedList* GetInvertedList(const std::string& word) {
auto it = inverted_index.find(word);
if(it == inverted_index.end()) {
std::cerr << word << " has no InvertedList, error!" << std::endl;
return nullptr;
}
return &(it->second);
}
// 根据清洗后的文档,构建正排索引和倒排索引
// ./data/cleaned_html/cleaned.txt
bool BuildIndex(const std::string& input) {
std::ifstream in(input, std::ios::in | std::ios::binary);
if(!in.is_open()) {
std::cerr << input << " open error!" << std::endl;
return false;
}
std::string line;
int count = 0;
while(std::getline(in, line)) {
DocInfo* doc = BuildForwardIndex(line);
if(nullptr == doc) {
std::cerr << line << " build error!" << std::endl; // for debug
continue;
}
BuildInvertedIndex(*doc);
++count;
if(count % 100 == 0) {
std::cout << "当前建立索引的文档序号:> " << count << std::endl;
}
}
return true;
}
private:
DocInfo* BuildForwardIndex(const std::string& line) {
// 正排索引,doc_id -> DocInfo{title, content, url, doc_id}
// 1. 解析line -> title, content, url
std::vector<std::string> results;
const std::string sep = "\3"; // 行内分隔符
ns_util::StringUtil::Split(line, &results, sep);
// 2. 填充DocInfo,并插入正排索引的vector
DocInfo doc;
doc.title = results[0];
doc.content = results[1];
doc.url = results[2];
doc.doc_id = forward_index.size();
forward_index.push_back(std::move(doc)); // 减少拷贝
return &forward_index.back();
}
bool BuildInvertedIndex(const DocInfo& doc){
// 倒排索引,word -> 倒排拉链(一个或多个InvertedElem{doc_id, word, weight})
struct word_cnt{
int title_cnt;
int content_cnt;
word_cnt() : title_cnt(0), content_cnt(0) {}
};
// 1. 对title&&content分词(使用第三方库cppjieba),并统计title和content的词频;
std::unordered_map<std::string, word_cnt> word_map;
std::vector<std::string> title_words;
ns_util::JiebaUtil::CutString(doc.title, &title_words);
for(auto& word : title_words) {
boost::to_lower(word); // 转成小写,表示不区分大小写
word_map[std::move(word)].title_cnt++;
}
std::vector<std::string> content_words;
ns_util::JiebaUtil::CutString(doc.content, &content_words);
for(auto& word : content_words) {
boost::to_lower(word); // 转成小写,表示不区分大小写
word_map[std::move(word)].content_cnt++;
}
// 2. 填充InvertedElem,计算weight,并插入倒排索引的vector
#define X 10
#define Y 1
for(auto& word_pair : word_map) {
InvertedElem item;
item.doc_id = doc.doc_id;
item.word = std::move(word_pair.first);
item.weight = X*word_pair.second.title_cnt + Y*word_pair.second.content_cnt;
InvertedList& inverted_list = inverted_index[item.word];
inverted_list.push_back(std::move(item));
}
return true;
}
private:
std::vector<DocInfo> forward_index; // 正排索引,通过id(即下标)进行索引
std::unordered_map<std::string, InvertedList> inverted_index; // 倒排索引
};
Index* Index::instance = nullptr;
std::mutex Index::mutex;
}2.2.2 util.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <fstream>
#include <boost/algorithm/string.hpp>
#include "cppjieba/Jieba.hpp"
namespace ns_util {
class FileUtil{
public:
static bool ReadFile(const std::string& file_path, std::string* out) {
std::ifstream in(file_path, std::ios::in);
if(!in.is_open()) {
std::cerr << "open file " << file_path << " error" << std::endl;
return false;
}
std::string line;
// std::getline() 在内部会先清空字符串再填充新内容
// getline() 返回流对象,流对象在布尔上下文中会自动转换
while(getline(in, line)) {
*out += line;
}
in.close();
return true;
}
};
class StringUtil{
public:
static void Split(const std::string& target, std::vector<std::string>* out, const std::string sep) {
// boost split
boost::split(*out, target, boost::is_any_of(sep), boost::token_compress_on);
}
};
#define DICT_DIR "./dict"
class JiebaUtil{
public:
static void CutString(const std::string& src, std::vector<std::string>* out) {
jieba.CutForSearch(src, *out);
}
private:
static cppjieba::Jieba jieba;
};
cppjieba::Jieba JiebaUtil::jieba(DICT_DIR "/jieba.dict.utf8",
DICT_DIR "/hmm_model.utf8",
DICT_DIR "/user.dict.utf8",
DICT_DIR "/idf.utf8",
DICT_DIR "/stop_words.utf8");
}3、编写搜索引擎的模块(Searcher)
3.1 思路
-
void InitSearcher(const std::string& input)
-
获取索引对象;
-
通过索引对象,建立索引。
-
-
void Search(const std::string& query, std::string* json_string)
-
分词;
-
根据word,在倒排索引中 ,搜索并保存InvertedElem {doc_id,words,weight};
-
InvertedElem 按权重的降序排序;
-
通过InvertedElem.doc_id ,在正排索引中 ,获取DocInfo ,构建json串;
cppsudo apt install -y libjsoncpp-dev // 包含的头文件 #include <jsoncpp/json/json.h> // 编译时,带-ljsoncpp选项
-
- 注意:
- 倒排索引和query,都是转换成了小写(为了不区分大小写),但是,当用小写的词在原文中查desc时,原文不一定是小写,所以将文档的内容转成小写比较。
3.2 代码实现
3.2.1 searcher.hpp
cpp
#pragma once
#include "index.hpp"
#include <algorithm>
#include <jsoncpp/json/json.h>
namespace ns_searcher{
struct InvertedElem{
uint64_t doc_id;
std::vector<std::string> words; // 哪些word索引过来的
int weight; // 权重相加
InvertedElem() : weight(0) {}
};
class Searcher{
public:
void InitSearcher(const std::string& input) {
// 1. 获取索引对象
index = ns_index::Index::GetInstance();
std::cout << "获取index单例成功..." << std::endl;
// 2. 通过索引对象,建立索引
index->BuildIndex(input);
std::cout << "建立正倒排索引成功..." << std::endl;
}
void Search(const std::string& query, std::string* json_string){
// 1. 分词
std::vector<std::string> query_words;
ns_util::JiebaUtil::CutString(query, &query_words);
// 2. 根据word,在倒排索引中,搜索并保存InvertedElem
std::unordered_map<uint64_t, InvertedElem> doc_id_map; // 文档去重
std::vector<InvertedElem> inverted_list_all;
for(auto& word : query_words) {
boost::to_lower(word); // 转成小写,表示不区分大小写
ns_index::InvertedList* inverted_list = index->GetInvertedList(word);
if(nullptr == inverted_list) {
continue;
}
for(auto& elem : *inverted_list) {
auto& item = doc_id_map[elem.doc_id];
item.doc_id = elem.doc_id; // item可能是新建的
item.words.push_back(elem.word);
item.weight += elem.weight;
}
}
for(auto& elem : doc_id_map) {
inverted_list_all.push_back(std::move(elem.second));
}
// 3. InvertedElem按权重的降序排序
std::sort(inverted_list_all.begin(), inverted_list_all.end(),
[](const InvertedElem& e1, const InvertedElem& e2){
return e1.weight > e2.weight;
});
// 4. 通过InvertedElem.doc_id,在正排索引中,获取DocInfo,构建json串
Json::Value root;
for(auto& InvertedElem : inverted_list_all) {
ns_index::DocInfo* doc = index->GetDocInfo(InvertedElem.doc_id);
if(nullptr == doc) {
continue;
}
Json::Value item;
item["title"] = doc->title;
item["desc"] = GetDesc(doc->content, InvertedElem.words[0]);
item["url"] = doc->url;
// for debug
item["id"] = doc->doc_id;
item["weight"] = InvertedElem.weight;
root.append(item);
}
Json::StyledWriter writer;
*json_string = writer.write(root);
}
private:
std::string GetDesc(const std::string& html_content, const std::string& word) {
const int prev_step = 50;
const int next_step = 100;
// size_t pos = html_content.find(word); // bug:索引里的word已经是小写了,content里面不一定是小写
// if(pos == std::string::npos) {
// return "None1";
// }
// 将文档的内容转成小写比较
auto it = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){
return std::tolower(x) == std::tolower(y);
});
if(it == html_content.end()) {
return "None1";
}
int pos = std::distance(html_content.begin(), it);
int start = 0, end = html_content.size() - 1; // [ , ]
// 取pos+前50个字节(没有50个字节,就从start开始)+后100个字节(没有100个字节,就在end结束)
if(pos - prev_step > start) start = pos - prev_step;
if(pos + next_step < end) end = pos + next_step;
if(start > end) return "None2";
return html_content.substr(start, end - start + 1);
}
private:
ns_index::Index* index;
};
}3.3 简单测试
cpp
#include "searcher.hpp"
const static std::string input = "./data/cleaned_html/cleaned.txt";
int main(){
ns_searcher::Searcher * searcher = new ns_searcher::Searcher();
searcher->InitSearcher(input);
std::string query;
std::string json_string;
while(true) {
std::cout << "Please enter your query statement# ";
std::cin >> query;
searcher->Search(query, &json_string);
std::cout << json_string <<std::endl;
// query的分词情况
std::vector<std::string> cut_strings;
ns_util::JiebaUtil::CutString(query, &cut_strings);
std::cout << query << " 分词情况:> " << cut_strings.size() << "个分词"<< std::endl;
int count = 1;
for(auto& str : cut_strings) {
std::cout << "第" << count++ << "个分词:> "<< str << std::endl;
}
}
return 0;
}- 测试结果:

4、编写http_server模块
4.1 调用cpp-httplib库
4.1.1 http_server_lib.cc
- 使用cpp-httplib库。
cpp
git clone https://gitee.com/openworking/cpp-httplib.git
// 建立软连接
ln -s ./thirdpart/cpp-httplib cpp-httplib
// 要求:gcc/g++是比较新的版本。
// 编译时,带-pthread选项
cpp
#include "searcher.hpp"
#include "cpp-httplib/httplib.h"
const static std::string input = "./data/cleaned_html/cleaned.txt";
const static std::string root_path = "./wwwroot";
int main() {
ns_searcher::Searcher searcher;
searcher.InitSearcher(input);
httplib::Server server;
server.set_base_dir(root_path);
server.Get("/s", [&searcher](const httplib::Request& request, httplib::Response& response){
if(!request.has_param("word")) {
response.set_content("必须要有搜索关键字!", "text/plain; charset=utf-8");
return;
}
std::string word = request.get_param_value("word");
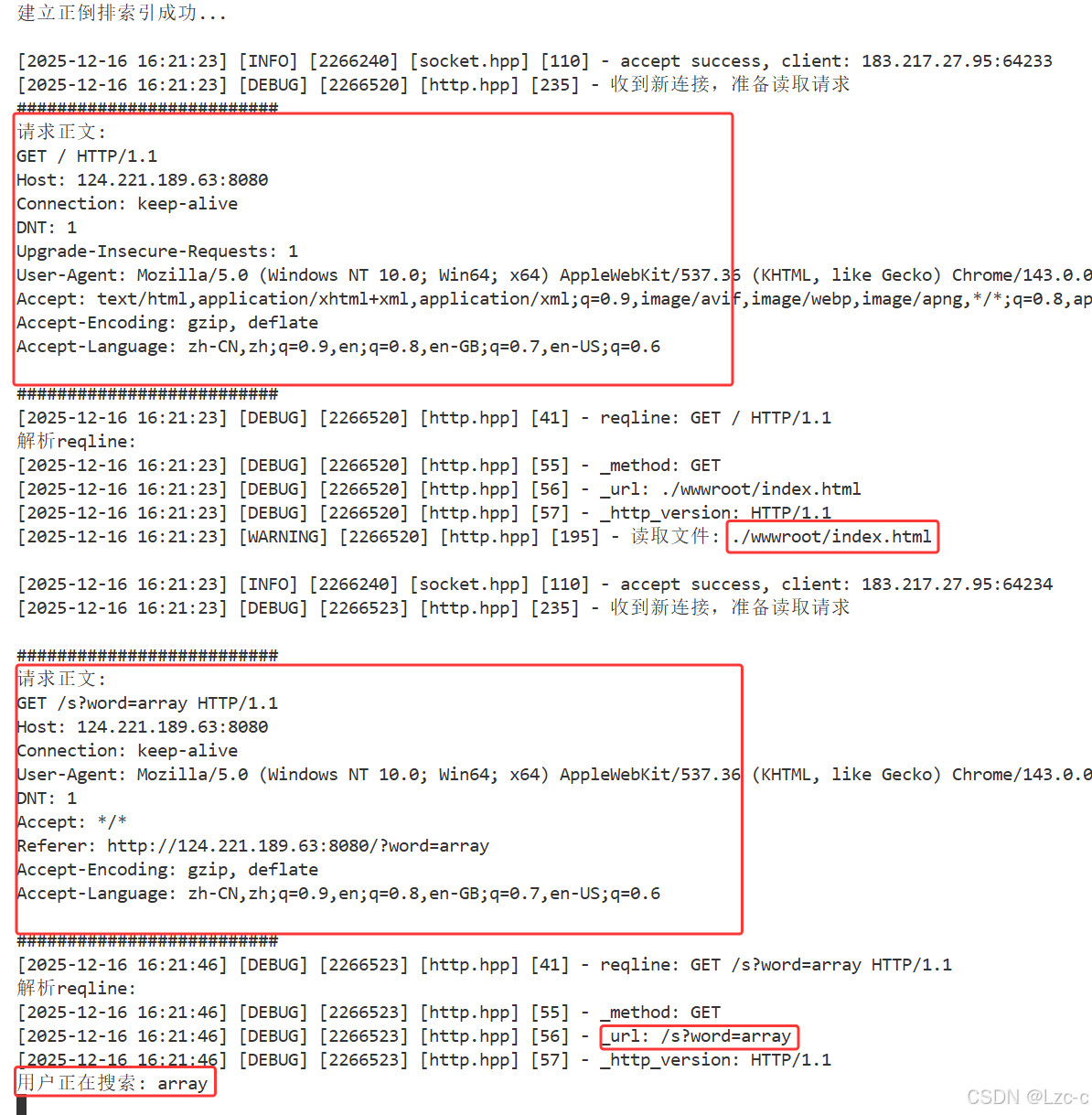
std::cout << "用户正在搜索: " << word << std::endl;
std::string json_string;
searcher.Search(word, &json_string);
response.set_content(json_string, "application/json");
});
server.listen("0.0.0.0", 8080);
return 0;
}4.2 自己实现http
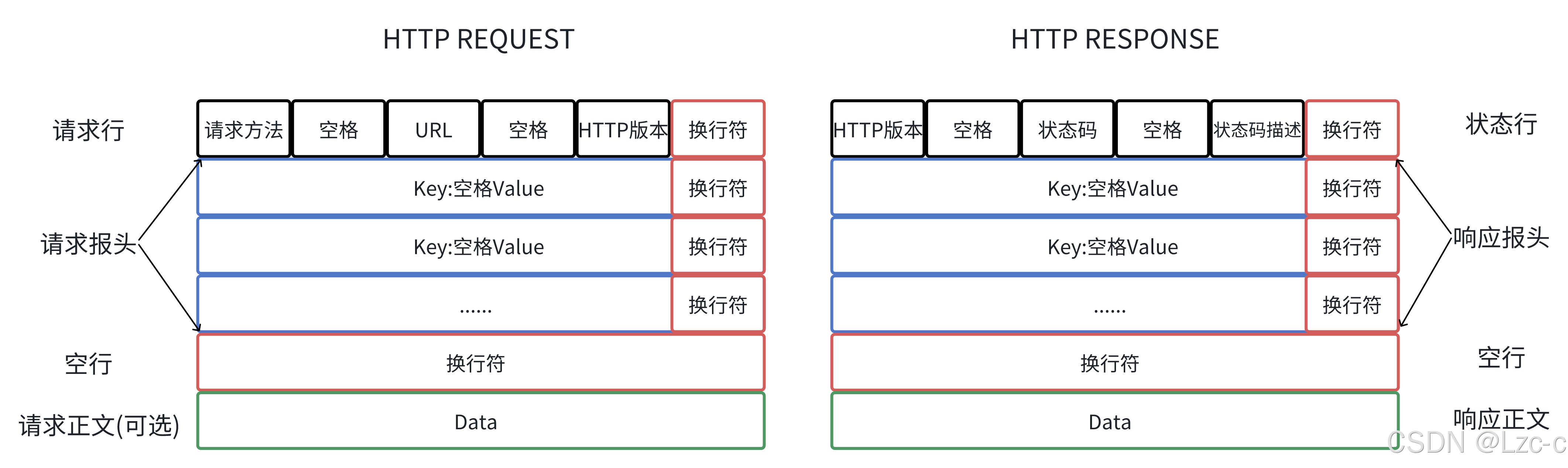
- HTTP 的请求报头 和应答报头:
- 下面是几个主要的文件:完整的代码在本文的最后。
4.2.1 http_server_self.cc
cpp
#include "http.hpp"
#include <memory>
// ./myhttp server_port
int main(int argc, char* argv[])
{
if(argc != 2)
{
std::cerr << "Usage: " << argv[0] << " server_port" << std::endl;
exit(USAGE_ERROR);
}
Enable_Console_Log_Strategy();
uint16_t server_port = std::stoi(argv[1]);
std::unique_ptr<Http> httpsvrp = std::make_unique<Http>(server_port);
httpsvrp->Start();
return 0;
}4.2.2 http.hpp
cpp
#pragma once
#include "socket.hpp"
#include "tcp_server.hpp"
#include "util.hpp"
#include "log.hpp"
#include <string>
#include <unordered_map>
#include <functional>
const static std::string sep_space = " ";
const static std::string sep_line = "\r\n";
const static std::string sep_kv = ": ";
const static std::string wwwroot = "./wwwroot";
const static std::string home_page = "/index.html";
const static std::string page_404 = "/404.html";
const static std::string input = "./data/cleaned_html/cleaned.txt";
using search = std::function<void(const std::string& query, std::string* json_string)>;
class HttpRequest
{
public:
void ParseReqLine(std::string &req_line)
{
// GET / HTTP/1.1
std::stringstream ss(req_line);
ss >> _method >> _url >> _http_version;
}
bool Deserialize(std::string& req_str)
{
// 请求行
std::string req_line;
bool res = ns_util::FileUtil::ReadOneLine(req_str, &req_line, sep_line);
if(!res)
return false;
ParseReqLine(req_line);
LOG(LogLevel::DEBUG) << "reqline: " << req_line;
if(_url == "/") {
_url = wwwroot + home_page; // "./wwwroot/index.html";
} else {
const std::string search = "/s?word=";
if(_url.substr(0, search.size()) == search) {
_args = _url.substr(search.size()); // 搜索
} else {
_url = wwwroot + _url; // "./wwwroot/..."
}
}
std::cout << "解析reqline: " << std::endl;
LOG(LogLevel::DEBUG) << "_method: " << _method;
LOG(LogLevel::DEBUG) << "_url: " << _url;
LOG(LogLevel::DEBUG) << "_http_version: " << _http_version;
// 请求报头 请求正文 ...
return true;
}
std::string GetUrl()
{
return _url;
}
std::string GetArgs() {
return _args;
}
private:
std::string _method;
std::string _url;
std::string _args; // 搜索关键词
std::string _http_version;
std::unordered_map<std::string, std::string> _headers;
std::string _blank_line;
std::string _text;
};
class HttpResponse
{
public:
HttpResponse()
:_blank_line(sep_line)
,_http_version("HTTP/1.1")
{}
// 实现: 成熟的http,应答做序列化,不要依赖任何第三方库!
std::string Serialize()
{
std::string status_line = _http_version + sep_space + std::to_string(_code) + sep_space + _code_desc + sep_line;
std::string headers;
for(auto& header : _headers)
{
headers += header.first + sep_kv + header.second + sep_line;
}
return status_line + headers + _blank_line + _text;
}
void SetCode(int code)
{
_code = code;
switch(code)
{
case 200:
_code_desc = "OK";
break;
case 302:
_code_desc = "Found";
break;
case 404:
_code_desc = "Not Found";
break;
default:
break;
}
}
void SetHeaders(const std::string& key, const std::string& value)
{
auto it = _headers.find(key);
if(it == _headers.end())
_headers.insert({key,value});
}
std::string Uri2Suffix(const std::string &targetfile)
{
// ./wwwroot/a/b/c.html
auto pos = targetfile.rfind(".");
if (pos == std::string::npos) // 默认访问的是.htm/.html文件
{
return "text/html";
}
std::string suffix = targetfile.substr(pos);
if (suffix == ".html" || suffix == ".htm")
return "text/html";
else if (suffix == ".jpg")
return "image/jpeg";
else if (suffix == "png")
return "image/png";
else
return "";
}
void SetTargetFile(const std::string& file)
{
_target_file = file;
}
void SetArgs(const std::string args) {
_args = args;
}
void SetText(const std::string text)
{
_text = text;
}
bool MakeResponse(uint16_t port, search Search)
{
// 浏览器要访问图标, 忽略他
if(_target_file == "./wwwroot/favicon.ico")
{
LOG(LogLevel::INFO) << "用户请求图标: " << _target_file << "忽略他";
return false;
}
// 执行搜索
if(!_args.empty()) {
std::cout << "用户正在搜索: " << _args << std::endl;
SetCode(200); // 成功
Search(_args, &_text);
SetHeaders("Content-Type", "application/json");
return true;
}
// 返回页面
bool res = ns_util::FileUtil::ReadFileContent(_target_file, &_text);
if(!res)
{
LOG(LogLevel::WARNING) << "没有文件: " << _target_file << " , 404";
SetCode(302); // 没有这个文件, 临时重定向到404
SetHeaders("Location","http://124.221.189.63:"+std::to_string(port)+"/404.html");
}
else
{
LOG(LogLevel::WARNING) << "读取文件: " << _target_file;
SetCode(200); // 成功
int file_size = ns_util::FileUtil::FileSize(_target_file);
std::string suffix = Uri2Suffix(_target_file);
SetHeaders("Content-Type", suffix);
SetHeaders("Content-Length", std::to_string(file_size));
}
return true;
}
private:
std::string _http_version;
int _code;
std::string _code_desc;
std::unordered_map<std::string, std::string> _headers;
std::string _blank_line;
std::string _text;
// 其他属性
std::string _target_file;
std::string _args;
};
class Http
{
public:
Http(uint16_t port)
:_tsvrp(std::make_unique<TcpServer>(port))
,_port(port)
{
searcher.InitSearcher(input); // 建立索引
}
void HandleHttpRequest(std::shared_ptr<Socket>& sockfd, const InetAddr& client, search Search)
{
LOG(LogLevel::DEBUG) << "收到新连接,准备读取请求";
std::string http_req;
int n = sockfd->Recv(&http_req); // 大概率一次读到完整的请求报文
if(n > 0)
{
std::cout << "##########################" << std::endl;
std::cout << "请求正文: " << std::endl;
std::cout << http_req;
std::cout << "##########################" << std::endl;
HttpRequest req;
HttpResponse resp;
req.Deserialize(http_req);
resp.SetTargetFile(req.GetUrl());
resp.SetArgs(req.GetArgs());
if(resp.MakeResponse(_port, Search))
{
sockfd->Send(resp.Serialize());
}
}
}
void Start()
{
auto search = std::bind(&ns_searcher::Searcher::Search,
&searcher,
std::placeholders::_1,
std::placeholders::_2);
_tsvrp->Start([this, search](std::shared_ptr<Socket>& sockfd, const InetAddr& client){
this->HandleHttpRequest(sockfd, client, search);
});
}
private:
std::unique_ptr<TcpServer> _tsvrp;
ns_searcher::Searcher searcher;
uint16_t _port;
};4.2.3 tcp_server.hpp
cpp
#pragma once
#include "socket.hpp"
#include "searcher.hpp"
#include <functional>
#include <sys/wait.h>
using ioservice_t = std::function<void(std::shared_ptr<Socket>&, const InetAddr&)>;
class TcpServer : public NoCopy
{
public:
TcpServer(uint16_t port)
: _listen_socket(std::make_unique<TcpSocket>())
, _running(false)
{
// 1. 创建套接字
// 2. bind套接字
// 3. 设置监听套接字
_listen_socket->BuildTcpServer(port);
}
// version-多进程
void Start(ioservice_t service)
{
_running = true;
while (_running)
{
// 4. 创建已连接套接字
InetAddr client;
std::shared_ptr<Socket> sockfd = _listen_socket->Accept(&client);
if(!sockfd)
continue;
pid_t pid = fork();
if(pid < 0)
{
LOG(LogLevel::WARNING) << "fork failed";
continue;
}
else if(pid == 0)
{
_listen_socket->Close(); // 关闭listen_sockfd
// 子进程
if(fork() > 0)
exit(OK);
// 孙子进程
service(sockfd,client);
exit(OK);
}
else
{
sockfd->Close(); // 关闭sockfd
// 父进程
waitpid(pid,nullptr,0);
}
}
}
private:
std::unique_ptr<Socket> _listen_socket;
bool _running;
};4.2.4 socket.hpp
cpp
#pragma once
#include "common.hpp"
#include "log.hpp"
#include <memory>
using namespace LogModule;
const static int default_sockfd = -1;
const static int default_backlog = 16;
class Socket
{
public:
virtual void SocketOrDie() = 0; // = 0, 不需要实现
virtual void BindOrDie(uint16_t port) = 0;
virtual void ListenOrDie(int backlog) = 0;
virtual void ConnectOrDie(std::string &server_ip, uint16_t server_port) = 0;
virtual std::shared_ptr<Socket> Accept(InetAddr* client) = 0;
virtual int Recv(std::string* out) = 0;
virtual int Send(const std::string& in) = 0;
virtual void Close() = 0;
public:
void BuildTcpServer(uint16_t port)
{
SocketOrDie();
BindOrDie(port);
ListenOrDie(default_backlog);
}
void BuildTcpClient(std::string &server_ip, uint16_t server_port)
{
SocketOrDie();
ConnectOrDie(server_ip,server_port);
}
};
class TcpSocket : public Socket
{
public:
TcpSocket(int sockfd = default_sockfd)
: _sockfd(sockfd)
{
}
virtual void Close() override
{
if (_sockfd != default_sockfd)
::close(_sockfd); // ::表示调用 全局作用域 中的 close 函数
}
virtual void SocketOrDie() override
{
_sockfd = ::socket(AF_INET, SOCK_STREAM, 0);
if (_sockfd < 0)
{
LOG(LogLevel::FATAL) << "socket error!";
exit(SOCKET_ERROR);
}
LOG(LogLevel::INFO) << "socket success, socket: " << _sockfd;
}
virtual void BindOrDie(uint16_t port) override
{
InetAddr local(port);
int n = ::bind(_sockfd, CONST_CONV(local.Addr()), local.AddrLen());
if (n < 0)
{
LOG(LogLevel::FATAL) << "bind error!";
exit(BIND_ERROR);
}
LOG(LogLevel::INFO) << "bind success, socket: " << _sockfd;
}
virtual void ListenOrDie(int backlog) override
{
int n = ::listen(_sockfd, default_backlog);
if (n < 0)
{
LOG(LogLevel::FATAL) << "listen error!";
exit(LISTEN_ERROR);
}
LOG(LogLevel::INFO) << "listen success, sockfd: " << _sockfd;
}
virtual void ConnectOrDie(std::string &server_ip, uint16_t server_port) override
{
InetAddr server(server_ip, server_port);
int n = ::connect(_sockfd, CONST_CONV(server.Addr()), server.AddrLen());
if (n < 0)
{
LOG(LogLevel::FATAL) << "connect error!";
exit(CONNECT_ERROR);
}
LOG(LogLevel::INFO) << "connect success, sockfd: " << _sockfd;
}
virtual std::shared_ptr<Socket> Accept(InetAddr* client) override
{
std::cout << std::endl;
struct sockaddr_in addr;
socklen_t len = sizeof(addr);
int fd = ::accept(_sockfd, CONV(addr), &len);
if (fd < 0)
{
LOG(LogLevel::WARNING) << "accept failed";
return nullptr;
}
client->SetAddr(addr);
LOG(LogLevel::INFO) << "accept success, client: " << client->StringAddr();
return std::make_shared<TcpSocket>(fd); // 这个server的sockfd就可以调用Recv和Send方法。
}
virtual int Recv(std::string* out) override
{
char buf[1024*8];
ssize_t n = ::recv(_sockfd,buf,sizeof(buf)-1,0);
if(n > 0)
{
buf[n] = 0;
*out += buf; // += 可能要不断的读
}
return n;
}
virtual int Send(const std::string& in) override
{
return ::send(_sockfd,in.c_str(),in.size(),0);
}
private:
int _sockfd; // 既可以是listen_sockfd,也可以是sockfd,复用代码。
};4.2.5 inet_addr.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
class InetAddr
{
public:
InetAddr() // 默认构造
{}
InetAddr(uint16_t port) :_port(port)
{
// 主机 -> 网络
memset(&_addr, 0, sizeof(_addr));
_addr.sin_family = AF_INET;
_addr.sin_addr.s_addr = INADDR_ANY;
_addr.sin_port = htons(_port);
}
InetAddr(struct sockaddr_in &addr)
: _addr(addr)
{
// 网络 -> 主机
char buf[32];
inet_ntop(AF_INET, &_addr.sin_addr, buf, sizeof(buf) - 1);
_ip = buf;
_port = ntohs(_addr.sin_port);
}
InetAddr(const std::string &ip, uint16_t port)
: _ip(ip), _port(port)
{
// 主机 -> 网络
memset(&_addr, 0, sizeof(_addr));
_addr.sin_family = AF_INET;
inet_pton(AF_INET, _ip.c_str(), &_addr.sin_addr);
_addr.sin_port = htons(_port);
}
void SetAddr(struct sockaddr_in &addr)
{
// 网络 -> 主机
_addr = addr;
char buf[32];
inet_ntop(AF_INET, &_addr.sin_addr, buf, sizeof(buf) - 1);
_ip = buf;
_port = ntohs(_addr.sin_port);
}
std::string Ip() const
{
return _ip;
}
uint16_t Port() const
{
return _port;
}
const struct sockaddr_in& Addr() const
{
return _addr;
}
socklen_t AddrLen() const
{
return sizeof(_addr);
}
std::string StringAddr() const
{
return _ip + ":" + std::to_string(_port);
}
bool operator==(const InetAddr &addr) const
{
return _ip == addr._ip && _port == addr._port; // 我们任务ip和port相同,才相等;允许一个ip的多个端口访问。
}
private:
struct sockaddr_in _addr;
std::string _ip;
uint16_t _port;
};4.2.6 服务器日志
5、结果展示及完整代码
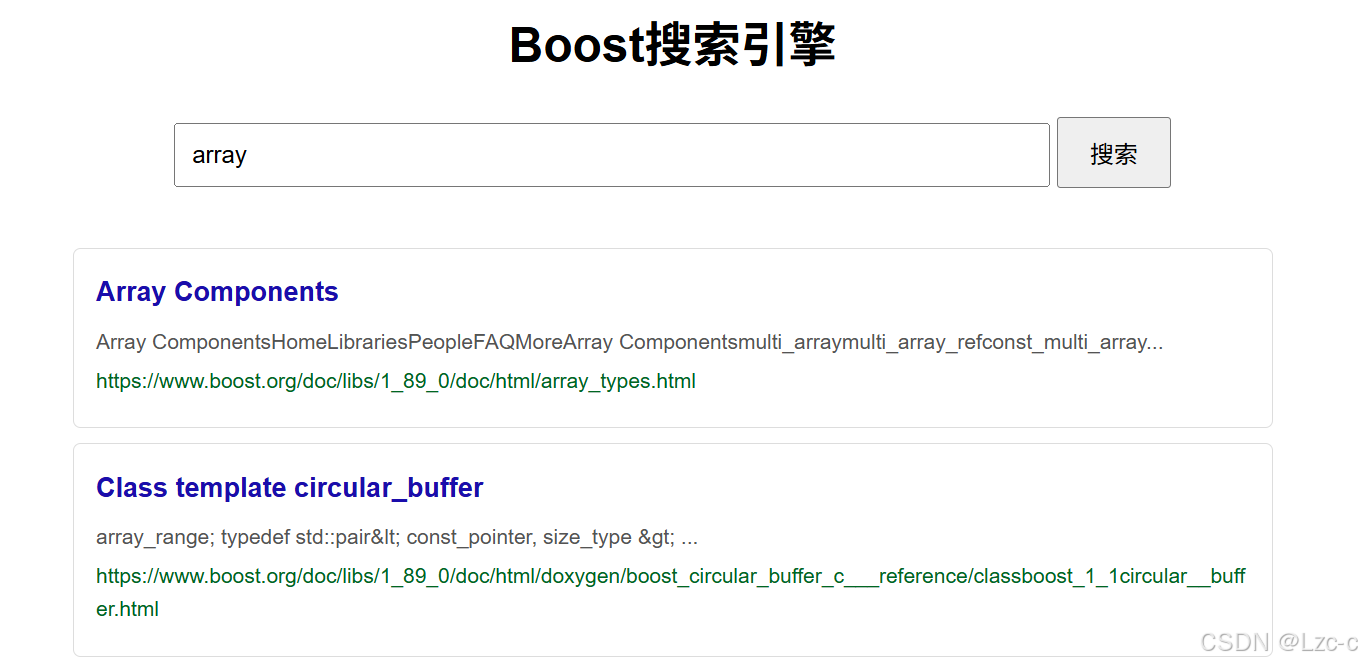
- 结果展示:
- 完整代码:boost_searcher。
6、项目总结
- 不足:
- 没有做到全站搜索,还有一些html文档不在doc/html路径下,并且只支持搜索一个版本的Boost库。
- cppjieba分词,可能会存在暂停词。
- 可优化:
- 可以利用爬虫技术,获取文档资源,并定期更新重新构建索引。
- 可以进行热词统计,显示搜索关键词。
- 可以添加登录注册的功能,引入对MySQL的使用。