引言
在掌握了顺序表的基本原理和实现后,现在是时候将它应用到实际问题中了。本文将通过实现一个完整的通讯录系统,展示顺序表在实际开发中的应用价值。同时,我们还将探讨顺序表的经典算法,并深入分析顺序表的局限性。
文章目录
[1.1 项目需求分析](#1.1 项目需求分析)
[1.2 设计思路](#1.2 设计思路)
[1.3 完整代码实现](#1.3 完整代码实现)
[1.3.1 头文件定义 (contact.h)](#1.3.1 头文件定义 (contact.h))
[1.3.2 核心实现 (contact.c)](#1.3.2 核心实现 (contact.c))
[1.3.3 主程序 (test.c)](#1.3.3 主程序 (test.c))
[2.1 移除元素(原地修改)](#2.1 移除元素(原地修改))
[2.2 合并两个有序数组](#2.2 合并两个有序数组)
[3.1 顺序表的局限性](#3.1 顺序表的局限性)
[3.2 解决方案的思考](#3.2 解决方案的思考)
[3.3 实际应用中的权衡](#3.3 实际应用中的权衡)
第一部分:基于动态顺序表实现通讯录
1.1 项目需求分析
我们的通讯录需要实现以下功能:
-
存储至少100个联系人的信息
-
支持保存姓名、性别、年龄、电话、地址等信息
-
实现增删改查基本操作
-
数据持久化保存
1.2 设计思路
数据结构设计:
cpp
#define NAME_max 20
#define SEX_max 10 //male female
#define TEL_max 20
#define Addr_max 100
typedef struct personinfo
{
char name[NAME_max];
char sex[SEX_max];
int age;
char tel[TEL_max];
char addr[Addr_max];
}perinfo;
//姓名 性别 年龄 电话 住址
//通讯录其实就是将顺序表中的数据类型修改为一个具体的联系人信息结构体
//其他结构不会发生改变
typedef perinfo sldatatype;
typedef struct seqlist //这里是对顺序表结构的创建
{
sldatatype* conf;
int len;
int capacity;
}SL;
typedef SL Contact;//其实可以在上一步就直接修改,这里只是为了方便理解为什么选择动态顺序表?
-
静态顺序表:空间固定,要么浪费要么不够
-
动态顺序表:按需分配,灵活高效
1.3 完整代码实现
1.3.1 头文件定义 (contact.h)
cpp
#pragma once
#include<stdio.h>
#include<stdlib.h>
#define NAME_max 20
#define SEX_max 10 //male female
#define TEL_max 20
#define Addr_max 100
typedef struct personinfo
{
char name[NAME_max];
char sex[SEX_max];
int age;
char tel[TEL_max];
char addr[Addr_max];
}perinfo;
//姓名 性别 年龄 电话 住址
//通讯录其实就是将顺序表中的数据类型修改为一个具体的联系人信息结构体
//其他结构不会发生改变
typedef perinfo sldatatype;
typedef struct seqlist //这里是对顺序表结构的创建
{
sldatatype* conf;
int len;
int capacity;
}SL;
typedef SL Contact;//其实可以在上一步就直接修改,这里只是为了方便理解
//通讯录的初始化 销毁 添加 删除 修改 查找 展示
void InitContact(Contact* con);
void DestroyContact(Contact* con);
void AddContact(Contact* con);
void DelContact(Contact* con);
void ModContact(Contact* con);
void FindContact(Contact* con);
void ShowContact(Contact* con);1.3.2 核心实现 (contact.c)
cpp
#define _CRT_SECURE_NO_WARNINGS
#include"contact.h"
void InitContact(Contact* con)
{
con->conf = NULL;
con->len =con->capacity = 0;
}
void DestroyContact(Contact* con)
{
if (con->conf)
free(con->conf);
InitContact(con);
}
void checkcapacity(Contact* con)
{
if (con->len == con->capacity)
{
int newcapacity = con->capacity == 0 ? 4 : 2 * con->capacity;
perinfo* newconf = (perinfo*)realloc(con->conf,newcapacity * sizeof(perinfo));
if (newconf==NULL)
{
perror("realloc failed");
exit(1);
}
con->capacity=newcapacity;
con->conf = newconf;
}
}
void AddContact(Contact* con)
{
checkcapacity(con);
printf("请输入联系人姓名:\n");
scanf("%s", con->conf[con->len].name);
printf("请输入联系人电话:\n");
scanf("%s", con->conf[con->len].tel);
printf("请输入联系人的性别:\n");
scanf("%s", con->conf[con->len].sex);
printf("请输入联系人的年龄:\n");
scanf("%d", &con->conf[con->len].age);//这里是&符号,表示地址,而不是值
printf("请输入联系人的地址:\n");
scanf("%s", con->conf[con->len].addr);
con->len++;//这里使用尾插法
}
void ShowContact(Contact* con)
{
for (int i = 0; i < con->len; i++)
{
printf("第%d个联系人的信息\n", i+1);
printf("姓名:%s ", con->conf[i].name);
printf("电话:%s ", con->conf[i].tel);
printf("性别:%s ", con->conf[i].sex);
printf("年龄:%d ", con->conf[i].age);
printf("地址:%s\n", con->conf[i].addr);
}
}
int findbyname(Contact* con, char* name)
{
for (int i = 0; i < con->len; i++)
{
if (strcmp(con->conf[i].name, name) == 0)
{
return i;
}
}
return -1;//没有找到
}
void DelContact(Contact* con)
{
char name[NAME_max];
printf("请输入要删除的联系人姓名:\n");
scanf("%s", name);
int i=findbyname(con, name);
if (i != -1)
{
for (int j = i; j < con->len - 1; j++)
{
con->conf[j] = con->conf[j + 1];
}
con->len--;
printf("删除成功!\n");
}
else printf("没有找到该联系人!\n");
}
void ModContact(Contact* con)
{
char name[NAME_max];
printf("请输入要修改的联系人姓名:\n");
scanf("%s", name);
int i = findbyname(con, name);
if (i != -1)
{
printf("请输入新的联系人姓名:\n");
scanf("%s", con->conf[i].name);
printf("请输入新的联系人电话:\n");
scanf("%s", con->conf[i].tel);
printf("请输入新的联系人的性别:\n");
scanf("%s", con->conf[i].sex);
printf("请输入新的联系人的年龄:\n");
scanf("%d", &con->conf[i].age);
printf("请输入新的联系人的地址:\n");
scanf("%s", con->conf[i].addr);
printf("修改成功!\n");
}
else
{
printf("该联系人不存在 !\n");
return;
}
}
void FindContact(Contact* con)
{
char name[NAME_max];
printf("请输入要查找的联系人姓名:\n");
scanf("%s", name);
int i = findbyname(con, name);
if (i != -1)
{
printf("第%d个联系人的信息\n", i + 1);
printf("姓名:%s ", con->conf[i].name);
printf("电话:%s ", con->conf[i].tel);
printf("性别:%s ", con->conf[i].sex);
printf("年龄:%d ", con->conf[i].age);
printf("地址:%s\n", con->conf[i].addr);
}
else
{
printf("该联系人不存在\n");
return ;
}
}1.3.3 主程序 (test.c)
cpp
//#include"seqlist.h"
//void test()
//{
// SL sl;
// seqInit(&sl);
// seqpushback(&sl, 1);
// seqpushback(&sl, 1);
// seqpushback(&sl, 2);
// seqpushback(&sl, 3);
// seqprint(&sl);
// seqpushfront(&sl, 4);
// seqprint(&sl);
// seqInsert(&sl, 2, 5);
// seqprint(&sl);
// seqDelete(&sl, 2);
// seqprint(&sl);
// seqgetlen(&sl, 2);
// seqDestory(&sl);
//}
//int main()
//{
// test();
// return 0;
//}
//整体流程
//初始化 销毁 打印 尾部插入 头部插入 尾部删除 头部删除
//指定位置插入数据 指定位置删除数据 查找某个数在顺序表中的位置
//最好写完一个模块就进行测试
#include"contact.h"
//void test()
//{
// Contact con;
// InitContact(&con);
// AddContact(&con);
// AddContact(&con);
// DelContact(&con);
// AddContact(&con);
// ModContact(&con);
// ShowContact(&con);
// DestroyContact(&con);
//}
void menu()
{
printf("***************通讯录****************\n");
printf("***** 1.添加联系人 2.删除联系人 *****\n");
printf("***** 3.修改联系人 4.查找联系人 *****\n");
printf("***** 5.显示联系人 0.退出程序 *******\n");
printf("*************************************\n");
}
int main()
{
int op = -1;
Contact con;
InitContact(&con);
void (*pfun[6])(Contact*) = {DestroyContact, AddContact, DelContact, ModContact, FindContact, ShowContact};
do
{
menu();
printf("请选择将要进行的操作\n");
scanf("%d", &op);
if (op >= 0 && op <= 5)
{
pfun[op](&con);
}
else
{
printf("输入错误,请重新输入!\n");
}
} while (op != 0);
return 0;
}注释部分可以用来对各个功能的进行测试,所以进行保留。很多操作都是与顺序表中的操作一样,可以看看顺序表知识。
第二部分:顺序表经典算法
2.1 移除元素(原地修改)
问题描述:给定一个数组和一个值,移除数组中所有等于该值的元素,返回新长度。
cpp
int removeElement(int* nums, int numsSize, int val) {
int slow = 0; // 慢指针,指向下一个有效位置
for (int fast = 0; fast < numsSize; fast++) {
if (nums[fast] != val) {
nums[slow] = nums[fast];
slow++;
}
}
return slow; // 新数组长度
}2.2 合并两个有序数组
问题描述 :将两个有序数组合并为一个有序数组。问题链接
算法实现(从后向前合并):
cpp
void merge(int* nums1, int nums1Size, int m,
int* nums2, int nums2Size, int n) {
int i = m - 1; // nums1的有效元素末尾
int j = n - 1; // nums2的末尾
int k = m + n - 1; // 合并后的末尾
// 从后向前合并,避免元素覆盖
while (i >= 0 && j >= 0) {
if (nums1[i] > nums2[j]) {
nums1[k] = nums1[i];
i--;
} else {
nums1[k] = nums2[j];
j--;
}
k--;
}
// 如果nums2还有剩余元素
while (j >= 0) {
nums1[k] = nums2[j];
j--;
k--;
}
}或者将数组合并,然后用冒泡排序:
cpp
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{
for(int i=0;i<n;i++)
{
nums1[i+m]=nums2[i];
}
for(int i=0;i<m+n;i++)
{
for(int j=1;j<m+n-i;j++)
{
int tmp=nums1[0];
if(nums1[i]>nums1[i+1])
{
tmp=nums1[i];
nums1[i]=nums1[i+1];
nums1[i+1]=tmp;
}
}
}
}第三部分:顺序表的问题及思考
3.1 顺序表的局限性
通过实现通讯录和算法练习,我们发现了顺序表的一些问题
1.插入删除效率低
时间复杂度:O(n),最坏情况需要移动所有元素
2.扩容成本高
-
需要申请新空间
-
复制所有数据
-
释放旧空间
3.空间浪费
-
扩容通常按2倍增长
-
可能出现容量远大于实际需求的情况
-
例如:当前容量100,扩容到200,但只用了105个位置
3.2 解决方案的思考
这些问题引出了对更好数据结构的需求:
-
链表:解决插入删除效率问题
-
不需要移动元素
-
每个元素独立分配空间
-
-
更智能的扩容策略
-
按需扩容,避免浪费
-
缩容机制,释放多余空间
-
-
其他数据结构的选择
-
哈希表:快速查找
-
树结构:有序存储和快速查找
-
3.3 实际应用中的权衡
在实际开发中,我们需要根据具体需求选择数据结构:
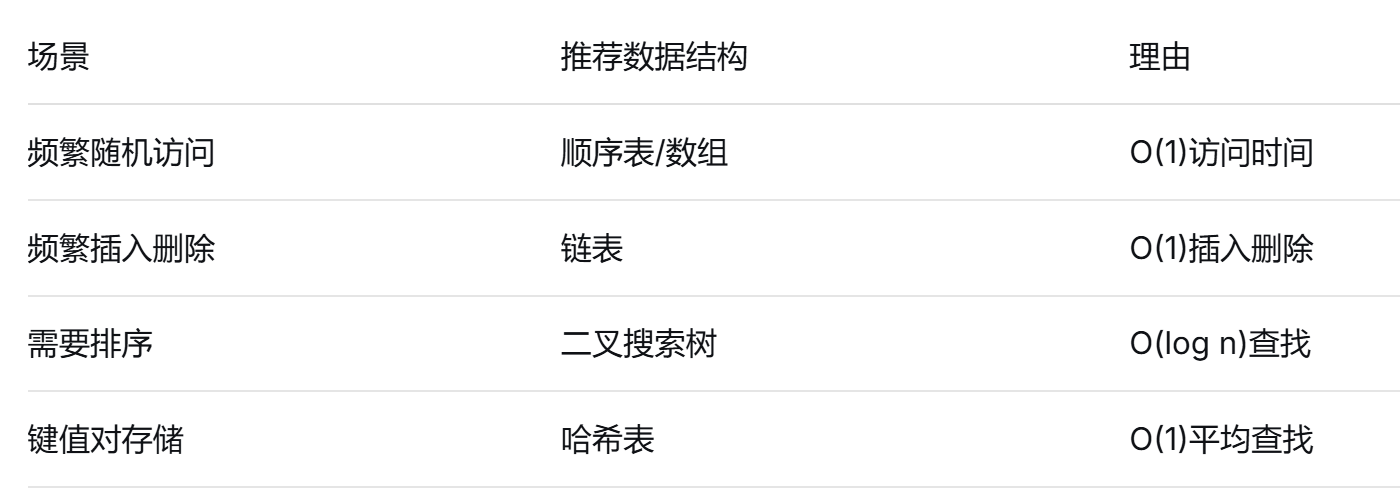
结语
通过实现通讯录项目,我们看到了顺序表在实际应用中的价值。它简单、高效,特别适合读多写少的场景。同时,我们也认识到了它的局限性,这为后续学习更复杂的数据结构(如链表、树、哈希表)提供了动机。
顺序表是数据结构的起点,但不是终点。在接下来的学习中,我们将探索更多高效的数据组织方式,每种结构都有其独特的优势和适用场景。
下一站:链表 - 我们将学习如何解决顺序表插入删除效率低的问题,实现更加灵活的数据存储结构。