海量数据去重的利器:布隆过滤器(Bloom Filter)深度解析与实战
在互联网开发中,我们经常会遇到海量数据判重 的场景。比如,在开发类似"今日头条"的新闻客户端时,如何保证推荐给用户的内容不重复?如果每个用户的历史记录都存入关系型数据库,频繁的 EXISTS 查询会瞬间击垮数据库;如果存入 Redis 的 Set,随着用户阅读量增长,内存消耗将变得不可接受。
这时候,布隆过滤器(Bloom Filter) 便是兼顾性能与内存空间的"杀招"。
一、 什么是布隆过滤器?
布隆过滤器由 Burton Howard Bloom 于 1970 年提出。它是一种概率型数据结构,特点是利用极小的空间成本,判断一个元素是否在一个集合中。
核心特性
-
空间效率极高:通常只需要哈希表 1/8 到 1/4 的空间。
-
判断逻辑:
-
当布隆过滤器说"数据不存在"时,该数据一定不存在(100%准确)。
-
当布隆过滤器说"数据存在"时,该数据可能不存在(存在误判率)。
-
只增不减 :标准布隆过滤器支持插入,但不支持删除。
二、 工作原理
布隆过滤器的底层是一个位数组(Bit Array),初始状态全部位均为 0。
- 添加元素:使用 个相互独立的哈希函数对元素进行计算,得到 个位置,并将位数组中对应的位置全部设为 1。
- 查询元素 :同样使用这 个哈希函数计算位置。如果所有对应位都是 1,则认为元素可能存在 ;只要有一位是 0,则该元素一定不存在 。
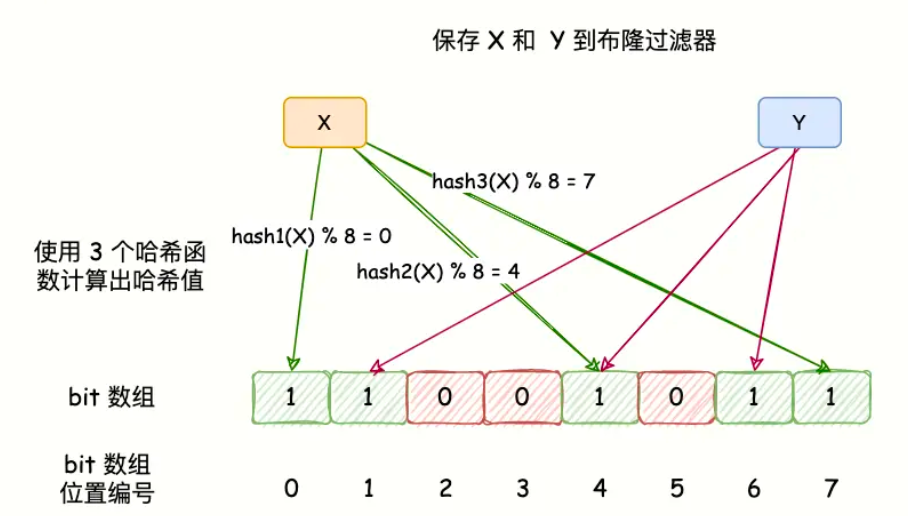
为什么会有误判?
由于哈希碰撞的存在,不同的 key 经过哈希后可能会映射到相同的位上。如果某些位被其他元素置为了 1,查询一个不存在的 key 时也可能发现对应位全为 1,从而产生误判。
为什么不能删除?
删除需要将对应的 个位置重置为 0。但由于一个位置可能同时被多个元素共用,删除操作会连带影响其他元素的判断,导致本该存在的元素被判为不存在(False Negative),这违背了布隆过滤器的基本可靠性。
三、 应用场景
布隆过滤器适用于对内存敏感、且能容忍极小误判率的场景:
- 解决 Redis 缓存穿透:在查询数据库之前,先过一遍布隆过滤器。如果过滤器判断数据不存在,直接返回,避免无效请求冲击数据库。
- 邮件黑名单过滤:判断发件人是否在数亿级的黑名单库中。
- 爬虫去重:记录已爬取的 URL,避免重复爬取。
- 推荐系统去重:如新闻 APP 过滤已读文章,确保用户每次刷到的都是新鲜内容。
四、 Redis 实战指南
Redis 通过 RedisBloom 模块原生支持了布隆过滤器。以下是核心命令实战:
1. 创建过滤器
建议在使用前手动创建,以控制误判率和初始容量。
bash
# BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}]
BF.RESERVE orders 0.1 10000000- error_rate:期望误判率,默认 0.1。值越小,占用的位数组越长。
- capacity:初始容量。实际元素超过此值时,误判率会上升。
- EXPANSION:自动扩容系数,默认是 2。
2. 添加元素
bash
# 单个添加
BF.ADD orders 10086
# 批量添加
BF.MADD orders 10087 100893. 判断是否存在
bash
# 单个检查
BF.EXISTS orders 10086 # 返回 1 表示存在
# 批量检查
BF.MEXISTS orders 100 10089 # 返回 [0, 1]4. 查看过滤器信息
bash
BF.INFO orders通过此命令可以观察已插入的元素数量(Number of items inserted)和过滤器层数(Number of filters)。
五、 总结与选型建议
布隆过滤器是海量数据判重的首选方案,但它也有局限性。如果你在项目中:
- 需要严格支持删除操作 :请考虑使用 布谷鸟过滤器(Cuckoo Filter),它支持删除且查询效率在某些场景下更高。
- 无法预估数据规模:注意 Redis 布隆过滤器的扩容会导致查询性能略微下降,因为扩容是通过堆叠多层过滤器实现的。
开发建议 :在设计系统时,务必根据业务规模预估 capacity,并权衡 error_rate 带来的空间消耗。