在互联网的世界里,数据是金矿,而 KV 存储就是我们挖矿用的铲子。
KV 存储,说白了就是 Key-Value 存储系统:给个 Key,就能快速拿到 Value。
比如用户登录信息、缓存数据、热点配置......都离不开它。
那你想过没有,当你的业务从几千并发涨到几百万甚至上亿并发时,这个"铲子"还能扛得住吗?
今天就来讲讲------美团万亿级 KV 存储系统的架构演化史------从最开始的"小作坊"一步步走向"分布式王者"的全过程。
一、KV 存储发展历程
️ 第一代:Memcached + 一致性哈希
还记得那个年代吗?美团用的是 Memcached,客户端自己做一致性哈希,后端部署一堆 Memcached 实例。
听起来是不是很熟悉?没错,这就是很多公司最初使用的 KV 存储架构。
但问题也很明显:
- 节点宕机 → 数据丢失;
- 扩容 → 数据重分布,可能丢数据;
- 客户端复杂度高;
- 没有自动故障转移机制;
- 没有持久化能力......
这就像是你家里搭了个简易书架,刚开始还能应付,书一多就开始摇晃,动不动就倒。
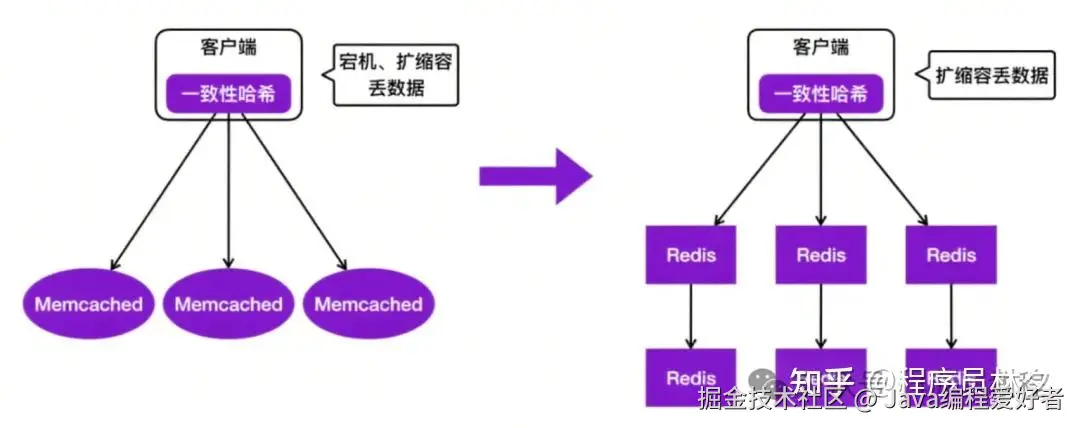
第二代:Redis 主从架构 + 哨兵机制
随着 Redis 社区逐渐成熟,也引入了 Redis,架构升级为:
客户端\] → \[一致性哈希\] → \[Redis [主从集群](https://link.juejin.cn?target=https%3A%2F%2Fzhida.zhihu.com%2Fsearch%3Fcontent_id%3D260370939%26content_type%3DArticle%26match_order%3D1%26q%3D%25E4%25B8%25BB%25E4%25BB%258E%25E9%259B%2586%25E7%25BE%25A4%26zhida_source%3Dentity "https://zhida.zhihu.com/search?content_id=260370939&content_type=Article&match_order=1&q=%E4%B8%BB%E4%BB%8E%E9%9B%86%E7%BE%A4&zhida_source=entity")
这时候,Redis 哨兵机制可以实现 Failover,解决了节点宕机的问题,读写分离也更容易。
但还有一个痛点没解决:扩缩容依然会丢数据!
因为一致性哈希机制决定了,节点变动就会导致 Key 映射变化,老数据找不到地方去,照样会丢。
所以,是时候换个更成熟的方案了。
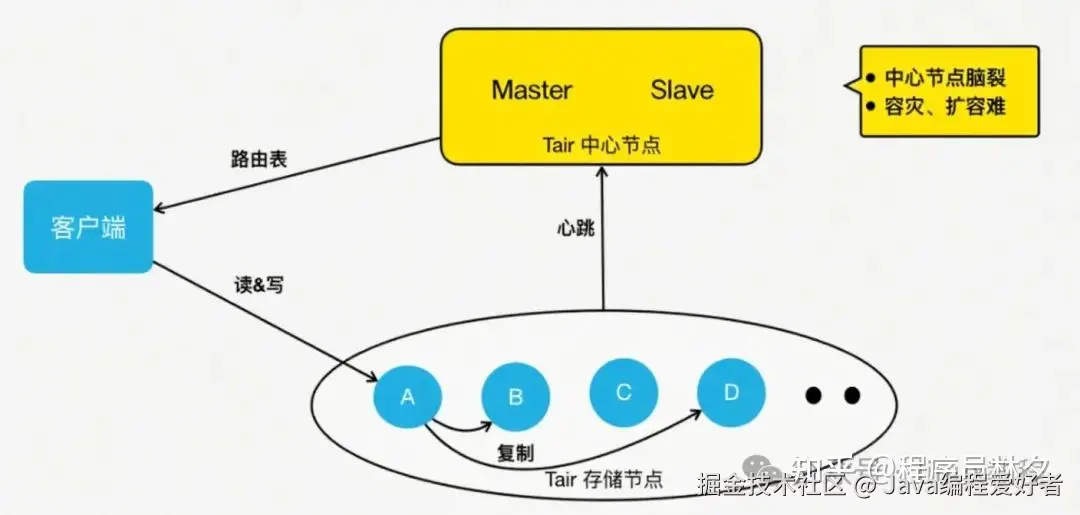
第三代:Tair 分布式架构
这个时候,阿里开源的 Tair 成为了新选择。
它的架构分为三部分:
客户端\] → \[[中心节点](https://link.juejin.cn?target=https%3A%2F%2Fzhida.zhihu.com%2Fsearch%3Fcontent_id%3D260370939%26content_type%3DArticle%26match_order%3D1%26q%3D%25E4%25B8%25AD%25E5%25BF%2583%25E8%258A%2582%25E7%2582%25B9%26zhida_source%3Dentity "https://zhida.zhihu.com/search?content_id=260370939&content_type=Article&match_order=1&q=%E4%B8%AD%E5%BF%83%E8%8A%82%E7%82%B9&zhida_source=entity")\] → \[存储节点
- 客户端不再自己算路由,而是从中心节点拉取"路由表";
- 中心节点有两个配置管理节点,负责监控所有存储节点;
- 当节点宕机或扩容时,它能自动重建拓扑,并触发数据迁移;
- 客户端根据新的路由表访问对应的存储节点。
这样一来,扩缩容不再丢数据 ,Tair 通过数据迁移机制保证了数据完整性。
看起来很完美?
但又遇到了新的问题
⚠️ Tair 的局限性:脑裂、迁移影响业务、数据结构不丰富
虽然 Tair 解决了很多问题,但在使用过程中发现:
- 中心节点虽然是主备架构,但没有分布式仲裁机制
- ,在网络分区情况下容易出现"脑裂";
- 数据迁移期间性能波动大
- ,影响线上业务;
- 相比 Redis,Tair 不支持丰富的数据结构
- ,很多 Redis 用户用起来不习惯;
- 开源版本四五年未更新,迭代完全靠自己维护。
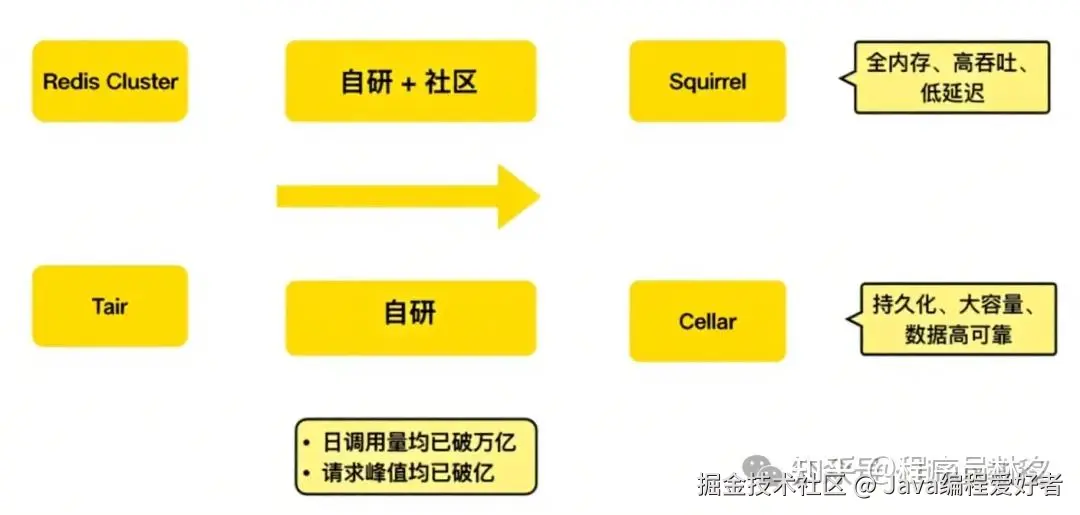
于是美团决定:在已有开源系统的基础上,开启自研之路!
第四代:自研双引擎架构Squirrel & Cellar
美团基于 Redis Cluster 和 Tair 分别开发了两个不同的 KV 存储系统:
Squirrel:全内存、低延迟、高吞吐的缓存引擎
- 基于 Redis Cluster 架构优化;
- 支持 Redis 全部数据结构;
- 适用于对延迟敏感、数据量小的场景;
- 自研功能尽量兼容官方架构,方便未来升级;
- 目前已支撑每秒亿级请求。
️ Cellar:持久化、大容量、高可靠的数据存储引擎
- 基于 Tair 改造,加入大量自研特性;
- 支持数据落盘、冷热分离;
- 适用于数据量大、对延迟容忍度高的场景;
- 因为 Tair 社区停滞,Cellar 完全由美团团队自主迭代;
- 同样支撑每秒亿级请求。
这两个系统相辅相成,构成了美团内部的"KV 双子星"。
关注【Linux教程】,获取编程学习路线、项目教程、简历模板、大厂面试题pdf文档、大厂面经、编程交流圈子等等。

二、 内存KV存储 Squirrel 架构揭秘
前面讲了美团整个 KV 存储系统的演化史,从 Memcached 到 Redis,再到 Tair,最终形成了美团现在的两大主力系统:Squirrel(全内存) 和 Cellar(持久化) 。
接下来就重点来看看 Squirrel 是怎么设计出来的?它又是如何支撑起万亿级请求的?
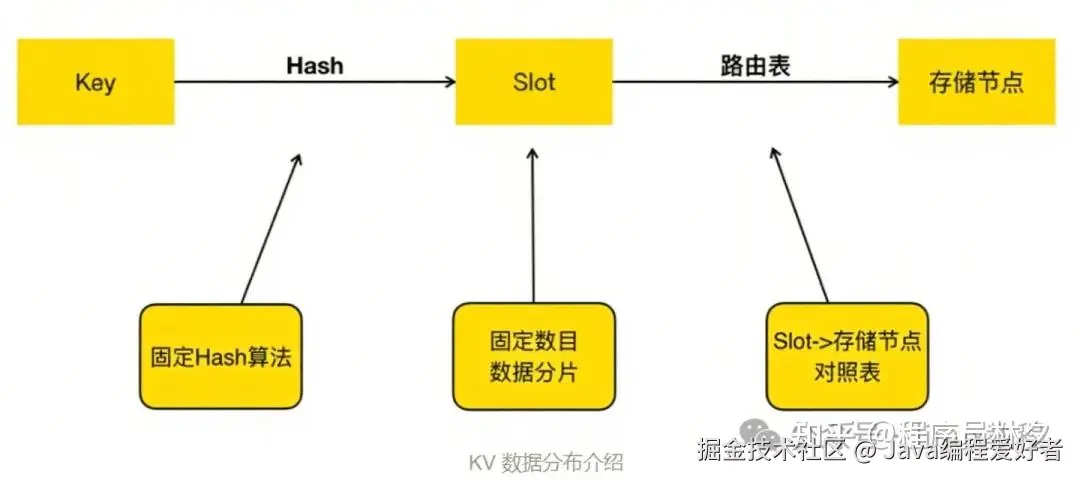
2.1、数据分布机制:Key 是怎么找到"家"的?
先说个关键问题:Key 是怎么分布到各个节点上的?
这个问题在分布式系统里叫"数据分片",而在 Squirrel 和 Cellar 中,美团采用的是 Redis Cluster 的经典方案:
vbnet
Key → 哈希计算 → Slot ID → 路由表映射 → 找到目标节点具体来说:
- 预分片机制
- :美团预先划分了 16384 个 Slot(跟 Redis Cluster 一致);
- 哈希算法固定
- :每个 Key 经过 CRC32 哈希后取模,得到一个 Slot ID;
- 路由表控制分配
- :Slot 到节点的映射通过路由表维护;
- 客户端直连
- :客户端根据最新的路由表直接访问对应节点,不经过代理层;
这种方式的好处是:
- 分布均匀;
- 易于扩缩容;
- 客户端负担可控;
- 与 Redis 社区生态兼容性强。
你可以把它想象成"快递分拣系统":
快递员拿到包裹(Key),扫描一下编号(CRC32),查一下分拣柜(Slot ID),然后按照最新的派送地图(路由表)送到对应的站点(Redis 实例)。
2.2、高可用设计:宏观容灾 & 微观稳定性都要抓!
说到高可用,很多人第一反应是"别挂",但其实它包含两个层面的理解:
✅ 宏观高可用:能扛住大风大浪
- 单点故障(宕机) → 自动 Failover;
- 多节点宕机 → 主动迁移副本;
- 机房级故障 → 支持跨机房部署和切换;
- 区域级故障 → 异地多活备份;
这就像你在家里准备了一个备用电源,小区停电也不怕。
✅ 微观高可用:让每一次请求都稳稳当当
这就像你开车的时候遇到小坑小路,车自己帮你缓冲过去了,你根本没感觉。
美团在 Squirrel 的设计中,从这两个维度都做了大量工作,确保系统既"扛得住大事",也"经得起小事"。
2.3、Squirrel 架构解析:Redis Cluster 的增强版
来看一下 Squirrel 的整体架构图
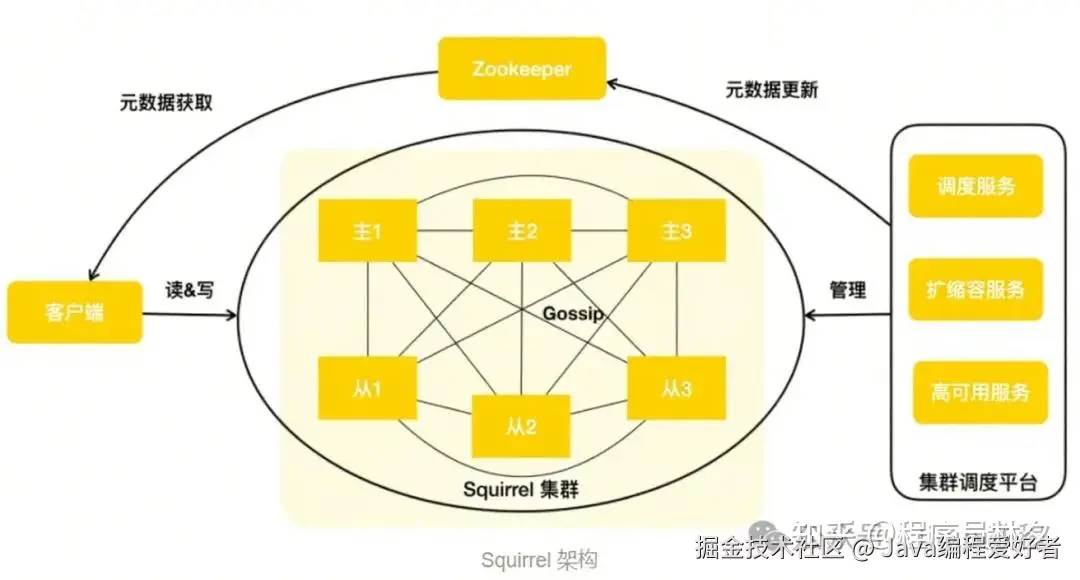
各组件说明:
| 组件 | 作用 |
|---|---|
| 客户端 SDK | 拉取路由表、执行请求、自动重试、失败转移 |
| ZooKeeper | 存储集群元数据,如 Slot 分配、主从拓扑等 |
| 集群调度平台 | 负责扩缩容、故障转移、负载均衡等自动化运维 |
| Redis 实例 | 主从结构,负责实际的数据读写 |
| Gossip 协议 | 实例之间互相通信,同步状态信息 |
Squirrel 本质上是在 Redis Cluster 的基础上,加上美团自研的调度平台和客户端 SDK,打造出了一个全内存、低延迟、高吞吐、高可用 的分布式缓存系统。它不仅继承了 Redis 的丰富生态,还在易用性、稳定性、扩展性方面做了大量增强。
2.4、Squirrel 节点容灾
我们再来回顾一下 Squirrel 是如何实现节点容灾的。对于 Redis 集群来说,官方已经提供了一套较为完备的节点宕机处理机制。按照标准流程,任何一个节点从发生宕机到被标记为 FAIL 并最终摘除,通常需要约 30 秒时间。
对于主库的摘除操作,需要格外谨慎,因为它可能影响数据的一致性。但如果是从库呢?美团认为这个等待过程是不必要的。此外,也注意到,内存型 KV 存储的数据量一般较小,但在业务规模较大的公司中,往往会存在大量的集群。一旦发生交换机故障,可能会同时影响多个集群,宕机后补副本的操作就会变得非常繁琐。
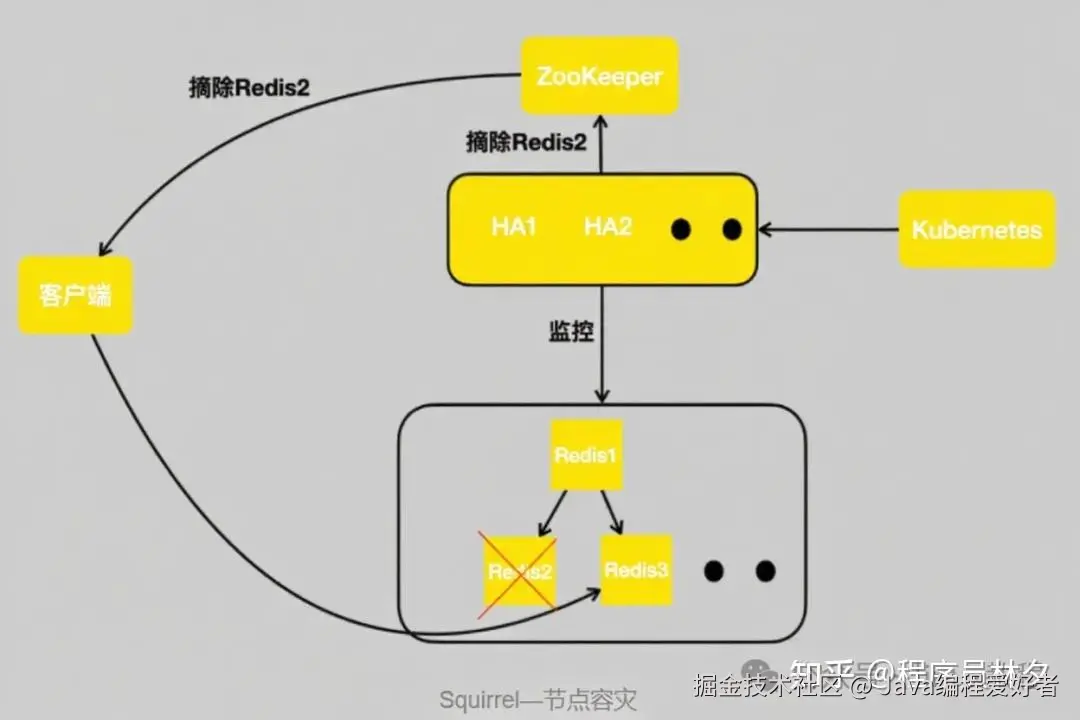
为了解决上述两个问题,美团设计并实现了 HA(High Availability)高可用服务。
它的架构如下图所示,能够实时监控集群中的所有节点。无论是网络抖动还是节点宕机(例如 Redis 2),HA 都能迅速感知,并实时更新 ZooKeeper,通知其摘除 Redis 2。客户端接收到变更通知后,会将读流量自动路由到 Redis 3 上。
如果 Redis 2 只是几十秒的短暂网络抖动,在 HA 检测到它恢复之后,会将其重新加回集群。
如果过了一段时间,HA 判断该节点属于永久性宕机,则会直接向 Kubernetes 集群申请一个新的 Redis 容器实例(如 Redis 4),并将其加入集群。此时,集群拓扑结构恢复为一主两从的标准结构。HA 更新完集群拓扑信息后,会写入 ZooKeeper,通知客户端更新路由表,使其能够将读请求转发到新的从节点 Redis 4 上。
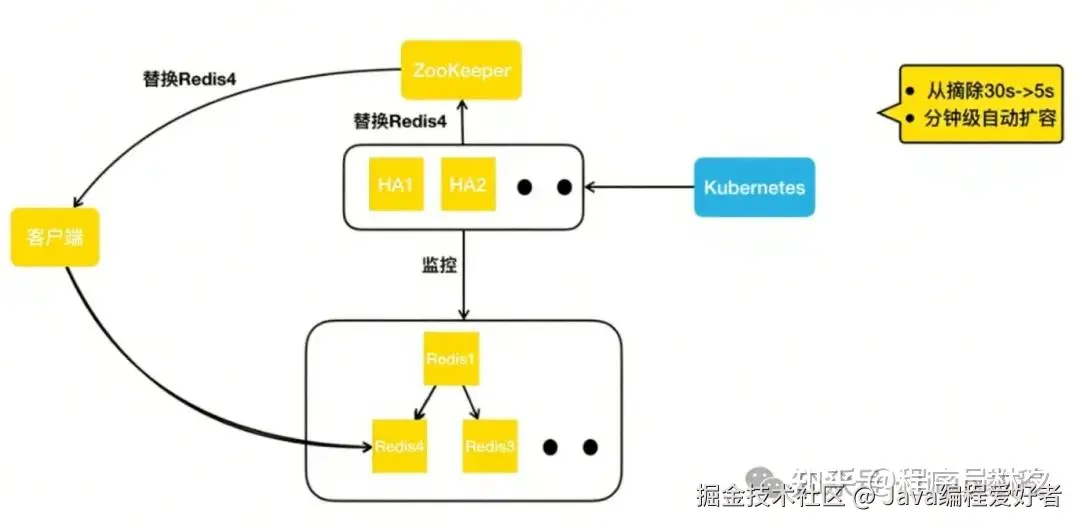
通过这套机制,美团将从库的摘除时间由原来的 30 秒缩短至 5 秒以内。同时,借助 HA 自动申请容器实例的能力,美团实现了分钟级的宕机补副本操作,整个过程无需任何人工介入。
2.5、Squirrel 跨地域容灾
解决了单节点宕机的问题之后,美团再来看跨地域部署场景下的挑战。跨地域容灾与同地域部署相比,存在两个显著差异:
第一,相对于同地域机房间的网络环境,跨地域专线的稳定性较差;
第二,跨地域专线带宽有限且成本高昂。
而原生 Redis 集群内的复制机制并未考虑极端网络状况的影响。比如,如果美团把主库部署在北京,两个从库部署在上海,同一份数据需要通过北上专线传输两次,这将造成巨大的带宽浪费。
此外,随着业务的发展演进,美团也在推进单元化部署和异地多活架构。显然,使用 Redis 原生的主从同步机制已无法满足美团的需求。因此,进一步开发了集群间复制方案。
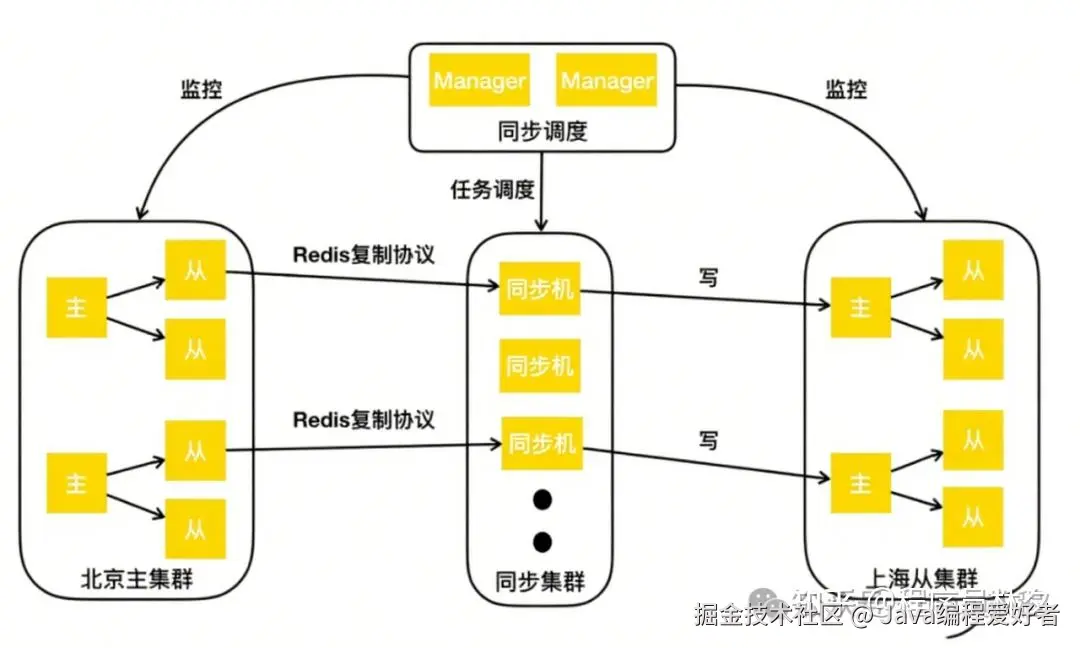
如上图所示,美团以北京的主集群和上海的从集群为例进行说明。美团要实现的是:通过集群同步服务,将北京主集群的数据同步到上海从集群。
具体流程如下:
首先,向同步调度模块下发"建立两个集群间同步链路"的任务。调度模块根据主从集群的拓扑结构,将同步任务下发至同步集群。同步集群接收到任务后,会模拟一个 Redis 的 Slave 节点,通过 Redis 的复制协议,从主集群的从库拉取数据,包括初始的 RDB 快照以及后续的增量变更。同步机获取到这些数据后,会将其转换为客户端的写命令,并写入到上海从集群的主节点中。
通过这样的方式,美团成功地将北京主集群的数据同步到了上海从集群。若要实现异地多活,只需添加一条反向的同步链路即可,从而实现集群间的双向数据同步。
接下来,继续讨论微观层面的高可用保障,即如何维持端到端的高成功率。在 Squirrel 中,主要有以下三类问题会影响成功率:
① 数据迁移造成的超时抖动;
② 持久化操作引起的超时抖动;
③ 热点 Key 请求导致单个节点负载过高。
2.6、Squirrel 智能迁移
在数据迁移方面,美团主要面临以下三个挑战:
① 虽然 Redis Cluster 提供了 Slot 迁移能力,但它并不负责决定迁哪些 Slot,也不指定 Slot 从哪个节点迁移到哪个节点;
② 在实际迁移过程中,大家都希望迁移越快越好,但迁移速度过快又可能对正常业务请求产生干扰;
③ Redis 的 MIGRATE 命令会阻塞工作线程,尤其在迁移大 Value 时,主线程会被长时间阻塞,严重影响性能。
为了解决这些问题,构建了一整套全新的智能迁移服务。
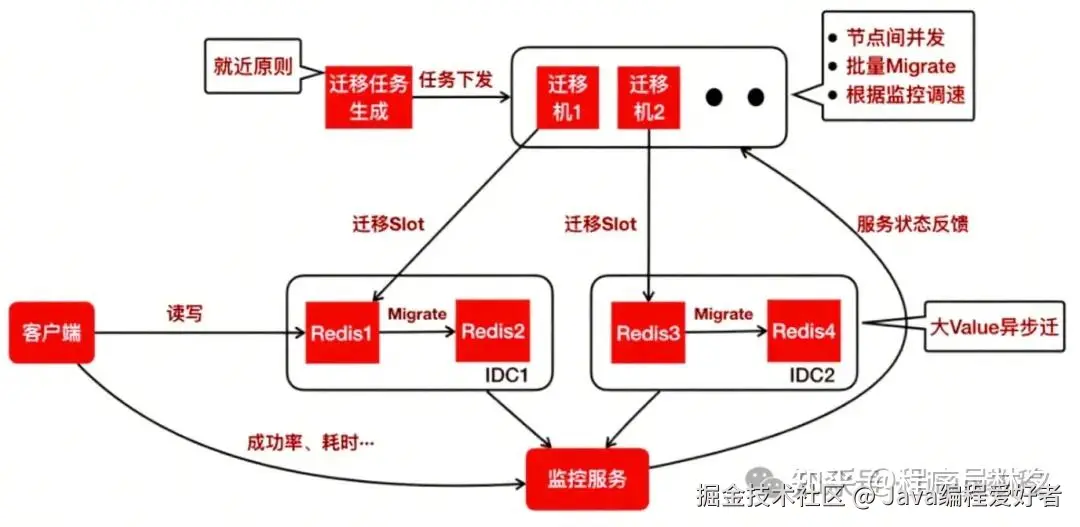
该服务具备以下几个关键特性:
- 支持自动化决策 Slot 的迁移源与目标;
- 动态控制迁移速率,避免影响线上业务;
- 引入异步非阻塞迁移机制,解决大 Value 阻塞主线程问题;
- 支持并发迁移多个 Slot,提升整体效率;
通过这套智能迁移服务,在保证系统稳定性的前提下,大幅提升了数据迁移的速度与灵活性。
下面按照工作流来介绍迁移服务是如何运行的。
首先,生成迁移任务。这一步的核心原则是"就近优先"。例如,在同机房内的两个节点之间进行迁移,相比跨机房迁移效率更高、延迟更低。因此,在生成任务时会优先选择网络距离更近的节点作为源和目标。
迁移任务生成之后,会下发到一组专门用于执行迁移操作的迁移机上。迁移过程中,迁移机具备以下几个关键特性:
- 集群内并发迁移
- :迁移机会在多个迁出节点之间并发执行迁移命令。例如,可以同时向 Redis 1 和 Redis 3 下发迁移指令,提高整体迁移效率;
- 批量 Key 迁移
- :每次执行 MIGRATE 命令时,不是只迁移一个 Key,而是迁移一批 Key,从而减少网络往返次数,提升吞吐量;
- 动态速率控制
- :美团会通过监控服务实时采集客户端的成功率、响应耗时,以及服务端的负载、QPS 等指标,并将这些状态反馈给迁移机。整个迁移过程类似于 TCP 的慢启动机制:迁移速度会逐步提升,一旦检测到请求成功率下降或延迟上升,迁移速度就会自动降低,最终达到一种动态平衡------在尽可能快完成迁移的同时,最小化对正常业务请求的影响。
接下来,来看一下大 Value 的迁移问题。
Redis 原生的 MIGRATE 命令在迁移大 Value 时会阻塞主线程,严重影响服务的响应性能。为此,美团实现了一个异步 MIGRATE 命令。
该命令在执行过程中,Redis 的主线程不会被阻塞,仍然可以继续处理其他正常的请求。如果在此期间有针对正在迁移 Key 的写请求到达,Redis 会返回错误信息,以避免数据不一致的问题。
通过这一改造,美团最大限度地保障了业务请求的稳定性,同时避免了主线程因迁移大 Value 而陷入长时间阻塞的风险。
2.7、Squirrel 持久化重构
在 Redis 的主从同步过程中,会生成 RDB 快照文件。生成 RDB 的过程通常通过调用 fork() 创建一个子进程来将内存数据写入磁盘。虽然操作系统提供了写时复制(Copy-on-Write,COW)机制来优化这一过程,但当内存使用量达到 10GB 或 20GB 以上时,fork() 仍可能导致整个 Redis 进程出现接近秒级的阻塞。
这对在线业务来说几乎是不可接受的。此外,为了满足对数据可靠性要求较高的业务场景,美团也会开启 AOF 持久化功能。然而,在高写入压力下,AOF 刷盘操作可能因 I/O 抖动造成主线程阻塞,从而影响请求的成功率。
为了解决官方持久化机制带来的这两个问题,美团对 Redis 的持久化机制进行了全面重构。
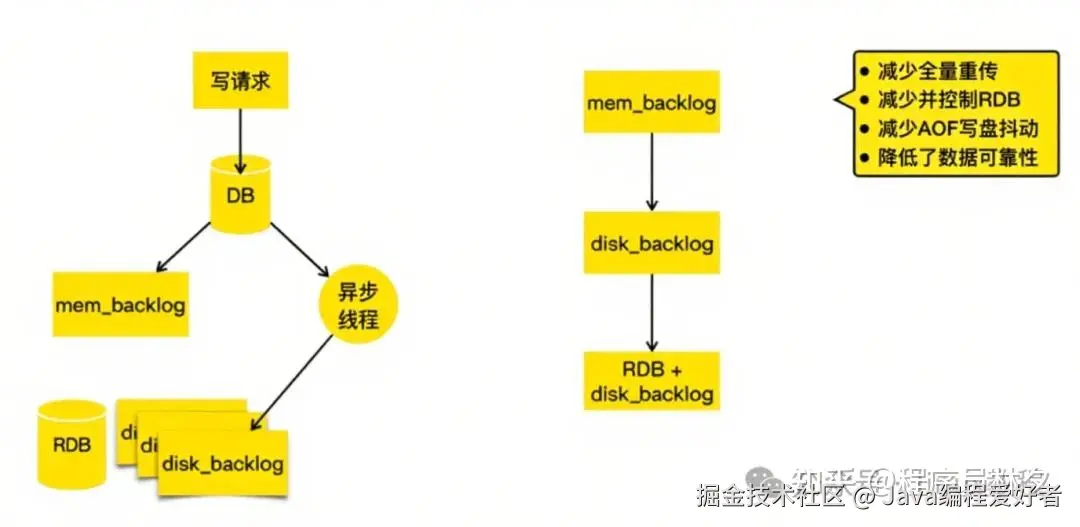
以下是新版持久化机制的核心流程:
写请求\] → \[写入 DB\] → \[记录到内存 [Backlog](https://link.juejin.cn?target=https%3A%2F%2Fzhida.zhihu.com%2Fsearch%3Fcontent_id%3D260370939%26content_type%3DArticle%26match_order%3D1%26q%3DBacklog%26zhida_source%3Dentity "https://zhida.zhihu.com/search?content_id=260370939&content_type=Article&match_order=1&q=Backlog&zhida_source=entity")\] → \[[异步线程](https://link.juejin.cn?target=https%3A%2F%2Fzhida.zhihu.com%2Fsearch%3Fcontent_id%3D260370939%26content_type%3DArticle%26match_order%3D1%26q%3D%25E5%25BC%2582%25E6%25AD%25A5%25E7%25BA%25BF%25E7%25A8%258B%26zhida_source%3Dentity "https://zhida.zhihu.com/search?content_id=260370939&content_type=Article&match_order=1&q=%E5%BC%82%E6%AD%A5%E7%BA%BF%E7%A8%8B&zhida_source=entity")刷盘到硬盘 Backlog
具体改进如下:
- 写请求首先写入数据库;
- 同时记录到内存中的 Backlog 中,这部分与官方实现一致;
- 异步线程负责将变更持续地刷写到硬盘 Backlog 中;
- 当硬盘 Backlog 积累过多时,会选择在业务低峰期触发一次 RDB 快照,并删除该 RDB 之前的所有硬盘 Backlog 数据,以节省存储空间。
那么,当需要进行主从同步并寻找同步点时,这套机制又是如何工作的呢?
处理流程如下:
- 首先查找内存 Backlog
- :如果同步点在内存 Backlog 中存在,则直接使用;
- 若内存中未找到,则查找硬盘 Backlog
- :由于硬盘容量远大于内存,因此硬盘 Backlog 可以保留大量历史数据,大大降低了找不到同步点的概率;
- 如果硬盘 Backlog 中也找不到同步点
- :则会触发一次类似全量同步的操作。但与官方不同的是,这次全量同步无需重新生成 RDB 文件,而是直接利用已有的硬盘 RDB 文件及其之后的硬盘 Backlog 完成同步。
通过这一设计,美团显著减少了全量同步的次数,提升了主从同步的成功率与效率。
2.8、Squirrel 热点 Key 解决方案
接下来介绍 Squirrel 是如何应对热点 Key 问题的。如下图所示,普通主从节点构成了正常集群的一部分,而"热点主从节点"则是独立于正常集群之外的一组特殊节点。
它们之间是如何协作的呢?来看一下完整流程:
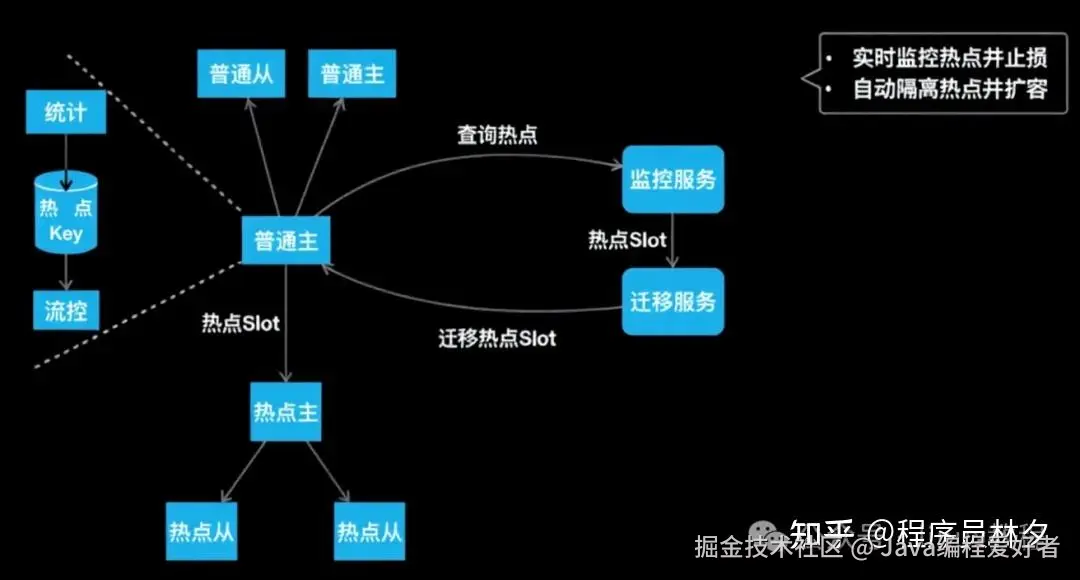
当客户端向普通节点发起读写请求时,Redis 实例会在内部同时对 Key 的访问频率进行统计。一旦某个 Key 达到预设的访问频率或带宽占用阈值,系统就会自动触发流控机制,限制对该热点 Key 的访问,防止节点因突发流量被打满。
与此同时,美团的监控服务会定期扫描所有 Redis 实例,收集统计到的热点 Key 信息。一旦发现热点 Key 存在,监控服务会将对应的 Slot 上报给迁移服务。
迁移服务接收到通知后,会执行以下动作:
- 将一组专门用于处理热点流量的"热点主从节点"加入当前集群;
- 将包含热点 Key 的 Slot 整体迁移到这组热点主从节点上;
由于这些热点节点仅承载热点 Slot 的请求,其处理能力得到了显著提升。这样一来,就实现了:
- 实时热点 Key 监控;
- 自动流控止损;
- 热点 Slot 的快速隔离与扩容;
- 高效应对突发访问压力;
通过这一整套机制,美团不仅有效避免了单个节点因热点请求过载而导致的服务异常,还实现了对热点流量的动态响应和弹性扩展。
三、持久化 KV Cellar 架构和实践
接下来介绍持久化 KV 系统 ------ Cellar 的架构设计与工程实践。下图是 Cellar 架构图。
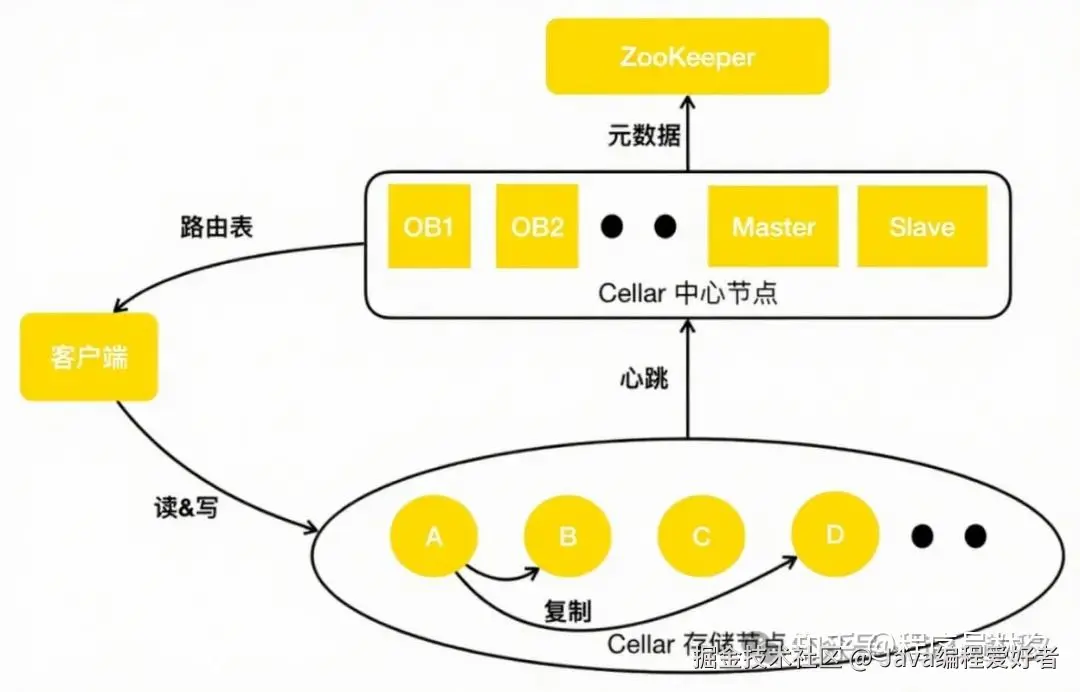
相较于阿里开源的 Tair,美团在架构层面做了两个关键改进:一是引入了 OB(Observer)节点 ,二是引入了 ZooKeeper 来增强集群的元数据管理能力。
OB 的作用类似于 ZooKeeper 的 Observer 角色,它主要负责提供中心节点的元数据查询服务。OB 实时从中心节点的 Master 同步最新的路由表信息,客户端通过 OB 获取路由表,而不是直接访问 Master。
这种设计带来了两个显著优势:
- 天然隔离客户端与 Master
- ,防止大量客户端请求对 Master 造成压力;
- OB 不参与集群管理决策
- ,只提供读取服务,因此可以水平扩展,极大提升了路由表的查询能力。
为了进一步提升系统的高可用性与一致性,美团引入了 ZooKeeper 做分布式仲裁,解决在网络分区(脑裂)场景下 Master 与 Slave 之间的冲突问题。同时,美团将集群的核心元数据存储在 ZooKeeper 中,保障了元数据的可靠性与一致性。
3.1、Cellar 节点容灾
了解完整体架构后,来看一下 Cellar 是如何实现节点容灾的。
在实际运行中,节点宕机或网络抖动通常是临时性的故障 。如果每次节点短暂离线都触发副本重建和数据补全操作,会消耗大量资源并影响业务请求。为应对这一挑战,美团设计了 Handoff 机制。
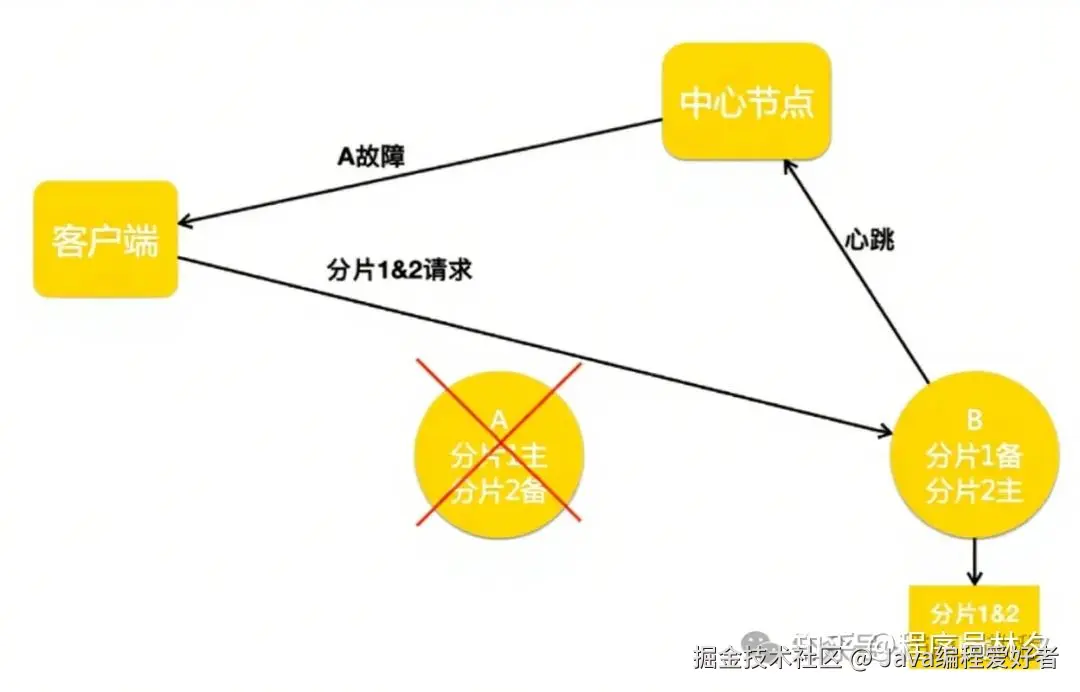
如上图所示,当 A 节点宕机后,系统会触发 Handoff 流程。中心节点通知客户端:A 节点不可用,将原本属于 A 的分片 1 请求转发到 B 节点。B 节点在处理正常请求的同时,还会将应写入 A 的数据记录在本地日志中。
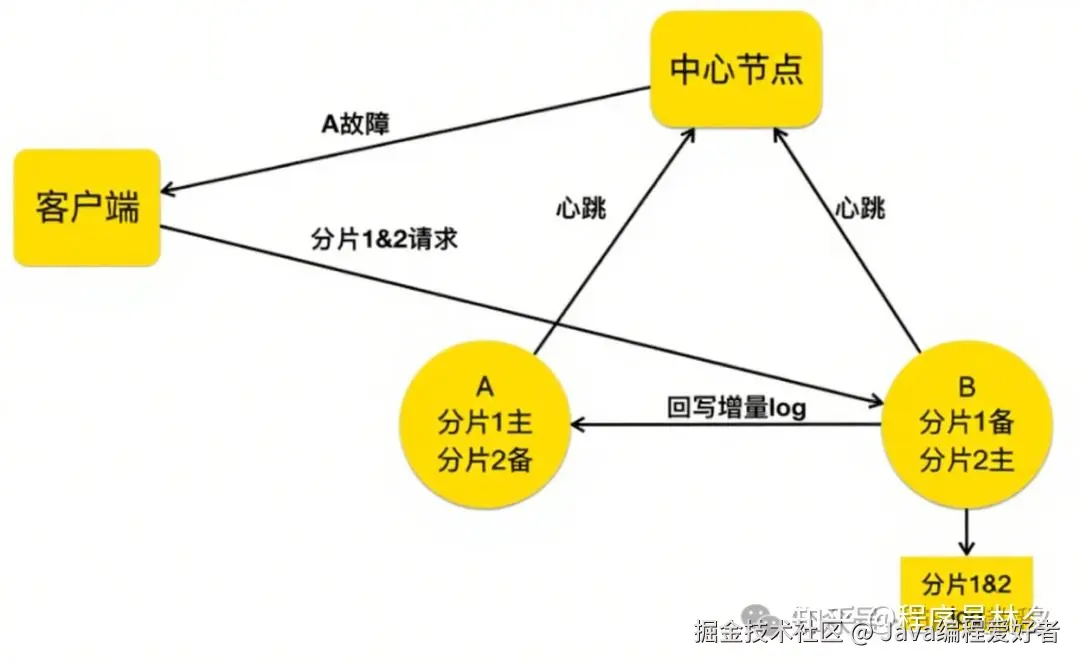
若 A 节点在数分钟内恢复(如因网络抖动导致短暂停机),中心节点会指示 B 节点将暂存的日志回传给 A。待 A 完成数据同步后,中心节点再通知客户端恢复正常的请求路径,将分片 1 的流量重新打回 A 节点。
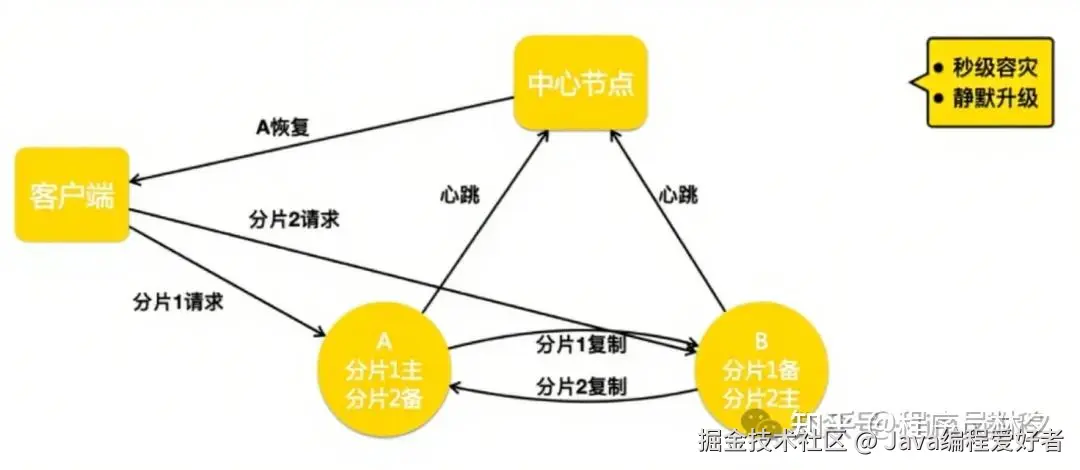
通过这套机制,美团可以做到:
- 秒级摘除故障节点
- 快速恢复时仅需同步增量数据
- 支持主动 Handoff,用于升级等运维操作,实现"静默升级"。
3.2、Cellar 跨地域容灾
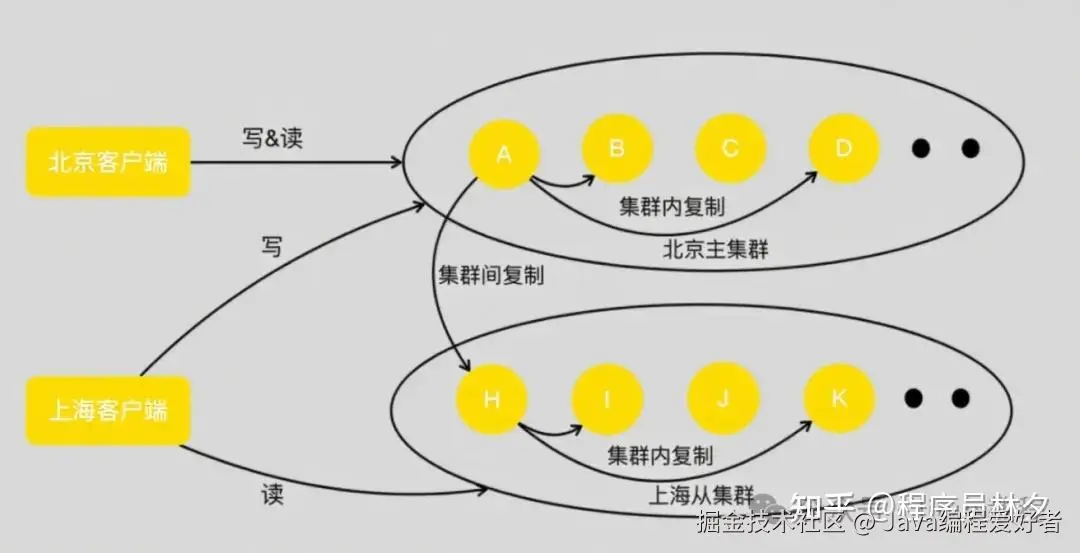
接下来介绍 Cellar 如何实现跨地域容灾。其面临的问题与 Squirrel 类似,但美团也采用了类似的解决方案 ------ 集群间复制机制。
以一个典型的北京主集群、上海从集群为例说明:
当客户端向北京主集群的 A 节点发起写操作时,A 会像普通集群那样,将数据复制到 B 和 D 节点。同时,A 还会将该写操作发送到上海从集群的 H 节点。H 节点接收后,在本地执行写操作,并将其复制到从集群的 I、K 节点。
通过在主从集群之间建立这样的复制链路,美团实现了跨地域的数据同步,同时最大程度降低了跨地域专线的带宽占用。
此外,只需在主从集群间配置双向复制链路,即可轻松实现异地多活架构。
3.3、Cellar 强一致
在完成节点容灾与跨地域容灾之后,美团迎来了更高的业务诉求 ------ 强一致性。
美团原有的复制机制是异步的,在发生故障切换时可能会丢失尚未复制的数据。这对金融支付等不允许数据丢失的业务来说是无法接受的。
为此,美团选择了业界主流的 Raft 协议,作为实现强一致性的基础。选择 Raft 主要基于以下几点考虑:
- 论文描述详尽,工程实现性强;
- 社区已有多个成熟开源实现可供参考;
- 可有效缩短研发周期;
下图展示了当前 Cellar 集群在 Raft 模式下的架构。中心节点负责调度 Raft 组,决定每个 Slot 的三个副本部署在哪些节点上。
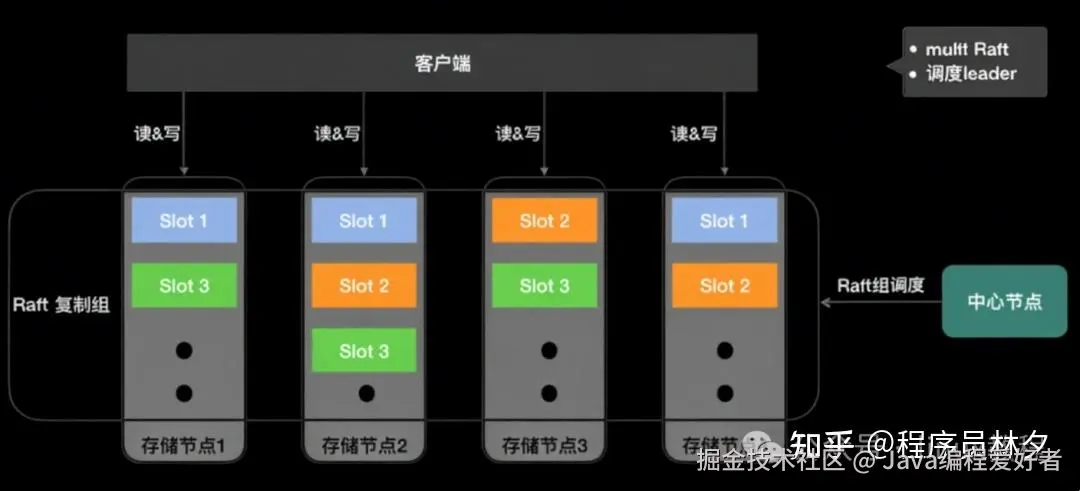
例如:
- Slot 1 分布在节点 1、2、4 上;
- Slot 2 分布在节点 2、3、4 上;
每个 Slot 对应一个独立的 Raft 组,客户端只能在对应的 Raft Leader 上进行读写操作。
由于美团预分配了 16384 个 Slot,在集群规模较小时,单个节点可能承载数百甚至上千个 Slot。若每个 Raft 组单独维护复制线程和日志,会造成严重的性能损耗。
为此,美团实现了 Multi Raft 模式:
虽然 Raft 自身具备选主机制,但在某些场景下可能出现负载不均。例如,经过多次宕机恢复后,Leader 可能集中分布在少数节点上,从而影响整体性能。
为此,美团的中心节点还承担了 Raft 组 Leader 调度职责。例如,当节点 1 恢复后,中心节点可命令节点 2 将 Slot 1 的 Leader 归还给节点 1,确保整个集群中各节点的 Leader 数量均衡。
3.4、Cellar 智能迁移
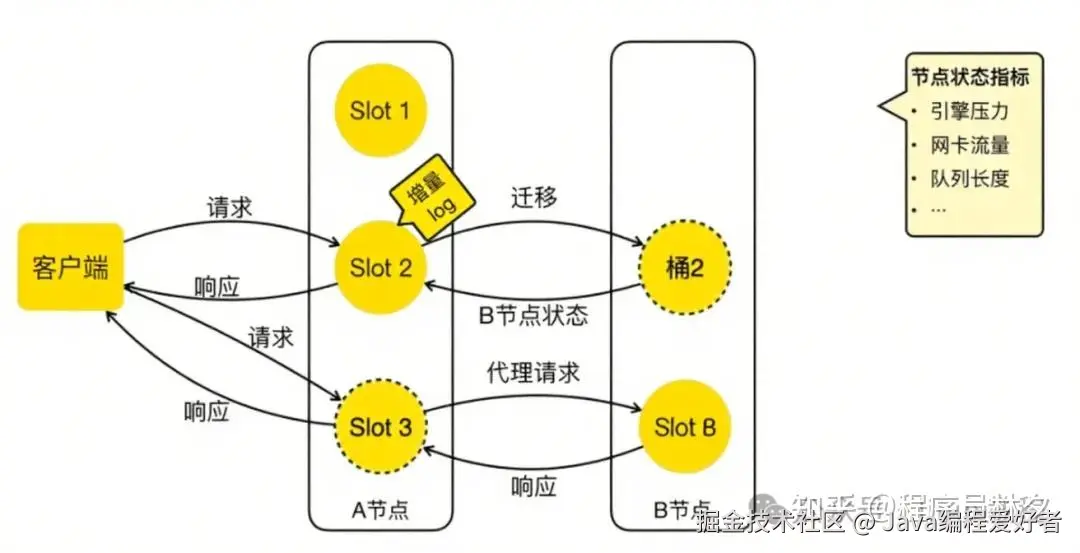
接下来介绍 Cellar 的智能迁移机制。如图所示,美团将桶迁移分为三个状态:
- 正常状态,无迁移;
- 开始迁移,源节点 A 创建快照并发往目标节点 B;
- 迁移完成后,进入代理过渡阶段;
在迁移过程中,A 节点会根据 B 节点反馈的状态(如引擎负载、网卡流量、队列长度等)动态调整迁移速度。迁移过程类似 TCP 慢启动机制,最终达到一种动态平衡 ------ 在最短时间内完成迁移,同时尽可能减少对正常业务的影响。
迁移完成后,客户端可能还未更新路由表。此时若请求到达 A 节点,A 会将请求代理至 B 节点,并返回响应的同时提醒客户端更新路由表。这样既避免了错误响应,也保证了客户端平滑过渡。
3.5、Cellar 快慢队列
下图展示了一个标准的线程队列模型:网络线程池接收请求包,解析后放入工作队列,由工作线程池处理并返回结果。
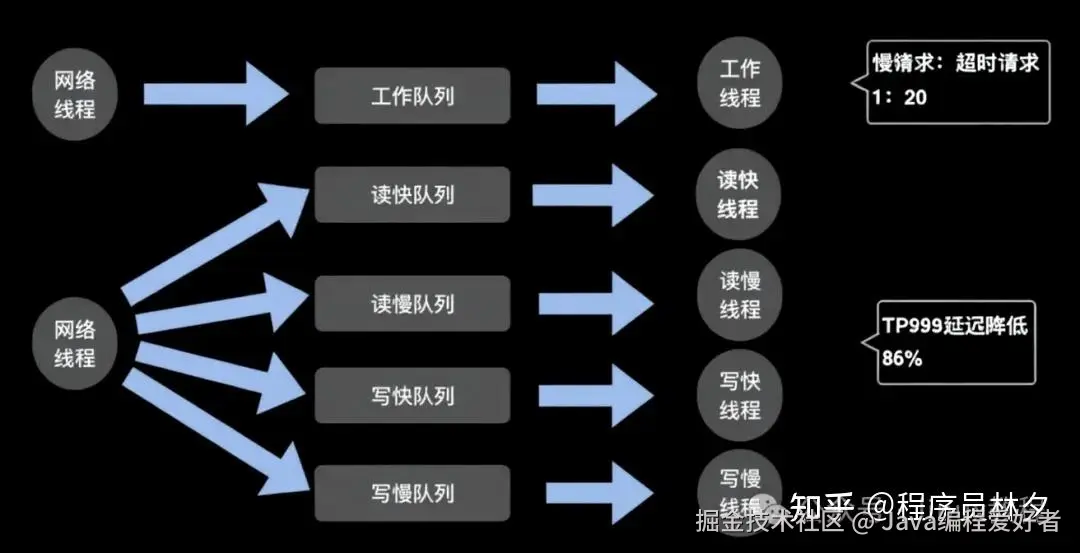
然而,在分析线上超时案例时发现:一批超时请求中,真正因引擎处理慢而导致超时的仅占约 1/20,其余都是因为排队等待时间过长。
为此,美团提出了"拆线程池 + 拆队列"的优化方案:
- 网络线程收到请求后,根据其类型(读/写)和耗时特征(快/慢)分发到四个不同的队列;
- 每类请求由独立的工作线程池处理;
- 请求的分类依据包括 Key 数量、Value 大小、数据结构元素数等;
这种设计实现了不同请求类型的资源隔离。例如,一个慢读请求不会阻塞快写请求的处理。
尽管线程池数量从 1 增加到 4,但美团通过线程池间的互助机制(空闲线程帮助其他队列)控制了总线程数不变,避免了资源浪费。
线上实测表明,该设计可将 TP999 延迟降低 86% ,大幅提升了系统的稳定性和成功率。
3.6、Cellar 热点 Key 解决方案
最后介绍 Cellar 的热点 Key 治理方案。如下图所示,中心节点新增了"热点区域管理"的职责。除了管理正常副本分布外,还需协调热点数据的分布。示例中,节点 C、D 被指定为热点区域。
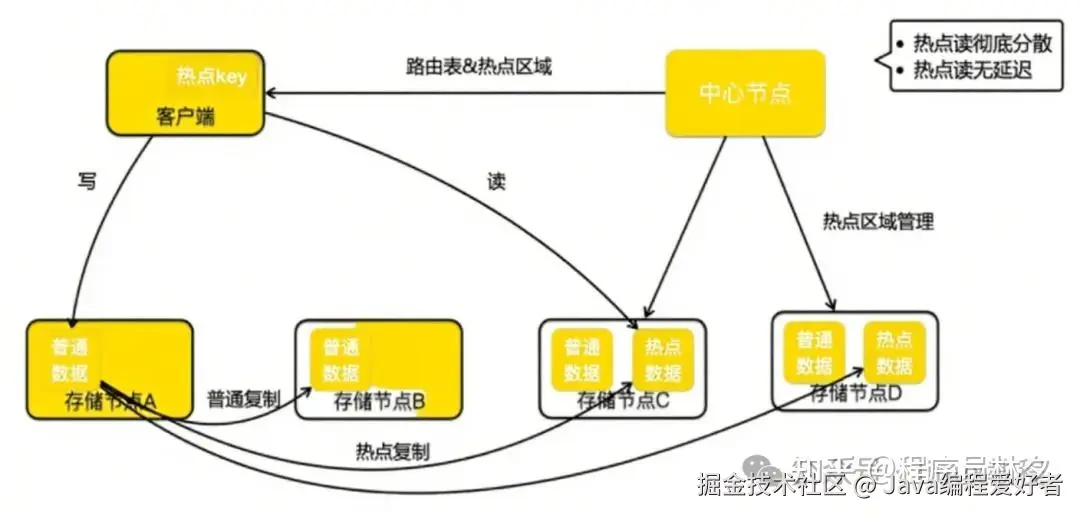
美团通过一次完整的读写流程来说明其运作方式:
当客户端写请求到达 A 节点时,A 在处理完请求后,会根据实时统计判断该 Key 是否为热点。如果是热点,则在进行集群内复制的同时,还将数据复制到热点区域节点(C、D)。响应客户端时,A 会标记该 Key 为热点,客户端缓存该信息。
后续客户端对该 Key 的读请求将直接转发到热点区域,绕过常规副本节点,从而大幅提升热点 Key 的处理能力。
该方案的优势在于:
- 按 Key 级别扩容 ,而非整 Slot 迁移;
- 可动态扩展热点区域节点数量,实现负载均衡;
- 通过实时复制机制,避免了传统客户端缓存热点带来的数据一致性问题;
✅ 结语
从 Squirrel 到 Cellar,我们围绕"高可用、低延迟、强一致"三大核心目标,构建了一套面向不同业务场景的分布式 KV 存储体系。
Squirrel 以高性能和快速容灾见长,适用于缓存类场景;Cellar 则在持久化、跨地域容灾、强一致性等方面进行了深度优化,满足金融级、支付类等对数据可靠性要求极高的业务需求。
在这两个系统的演进过程中,美团不仅解决了诸如节点宕机、网络分区、热点 Key、慢请求阻塞等常见问题,还通过智能迁移、快慢队列隔离、Raft 多副本复制等机制,实现了系统级别的稳定与高效。
这些能力的背后,是一次次线上问题的复盘、一次次架构的重构、一次次性能调优的积累。