Semantic Search At LinkedIn
Authors: Fedor Borisyuk, Sriram Vasudevan, Muchen Wu, Guoyao Li, Benjamin Le, Shaobo Zhang, Qianqi Kay Shen, Yuchin Juan, Kayhan Behdin, Liming Dong, Kaixu Yang, Shusen Jing, Ravi Pothamsetty, Rajat Arora, Sophie Yanying Sheng, Vitaly Abdrashitov, Yang Zhao, Lin Su, Xiaoqing Wang, Chujie Zheng, Sarang Metkar, Rupesh Gupta, Igor Lapchuk, David N. Racca, Madhumitha Mohan, Yanbo Li, Haojun Li, Saloni Gandhi, Xueying Lu, Chetan Bhole, Ali Hooshmand, Xin Yang, Raghavan Muthuregunathan, Jiajun Zhang, Mathew Teoh, Adam Coler, Abhinav Gupta, Xiaojing Ma, Sundara Raman Ramachandran, Morteza Ramezani, Yubo Wang, Lijuan Zhang, Richard Li, Jian Sheng, Chanh Nguyen, Yen-Chi Chen, Chuanrui Zhu, Claire Zhang, Jiahao Xu, Deepti Kulkarni, Qing Lan, Arvind Subramaniam, Ata Fatahibaarzi, Steven Shimizu, Yanning Chen, Zhipeng Wang, Ran He, Zhengze Zhou, Qingquan Song, Yun Dai, Caleb Johnson, Ping Liu, Shaghayegh Gharghabi, Gokulraj Mohanasundaram, Juan Bottaro, Santhosh Sachindran, Qi Guo, Yunxiang Ren, Chengming Jiang, Di Mo, Luke Simon, Jianqiang Shen, Jingwei Wu, Wenjing Zhang
Deep-Dive Summary:
LinkedIn 语义搜索 (Semantic Search At LinkedIn) 论文总结
摘要 (Abstract)
LinkedIn 展示了其基于大语言模型 (LLM) 的语义搜索框架,专门用于"AI 职位搜索"和"AI 人才搜索"。该框架解决了 LLM 推理效率的挑战,通过结合 LLM 相关性评判器、基于嵌入的检索以及经过多导师蒸馏 (Multi-teacher Distillation) 训练的小型语言模型 (SLM),共同优化相关性和用户参与度。通过模型剪枝、上下文压缩和文本-嵌入混合交互等推理架构设计,在固定延迟限制下将排序吞吐量提升了 75 倍以上,同时保持了接近导师模型水平的 NDCG。这是首个在生产环境中实现的、效率可比肩传统方法的 LLM 排序系统,显著提升了搜索质量和用户参与度。
2. 建模与基础设施创新 (Modeling and Infra Innovations)
系统采用两阶段架构:GPU 加速的嵌入检索器生成候选集,随后由 SLM 对前 250 个结果进行重排序。
2.1 SLM 排序 (SLM Ranking)
SLM 作为一个统一模型,同时预测相关性、参与度(如点击、申请)和生态健康指标。
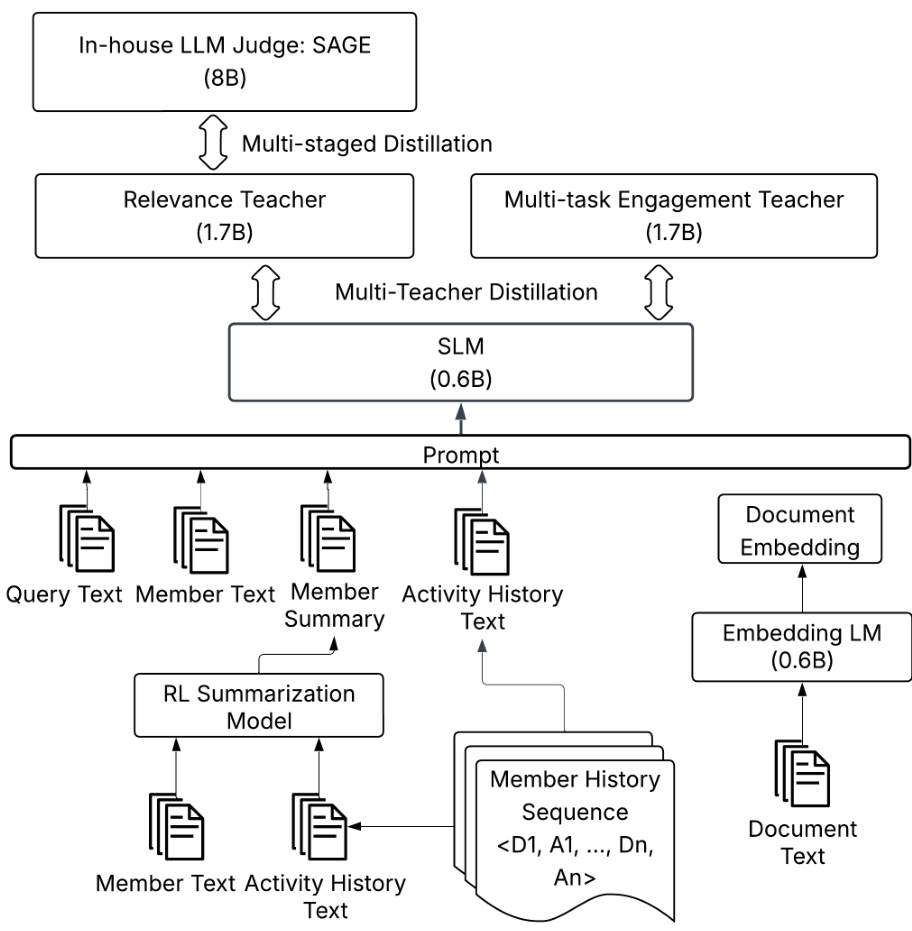
图 1:语义搜索中 SLM 排序的多阶段训练框架概览。
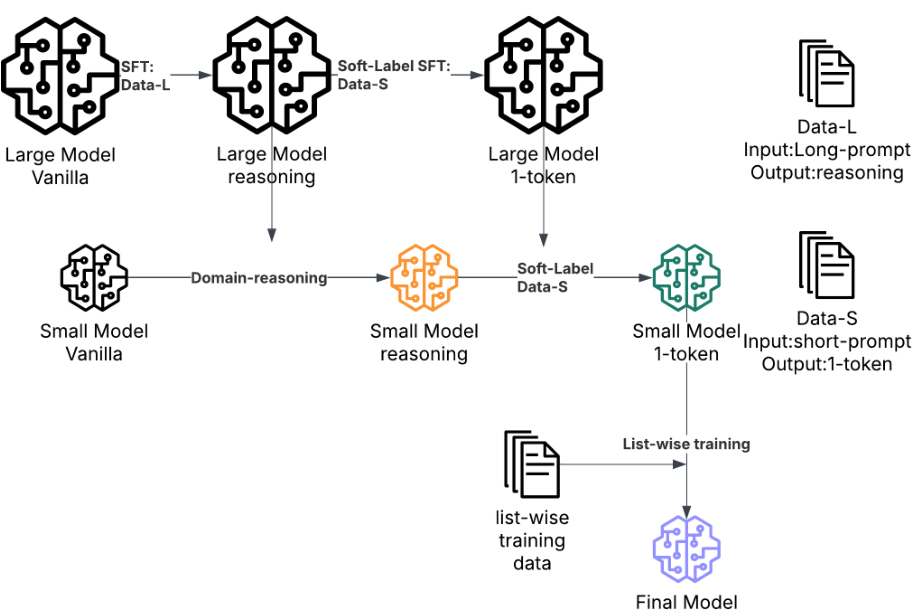
2.1.1 相关性训练 (Relevance Training)
使用一个 8B 的"Oracle"模型作为策略对齐的评判器。
- 技术路线:
- 领域推理蒸馏: 学习 Oracle 的推理逻辑和评分分布。
- 软标签微调 (Soft-label SFT): 将等级映射到 0 , 1 0, 1 0,1 区间,保留决策边界的不确定性。
- 排序损失: 使用 Pairwise 损失函数优化列表顺序。
- 数据缩放: 职位搜索数据量增加了 40 倍,显著提升了 NDCG。
2.1.2 多任务参与度导师 (Multi-task Engagement Teacher)
专门训练一个 1.7B 模型来预测点击、申请、关注等行为。
- 特征工程: 加入会员个人档案文本、历史活动轨迹等特征,使职位点击的 AUROC 提升了 4.4 % 4.4\% 4.4%。
- 超参数优化: 调整学习率和 Batch Size 进一步提升了表现。
2.1.3 参与度与相关性联合优化 (MTD)
多导师蒸馏 (MTD) 解决了小型模型容量有限的问题。
- 预热启动: 先从相关性专用模型开始,再进行多导师蒸馏,相比从零训练,其 NDCG 提升了 0.68 % 0.68\% 0.68%。
- 损失掩码 (Loss Masking): 针对"关注"、"发消息"等稀疏行为,通过掩码技术平衡正负样本,避免稀疏信号被淹没。
2.1.4 校准 (Calibration)
由于排序模型的分数往往是失真的,系统在 SLM 后增加了一个保序回归 (Isotonic-regression) 风格的校准层。
- 位置感知: 学习不同排名位置的映射关系(例如排名第 r r r 位的预测概率 p ^ ( r ) \hat{p}^{(r)} p^(r)),这在职位搜索中将点击 AUROC 从 0.67 提升至 0.71。
2.1.5 基于 SLM 的特征工程
- 档案摘要: 使用 GRPO 算法训练模型对长档案进行摘要。对于搜索者历史记录 ⟨ d 1 , a 1 ⟩ , ... , ⟨ d n , a n ⟩ \langle d_1, a_1 \rangle, \ldots, \langle d_n, a_n \rangle ⟨d1,a1⟩,...,⟨dn,an⟩,模型生成摘要 s s s 以预测未来行为 a n a_n an,其奖励函数定义为:
R ( s ) = I a \^ n = a n ( 1 − λ l e n ⋅ ℓ ( s ) + λ q u a l ⋅ q ( s ) ) R(s) = \mathbb{I}\\hat{a}_n = a_n\left(1 - \lambda_{\mathrm{len}}\cdot \ell (s) + \lambda_{\mathrm{qual}}\cdot q(s)\right) R(s)=Ia\^n=an(1−λlen⋅ℓ(s)+λqual⋅q(s)) - 数值特征: 在 Prompt 中直接包含网络距离、历史点击率 (CTR) 等数值,有助于模型理解非文本信号。
2.2 语义搜索检索 (Semantic Search Retrieval)
检索是语义搜索的第一阶段,旨在为下游排序产生高召回率的候选集。我们的设计基于 LLM 嵌入模型。我们使用对比性 LLM 双编码器(bi-encoder)将查询(query)和文档映射到共享的表示空间,在捕获语义相似性的同时实现高效的最近邻搜索。先前的研究表明,仅解码器(decoder-only)的 LLM 可以通过对比目标和双向注意力转化为强大的嵌入器。
给定查询 q q q 和多达 13 亿个文档的语料库,检索层选择前 K K K 个候选者( K = 1000 K = 1000 K=1000)。我们的系统结合了微调的嵌入模型与 GPU 检索即排序(RAR)距离模型,在对全语料库评分的同时,共同优化相关性和参与度。
2.2.1 数据工程
训练和评估数据源自 LinkedIn 搜索流量,并由 8B LLM "oracle" 进行标注,产生具有分级相关性标签 { 1 , 2 , 3 , 4 } \{1, 2, 3, 4\} {1,2,3,4} 的 ⟨ q , d ⟩ \langle q, d\rangle ⟨q,d⟩ 对。我们通过高置信度过滤和去重来提高数据质量,并采用以查询为中心的硬负采样(hard-negative sampling)。
训练数据通过策略分桶采样(policy-bucketed sampling)和硬负挖掘构建。策略采样将查询分为语义类别,并根据产品需求( P i P_{i} Pi)和离线质量差距( G i G_{i} Gi)调整桶 i i i( B i B_{i} Bi)的大小,公式如下:
G i = P r e c i s i o n @ 10 b a s e l i n e , i P r e c i s i o n @ 10 t r e a t m e n t , i , B i = P i ⋅ G i . ( 2 ) G_{i} = \frac{\mathrm{Precision@10}{\mathrm{baseline},i}}{\mathrm{Precision@10}{\mathrm{treatment},i}}, \qquad B_{i} = P_{i} \cdot G_{i}. \quad (2) Gi=Precision@10treatment,iPrecision@10baseline,i,Bi=Pi⋅Gi.(2)
2.2.2 模型建模
我们的检索模型是采用对比学习训练的基于 LLM 的双编码器。查询 q q q 和文档 d d d 的嵌入表示为 e q e_{q} eq 和 e d e_{d} ed,评分通过余弦相似度 ⟨ e q , e d ⟩ = cos ( e q , e d ) \langle e_{q}, e_{d} \rangle = \cos (e_{q}, e_{d}) ⟨eq,ed⟩=cos(eq,ed) 进行。
训练结合了全局 InfoNCE 目标( L I n f o N C E \mathcal{L}{\mathrm{InfoNCE}} LInfoNCE)和成对边际损失( L p a i r \mathcal{L}{\mathrm{pair}} Lpair):
L I n f o N C E = − log exp ( ⟨ e q , e d ⟩ / τ ) exp ( ⟨ e q , e d ⟩ / τ ) + ∑ d − ∈ B − exp ( ⟨ e q , e d ⟩ / τ ) , ( 3 ) \mathcal{L}{\mathrm{InfoNCE}} = -\log \frac{\exp\left(\langle e_q,e_d\rangle / \tau\right)}{\exp\left(\langle e_q,e_d\rangle / \tau\right) + \sum{d^{-}\in \mathcal{B}^{-}}\exp\left(\langle e_q,e_d\rangle / \tau\right)}, \quad (3) LInfoNCE=−logexp(⟨eq,ed⟩/τ)+∑d−∈B−exp(⟨eq,ed⟩/τ)exp(⟨eq,ed⟩/τ),(3)
其中 τ > 0 \tau > 0 τ>0 是温度超参数, B − \mathcal{B}^{-} B− 包含批次内负样本和显式挖掘的硬负样本。
L p a i r = ∑ d − ∈ D − max ( 0 , m − ⟨ e q , e d ⟩ + ⟨ e q , e d ⟩ ) , ( 4 ) \mathcal{L}{\mathrm{pair}} = \sum{d^{-}\in \mathcal{D}^{-}}\max \left(0,m - \langle e_q,e_d\rangle + \langle e_q,e_d \rangle \right), \quad (4) Lpair=d−∈D−∑max(0,m−⟨eq,ed⟩+⟨eq,ed⟩),(4)
其中 m > 0 m > 0 m>0 是边际(margin)。最终目标函数为 λ L I n f o N C E + ( 1 − λ ) L p a i r \lambda \mathcal{L}{\mathrm{InfoNCE}} + (1 - \lambda) \mathcal{L}{\mathrm{pair}} λLInfoNCE+(1−λ)Lpair。
2.2.3 GPU RAR 模型训练
为了反映个性化和参与度偏好,我们使用 GPU 检索即排序(GPU RAR)评分代替纯余弦相似度:
S ( q , d ) = w 0 ⟨ e q , e d ⟩ + ∑ i = 1 n w i f i ( q , d ) , ( 5 ) S(q,d) = w_0\langle e_q,e_d\rangle + \sum_{i = 1}^{n}w_if_i(q,d), \quad (5) S(q,d)=w0⟨eq,ed⟩+i=1∑nwifi(q,d),(5)
其中 f i f_{i} fi 是个性化和参与度特征。GPU RAR 采用加权多任务目标进行训练:
L R A R = λ L B C E ( S , L R ) + ( 1 − λ ) L B C E ( S , L E ) , ( 6 ) \mathcal{L}{\mathrm{RAR}} = \lambda \mathcal{L}{\mathrm{BCE}}(S,L_R) + (1 - \lambda)\mathcal{L}_{\mathrm{BCE}}(S,L_E), \quad (6) LRAR=λLBCE(S,LR)+(1−λ)LBCE(S,LE),(6)
其中 L R L_{R} LR 和 L E L_{E} LE 分别代表相关性和参与度标签。
表 8:职位搜索的检索模型指标(P@50, R@50, NDCG@50)
| 模型变体 | P@50 | R@50 | NDCG@50 |
|---|---|---|---|
| Baseline-8B | 0.414 | 0.774 | 0.735 |
| + Chat template | 0.446 | 0.830 | 0.788 |
| + InfoNCE (LoRA) | 0.471 | 0.874 | 0.829 |
| + InfoNCE + HardNeg (LoRA) | 0.497 | 0.887 | 0.833 |
| + InfoNCE + HardNeg (FPFT) | 0.505 | 0.899 | 0.842 |
| 4B + InfoNCE + HardNeg (FPFT) | 0.501 | 0.889 | 0.834 |
表 9:人员搜索的检索模型指标(P@10, R@10, NDCG@10)
| 模型变体 | P@10 | R@10 | NDCG@10 |
|---|---|---|---|
| Baseline-4B | 0.33 | 0.70 | 0.71 |
| + Chat template | 0.36 | 0.74 | 0.74 |
| + HardNeg Mining | 0.41 | 0.75 | 0.76 |
| + Quality based upsampling Eq(2) | 0.46 | 0.78 | 0.78 |
| + GPU RAR model | 0.47 | 0.79 | 0.79 |
2.2.4 GPU 检索服务
我们将优化后的查询和文档嵌入塔部署在 GPU 加速的穷举检索栈上。通过减小嵌入维度、支持多模型部署、实施 vRAM 保护措施等手段,确保了高吞吐量和鲁棒性。
2.2.5 实验结果
如表 8 所示,InfoNCE 微调显著提高了职位搜索的召回率和排序质量,全参数微调(FPFT)效果最佳。在人员搜索中(表 9),使用对话模板、硬负挖掘和基于质量的上采样显著提升了所有指标。GPU RAR 进一步平衡了相关性和参与度,Click AUC 提升了 + 1.7 % +1.7\% +1.7%。
表 10:在固定 500ms 延迟预算下的效率比较(单张 H100)
| 模型 | NDCG@10 | QPS (items/s/GPU) | 延迟 (ms) |
|---|---|---|---|
| Full Text | 0.9432 | 290 | < 500 |
| Summarized + Pruned | 0.9218 | 2,200 | < 500 |
| MixLM 18 | 0.9239 | 22,000 | < 500 |
2.3 SLM 推理优化的建模 (Modeling for SLM Inference Optimizations)
大规模服务交叉编码器(cross-encoder)SLM 排序器极具挑战性。我们应用了以下优化(见表 10):
2.3.1 上下文摘要 (Context Summarization)
推理成本随输入长度线性增长。我们通过 1.7B LLM 进行离线摘要,压缩长文本字段(如职位描述、个人档案)。这在职位搜索中带来了 4 倍的吞吐量提升,在人员搜索中将 P95 Prompt 长度从约 1500 token 减少到约 500 token。
2.3.2 模型剪枝 (Model Pruning)
我们使用 OSSCAR 进行结构化压缩,剪掉每个 MLP 块中 50% 的隐藏神经元,并移除最后 8 层 Transformer 层。模型参数从 600M 减少到 375M。如表 11 所示,剪枝后的模型质量与基准相当,但吞吐量大幅提升。
表 11:人员搜索中密集与剪枝 SLM 的排序质量
| 模型 | Precision@10 | Recall@10 | NDCG@10 |
|---|---|---|---|
| Baseline (600M) | 0.5369 | 0.8597 | 0.8629 |
| Pruned (375M) | 0.5434 | 0.8578 | 0.8652 |
2.3.3 文本-嵌入混合交互 (MixLM)
MixLM 架构通过专用编码器将每个项目压缩为一小组学习到的嵌入 token。推理时,排序器消耗查询文本及这些嵌入 token。MixLM 的吞吐量比原始文本 SLM 高出约 76 倍。
2.4 训练基础设施优化 (Training Infrastructure Optimizations)
我们采用 LiGer(减少内存,使 batch size 扩大 2 倍)、多节点训练(加速 3.5 倍)、FSDP2 以及 H200 集群。
2.4.1 多教师蒸馏框架
我们开发了基于 SGLang 的在线/离线多教师蒸馏框架。在线模式实现 3 倍加速;离线模式预计算教师输出并缓存,使训练时间减少约 35%,节省 25% 的 GPU 小时数。
2.4.2 代理式 GPU 优化 (Agentic GPU Optimizations)
开发了一个 GPU 优化代理(Agent),分析训练代码和利用率指标,通过 LLM 引导配置调整(如梯度检查点、FSDP 设置)。在 MixLM 训练中,这节省了 256 个 GPU 小时。
2.5 ML 推理基础设施优化 (ML Inference Infrastructure Optimizations)
LLM 排序器的推理主要受 Prefill 计算、分词和 CPU 编排主导。我们的推理栈优化总结见表 12:
2.5.1 针对评分优化的 Prefill 执行
我们引入了专门的 Prefill 路径,仅执行单次前向传递,跳过解码和采样,立即释放 KV 状态。在 375M 剪枝排序器上,这使吞吐量提升了 44%。
表 12:单张 H100 GPU 上推理优化带来的吞吐量增益 (p99 ≤ \leq ≤ 500ms)
| 优化阶段 | 增益 (items/s/GPU) | 总吞吐量 (items/s/GPU) |
|---|---|---|
| Baseline | - | 750 |
| + Batch tokenization & batch send | +150 | 900 |
| + Scoring-only prefill execution | +400 | 1300 |
| + Python/runtime optimizations | +300 | 1600 |
| + In-batch prefix caching (IBPC) | +400 | 2000 |
| + Piecewise CUDA graph (prefill) | +200 | 2200 |
2.5.2 共享前缀摊销 (Shared-Prefix Amortization)
排序 prompt 共享长查询前缀。我们采用批次内前缀缓存(IBPC),确保前缀 KV 只计算一次。
F l i m n a i v e ∝ N i ( T q + T i ) 2 → F l i m a m o r t ∝ T q 2 + N i ( 2 T i T q + T i 2 ) F_{\mathrm{lim}}^{\mathrm{naive}} \propto N_{i}(T_{q} + T_{i})^{2} \rightarrow F_{\mathrm{lim}}^{\mathrm{amort}} \propto T_{q}^{2} + N_{i}(2T_{i}T_{q} + T_{i}^{2}) Flimnaive∝Ni(Tq+Ti)2→Flimamort∝Tq2+Ni(2TiTq+Ti2)
结合分段 CUDA 图(Piecewise CUDA graph)执行,最终实现了相比基准 2.93 倍的加速。
2.5.3 CPU 与运行时优化
通过多进程 gRPC 设计并行化 CPU 预处理,避开 Python GIL 限制,并通过 gc.freeze() 稳定尾部延迟。
2.5.4 混合输入推理与基于嵌入的评分
支持 MixLM 的文本-嵌入混合输入。如表 13 所示,多进程服务配合 CUDA 图可使吞吐量扩展至约 22,000 items/s/GPU。
表 13:0.6B 参数排序器在 H100 上的基础设施优化消融实验
| 基础设施配置 | 吞吐量 (items/s/GPU) |
|---|---|
| Single gRPC servicer + single SGLang worker | ~10,000 |
| Multi-process serving (6 gRPC + 6 SGLang) | ~19,500 |
| Multi-process serving + CUDA graph | ~22,000 |
2.5.5 中间层服务优化
使用 Couchbase 缓存已评分的项目 ID,超过 50% 的请求通过缓存服务。此外,采用基于 PID 的动态评分深度控制器,在高峰期调整评分深度,并利用流量整形(Traffic Shaping)提高 GPU 调度效率。
3 在线部署与未来工作 (Online Deployment and Future Work)
该系统在 LinkedIn 规模上实现了 LLM 检索和排序。在职位搜索中,NDCG@10 提升了 + 7.73 % +7.73\% +7.73%,差匹配率(PMR@10)降低了 − 46.88 % -46.88\% −46.88%。人员搜索的 NDCG@10 提升超过 10%。上线后,日活跃用户(DAU)提升超过 + 1.2 % +1.2\% +1.2%。未来将专注于更深层次的个性化和进一步降低成本。
4 附录 (APPENDIX)
4.1 多任务优化的损失掩码 (Loss Masking)
在人员搜索中,关注和发消息等操作比点击稀疏得多。为了解决数据不平衡,我们应用了掩码训练目标(见图 3)。
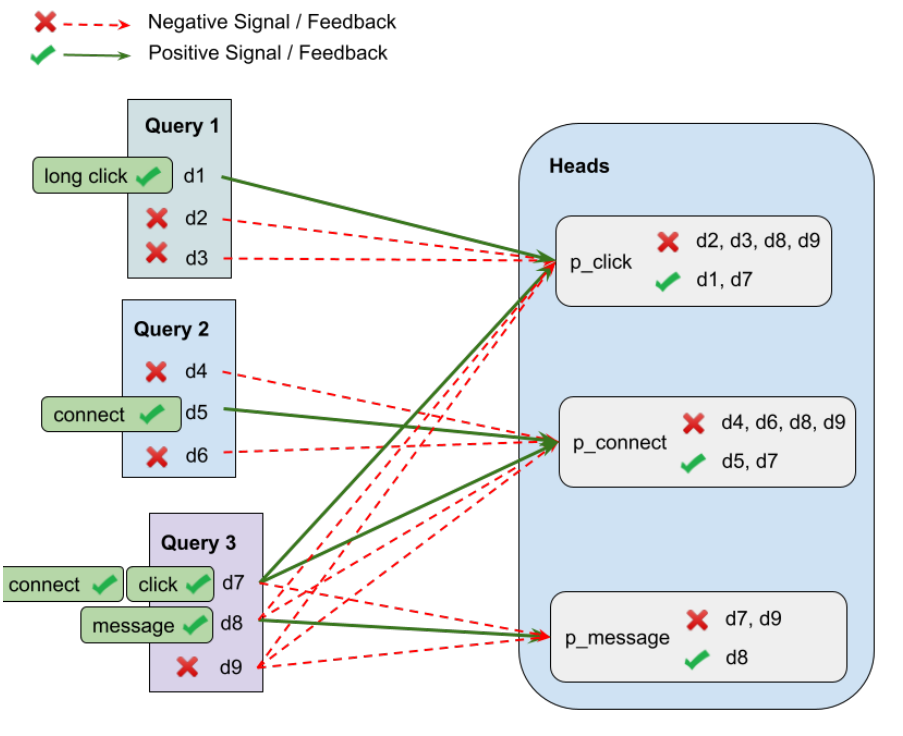
图 3:负样本选择。仅当同一查询的另一个文档发生该操作时,才将文档视为该操作的负样本。
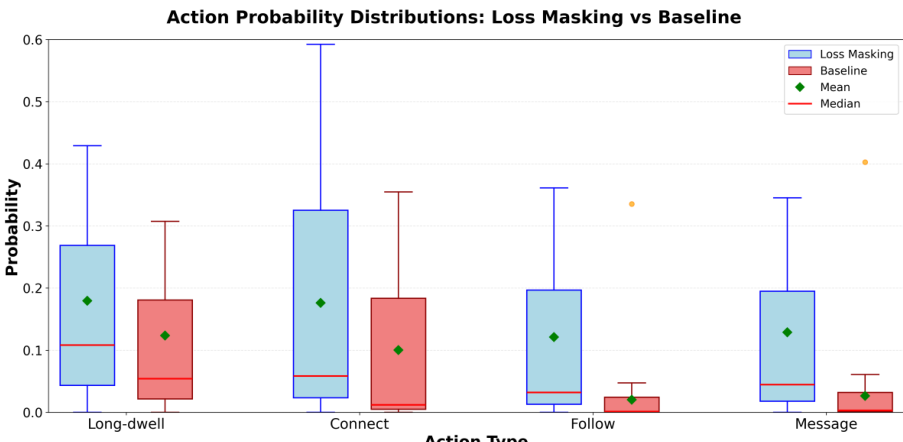
图 4:使用损失掩码与不使用掩码训练时,多任务参与度模型预测概率得分的分布。
4.2 语义搜索系统架构
生产系统(图 5)强调端到端效率。包括评分缓存、深度控制、流量整形以及 MixLM 等压缩技术,共同提升了 GPU 吞吐量。
Original Abstract: Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
PDF Link: 2602.07309v1
部分平台可能图片显示异常,请以我的博客内容为准
