一、海量数据存储与异构数据同步核心原理
1.1 数据分片的痛点与解决方案
- 分片痛点:以用户 ID 为分片键的订单表,无法高效支持商家按店铺 ID 查询(全分片扫描性能极低)。
- 通用解决方案 :空间换时间 ,根据业务查询需求构建多份数据存储:
- 订单数据:一份按用户 ID 分片供用户查询,一份按店铺 ID 分片供商家查询;
- 商品数据:MySQL 存储业务数据,ElasticSearch 存储供关键字搜索的索引数据(tulingmall-canal 中由
ProductESData负责同步)。
- 核心设计原则 :大规模系统中,从业务查询需求反向设计数据存储方案(数据库选型、数据结构、分片规则),而非先存储后查询。
1.2 异构数据实时同步的核心方案
- 分布式事务的局限性:无法解决大规模、多存储的实时数据同步问题。
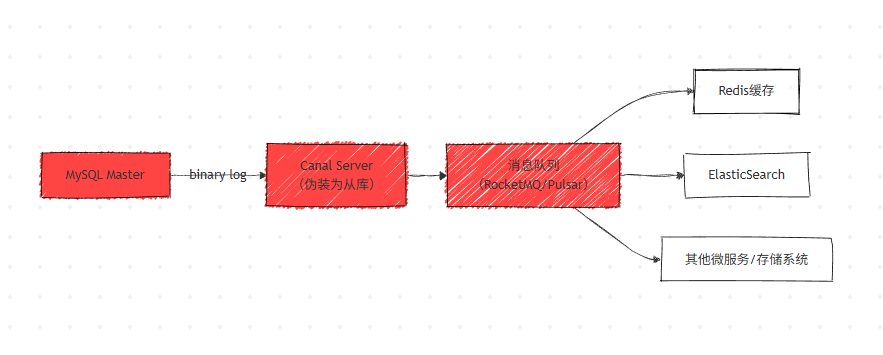
- 主流实现方案 :基于MySQL Binlog + Canal + 消息队列实现,核心是将 Canal 伪装为 MySQL 从库,实时解析 Binlog 并分发数据。
- 架构设计 :引入消息队列(RocketMQ/Pulsar)解耦上下游,解决两个核心问题:
- 避免 Canal 直接写入下游多数据库导致的写入性能瓶颈;
- 为下游数据库提供数据转换、过滤的处理时间。
异构数据同步架构图
二、不停机更换数据库
2.1 数据库更换的常见场景
- MySQL 单实例→分库分表集群;
- 自建数据库→云数据库(系统上云);
- MySQL→分析型数据库(如 HBase,解决 OLAP 性能不足问题)。
2.2 核心设计原则
迁移过程可逆:每一步操作后若出现故障,能快速回滚到上一稳定状态(唯一不可逆步骤为最终停旧库单写新库),避免业务长时间不可用或数据丢失。
2.3 完整迁移流程(以订单库为例)
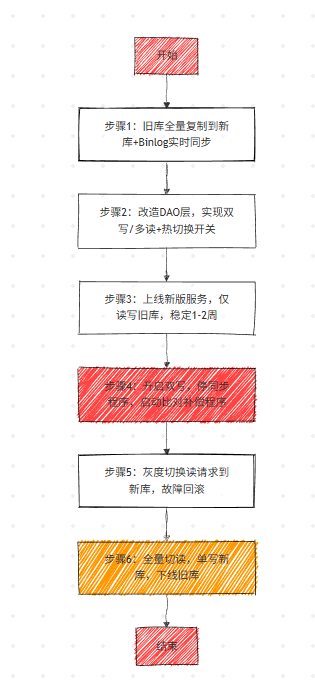
步骤 1:全量复制 + 实时同步新旧库
- 操作:将旧库全量数据复制到新库,基于 Binlog 开发实时同步程序,保证新旧库数据实时一致;
- 特性:对原有业务无侵入,同步程序故障可直接停掉,无需回滚。
步骤 2:改造订单服务 DAO 层(双写 + 热切换 + 多读模式)
- 写操作 :支持「只写旧库」「只写新库」「同步双写」三种状态,通过热切换开关控制(无代码重启);
- 读操作:支持「读旧库」「读新库」切换,同样通过热切换开关控制;
- 业务层:无需修改,仅修改数据访问层,符合 "开闭原则"。
步骤 3:上线新版服务,仅读写旧库
- 操作:新版服务部署后,保持「只读写旧库」模式运行1-2 周;
- 验证:服务稳定性 + 新旧库数据一致性,故障则直接回滚到旧版本服务。
步骤 4:开启双写,停同步程序(核心注意点)
- 双写规则:先写旧库,后写新库,以旧库结果为准(Java 代码中需保证执行顺序);
- 异常处理:
- 旧库成功、新库失败:返回业务成功,记录异常日志(后续补偿);
- 旧库失败:直接返回业务失败,不写新库(避免新库影响核心业务);
- 数据一致性:上线比对和补偿程序,解决 "同步程序停止 + 双写开启" 的衔接不一致问题。
步骤 5:灰度切换读请求到新库
- 操作:以灰度发布方式逐步将读请求切到新库,故障则立即切回旧库;
- 验证:新库的读性能、数据准确性。
步骤 6:全量切读 + 单写新库,下线旧库
- 全量读请求切到新库后,稳定运行一段时间,停比对程序;
- 将写状态改为「只写新库」,旧库正式下线(唯一不可逆步骤);
- 可选优化:若需可逆,可增加「双写以新库为准」过渡状态,比对程序改为 "新库补偿旧库"(成本较高,一般不采用)。
不停机数据库迁移全流程图
2.4 数据表结构变更的迁移思路
- 新增表:直接回滚旧版本程序即可,无复杂操作;
- 字段变更:采用双写新旧表 + 热切换开关,思路与数据库迁移一致,先双写保证数据一致,再逐步切到新表。
三、比对和补偿程序实现
3.1 核心难点
比对实时变化的两个数据库 数据,无通用的 "复制状态机" 类方案,需根据业务数据特性定制实现。
3.2 按业务数据分类的实现方案
方案 1:时效性强的静态数据(如订单)
- 特性:订单完成后几乎无变更,数据具有 "终态";
- 比对逻辑:按订单完成时间划分窗口,仅比对窗口内完成的订单;
- 补偿逻辑:发现不一致,直接用旧库数据覆盖新库(以旧库为基准)。
方案 2:动态变化的数据(如商品信息)
前提 :数据带更新时间戳 (Java 实体类中需设计updateTime字段,面试常问字段设计)
- 比对逻辑:按更新时间划分窗口,读取旧库窗口内数据,按主键匹配新库数据;
- 时间窗口优化:结束时间比当前时间早 1 分钟,避免比对正在写入的脏数据;
- 异常处理:若新库数据更新时间晚于旧库,说明比对期间数据变更,暂不补偿,放到下一个窗口重新比对。
方案 3:无时间戳的通用数据
- 核心思路:解析旧库 Binlog获取数据变更记录,按主键到新库比对,不一致则基于 Binlog 记录补偿。
3.3 核心目标
将新旧库的数据差异逐步收敛到一致,保证双写期间数据无永久性不一致。
四、基于 Binlog 的 MySQL 数据备份与恢复
4.1 数据安全的两大核心需求
- 高可靠性:避免数据丢失导致的直接财产损失(如订单丢失);
- 高可用性:避免存储系统故障导致的业务停服损失(如电商停服)。
4.2 传统全量备份的痛点
- 备份命令:
mysqldump -uroot -p test > test.sql(MySQL 原生命令); - 核心问题:
- 备份文件大,占用大量磁盘空间;
- 备份过程占用 CPU/IO 资源,易锁表,导致数据库性能下降;
- 无法频繁备份,数据丢失后只能恢复到最近一次全量备份时间点,存在数据丢失风险。
4.3 全量备份 + Binlog 增量备份的最优方案
4.3.1 Binlog 增量备份原理
- Binlog 是 MySQL 的数据变更操作日志,开启后会记录所有数据更新操作(增删改);
- 核心特性:可回放,按顺序执行 Binlog 中的操作,可将数据恢复到任意时间点;
- Java 开发关联:Canal 的核心就是解析 Binlog 日志,面试常问 Canal 与 Binlog 的关系。
4.3.2 备份恢复流程
- 定期执行全量备份(如每日一次);
- 实时保存Binlog 日志(按时间切割,避免单文件过大);
- 数据恢复:先恢复全量备份,再回放全量备份时间点后的 Binlog,恢复到指定时间点。
4.3.3 备份恢复的核心注意点
- 异地存储 :全量备份文件和 Binlog 日志不能与数据库同服务器 / 同机房,最好跨城市存储,避免机房级故障;
- Binlog 格式 :设置为ROW 格式 ,保证回放的幂等性(避免重复执行导致数据异常);
- 时间偏移 :回放 Binlog 的起始时间比全量备份时间稍提前,保证全量备份后的所有操作都被回放,无数据遗漏。