兄弟们,高可用这东西,不出事时岁月静好,一出事就是P1级故障。还记得那次吗?某核心交易系统,MySQL主库的存储IOPS突然飙到100%,整个实例hang死,别说交易了,连登录都登不上去。按理说,咱们的MySQL主从复制是配了的,备库数据也跟得紧紧的。但最要命的是,业务访问的那个VIP(虚拟IP),像被502胶水焊死了一样,还死死地钉在故障机上,导致业务全断。
项目经理的电话比闹钟还准时,三点准时响起,那语气,恨不得从电话线里爬过来掐我脖子。
查了半天,根源找到了:只做了数据层的高可用(主从复制),却忽略了服务层的高可用(VIP自动漂移) 。高可用是个"木桶",最短的那块板决定你的睡眠质量。你的数据同步得再快,应用访问不到也是白搭。
今天这篇,就是要把这块最短的板补上。我带你用Keepalived这个"神器",从零开始搭建一个真正能自动切换、让你睡得安稳的MySQL高可用架构。
1 Keepalived是个啥?
别被那些复杂的文档吓到,这玩意的原理其实很简单。
通俗解释: 你可以把Keepalived比作两个时刻准备"抢公章"(也就是我们的VIP)的办公室主任(两台MySQL服务器)。谁的"声望"(priority 优先级)高,默认就由谁拿着公章对外提供服务。这个拿着公章的主任,为了证明自己还活着,会定期在办公室里"吼一嗓子"(发送VRRP心跳通告),告诉另一位主任:"我还行,公章还在我这!" 如果大家在规定时间内没听到他吼,那么另一位主任就会立刻站出来,把公章抢过来,继续对外服务。
核心概念:
-
VRRP协议 (Virtual Router Redundancy Protocol): 虚拟路由冗余协议,这就是Keepalived实现高可用的技术基础,刚才说的"吼一嗓子"就是通过这个协议来的。
-
VIP (虚拟IP): 对外统一的服务入口,高可用的灵魂。应用程序连接的是这个永不改变的IP,它底下是哪台机器在干活,应用层完全无感。
-
MASTER/BACKUP 角色: 一个VRRP实例中,同一时间只有一台是MASTER(主),负责持有VIP。其他都是BACKUP(备),时刻准备接管。这个角色是根据
priority值动态选举出来的。
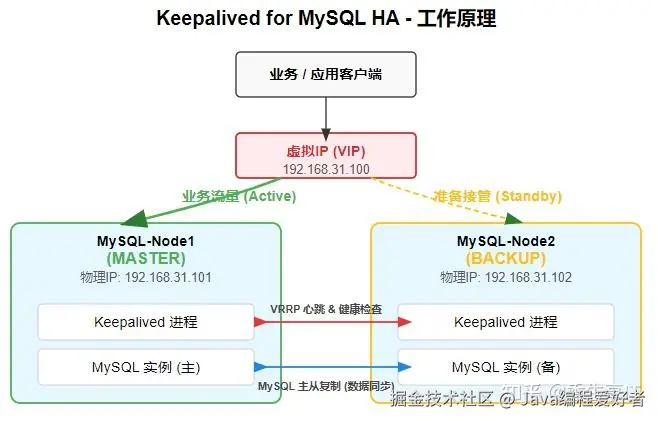
这张图把关系说透了:客户端只认VIP。VIP平时在MASTER身上。MASTER和BACKUP之间通过VRRP心跳互相知晓对方的存活状态。一旦MASTER挂了,心跳中断,BACKUP就会把VIP"抢"过来。
2 环境准备与安装
光说不练假把式,开整!
环境规划:
- 服务器A (主节点):
mysql-node1,物理IP192.168.31.101 - 服务器B (备节点):
mysql-node2,物理IP192.168.31.102 - 虚拟IP (VIP):
192.168.31.1010 - 操作系统: Red Hat 8.2
- Keepalived版本: 2.0.10 (RHEL 8 自带)
安装步骤 (RHEL 8): 这个简单,两台机器上都执行就行了,属于"抄作业"环节。
yaml
# dnf -y install keepalived
# 执行结果如下
Local Repository 2.7 MB/s | 2.8 kB 00:00
Local Repository 3.1 MB/s | 3.2 kB 00:00
Dependencies resolved.
======================================================================================================================================
Package Architecture Version Repository Size
======================================================================================================================================
Installing:
keepalived x86_64 2.0.10-10.el8 local-AppStream 466 k
Installing dependencies:
lm_sensors-libs x86_64 3.4.0-21.20180522git70f7e08.el8 local 59 k
mariadb-connector-c x86_64 3.0.7-1.el8 local-AppStream 148 k
net-snmp-agent-libs x86_64 1:5.8-14.el8 local-AppStream 747 k
net-snmp-libs x86_64 1:5.8-14.el8 local 821 k
Transaction Summary
======================================================================================================================================
Install 5 Packages
Total size: 2.2 M
Installed size: 7.2 M
Downloading Packages:
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Running scriptlet: mariadb-connector-c-3.0.7-1.el8.x86_64 1/1
Preparing : 1/1
Installing : net-snmp-libs-1:5.8-14.el8.x86_64 1/5
Installing : mariadb-connector-c-3.0.7-1.el8.x86_64 2/5
Installing : lm_sensors-libs-3.4.0-21.20180522git70f7e08.el8.x86_64 3/5
Running scriptlet: lm_sensors-libs-3.4.0-21.20180522git70f7e08.el8.x86_64 3/5
Installing : net-snmp-agent-libs-1:5.8-14.el8.x86_64 4/5
Installing : keepalived-2.0.10-10.el8.x86_64 5/5
Running scriptlet: keepalived-2.0.10-10.el8.x86_64 5/5
Verifying : lm_sensors-libs-3.4.0-21.20180522git70f7e08.el8.x86_64 1/5
Verifying : net-snmp-libs-1:5.8-14.el8.x86_64 2/5
Verifying : keepalived-2.0.10-10.el8.x86_64 3/5
Verifying : mariadb-connector-c-3.0.7-1.el8.x86_64 4/5
Verifying : net-snmp-agent-libs-1:5.8-14.el8.x86_64 5/5
Installed products updated.
Installed:
keepalived-2.0.10-10.el8.x86_64 lm_sensors-libs-3.4.0-21.20180522git70f7e08.el8.x86_64
mariadb-connector-c-3.0.7-1.el8.x86_64 net-snmp-agent-libs-1:5.8-14.el8.x86_64
net-snmp-libs-1:5.8-14.el8.x86_64
Complete!
## 确认版本
[root@node101 ~]# keepalived --version
防火墙配置:
⚠️ 生产大坑: 兄弟们注意了,这是我踩过最大的坑!必须放行VRRP协议!Keepalived主备节点之间靠VRRP协议通信,你把防火墙挡住了,它俩就成了"聋子和瞎子",互相都以为对方挂了,结果就是两边都抢着声明自己是MASTER,都去绑定VIP。这就是传说中的"脑裂"!业务流量一会打到A,一会打到B,数据不一致,等着背锅吧。
如果服务器上防火墙是开着的,得在两台机器上都执行:
arduino
# firewall-cmd --add-rich-rule='rule protocol value="vrrp" accept' --permanent
# firewall-cmd --reload内核参数调整: Keepalived需要把一个不属于本机网卡的IP(也就是VIP)绑定上来,默认Linux内核是不允许的。所以需要调整一个内核参数。
ini
# echo "net.ipv4.ip_nonlocal_bind = 1" >> /etc/sysctl.conf
# sysctl -p
## 结果如下
[root@node101 ~]# sysctl -p
net.ipv4.ip_nonlocal_bind = 1这个操作也是两台机器都要做。
3 高可用方案对决:自动 vs 手动
讲到这里,就到了十字路口。Keepalived给我们提供了能力,但怎么用这个能力,是门大学问。下面我给你端上两盘菜,一盘是"入门级自动切换",另一盘是"生产级手动切换",咱们把优缺点掰扯清楚了,你再决定在你的环境里用哪一盘。
方案一:入门级自动切换 (Keepalived + Notify脚本)
这个方案追求的是"无人值守",一旦MySQL出问题,系统自动完成VIP和数据库角色的切换。
A. 核心思路
咱们利用Keepalived的notify_*系列指令。当Keepalived的状态从BACKUP变成MASTER时,就自动触发一个我们写好的mysql_role_switch.sh脚本,让这个脚本去完成数据库的read_only状态切换。
B. 配置文件 (主备有别)
vi /etc/keepalived/keepalived.conf
主节点 mysql-node1 (192.168.31.101):
csharp
! Configuration File for keepalived (Auto-Switch MASTER)
global_defs {
# 路由ID,在一个局域网内,这个ID必须是唯一的,相当于Keepalived的身份证
router_id MYSQL_HA_01
}
vrrp_script chk_mysql {
script "/etc/keepalived/check_mysql.sh" # 脚本路径
interval 2 # 每2秒执行一次
weight -20 # 如果脚本失败(退出码非0),则当前节点的优先级降低20
fall 2 # 连续2次失败,才认为是真的失败
rise 3 # 连续3次成功,才认为是真的恢复
}
vrrp_instance VI_MYSQL {
state MASTER
interface ens18
virtual_router_id 51
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.31.100/24 dev ens18 label ens18:vip
}
track_script {
chk_mysql
}
# 状态变更时触发总司令脚本
notify_master "/etc/keepalived/mysql_role_switch.sh MASTER"
notify_backup "/etc/keepalived/mysql_role_switch.sh BACKUP"
notify_fault "/etc/keepalived/mysql_role_switch.sh BACKUP"
}备节点 mysql-node2 (192.168.31.102):
csharp
! Configuration File for keepalived (Auto-Switch BACKUP)
global_defs {
router_id MYSQL_HA_02
}
vrrp_script chk_mysql {
# ... 配置与主节点完全一样 ...
}
vrrp_instance VI_MYSQL {
state BACKUP
interface ens18
virtual_router_id 51
priority 100
advert_int 1
nopreempt # 关键!防止主库恢复后VIP来回抖动
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.31.100/24 dev ens18 label ens18:vip
}
track_script {
chk_mysql
}
# 状态变更时触发总司令脚本
notify_master "/etc/keepalived/mysql_role_switch.sh MASTER"
notify_backup "/etc/keepalived/mysql_role_switch.sh BACKUP"
notify_fault "/etc/keepalived/mysql_role_switch.sh BACKUP"
}核心参数讲解:
virtual_router_id: 主备的"接头暗号",必须一样,不然它俩不在一个频道,各玩各的。priority: 选举的核心,谁的数字大谁就是MASTER。vrrp_script&track_script: 这两个是黄金搭档。前者定义了"怎么检查",后者负责"把检查结果用起来"。当chk_mysql脚本执行失败,track_script就会让当前节点的priority减去weight定义的值(101 - 20 = 81)。81比备机的100低,于是VIP就漂移了。nopreempt: 最佳实践! 这个参数只在BACKUP节点上配。意思是"不抢占"。假设原来的主库mysql-node1只是网络抖动了一下,导致VIP切到了mysql-node2。几秒后mysql-node1恢复了,如果没有nopreempt,它的优先级(101)还是比mysql-node2(100)高,它会立刻把VIP抢回来。这一来一回的切换,对业务可能是致命的抖动。配置了nopreempt,就意味着只要mysql-node2还活着,即使mysql-node1恢复了,也得"靠边站",VIP不会切回去。这大大减少了不必要的切换,生产环境更稳定。
C. 核心脚本 (侦察兵 + 总司令)
check_mysql.sh负责高频侦察,mysql_role_switch.sh负责在收到Keepalived命令后,执行数据库角色切换的重操作。
/etc/keepalived/check_mysql.sh
bash
#!/bin/bash
# 使用mysqladmin工具检查MySQL服务的可用性
mysqladmin ping -u root -p'YourComplexP@ssw0rd!_2025' > /dev/null 2>&1
# 检查上一条命令的退出码
if [ $? -eq 0 ]; then
# 如果ping通,说明MySQL服务正常,脚本以退出码0结束
exit 0
else
# 如果ping不通,说明MySQL服务异常,脚本以退出码1结束
exit 1
fi/etc/keepalived/mysql_role_switch.sh
bash
#!/bin/bash
STATE=$1
LOG_FILE="/var/log/keepalived-mysql-state.log"
echo "$(date): Script called with state $STATE" >> $LOG_FILE
case $STATE in
"MASTER")
echo "Transitioning to MASTER..." >> $LOG_FILE
# 1. 停止从属关系
mysql -u root -p'YourComplexP@ssw0rd!_2025' -e "STOP SLAVE;"
# 2. 将数据库设置为可写
mysql -u root -p'YourComplexP@ssw0rd!_2025' -e "SET GLOBAL read_only = OFF;"
# 3. 如果需要,可以重置主库信息(在某些场景下需要)
# mysql -u root -p'YourComplexP@ssw0rd!_2025' -e "RESET MASTER;"
echo "Transition to MASTER finished." >> $LOG_FILE
;;
"BACKUP")
echo "Transitioning to BACKUP..." >> $LOG_FILE
# 1. 将数据库设置为只读
mysql -u root -p'YourComplexP@ssw0rd!_2025' -e "SET GLOBAL read_only = ON;"
# 2. (可选但推荐) 尝试重新配置并启动与新主库的同步
# 这一步比较复杂,通常需要外部脚本或人工介入来获取新主库的binlog位点
# 在一个简单的自动切换场景中,可以暂时只做降级为只读的操作
# mysql -u root -p'YourComplexP@ssw0rd!_2025' -e "START SLAVE;"
echo "Transition to BACKUP finished." >> $LOG_FILE
;;
*)
echo "Unknown state. No action taken." >> $LOG_FILE
exit 1
;;
esac
exit 0注意:这两个脚本的权限和属主是否正确?脚本里的数据库密码是否做了安全处理?
bash
chmod +x /etc/keepalived/check_mysql.sh /etc/keepalived/mysql_role_switch.sh
ls -l /etc/keepalived/check_mysql.sh /etc/keepalived/mysql_role_switch.sh
## 启动服务
systemctl enable --now keepalived
systemctl start keepalived
systemctl status keepalived
## 确认vip地址
ip addr dev ens18
## 查看日志
tail -f /var/log/messages | grep Keepalived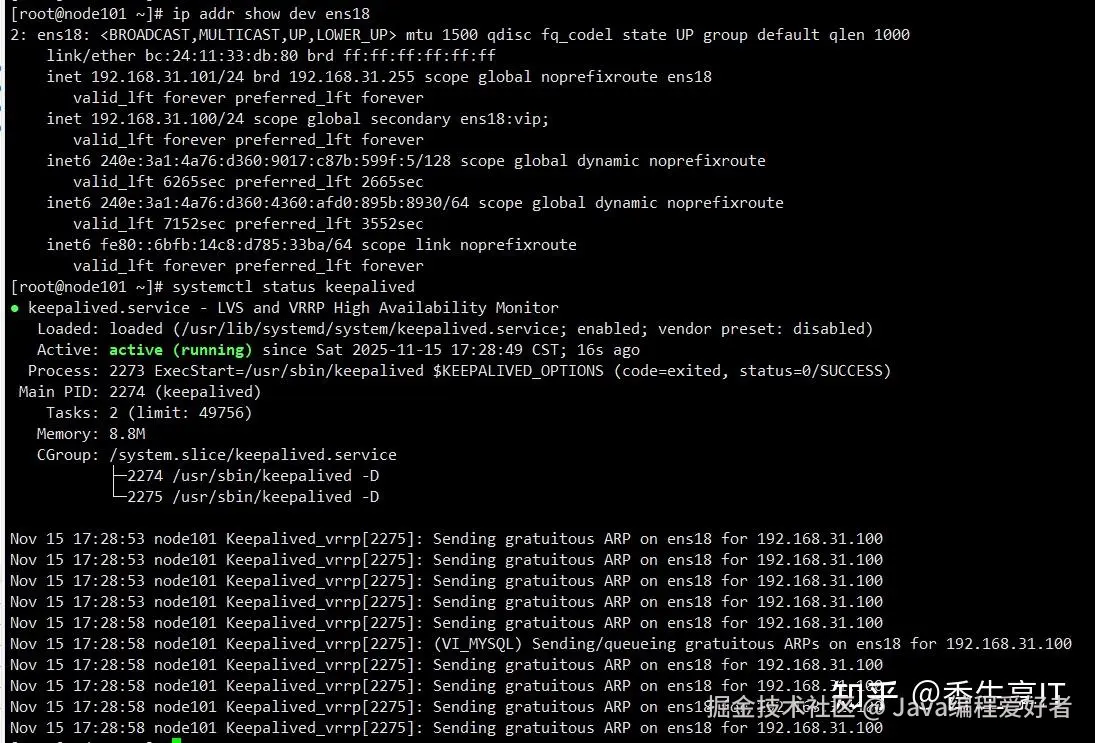

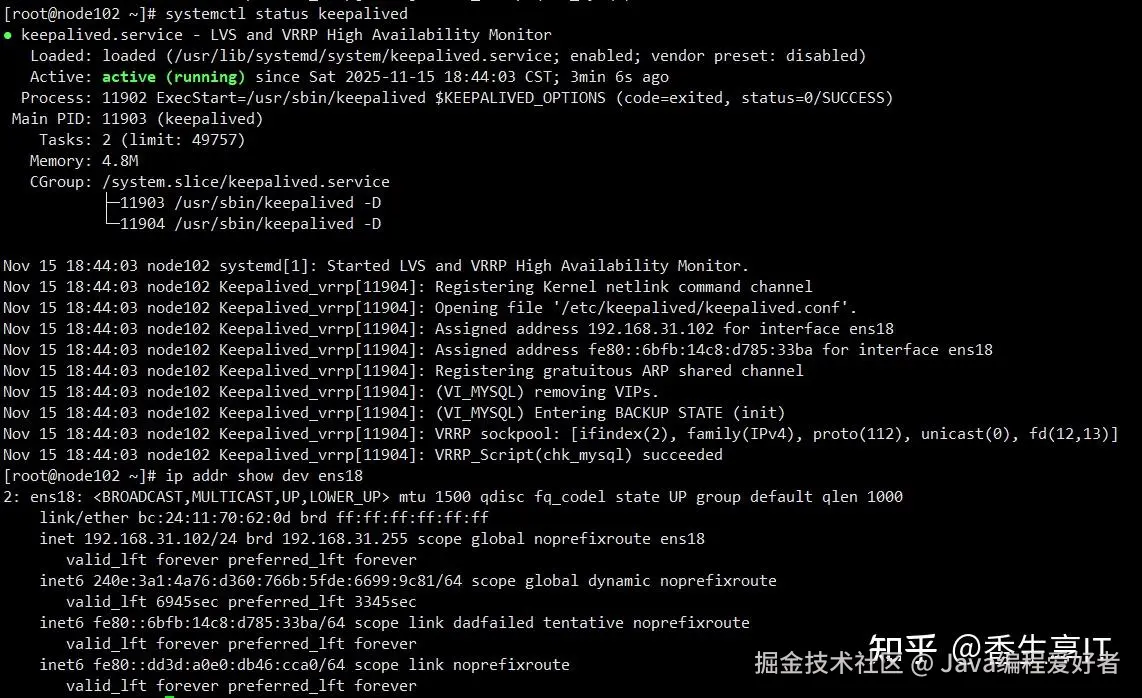
D. 切换演练
在主节点mysql-node1上执行systemctl stop mysqld,你会观察到VIP在几秒内自动漂移到mysql-node2,同时mysql-node2的数据库read_only状态自动变为OFF。
运行脚本"模拟交易往数据库中插入数据,并检查vip飘逸情况
ini
## 模拟交易,连接100
[root@node101 ~]# ./simulate_trx.sh
开始模拟交易,按 CTRL+C 停止...
插入新交易: trx_id = 15048884, cust_id = 674, amt = 232.11, 耗时: .037132763s
插入新交易: trx_id = 15048885, cust_id = 752, amt = 116.62, 耗时: .035379153s
## 停止节点1 mysqld
[root@node101 ~]# systemctl stop mysqld
## 节点2上监听 VRRP协议的包
[root@node102 ~]# tcpdump -i any -n vrrp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
19:05:29.651565 IP 192.168.31.101 > 224.0.0.18: VRRPv2, Advertisement, vrid 51, prio 81, authtype simple, intvl 1s, length 20
19:05:30.651689 IP 192.168.31.101 > 224.0.0.18: VRRPv2, Advertisement, vrid 51, prio 81, authtype simple, intvl 1s, length 20
19:05:31.651886 IP 192.168.31.101 > 224.0.0.18: VRRPv2, Advertisement, vrid 51, prio 81, authtype simple, intvl 1s, length 20
## 观察节点1 keepalived日志
Nov 15 19:00:00 node101 Keepalived_vrrp[48612]: Script `chk_mysql` now returning 1
Nov 15 19:00:02 node101 Keepalived_vrrp[48612]: VRRP_Script(chk_mysql) failed (exited with status 1)
Nov 15 19:00:02 node101 Keepalived_vrrp[48612]: (VI_MYSQL) Changing effective priority from 101 to 81
## 观察节点2 keepalived日志
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: (VI_MYSQL) Backup received priority 0 advertisement
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: (VI_MYSQL) Receive advertisement timeout
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: (VI_MYSQL) Entering MASTER STATE
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: (VI_MYSQL) setting VIPs.
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: (VI_MYSQL) Sending/queueing gratuitous ARPs on ens18 for 192.168.31.100
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:53 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:58 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:58 node102 Keepalived_vrrp[13558]: (VI_MYSQL) Sending/queueing gratuitous ARPs on ens18 for 192.168.31.100
Nov 15 19:09:58 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:58 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:58 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
Nov 15 19:09:58 node102 Keepalived_vrrp[13558]: Sending gratuitous ARP on ens18 for 192.168.31.100
## 查看vip情况
[root@node101 ~]# ip addr show dev ens18
2: ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether bc:24:11:33:db:80 brd ff:ff:ff:ff:ff:ff
inet 192.168.31.101/24 brd 192.168.31.255 scope global noprefixroute ens18
valid_lft forever preferred_lft forever
inet6 240e:3a1:4a76:d360:9017:c87b:599f:5/128 scope global dynamic noprefixroute
valid_lft 6744sec preferred_lft 3144sec
inet6 240e:3a1:4a76:d360:4360:afd0:895b:8930/64 scope global dynamic noprefixroute
valid_lft 7006sec preferred_lft 3406sec
inet6 fe80::6bfb:14c8:d785:33ba/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@node102 ~]# ip addr show dev ens18
2: ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether bc:24:11:70:62:0d brd ff:ff:ff:ff:ff:ff
inet 192.168.31.102/24 brd 192.168.31.255 scope global noprefixroute ens18
valid_lft forever preferred_lft forever
inet 192.168.31.100/24 scope global secondary ens18:vip
valid_lft forever preferred_lft forever
inet6 240e:3a1:4a76:d360:766b:5fde:6699:9c81/64 scope global dynamic noprefixroute
valid_lft 7021sec preferred_lft 3421sec
inet6 fe80::6bfb:14c8:d785:33ba/64 scope link dadfailed tentative noprefixroute
valid_lft forever preferred_lft forever
inet6 fe80::dd3d:a0e0:db46:cca0/64 scope link noprefixroute
valid_lft forever preferred_lft forever
## 查看节点2的状态
mysql> show variables like 'read_only';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+
1 row in set (0.00 sec)E. 方案弱点 (一针见血)
⚠️ 老兵提醒: 这个方案看起来很美,但在复杂的生产环境,它的"自动"可能会变成"自动惹祸":
-
没有"仲裁"机制: 如果主备之间的心跳网络断了(比如交换机故障),但两台服务器都活着,就会导致"脑裂"。双方都认为对方挂了,都抢着当
MASTER,都会把自己变成可写,数据会彻底写乱! -
数据一致性隐患: 切换只依赖于简单的健康检查,没有MHA那种"捞数据"的过程。如果主库宕机前有一笔事务的binlog没来得及传到备库,这笔数据就永久丢失了。
-
恢复流程复杂: 老的主库修好后,怎么让它重新以
SLAVE的身份加入集群?这个过程自动化脚本很难做得完美,大概率需要DBA手动介入,反而增加了操作风险。
正是因为有这些"坑",所以很多严谨的团队,特别是金融行业,会选择下面这种看起来"笨",但实际上更稳妥的方案。
方案二:生产级手动切换 (SOP保障)
这个方案的哲学是:机器负责监控和漂移VIP,但切换决策由人来做。 我们把Keepalived当成一个手动的、高效率的VIP切换工具,而不是一个自动决策系统。
A. 核心思路
两台服务器上的Keepalived配置文件完全一样 !并且,在任何时候,只允许一台服务器上的Keepalived服务是运行状态。切换时,我们严格按照标准操作流程(SOP),先手动完成数据库角色的确认和变更,然后再"一停一启"Keepalived服务,完成VIP的切换。
B. 统一配置文件 (两边完全一样)
把下面这份配置原封不动地放到mysql-node1和mysql-node2的/etc/keepalived/keepalived.conf。
perl
! Configuration File for keepalived (Manual-Switch)
global_defs {
# 名字可以根据你的业务来,但两边要一样
router_id MYSQL_HA_CLUSTER
}
vrrp_instance VI_MYSQL {
# 默认都写MASTER,谁先启动谁就是MASTER
state MASTER
interface ens192 # 根据你的实际网卡修改
virtual_router_id 51 # 必须一样
priority 100 # 优先级一样,谁先启动谁优先
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.31.100 # 根据你的VIP修改
}
# 注意!这个方案里,我们不使用任何的track_script或notify脚本!
}⚠️ 关键点: 这个配置里没有
track_script!Keepalived不再关心MySQL的死活,它只做一个纯粹的VIP管理工具。它的启停,完全由DBA掌控。
C. 标准切换流程
假设当前主库是mysql-node1,我们要切换到mysql-node2。
第1步:在旧主库 mysql-node1 上操作
bash
# 1. 停止Keepalived服务,释放VIP
systemctl stop keepalived
echo "Keepalived on old master stopped."
# 2. 确认VIP已释放
ip a | grep "192.168.31.100" # 确保这条命令没有任何输出
# 3. 将旧主库设置为只读,防止新数据写入
mysql -e "SET GLOBAL read_only = ON;"
echo "Old master is now read-only."第2步:在新主库 mysql-node2 上操作
bash
# 1. 确认与旧主库的数据同步已完成 (非常重要!)
# 登录MySQL,执行 SHOW SLAVE STATUS\G,查看 Seconds_Behind_Master 是否为 0
# 在确认同步无延迟后,再进行下一步
# 2. 停止同步并提升为新主
mysql -e "STOP SLAVE; SET GLOBAL read_only = OFF;"
echo "New master promoted."
# 3. 启动Keepalived服务,接管VIP
systemctl start keepalived
echo "Keepalived on new master started."第3步:验证
perl
# 1. 在新主库 `mysql-node2` 上确认VIP已绑定
ip a | grep "192.168.31.100" # 应该能看到VIP
# 2. 尝试用VIP连接数据库,并执行写操作,确认服务正常
# mysql -h 192.168.31.100 -u ... -p... -e "CREATE TABLE test_switch (id int); INSERT INTO test_switch VALUES (1);"这个流程清晰、可控,每一步都有明确的检查点,最大限度地避免了自动切换带来的不确定性。
4 运维最佳实践
针对上面两种方案,我们的运维监控重点也不同。
监控:
- 对于方案一 (自动): 必须重点监控
/var/log/keepalived-mysql-state.log这个自定义日志文件。任何状态切换都应该触发最高级别的告警,通知DBA立即介入检查。同时,要监控主备两边read_only的状态是否符合预期。 - 对于方案二 (手动): 监控的重点是 "Keepalived进程的唯一性" 。必须有一个监控项,确保集群中永远只有一个
keepalived进程在运行。一旦发现两个都在运行,必须立即告警,这是脑裂的前兆! - 通用监控: VIP的归属、MySQL主从复制延迟(
Seconds_Behind_Master)是两种方案都必须死盯的指标。
日志分析:
tail -f /var/log/messages | grep Keepalived依然是排错第一神器。要学会看懂Entering MASTER state、Entering BACKUP state等关键日志。- 在方案一中,
mysql_role_switch.sh脚本的输出日志是判断切换是否成功、哪里卡住的关键依据。
"脑裂" (Split-Brain) 防治:
- 方案一 (自动): 脑裂风险较高,唯一的物理缓解措施就是使用独立、可靠的心跳网络,比如两台服务器用一根网线直连,专门跑VRRP协议。
- 方案二 (手动): 从机制上杜绝了脑裂的发生。因为我们严格遵守"只启一个"的原则,只要SOP被严格执行,就不会出现两个节点都认为自己是主的混乱局面。这就是它"笨"却"稳"的核心优势。
5 总结
好了,兄弟们,今天我们把Keepalived配合MySQL的两种玩法都掰扯清楚了。
- 方案一 (自动切换): 像一辆"自动驾驶汽车"。适合那些对RTO(恢复时间目标)要求极高,但对数据一致性容忍度稍高(比如允许丢失几秒数据)的非核心业务。优点是快,缺点是"方向盘"不在你手里,极端情况下可能失控。
- 方案二 (手动切换): 像一辆"手动挡的越野车"。它把切换的最终决定权牢牢地交还给了DBA。每一步操作都在你的掌控之中。它牺牲了一点点切换速度,但换来的是极高的可靠性和数据安全性。这在金融、核心交易等场景,是毋庸置疑的选择。
技术方案没有绝对的"最好",只有"最合适"。你问我推荐哪个?在你不完全确定你的业务能承受自动切换带来的风险之前,我强烈建议你从方案二开始。 先用最稳的方法把高可用搭起来,把SOP流程跑到滚瓜烂熟。等你对整个系统的脾气都摸透了,再考虑是否需要向自动化演进。
记住,作为一个生产环境的DBA,"稳"字永远是第一位的。