前言
最近做项目,要求一定要使用ai,降b增x,说实在的在vibe coding方面,尤其是crud确实可以,节省了大量的重复工作量,但是还是达不到替代人的效果。笔者在尝试使用springai来实现chat mcp等能力,方便以后开发各种定制增强coding能力。
准备demo
spring ai在前段时间发布了1.1.2版本,目前已经趋于稳定使用,实际上很多网上的示例使用的langchain,语言绝大部分为python,nodejs相关。Java的springai实际上很早就有了,只不过更新次数很少,到1.1.2已经很完善了,先试了一下聊天,看看走的协议,其实就是一个壳,本质就是http调用ollama。
XML
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>springai-chat</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.5.8</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.1.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>springai是基于jdk17打造的,这点不如langchain的sdk,可以使用jdk8。其实这个原因是springboot基线版本使用3.x,发送http请求跟jdk版本无关。根据官方文档:https://docs.spring.io/spring-ai/reference/api/chat/ollama-chat.html
bash
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
# deepseek-r1:1.5b
model: gemma3:4b笔者运行的gemma3 4b模型,谷歌开源
java
@Configuration
public class ChatConfiguration {
@Autowired
private ChatClient.Builder builder;
@Bean
public ChatClient initChatClient() {
return builder.defaultSystem("你是一名AI助手,你的名字叫阿尔法。你可以帮助用户解答关于用户提出的相关的知识")
.build();
}
}
@RestController
@RequestMapping("/chat")
public class ChatController {
@Autowired
private ChatClient chatClient;
@PostMapping("/ask")
public String ask(@RequestParam("question") String ques) {
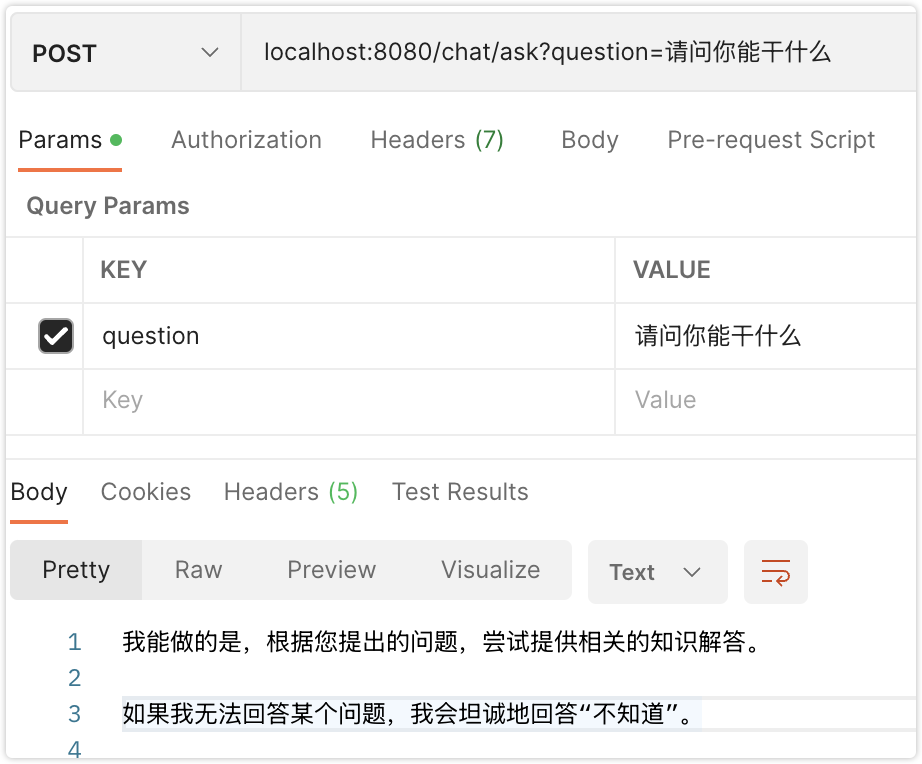
return chatClient.prompt("请仔细回答,不知道就回答不知道,请忽乱答\n务必遵循上面原则").user(ques).call().content();
}
@PostMapping("/multiAsk")
public String multiAsk(@RequestParam("question") String question) {
List<Message> messageList = new ArrayList<>();
messageList.add(new UserMessage("你好,我是用户,你是谁?"));
messageList.add(new AssistantMessage("你好,我是阿尔法,很高兴为你解答,请问需要知道什么?"));
messageList.add(new UserMessage(question));
return chatClient.prompt().messages(messageList).call().content();
}
}访问ask请求
当需要上下文联动时,如下:
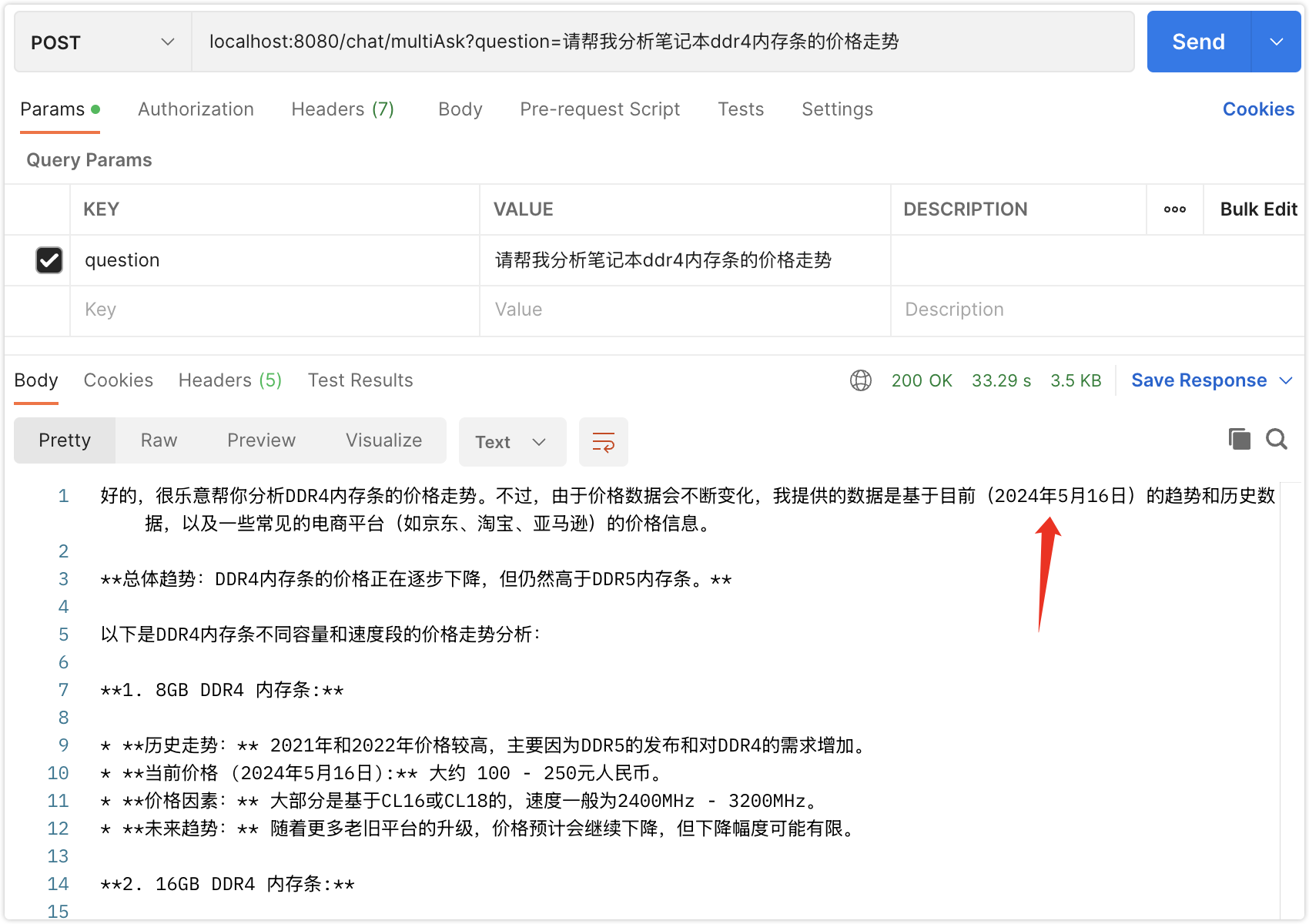
笔者的模型数据是2024年的,代码的上下文实际上未体现出来
抓包
笔者想知道,怎么交互的,通过抓包发现使用http请求,当然可能跟我使用ollama有关系,这个毕竟是用来自己验证测试使用的
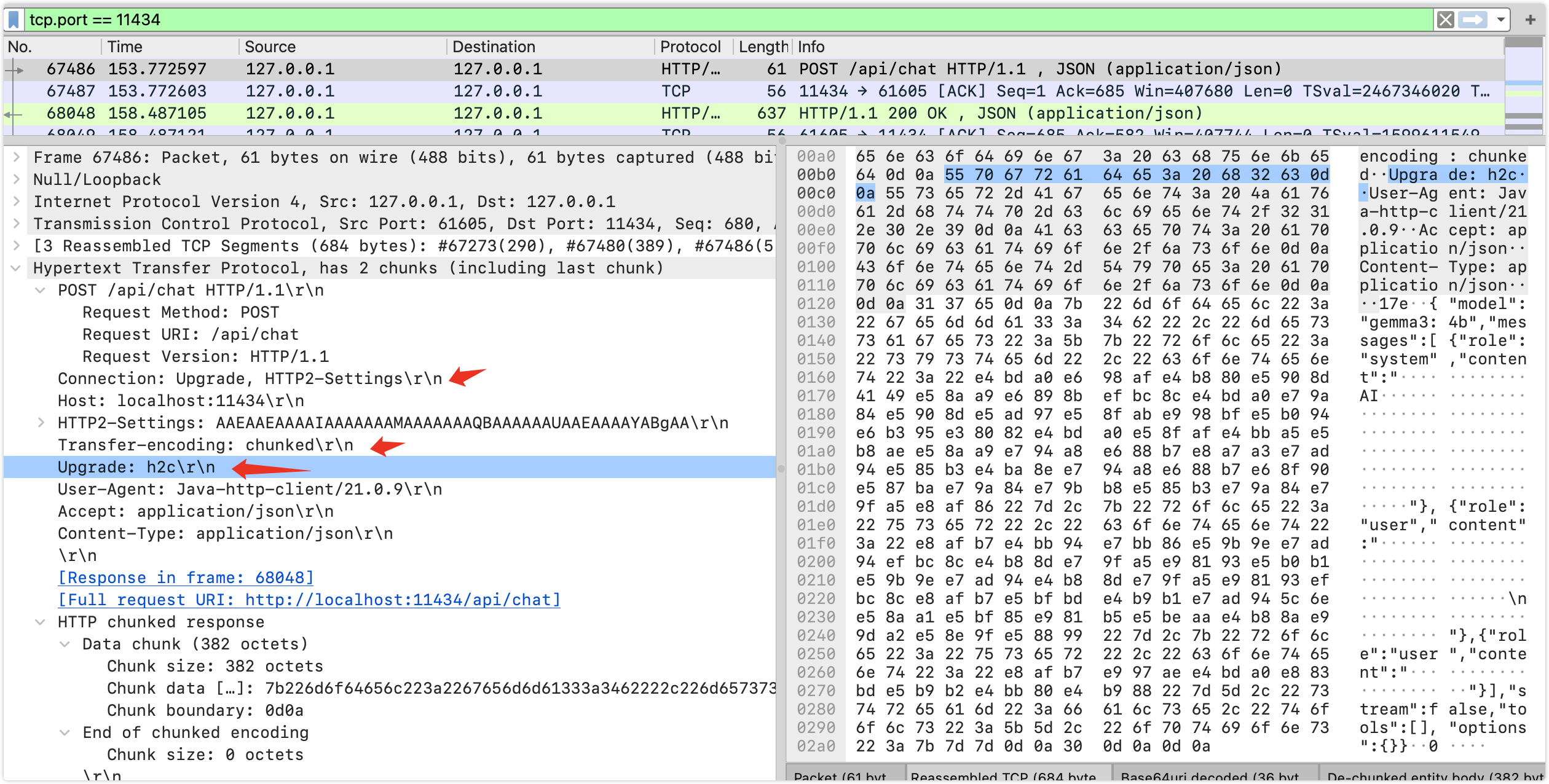
可以看到ollama的服务端使用了h2,springai的请求被升级到h2c,使用chunk传输,在h2上实际上为帧,看看传输的内容
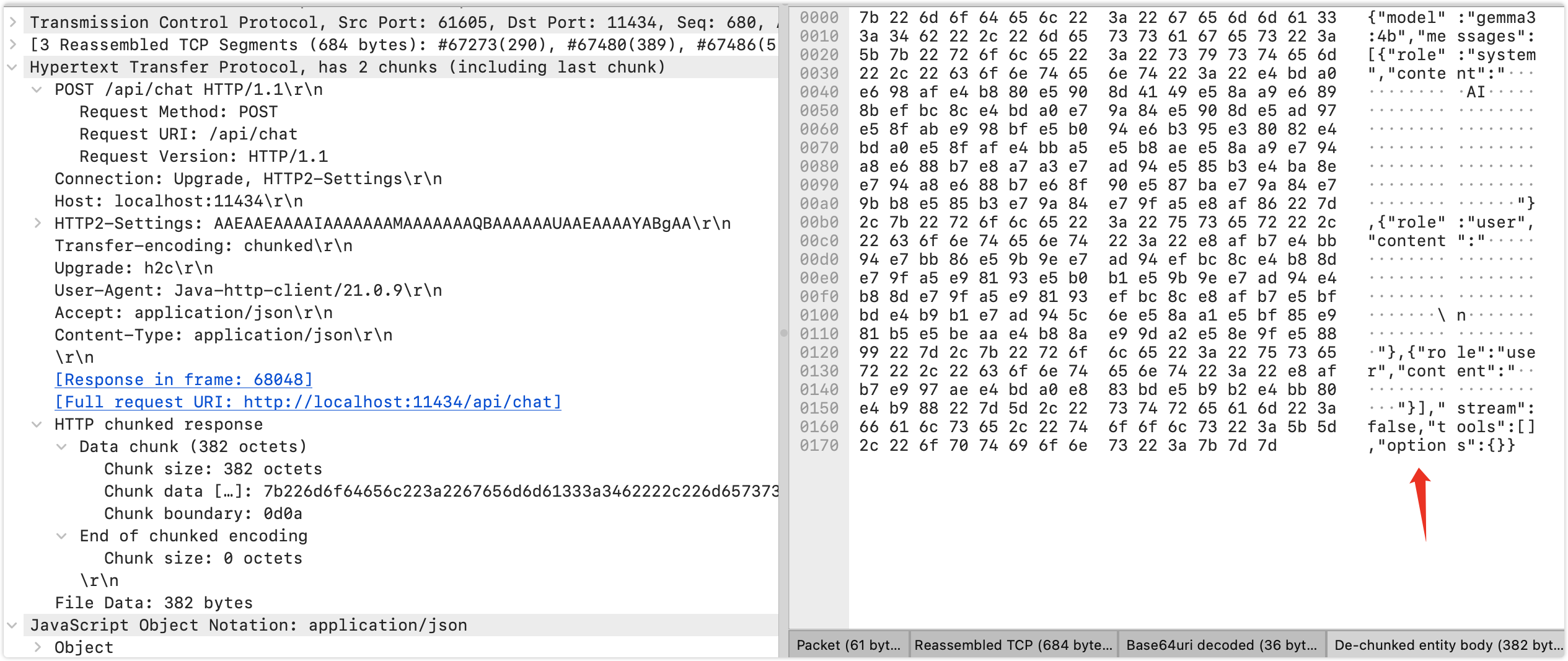
转为字符串为:
bash
{
"model": "gemma3:4b",
"messages": [
{
"role": "system",
"content": "你是一名AI助手,你的名字叫阿尔法。你可以帮助用户解答关于用户提出的相关的知识"
},
{
"role": "user",
"content": "请仔细回答,不知道就回答不知道,请忽乱答\n务必遵循上面原则"
},
{
"role": "user",
"content": "请问你能干什么"
}
],
"stream": false,
"tools": [],
"options": {}
}定义了模型信息
messages为交互内容,虽然我们只说了一句,实际上内嵌了一些信息:包括初始提示语,prompt,还有我们的问答信息
stream 为是否流传输,这个为新特性,从sse到streamable方式
tools为工具,这个在agent平台经常见到,我这里没有编写工具,比如执行function calling
options为选项,暂时先不管
看看返回信息:返回是http1.1
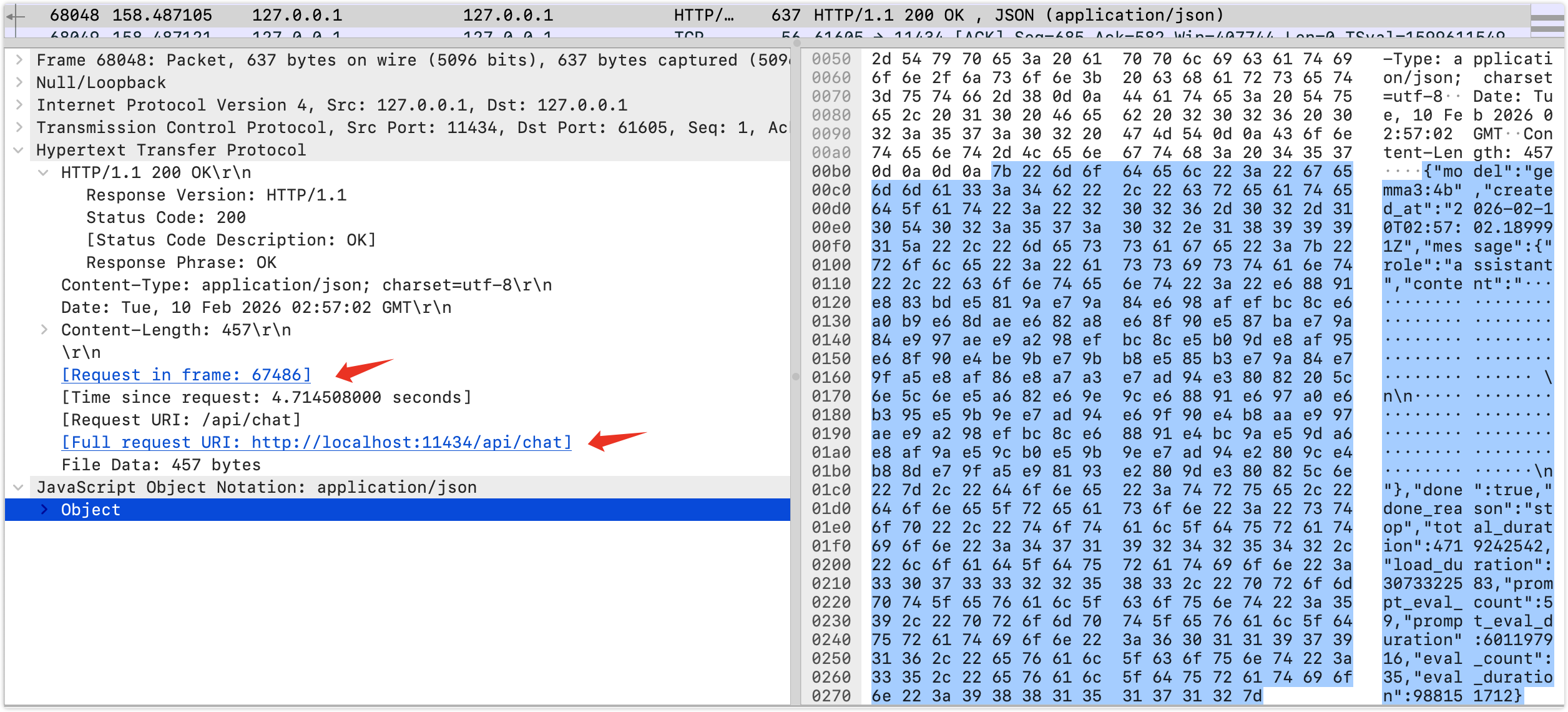
API为/api/chat,从这么看我们其实是API工程师,类似容器的kukectl
bash
{
"model": "gemma3:4b",
"created_at": "2026-02-10T02:57:02.189991Z",
"message": {
"role": "assistant",
"content": "我能做的是,根据您提出的问题,尝试提供相关的知识解答。 \n\n如果我无法回答某个问题,我会坦诚地回答"不知道"。\n"
},
"done": true,
"done_reason": "stop",
"total_duration": 4719242542,
"load_duration": 3073322583,
"prompt_eval_count": 59,
"prompt_eval_duration": 601197916,
"eval_count": 35,
"eval_duration": 988151712
}其实返回内容基本上只需要content,其他是一些模型的运行信息,比如状态,耗时,eval等
那么分析多轮对话看看,抓包得:请求数据
bash
{
"model": "gemma3:4b",
"messages": [
{
"role": "system",
"content": "你是一名AI助手,你的名字叫阿尔法。你可以帮助用户解答关于用户提出的相关的知识"
},
{
"role": "user",
"content": "你好,我是用户,你是谁?"
},
{
"role": "assistant",
"content": "你好,我是阿尔法,很高兴为你解答,请问需要知道什么?"
},
{
"role": "user",
"content": "请帮我分析笔记本ddr4内存条的价格走势"
}
],
"stream": false,
"tools": [],
"options": {}
}返回结果:
bash
{
"model": "gemma3:4b",
"created_at": "2026-02-10T09:09:01.860509Z",
"message": {
"role": "assistant",
"content": "好的,很乐意帮你分析DDR4内存条的价格走势。不过,由于价格数据会不断变化,我提供的数据是基于目前(2024年5月16日)的趋势和历史数据,以及一些常见的电商平台(如京东、淘宝、亚马逊)的价格信息。\n\n**总体趋势:DDR4内存条的价格正在逐步下降,但仍然高于DDR5内存条。**\n\n以下是DDR4内存条不同容量和速度段的价格走势分析:\n\n**1. 8GB DDR4 内存条:**\n\n* **历史走势:** 2021年和2022年价格较高,主要因为DDR5的发布和对DDR4的需求增加。 \n* **当前价格 (2024年5月16日):** 大约 100 - 250元人民币。\n* **价格因素:** 大部分是基于CL16或CL18的,速度一般为2400MHz - 3200MHz。 \n* **未来趋势:** 随着更多老旧平台的升级,价格预计会继续下降,但下降幅度可能有限。\n\n**2. 16GB DDR4 内存条:**\n\n* **历史走势:** 价格波动较大,受DDR5的冲击影响,初期价格较高,之后又因为DDR5供不应求价格飙升。\n* **当前价格 (2024年5月16日):** 大约 200 - 450元人民币。\n* **价格因素:** CL16、CL18、CL19等,速度 3200MHz - 3600MHz。\n* **未来趋势:** 价格会继续下降,但仍然会受到二手DDR5供应的影响。\n\n**3. 32GB DDR4 内存条:**\n\n* **历史走势:** 价格与16GB类似,受DDR5影响较大。\n* **当前价格 (2024年5月16日):** 大约 400 - 800元人民币。\n* **价格因素:** CL16/CL18,速度 3200MHz - 3600MHz。\n* **未来趋势:** 预计会继续下降,但由于DDR4的生产规模较小,价格不会有太大波动。\n\n**4. 64GB DDR4 内存条:**\n\n* **历史走势:** 价格相对较高,主要用于高端游戏玩家和专业人士。\n* **当前价格 (2024年5月16日):** 大约 800 - 1600元人民币。\n* **价格因素:** CL16/CL18,速度 3200MHz - 3600MHz。\n* **未来趋势:** 价格会继续下降,但仍会维持一定的溢价。\n\n**影响价格的主要因素:**\n\n* **速度 (MHz):** 速度越快,价格越高。\n* **时序 (CL - CAS Latency):** 时序越低,延迟越小,价格越高。\n* **品牌:** 知名品牌的价格通常会略高。\n* **散热片:** 散热片的设计会影响内存条的性能和价格。\n* **市场供求关系:** 市场需求和供应量对价格影响很大。\n\n**总结:**\n\n* **DDR4内存条是DDR5的替代品,但在DDR5盛行的今天,DDR4的供应量越来越少,价格也逐渐下降。**\n* **购买DDR4内存条时,建议优先选择速度较高的内存条(3600MHz以上),并注意时序。**\n* **考虑到DDR5的普及趋势,建议根据预算和需求选择DDR5内存条。**\n\n**获取实时价格的建议:**\n\n* **京东:** [https://item.jd.com/search.html?query=ddr4%E5%86%95](https://item.jd.com/search.html?query=ddr4%E5%86%95)\n* **淘宝:** 搜索关键词 "DDR4内存"\n* **亚马逊中国:** [https://www.amazon.cn/s?k=ddr4+内存](https://www.amazon.cn/s?k=ddr4+内存)\n\n**免责声明:** 以上数据仅供参考,实际价格可能因销售商、促销活动等因素而有所不同。建议在购买前仔细比较不同品牌和型号的价格,并根据自己的需求选择合适的内存条。\n\n希望以上分析对您有所帮助! 您还有其他想了解的吗? 比如,你想知道特定型号DDR4内存条的当前价格,或者想了解购买DDR4内存条时需要注意的事项?\n"
},
"done": true,
"done_reason": "stop",
"total_duration": 33269420625,
"load_duration": 138193959,
"prompt_eval_count": 82,
"prompt_eval_duration": 175186958,
"eval_count": 1083,
"eval_duration": 32676605452
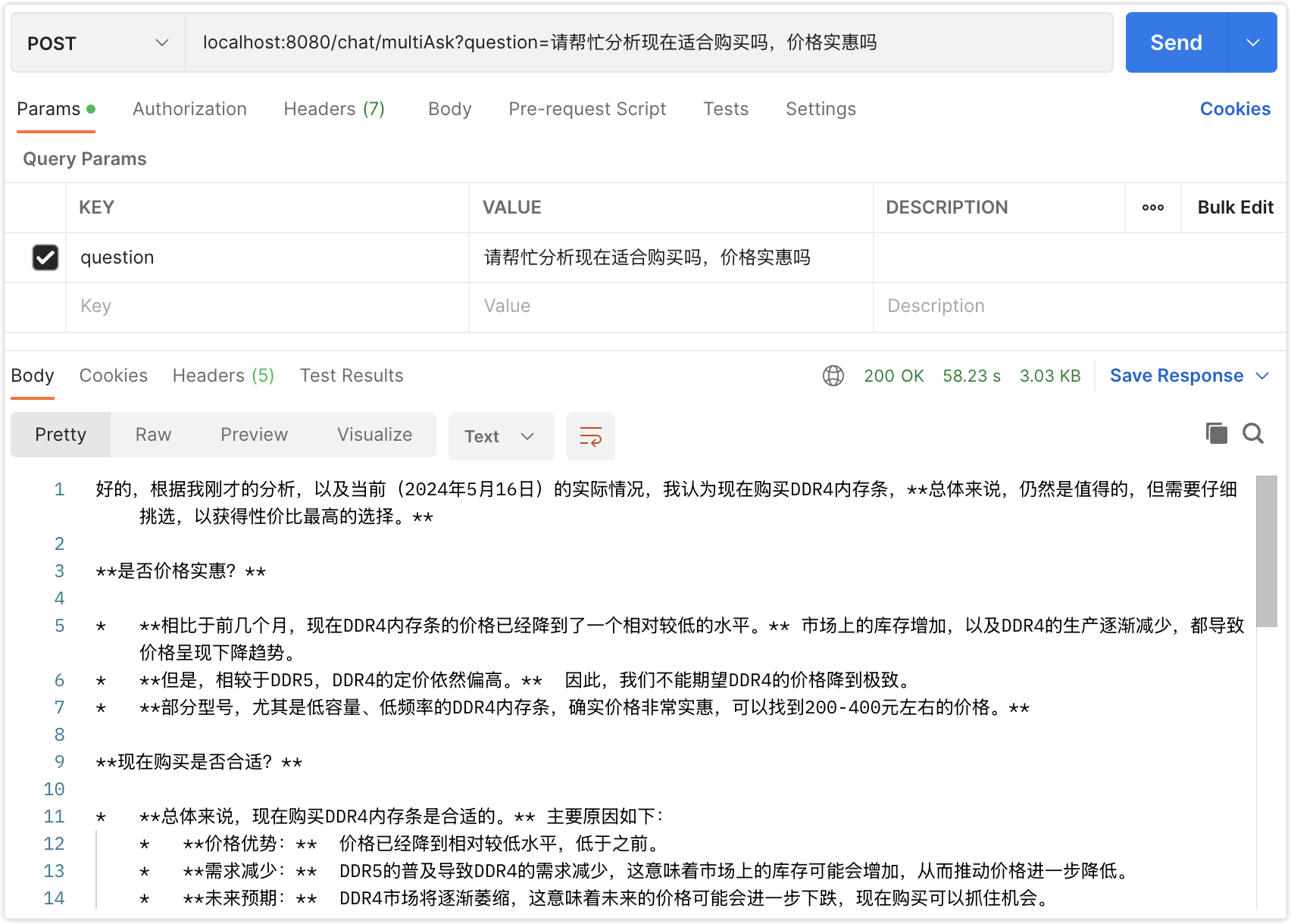
}这个时候上下文不明显,比如我们还想买一条内存条,就比较明显了,这里改一下代码,直接把结果传入chat,如果实现联网查询价格,那么需要mcp服务,如果需要计算折扣,怎么买最划算就需要tools function calling了。
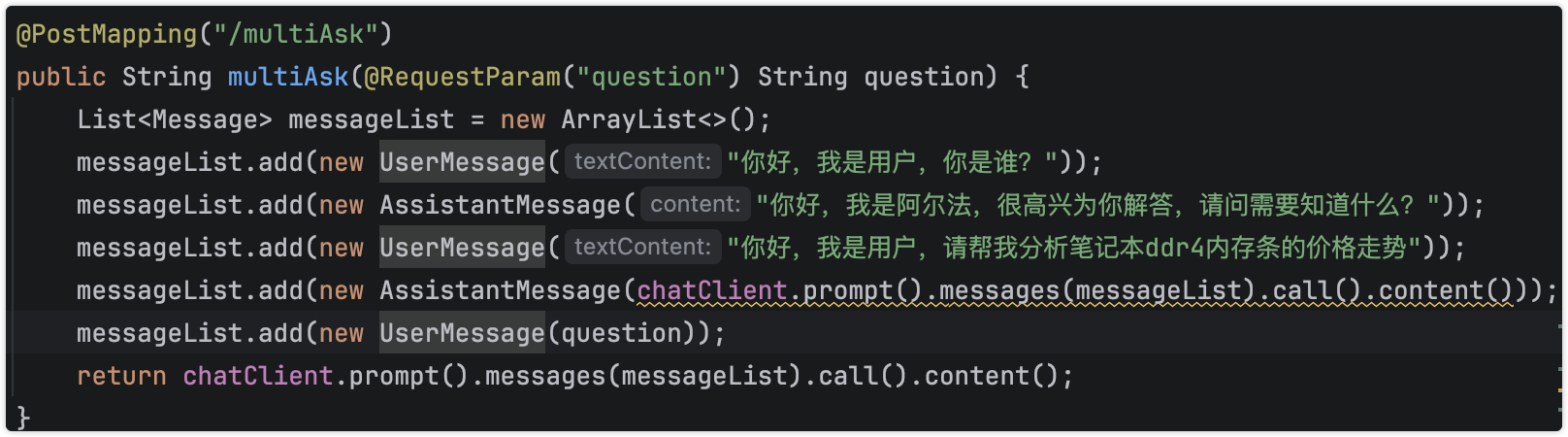
当然笔者demo这里写死了,实际情况可以灵活点,后台记忆存储,记忆次数越多,消耗token越大,所以一般不会超过3次上下文联想。当然笔者这里进行了多次chat,实际情况上次的结果是缓存带入下一次的,毕竟多次chat耗时太久了。
总结
笔者使用springai和ollama来聊天,发现ai在分析问题方面确实还可以,逻辑比较清晰,结果比较令人满意。但是笔者测试较少,不排除致幻的可能性,对于springai的程序编写,说句总结:API编程,类似容器kubectl。其中多轮对话可以更好的利用ai的能力,本质就是message的多次传递。其中暴露ai的一些问题:
-
模型训练后,如果有新的咨询,模型无法识别,比如天气,价格走势
-
模型的回答结果是不确定的,可能8成(这个根据不同模型不同的提问不同)符合预期,这个需要海量数据评估才行,如果不符合预期,人怎么确定是否正确,比如把羊和老虎说是和睦关系
-
模型本身的能力和知识不足需要外部能力,比如mcp tools,知识库rag skills等,这带来新的问题,多次交互会耗时严重。