最近爆火的开源项目 OpenClaw 是一个款能够运行在自己设备上的个人 AI 助手。你只需分配任务,它就会 7x24 干活------而不是简单的文字回复。
目前,网上已经有很多详细的 OpenClaw 安装教程,这里就不再重复了。我平时用 OpenClaw 干活,比如:创意策划和执行落地这两个角色是需要分开的------前者需要天马行空,后者需要严谨细致。这个时候,不同的 AI 需要有不同的定位才能干好活。
我就想,能不能让两个 OpenClaw 各干各的活,但又能无缝衔接 24/7 搞事情?
最近在 x 上也看到了 @huangserva 大佬的方案,给了我更多的灵感!如果跑通了,以后「一人公司」的未来不就是我带着自己的 OpenClaw A、B、C 一起 24/7 高效搞事儿?!
这时候我又看到了 MemOS 刚发的 OpenClaw 插件,用下来感觉还真行。

GitHub 地址:github.com/MemTensor/M...
下面就是我的实际操作记录:怎么部署的、怎么配置的以及最后跑通了的效果(多 OpenClaw 协作)。
一、为什么需要两个 OpenClaw 协作?
一开始我也觉得,一个 OpenClaw 不就够了吗?为什么要搞两个?
用了一阵子发现,有些场景确实需要分工,其次是分工可以更高效的产出。
比如:策划活动时,创意阶段需要发散思维、天马行空。执行阶段需要落地细节、风险把控。让同一个 Agent 既发散又严谨,很容易精神分裂。
其次,一个 OpenClaw 装了设计工具、文案模板,专门干创意。另一个连接了项目管理系统、预算工具,专门干落地。各司其职,效率更高。
我的需求就是第一种:策划一场技术沙龙。创意阶段让 OpenClaw A 产出活动主流程和招募文案,执行阶段让 OpenClaw B 接力产出物料清单、风险预案,最后再 double-check 一遍。
这里的关键是:B 不需要我手动告诉它 A 做了什么,它应该自己从记忆里读到 A 的产出,然后无缝接力 24/7 搞事情。
然后 MemOS 的 OpenClaw 插件帮助我更好的干了这个脏活。
二、部署两个 OpenClaw + MemOS 插件
整个部署过程不复杂,但有几个细节要注意。
2.1 获取 MemOS API Key
首先去 MemOS 官方注册并获取 API Key 格式是 mpg-... 开头的字符串。
!\[\](img2024.cnblogs.com/blog/759200... =1363x308)
这个 Key 是两个 OpenClaw 共享记忆的凭证。有了它,两个独立的 OpenClaw 实例就能访问同一个记忆池。
2.2 部署两个 OpenClaw 实例
我是在同一台机器上跑两个实例,用不同端口区分。你也可以分别部署在两台服务器上,效果一样。
OpenClaw A:创意策划
bash
# 创建配置目录并写入 API Key
mkdir -p ~/.openclaw && echo "MEMOS_API_KEY=mpg-your_key_here" > ~/.openclaw/.env
# 安装 OpenClaw(如果还没装)
npm install -g openclaw@latest
# 初始化配置
openclaw onboard按提示配置完后,OpenClaw A 会跑在默认端口(通常是 3000)。
OpenClaw B:执行落地
这里有个坑:同一台机器跑两个实例,需要指定不同的工作目录和端口。
bash
# 创建 OpenClaw B 的独立工作目录
mkdir -p ~/.openclaw-exec
# 复制配置(用同一个 API Key)
cp ~/.openclaw/.env ~/.openclaw-exec/.env
# 用独立配置启动第二个实例
OPENCLAW_HOME=~/.openclaw-exec openclaw onboard --port 3001这样两个 OpenClaw 就跑起来了,一个在 3000 端口一个在 3001 端口。
2.3 安装 MemOS 插件
两个实例都要装 MemOS 插件。分别进入各自的终端执行:
OpenClaw A
openclaw plugins install github:MemTensor/MemOS-Cloud-OpenClaw-Plugin
openclaw gateway restartOpenClaw B
ini
OPENCLAW_HOME=~/.openclaw-exec openclaw plugins install github:MemTensor/MemOS-Cloud-OpenClaw-Plugin
OPENCLAW_HOME=~/.openclaw-exec openclaw gateway restart装完后,检查插件是否启用:
bash
# OpenClaw A
cat ~/.openclaw/openclaw.json | grep memos-cloud-openclaw-plugin
# OpenClaw B
cat ~/.openclaw-exec/openclaw.json | grep memos-cloud-openclaw-plugin看到 "enabled": true 就说明插件已激活。
2.4 共享 user_id(关键)
user_id 是实现让多个 OpenClaw 记忆共享的关键。
MemOS 用 user_id 来区分不同的记忆空间。同一个 user_id 下的所有对话和产出,都存在同一个记忆池里。
默认配置下 MEMOS_USER_ID=openclaw-user,两个 OpenClaw 实例用的是同一个 .env 文件(或者你手动复制了一份相同的),所以它们的 user_id 是一样的------这就实现了记忆共享。
如果你想改成自定义的 user_id,可以在 .env 文件里加一行就搞定:
ini
MEMOS_USER_ID=my-custom-user-id两个龙虾(OpenClaw)都用这个配置,就能轻松共享记忆!
三、测试两个 OpenClaw 协作策划技术沙龙
部署好后,开始测试协作流程。
3.1 任务分工
我给两个 OpenClaw 定了明确的分工和角色:
OpenClaw A 负责创意策划


OpenClaw B 则负责执行落地
- 基于 A 的方案,产出物料清单
- 制定风险预案
- 最后再 double-check 整体方案
这么操作的目的是:B 不需要我告诉它 A 做了什么,自己就能从 MemOS 记忆里读到 A 的产出,并开始无缝接力干活。
3.2 第一步:OpenClaw A 产出创意方案
我打开 OpenClaw A 的界面,直接问:

OpenClaw A 开始工作。几分钟后,它开始产出了:

并且快速给我返回了结果:
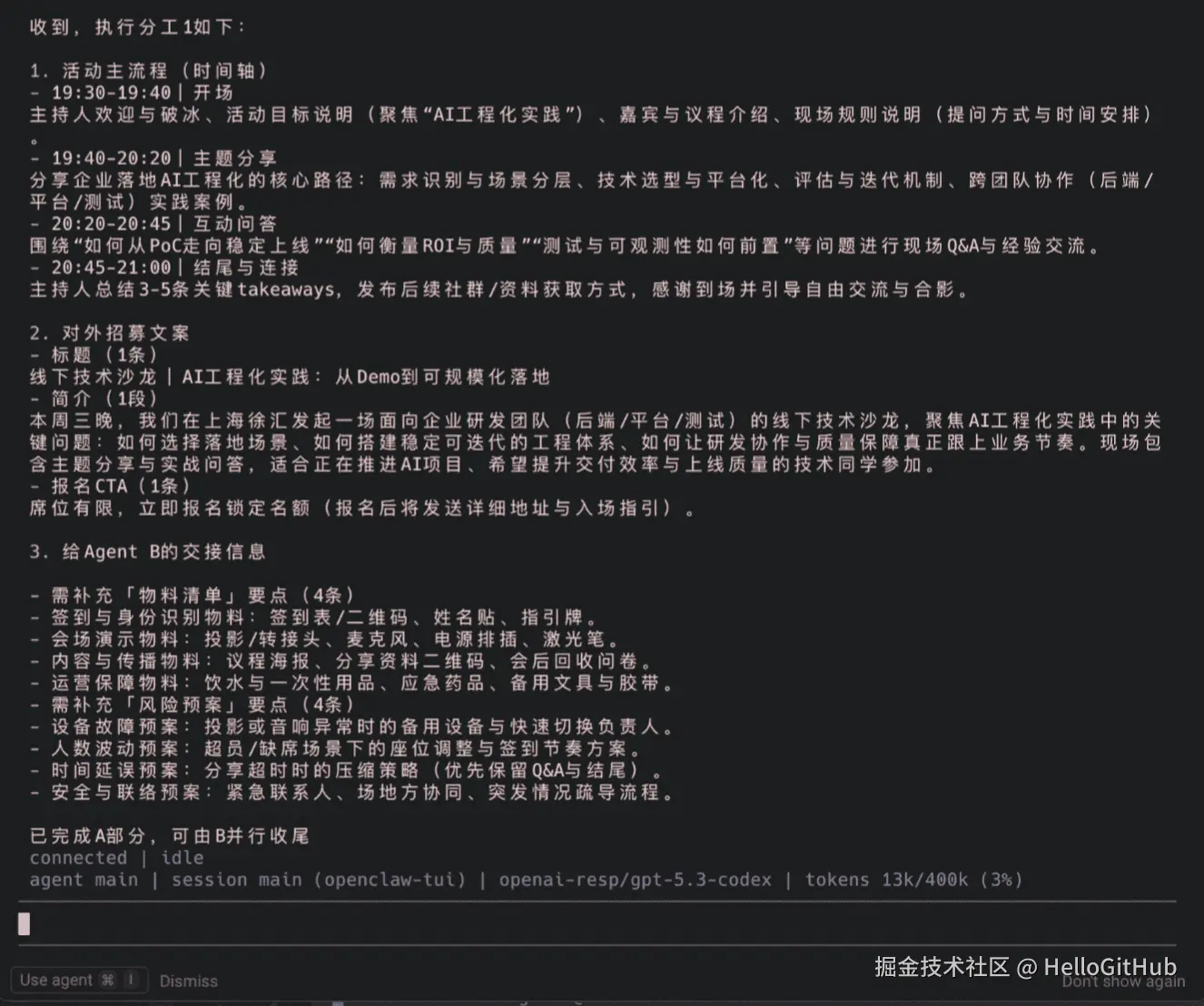
这些内容自动写入了 MemOS。我没做任何手动保存,插件已经把 A 的产出存进了记忆池。
3.3 第二步:OpenClaw B 无缝接力
协作的关键点来啦!我切换到 OpenClaw B 的界面(http://localhost:3001),不告诉它任何背景信息,直接问:

OpenClaw B 开始工作,可以明显看到它在"思考"------它先调用了 MemOS 的记忆检索,然后基于 A 的产出开始接力。几分钟后,B 也开始产出了:

B 返回的结果:
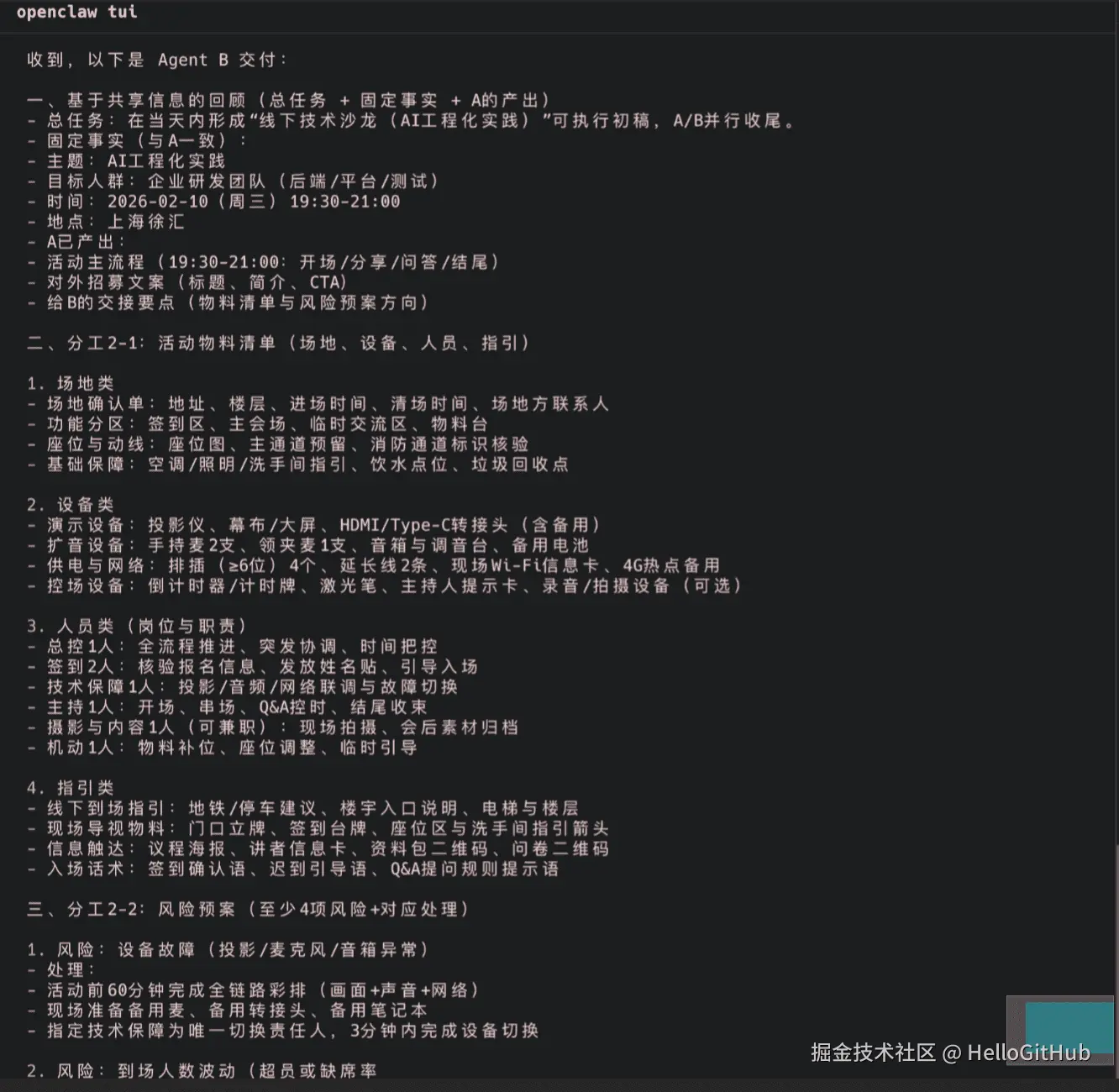
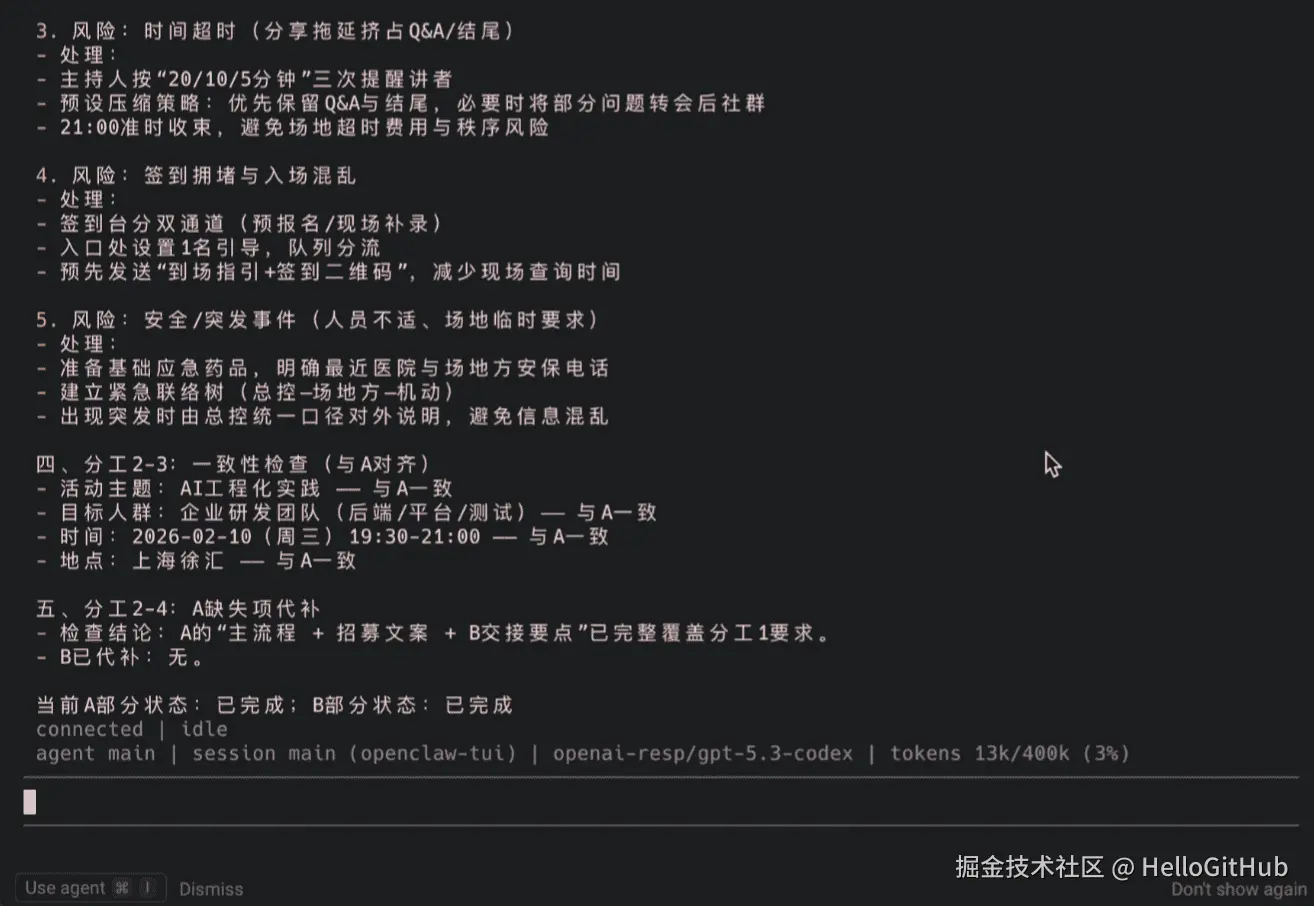
从返回的结果可以看出:
- B 没有问我什么活动
- B 直接基于 A 的方案做了后续的补充和延展
- B 的物料清单和 A 的议程完全对得上~
这说明 MemOS 的记忆检索和注入机制是有效的!B 确实读到了 A 的产出,并且理解了完整上下文。
3.4 第三步:OpenClaw B 做 Double-Check
为了验证 B 的质量把控能力,我又问了一句:

B 很快给出了反馈:

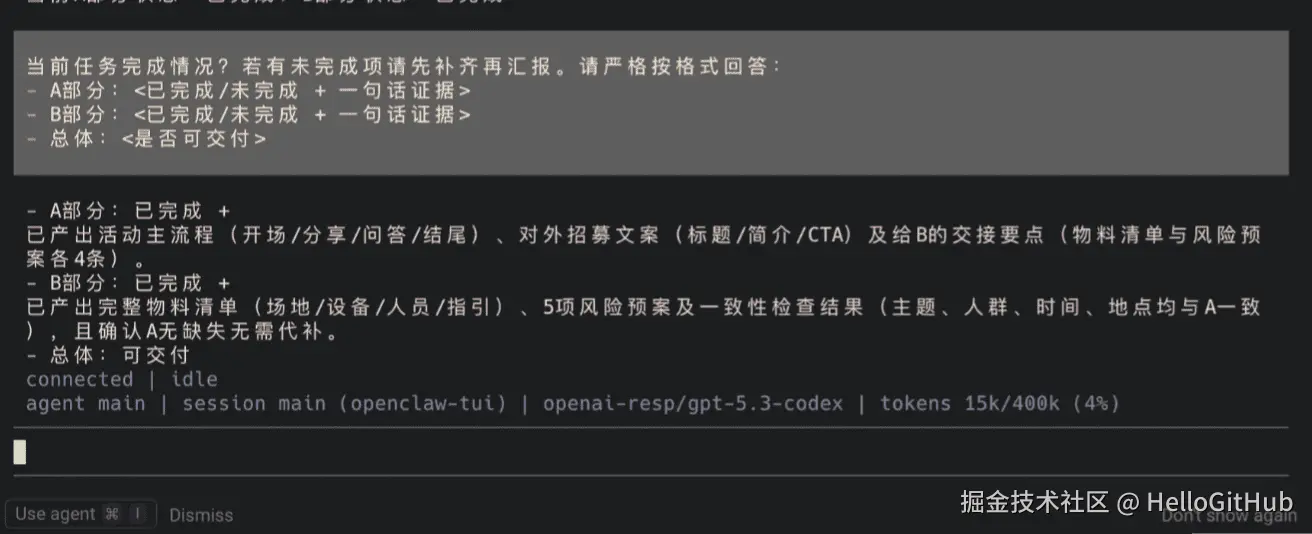
还不错,可以交付了!
四、技术原理:MemOS 如何实现跨龙虾共享?
整体两个 OpenClaw 的协作过程很顺畅,安装配置简单,而且背后的技术原理也不难理解。核心就是下面三点:
- 记忆隔离机制
- 召回机制
- 写回机制
记忆隔离机制
MemOS 通过 user_id 区分不同的记忆空间。可以简单理解为:
ini
user_id="openclaw-user"(默认配置)
├─ OpenClaw A 的对话记录和输出
├─ OpenClaw B 的对话记录和输出
└─ 所有共享的上下文两个 OpenClaw 用同一个 user_id,就能访问同一个共享记忆池。
召回机制
OpenClaw B 启动后,MemOS 就会开始默默工作。它会分析用户的问题意图,然后去共享记忆池里找。等它把 OpenClaw A 之前产出的那份方案扒出来后,会先做个精简,然后将这些记忆直接"喂"给 B 当作背景知识(上下文)。这样一来,B 就不再是每次都失忆的状态,而是基于 A 的工作成果继续干。
这个过程实现了完全自动,不再需要人工干预或复制粘贴。
写回机制
OpenClaw A 和 B 的产出都会自动写回 MemOS,同时,根据 MemOS 官方文档说明:不需要手动保存、不需要指定存储格式自动分类和索引且支持后续检索。
这就是为什么 B 能读到 A 的产出------因为 A 的每次对话都自动存进了 MemOS 的记忆池。
五、最后
在跑通了两个 OpenClaw 自动协作后,我开始思考这套方案适合什么场景、有什么局限。
从 OpenClaw 爆火后,可以看到一个趋势,就是未来更多的场景会变成了多个智能体/AI 协同,如何管理让它们更好地高效协作成为了这个阶段大家探讨最多的问题。
我看到的很多场景都已经开始涌现了对应的需求:
- 多个 🦞 协作:创意 + 执行、前端 + 后端、技术 + 运营,需要分工但又要信息同步的场景。
- 异步工作流:A 今天产出方案,B 明天接力执行。不需要同时在线,记忆会持久化保存。
- 多人项目 :我的 OpenClaw 负责一部分,同事的 OpenClaw 负责另一部分,通过同一个
user_id共享上下文。
结合这些场景,再看基于 MemOS 的方案,还是有一些改进空间:
- 同一个账号(user_id):目前不支持更灵活的权限控制,比如 A 可以读 B 的输出,但 B 不能修改 A 的记忆。
- 记忆检索精度:B 能否准确读到 A 的产出,取决于 MemOS 的检索算法。我测试下来准确率还不错,但复杂场景可能需要调整检索参数。
- 复用模板:支持将好用的案例提取成可复用的模板或 Skills,新项目自动继承最佳实践。
写了这么多,也不知道 MemOS 官方能不能看到我提出的改进点😅。
但总体来说这套基于 MemOS 的方案还是值得一试!部署简单几个命令就能跑起来,让多个 OpenClaw 相互协作 24/7 搞事儿。
虽说还有提升空间但也算是一套快速极简的 OpenClaw 协作方案,我觉得还挺有意思的。
- MemOS 官网:memos.openmem.net
- GitHub:github.com/MemTensor/M...
- MemOS 插件:github.com/MemTensor/M...
- OpenClaw 文档:docs.openclaw.ai
最后,开启春节假期模式,让 OpenClaw 帮你干活吧!