Anthropic发布了Claude Opus 4.6新版本,官方定位为"最智能的模型",主打复杂智能体任务和长时程工作。相比此前的Claude Opus 4.5版本,新版本在架构上进行了多项升级,包括首次在Opus级别支持100万token上下文窗口、引入自适应思考(adaptive thinking)机制等。
我们对这两个版本进行了全面的对比评测,测试其在准确率、响应时间、token消耗和成本等关键指标上的表现差异。需要特别说明的是,本次评测主要聚焦于中文语境下的场景,官方所强调的复杂智能体任务、长时程编程工作、跨百万token上下文处理等核心优势,在当前评测框架下尚未得到充分体现。
Claude Opus 4.6版本表现:
- 测试题数:约1.5万
- 总分(准确率):70.5%
- 平均耗时(每次调用):15s
- 平均token(每次调用消耗的token):794
- 平均花费(每千次调用的人民币花费):96.5
1、新旧版本对比
首先对比上个版本(Claude Opus 4.5),数据如下:


*数据来源:ReLE评测github.com/jeinlee1991...
*输出价格单位: 元/百万token
- 整体性能显著提升:新版本准确率从64.9%跃升至70.5%,提升了5.6个百分点,排名从第44位大幅攀升至第11位。
- Agent能力大幅增强:最突出的改进在于"agent与工具调用"能力,从49.1%飙升至69.1%,增幅高达20个百分点,这与官方强调的"智能体任务持续时间更长、规划更周密"的定位高度吻合。
- 推理能力稳步优化:"推理与数学计算能力"从67.9%提升至71.8%(+3.9%),"教育"领域也有所进步,从60.6%升至63.0%(+2.4%)。
- 部分领域轻微回落:值得注意的是,新版本在"医疗与心理健康"(82.8%→81.5%,-1.3%)和"金融"(81.8%→79.0%,-2.8%)两个领域略有下降,表明在整体能力提升过程中存在一定的权衡取舍。
- Token效率大幅优化 :每次调用平均消耗的token从1063降至794,减少约25%,这得益于新版本引入的"自适应思考"机制------模型可以根据任务复杂度自动调节推理深度,在简单问题上避免过度思考。
- 成本明显下降:每千次调用的费用从146.1元降至96.5元,降幅达34%,主要受益于token消耗减少和输出价格小幅下调(178.0元/M→175.0元/M)。
2、对比其他模型
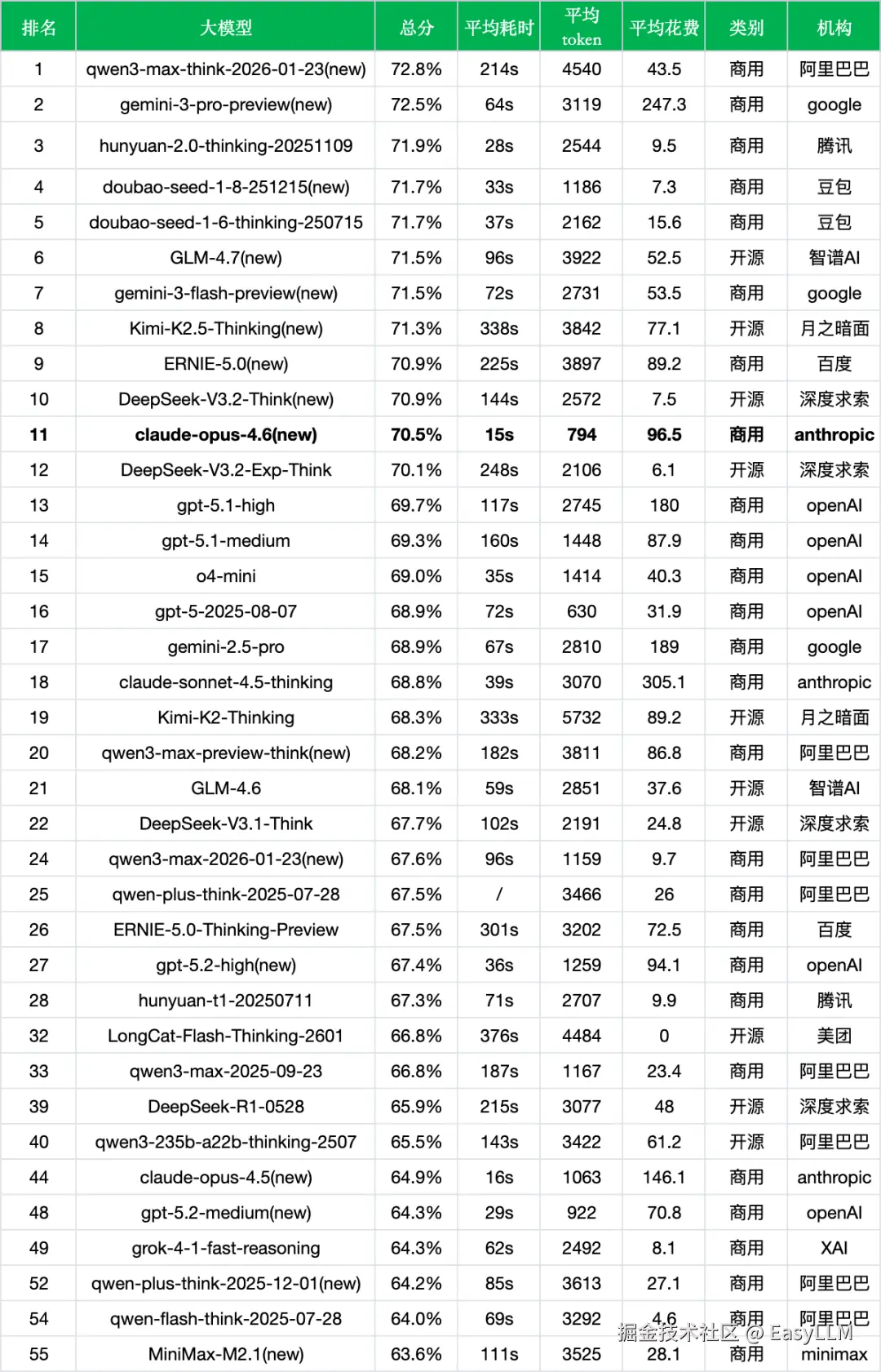
在当前主流大模型竞争格局中,Claude Opus 4.6表现如何?我们从三个维度进行横向对比分析(本评测侧重中文场景,模型在其他语言和专业领域的表现可能有所不同):
*数据来源:ReLE评测github.com/jeinlee1991...
2.1 同成本档位对比
- 成本处于较高区间:96.5元/千次的成本使Claude Opus 4.6位于高端成本档位区间。在相近成本档位中,gpt-5.1-medium(87.9元)以69.3%的准确率与之接近,但Claude Opus 4.6以70.5%的准确率和更快的响应速度(15s vs 160s)占据优势。
- 高成本模型中效率突出:与准确率相近的gemini-3-pro-preview(72.5%,247.3元)相比,Claude Opus 4.6成本更低且响应更快(15s vs 64s)。但与doubao-seed-1-8-251215(71.7%,7.3元)相比,Claude Opus 4.6的成本高出13倍,在追求极致成本效率比的场景下竞争力有限,在资源受限场景下需权衡考量。
2.2 新旧模型对比
- 代际升级成效显著:相比Claude Opus 4.5(64.9%),新版本提升5.6个百分点,属于明显的代际进步。
- 各厂商代际表现分化:Google阵营同样展现出代际优化,gemini-3-pro-preview(72.5%)相比gemini-2.5-pro(68.9%)提升了3.6个百分点;而OpenAI的gpt-5.2-high(67.4%)相比gpt-5.1-high(69.7%)则出现了2.3个百分点的回落,代际升级并非总能带来全面提升。
- Anthropic产品线分化:Claude Opus 4.6(70.5%)定位旗舰,而claude-sonnet-4.5-thinking(68.8%)在本次中文场景评测中准确率略低。
2.3 开源VS闭源对比
- 闭源阵营竞争激烈:在闭源商用模型中,qwen3-max-think-2026-01-23(72.8%)、hunyuan-2.0-thinking-20251109(71.9%)、doubao-seed-1-8-251215(71.7%)均超过Claude Opus 4.6的70.5%,国内厂商在中文场景下展现出强劲竞争力。
- 开源模型表现亮眼:开源阵营中,GLM-4.7(71.5%)、Kimi-K2.5-Thinking(71.3%)、DeepSeek-V3.2-Think(70.9%)等模型准确率与Claude Opus 4.6相当甚至更高,且成本更低(如DeepSeek-V3.2-Think仅7.5元/千次)。
- Claude Opus 4.6的效率优势:相比同档准确率的思考模型,Claude Opus 4.6的核心优势在于响应速度(15s)和token效率(794),远优于DeepSeek-V3.2-Think(144s、2572 token)、Kimi-K2.5-Thinking(338s、3842 token)等,适合对延迟敏感的生产环境。
3、官方评测
根据Anthropic官方发布的信息,Claude Opus 4.6在多个专业评测基准上取得了领先成绩:
3.1 知识工作能力
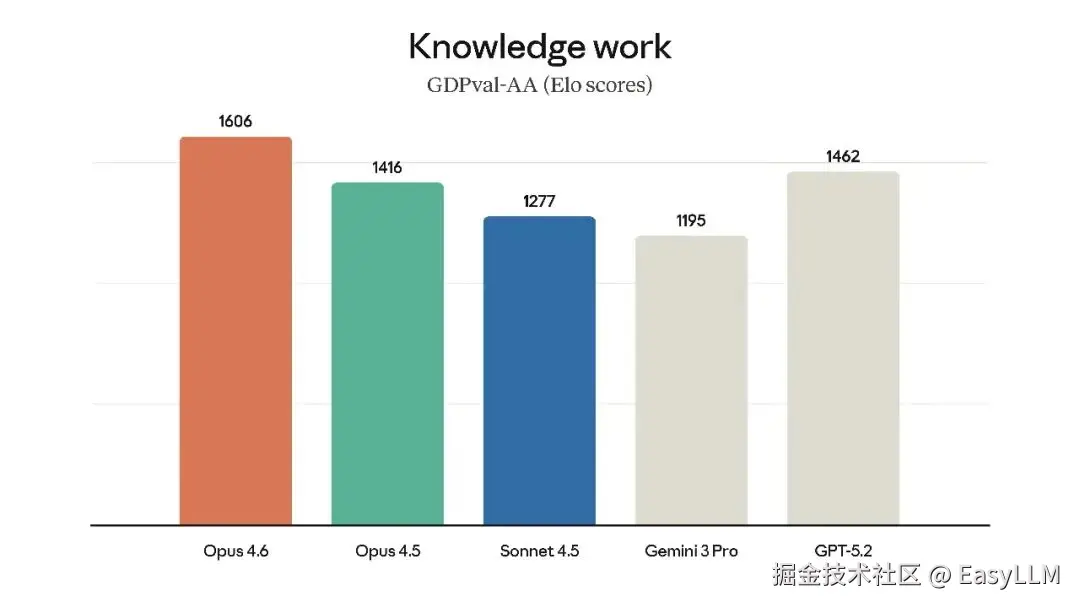
在GDPval-AA评测(由Artificial Analysis独立运行,评估金融、法律等领域的高价值知识工作任务)中,Opus 4.6超越了业界第二名OpenAI的GPT-5.2约144 Elo分,超越其前代产品Claude Opus 4.5达190 Elo分。官方表示,这意味着Claude Opus 4.6在该评测中击败GPT-5.2的概率约为70%。
3.2 智能体编程能力
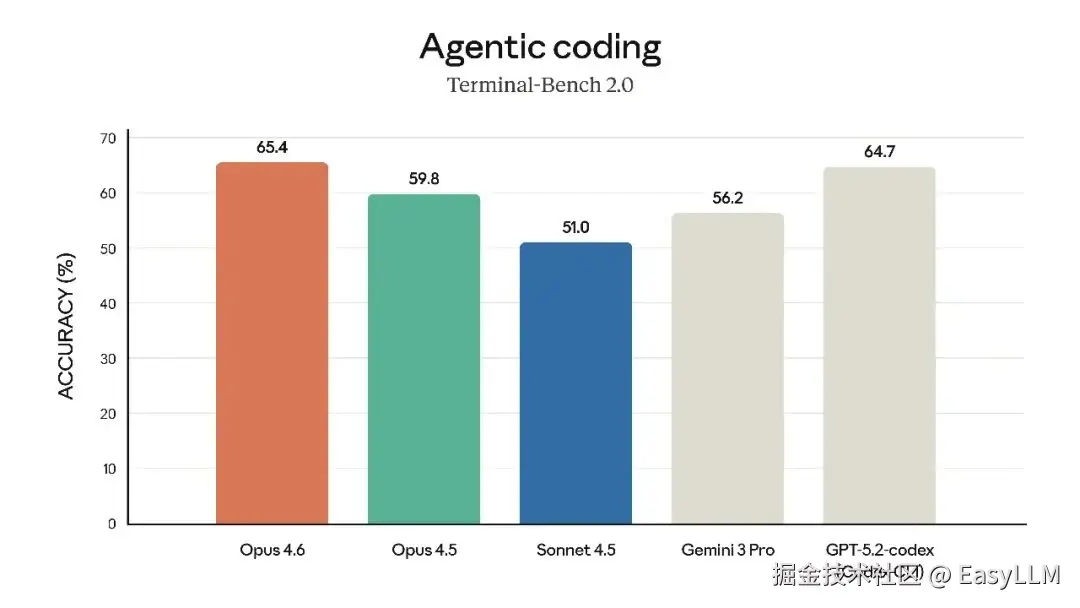
在智能体编程评测Terminal-Bench 2.0上,Opus 4.6取得了业界最高分,展现了在真实世界智能体编程和系统任务上的卓越表现。官方强调,新版本"规划更周密,能够更长时间地持续执行智能体任务,在大型代码库中运行更可靠,并具有更好的代码审查和调试能力来发现自身错误"。
3.3 深度推理能力
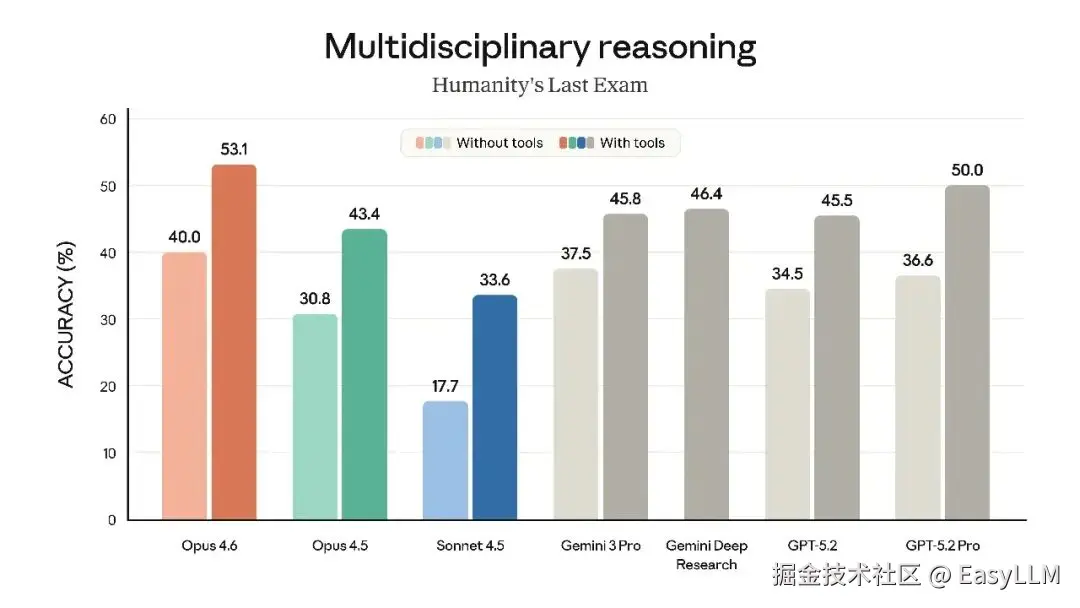

在Humanity's Last Exam(复杂多学科推理测试)中,Opus 4.6领先所有其他前沿模型。在BrowseComp(评估模型定位网络难查信息的能力)上也取得了最佳表现。
3.4 长上下文处理
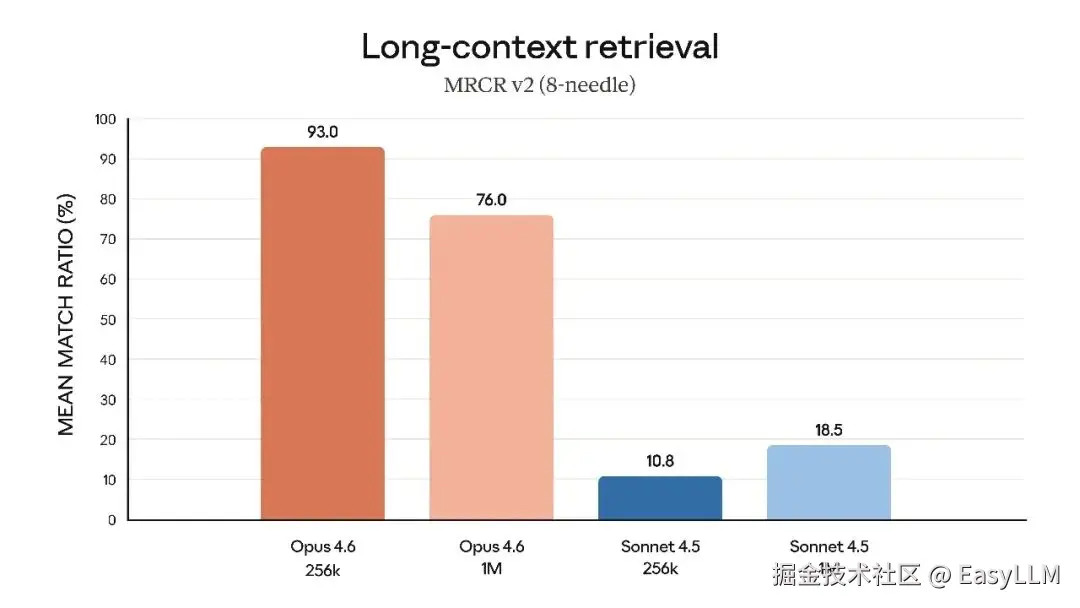
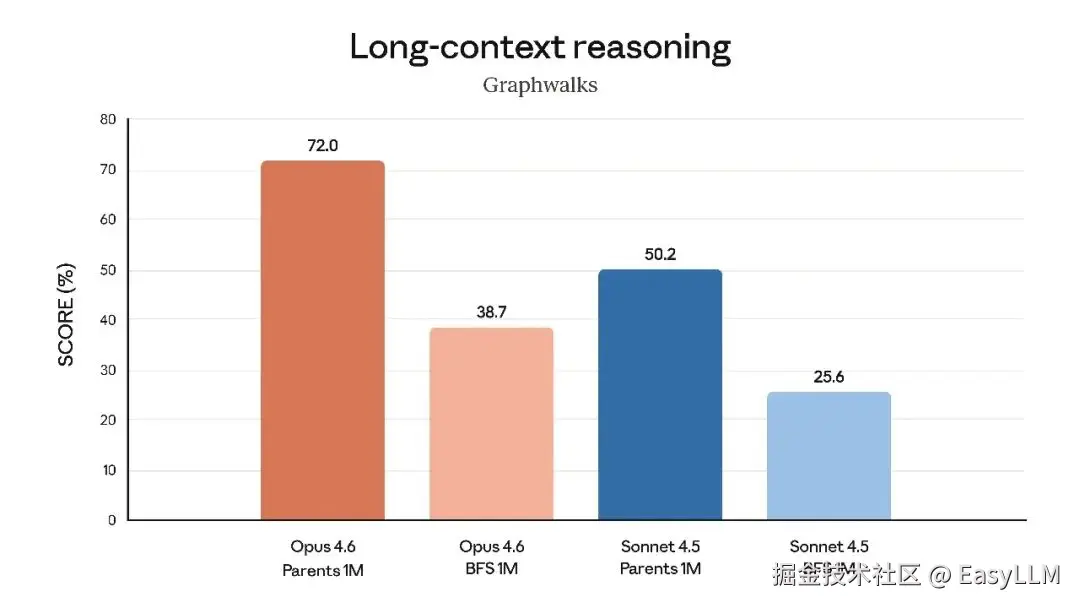
官方特别强调了Opus 4.6在长上下文任务上的突破:在MRCR v2的100万token、8针变体测试中,Opus 4.6得分76%,而Sonnet 4.5仅为18.5%。这代表了"模型在保持峰值性能的同时能实际利用多少上下文的质的飞跃"。
3.5 软件工程与专业领域能力
官方还展示了Claude Opus 4.6在多项专业基准上的表现,涵盖软件工程技能、多语言编程能力、长期连贯性、网络安全能力以及生命科学知识等维度:
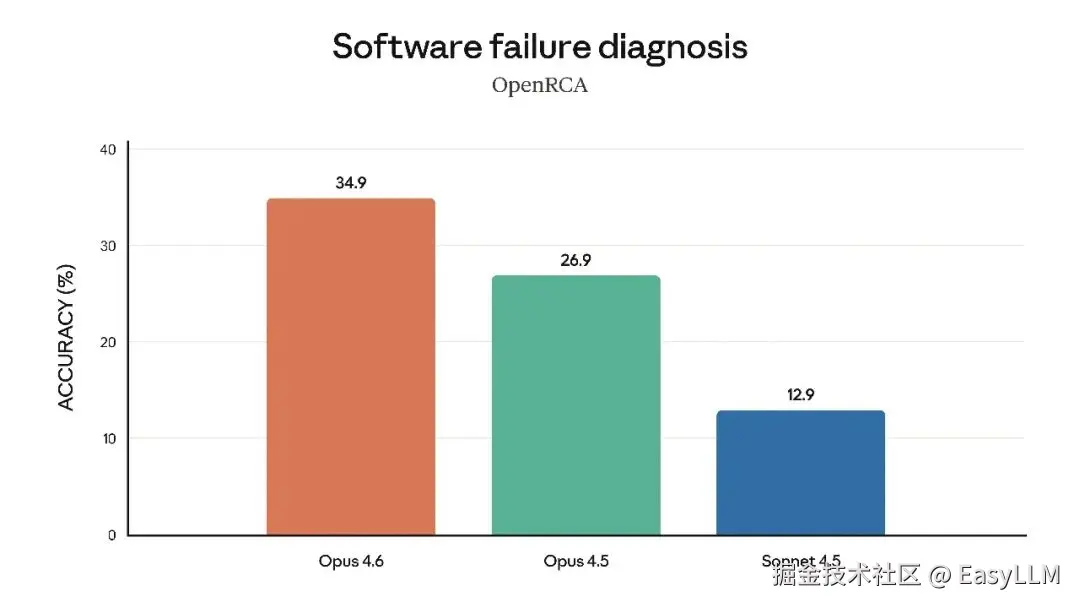
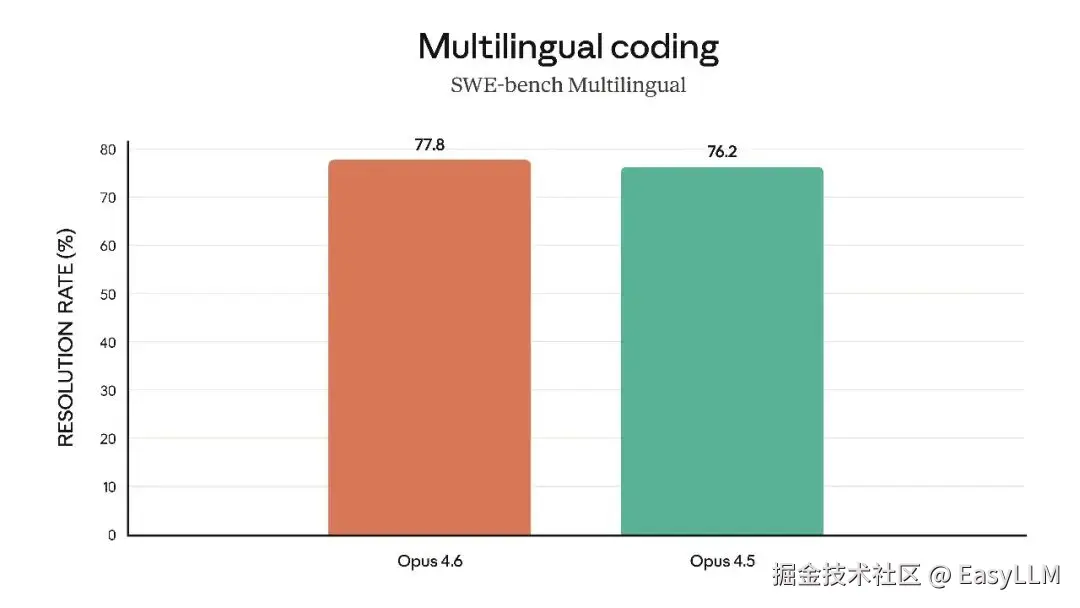
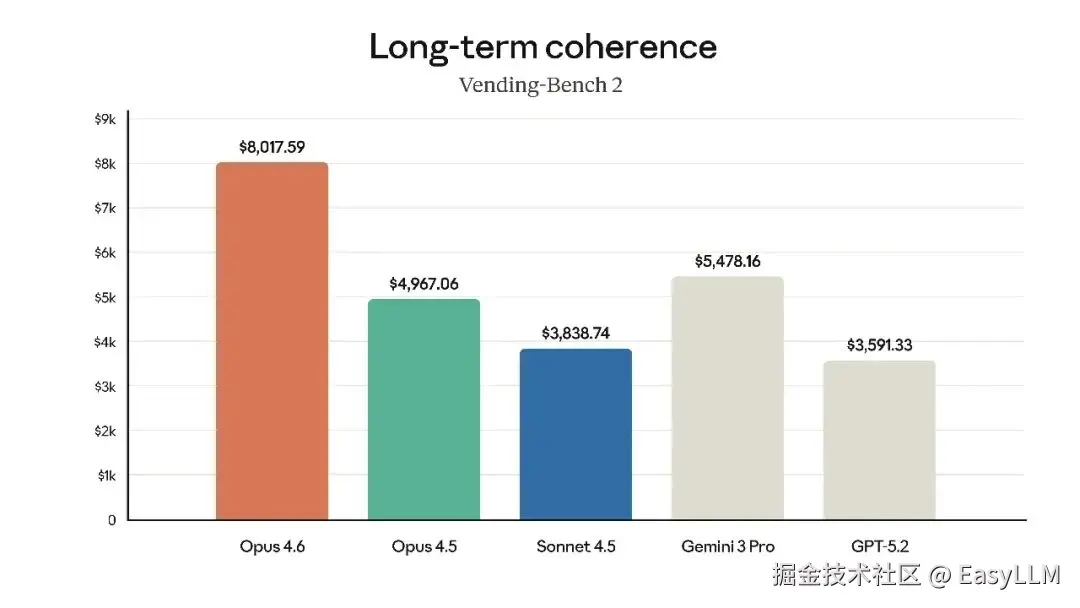
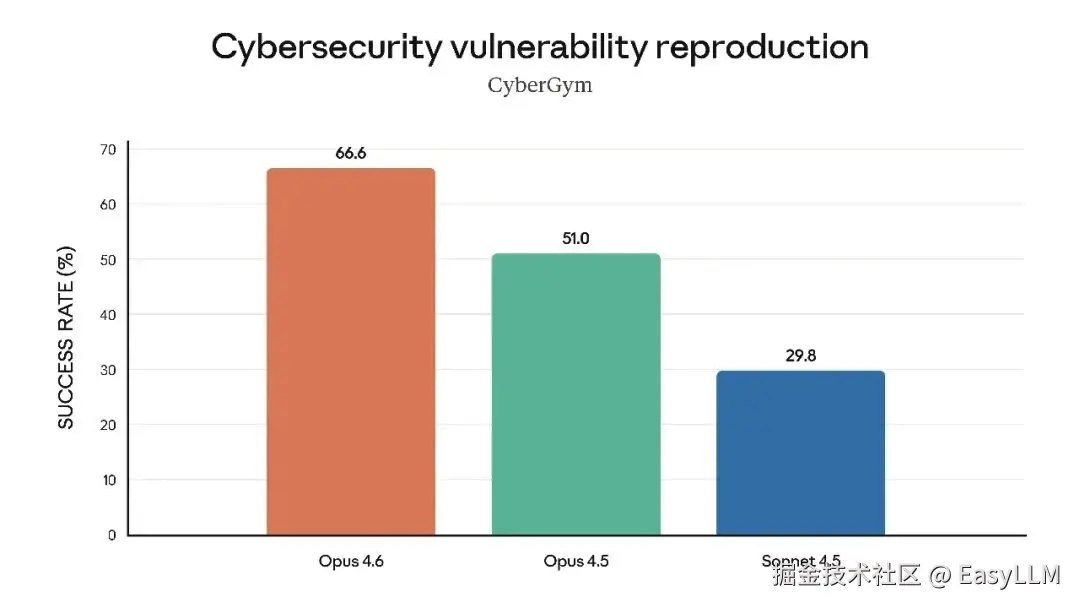
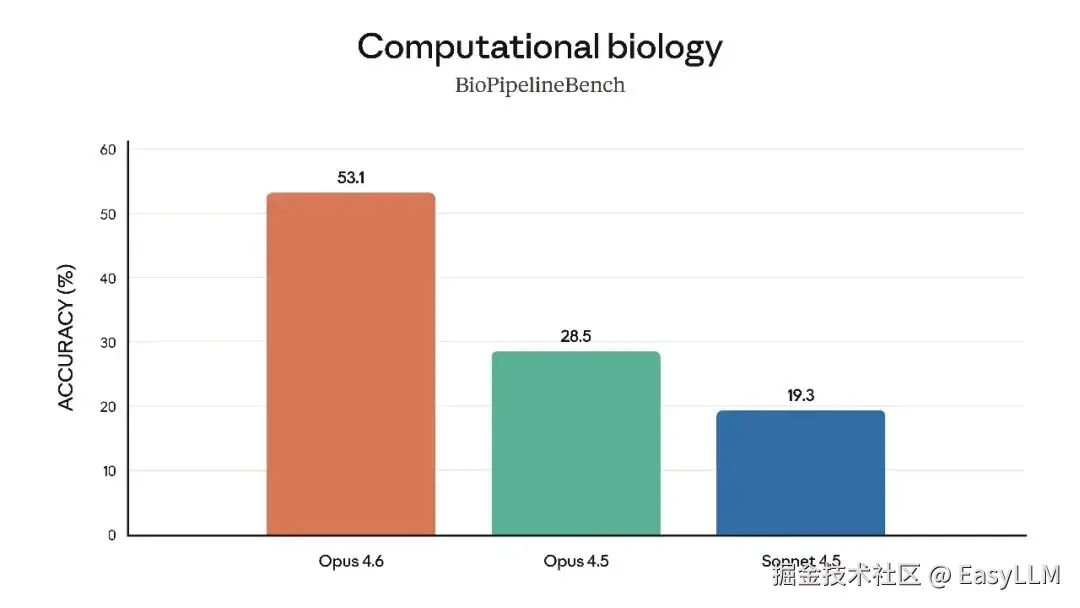
官方表示,在根因分析方面,Opus 4.6擅长诊断复杂软件故障;在多语言编程方面,能够跨编程语言解决软件工程问题;在长期连贯性测试Vending-Bench 2中,Opus 4.6比Opus 4.5多赚取3,050.53美元,展现了长时间保持专注的能力;在网络安全方面,Opus 4.6在代码库中发现真实漏洞的能力优于其他所有模型;在生命科学领域,Opus 4.6在计算生物学、结构生物学、有机化学和系统发育学测试中的表现几乎是Opus 4.5的2倍。
3.6 安全性评估
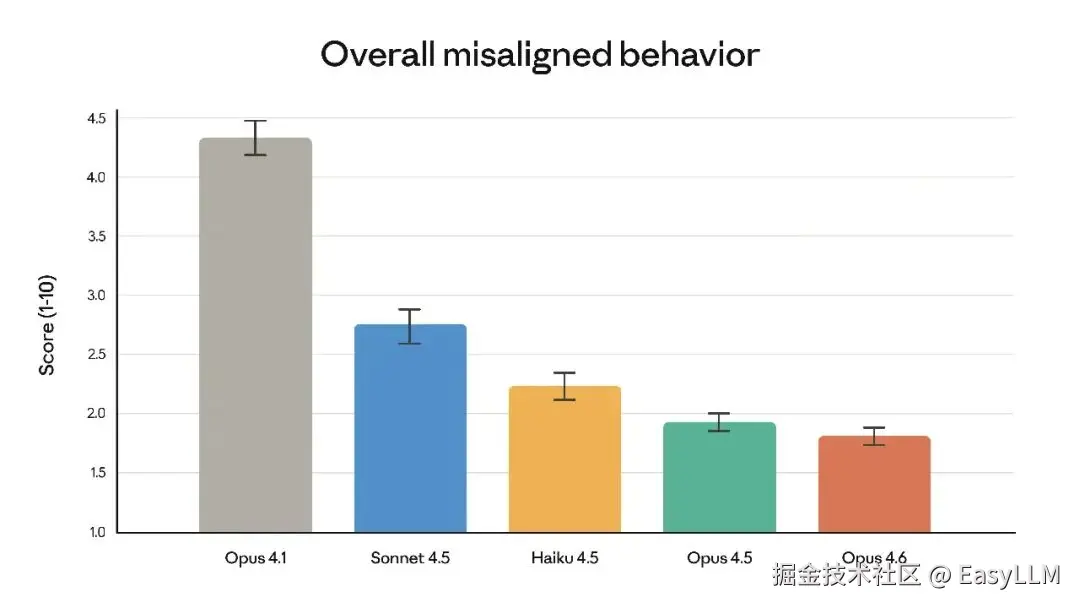
官方系统卡显示,Opus 4.6的整体安全性与此前最对齐的前沿模型Claude Opus 4.5持平或更优,在欺骗、谄媚、助长用户妄想、配合滥用等方面的错误行为率较低。同时,Opus 4.6的过度拒绝率是近期Claude模型中最低的。
目前所有大模型评测文章在公众号:大模型评测及优化NoneLinear