TCP/UDP是传输层协议,本文主要探讨TCP/UDP的核心机制
一、 认识端口
端口号标识了一个主机上进行通信的不同的应用程序
在TCP/IP协议中, 用 "源IP", "源端口号", "目的IP", "目的端⼝号", "协议号" 这样⼀个五元组来标识⼀个通信。
端口号范围划分
0-1023:知名端口号,HTTP,SSH等应用层协议,它们的端口号是固定的
ssh服务器:22端口,ftp:21,telnet:23,http:80,https:443
1024-65535:操作系统动态分配的端口号,客户端程序的端口号,由操作系统从这个范围划分。
进程与端口号绑定问题
1.⼀个进程是否可以 bind 多个端⼝号
这个是可以的
实现原理:在网络编程中,一个端口对应一个"套接字(Socket)"。一个进程可以创建多个套接字,并分别调用 bind() 函数将它们绑定到不同的端口上。
比如:Web 服务器中,同一个进程可能同时监听 80 端口(HTTP)和 443 端口(HTTPS);还有多协议支持,一个进程可能同时绑定 TCP 8888 端口和 UDP 8888 端口。
2.一个端口是否可以被多个进程bind
通常不可以,但在特定条件下可以。
按照传统规则,一个端点(IP + 端口 + 协议)在同一时间内只能被一个进程占用,否则会报 Address already in use 错误。但以下几种情况允许"共享"或"共同绑定":
(1) 使用 SO_REUSEPORT 选项 (现代 Linux 特性)
这是最常见的实现方式。从 Linux 内核 3.9 版本开始,引入了SO_REUSEPORT 选项:
如果多个进程在 bind() 之前都设置了这个选项,它们就可以同时绑定到同一个 IP 和端口。
用途:内核会自动在这些进程之间进行负载均衡(将新连接分发给不同的进程),这常用于高并发服务器(如 Nginx、HAProxy)来提升性能。
(2) 父子进程继承 (Fork)
如果父进程先 bind() 并 listen() 了一个端口,然后调用 fork() 创建子进程,那么子进程会继承父进程的文件描述符。
此时,多个进程实际上在共享同一个监听套接字。
(3) 不同协议 (TCP vs UDP)
端号在 TCP 和 UDP 协议中是独立的命名空间。
进程 A 可以 bind TCP 8080,进程 B 可以同时 bind UDP 8080,两者互不干扰。
(4) 绑定不同的 IP 地址
如果一台机器有多个网卡或 IP 地址,进程 A 可以绑定 127.0.0.1:80,进程 B 可以绑定 192.168.1.10:80。虽然端口号相同,但由于 IP 地址不同,它们并不算冲突。
二、UDP:用户数据报协议
UDP 就像是"寄平信"。你把信投进邮筒,邮局尽力帮你送,但不会给你回执,信丢了也不会重发。
1.UDP报头
UDP 报头极其简单,只有固定的 8 个字节,分为四个字段(每个 2 字节):
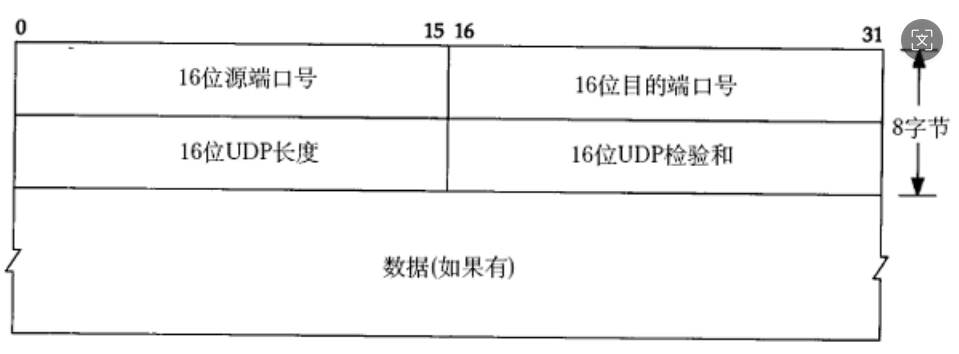
- 源端口号:发送方程序的端口。
- 目的端口号:接收方程序的端口。
- 长度:整个 UDP 报文的长度(报头 + 数据)
- 校验和:检测报文在传输过程中是否出错(若出错直接丢弃)
2.UDP传输特点
- 无连接:不需要握手,想发就发。
- 不可靠:不保证到达,不保证顺序,没有确认机制
- 面向报文:应用层给 UDP 多长,UDP 就发多长,不会拆分也不会合并。
- 速度快:没有握手开销和复杂的控制逻辑,适合实时音视频、在线游戏、DNS查询
三、TCP:传输控制协议
TCP 就像是"打电话"。通话前要先拨号建立连接,通话中你会不断确认"听清了吗",如果没听清对方会重讲
1.TCP报头
TCP 报头较复杂,基础长度为 20 字节(含选项时更长):
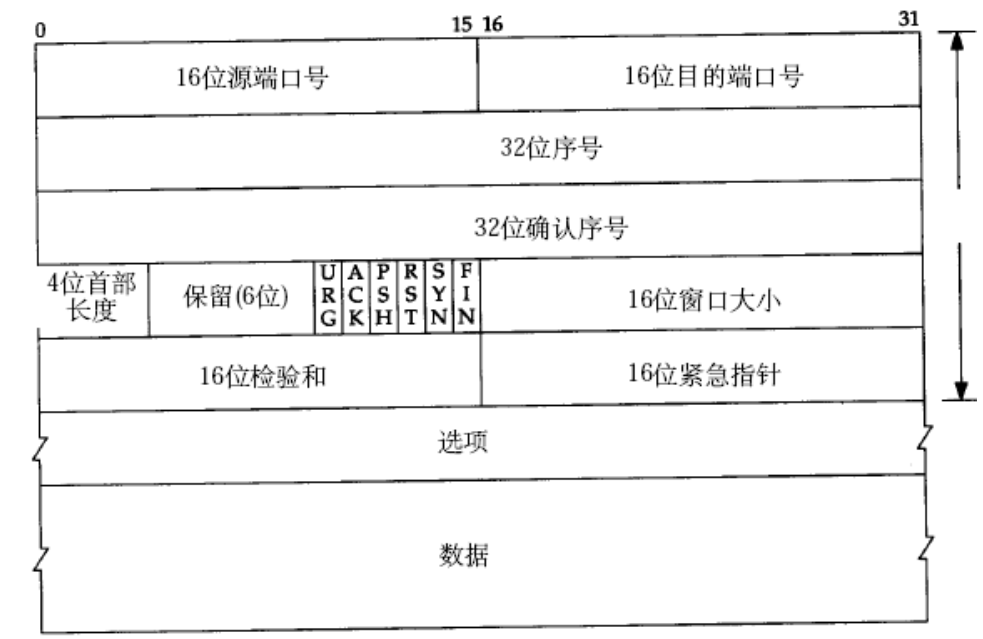
-
源/目的端口号: 表示数据是从哪个进程来, 到哪个进程去
-
序号 (Sequence Number):本段数据的第一个字节的编号(用于重组乱序包)
-
确认号 (Acknowledgment Number):期望收到的下一个字节的编号(用于确认应答)
-
标志位 (Flags): SYN (请求建立连接; 我们把携带SYN标识的称为同步报文段)、ACK (确认号是否有效)、FIN (释放连接) 、URG (紧急指针是否有效)、PSH ( 提示接收端应用程序立刻从TCP缓冲区把数据读走)、RST( 对方要求重新建立连接; 我们把携带RST标识的称为复位报文段)
-
窗口 (Window):告知对方,我现在的缓冲区还能收多少数据(用于流量控制)
-
16位校验和: 发送端填充, CRC校验. 接收端校验不通过, 则认为数据有问题. 此处的检验和不光包含TCP首部, 也包含TCP数据部分.
-
16位紧急指针: 标识哪部分数据是紧急数据
2.TCP连接基本机制
2.1 确认应答
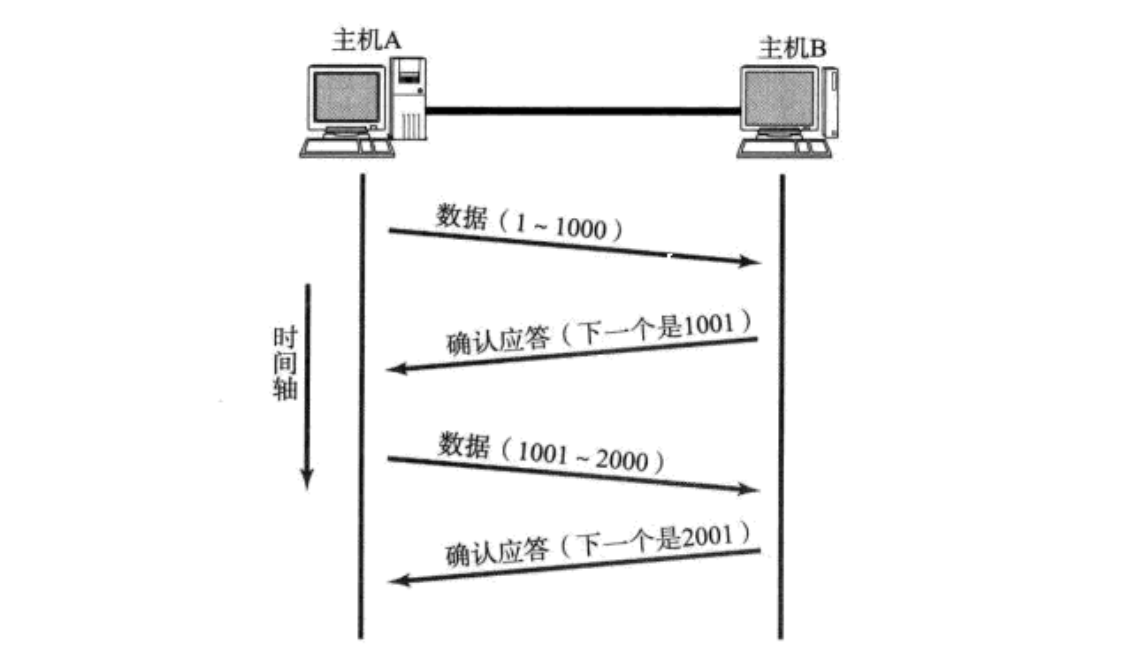
接收方每收到一段数据,就给发送方发一个 ACK,告诉它"我收到了",并告诉他下次你得给我从哪传
2.2序列号排序
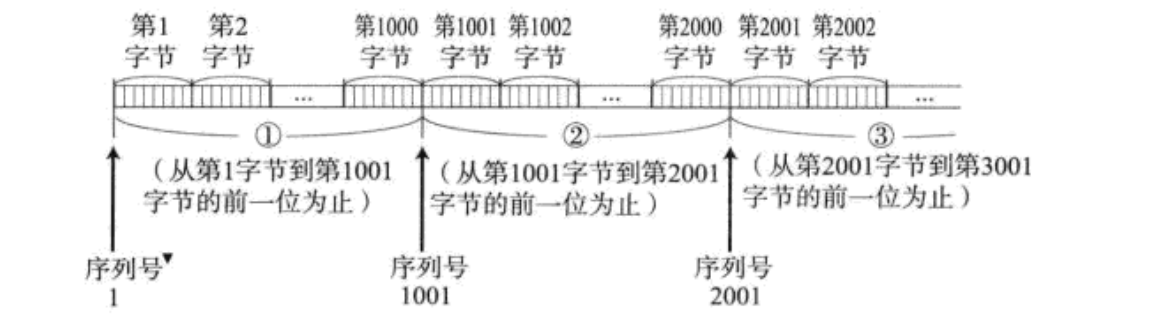
TCP将每个字节的数据都进行了编号. 即为序列号.
每⼀个ACK都带有对应的确认序列号, 意思是告诉发送者, 我已经收到了哪些数据; 下⼀次你从哪里开始发
网络会导致数据包"先发后到"或"重复",TCP 利用序列号对数据重新排序并去重
2.3超时重传
如果发送方在规定时间内没收到确认,就认为包丢了,会重新发送
3.TCP连接管理:三次握手与四次挥手
握手:建立连接
挥手:断开链接
我们可以将 TCP 通讯想象成两个人在用对讲机进行通话。
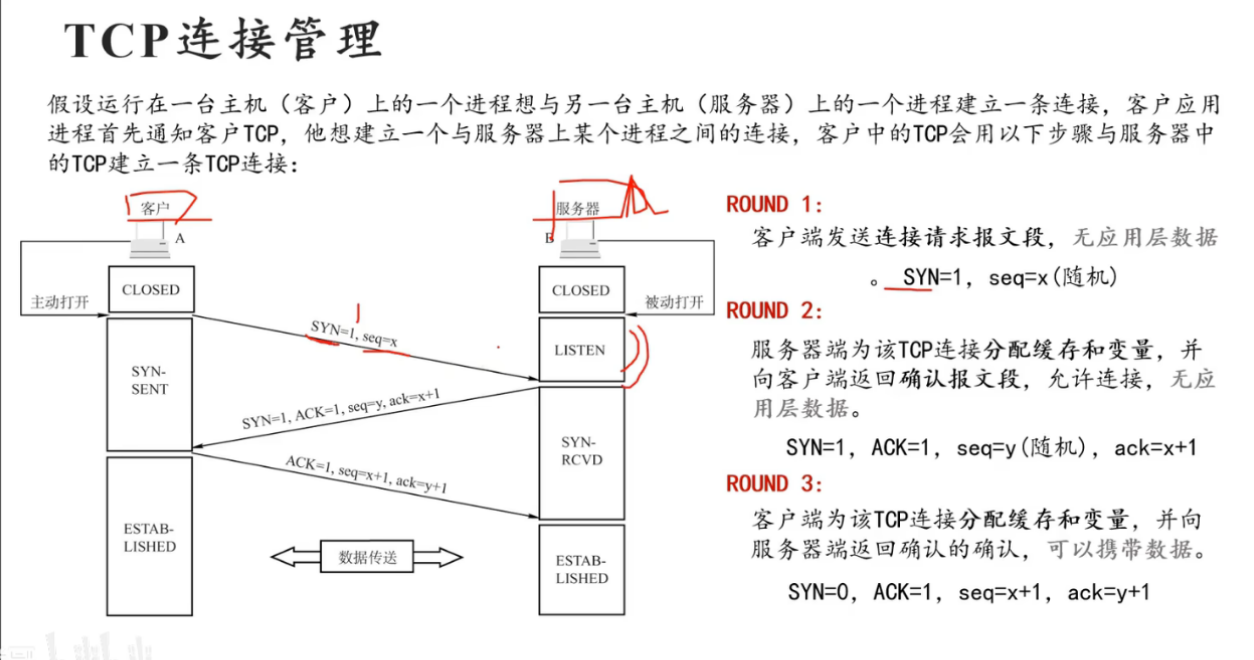
3.1 三次握手(建立连接)
核心目的 :确保双方的发送能力 和接收能力都是正常的。
-
第一次握手(Client -> Server)
- 动作 :客户端发送
SYN包。 - 对话:A 说:"喂,B,你能听到我说话吗?"
- 结论:B 明白 A 的发送能力正常,自己的接收能力正常。
- 动作 :客户端发送
-
第二次握手(Server -> Client)
- 动作 :服务端回复
SYN + ACK包。 - 对话:B 说:"听到了!你能听到我说话吗?"
- 结论:A 明白 B 的发送和接收都正常,A 自己的发送和接收也都正常。
- 此时注意:B 还不敢确定 A 是否听到了自己的回复。
- 动作 :服务端回复
-
第三次握手(Client -> Server)
- 动作 :客户端发送
ACK包。 - 对话:A 说:"我也听到了,咱们开始聊吧!"
- 结论:B 明白 A 的接收能力也是正常的。
- 结果:连接成功建立(Established)。
- 动作 :客户端发送
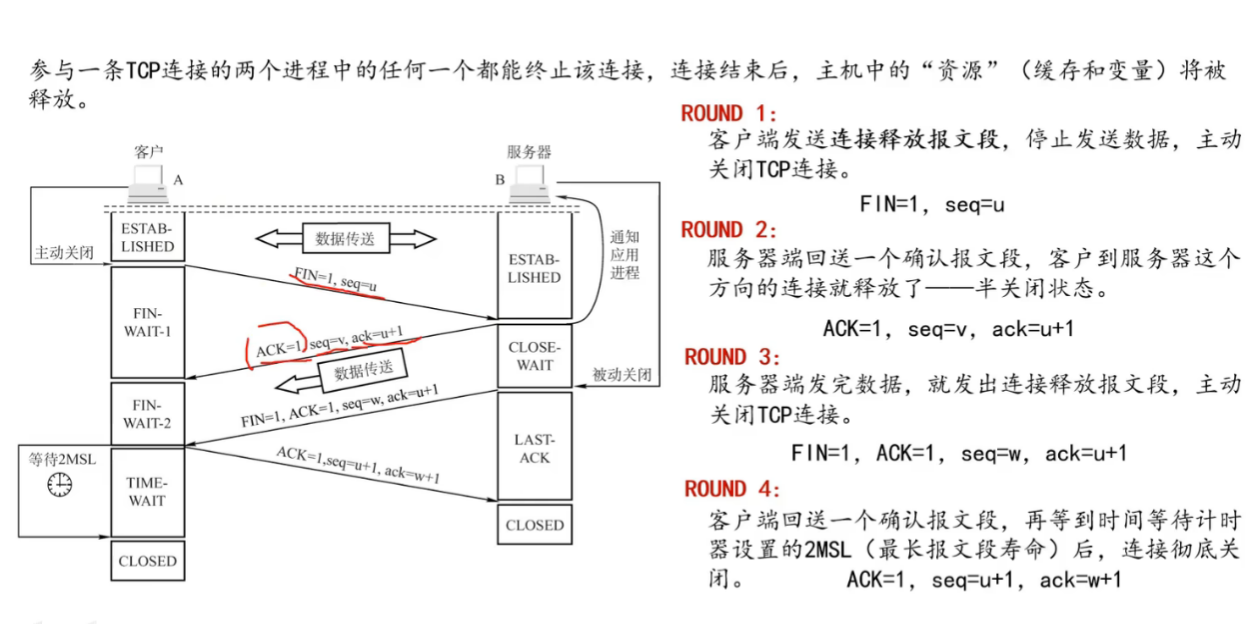
3.2 四次挥手(释放连接)
核心逻辑 :TCP 是双工通信,我没话说了不代表你也没话说了,所以两个方向的通道必须分别关闭。
-
第一次挥手(Client -> Server)
- 动作 :客户端发送
FIN包。 - 对话:A 说:"我的话说完了,我准备挂了。"
- 状态:A 停止发送数据,但仍能接收数据。
- 动作 :客户端发送
-
第二次挥手(Server -> Client)
- 动作 :服务端回复
ACK包。 - 对话:B 说:"收到了,但我这边还有数据没传完,你等我一下。"
- 状态:此时连接处于"半关闭"状态,B 继续发送剩余数据。
- 动作 :服务端回复
-
第三次挥手(Server -> Client)
- 动作 :服务端发送
FIN包。 - 对话:B 说:"好了,我也说完了。我也要挂了,再见!"
- 状态:B 停止发送数据,等待 A 的最后确认。
- 动作 :服务端发送
-
第四次挥手(Client -> Server)
- 动作 :客户端发送
ACK包。 - 对话:A 说:"收到,再见!"
- 状态:A 会原地等待一会儿(TIME_WAIT),确保 B 收到消息。B 收到后直接断开,A 等待结束后也彻底断开。
- 动作 :客户端发送
3.3 关键问答
1. 为什么不能是"两次握手"?
- 防止失效的连接请求突然到达。
- 如果 A 发出的第一个请求在网络中"堵车"了,A 又发了第二个请求并完成通话。
- 当 A 挂断后,第一个请求才到达 B,B 回复后如果直接建立连接,B 就会一直空等 A 发送数据,造成资源浪费。
- 三次握手下,由于 A 不会给那个过期的请求发 ACK,B 没收到确认就不会开启连接。
2. 为什么挥手要"四次"而不是"三次"?
- 因为 B 被告知断开时,可能还有数据在处理中。
- 当 B 收到 A 的
FIN时,它只能先回一个ACK表示收到了请求。 - B 必须等待自己的数据全部发送完毕后,才能发
FIN。 - 中间的两步(ACK 和 FIN)通常不能合并,因为发送 FIN 取决于 B 的数据是否传完。
3. 为什么 A 最后要等 2MSL(TIME_WAIT)?
- 确保 B 收到最后一次 ACK。
- 如果 A 发的 ACK 丢了,B 会重发第三次挥手的
FIN。 - 如果 A 立刻消失,B 就永远收不到最后的确认,无法正常进入关闭状态。
4.滑动窗口(TCP性能提升)
如果在TCP协议下这样传数据,性能会很差,你传一个就得等半天
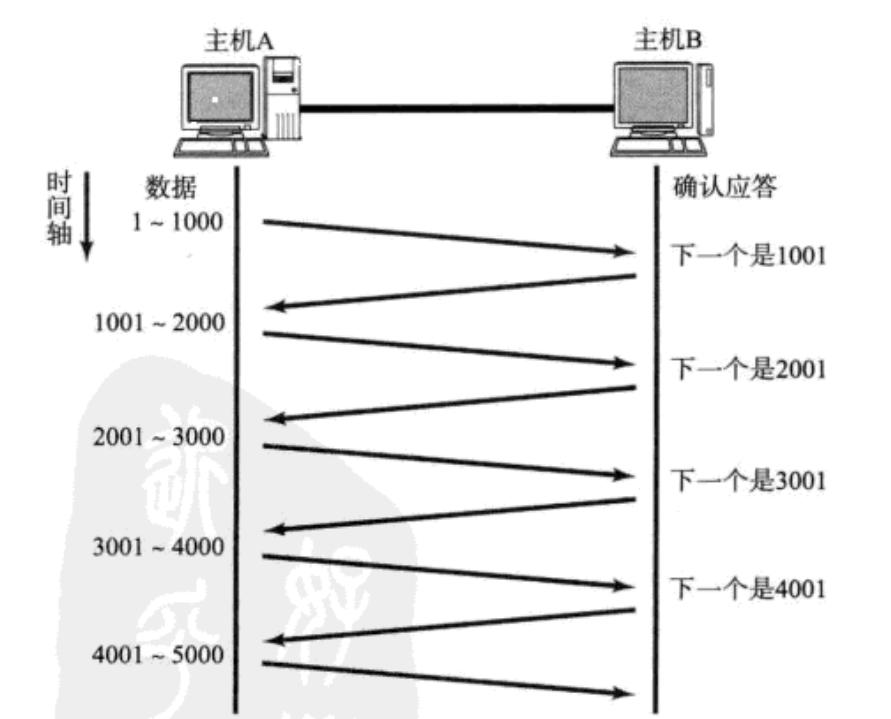
所以为了提升性能,我们一次发生多条数据那不就行了
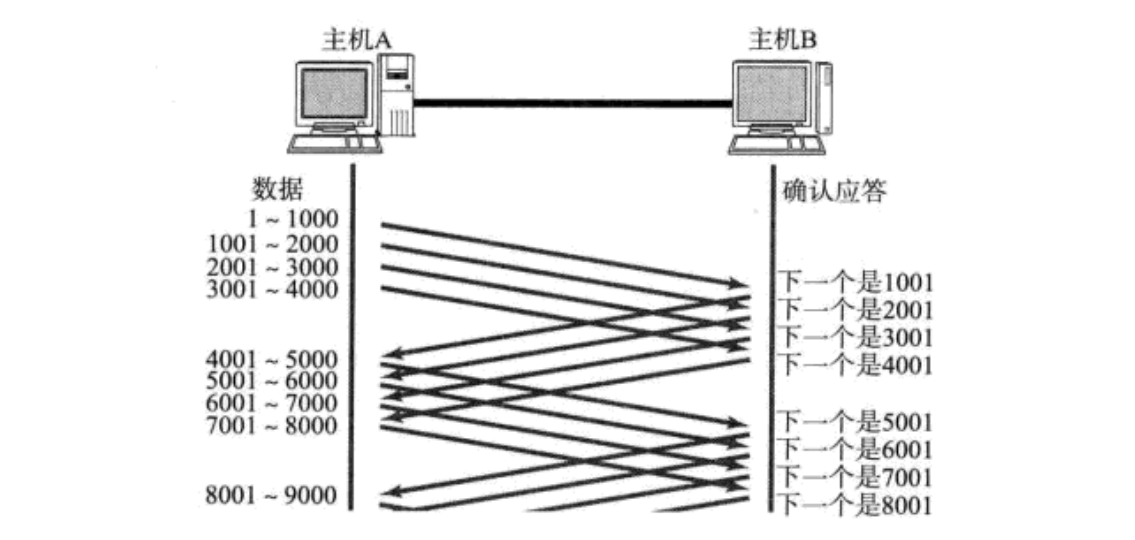
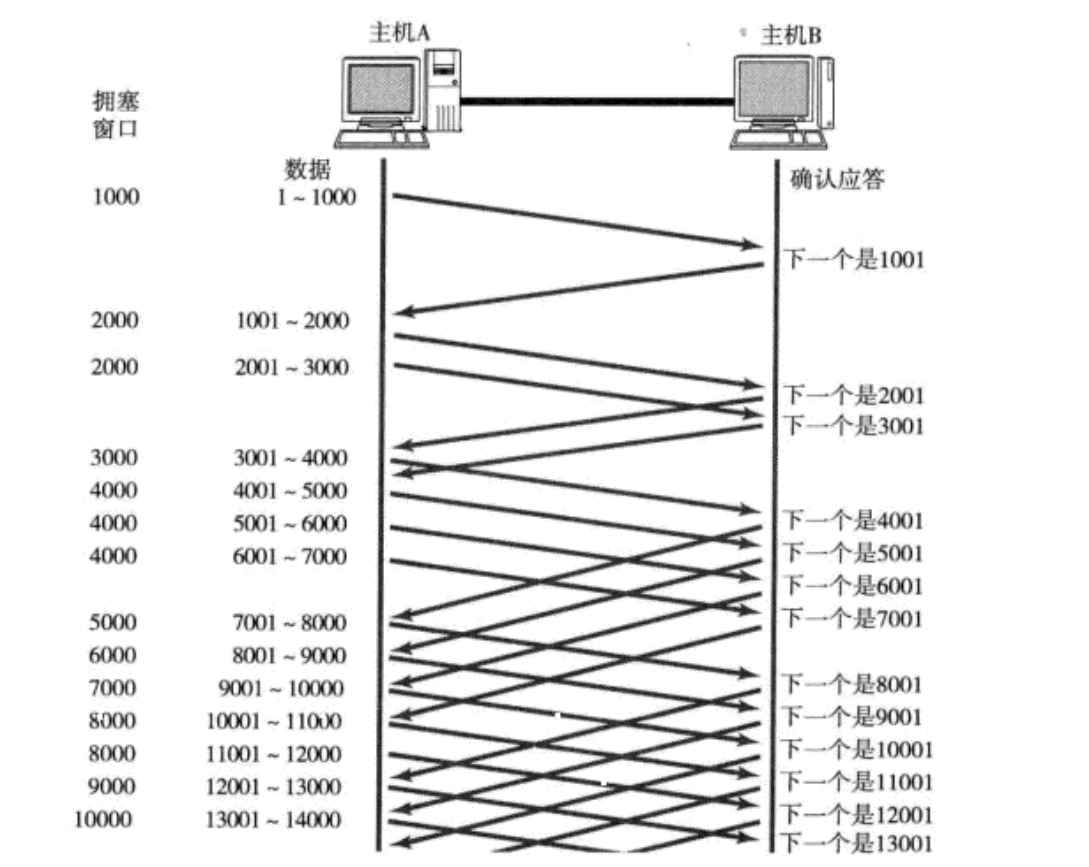
窗口大小指的是无需等待确认应答而可以继续发送数据的最大值。上图的窗口大小就是4000个字节(四个段)。
• 发送前四个段的时候,不需要等待任何ACK,直接发送;
• 收到第一个ACK后,滑动窗口向后移动,继续发送第五个段的数据;依次类推;
• 操作系统内核为了维护这个滑动窗口,需要开辟发送缓冲区来记录当前还有哪些数据没有应答;只有确认应答过的数据,才能从缓冲区删掉;
• 窗口越大,则网络的吞吐率就越高。
4.1滑动窗口丢包问题
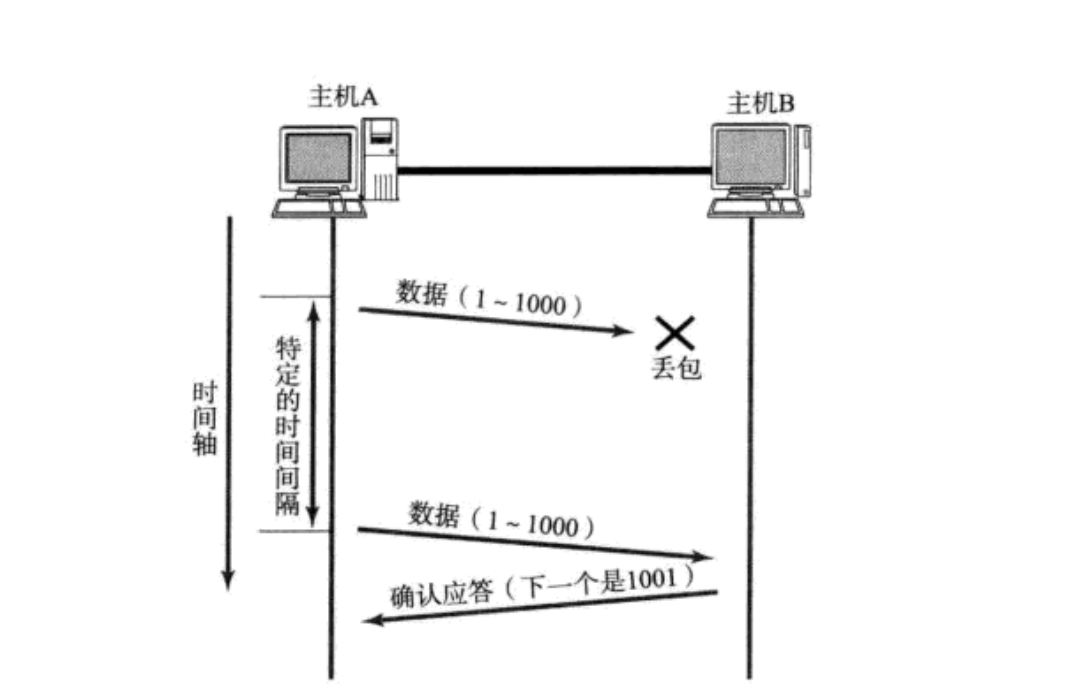
4.1.1数据包已经抵达, ACK被丢了
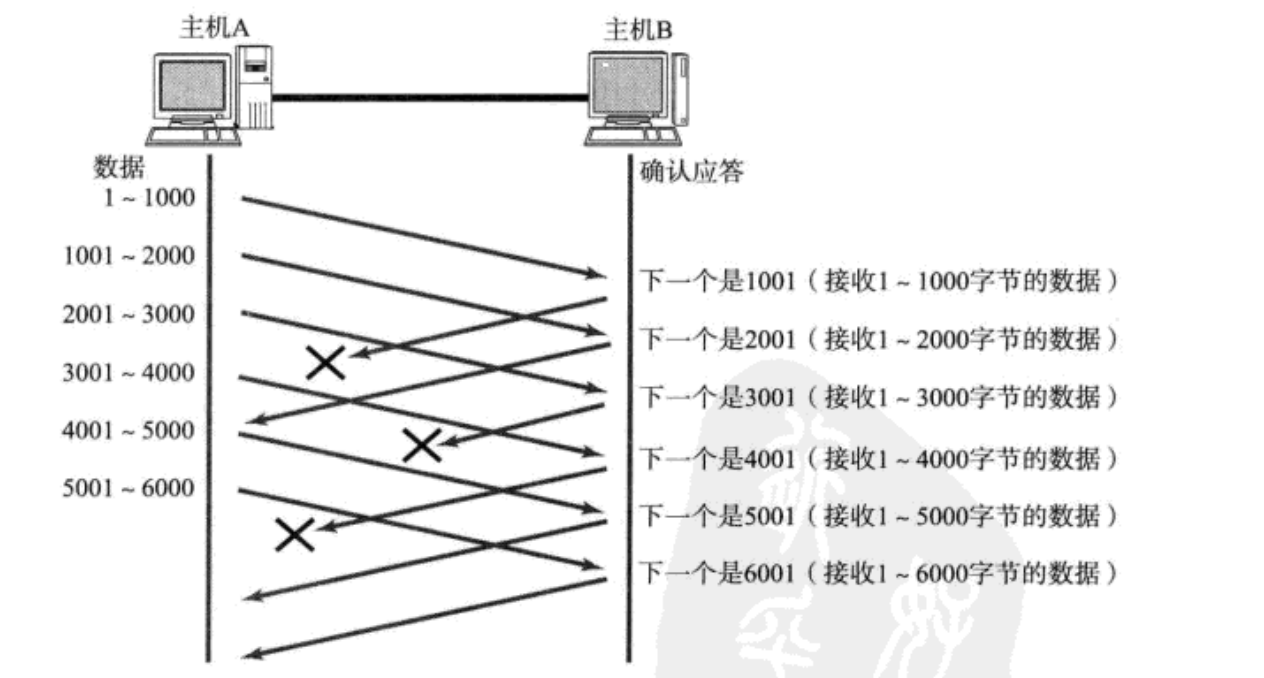
这时候通过后面的ACK判断就行了
4.1.2数据包丢了
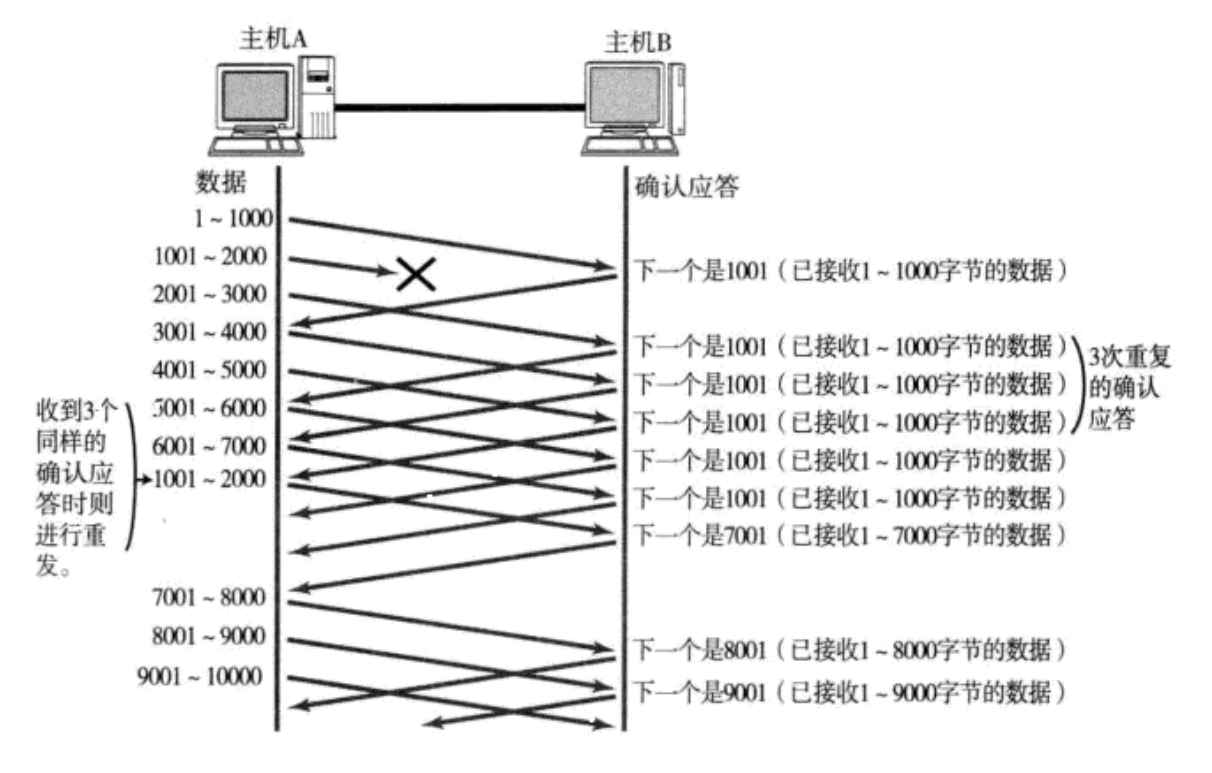
这时候必须等待发送端再次发送1001数据包,然后就能把剩下的全处理了(因为被放在缓存区中)
4.2流量控制
我接受方处理能力有限,如果你发送方发太快那我不是处理不过来吗,那不肯定又是丢包又是重传的老麻烦了。
因此TCP支持根据接收端的处理能力, 来决定发送端的发送速度. 这个机制就叫做流量控制(Flow
Control):
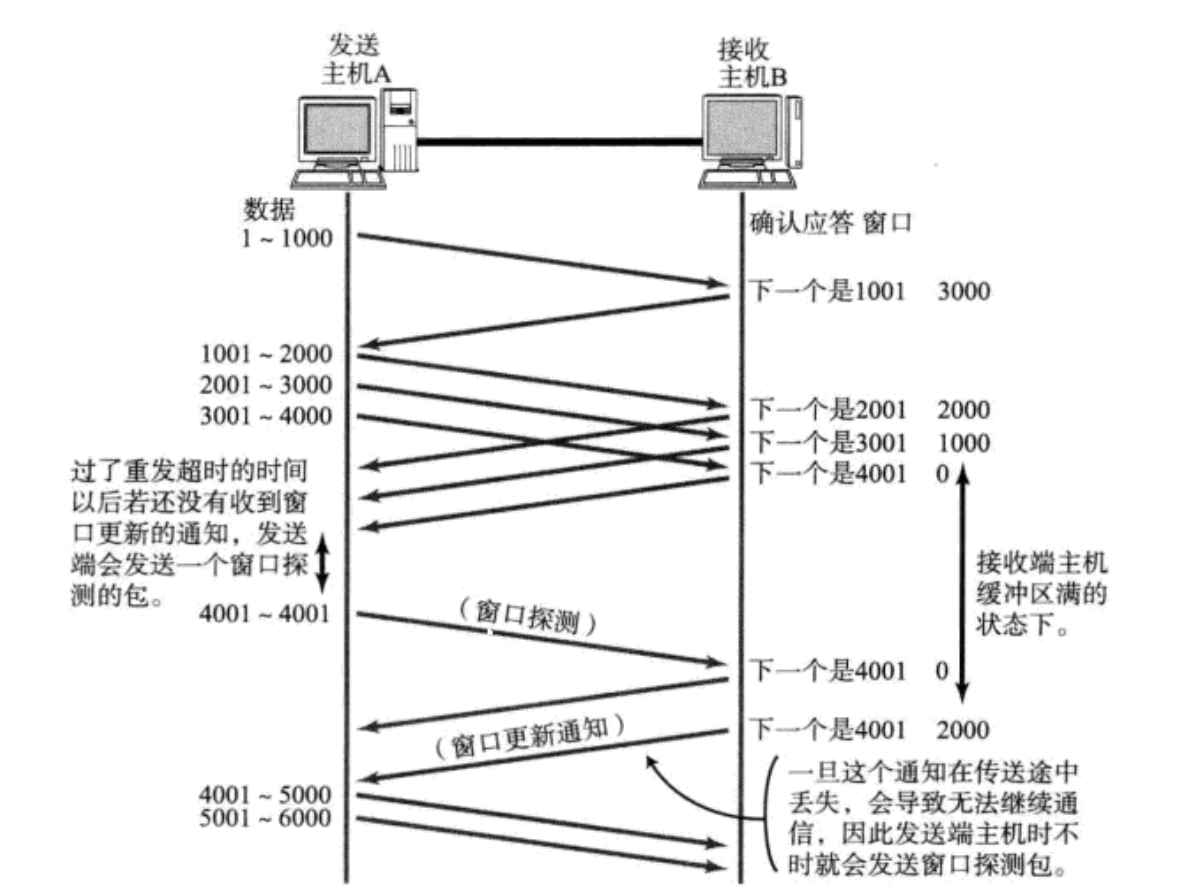
接收端将自己可以接收的缓冲区大小放入 TCP 首部的"窗口大小"字段,通过 ACK 端通知发送端。
-
窗口大小字段越大,说明网络的吞吐量越高;
-
接收端一旦发现自己的缓冲区快满了,就会将窗口大小设置成一个更小的值通知给发送端;
-
发送端接收到这个窗口后,就会减慢自己的发送速度;
-
如果接收端缓冲区满了,就会将窗口置为 0;这时发送方不再发送数据,但是需要定期发送一个窗口探测数据段,使接收端把窗口大小告诉发送端。
4.3拥塞控制
拥塞控制解决的是发送端一开始发送太快的问题,你虽然有流量控制了,但你一开始传一堆不还是轧钢吗?
所以TCP引入慢启动 机制, 先发少量的数据, 探探路, 摸清当前的网络拥堵状态, 再决定按照多大的速度传输数据;
拥塞控制是发送方根据"网络拥挤程度"来决定发多少数据。它引入了一个核心变量:拥塞窗口 (CWND, Congestion Window) 。
发送方的实际发送上限 = Min(RWND, CWND)
拥塞控制的四个阶段:
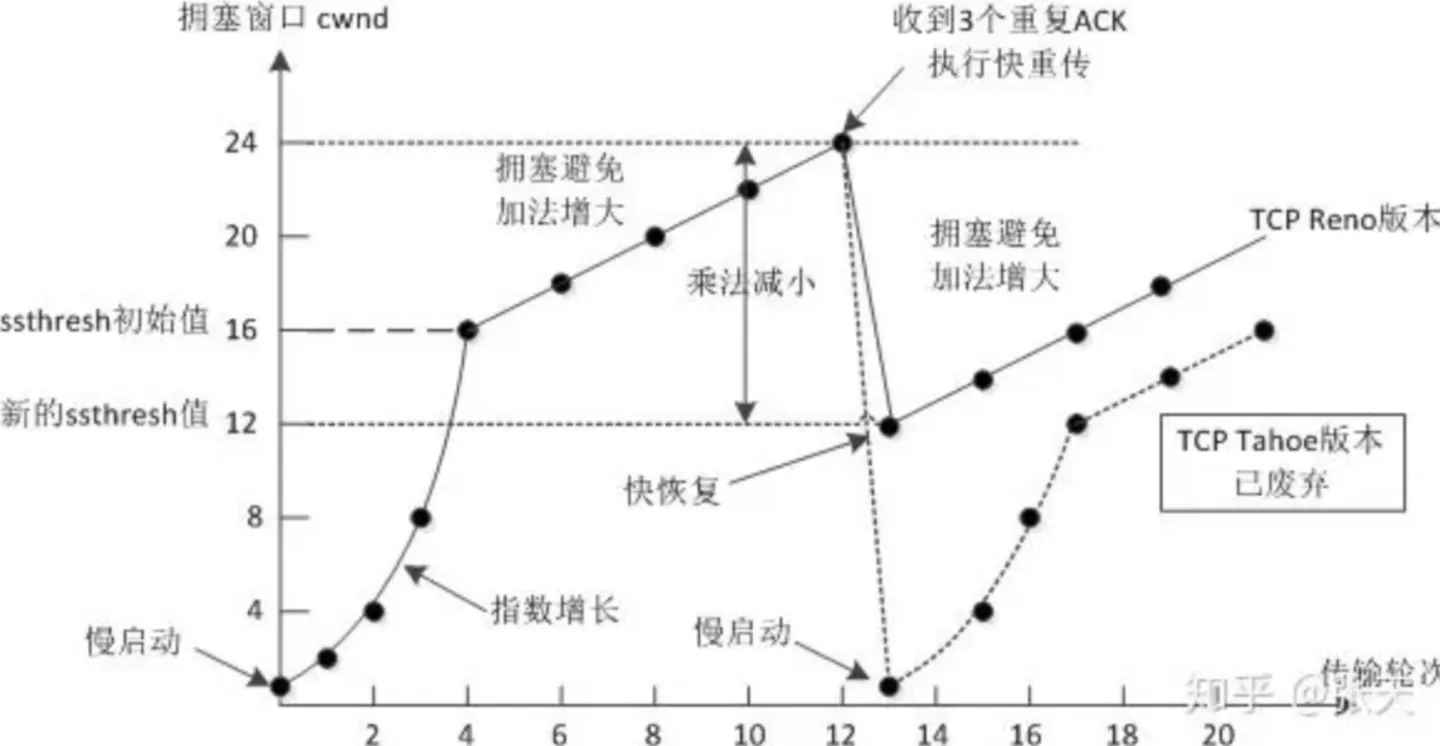
1. 慢启动 (Slow Start)
- 策略:刚开始发数据时,不清楚网络状况,从小到大指数级增长。
- 过程:收到 1 个 ACK,CWND 加 1。实际上每过一个往返时间(RTT),CWND 翻倍(1 -> 2 -> 4 -> 8...)。
- 目的:快速探测网络的承载能力。
2. 拥塞避免 (Congestion Avoidance)
- 触发点:当 CWND 达到一个阈值(ssthresh,慢启动门限)时。
- 策略:从"指数增长"变为"线性增长"。
- 过程:每过一个 RTT,CWND 只加 1。
- 目的:在接近网络容量上限时,小心翼翼地试探,防止突然拥堵。
3. 拥塞发生时的处理(快重传与快恢复)
当网络真的出现丢包时,有两种触发逻辑:
-
情况 A:超时重传(最严重)
- 网络已经非常拥堵了。
- 动作:ssthresh 砍半,CWND 直接降为 1,重新进入"慢启动"。
-
情况 B:快重传(Fast Retransmit)
- 接收方发现少了一个包,连续发 3 个同样的 ACK 告诉发送方。
- 动作:发送方立即重传丢失的包,不需要等定时器超时。
- 进入快恢复 (Fast Recovery):ssthresh 砍半,CWND 设为砍半后的值(而不是降为 1),直接进入"拥塞避免"阶段。
5.TCP 性能优化(延迟应答与捎带应答)
为了减少网络中"纯确认包(ACK)"的数量并提高带宽利用率,TCP 设计了延迟应答和捎带应答机制。
5.1 延迟应答 (Delayed Acknowledgment) ------ "等一等再回话"
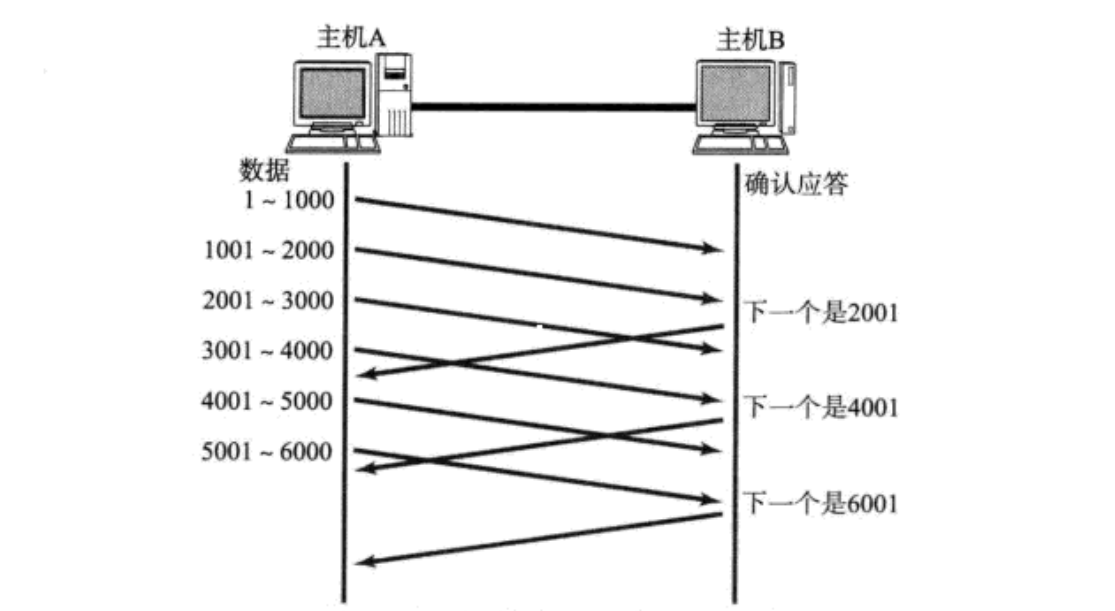
1. 核心动机
如果接收方在收到数据后立即回发 ACK,会存在两个弊端:
- 窗口太小:接收方缓冲区刚满,还没来得及被应用层取走,立即回发的窗口值很小,限制了发送方的速率。
- ACK 包过多:如果每个数据包都对应一个 ACK,网络中会充斥着大量只有 40 字节(IP头+TCP头)且无载荷的空包。
2. 工作原理
接收方收到数据后,并不立刻发送 ACK,而是启动一个定时器等待一小段时间。在此期间:
- 期待窗口增大 :等待应用层从缓冲区取走数据,从而在回发 ACK 时能通告一个更大的
Window。 - 期待累计确认 :如果在等待期间又收到了后续包,可以用一个 ACK 确认多个包。
3. 触发规则(防止等待过久)
为了不触发发送方的"超时重传",延迟应答必须遵循以下限制:
- 数量限制 :通常每收到 2 个 满长度的数据段,必须发送一个 ACK。
- 时间限制 :通常最大延迟时间为 200ms(不同系统实现略有差异),超时必须发送。
5.2 捎带应答 (Piggybacking) ------ "顺风车机制"
1. 核心思想
在典型的"请求-响应"通信(如 HTTP、Telnet)中,接收方在收到数据后,往往很快就要给发送方回发数据。
捎带应答 允许将 ACK 信息(确认号、标志位等)直接"搭便车",放在接收方准备发回的数据报文中。
2. 对比流程
- 无优化 :
- A -> B: 发送数据
- B -> A: 发送 ACK(纯确认包)
- B -> A: 发送响应数据
- A -> B: 发送 ACK(纯确认包)
- 开启捎带应答 :
- A -> B: 发送数据
- B 触发延迟应答,等待一会儿...
- B 刚好要发响应数据,于是将 ACK 信息并入响应数据包
- B -> A: 发送 响应数据 + ACK (合并为一个包)
6.TCP 特性:面向字节流
"面向字节流"是指:TCP 不关心应用程序一次性发送了多少数据,也不关心数据的逻辑结构。在 TCP 看来,数据就是一串连续的、无结构的字节序列。
6.1 类比UDP
1. UDP:面向报文(邮寄包裹)
- 就像寄快递,你发一个包裹,对方收一个包裹。
- 如果你发了 3 个包裹,对方必须分 3 次才能收完。
- 每个包裹都有明确的边界。
2. TCP:面向字节流(自来水管)
- 就像用水管供水。发送端是水龙头,接收端是接水盆。
- 发送者可以一次注水 100 升,也可以分 100 次每次注水 1 升。
- 对于接收者来说,他只看到盆里的水在增加,无法分辨这些水是分几次流进来的。
- 接收者可以根据自己的心情,用小勺舀水,或者直接拿大桶装,想取多少取多少。
6.2 内部实现机制:缓冲区 (Buffer)
TCP 能够实现"面向字节流",依靠的是内核中的发送缓冲区 和接收缓冲区。
-
发送端:
- 应用层调用
write/send写入数据。 - 数据先被存入内核的发送缓冲区。
- TCP 根据网络状况(拥塞窗口、MSS、流量控制)来决定什么时候发、发多少。它可能会把一个大的应用层数据拆成多个包发送,也可能把多个小的数据合并成一个包发送。
- 应用层调用
-
接收端:
- TCP 将收到的网络包解包,按序号重组后放入接收缓冲区。
- 应用层调用
read/recv读取数据。 - 应用层可以一次读取 1 字节,也可以读取整个缓冲区,读取的长度与发送时写入的长度不需要一致。
6.3 "粘包"问题 (Sticky Packets)
由于 TCP 没有消息边界,这就引出了开发者必须面对的"粘包/半包"问题。
-
现象:
- 发送方发了两个消息:
"Hello"和"World"。 - 接收方最终可能读到:
"HelloWorld"(两个合在一起了 ------ 粘包)"HelloWo"和"rld"(一个被切开了 ------ 半包)
- 发送方发了两个消息:
-
原因:
- TCP 本身就没有"包"的概念,只有"字节"的概念。所谓的"粘包"其实是应用层没有正确处理字节流边界。
6.4 如何在应用层解决边界问题?
既然 TCP 不帮我们划分边界,应用层协议(如 HTTP、Redis 协议)必须自己制定规则:
- 固定长度 :
- 规定每个消息固定为 128 字节,不够的补空格。
- 特殊分隔符 :
- 在消息末尾加上特殊字符,如
\r\n(FTP、早期 HTTP 使用)。
- 在消息末尾加上特殊字符,如
- 自描述长度(最常用) :
- 在消息头部增加一个固定长度的字段,表示后续数据的字节数。
- 流程:先读 4 字节获取长度 LLL -> 再读取 LLL 字节的数据。
7.TCP小结
为什么 TCP 这么复杂?
因为要保证可靠性,同时又尽可能提高性能。
可靠性:
• 校验和
• 序列号(按序到达)
• 确认应答
• 超时重发
• 连接管理
• 流量控制
• 拥塞控制
提高性能:
• 滑动窗口
• 快速重传
• 延迟应答
• 捎带应答