
OpenClaw 原生架构的记忆依赖上下文历史拼接、工具调用读写本地文件,以及显式对话指令触发记忆。
这带来几个问题:
- 检索算法简陋: 召回不稳定、相关性弱,Agent 需要反复试错与重问,Token 随对话轮次快速累积。
- 上下文注入过量: 每次执行固定读取近两天全量记忆(today + yesterday)+ 长期记忆,缺乏按任务裁剪,导致无效上下文占比高。
- 记忆缺少结构与去冗余: 工具调用的长输出(如 find 遍历、config.schema 等)被直接写入并在后续反复重传,成本呈滚雪球式放大。
最严重的是上下文爆炸,文件读写加上工具调用日志进入 prompt,导致 token 非线性增长。
原生 OpenClaw 本质是 Prompt 驱动型 Agent,记忆等于上下文,状态等于 token,长期能力等于上下文堆叠。而 OpenClaw + MemOS 转变为系统驱动型 Agent,记忆是系统层,状态是结构化存储,推理是状态调度加模型调用,Agent 从"会聊天的程序"转向"具备长期状态连续性的智能系统组件"。
本次测试,我们用公开数据集和真实任务对 OpenClaw 原生方案和 OpenClaw + MemOS 插件两个方案,对长期记忆能力、跨会话一致性、token 消耗与系统效率进行系统对比评测。
公开数据集测试(LOCOMO)
数据集说明
通过 LOCOMO(Long-Term Conversational Memory Benchmark),测试两类任务:
- 问答任务测精确召回能力,
- 事件摘要测长期语义整合能力。
评测通过 Gateway 启动两个 OpenClaw 端点版本:原生 OpenClaw、集成 MemOS 插件的 OpenClaw。
测试流程:
- 将数据集中的文本对话输入 OpenClaw,
- 再以数据集中的问题作为 query 进行提问,
- 对返回结果进行准确率评估,
- 并通过底层模型日志统计 token 使用量,从而同时评估记忆效果与系统成本。
全量测试结果
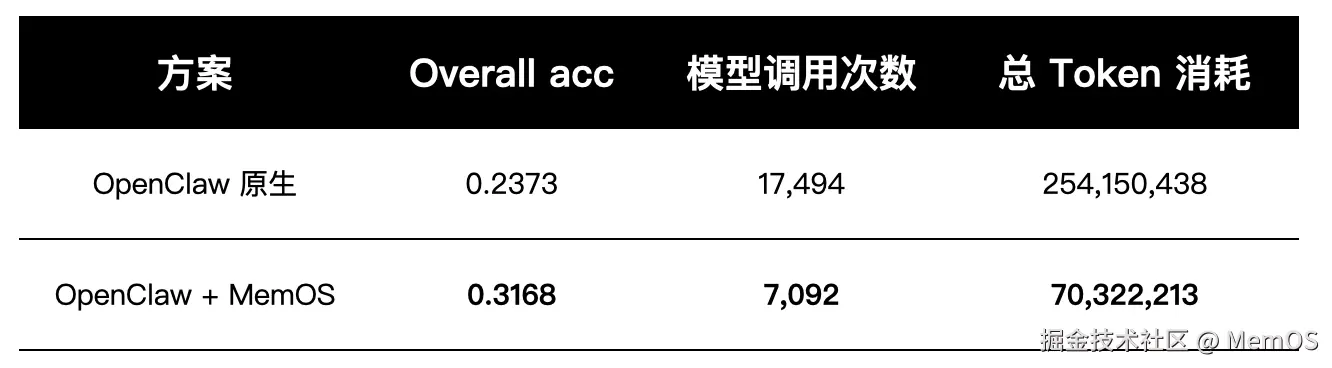
准确性方面,准确率从 0.2373 提升到 0.3168,说明长期对话的记忆稳定性明显增强。Agent 不再只靠上下文拼接做短期推理,而是有了结构化记忆调度能力。
成本方面,模型调用次数降低 59.5%,token 消耗降低 72%+。系统不再通过"堆 prompt"维持状态,而是通过记忆系统做状态抽取、结构化存储和按需激活。这是个重要转变:从"上下文记忆"到"系统记忆"。
真实任务测试(工程场景)
公开数据集只能验证模型能力上限,真实系统更关心工程行为:跨会话连续任务、复杂状态保持、长期协作交互。
我们构建了一组复杂真实任务流,测试跨会话任务连续性、多维度信息检索稳定性、记忆写入与召回效率,以及 token 成本随复杂度的增长趋势。
MemOS OpenClaw Plugin 通过自动记忆机制,让 Agent 的所有交互进入记忆系统,形成结构化存储和可调度状态。
工程实测对比
跨会话任务测试

集成 MemOS 后,对话轮次减少约 53%,token 消耗减少约 49%。
跨会话任务可以自然延续,无需用户反复重建上下文。不再出现"行为反转"、"偏好丢失"、"任务方向漂移"这些问题。
Agent 从"短期记忆型对话工具"转变为"具备长期状态连续性的协作系统"。
单会话记忆读写效率测试
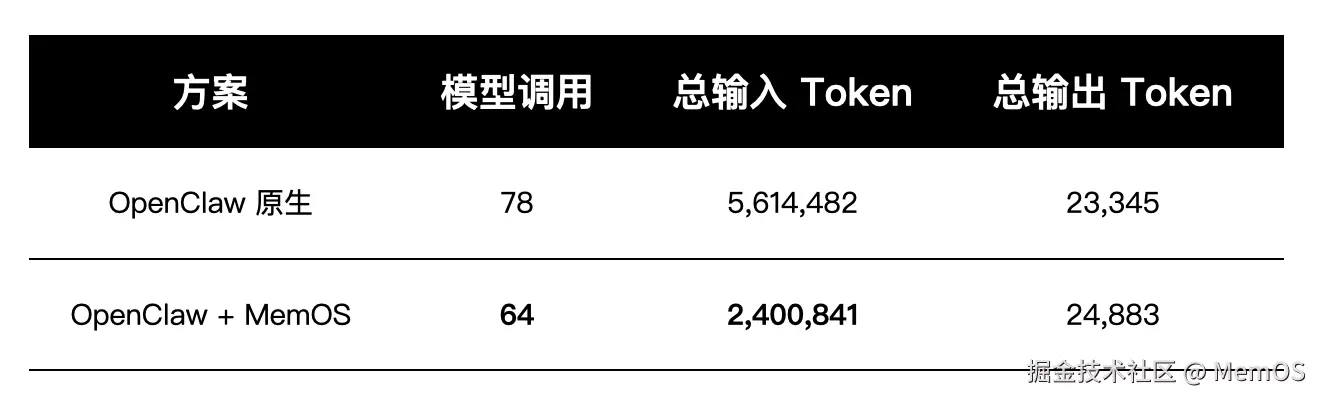
在 OpenClaw 原生架构中,记忆读写依赖工具调用,本地文件操作产生大量不可控上下文污染,一次"写一句话"的操作能引入数千 token 的上下文膨胀。
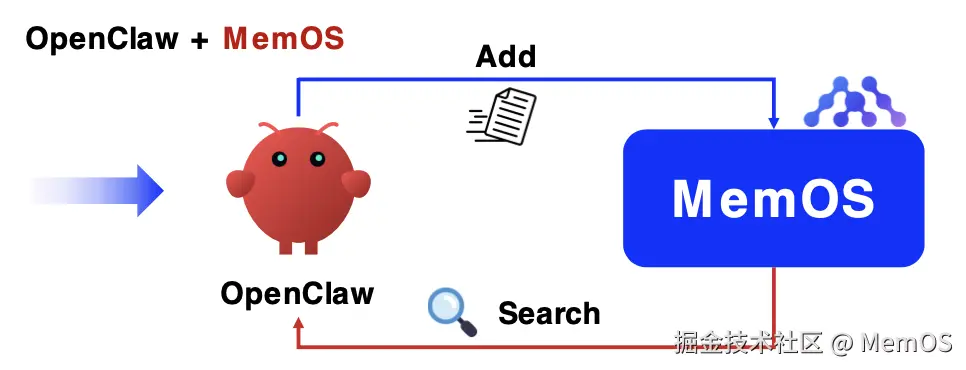
MemOS 将记忆从"prompt 负担"转为"系统状态层",记忆不进入上下文堆叠而是按需激活注入,状态与对话解耦,记忆与推理解耦,从架构上阻断了 token 爆炸路径。
从工具到落地
Token 成本可控:从"全量灌上下文"变成"按任务精确召回"
OpenClaw 不再每次固定塞入 today+yesterday+ 长期记忆,而是由 MemOS 按当前任务检索最相关的少量记忆(可设定召回预算/条数),显著降低无效上下文占比,避免 Token 滚雪球。
检索更稳更准:减少反复试错与重问,提升一次命中率
MemOS 提供更强的记忆组织与检索能力(结构化、分层/多粒度、语义检索 + 规则过滤等),让 OpenClaw 召回的内容相关性更强、稳定性更高,减少 Agent 因"召回不稳"导致的重复推理与反复确认。
记忆更干净可用:结构化 + 去冗余 + 高压缩,避免"长输出污染"
工具调用的长输出(如遍历结果、config/schema 等)不会直接原样反复写入上下文;MemOS 可以做摘要/压缩、去重与归档,长期运行越用越"清爽",记忆质量随时间提升而不是劣化。
在真实工程环境中,这带来可扩展性提升、token 成本可控、跨会话能力稳定、长期任务可持续,以及 Agent 行为一致性增强。
记忆不再是 prompt 技巧,而是系统架构能力。
立即体验
🦞 Your lobster now has a working memory system.
Get your API key:
memos-dashboard.openmem.net/quickstart/...
Try it: Full tutorial
关于 MemOS
MemOS 为 AI 应用构建统一的记忆管理平台,让智能系统如大脑般拥有灵活、可迁移、可共享的长期记忆和即时记忆。
作为记忆张量首次提出"记忆调度"架构的 AI 记忆操作系统,我们希望通过 MemOS 全面重构模型记忆资源的生命周期管理,为智能系统提供高效且灵活的记忆管理能力。