前言
在 LLM 应用落地的过程中,RAG(Retrieval-Augmented Generation)已经成为最主流的知识增强方案。但真正把 RAG 做好并不容易------嵌入模型怎么选?向量数据库用哪个?文档怎么切分?中文场景有哪些坑?
今天通过开源项目 SmartChat 的源码,深入拆解一套生产级 RAG 架构的设计思路。
🔗 项目地址:smartchat.nofx.asia/
一、RAG 的核心流程
RAG 的本质是"先检索,再生成":
用户提问 → Embedding 向量化 → 向量数据库检索 → 取回相关文档片段 → 拼接 Prompt → LLM 生成回答SmartChat 的实现完整覆盖了这条链路,并在每个环节做了工程化优化。
二、双嵌入策略:本地 vs 远程
SmartChat 最有意思的设计之一是双嵌入策略:
本地嵌入(默认):
- 使用 HuggingFace Transformers 在浏览器/Node 端运行
- 支持
BGE-small-zh-v1.5(中文场景)和all-MiniLM-L6-v2(英文场景) - 零成本,无需 API Key,数据不出本地
远程嵌入(备选):
- 使用通义千问
text-embedding-v3,512 维向量 - 适合部署在 Vercel 等无法运行本地模型的环境
typescript
// 嵌入模型选择逻辑
async function generateEmbedding(text: string, model: string) {
if (model === 'local-bge' || model === 'local-minilm') {
// HuggingFace Transformers 本地推理
const pipe = await pipeline('feature-extraction', modelName);
const output = await pipe(text, { pooling: 'mean', normalize: true });
return Array.from(output.data);
} else {
// 远程 API 调用
const response = await openai.embeddings.create({
model: 'text-embedding-v3',
input: text,
dimensions: 512
});
return response.data[0].embedding;
}
}这种设计的好处是:开发阶段用本地模型零成本调试,生产环境可以按需切换到远程模型。
三、pgvector:为什么不用 Pinecone 或 Milvus?
SmartChat 选择 Supabase + pgvector 作为向量存储,而不是专用向量数据库,原因很务实:
| 维度 | pgvector | Pinecone | Milvus |
|---|---|---|---|
| 部署复杂度 | 零(Supabase 自带) | 需要额外服务 | 需要独立部署 |
| 成本 | Supabase 免费额度内 | 按量付费 | 自建服务器 |
| 关系查询 | 原生 SQL JOIN | 不支持 | 不支持 |
| 适用规模 | 中小规模(<100万向量) | 大规模 | 大规模 |
| 生态整合 | 与业务数据同库 | 独立系统 | 独立系统 |
对于智能客服场景,知识库通常在几千到几万条文档片段,pgvector 完全够用,而且最大的优势是向量数据和业务数据在同一个数据库里,不需要维护额外的基础设施。
SmartChat 使用的向量检索函数:
sql
CREATE FUNCTION match_documents(
query_embedding vector(512),
match_count int DEFAULT 5,
filter_bot_id uuid DEFAULT NULL
) RETURNS TABLE (
id uuid,
content text,
metadata jsonb,
similarity float
)
LANGUAGE plpgsql AS $$
BEGIN
RETURN QUERY
SELECT
dc.id,
dc.content,
dc.metadata,
1 - (dc.embedding <=> query_embedding) as similarity
FROM document_chunks dc
WHERE dc.bot_id = filter_bot_id
ORDER BY dc.embedding <=> query_embedding
LIMIT match_count;
END;
$$;使用余弦距离 <=> 操作符,配合 IVFFlat 索引加速检索。
四、CJK 智能分块策略
文档分块是 RAG 中最容易被忽视但影响巨大的环节。SmartChat 针对中日韩文本做了专门优化:
typescript
function splitTextIntoChunks(text: string, chunkSize = 500, overlap = 50) {
// 检测是否包含 CJK 字符
const isCJK = /[\u4e00-\u9fff\u3040-\u309f\u30a0-\u30ff]/.test(text);
if (isCJK) {
// 中文按字符数分块,优先在句号、问号、感叹号处断开
return splitBySentenceBoundary(text, chunkSize, overlap);
} else {
// 英文按 token 数分块,优先在段落和句子边界断开
return splitByTokenBoundary(text, chunkSize, overlap);
}
}关键设计点:
- CJK 检测:自动识别文本语言,选择不同的分块策略
- 句子边界优先:避免在句子中间截断,保持语义完整性
- 重叠窗口:相邻块之间有 50 字符重叠,防止关键信息被切断
- 批量插入:每 10 个块一批写入数据库,避免 payload 过大
五、检索与生成的衔接
检索到相关文档片段后,SmartChat 将其拼接到 Prompt 中:
typescript
const systemPrompt = `${bot.systemPrompt}
以下是从知识库中检索到的相关信息,请基于这些信息回答用户问题:
${relevantChunks.map(chunk => chunk.content).join('\n\n')}
如果以上信息不足以回答问题,请如实告知用户。`;同时,对话上下文管理取最近 10 条消息,在保持连贯性和控制 token 消耗之间取得平衡。
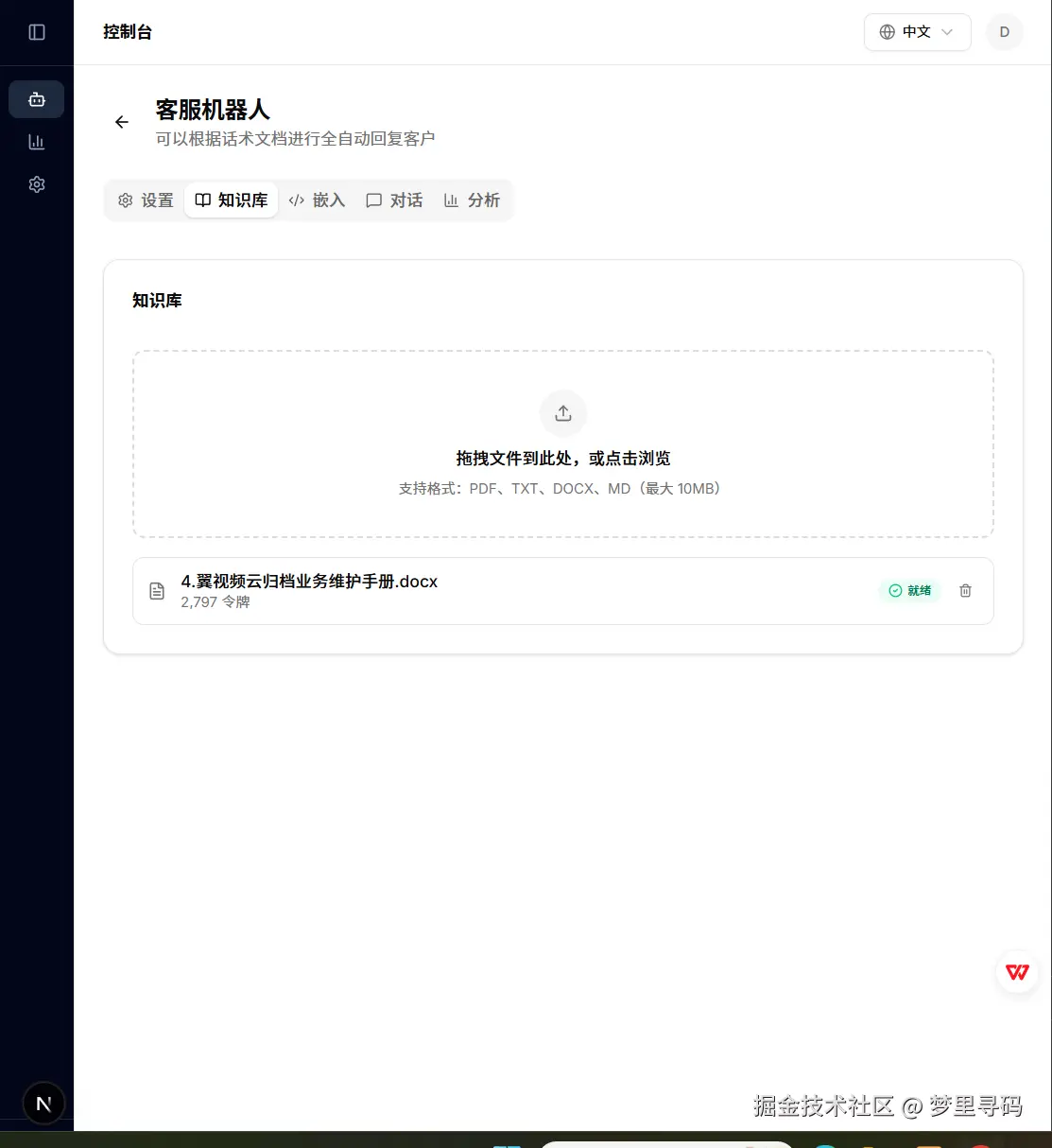
总结
SmartChat 的 RAG 架构虽然不复杂,但每个环节都做了务实的工程选择:本地嵌入降低成本、pgvector 简化架构、CJK 分块保证中文质量、批量写入保证稳定性。这套方案特别适合中小团队快速落地 AI 客服场景。
🔗 项目地址:smartchat.nofx.asia/,MIT 开源协议,欢迎 Star 和贡献。