在 AI 智能体时代,知识不再只是文字。Coze 照片知识库的出现,让 AI 真正拥有了「视觉记忆」。本文将从价值定位、与传统文档知识库的差异、核心应用场景、实操指南以及使用注意事项等维度,带你全面理解这一能力。
一、为什么需要照片知识库?------价值与意义
1.1 文字描述的天然局限
传统的文档知识库(文本、PDF、表格)本质上是文字世界的检索引擎。但在真实业务中,大量关键信息天然以图片形式存在:
- 产品外观、包装设计
- 操作手册中的截图与示意图
- 医疗影像、建筑图纸
- 电商商品主图、场景图
- 社交媒体中的 meme、海报
仅靠文字去描述一张图片,永远存在信息折损。一张产品实拍图传达的信息量,可能抵得上 500 字的文字描述。
1.2 照片知识库的核心价值
Coze 照片知识库的出现,解决了三个关键问题:
| 痛点 | 照片知识库的解法 |
|---|---|
| 图片信息无法被 AI 理解 | 自动调用图片理解模型,将视觉信息转化为可检索的文字描述 |
| 图文关联关系松散 | 建立图片与描述的强绑定关系,图片即知识主体 |
| 大量图片难以管理和检索 | 支持批量导入 + 智能标注,快速构建可检索的图片资产库 |
简单来说,照片知识库让你的 AI 智能体从「只能读文字」进化到「能看图、能找图、能用图回答问题」。
1.3 多模态 RAG 的关键拼图
在 RAG(检索增强生成)架构中,照片知识库补全了多模态检索的最后一块拼图:
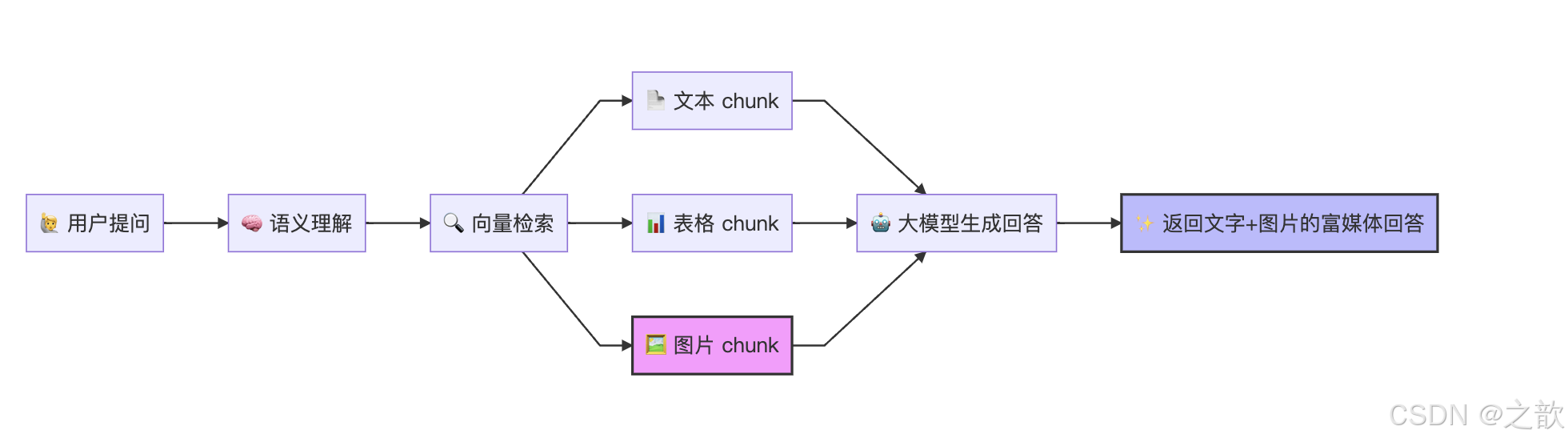
有了照片知识库,AI 不仅能引用文字和数据,还能在回答中直接返回相关图片,大幅提升信息表达的丰富度和准确性。
二、照片知识库 vs 文档知识库------关键差异对比
很多人会疑惑:文本知识库也能上传包含图片的 PDF,表格知识库也支持图片列,为什么还需要一个单独的照片知识库?
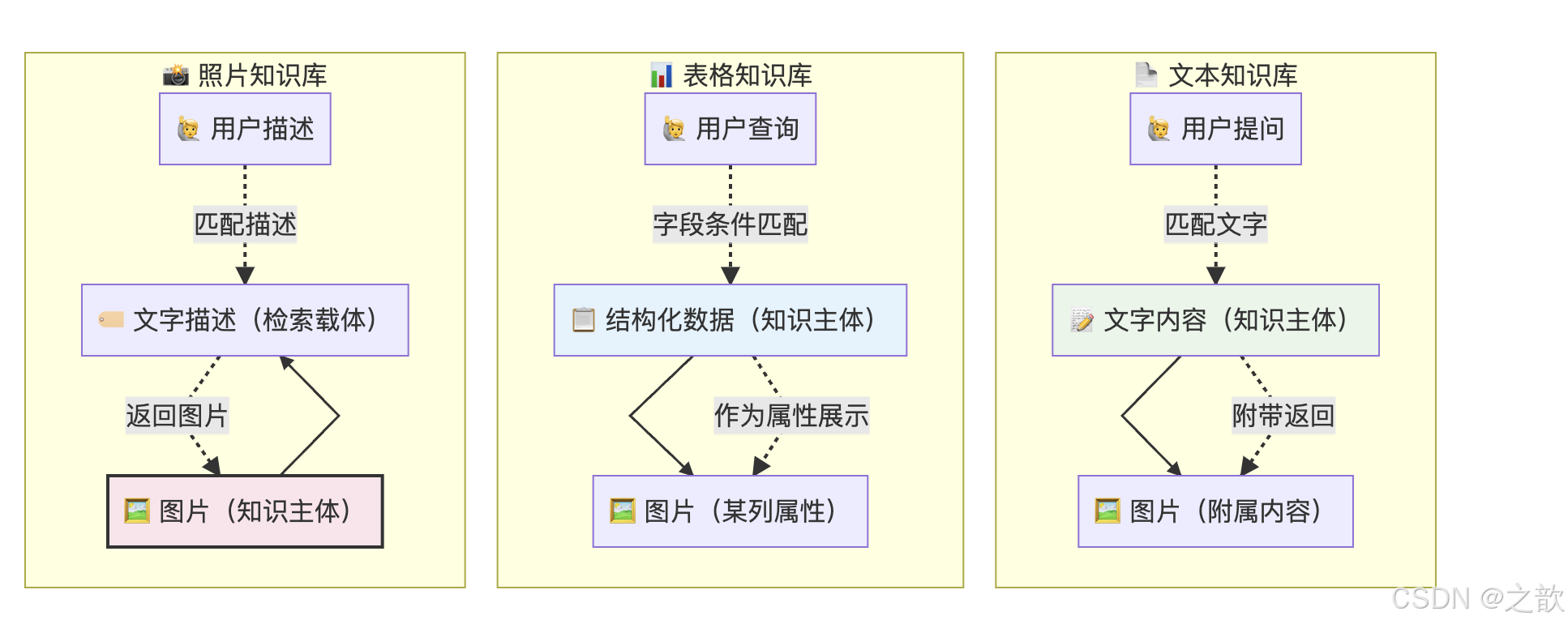
2.1 三种知识库中「图片」的角色完全不同
| 维度 | 文本知识库中的图片 | 表格知识库中的图片 | 照片知识库中的图片 |
|---|---|---|---|
| 图片角色 | 知识点的附属内容 | 表格行的一个属性字段 | 知识的主体本身 |
| 文字角色 | 知识的主体 | 结构化数据的主体 | 图片的描述/检索载体 |
| 关联方式 | 图片嵌入在文本 chunk 中 | 图片作为某行某列的值 | 图片与描述强绑定 |
| 检索逻辑 | 通过文字命中 chunk,图片附带返回 | 通过字段条件查询,图片作为结果展示 | 通过描述匹配图片,图片是核心返回物 |
| 典型场景 | 操作手册配图 | 商品列表展示 | 根据描述查找图片 |
2.2 一个具体例子帮你理解
假设你在做一个「宠物百科」智能体:
- 文本知识库:上传一篇关于金毛犬的文章,文章中间插入了一张金毛犬的图片。当用户问「金毛犬的特征是什么」,AI 返回文字描述的同时,会附带显示这张图片。
- 表格知识库:创建一个品种对照表,每行一个品种,其中一列是品种图片的 URL。当用户查询品种信息时,图片作为属性被展示出来。
- 照片知识库:上传 100 张不同品种狗的照片,每张自动生成描述(如"一只金毛犬在草地上奔跑")。当用户说「我想找一张狗在草地上玩耍的图片」,AI 直接返回匹配的照片。
核心区别在于:照片知识库以图片为中心,文字服务于图片检索;文本知识库以文字为中心,图片服务于内容呈现。
下面这张图清晰展示了三种知识库在处理图片时的本质区别:
2.3 检索效果的关键差异
根据实测数据,三种方案在图片检索上有显著差异:
文本知识库中的图片:
- 图片放在文本上方时,chunk 匹配度分值更高
- 图片放在文本下方时,匹配度分值会下降
- 在按 token 数分割的 chunk 中,图片必须在知识点内部才能被正确关联
- 图片无法独立被检索,依赖文字 chunk 的命中
表格知识库中的图片:
- 图片不能作为查询条件,只能作为展示手段
- 查询时如果没有明确要求显示图片,通常不会主动返回
照片知识库中的图片:
- 可以通过描述直接查询到匹配的图片
- 支持同一描述匹配多张图片
- 不同描述查询多张图片时,建议控制在 2 张以内,否则匹配度会下降
- 不支持以图搜图(需要先通过插件将图片转为文字描述再查询)
三、照片知识库导入方式详解与对比
Coze 照片知识库目前提供本地图片上传 这一核心导入方式,同时在标注环节提供了智能标注 和人工标注两种截然不同的处理策略。导入方式和标注策略的选择,直接决定了知识库的检索质量。
3.1 导入方式:本地图片上传
在创建照片知识库时,导入类型为「本地图片」,支持上传 JPG、JPEG、PNG 三种格式,单个文件不超过 20 MB,支持一次性批量上传多张图片。
与文本知识库相比,文本知识库支持本地文档(PDF/TXT/MD/DOC/DOCX)、在线数据(网站爬取)、飞书、微信公众号、Notion 等多种导入源。而照片知识库目前仅支持本地图片上传,导入渠道相对单一,但更加聚焦于图片资产管理。
3.2 两种标注方式的深度对比
上传图片后,进入标注设置环节,这是照片知识库最关键的步骤。Coze 提供两种标注方式:
| 对比维度 | 智能标注 | 人工标注 |
|---|---|---|
| 处理方式 | 系统自动调用图片理解模型,深度理解图片并生成全面详细的内容描述信息 | 不执行处理,在图片导入完成后,手动添加图片描述 |
| 效率 | 高效,适合大批量处理 | 耗时较长,需要逐张编辑 |
| 描述质量 | 客观准确,但偏向视觉表面描述 | 完全可控,可融入业务语义 |
| 适用场景 | 图片内容本身即为核心信息(如识别图中物体、场景) | 图片承载业务含义,需要自定义检索关键词 |
| 可编辑性 | 生成后支持手动修改和重新生成 | 完全手动编写 |
| 推荐策略 | 作为初始标注快速生成底稿 | 在智能标注基础上进一步精修 |
智能标注的实际效果
以上传一张客服二维码图片为例,智能标注会自动生成如下描述:
"这是一张微信二维码,位于一个绿色背景下的白色文本框中,二维码中间有一个绿色的圆形图标。"
可以看到,智能标注准确描述了图片的视觉内容 ------二维码的外观、颜色、布局。但它无法理解这张图片的业务含义:这是一个客服联系方式的二维码。
人工标注的价值
同样这张二维码图片,手动将描述修改为:
"这是 优品尚 客服联系方式。"
这样当用户问「怎么联系客服」或「客服联系方式是什么」时,AI 就能精准匹配到这张图片并返回给用户。
最佳实践:智能标注 + 手动精修
推荐的工作流程如下:
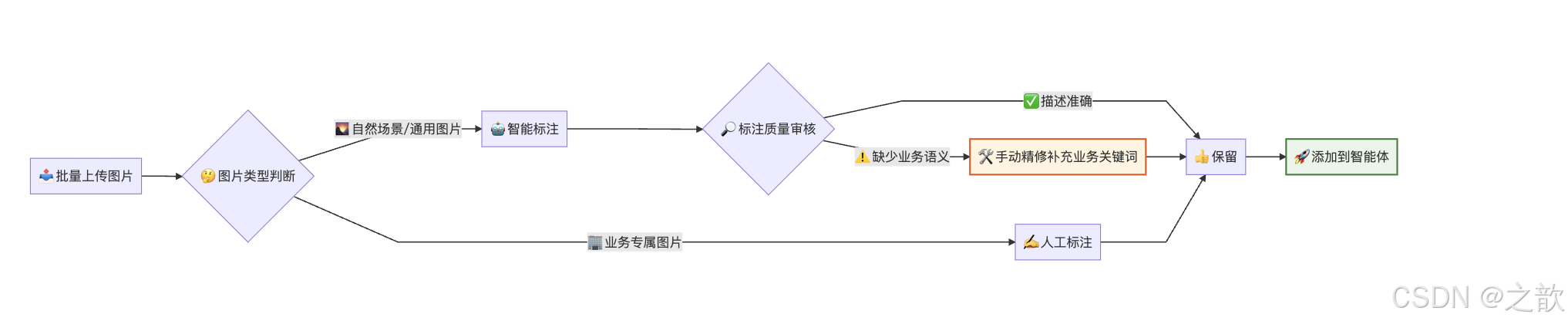
总结为三步:
- 先使用智能标注批量生成所有图片的初始描述
- 再逐一审核和修改关键图片的描述,补充业务关键词
- 对于业务含义明确的图片(如 logo、二维码、证件照模板),优先手动标注
3.3 与文本/表格知识库导入方式的横向对比
| 对比维度 | 文本知识库 | 表格知识库 | 照片知识库 |
|---|---|---|---|
| 导入源 | 本地文档、在线数据、飞书、微信公众号、Notion | 本地文件、API、飞书、自定义 | 本地图片 |
| 支持格式 | PDF/TXT/MD/DOC/DOCX | Excel/CSV(≤20M) | JPG/JPEG/PNG(单个≤20M) |
| 解析方式 | 快速解析/精准解析 | 自动识别表头 | 智能标注/人工标注 |
| 分段策略 | 自动分段与清洗/按层级分段/自定义分段 | 按行存储 | 一图一描述(图片即最小单元) |
| 导入后可编辑 | 可编辑分段内容 | 可编辑单元格 | 可编辑图片描述 |
| 批量处理能力 | 支持,可多文件上传 | 支持,最多10个文件 | 支持,批量上传多张图片 |
四、核心应用场景
场景 1:电商商品图片智能客服
痛点:客户问「有没有红色的运动鞋」,传统客服 Bot 只能返回文字链接。
方案:将商品图片导入照片知识库,标注描述(如"红色 Nike 跑步鞋,网面透气,白色鞋底")。AI 可以根据客户的自然语言描述,直接返回匹配的商品图片。
用户:有没有适合跑步的红色鞋子?
AI:为您找到以下商品 👇
[红色 Nike 跑步鞋图片]
[红色 Adidas 慢跑鞋图片]场景 2:内容创作与文章配图
痛点:写文章时需要配图,传统方式要在图库中反复搜索。
方案:将常用素材图片导入照片知识库并标注描述。创作时,AI 根据文章内容自动匹配合适的配图。
场景 3:设计素材管理与检索
痛点:设计团队积累了大量素材,但查找困难。
方案:将设计素材批量导入照片知识库,利用智能标注自动生成描述,再根据需要手动补充关键标签。需要素材时,用自然语言描述即可检索。
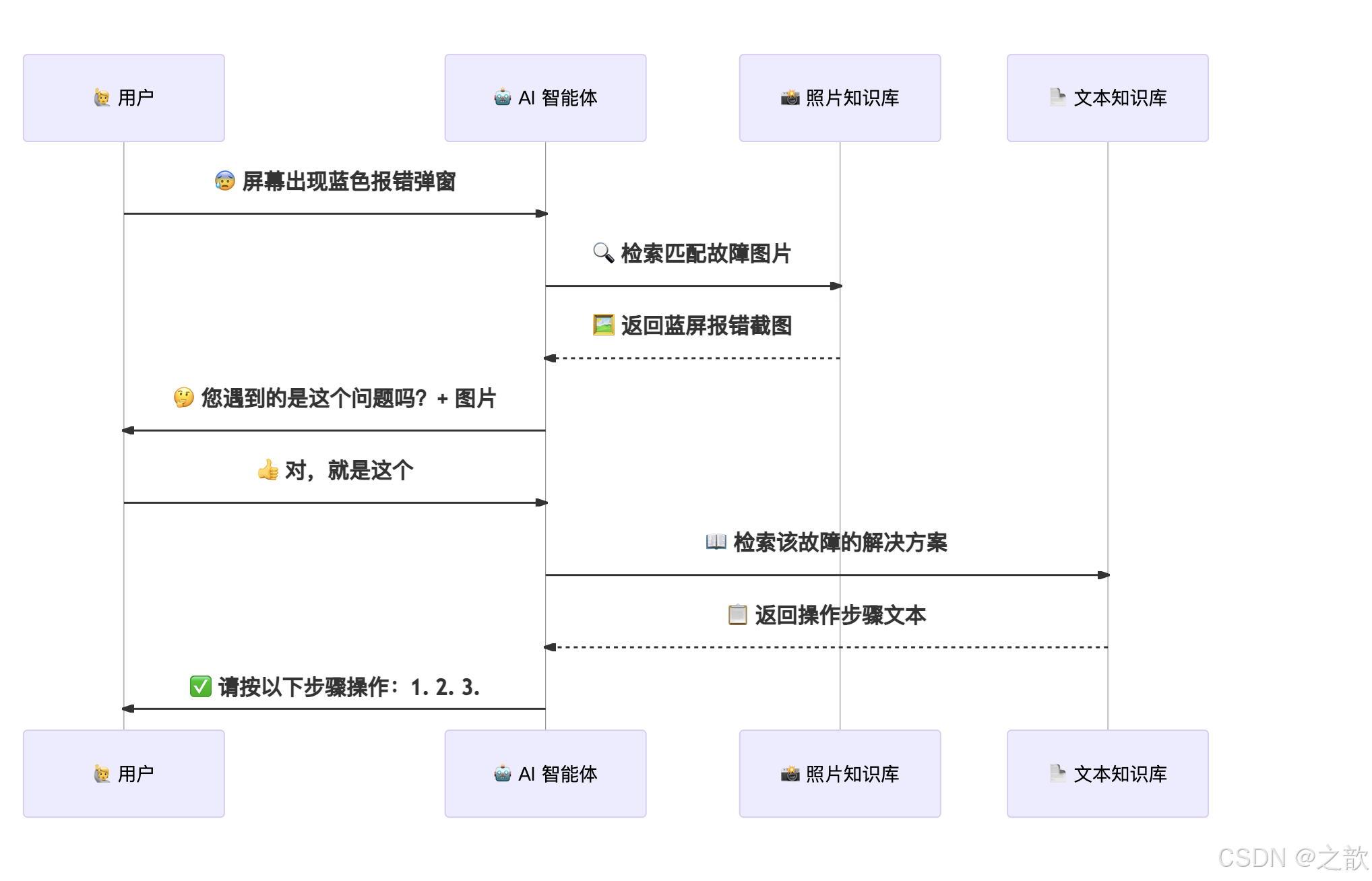
场景 4:产品操作手册(文本知识库 + 照片知识库协同)
痛点:纯文字的操作指南用户看不懂。
方案:
- 文本知识库存放操作步骤说明(在知识点内部嵌入操作截图)
- 照片知识库存放常见故障现象图片(标注故障描述)
- 用户描述故障现象时,AI 先从照片知识库匹配故障图片确认问题,再从文本知识库返回解决方案
场景 5:旅游/房产/餐饮行业的视觉问答
痛点:用户想看"海景房的阳台效果"、"餐厅的环境照片"、"景点实拍图"。
方案:将场景照片导入照片知识库,标注详细的场景描述。用户用自然语言提问时,AI 直接返回对应的实拍图片,体验远优于纯文字描述。
五、实操指南:从创建到使用(全流程图解)
下面以一个「人工客服」智能体为例,演示照片知识库从创建到最终生效的完整流程。
整体流程概览:

其中步骤 ④⑤(标注相关)是核心环节,直接决定检索质量。
5.1 第一步:创建智能体
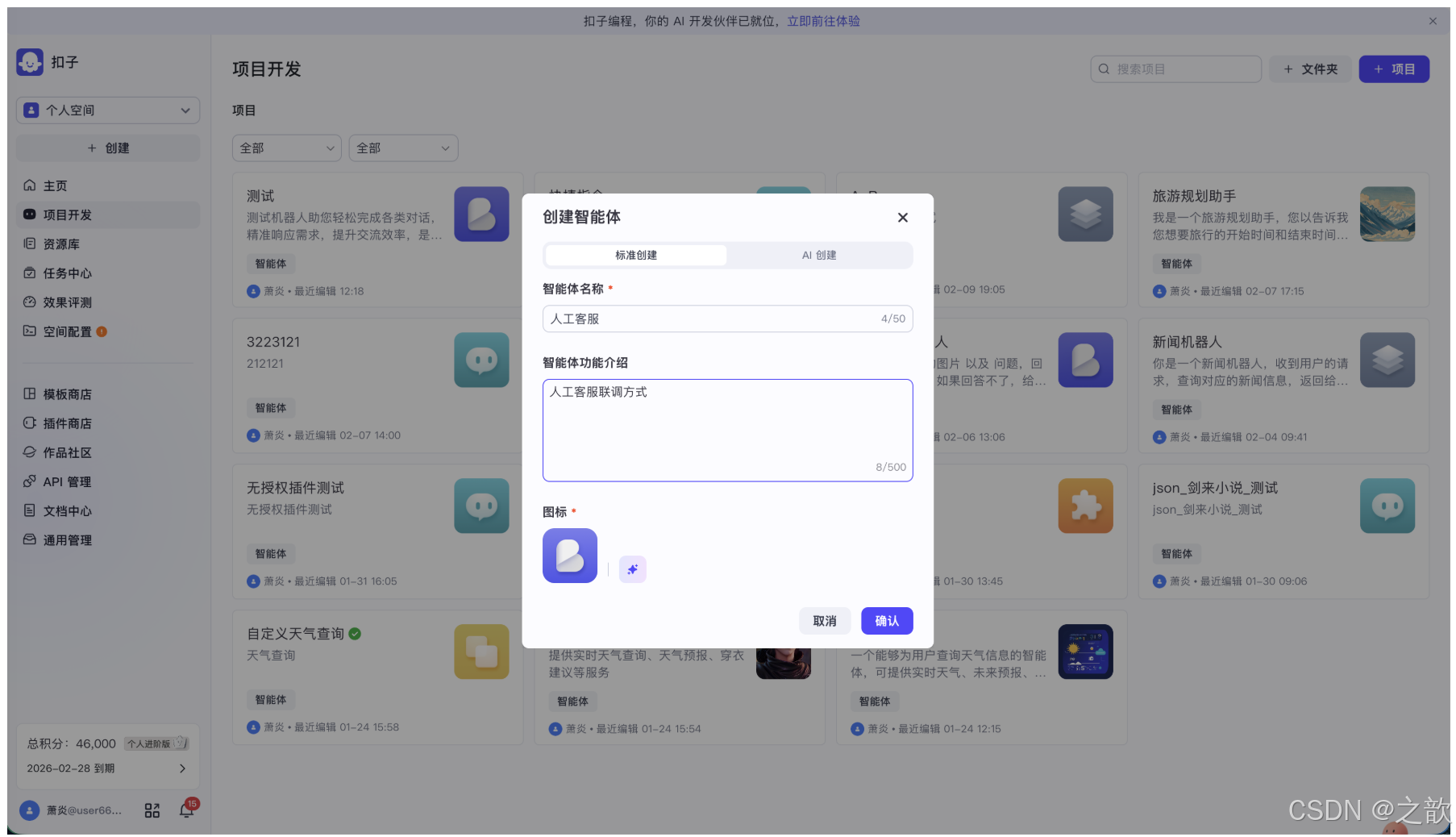
首先在 Coze 平台创建一个智能体。进入「项目开发」页面,点击「创建智能体」,输入智能体名称(如"人工客服")、功能介绍(如"人工客服联调方式"),选择图标后点击确认。
5.2 第二步:进入资源库创建照片知识库
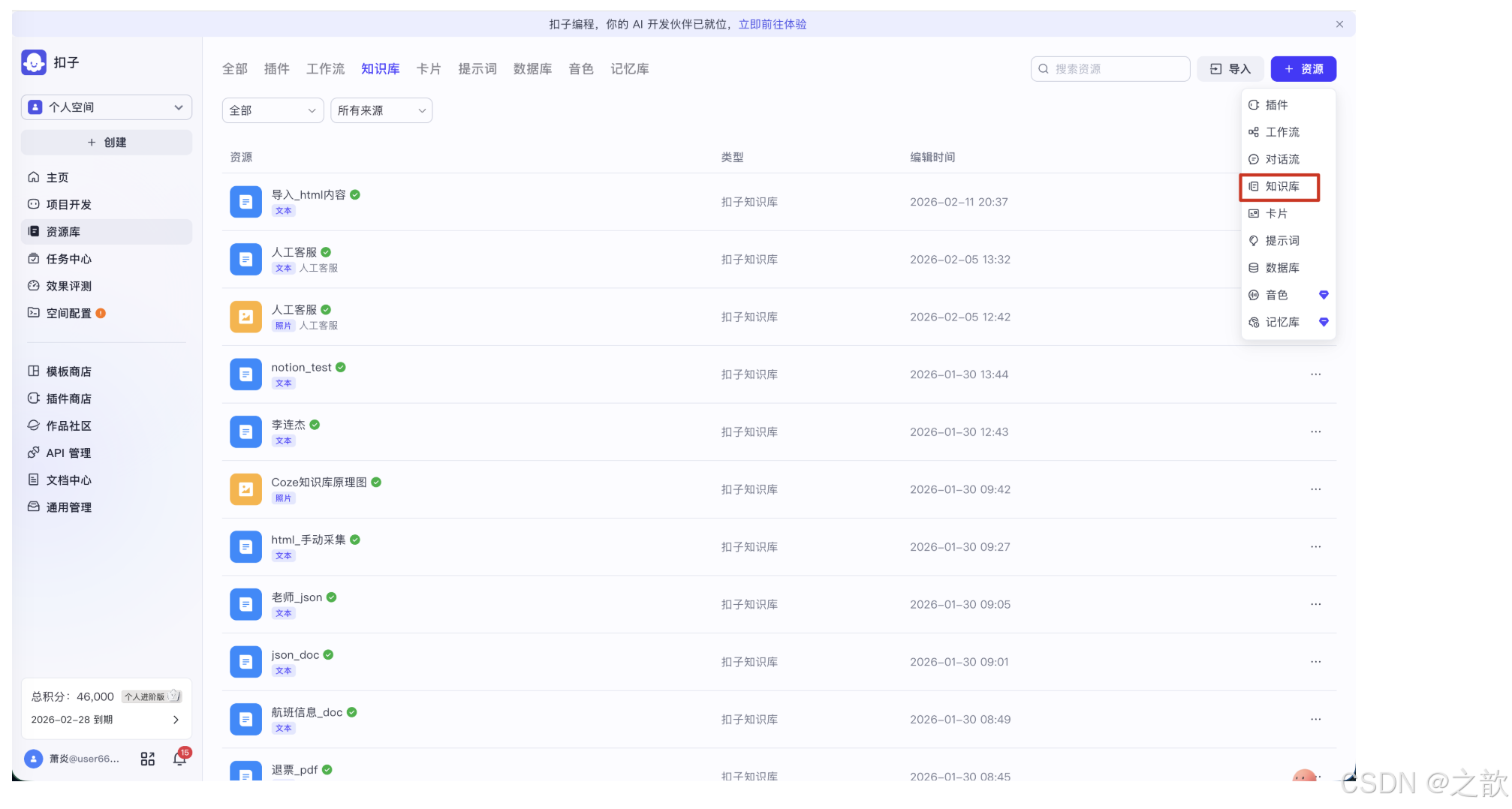
智能体创建完成后,需要为它准备知识来源。在 Coze 左侧导航栏点击「资源库」,进入资源管理页面。点击右上角的「+ 资源」按钮,在下拉菜单中选择**「知识库」**。
此时会弹出「创建知识库」对话框。这里有两个关键选择:
- 知识库创建方式:选择「创建扣子知识库」(支持照片、文本、表格知识库,智能切换管理,适合轻量检索场景)
- 知识库格式:点击右侧的**「照片类型」**标签
然后填写知识库的名称(如"人工客服二维码")和描述(如"人工客服二维码图片")。可以看到,导入类型显示为**「本地图片 - 上传 JPG, JPEG, PNG ...」**。
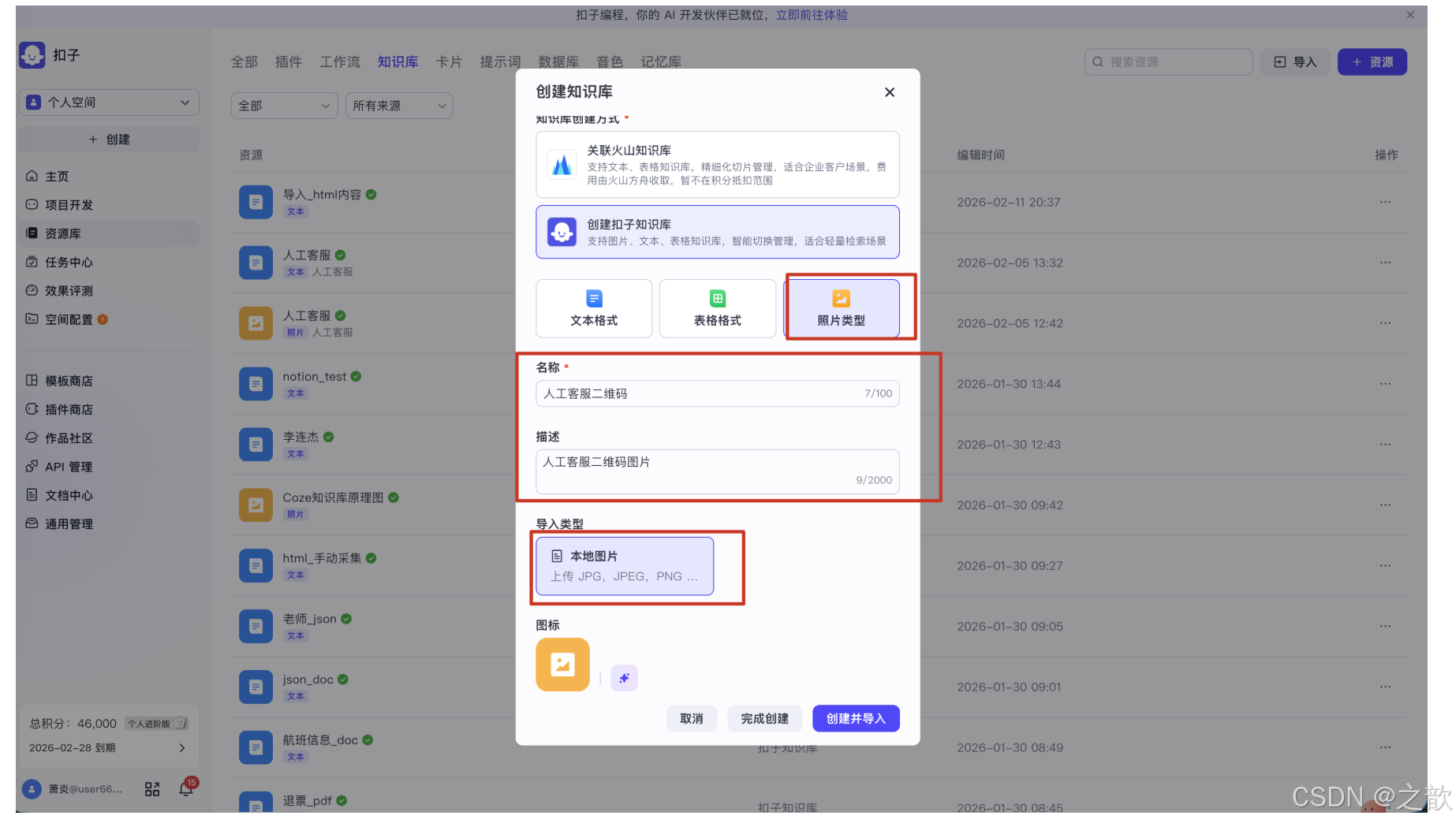
注意:此处可以选择「完成创建」或「创建并导入」。选择「创建并导入」可以直接进入图片上传流程。
5.3 第三步:上传图片
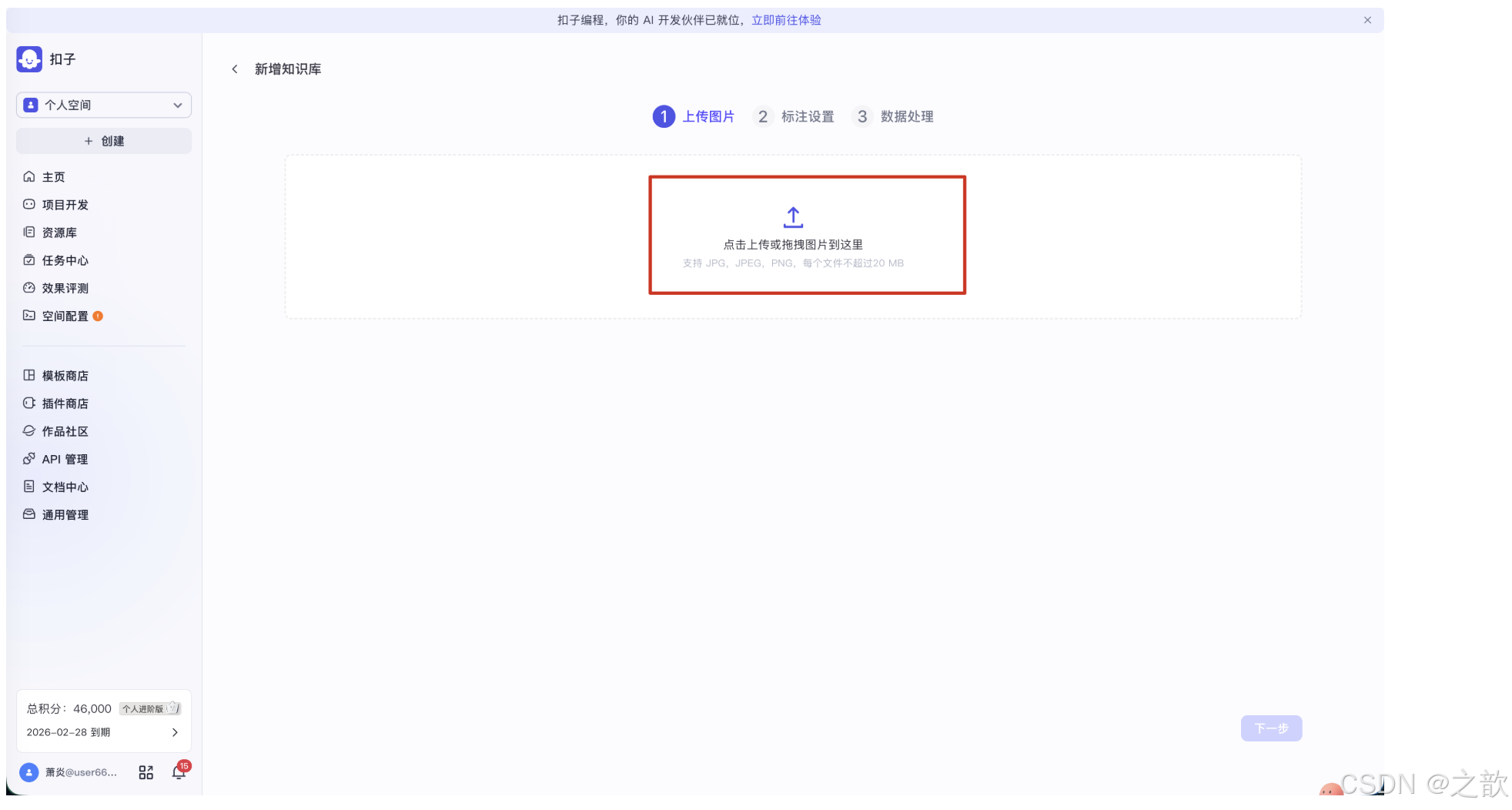
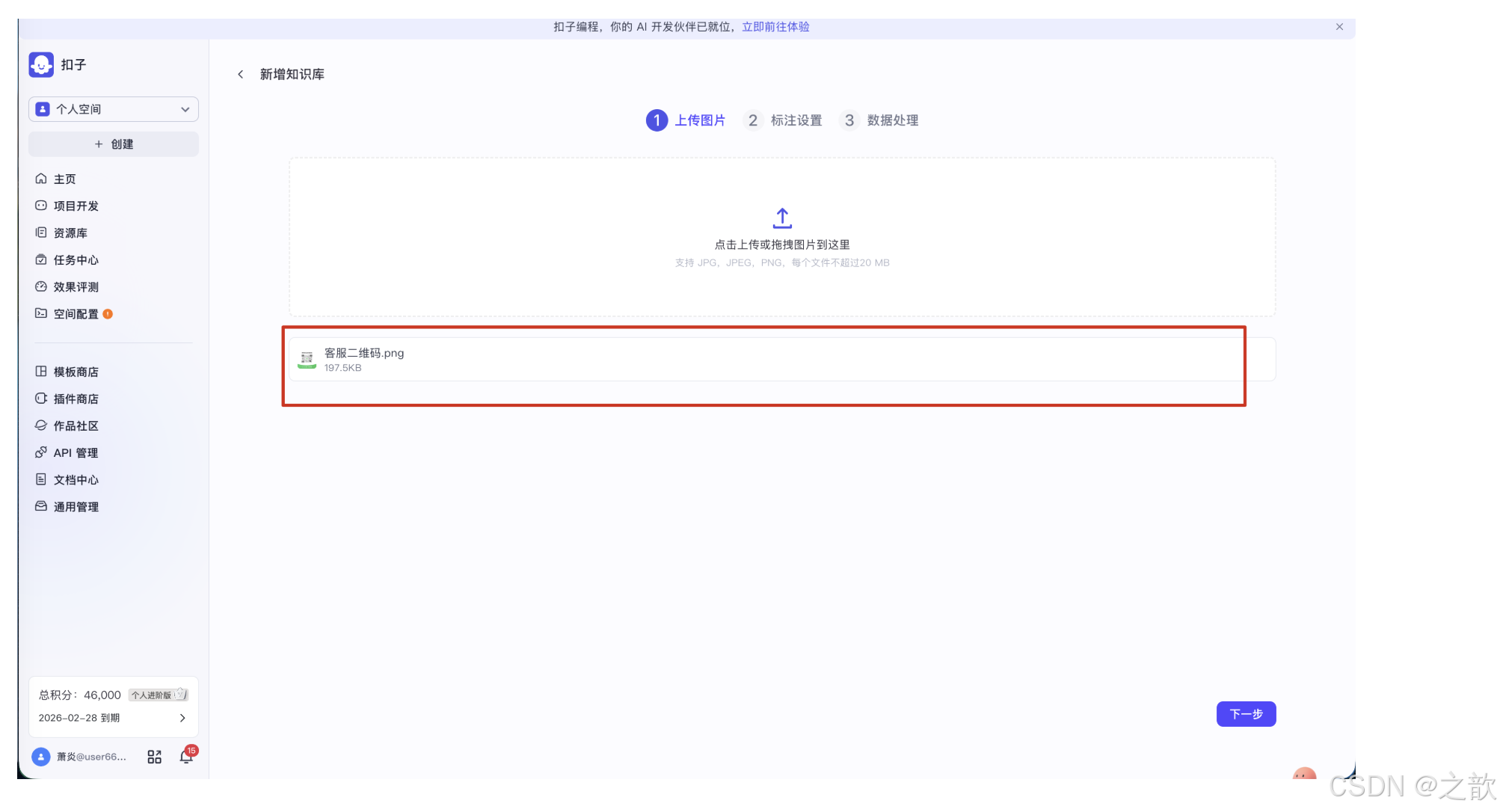
进入新增知识库流程后,页面顶部显示三个步骤:① 上传图片 → ② 标注设置 → ③ 数据处理。
在上传区域,可以点击上传或拖拽图片 到指定区域。支持 JPG、JPEG、PNG 格式,每个文件不超过 20 MB。
上传完成后,页面下方会显示已上传的文件列表,包括文件名和文件大小。确认无误后,点击右下角的**「下一步」**。
5.4 第四步:选择标注方式
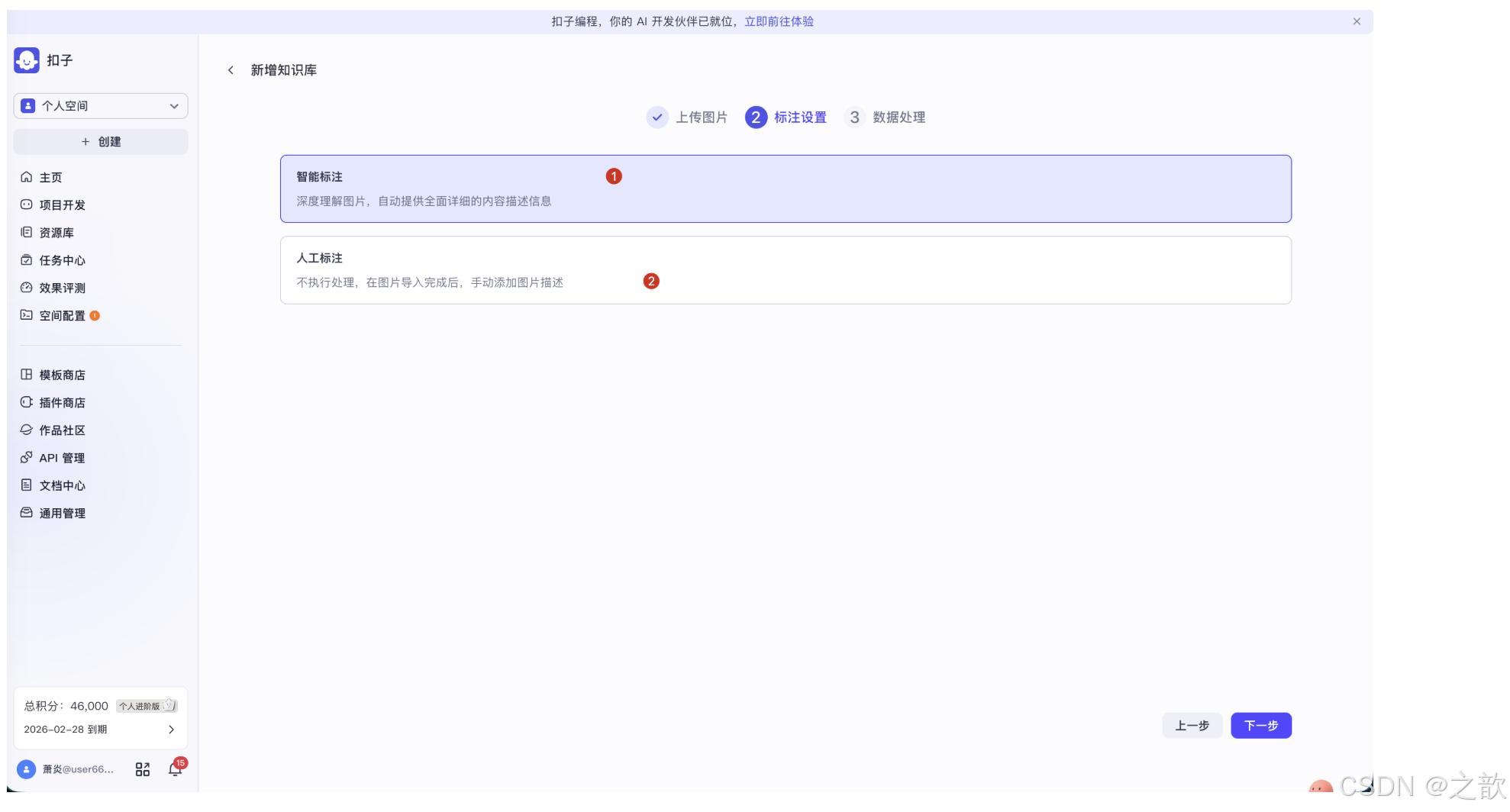
进入步骤 2「标注设置」。这是照片知识库最关键的环节,直接决定了图片的检索效果。系统提供两个选项:
- ① 智能标注:深度理解图片,自动提供全面详细的内容描述信息
- ② 人工标注:不执行处理,在图片导入完成后,手动添加图片描述
如何选择? 如果你的图片数量较多且需要快速处理,先选智能标注;如果图片承载特定业务含义(如品牌 logo、二维码、特定产品型号),建议选智能标注后再手动精修。
5.5 第五步:查看与编辑标注结果
选择智能标注并完成数据处理后,进入知识库详情页面。可以看到每张图片下方都有系统自动生成的描述。
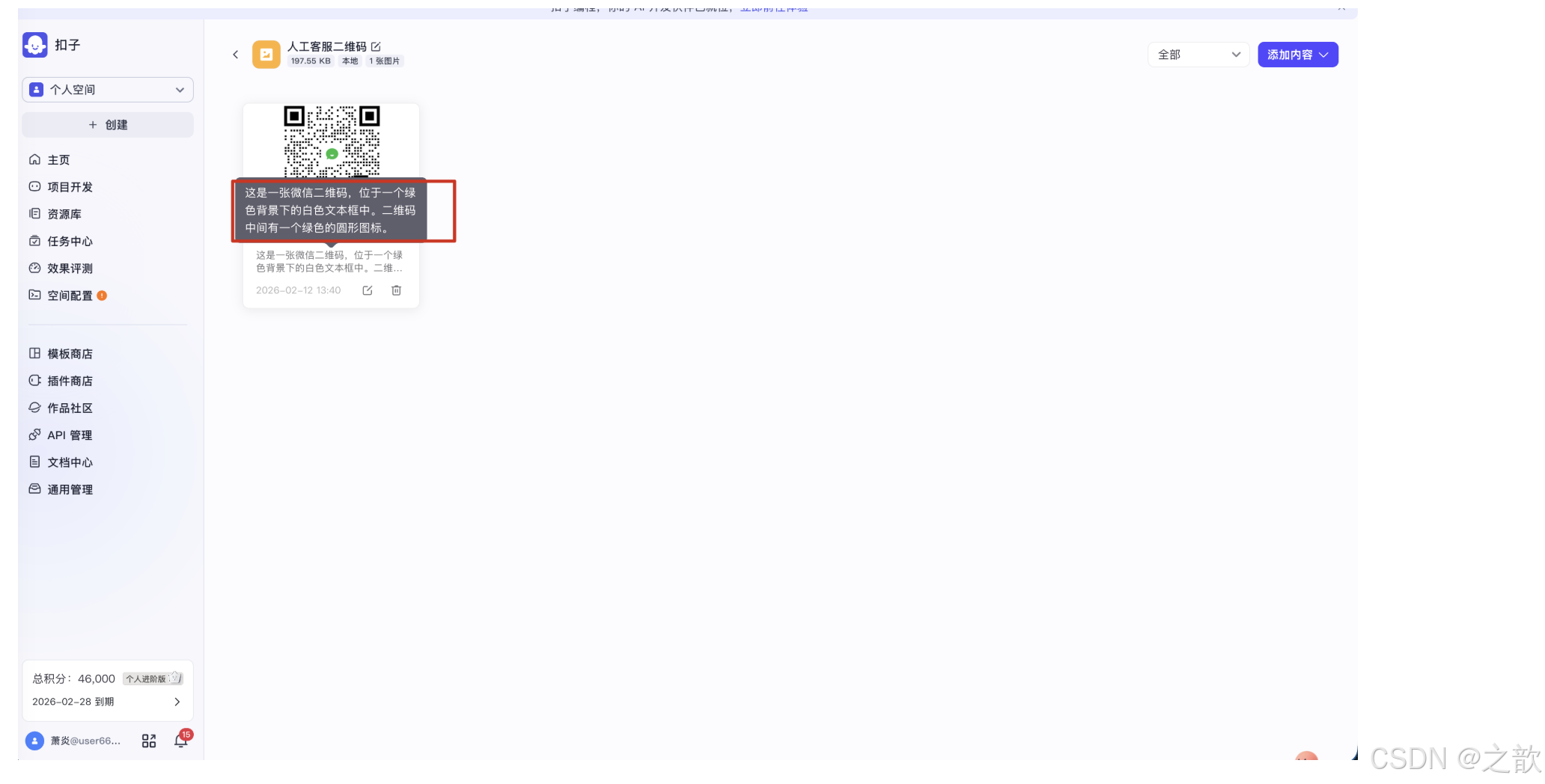
以客服二维码为例,智能标注自动生成的描述为:
"这是一张微信二维码,位于一个绿色背景下的白色文本框中,二维码中间有一个绿色的圆形图标。"
这段描述准确描述了图片的视觉内容,但缺少业务语义------用户不会问"有没有绿色背景的二维码",而是会问"客服联系方式是什么"。
因此,我们需要手动编辑描述,将其修改为贴合业务场景的内容:
"这是 优品尚 客服联系方式。"
修改后,当用户询问客服联系方式时,AI 就能精准匹配并返回这张二维码图片。

5.6 第六步:将照片知识库添加到智能体
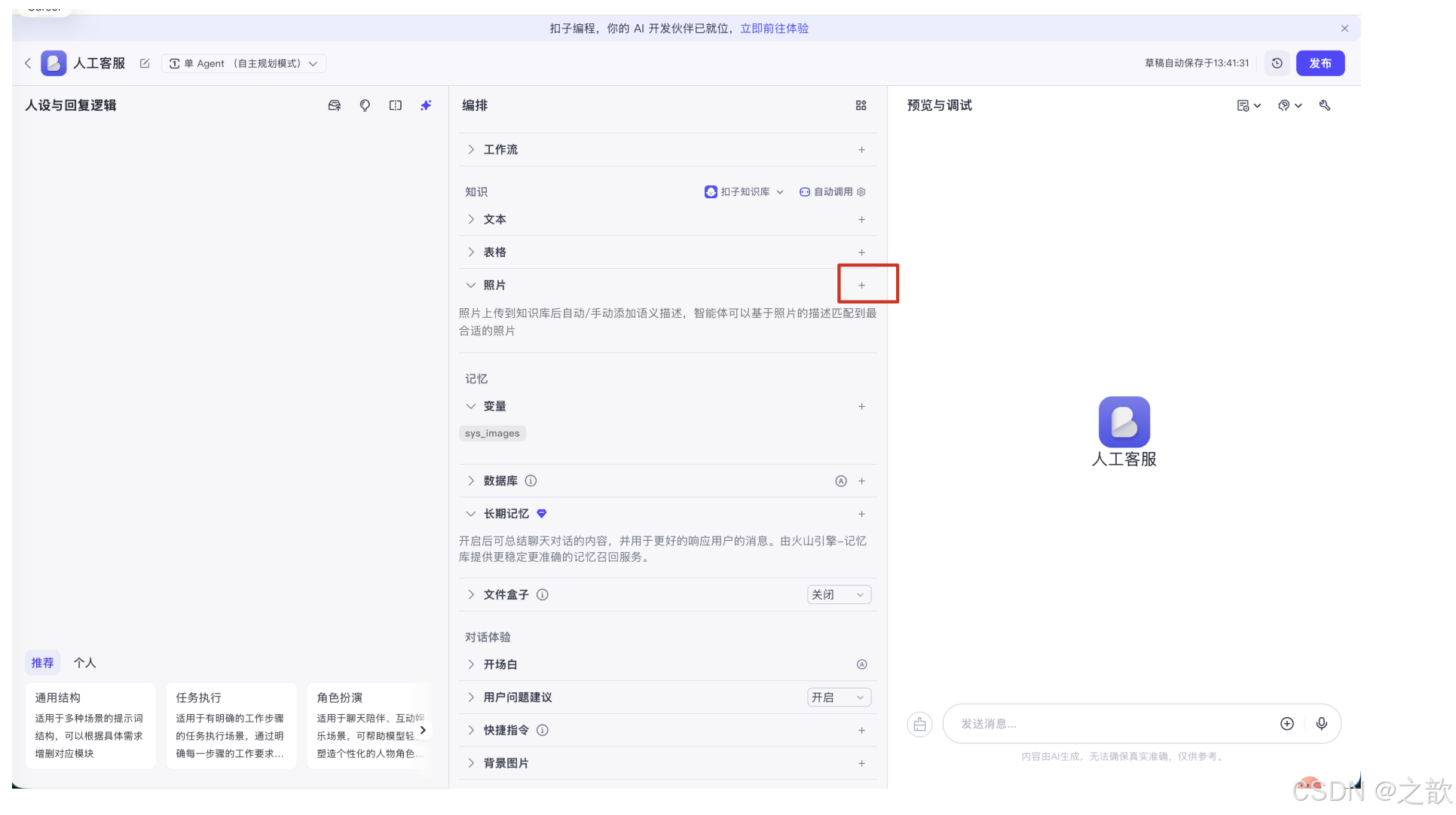
照片知识库创建完成后,需要将它关联到智能体。回到智能体编辑页面,在中间「编排」区域找到 知识 > 照片 模块,点击右侧的**「+」号**,选择刚才创建的照片知识库。
页面提示:"照片上传到知识库后自动/手动添加语义描述,智能体可以基于照片的描述匹配到最合适的照片"------这正是照片知识库的核心工作原理。
5.7 第七步:调试验证效果
一切配置完成后,在右侧「预览与调试」区域测试效果。例如点击预设问题「优品尚 人工客服联系方式」,可以看到 AI 成功从照片知识库中检索到匹配的二维码图片,并在回答中直接展示给用户。
在调试结果中可以看到:
- AI 标注了**「已搜索知识库」**,表明确实从照片知识库中进行了检索
- 回答中直接渲染了二维码图片
- 同时返回了图片的描述文字

至此,一个包含照片知识库的智能体就完整搭建完成了。
六、使用注意事项(避坑指南)
6.1 图片上传限制
| 限制项 | 具体要求 |
|---|---|
| 支持格式 | JPG、JPEG、PNG |
| 单文件大小 | 不超过 20 MB |
| 批量上传 | 支持一次导入多张 |
| 不支持格式 | GIF、SVG、WebP、BMP、TIFF 等 |
建议:如果图片格式不在支持范围内,可以提前用工具批量转换为 PNG 或 JPG 格式。对于大于 20MB 的高清图片,建议先压缩后再上传。
6.2 标注质量直接决定检索效果
照片知识库的检索本质上是通过描述文字的向量匹配来查找图片。描述写得好不好,直接影响用户能不能找到这张图。
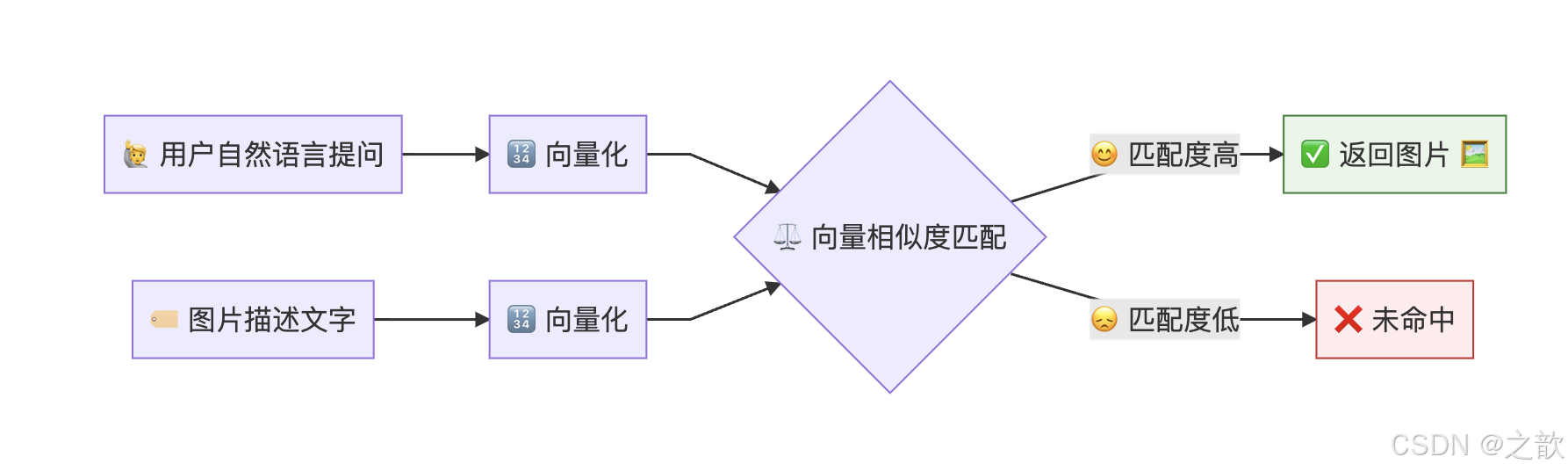
核心链路:用户查询词 ↔ 图片描述 之间的语义相似度决定了能否命中。因此,描述的质量就是检索的质量。
常见标注误区:
| 误区 | 示例 | 问题 |
|---|---|---|
| 描述太笼统 | "一张照片" | 几乎不可能被精准匹配 |
| 只描述外观 | "一个黑白相间的二维码" | 用户不会用外观特征搜索二维码 |
| 缺少业务语境 | "一双红色的鞋" | 缺少品牌、型号、用途等关键检索词 |
| 描述过长 | 超过 500 字的详细描述 | 向量匹配时关键词被稀释 |
标注要素清单:
✅ 主体:图片中的核心对象是什么(产品名、人物、场景)
✅ 特征:颜色、形状、状态、动作(红色、圆形、运行中)
✅ 业务标签:该图片在业务中代表什么(客服二维码、产品正面图、户型图)
✅ 检索关键词:用户可能用什么词来查找这张图
✅ 用途场景:适合在什么场景使用(可选)6.3 检索匹配的数量限制
- 单一描述查询多张图片:效果较好,可以返回多张描述相似的图片
- 多个不同描述同时查询 :建议不超过 2 个不同描述,否则匹配度会显著下降
- 最大召回数量:受系统召回值设置的限制,并非无上限
建议:如果需要查询多张不同类型的图片,建议拆分为多次查询,或通过工作流串联实现。
6.4 不支持以图搜图
当前照片知识库不支持以图搜图(即用户上传一张图片,系统查找相似图片)。如果业务中有这个需求,可以通过以下变通方案实现:

6.5 智能标注 vs 人工标注的选择策略
| 场景 | 推荐方式 | 理由 |
|---|---|---|
| 大量自然场景照片(风景、人物、动物) | 智能标注 | AI 擅长描述视觉内容 |
| 品牌 logo、企业二维码 | 人工标注 | 业务含义无法从外观推断 |
| 产品展示图 | 智能标注 + 手动精修 | 外观描述有价值,但需补充型号、品类 |
| 操作界面截图 | 人工标注 | 截图中的业务流程需要人工理解 |
| 设计素材(icon、插画) | 智能标注 + 补充标签 | 视觉描述为基础,风格标签需手动补充 |
| 医疗/专业领域图片 | 人工标注 | 专业术语和诊断信息需要领域知识 |
6.6 知识库命名与组织规范
- 按业务模块分库:如"商品主图"、"客服物料"、"操作手册截图"等,避免将所有图片混入一个知识库
- 知识库名称要清晰:命名应能直接反映内容主题,便于多个知识库协同管理
- 描述字段善加利用:创建知识库时的描述字段,可以帮助团队成员理解该库的用途和范围
6.7 与 Prompt 配合的注意事项
将照片知识库添加到智能体后,建议在 Prompt 中明确引导 AI 的图片检索行为:
推荐的 Prompt 写法:
当用户询问产品外观、要求查看图片、或描述某个视觉场景时,
请优先从照片知识库中检索匹配的图片并展示给用户。
如果找到匹配图片,先展示图片,再用文字补充说明。
请读取知识库内容,不要发散。需要注意:
- 加上「请读取知识库内容,不要发散」可以有效减少 AI 的幻觉问题
- 如果同时使用了多个知识库(文本 + 照片),需要在 Prompt 中明确优先级
- 根据实际测试效果持续调优 Prompt 策略
6.8 常见问题排查
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 用户提问后不返回图片 | 描述与用户查询关键词不匹配 | 优化图片描述,加入用户常用查询词 |
| 返回了错误的图片 | 多张图片描述过于相似 | 增加差异化描述,标注各图片的独特特征 |
| 图片上传失败 | 文件格式不支持或超过 20MB | 转换格式/压缩文件大小 |
| 智能标注结果不准确 | 图片内容复杂或含大量文字 | 手动编辑标注内容 |
| 一次查询返回不全 | 查询了多个不同描述的图片 | 拆分为多次查询,每次不超过 2 种描述 |
七、总结
Coze 照片知识库不是文档知识库的简单「图片版」,而是一种以图片为中心的全新知识组织方式。它的核心逻辑是:
图片是知识本身,文字描述是检索的桥梁。
对比传统文档知识库将图片视为文字的附属品,照片知识库真正将视觉信息提升为一等公民。在电商、内容创作、设计管理、客户服务等视觉信息密集的场景中,它能显著提升 AI 智能体的回答质量和用户体验。
关键要点回顾:

如果你的业务中有「看图」和「找图」的需求,照片知识库值得认真用起来。
参考资料:
- Coze 官方文档 - 图片知识库
- 《Coze 全场景知识库指南》
- 《Coze 知识库中图片的实验与测试》