GENIUS: Generative Fluid Intelligence Evaluation Suite
Authors: Ruichuan An, Sihan Yang, Ziyu Guo, Wei Dai, Zijun Shen, Haodong Li, Renrui Zhang, Xinyu Wei, Guopeng Li, Wenshan Wu, Wentao Zhang
Deep-Dive Summary:
GENIUS: 生成式流体智能评估套件
摘要
统一多模态模型(UMMs)在视觉生成领域取得了显著进展。然而,现有的基准测试主要评估晶体智能 (Crystallized Intelligence),即依赖于积累的知识和已学模式的回忆。这种侧重点忽视了生成式流体智能 (Generative Fluid Intelligence, GFI):即在即时情境中归纳模式、通过约束进行推理以及适应新颖场景的能力。为了严格评估这种能力,我们推出了 GENIUS(生成式流体智能评估套件)。我们将 GFI 形式化为三个原语的综合:归纳隐式模式(例如,推断个性化视觉偏好)、执行即兴约束(例如,将抽象隐喻可视化)以及适应情景知识(例如,模拟反直觉的物理现象)。这些原语挑战模型在完全基于即时语境的情况下解决问题。我们对 12 个代表性模型进行的系统评估显示,这些任务中存在显著的性能缺陷。诊断分析表明,缺陷源于有限的情境理解,而非生成能力不足。为弥补这一差距,我们提出了一种无需训练的注意力干预策略。最终,GENIUS 为 GFI 建立了严格标准,引导该领域从知识利用迈向动态、通用的推理。
1. 引言
统一多模态模型(UMMs)近期见证了卓越的进步,被广泛认为是通往通用人工智能(AGI)的里程碑。然而,现有的评估大多集中在晶体智能(CI),即对预训练知识的记忆和检索。例如,模型生成完美的"猫"通常源于训练中接触过数十亿个实例。这掩盖了视觉生成中关键的**生成式流体智能(GFI)**缺陷,即在陌生场景中进行归纳、推理和即兴适应的能力。
如图 1 所示,"简单约束"任务要求模型识别即兴规则(如抽象符号代表"雨")并将其应用于视觉输出,而不仅仅是检索静态概念。
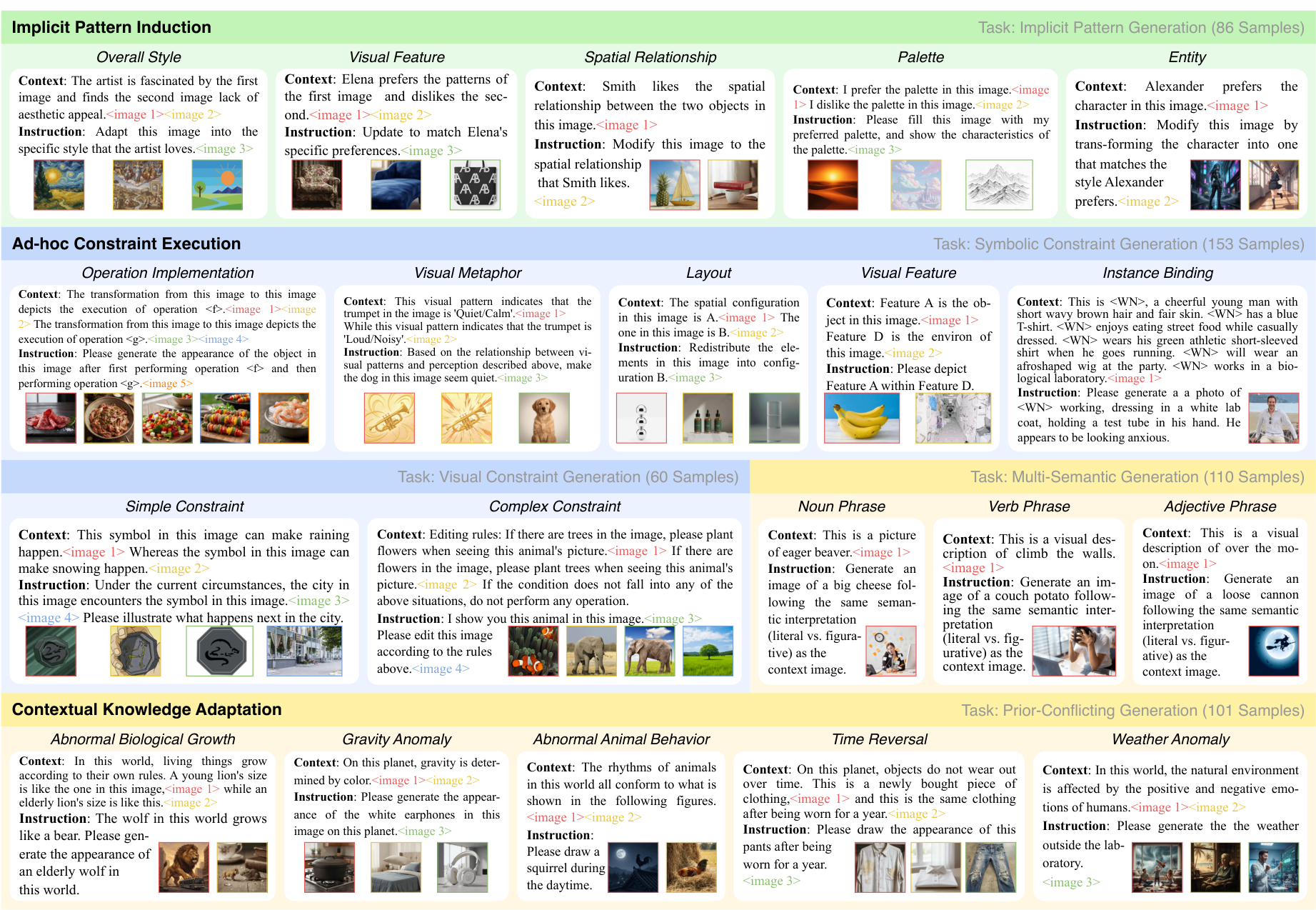
图 1:GENIUS 基准概览。它在结构上分为三个维度、五个任务和多种子任务。
目前该领域的研究存在三个空白:缺乏正式定义、基准测试不足以及系统性分析匮乏。为了填补这些空白,我们基于 Cattell-Horn-Carroll (CHC) 理论,提取了 GFI 的三个核心原语:(I) 归纳推理 ,(II) 抽象动态推理 ,以及 (III) 自适应抑制,并据此构建了 GENIUS 框架。
2. GENIUS 评测基准
2.1 基准概览
我们将 GFI 定义为视觉生成中三种核心能力的综合:
- 归纳隐式模式:从观察中提炼隐式模式和内在属性。
- 执行即兴约束:在即兴定义的视觉或符号约束边界内进行逻辑推理。
- 基于情景知识进行适应:根据情境线索进行调整,即使需要偏离既定的常识。
GENIUS 包含 510 个专家策划的样本,涵盖 20 个子任务。与优先考虑静态知识或安全性的基准不同,GENIUS 严格排除先验知识,纯粹量化模型解决新问题的能力。
2.2 基准构建
每个实例都包含多模态交错的情境。
- 隐式模式归纳:评估从情境中推断未声明的视觉偏好并应用于生成的能力。
- 即兴约束执行:分为视觉约束生成和符号约束生成。我们故意选择没有预先语义关联的元素(如定义一个蓝色方块为"移除物体"的操作),测试模型的抽象推理能力。
- 情景知识适应 :包括冲突先验生成 (如"物体重量由颜色决定")和多语义生成(辨别字面意思与隐喻,如"green hand"指新手还是绿色的手)。
2.3 评估指标
我们采用多模态大模型(LMM,如 Gemini-3-Pro)作为评判者,结合手动策划的提示(hints)进行混合评估。得分范围为 0(失败)到 2(完美):
- 规则符合度(Rule Compliance):衡量执行严格即兴规则的准确性。
- 视觉一致性(Visual Consistency):评估在动态推理过程中保持原始对象视觉身份的能力。
- 审美质量(Aesthetic Quality):确保输出符合基本的视觉现实感(如解剖逻辑、光照等)。
3. 实验
我们评估了 12 个代表性模型,包括开源模型(如 Qwen-Image-Edit-2511, GLM-Image, FLUX.2-dev, Bagel 等)和闭源模型(如 Nano Banana Pro, GPT-Image 等)。
3.1 主要结果
GFI 仍是当前模型的重大瓶颈。即使是表现最好的 Nano Banana Pro,总分也仅为 57.19。结果表明,开源模型在处理复杂推理任务时存在显著缺陷。
3.2 诊断分析
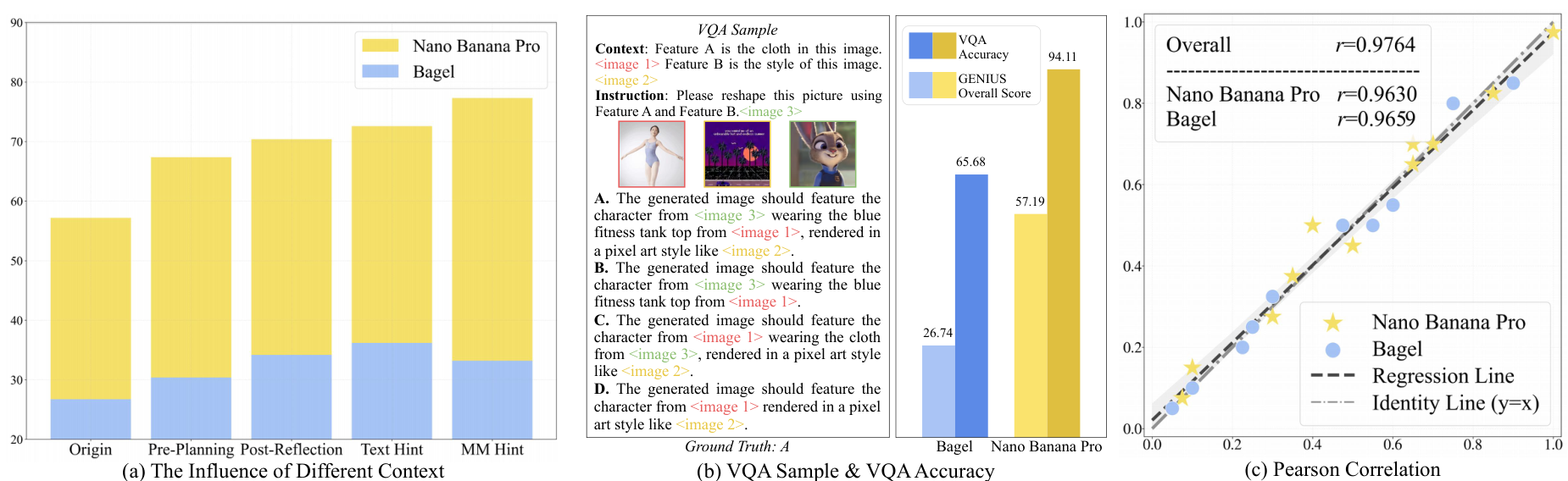
图 2:诊断分析与指标验证。(a) 不同情境设置下的性能对比。(b) 情境理解 (VQA) 与生成能力之间的差距分析。© 验证 LMM 作为评判者与人工评分的相关性。
分析发现,生成的失败主要源于执行差距而非理解缺陷。如图 2(b) 所示,模型在视觉问答(VQA)中表现良好,但在将其转化为合规的视觉输出时失败。这反映了"知道但画不出"的现象,可能是由于 UMM 架构中编码器的语义理解未能有效传播到生成解码器。
3.3 LMM 评判者的有效性
如图 2© 所示,LMM 评分与人类专家评分具有高度相关性(皮尔逊相关系数 r r r 超过 0.96),证明了该自动化评估框架的稳健性。
4. 潜在解决方案
4.1 实验观察
通过可视化 Bagel 模型的注意力分布(图 3 左侧),我们发现模型在处理失败样本时,注意力分布极其不合理,表现为不规则的噪声和随机峰值。这说明模型无法精确捕捉情境中的关键即兴规则,而是陷入了预训练的先验中。
4.2 理论分析
我们将上下文学习(ICL)视为一种隐式微调。对于采用 Mixture-of-Transformer 架构的 Bagel 模型,我们定义了层更新的特性:
定理 4.1 :层更新满足如下属性,其中偏置扰动 Δ b \Delta b Δb 和上采样算子扰动 Δ U p \Delta Up ΔUp 定义为:
L U p + Δ U p , b + Δ b ( u ′ , g ) = L U p , b ( u , g ) ( 1 ) \mathcal{L}{Up + \Delta Up,b + \Delta b}(u',g) = \mathcal{L}{Up,b}(u,g) \quad (1) LUp+ΔUp,b+Δb(u′,g)=LUp,b(u,g)(1)
Δ b = A ( u , g ) − A ( u ′ , g ) ( 2 ) \Delta b = \mathcal{A}(u,g) - \mathcal{A}(u',g) \quad (2) Δb=A(u,g)−A(u′,g)(2)
Δ U p = U p ( δ A ) N ( A ( u ′ , g ) ) ⊤ ∥ N ( A ( u ′ , g ) ) ∥ 2 , N ( x ) = x R M S ( x ) ( 3 ) \Delta Up = \frac{Up(\delta A)\mathcal{N}(\mathcal{A}(u',g))^\top}{\|\mathcal{N}(\mathcal{A}(u',g))\|^2}, \mathcal{N}(x) = \frac{x}{RMS(x)} \quad (3) ΔUp=∥N(A(u′,g))∥2Up(δA)N(A(u′,g))⊤,N(x)=RMS(x)x(3)
定理 4.2 :在第 ( i + 1 ) (i+1) (i+1) 次迭代中,参数遵循如下梯度下降更新规则:
{ U p i + 1 = U p i − h ∇ U p L i ( U p i ) , b i + 1 = b i − ∇ b ( t r ( δ i ⊤ b i ) ) ( 9 ) \left\{ \begin{array}{l l}{U p_{i + 1} = U p_{i} - h\nabla_{U p}L_{i}(U p_{i}),}\\ {b_{i + 1} = b_{i} - \nabla_{b}\left(\mathrm{tr}\left(\delta_{i}^{\top}b_{i}\right)\right)} \end{array} \right. \quad (9) {Upi+1=Upi−h∇UpLi(Upi),bi+1=bi−∇b(tr(δi⊤bi))(9)
这表明注意力权重的分布直接决定了隐式梯度的方向。如果不平衡的注意力导致噪声 token 权重过高,梯度更新就会偏离目标。
4.3 注意力调节机制
我们提出了一种无需训练的调节机制,通过抑制噪声 token 的注意力来修正隐式优化方向。

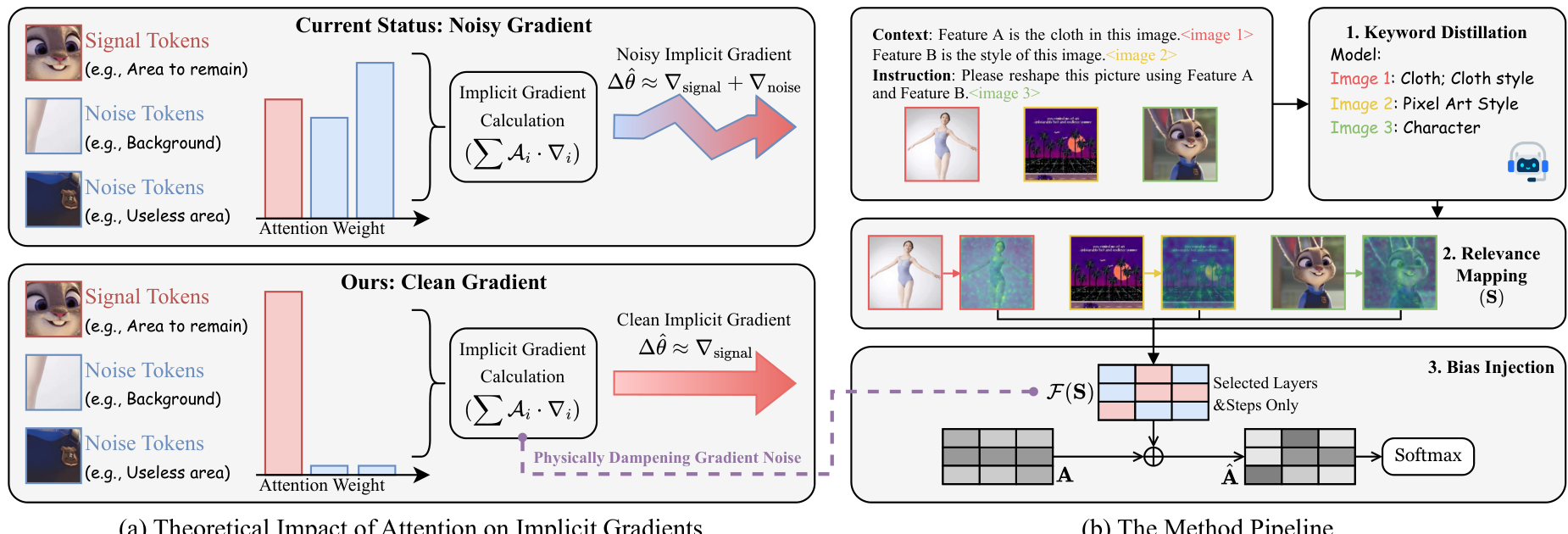
图 4:方法概览。(a) 注意力大小决定梯度范数;(b) 三阶段流水线:关键词提取、相关性映射、偏置注入。
该机制通过在注意力 logits 中注入空间偏置 F ( S ) \mathcal{F}(\mathbf{S}) F(S) 来实现:
A t t e n t i o n = s o f t m a x ( A + λ ⋅ F ( S ) d ) V ( 10 ) \mathrm{Attention} = \mathrm{softmax}\left(\frac{\mathbf{A} + \lambda\cdot\mathcal{F}(\mathbf{S})}{\sqrt{d}}\right)V \quad (10) Attention=softmax(d A+λ⋅F(S))V(10)
4.4 实验结果
定量结果(表 2)显示,该机制在 Bagel 模型上实现了总分 6.18 % 6.18\% 6.18% 的提升,成功激活了模型的潜在 GFI 能力,而无需更新参数。
5. 结论
本文推出了 GENIUS,这是首个系统量化生成式流体智能(GFI)的基准。通过对 12 个模型的评估,我们揭示了当前 SOTA 模型在即兴推理场景下的巨大差距。我们发现"执行差距"是失败的主因,并追溯到推理时的注意力机制缺陷。我们提出的无需训练的调整策略为提升 GFI 提供了新的范式。我们希望 GENIUS 能引导下一代模型从简单的知识记忆转向真正的通用智能。
Original Abstract: Unified Multimodal Models (UMMs) have shown remarkable progress in visual generation. Yet, existing benchmarks predominantly assess Crystallized Intelligence \textit{Crystallized Intelligence} Crystallized Intelligence, which relies on recalling accumulated knowledge and learned schemas. This focus overlooks Generative Fluid Intelligence (GFI) \textit{Generative Fluid Intelligence (GFI)} Generative Fluid Intelligence (GFI): the capacity to induce patterns, reason through constraints, and adapt to novel scenarios on the fly. To rigorously assess this capability, we introduce GENIUS \textbf{GENIUS} GENIUS ( GEN \textbf{GEN} GEN Fluid I \textbf{I} Intelligence Eval U \textbf{U} Uation S \textbf{S} Suite). We formalize GFI \textit{GFI} GFI as a synthesis of three primitives. These include Inducing Implicit Patterns \textit{Inducing Implicit Patterns} Inducing Implicit Patterns (e.g., inferring personalized visual preferences), Executing Ad-hoc Constraints \textit{Executing Ad-hoc Constraints} Executing Ad-hoc Constraints (e.g., visualizing abstract metaphors), and Adapting to Contextual Knowledge \textit{Adapting to Contextual Knowledge} Adapting to Contextual Knowledge (e.g., simulating counter-intuitive physics). Collectively, these primitives challenge models to solve problems grounded entirely in the immediate context. Our systematic evaluation of 12 representative models reveals significant performance deficits in these tasks. Crucially, our diagnostic analysis disentangles these failure modes. It demonstrates that deficits stem from limited context comprehension rather than insufficient intrinsic generative capability. To bridge this gap, we propose a training-free attention intervention strategy. Ultimately, GENIUS \textbf{GENIUS} GENIUS establishes a rigorous standard for GFI \textit{GFI} GFI, guiding the field beyond knowledge utilization toward dynamic, general-purpose reasoning. Our dataset and code will be released at: \href \href{https://github.com/arctanxarc/GENIUS}{https://github.com/arctanxarc/GENIUS} \href.
PDF Link: 2602.11144v1
部分平台可能图片显示异常,请以我的博客内容为准
