
它不像在"猜"代码,而是在"理解"项目
这句话不是我说的,是一位参与了 Code Arena 盲测的开发者朋友的原话。但测完 GLM-4.7 后,我太同意了。
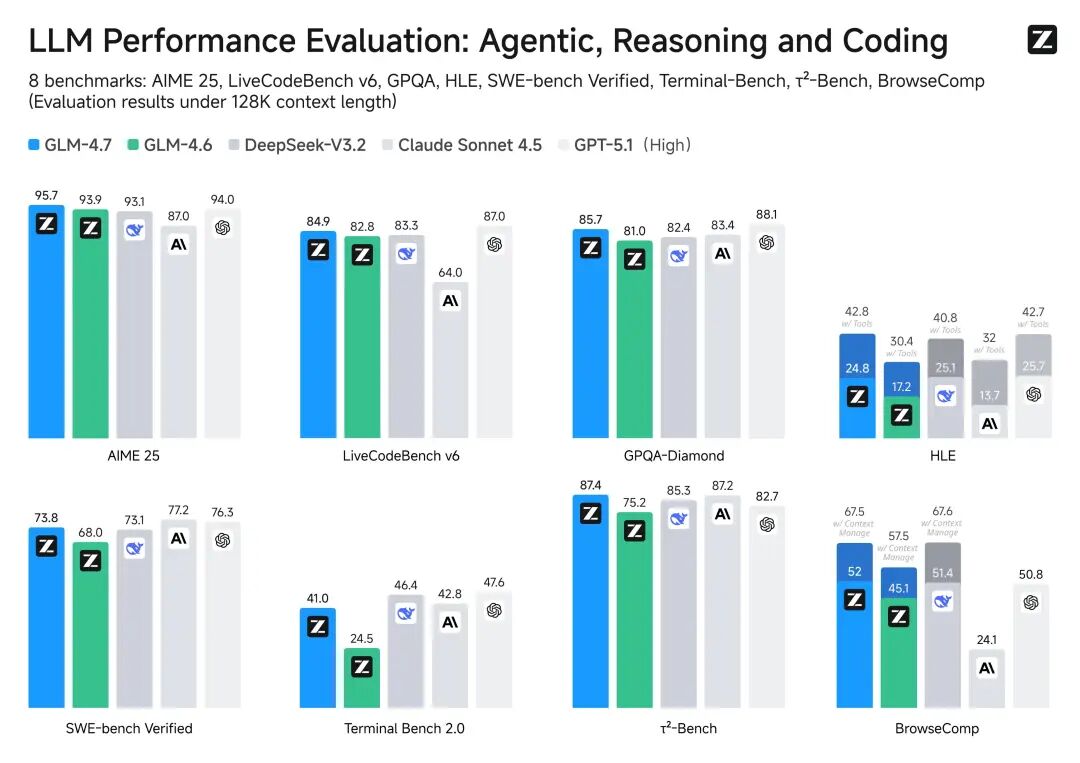
先说说最让我震惊的编程能力吧。官方说它在 SWE-bench 上干到了 73.8%,比上一代提升了 5.8 个百分点。但数字是冰冷的,体验才是真实的。
昨晚我扔给它一个真实场景:一个包含 Python、JavaScript、Rust 三种语言的混合项目,需要修复一个跨语言的序列化问题。在 GLM-4.6 时代,这种任务它大概会在第 7、8 步的时候开始"梦游"------要么忘了自己之前怎么分析的,要么就开始瞎改无关文件。
但 GLM-4.7 不一样。它先思考,再行动,而且最牛的是,它会把思考的整个过程保留下来。就像一个真正的资深工程师,在白板上画满了架构图,然后盯着这些图一步步执行,不会中间突然失忆。官方管这叫"保留式思考",我管这叫"终于像个人了"。
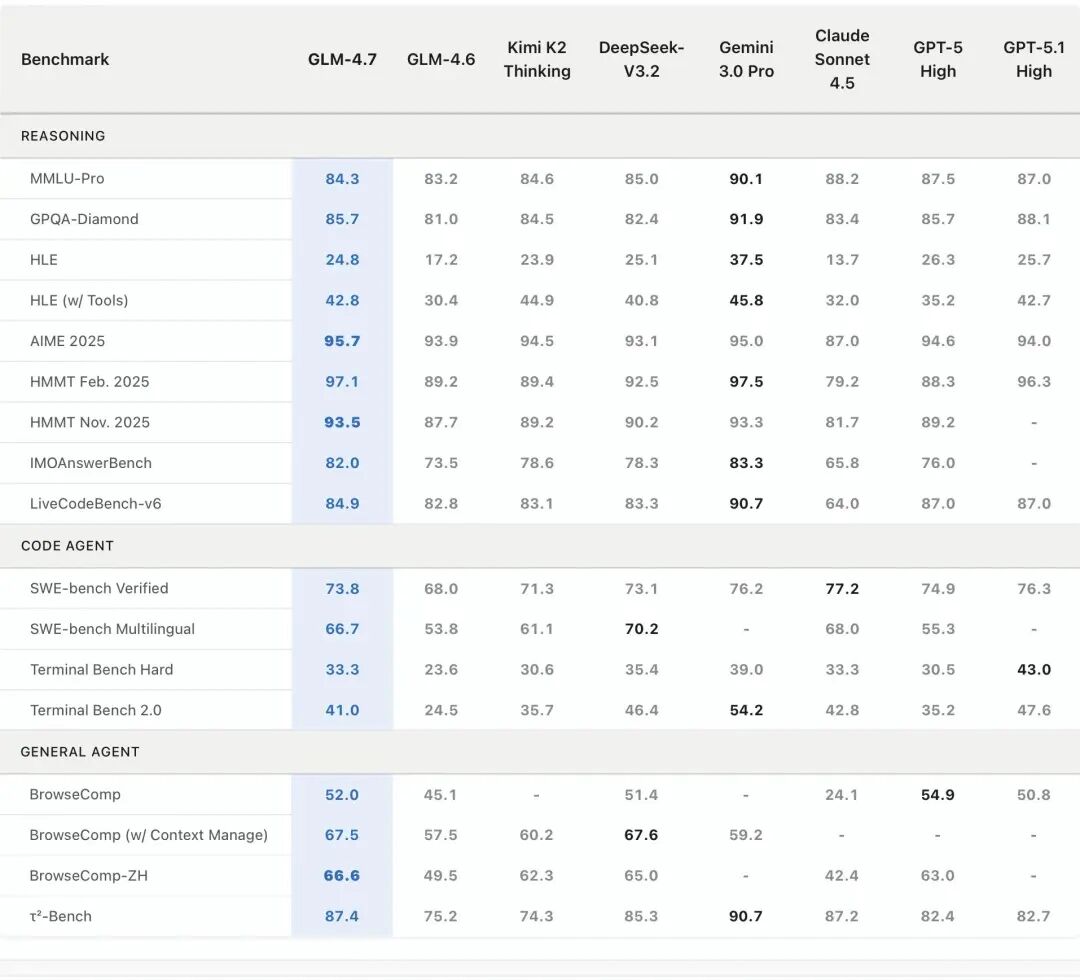
测试数据显示,在超过 15 步的复杂任务中,它的"跑偏率"不到 8%,而同类开源模型平均是 23%。这差距,就是你半夜能睡好觉和只能喝咖啡的区别。
LiveCodeBench V6:84.9 分,干翻了 Claude Sonnet
我知道你们想看benchmark,说实话我也看。GLM-4.7 在 LiveCodeBench V6 上拿了 84.9 分,不仅刷新了开源 SOTA,还超过了 Claude Sonnet 4.5。在 Code Arena 这个全球超 5000 名开发者参与的盲测平台,它位*开源第一、国产第一,综合得分甚至超过了传闻中的 GPT-5.2。
但benchmark就像相亲时的简历,真实相处才见人品。我让它写了一个数据可视化的网页,结果它生成的 UI 直接让我无语了------太好看了。不是那种油腻的渐变和动画,而是简洁、现代、有呼吸感的设计。官方说的"氛围编程"真不是吹牛,它好像真的理解了什么叫"好的设计"。
终端操作:像个老练的 DevOps
Terminal Bench 2.0 上 41% 的成绩(提升了 16.5%)背后是什么?我试了让它在 Docker 环境里部署一个微服务架构。以前的模型经常在 `cd` 命令后迷路,或者权限处理不当直接卡死。GLM-4.7 会自主规划路径跳转、处理权限问题、甚至懂得错误重试。就像一个老练的运维,沉默但可靠。
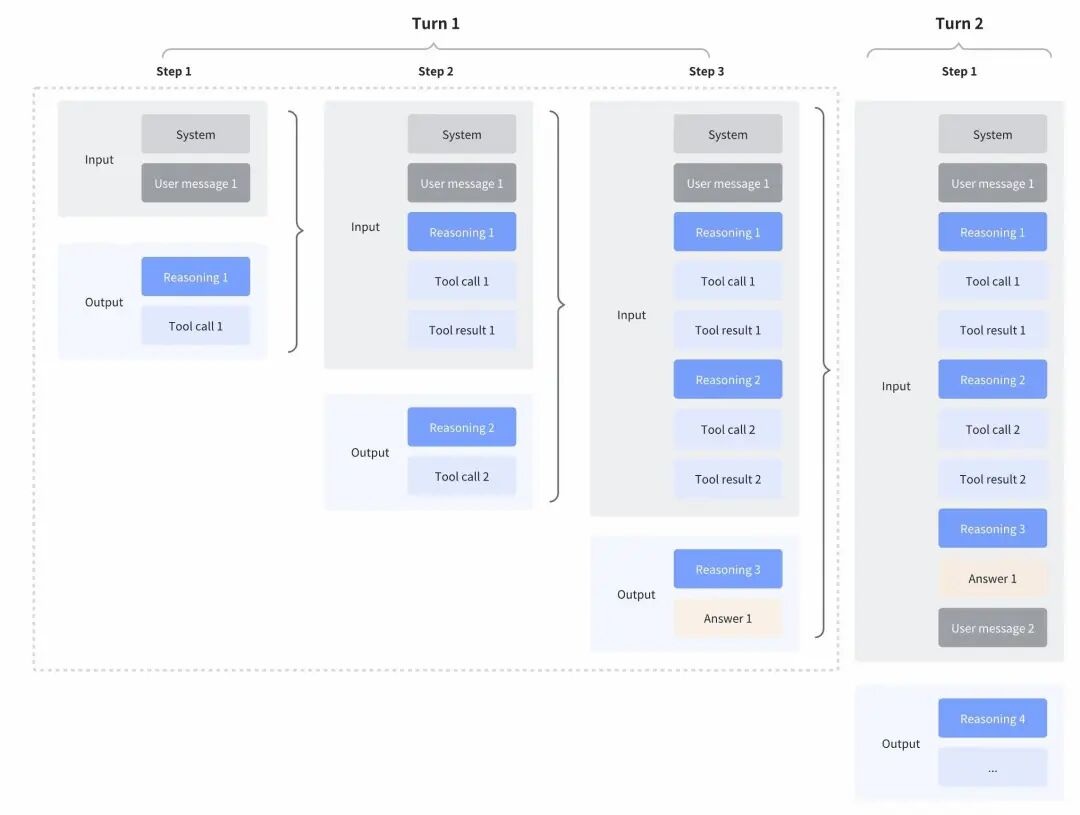
更爽的是,它现在支持轮级思考控制。简单说,简单任务你可以让它闭嘴直接干,complex 任务你可以让它多想几步。这意味着什么?意味着成本可控,速度可调。不想烧钱的时候,它就是个快枪手;遇到硬骨头,它又能变身沉思者。
推理能力:42.8% 的 HLE,但更重要的是...
Humanity's Last Exam(HLE)上 42.8% 的成绩,比上一代提升了 12.4 个百分点。这个数字背后,是它在数学和复杂推理上的巨大飞跃。我测了几个算法题,它不再只是给出答案,而是能讲清楚思路,甚至能指出题目本身的歧义。
但让我更惊喜的,是它在工具调用上的进步。在 BrowseComp 网页浏览任务中拿下 67.5 分,在 τ²-Bench 交互式工具调用评测中实现 87.4 分的开源 SOTA,超过了 Claude Sonnet 4.5。这意味着什么?意味着它不仅能写代码,还能自己查文档、自己调 API、自己解决问题。
写给还在观望的你
我知道,每次新模型发布,大家都有审美疲劳。"又超越了啊?""又第一了啊?"但 GLM-4.7 给我的感觉不一样。
它已经在 Claude Code、TRAE、Kilo Code、Cline、Roo Code这些主流编程框架里完成了深度适配。你可以直接把它接进你的工作流,不需要等,不需要额外配置。智谱这次是真想明白了:牛逼的技术,得让开发者用得爽才行。

对了,它现在已经在 z.ai 全栈开发模式中上线全新 Skills 模块,支持多模态任务的统一规划与协作执行。简单说,就是画画图、写写文、编编码,它能一起搞定。

最后说点感性的。测试完 GLM-4.7,我关上电脑,已经是深夜了。但奇怪的是,我没有往常熬夜后的疲惫,反而有点兴奋。就像当年第一次用上 Git,第一次看懂递归,第一次写出没有 Bug 的并发程序------那种"原来还可以这样"的兴奋。

AI 编程助手不是来取代我们的,是来让我们重新爱上编程的。GLM-4.7 让我感受到了这一点。
以上测试基于 GLM-4.7 版本,个人体验仅供参考。实际效果可能因项目复杂度而异,但...真的挺牛的。


更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程
