在 AI 开发圈,有个容易被忽视的"智商税":全量注入(Full Injection)。很多开发者习惯把所有 System Prompt 和工具定义一股脑塞给模型。结果就是:Token 飞涨、模型"幻觉"频发、响应慢得像上个世纪。用过"大龙虾"的小伙伴应该已经感受过了,原本速度很快的大模型,配置到"大龙虾"上面,就慢的跟蜗牛一样。其实,不是模型变慢了,超长的上下文,复杂的function call调用,让原本简单的任务变得十分的笨重。
在EchoMindBot的架构里,classify_intent 不是简单的过滤器,它是整个 Agent 的流量调度中枢。说白了可以让没那么聪明的模型,也可以成为我们的工作助手,用更小的"颗粒度",来提高模型处理问题的能力。
1. 痛点:Agent 的"注意力稀释"与成本黑洞
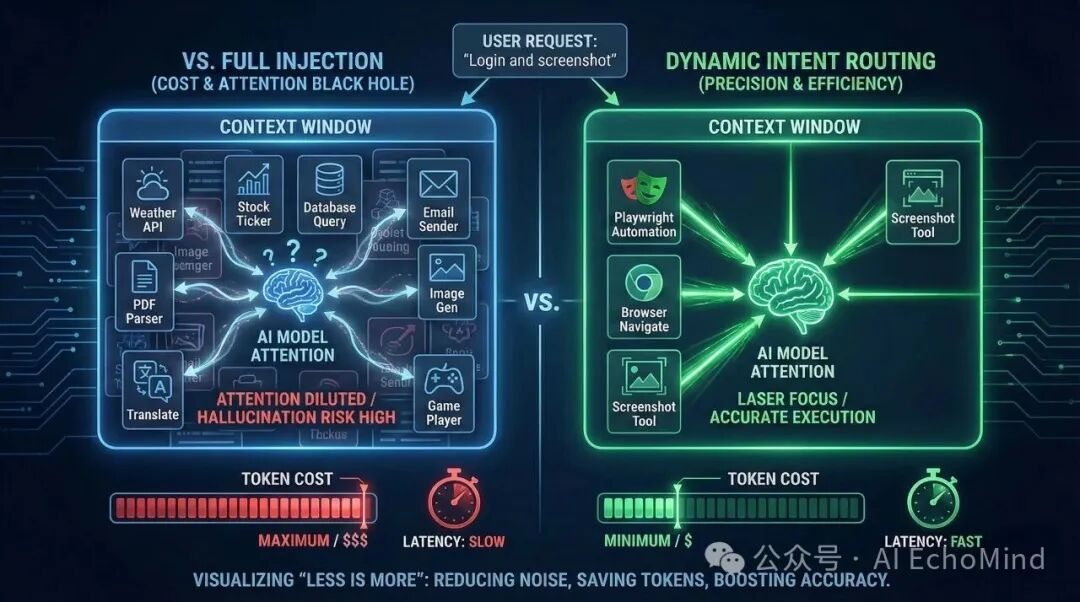
很多开发者在构建 Agent 时,容易陷入"全量注入(Full Injection)"的暴力逻辑:为了让 AI 随时待命,恨不得把所有的 API 文档和背景资料都拍在模型的脸上。这一点在skills盛行的当下尤为明显,看有些技术写的skills,你咋不把《新华字典》发给AI呢?能力调用的核心、指令的清晰、路径的明确,这些才是AI能准确执行的根本,而不是一句"帮我重构下系统"+"这里是所有项目的源码(skills):***"。
这种做法在实际工程中会引发两个致命的"黑洞":
A. 认知过载导致的"注意力稀释"
大模型虽然有很强的上下文处理能力,但它的有效注意力(Effective Attention)是有边际效应的。(上下文处理能力肯定是个大模型发展的必然路径,但是不是我们浪费算力的理由。)
- 选错"扳手":当 Prompt 中堆叠了 30 个工具定义时,模型极易产生"选择困难症"。原本一个简单的文件读取,它可能会绕弯路去调用搜索工具。工具选择的准确性,直接决定了最终呈现的效果。比如简单的一句系统指令就可以的"获取系统目录",你一定要通过OCR(计算机视觉)来实现,效果一定不尽如人意。
- 指令幻觉:过长的上下文会稀释 System Prompt 的权威性。模型开始"放飞自我",忽略核心约束,甚至在不该调用工具时强行编造参数。AI编程小白喜欢的大段大段的rules(规则),让AI写代码的时候只能用到1%的精力在你的业务需求,大量的算力在里面你的规则,当有冲突时,自动的会忽略你的真实需求。
B. 吞噬利润的"成本黑洞"
在商业化或高频使用场景下,全量注入无异于财务自杀。
- 冗余开销:如果每一句"你好"或"谢谢"都要背负 5000 Tokens 的工具定义,你支付的 Token 费用中有 99% 是在为重复的背景信息买单。这个情况,不管是用"大龙虾"的小伙伴,还是用cursor的小伙伴,应该都发现了,你简单的一句对话,可能几百万token就不翼而飞了。
- 首字延迟 (TTFT) 的惩罚:上下文每增加一倍,模型的预处理(Prefill)时间就会线性甚至指数级增长。对于用户来说,这种"思考感"带来的不是智能,而是迟钝。
2. 核心架构:三层意图分发机制
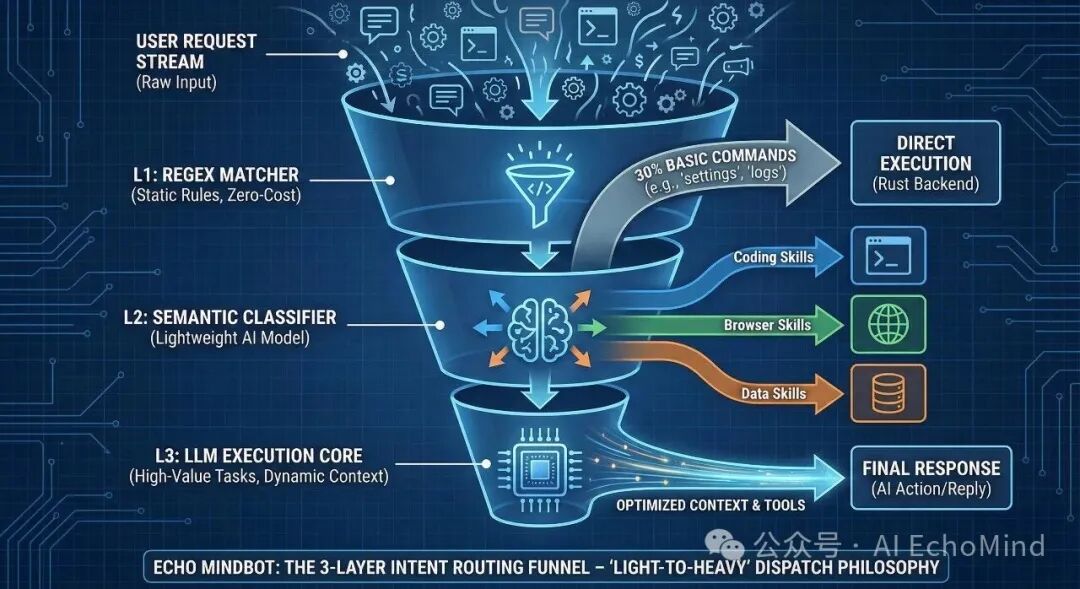
为了封堵这些黑洞,我在 src-tauri/src/ai.rs 中设计了一套"由轻到重"的路由体系,把昂贵的推理算力死死压在刀刃上:
L1:零成本正则/规则路由 (Static Regex & Local Logic)
这是系统的"反射神经"。针对高频、确定性的系统指令,我们完全不需要模型介入。这也是通过大量的调研和数据分析,其实绝大多数用户的需求没有这么复杂,什么"深度搜索"、"路径规划"可能在真实的业务场景中只占到5%不到的情况,所以,一个"聪明"的助理,要知道"钱"(算力)花在什么地方性价比最高。
- 处理逻辑:在 Rust 后端通过 RegexSet 或简单的字符串匹配捕获关键词(如:--version, open logs, clear memory)。
- 执行代价:0 Token,内存占用极低。
- 典型场景:开关设置、查看系统状态、基础的文件路径跳转。
L2:语义预判与技能路由 (Semantic Intent Router)
当用户输入进入"自然语言"范畴,系统会启动轻量级的语义预判。这一层的核心不是执行,而是"圈地"。
- 处理逻辑:调用一个极低延迟的模型(或本地加载的向量索引)对用户输入进行分类。
- 技能过滤:如果识别到意图是 Intent::BrowserAutomation,系统会瞬间屏蔽掉 SQL_Editor、Git_Master 等无关技能,只从 builtinSkills.ts 中挑选出 Playwright 相关的工具定义。
- 极致优化:这一步将原本 10k+ Tokens 的系统提示词压缩到了不到 500 Tokens,极大地降低了模型的首字延迟(TTFT)。
L3:动态上下文与工具闭环 (Dynamic ReAct Loop)
只有当任务进入"执行态",我们才会把最精简、最相关的技能包(Instruction + Tools)喂给最强的大模型。
- 处理逻辑:此时模型拿到的不是一个杂乱的工具箱,而是一份精准的"任务操作手册"。
- 执行优势:由于干扰项被 L2 层排除了,模型在 TOOL_CALL 阶段的准确率几乎达到 100%。它不会再因为看到 git_commit 和 browser_click 同时存在而产生逻辑混乱。
- 反馈回路:执行结果会通过 streaming.rs 实时回传,如果当前任务未结束,系统会维持该意图的"热度",直到任务闭环。
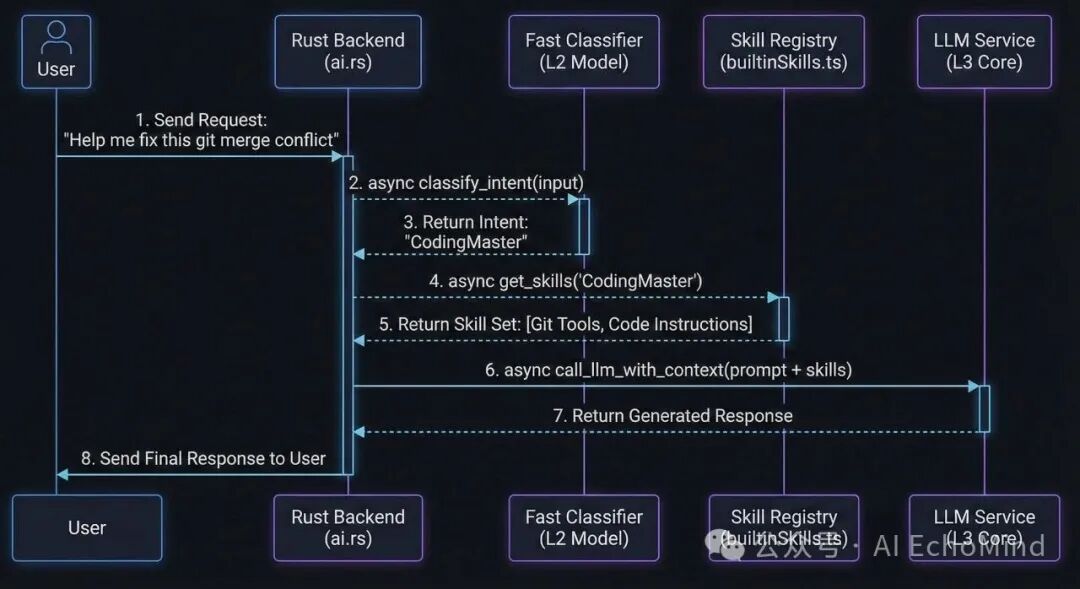
3. 代码实战:classify_intent 的 Rust 实现
这是我们在后端处理意图路由的核心逻辑。通过枚举(Enum)化管理意图,让代码结构极其清晰:
// ai.rs: 意图路由与按需加载
pub async fn dispatch_request(user_input: &str) -> Result<String, String> {
// 1. 快速分类
let intent = classify_intent(user_input).await?;
// 2. 动态加载技能包 (仅加载当前意图所需的 Tools & Instructions)
let skills_to_load = match intent {
Intent::WebAutomation => vec!["browser_automation", "web_fetch"],
Intent::FileSystem => vec!["file_manager", "search_local"],
Intent::CodingMaster => vec!["git_mcp", "code_executor"],
_ => vec![], // 默认纯聊模式
};
// 3. 构建最小化上下文:只注入选中的技能定义
let system_prompt = build_context_with_skills(skills_to_load);
// 4. 调用大模型 (此时上下文极其精简)
let response = call_llm(system_prompt, user_input).await?;
Ok(response)
}
4. 极致优化:状态机与 Token 压缩
除了路由分发,我们还在 streaming.rs 中引入了会话状态机:
- 意图继承:如果用户在"CodingMaster"模式下连续提问,系统会保持技能挂载,避免重复计算。
- Token 剪裁:对历史对话进行语义压缩,只保留关键的"事实摘要",将有限的上下文窗口留给真正复杂的任务。
结语:工程化的核心是"克制"
很多 Agent 看起来很聪明,其实是在用昂贵的 Token 堆砌假象。EchoMindBot的哲学是:用最轻量的逻辑,调动最强大的能力。
通过 classify_intent,我们成功将单次复杂任务的成本降低了70% 以上,同时把模型的任务成功率提升了近30%。因为对 AI 来说,"少即是多"。
啰嗦几句话,其实,AI大模型跟人一样,假装的勤劳是不能带来任何的价值的,我很信奉的一句话"在错误方向的努力,还不如原地休息"。不要让自己的"假装"勤奋来替代思考,就像一个优秀的职场精英,做事都是有自己的章法一样,AI的应用,也是要先规划而后动的。