目录
[1.1 单机困境与主从方案的诞生](#1.1 单机困境与主从方案的诞生)
[1.2 主从模式的技术缺陷](#1.2 主从模式的技术缺陷)
[2.1 设计理念与核心机制](#2.1 设计理念与核心机制)
[2.2 哨兵的三大核心职责](#2.2 哨兵的三大核心职责)
[2.3 哨兵的工作原理深度解析](#2.3 哨兵的工作原理深度解析)
[2.4 主观下线与客观下线:分布式共识的实践](#2.4 主观下线与客观下线:分布式共识的实践)
[2.5 哨兵模式的架构局限](#2.5 哨兵模式的架构局限)
[3.1 客户端分片:去中心化的开端](#3.1 客户端分片:去中心化的开端)
[3.2 Twemproxy:Twitter的工程实践](#3.2 Twemproxy:Twitter的工程实践)
[3.3 Codis:豌豆荚的创新之作](#3.3 Codis:豌豆荚的创新之作)
[四、Redis Cluster:官方的终极答案](#四、Redis Cluster:官方的终极答案)
[4.1 设计哲学:去中心化的P2P架构](#4.1 设计哲学:去中心化的P2P架构)
[4.2 哈希槽:优于一致性哈希的选择](#4.2 哈希槽:优于一致性哈希的选择)
[4.3 智能客户端与重定向机制](#4.3 智能客户端与重定向机制)
[4.4 故障检测与自动转移](#4.4 故障检测与自动转移)
[4.5 在线扩容与数据迁移](#4.5 在线扩容与数据迁移)
[4.6 使用场景与选型建议](#4.6 使用场景与选型建议)
引言:分布式系统中的永恒命题
在现代互联网架构中,单点故障(Single Point of Failure)始终是系统可用性的最大威胁。任何依赖单一节点的服务,都面临着一个残酷的现实:一旦这个节点失效,整个服务将陷入不可用状态。这不仅仅是技术问题,更是业务连续性的挑战。
Redis作为当今最流行的内存数据库,同样需要直面这一挑战。从最初的单机模式,到主从复制,再到哨兵模式,直至最终的Redis Cluster官方集群方案------Redis的演进历程,实际上就是分布式系统高可用性探索的缩影。本文将深入剖析Redis集群架构的技术演进脉络,探讨每种方案背后的设计权衡与技术洞察。
一、主从复制:高可用的起点
1.1 单机困境与主从方案的诞生
虽然Redis提供了RDB和AOF两种持久化机制,能够将内存数据持久化到磁盘,但这并未从根本上解决可用性问题。数据依然存储在单一服务器上,一旦发生硬件故障、网络分区或系统崩溃,服务将完全中断。更严重的是,单机架构无法实现读写分离,所有I/O请求都集中在同一个节点上,在高并发场景下极易成为性能瓶颈。
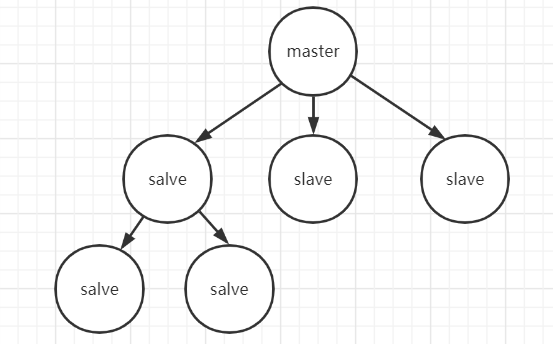
主从复制(Master-Slave Replication)的引入,标志着Redis向分布式架构迈出了第一步。这种模式通过数据冗余实现了两个核心目标:
- 数据备份与容灾: 主节点的数据变更实时同步到从节点,即使主节点宕机,数据也不会丢失
- 读写分离与负载均衡: 主节点处理写请求,从节点分担读请求,突破了单机I/O瓶颈
在架构设计上,主从模式支持一主多从的拓扑结构,甚至允许从节点级联其他从节点,形成树状复制层次。这种灵活性使得系统可以根据业务规模动态调整节点数量。
1.2 主从模式的技术缺陷
然而,主从模式存在一个致命缺陷:缺乏自动故障转移能力。当主节点故障时,必须依靠人工干预完成以下操作:
- 在从节点上执行 SLAVE NO ONE 命令,将其提升为新的主节点
- 修复原主节点后,执行 SLAVEOF 命令将其降级为从节点,重新加入集群
这种手动运维模式带来了两个严重问题:一是故障恢复时间长(通常需要分钟级别),二是依赖人的判断和操作,容易出错。在凌晨故障的情况下,甚至可能因为运维人员响应不及时而导致服务长时间中断。
二、哨兵模式:自动化故障转移的实现
2.1 设计理念与核心机制
哨兵模式(Sentinel)在Redis 2.6版本首次引入(2.8版本后趋于稳定),其核心思想是引入一个独立的监控进程,实现故障的自动发现和自动切换。从本质上讲,哨兵模式是在主从架构基础上增加了一个控制平面(Control Plane),将运维决策从人工转移到了自动化系统。
为了避免哨兵本身成为新的单点,实际部署中通常使用多哨兵集群,形成分布式监控网络。哨兵之间通过互相监控和协调,共同完成故障判定和主从切换。
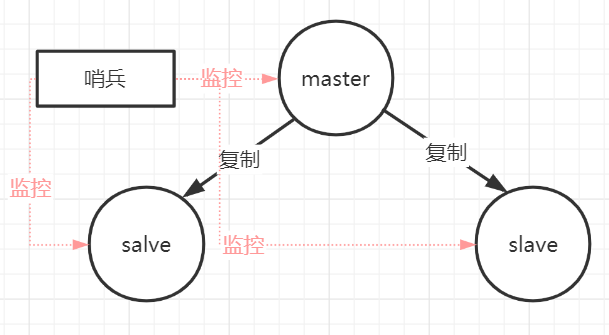
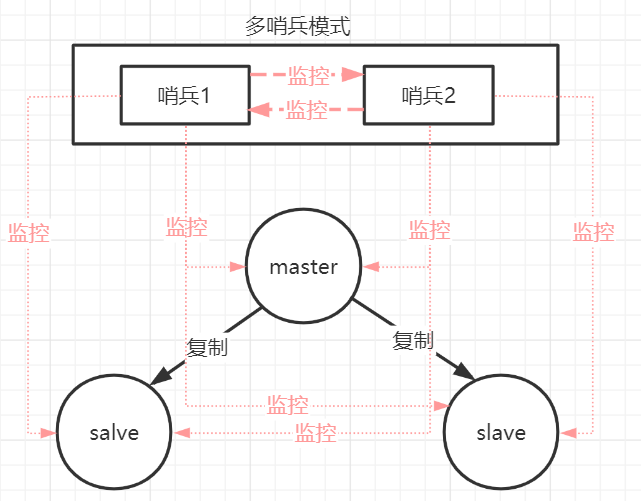
2.2 哨兵的三大核心职责
- 健康监控: 持续监测主节点、从节点以及其他哨兵的存活状态
- 故障判定: 通过主观下线和客观下线两级判断机制,准确识别节点故障
- 自动切换: 在确认主节点故障后,自动选举新主节点并通知所有客户端
2.3 哨兵的工作原理深度解析
哨兵启动时通过配置文件发现需要监控的主节点。值得注意的是,配置文件中只需要指定主节点信息,哨兵会通过 INFO 命令自动发现所有从节点,这体现了分布式系统中的服务发现(Service Discovery)设计模式。
哨兵与Redis节点建立连接后,会执行三个周期性任务:
- 每10 秒发送INFO 命令: 获取节点拓扑变化,发现新增节点或角色变更
- 每2 秒向_sentinel_:hello 频道发布消息: 广播自己的监控数据,实现哨兵间的互相发现和信息同步
- 每1 秒发送PING 命令: 通过心跳检测实时监控所有节点的健康状态
这种多频率的监控策略体现了分布式系统中的一个重要原则:不同类型的信息需要不同的同步频率。拓扑变化相对缓慢(10秒),哨兵发现需要较快(2秒),而故障检测必须实时(1秒)。
2.4 主观下线与客观下线:分布式共识的实践
哨兵模式引入了一个精妙的两阶段故障判定机制,这在分布式系统设计中具有重要的借鉴意义。
主观下线(Subjectively Down, SDOWN) : 单个哨兵根据自己的观察判断节点失效。当PING命令在指定时间(down-after-milliseconds)内未得到响应时,该哨兵认为节点主观下线。
客观下线(Objectively Down, ODOWN) : 多数哨兵达成共识,确认节点确实失效。当主观下线的哨兵询问其他哨兵并获得足够数量(quorum)的确认后,节点被标记为客观下线。
这种设计避免了因网络抖动或单个哨兵故障导致的误判。只有在多数哨兵达成一致时,才会触发昂贵的故障转移操作,这本质上是分布式共识算法的一个简化实现。
一旦主节点被判定为客观下线,就会启动自动故障转移流程:
- 选举领导者哨兵: 哨兵间通过Raft算法选出一个领导者负责故障转移
- 选择新主节点: 根据优先级、复制偏移量和run ID依次筛选最佳候选者
- 执行晋升操作: 向选中的从节点发送SLAVEOF NO ONE命令,将其提升为主节点
- 更新集群拓扑: 通知其他从节点切换主节点,并通过发布/订阅机制通知客户端
2.5 哨兵模式的架构局限
尽管哨兵模式实现了自动故障转移,但仍然存在三个本质性的限制:
- 中心化的写入瓶颈: 只有一个主节点接收写请求,写入吞吐量受限于单机性能
- 数据全量复制: 每个节点存储完整数据集,内存利用率低,无法实现真正的水平扩展
- 故障转移窗口期: 在选举新主节点期间,写操作会短暂不可用(通常几秒钟)
这些限制推动了数据分片技术的发展,也催生了下一代Redis集群方案的诞生。
三、社区方案的百花齐放:从客户端到代理层
Redis官方集群方案(Redis Cluster)直到2015年才随3.0版本正式发布。在此之前的漫长等待期,各大互联网公司面临着相同的挑战:如何实现Redis的数据分片和水平扩展?在缺乏官方支持的情况下,社区涌现出了多种创新性的解决方案,这些方案代表了分布式系统设计中的不同权衡路径。
3.1 客户端分片:去中心化的开端
架构设计
客户端分片将路由逻辑完全下沉到客户端库(如Jedis的ShardedJedis)。每个客户端维护完整的节点拓扑信息,通过预定义的哈希算法(通常是一致性哈希)决定Key应该路由到哪个Redis实例。
一致性哈希算法的引入解决了传统模运算的一个关键问题:在节点数量变化时,传统的hash(key) % N方法会导致几乎所有Key重新映射,引发雪崩式的缓存失效。而一致性哈希通过将Key和节点都映射到一个环形空间,使得节点增减只影响相邻节点的数据,最小化了数据迁移成本。
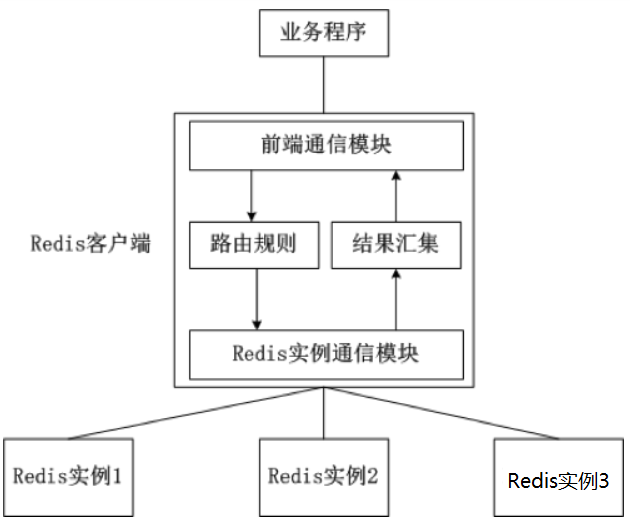
技术优势
- 架构简单透明: 所有逻辑在客户端可控,无需引入额外组件
- 性能开销最小: 客户端直连Redis,没有中间层的网络跳转和序列化开销
- 节点独立性强: Redis实例之间完全解耦,故障影响范围有限
致命缺陷
然而,客户端分片的缺陷也同样明显:
- 静态配置困境: 节点拓扑变化时,需要修改所有客户端配置并重启,运维成本极高
- 多语言维护噩梦: 在多语言技术栈的企业中,需要在Java、PHP、Python等多个客户端库中实现和维护相同的分片逻辑
- 缺乏弹性伸缩: 动态扩缩容几乎不可行,每次调整都是一次重大变更
这些问题推动了中间层代理方案的出现------将分片逻辑从客户端剥离,集中到独立的代理层管理。
3.2 代理分片-Twemproxy:Twitter的工程实践
2012年,Twitter开源了Twemproxy(又称nutcracker),这是第一个被广泛采用的Redis代理解决方案。Twemproxy本质上是将客户端分片的逻辑提升到了独立的代理层,客户端只需要连接代理,无需关心后端Redis集群的拓扑结构。
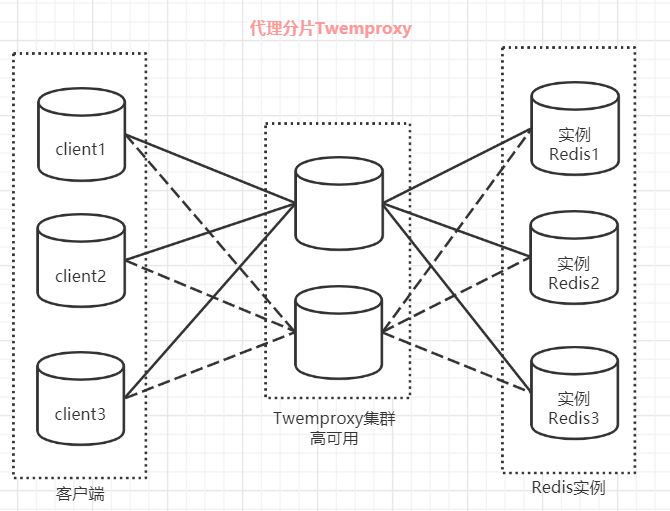
架构创新
Twemproxy充当了一个智能路由器的角色:接收客户端请求,根据一致性哈希算法路由到对应的Redis实例,聚合结果后返回。这种设计带来了显著的改进:
- 客户端零改造: 应用程序像连接单机Redis一样连接代理,无需修改代码
- 连接池复用: 代理层维护与Redis的长连接池,降低了连接开销
- 故障自动摘除: 能够检测并摘除失效节点,提升了系统韧性
工程局限
尽管Twemproxy解决了客户端分片的诸多问题,但也引入了新的挑战:
- 性能损耗: 每个请求都需要经过代理层的转发,增加了网络延迟和CPU开销
- 运维盲点: 缺乏完善的监控和管理界面,故障诊断困难
- 扩容之痛: 最大的痛点在于无法在线扩容,增减节点需要停服维护,这对于7x24小时运行的互联网服务来说几乎是不可接受的
Twemproxy的扩容痛点催生了下一代解决方案的诞生。
3.3 Codis:豌豆荚的创新之作
2014年,豌豆荚开源了Codis,这是中国开发者对Redis集群问题的一次突破性探索。Codis不仅解决了Twemproxy的扩容难题,还在架构设计上展现出更高的完整性。
核心创新:Slot机制
Codis引入了预分片(Pre-sharding)的设计理念,这是其最大的创新点。系统启动时预先创建1024个虚拟槽位(Slot),每个Key通过CRC32哈希后模1024映射到具体的Slot,Slot再映射到Redis Server Group。
这种三层映射架构(Key → Slot → Server Group)解耦了数据分布和物理节点的关系,使得在线迁移成为可能。当需要扩容时,只需要将部分Slot从原有Server Group迁移到新Server Group,Key的哈希结果不变,只是Slot的归属发生了变化。
架构完整性
Codis提供了一套完整的分布式系统解决方案:
- Codis Proxy : 无状态的代理层,可水平扩展
- Codis Dashboard : 集中式管理平台,提供图形化运维界面
- Codis FE : 前端展示,监控集群状态
- Codis HA : 可选的高可用组件,自动处理主从切换
- ZooKeeper/Etcd : 用于存储集群元数据和实现分布式协调
数据迁移的工程艺术
Codis的在线数据迁移是一个工程杰作。迁移过程中,源Server Group和目标Server Group同时服务:新写入的Key直接路由到目标,旧Key则在首次访问时异步迁移。这种渐进式迁移策略最大程度地降低了对业务的影响。
管理员可以通过两种方式触发Slot重新分配:
- 手动指定: 通过Codisconfig工具精确控制每个Server Group的Slot范围
- 自动均衡: 使用rebalance功能,根据内存使用情况自动分配Slot,实现负载均衡
架构权衡
Codis的设计也存在一些权衡。它依赖外部协调服务(ZooKeeper/Etcd),增加了系统复杂度;主从切换默认需要手动操作(除非启用Codis HA),在一致性和可用性之间选择了谨慎的立场。但这些权衡都是合理的------分布式系统本就是在CAP定理的约束下寻找最佳平衡点。
四、Redis Cluster:官方的终极答案
2015年,Redis 3.0正式发布,带来了期待已久的官方集群方案------Redis Cluster。这不仅是功能的补充,更代表了Redis团队对分布式系统设计的深刻理解和独到见解。
4.1 设计哲学:去中心化的P2P架构
Redis Cluster采用了完全去中心化的P2P(Peer-to-Peer)架构,这与Codis等方案的中心化管理形成了鲜明对比。在Redis Cluster中:
- 无单点依赖: 不依赖任何外部协调服务,集群元数据通过Gossip协议在节点间传播
- 多主架构: 采用多主多从模式,每个主节点负责一部分数据分片,写入能力真正实现了水平扩展
- 客户端直连: 客户端无需通过代理,可以直接连接任何节点,通过重定向机制找到数据所在节点
官方推荐至少部署3个主节点(通常配置为3主3从),这是因为故障转移需要超过半数节点投票,低于3节点无法形成有效的多数派。
4.2 哈希槽:优于一致性哈希的选择
Redis Cluster没有采用业界流行的一致性哈希算法,而是设计了更简洁的哈希槽(Hash Slot)机制。集群预先分配16384个槽位(0-16383),每个Key通过CRC16(key) % 16384映射到具体的槽,每个主节点负责一部分槽的数据。
为什么是16384个槽?这个数字的选择经过精心设计:
- 心跳包大小: 16384个槽的位图只需2KB,能够在心跳包中高效传输
- 集群规模: Redis官方认为集群不太可能超过1000个节点,16384已经足够精细的粒度
- 计算效率: 16384 = 2^14,模运算可以通过位运算优化
4.3 智能客户端与重定向机制
Redis Cluster的客户端设计体现了分布式系统中的一个重要模式:智能客户端。客户端维护一份槽位到节点的映射表,首次访问时通过以下机制更新和纠正:
- MOVED 重定向: 当Key所在的槽不在当前节点时,返回MOVED错误,告知客户端正确的节点地址
- ASK 重定向: 在槽迁移过程中,如果Key已经迁移但槽还未完全迁移,返回ASK错误,引导客户端临时访问目标节点
这种设计将路由复杂度分摊到客户端和服务端,避免了中心化代理的性能瓶颈,同时通过缓存映射表大幅减少了重定向开销。
4.4 故障检测与自动转移
Redis Cluster继承了哨兵模式的故障检测机制,但实现方式更加轻量。所有节点通过Gossip协议互相监控,当超过半数节点认为某主节点下线时,自动从其从节点中选举出新主节点。
与哨兵模式不同,这里的投票是由Redis节点本身完成的,而非独立的监控进程。这种设计简化了架构,但也意味着节点数量必须足够(通常至少3个主节点)才能形成有效的多数派决策。
4.5 在线扩容与数据迁移
Redis Cluster支持在线扩缩容,这是其相对于早期方案的重大优势。管理员可以通过以下命令动态调整集群:
- CLUSTER ADDSLOTS : 为节点分配槽位
- CLUSTER SETSLOT : 迁移槽位到新节点
- MIGRATE : 原子性地迁移Key
迁移过程中,源节点和目标节点协同工作,通过ASK重定向机制保证数据的可访问性,整个过程对客户端几乎透明。
4.6 使用场景与选型建议
Redis Cluster适合以下场景:
- 海量数据存储: 单机内存无法容纳全部数据时,通过分片实现水平扩展
- 高并发写入: 多主架构突破单机写入瓶颈
- 高可用要求: 自动故障转移,RTO(恢复时间目标)可控制在秒级
但需要注意的是,对于数据量不大(单机可容纳)的场景,哨兵模式可能是更简单的选择。Redis Cluster的复杂度主要体现在运维和调试上,引入它应当基于明确的扩展性需求。
五、总结:架构演进的启示
Redis集群架构的演进历程,是一部分布式系统设计的微缩史。从单机到主从,从哨兵到分片,从社区方案到官方集群,每一步都是对可用性、可扩展性和一致性的不断权衡与优化。
关键洞察
- 没有银弹: 每种方案都有其适用场景和局限性,选型需要基于具体业务需求
- 架构权衡: CAP定理始终生效,不同方案在一致性、可用性和分区容错性之间做出了不同选择
- 演进而非革命: Redis的方案演进是渐进式的,每个新方案都在解决前一代的核心痛点
- 去中心化趋势: 从中心化的哨兵到完全P2P的Cluster,反映了分布式系统设计理念的转变
选型指南
- 数据量 < 单机内存容量 + 读多写少: 主从模式 + 哨兵
- 数据量 > 单机内存容量 + 需要在线扩容: Redis Cluster
- 已有Codis 运维体系 + 对运维界面有需求: 继续使用Codis
- 极简场景 + 可接受静态配置: 客户端分片或Twemproxy
最后,值得强调的是:技术选型永远不是单纯的技术问题,它还涉及团队能力、运维成本、业务特点等多个维度。理解每种方案背后的设计思想和权衡,比记住具体的配置参数更加重要。