🎯 共享存储概述
什么是共享存储?
共享存储 是指多台服务器可以同时访问的存储系统,是实现高可用集群的关键组件。
为什么需要共享存储?
- 高可用与故障转移:应用从节点 A 切到节点 B 时,若数据只在 A 本地盘上,B 拿不到;共享存储让多节点看到同一份数据,切换后无需搬数据即可继续服务。
- 多节点同时读写:部分业务需要多台机器同时访问同一套数据(如共享配置、队列、数据库集群),只有「多机可见、一致视图」的存储才能满足。
- 统一管理:存储集中在一处(或通过网络暴露),扩容、备份、快照可以在存储侧统一做,而不是每台机器各管各的。
因此共享存储不是「可有可无」,而是多节点集群要同时做到高可用和共享数据时的基础。
共享存储 vs 复制存储(如 DRBD)对比
| 维度 | 共享存储(iSCSI + GFS2 + cLVM) | 复制存储(如 DRBD) |
|---|---|---|
| 数据位置 | 一份数据在存储上,多机通过网络访问 | 每节点一份副本,块级同步 |
| 多机写入 | 支持(集群文件系统协调) | 通常主从,主写从同步;双主需应用/FS 协调 |
| 存储依赖 | 依赖集中式/网络存储(Target) | 每节点本地盘,无单点存储 |
| 网络 | 存读写在存储网络上 | 同步流量在节点间 |
| 故障影响 | 存储或网络故障影响所有节点 | 单节点故障不影响其他节点访问本地副本 |
| 典型场景 | 多机共享同一命名空间、强一致 | 主从高可用、跨机房复制 |
| 本方案 | ✅ 采用 | 不采用(可与共享存储组合做异地复制) |
共享存储适合「多机要看到同一份数据、同时读写」;复制存储适合「主备切换、异地容灾」。二者也可结合:例如共享存储做主数据,DRBD 做异步复制到远端。
生活类比:
- iSCSI = 把仓库变成可以快递配送的
- cLVM = 灵活的分区管理,可以随时调整大小
- GFS2 = 多人可以同时使用的仓库管理系统
三大组件对比
| 组件 | 层次 | 功能 | 生活类比 |
|---|---|---|---|
| iSCSI | 网络传输层 | 把磁盘变成网络可访问 | 仓库的快递系统 |
| cLVM | 逻辑管理层 | 灵活的卷管理 | 灵活的货架系统 |
| GFS2 | 文件系统层 | 多机同时读写 | 多人协作的管理规则 |
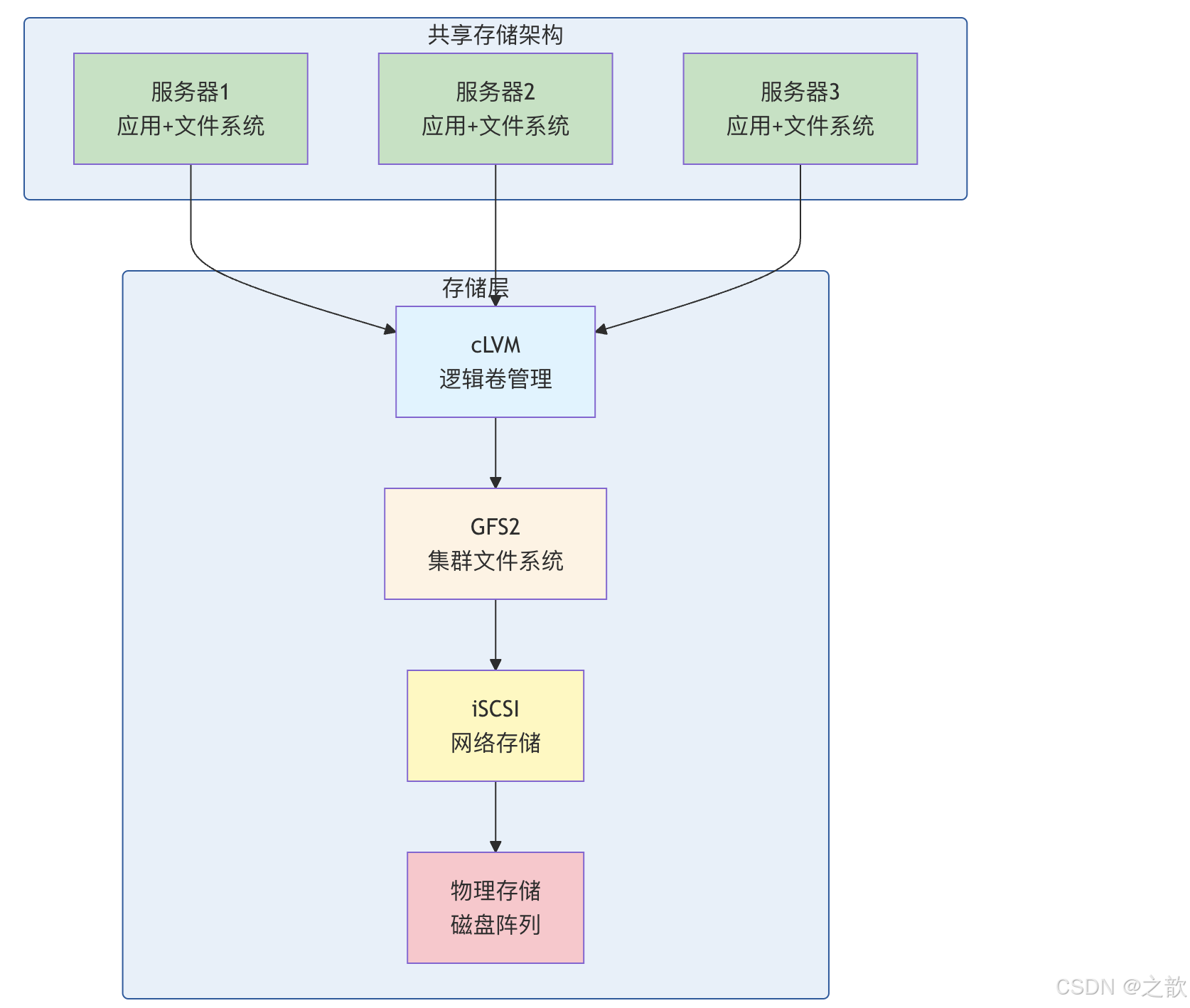
为什么是「iSCSI + cLVM + GFS2」这三层?
- iSCSI :解决「存储不在本机」的问题------用 IP 网络把远程磁盘当成本地块设备用,距离和拓扑灵活,成本比专用 FC 低。没有 iSCSI(或 FC 等)就没有多机共享的块设备。
- cLVM :块设备裸用不方便(分区固定、难扩容)。LVM 提供卷、快照、扩容,但普通 LVM 只考虑单机;多机共享同一块设备时,元数据(VG/LV 信息)必须一致,否则 A 节点建了 LV、B 节点不知道就会冲突。cLVM 用集群锁(DLM)保证多节点看到的 LVM 视图一致,所以需要 cLVM 这一层。
- GFS2 :有了共享块设备 + 共享卷,还要在之上建文件系统 。普通 ext4/XFS 假定「只有我这台机器在用这块盘」,多机同时挂载会立刻乱掉。GFS2 是集群感知的文件系统:用 DLM 协调元数据和缓存,多机同时挂载、同时读写,仍能保证一致。所以共享存储栈最上层必须是 GFS2(或 OCFS2 等)这类集群文件系统。
三层缺一不可:iSCSI 提供共享块,cLVM 管理共享卷,GFS2 提供多机一致的文件视图。
官方支持与产品依赖(来源:Red Hat 文档)
在 RHEL 中,共享存储能力依赖以下附加组件与限制(详见 Red Hat 文档):
| 项目 | 说明 |
|---|---|
| High Availability Add-On | 高可用附加组件,提供集群管理(Corosync/Pacemaker)、DLM 等,GFS2 与 cLVM 依赖该组件。 |
| Resilient Storage Add-On | 弹性存储附加组件,提供 GFS2、cLVM(clvmd)等,需与 HA 附加组件配合使用。 |
| GFS2 支持上限 | 文件系统最大 100 TB (当前支持值);理论架构为 64 位,可支持更大容量。节点数:x86/Power8 最多 16 节点 ,s390x 下 z/VM 最多 4 节点。 |
| 单节点 GFS2 | RHEL 不支持将 GFS2 作为单机文件系统使用;单机场景建议使用 XFS/ext4 等。仅支持单节点挂载 GFS2 集群文件系统的快照(如用于备份)。 |
| GFS2 底层存储 | 官方仅支持在 CLVM 逻辑卷上创建 GFS2;所有集群节点均需能访问该共享存储,非对称访问(部分节点无共享存储)不受支持。 |
🌐 iSCSI 详解
什么是 iSCSI?
iSCSI (Internet Small Computer System Interface) 是一种基于 IP 协议的块级存储网络协议,让 SCSI 命令可以通过 IP 网络传输。协议由 IETF 标准化:RFC 3720 (2004 年原始规范)已被 RFC 7143 (2014 年 consolidated 版本)取代;命名与发现见 RFC 3721。iSCSI 将 SCSI 映射到 TCP/IP,实现与 SAM-2(SCSI 架构模型)兼容的块存储访问。
为什么用块级(iSCSI)而不是文件级(NFS/SMB)?
- 块级 :把「一整块磁盘/卷」通过网络暴露给主机,主机上看到的是
/dev/sdX一样的块设备,上面自己建分区、LVM、文件系统。延迟和语义与本地盘一致,适合数据库、集群文件系统、需要精确控制 IO 的场景。 - 文件级(NFS/SMB):服务端已经建好文件系统,客户端直接挂载目录、读写文件。简单易用,但多机共享时通常要配合 NFS 锁或应用自己协调;且 IO 路径多一层、延迟和一致性由服务端决定。
- 选 iSCSI 的典型原因 :要做 GFS2/cLVM 或数据库直接跑在块设备上时,必须用块级存储;且 iSCSI 走 IP,无需专用 HBA 和光纤,成本低、易扩展。若只是「多机读同一批文件」且不需要集群文件系统,用 NFS 也可以。
块级 vs 文件级 vs 对象存储 对比
| 维度 | 块级(iSCSI/FC) | 文件级(NFS/SMB) | 对象存储(S3 兼容) |
|---|---|---|---|
| 暴露单位 | 块设备(LUN) | 目录/文件 | Bucket + 对象(键值) |
| 主机侧 | 分区/LVM/文件系统自建 | 直接挂载目录读写文件 | API 读写对象 |
| 多机共享 | 需集群文件系统(GFS2 等) | NFS 锁或应用协调 | 天然多端访问 |
| 延迟 | 低,接近本地盘 | 受网络与服务端影响 | 通常高于块/文件 |
| 典型场景 | 数据库、GFS2/cLVM、VM 磁盘 | 共享目录、首页、配置 | 备份、归档、大数据 |
| 本方案是否采用 | ✅ 采用(iSCSI) | ❌ 不采用 | ❌ 不采用 |
为什么需要 LUN、IQN、Portal?
- LUN(Logical Unit Number):一个 Target 可以导出多块「逻辑盘」,每块用一个 LUN 编号区分。Initiator 登录后看到多个 LUN,就像一块卡上有多块盘------这样一台存储服务器可以给多台主机、多个卷,按 LUN 隔离。
- IQN(iSCSI Qualified Name):在 IP 网络里要唯一标识「谁是谁」------哪台是 Initiator、哪台是 Target,避免串台。IQN 是协议规定的命名格式,发现、认证、ACL 都靠它。
- Portal(IP:端口):Initiator 要连到 Target 的哪个地址、哪个端口(默认 3260),Portal 就是「入口」。多网卡、多路径时可以配置多个 Portal,实现冗余或负载分担。
iSCSI
IP 网络
服务器
Initiator
存储设备
Target
传统 SCSI
SCSI 线缆
服务器
存储设备
核心概念:
| 术语 | 说明 | 生活类比 |
|---|---|---|
| Initiator | 发起端,客户端(RHEL 上由 iscsi-initiator-utils 提供) | 仓库的顾客 |
| Target | 目标端,服务端(RHEL 上常用 targetcli / LIO) | 仓库管理员 |
| LUN | 逻辑单元号(Logical Unit Number) | 具体的货架编号 |
| IQN | iSCSI 限定名称(RFC 3721 规定格式,如 iqn.日期.反向域:标识) | 身份证号 |
| Portal | 门户,IP:端口(默认 3260/tcp) | 仓库的入口地址 |
RHEL 配置可参考:Configuring an iSCSI target、Configuring an iSCSI initiator。
iSCSI vs 传统存储
传统 SCSI
专用线缆
距离受限
需要专用卡
成本较高
iSCSI
基于 IP 网络
距离无限制
使用现有网络
成本较低
| 特性 | iSCSI | 传统 SCSI / FC |
|---|---|---|
| 传输介质 | IP 网络 | 专用线缆 / 光纤 |
| 传输距离 | 理论无限制 | 几十米 |
| 成本 | 低 | 高 |
| 性能 | 受网络影响 | 稳定高速 |
| 适用场景 | 中小型、远程存储 | 高性能、低延迟 |
网络块存储协议对比(iSCSI / FC / FCoE / NVMe-oF)
| 特性 | iSCSI | FC(光纤通道) | FCoE | NVMe-oF |
|---|---|---|---|---|
| 传输 | TCP/IP(以太网) | 专用光纤 | 以太网封装 FC | 以太网/FC/RDMA |
| 协议 | SCSI over IP | 原生 FC | FC over Ethernet | NVMe over Fabric |
| HBA/网卡 | 普通以太网卡 | 专用 FC HBA | CNA 或专用卡 | 支持 NVMe-oF 的网卡或 HBA |
| 成本 | 低 | 高 | 中高 | 视方案而定 |
| 延迟 | 中 | 低 | 中低 | 低 |
| 本方案 | ✅ 使用 | 可选 | 可选 | 可选(新架构) |
iSCSI 适合「用现有 IP 网络、不想上光纤」的场景;FC/FCoE 常用于对延迟和带宽要求更高的数据中心;NVMe-oF 是新一代块访问协议,适合全闪存与极低延迟需求。
iSCSI 配置
服务端(Target)配置
bash
# 1. 安装 targetcli
yum install targetcli -y
systemctl enable target
systemctl start target
# 2. 创建后端存储
targetcli backstores/block create disk1 /dev/sdb1
# 3. 创建 IQN(iSCSI 限定名称)
targetcli iscsi/ create iqn.2025.com.example:storage
# 4. 创建 LUN
targetcli iscsi/iqn.2025.com.example:storage/lun create /backstores/block/disk1
# 5. 配置门户(监听地址)
targetcli iscsi/iqn.2025.com.example:storage/tpg1/portals create ip_address=192.168.1.100
# 6. 设置认证(可选)
targetcli iscsi/iqn.2025.com.example:storage/tpg1/attr set authentication=0
targetcli iscsi/iqn.2025.com.example:storage/tpg1/acls create iqn.2025.com.example:client
# 7. 保存配置
targetcli saveconfig客户端(Initiator)配置
bash
# 1. 安装 iscsi-initiator-utils
yum install iscsi-initiator-utils -y
systemctl enable iscsid
systemctl start iscsid
# 2. 发现 Target
iscsiadm -m discovery -t st -p 192.168.1.100
# 3. 登录 Target
iscsiadm -m node -T iqn.2025.com.example:storage -p 192.168.1.100 --login
# 4. 查看连接的磁盘
fdisk -l
# 应该能看到新磁盘,如 /dev/sdb
# 5. 配置自动登录
iscsiadm -m node -T iqn.2025.com.example:storage -p 192.168.1.100 --op update -n node.startup -v 2
# 6. 查看会话
iscsiadm -m session🗂️ cLVM 详解
什么是 cLVM?
cLVM (Cluster LVM) 是 LVM 的集群版本,允许多台服务器同时访问和管理逻辑卷。
为什么需要 cLVM?
- 普通 LVM 的假设是单机:元数据(卷组、逻辑卷的布局与属性)写在磁盘上,同一时刻只有本机在改;多机若同时改同一块盘上的 LVM 元数据,会互相覆盖或读到的视图不一致,导致数据损坏或误删。
- cLVM 要解决的是「多机共享同一块设备时,谁可以改、怎么改」 :通过 clvmd 和 DLM,把「改 VG/LV 元数据」变成集群内协调的动作------只有拿到锁的节点才能改,改完通过 clvmd 同步给其他节点,这样所有节点看到的 VG/LV 列表、大小、状态一致。
- 为什么不能只装 GFS2 不用 cLVM? :GFS2 需要建在块设备上;若用裸分区,扩容、快照、灵活划分都不方便。用 LVM 可以在同一块物理盘上划多个 LV、按需扩容;在集群里这份「划分与扩容」必须多机一致,所以要用 cLVM 而不是单机 LVM。
为什么 cLVM 必须依赖 DLM?
DLM(分布式锁管理器)提供集群范围内的锁 :某个节点要执行 lvcreate、lvextend 等会改元数据的操作时,先向 DLM 申请锁,避免多节点同时改同一 VG。没有 DLM,clvmd 无法在多个节点间协调「谁在改、改完了没」,因此 cLVM 必须和 HA 附加组件(提供 DLM)一起用。
物理卷
PV
卷组
VG
物理卷
PV
物理卷
PV
逻辑卷
LV
GFS2 文件系统
LVM 基础概念:
| 术语 | 英文 | 说明 | 生活类比 |
|---|---|---|---|
| PV | Physical Volume | 物理卷 | 实际的仓库建筑 |
| VG | Volume Group | 卷组 | 一组仓库建筑群 |
| LV | Logical Volume | 逻辑卷 | 仓库里的具体货架 |
| PE | Physical Extent | 物理扩展块 | 最小的存储单位 |
为什么 LVM 要有「PE」?
- 物理卷空间若按字节随意切分,会产生大量碎片,管理复杂。LVM 把 PV 切成固定大小的物理扩展块(PE),VG 和 LV 的分配都以 PE 为单位(例如「这个 LV 占 256 个 PE」)。这样分配、扩容、迁移时都以整块 PE 计算,简单且可预测;默认 PE 大小通常为 4 MiB,也可在创建 VG 时指定。cLVM 继承 LVM 的 PE 概念,只是元数据由集群锁保护、多机一致。
cLVM vs LVM
cLVM
LVM
单机访问
本地管理
简单场景
多机共享
集群管理
复杂场景
| 特性 | LVM | cLVM |
|---|---|---|
| 访问模式 | 单机独占 | 多机共享 |
| 锁机制 | 本地锁 | 集群锁 (DLM) |
| 集群软件 | 不需要 | 需要 dlm 服务 |
| 文件系统 | ext4/xfs | GFS2/OCFS2 |
cLVM vs HA-LVM 对比
| 维度 | cLVM | HA-LVM |
|---|---|---|
| 访问模式 | 多节点同时读写同一 LV(active/active) | 任意时刻仅一个节点访问 LV(active/passive) |
| 锁 | 集群锁(DLM),多机协调元数据 | 通常用 Pacemaker 管理「谁挂载」,故障时切换 |
| 典型场景 | GFS2、多节点共享同一文件系统 | 数据库/应用单实例 + 故障转移 |
| 共享存储 | 需要 | 需要 |
| 集群文件系统 | 需要(GFS2/OCFS2) | 不需要,单机文件系统即可 |
| 选型建议 | 要「多机同时挂载同一块盘」时用 cLVM | 只要「主挂了备机接管」时用 HA-LVM |
官方说明(Red Hat) :cLVM 属于 Resilient Storage Add-On ,依赖 High Availability Add-On (集群与 DLM)。核心守护进程为 clvmd ,在各节点运行,分发 LVM 元数据更新,使所有节点看到一致的逻辑卷视图。适用场景为多节点需同时读写 同一 LVM 卷(active/active);若仅为故障转移、任意时刻仅单节点访问,推荐使用 HA-LVM 而非 cLVM。配置要点:集群需已建立且具备法定人数(quorum);/etc/lvm/lvm.conf 中设置 locking_type=3(集群锁);卷组创建时加集群标志(如 vgcreate -c y)。详见 LVM in a Red Hat High Availability Cluster。
cLVM 配置
bash
# 1. 安装集群 LVM(两台都执行)
yum install lvm2-cluster -y
# 2. 创建物理卷
pvcreate /dev/sdb1
# 3. 创建共享卷组(只在主节点执行)
vgcreate -Ay -c y cluster_vg /dev/sdb1
# 4. 创建逻辑卷
lvcreate -L 10G -n data_lv cluster_vg
# 5. 查看集群状态
lvs -o+devices
vgs -o+devices📁 GFS2 详解
什么是 GFS2?
GFS2 (Global File System 2) 是一个集群文件系统,允许多台服务器同时读写同一个文件系统。
为什么需要集群文件系统(而不是每台机器各建一个文件系统)?
- 单机文件系统(ext4、XFS)假定「只有我这台机器访问这块盘」:元数据(inode、目录、块位图)没有多机协调,若两台机器同时挂载同一块盘并写入,会立刻出现元数据冲突、数据损坏。
- 集群文件系统 在设计上就假定多节点会同时挂载同一块设备 :通过 DLM + 日志 + 缓存一致性协议 ,保证「一个文件谁在写、目录怎么改、块分配归谁」在多机间一致。所以要做多机同时读写同一命名空间,就必须用 GFS2、OCFS2 这类集群文件系统。
为什么 GFS2 要有「日志」?
- 文件系统的元数据(如「某 inode 指向哪些块」「目录项增删」)若在写入中途断电,会处于不一致状态,单机上用 journal 把「将要做的修改」先写日志,崩溃后重放即可恢复一致。
- GFS2 是多机 写同一块盘,且每个节点各自有一份元数据日志 (所以 mkfs.gfs2 要指定
-j数量):这样某个节点崩溃时,可以只重放该节点的日志,而不必让整个集群停下来做 fsck。日志数通常 ≥ 节点数,每个挂载节点独占一个 journal,保证恢复粒度是单节点。
为什么 GFS2 官方要求建在 CLVM 上?
- GFS2 需要共享块设备 ;该设备可以是裸盘分区,也可以是 LVM 逻辑卷。Red Hat 只支持建在 CLVM 逻辑卷上,原因包括:便于用 LVM 做快照、扩容、多卷隔离;且 CLVM 已经解决「多机看到同一 LV」的一致性问题,和 GFS2 的「多机看到同一文件系统」配合成一整套方案,运维和支持边界清晰。
为什么单节点场景不推荐用 GFS2?
- GFS2 的设计和实现都围绕多节点、锁、日志、DLM ,有额外开销。单机只挂一块盘时,用 XFS/ext4 等单机文件系统更简单、性能更好、占用更少。RHEL 因此明确:单节点不支持把 GFS2 当普通本地文件系统用;仅支持单节点挂载 GFS2 的快照(例如做备份),因为快照是只读的,不需要集群锁。
GFS2 集群文件系统
服务器A
GFS2
共享磁盘
服务器B
GFS2
服务器C
GFS2
单机文件系统
服务器A
ext4
独占磁盘
GFS2 核心特性:
| 特性 | 说明 | 生活类比 |
|---|---|---|
| 共享访问 | 多机同时读写 | 多人同时用仓库 |
| 锁机制 | DLM 分布式锁管理 | 货架锁,谁用谁锁 |
| 日志 | 元数据日志 | 记录本子 |
| 恢复 | 快速恢复 | 出错能快速恢复 |
为什么 GFS2 是 64 位?
- 集群文件系统常用来承载大量数据和文件,32 位寻址在文件系统大小、inode 数量、单文件大小上都会遇到上限。GFS2 采用 64 位架构,可支持 TB 级甚至更大(当前 RHEL 支持上限 100 TB),单文件和 inode 数量也不会受 32 位限制,适合企业级共享存储的规模和扩展需求。
官方定义(Red Hat / kernel 文档) :GFS2 是 64 位对称集群文件系统 ,提供共享命名空间,并在共享同一块设备的多个节点间维护一致性。内核模块为 gfs2.ko 。为保持多节点缓存一致,GFS2 使用 glock(global lock) 状态机:基于 DLM,按 inode 管理缓存;PR(Protected Read) 允许多节点同时缓存读取,EX(Exclusive) 保证写时仅单节点缓存。DLM 中首个获得某资源锁的节点成为该锁的 lock master ,其他节点向 master 请求权限,因此锁操作在 master 节点上更快;性能调优时可为各节点分配不同文件以减少锁竞争。详见 GFS2 Overview、GFS2 Node Locking、Linux kernel GFS2。
GFS2 vs 其他集群文件系统
OCFS2
Oracle 开发
主要用于 Oracle
RHEL 支持有限
GFS2
RHEL 原生
成熟稳定
功能丰富
| 特性 | GFS2 | OCFS2 |
|---|---|---|
| 开发商 | Red Hat | Oracle |
| 主要用途 | 通用集群 | Oracle RAC |
| RHEL 支持 | 完全支持 | 有限支持 |
| 许可证 | GPL | GPL |
| 生活类比 | 公共仓库 | 专用仓库 |
集群场景:GFS2 vs 单机文件系统(ext4/XFS)
| 维度 | GFS2 | ext4 / XFS(单机 FS) |
|---|---|---|
| 多机同时挂载同一块设备 | ✅ 支持,设计目标 | ❌ 不支持,会损坏元数据 |
| 锁与一致性 | DLM + glock,多机协调 | 无集群锁,仅单机 |
| 适用存储 | 共享块设备(如 iSCSI + cLVM) | 本地盘或单机独占的块设备 |
| 单机场景 | 不推荐(开销大) | ✅ 推荐 |
| 集群中用法 | 多节点都挂载同一 GFS2,同时读写 | 仅一个节点挂载(配合 Pacemaker 做故障转移,即 HA-LVM 模式) |
结论:要多机同时读写同一块盘 用 GFS2;要的只是主备切换、一次只有一台在用时,用单机文件系统 + Pacemaker 管理挂载即可。
DLM(Distributed Lock Manager)简述
GFS2 与 cLVM 的集群锁由 DLM 提供(RHEL HA 附加组件)。DLM 在各节点运行,通过 TCP(或 SCTP)通信,要求集群具备法定人数(quorum)。其锁模型支持多种锁模式、锁提升/降级、同步/异步完成等。GFS2 的 glock 建立在 DLM 之上;调优时可调整 DLM 表大小(如 lkbtbl_size、rsbtbl_size、dirtbl_size),但需在挂载 GFS2 之前修改。详见 Lock Management。
为什么集群文件系统必须用「锁」?
- 多台机器共享同一块盘时,同一时刻只能有一个节点改某一块元数据(例如同一个 inode、同一块位图),否则就会写乱。锁的作用就是:节点在改某资源前先向 DLM 申请锁,拿到后再改;其他节点要改同一资源必须等待或协商(如 PR 共享读、EX 独占写)。
- glock(global lock) 是 GFS2 在 DLM 之上的封装,按 inode 粒度管理:读时多节点可持 PR 锁共享缓存,写时升级为 EX 锁、独占该 inode 的缓存,写完再降级或释放,这样多机缓存与磁盘上的数据保持一致。没有这套锁,GFS2 就无法在「多机同时挂载」下保证文件系统一致性。
GFS2 配置
bash
# 1. 安装 GFS2 和 DLM(两台都执行)
yum install gfs2-utils dlm -y
systemctl enable dlm
systemctl start dlm
# 2. 创建文件系统
mkfs.gfs2 -p mycluster -t mydata -j 2 /dev/cluster_vg/data_lv
# 参数说明:
# -p: 锁协议名称(lock protocol)
# -t: 锁表名称(lock table)
# -j: 日志副本数(journal 数量)为什么 mkfs.gfs2 要指定 -p、-t、-j?
- -p(锁协议名) :DLM 上会有多套「锁名字空间」,不同集群、不同文件系统用不同协议名,避免锁 ID 冲突。同一集群里所有 GFS2 文件系统通常用同一个协议名(如
mycluster),这样 DLM 知道它们属于同一集群。 - -t(锁表名) :同一协议下还可以再分子表,用来区分不同文件系统 的锁。每个 GFS2 一个唯一的锁表名(如
mydata),这样 A 文件系统的 inode 锁不会和 B 文件系统的混在一起。 - -j(日志数) :GFS2 为每个挂载节点 保留一份元数据日志,用于崩溃恢复。
-j 2表示预先分配 2 份 journal,最多 2 个节点同时挂载;若集群有 3 个节点要挂载,建文件系统时就要-j 3。建好后也可用gfs2_jadd增加 journal,但至少要在格式化时留够或事后补足,否则多出来的节点无法挂载。
bash
# 3. 挂载文件系统(两台都执行)
mkdir /data
mount -t gfs2 /dev/cluster_vg/data_lv /data
# 4. 查看挂载状态
df -h | grep data
gfs2_tool sb /data all🚀 完整部署实战
环境拓扑
存储层
集群层
应用层
节点1
192.168.1.10
节点2
192.168.1.11
Corosync
心跳
Pacemaker
资源管理
iSCSI Target
192.168.1.100
cLVM 集群卷
GFS2 文件系统
完整配置步骤
1. 配置 iSCSI Target
bash
# 在存储服务器上执行
# 1. 安装软件
yum install targetcli -y
systemctl enable target
systemctl start target
# 2. 配置存储
targetcli backstores/block create iscsi_disk /dev/sdb
targetcli iscsi/ create iqn.2025.com.example:server
targetcli iscsi/iqn.2025.com.example:server/lun create /backstores/block/iscsi_disk
targetcli iscsi/iqn.2025.com.example:server/tpg1/portals create ip_address=192.168.1.100
targetcli iscsi/iqn.2025.com.example:server/tpg1/attr set authentication=0
targetcli saveconfig2. 配置 iSCSI Initiator(两台节点)
bash
# 1. 安装软件
yum install iscsi-initiator-utils -y
systemctl enable iscsid
systemctl start iscsid
# 2. 发现并登录
iscsiadm -m discovery -t st -p 192.168.1.100
iscsiadm -m node -T iqn.2025.com.example:server -p 192.168.1.100 --login
# 3. 配置自动登录
iscsiadm -m node -T iqn.2025.com.example:server -p 192.168.1.100 --op update -n node.startup -v 2
# 4. 查看磁盘
fdisk -l | grep /dev/sd3. 配置 cLVM
bash
# 1. 安装集群 LVM(两台都执行)
yum install lvm2-cluster -y
# 2. 创建物理卷(两台都执行)
pvcreate /dev/sdb
# 3. 创建集群卷组(只在主节点执行)
vgcreate -Ay -c y shared_vg /dev/sdb
# 4. 创建逻辑卷
lvcreate -L 20G -n shared_lv shared_vg4. 配置 GFS2
bash
# 1. 安装 GFS2(两台都执行)
yum install gfs2-utils dlm -y
systemctl enable dlm
systemctl start dlm
# 2. 创建文件系统
mkfs.gfs2 -p mycluster -t mydata -j 2 /dev/shared_vg/shared_lv
# 3. 创建挂载点(两台都执行)
mkdir /shared
# 4. 配置 Pacemaker 资源
pcs resource create shared_fs Filesystem \
device="/dev/shared_vg/shared_lv" \
directory="/shared" \
fstype="gfs2" \
op monitor interval=30s5. 验证配置
bash
# 1. 查看集群状态
pcs status
# 2. 查看挂载状态
df -h | grep shared
# 3. 测试同时写入
# 节点1
echo "Hello from Node1" > /shared/test1.txt
# 节点2
echo "Hello from Node2" > /shared/test2.txt
# 两个节点都能看到两个文件
ls -l /shared/📊 监控与维护
监控命令
bash
# iSCSI 监控
iscsiadm -m session
iscsiadm -m node -T iqn.2025.com.example:server
# cLVM 监控
vgs -o+devices
lvs -o+devices
# GFS2 监控
gfs2_tool sb /shared all
gfs2_tool gettune /shared new_file_block_timeoutiSCSI 高级配置
CHAP 认证配置
CHAP 认证 vs 无认证 对比
| 维度 | 无认证 | CHAP 认证 |
|---|---|---|
| 安全性 | 仅靠网络隔离,谁都能连 Target | 需正确用户名/密码才能建会话 |
| 配置 | 简单,ACL 可选 | Target 与 Initiator 均需配置账号密码 |
| 适用 | 内网隔离、测试环境 | 生产、多租户、合规要求 |
| 本方案建议 | 仅限可信内网 | 生产建议开启 |
为什么需要 CHAP 认证?
就像仓库需要门禁卡一样,CHAP(Challenge Handshake Authentication Protocol)确保只有授权的客户端才能访问存储资源,防止未授权访问。
CHAP Challenge
CHAP Response
认证成功
允许访问
Initiator
Target
Target 端配置 CHAP:
bash
# 1. 设置用户名和密码
targetcli iscsi/iqn.2025.com.example:storage/tpg1/auth setattr userid=mystorage_user
targetcli iscsi/iqn.2025.com.example:storage/tpg1/auth setattr password=MySecretPassword123
# 2. 启用认证
targetcli iscsi/iqn.2025.com.example:storage/tpg1/attr set authentication=1
# 3. 配置 ACL(访问控制列表)
targetcli iscsi/iqn.2025.com.example:storage/tpg1/acls create iqn.2025.com.example:client1
# 4. 保存配置
targetcli saveconfigInitiator 端配置 CHAP:
bash
# 1. 配置认证信息
vim /etc/iscsi/iscsid.conf
# 添加以下内容:
node.session.auth.authmethod = CHAP
node.session.auth.username = mystorage_user
node.session.auth.password = MySecretPassword123
# 2. 设置 Initiator IQN
vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2025.com.example:client1
# 3. 重启服务
systemctl restart iscsid
# 4. 登录测试
iscsiadm -m discovery -t st -p 192.168.1.100
iscsiadm -m node -T iqn.2025.com.example:storage -p 192.168.1.100 --login多路径(Multipath)配置
单路径 vs 多路径 对比
| 维度 | 单路径 | 多路径(Multipath) |
|---|---|---|
| 网卡/交换机 | 一条链路到 Target | 多条链路(多网卡、多交换机、多 Target 端口) |
| 故障 | 路径断则存储不可用 | 一条断可切到其他路径 |
| 性能 | 受单条带宽限制 | 可负载均衡,总带宽更高 |
| 配置 | 无需 multipathd | 需安装并配置 multipathd、multipath.conf |
| 适用 | 测试、非关键 | 生产、高可用要求 |
为什么需要多路径?
想象仓库有多个入口,如果一个入口堵了,可以从另一个入口进入。多路径提供了:
- 高可用性:一条路径故障时自动切换
- 负载均衡:流量分散到多条路径
- 性能提升:多条路径同时工作
Target
Network
Initiator
主机
路径1: 192.168.1.0/24
路径2: 192.168.2.0/24
控制器A
192.168.1.100
控制器B
192.168.2.100
共享存储
多路径配置步骤:
bash
# 1. 安装多路径软件
yum install device-mapper-multipath -y
systemctl enable multipathd
systemctl start multipathd
# 2. 配置多路径
vim /etc/multipath.conf
# 添加以下内容:
defaults {
# 启用用户友好的名称
user_friendly_names yes
# 路径检查间隔
polling_interval 10
# 查找多路径设备
find_multipaths yes
# 路径选择器算法(round-robin 负载均衡)
path_selector "round-robin 0"
# 路径故障转移回退
failback immediate
# 无路径时的重试次数
no_path_retry 12
}
# 黑名单配置(排除本地磁盘)
blacklist {
devnode "^sda"
devnode "^sda[0-9]"
}
# iSCSI 设备配置
devices {
device {
vendor "LIO-ORG"
product "IFC*"
path_grouping_policy multibus
path_checker "tur"
prio "alua"
}
}
# 3. 重启多路径服务
systemctl restart multipathd
# 4. 查看多路径设备
multipath -ll
# 输出示例:
# mpathb (36001405xxx) dm-3 LIO-ORG,IFC*
# size=20G features='0' hwhandler='0' wp=0
# |-+- policy='round-robin 0' prio=1 status='active'
# | `- 2:0:0:1 sdb 8:16 active ready running
# `-+- policy='round-robin 0' prio=1 status='enabled'
# `- 3:0:0:1 sdc 8:32 active ready running
# 5. 在多路径设备上创建 LVM
pvcreate /dev/mapper/mpathb
vgcreate -Ay -c y shared_vg /dev/mapper/mpathb多路径命令参考:
bash
# 查看多路径状态
multipath -ll
multipath -l # 简洁格式
# 查看多路径拓扑
multipath -ll -v2
# 刷新多路径设备
multipath -r
# 刷新并重新加载
multipath -R
# 查看多路径统计
multipath -ll +stats🔄 故障恢复与灾难处理
脑裂(Split-Brain)处理
什么是脑裂?
脑裂就像两个管理员同时管理同一个仓库,各自认为对方不在,导致数据不一致。
为什么会出现脑裂?
- 集群依赖心跳 判断节点是否存活。当网络分区(例如交换机故障、网线断开)或节点负载过高导致心跳丢失时,一部分节点认为另一部分已经下线 ,若此时没有法定人数(quorum)约束,两边的多数派可能都认为「我这边是合法集群」,同时接管共享存储并写入,就会造成同一块盘被两个「集群」同时写,数据与元数据冲突,即脑裂。
- 因此集群必须配置 quorum(多数节点存活才认为集群有效)或 QDevice(仲裁设备),确保任意时刻最多只有一个子集能形成法定人数,只有这一边能继续访问共享存储,从而从机制上避免脑裂。
集群正常运行
网络故障
节点1: 认为节点2挂了
节点2: 认为节点1挂了
两边都尝试写入
数据不一致!
预防脑裂的方法:
- 使用 Quorum(法定人数)
- 配置 QDevice(仲裁设备)
- 使用多重心跳路径
恢复脑裂的步骤:
bash
# 1. 确定主节点(数据更新的节点)
# 查看最后写入时间
stat /shared
# 2. 在从节点上停止集群服务
pcs cluster stop --force
# 3. 在从节点上清除锁
gfs2_tool sb /dev/shared_vg/shared_lv all
# 4. 在主节点上重新挂载
umount /shared
mount -t gfs2 /dev/shared_vg/shared_lv /shared
# 5. 验证数据完整性
ls -l /shared/
# 6. 在从节点上重新启动集群
pcs cluster startGFS2 文件系统修复
注意(Red Hat 文档) :在非常大的 GFS2 上运行 fsck.gfs2 会耗时较长并占用较多内存;恢复时间还受备份介质速度限制。具体内存需求与用法见 Repairing a GFS2 File System。
bash
# 1. 卸载文件系统(所有节点)
umount /shared
# 2. 检查文件系统
fsck.gfs2 -y /dev/shared_vg/shared_lv
# 3. 如果需要,强制修复
fsck.gfs2 -y -n /dev/shared_vg/shared_lv
# 4. 重新挂载
mount -t gfs2 /dev/shared_vg/shared_lv /sharediSCSI 会话恢复
bash
# 1. 登出所有会话
iscsiadm -m node -T iqn.2025.com.example:storage --logout
# 2. 清除会话记录
rm -rf /var/lib/iscsi/nodes/*
# 3. 重新发现和登录
iscsiadm -m discovery -t st -p 192.168.1.100
iscsiadm -m node -T iqn.2025.com.example:storage -p 192.168.1.100 --login
# 4. 查看恢复状态
iscsiadm -m session
dmesg | grep -i iscsicLVM 锁清理
bash
# 1. 查看锁状态
lvs -o+devices
vgs -o+devices
# 2. 清理孤儿锁
vgchange --available y shared_vg
lvchange --refresh shared_vg/shared_lv
# 3. 如果卡住,重置锁
vgchange -cn shared_vg # 临时改为非集群模式
lvchange -an shared_vg/shared_lv
lvchange -ay shared_vg/shared_lv
vgchange -cy shared_vg # 改回集群模式
# 4. 验证
lvs -o+devices🔧 GFS2 性能调优详解
调优参数说明
| 参数 | 默认值 | 说明 | 生活类比 |
|---|---|---|---|
| quota_scale | 1.0 | 配额计算比例 | 仓库容量预留比例 |
| statfs_slow | 0 | 延迟统计信息更新 | 不每次都统计库存 |
| new_file_block_timeout | 64 | 新文件块分配超时 | 新货上架限时 |
| max_atomic_write | 0 | 最大原子写入大小 | 一次搬运的最大数量 |
性能调优配置
bash
# 1. 调整 GFS2 参数
# 禁用慢速 statfs(提高性能)
gfs2_tool settune /shared statfs_slow 0
# 调整配额比例
gfs2_tool settune /shared quota_scale 0.9
# 增加日志区大小(如需大量小文件操作)
gfs2_tool settune /shared logd_secs 30
# 2. 挂载选项优化
mount -t gfs2 -o noatime,nodiratime,data=writeback /dev/shared_vg/shared_lv /shared
# 选项说明:
# - noatime: 不更新访问时间,减少IO
# - nodiratime: 不更新目录访问时间
# - data=writeback: 写回模式,性能更好
# 3. 添加到 /etc/fstab 实现永久挂载
/dev/shared_vg/shared_lv /shared gfs2 defaults,noatime,nodiratime,_netdev 0 0
# 4. 调整 iSCSI 参数
# 增加队列深度
echo 128 > /sys/block/sdb/queue/nr_requests
# 调整超时时间
iscsiadm -m node -T iqn.2025.com.example:storage -p 192.168.1.100 \
--op update -n node.session.timeo.replacement_timeout -v 120
iscsiadm -m node -T iqn.2025.com.example:storage -p 192.168.1.100 \
--op update -n node.session.cmds_max -v 128监控 GFS2 性能
bash
# 1. 查看文件系统统计
gfs2_tool stat /shared
# 2. 查看调优参数
gfs2_tool gettune /shared all
# 3. 查看锁状态
gfs2_tool lockdump /shared
# 4. 查看日志区状态
gfs2_tool journals /shared
# 5. 使用 iostat 监控 IO
iostat -x 2
# 6. 监控网络延迟(iSCSI)
ping -i 0.1 192.168.1.100🚨 故障排查流程图
iSCSI 连接问题排查
不通
通
否
是
否
是
否
是
是
否
无法连接 iSCSI
网络通吗?
检查网络配置
防火墙/交换机
Target 服务运行?
启动 target 服务
认证配置正确?
检查 CHAP 配置
ACL 允许访问?
添加 ACL 规则
多路径配置?
检查 multipathd
检查本地配置
GFS2 性能问题排查
高
正常
是
否
是
否
是
否
GFS2 性能差
网络延迟?
优化网络配置
使用专用网络
锁竞争严重?
检查应用
减少文件锁定
磁盘 IO 高?
检查磁盘健康
考虑 SSD
参数未优化?
应用调优参数
检查网络带宽
📋 维护检查清单
日常检查
bash
#!/bin/bash
# 每日检查脚本
echo "=== 每日共享存储检查 ==="
echo "1. iSCSI 会话状态:"
iscsiadm -m session
echo -e "\n2. 多路径状态:"
multipath -ll
echo -e "\n3. GFS2 挂载状态:"
df -h | grep gfs2
echo -e "\n4. LVM 状态:"
vgs -o+devices
echo -e "\n5. DLM 状态:"
systemctl status dlm --no-pager
echo -e "\n6. 磁盘 IO:"
iostat -x 1 1 | grep -E "sd[a-z]+|Device"
echo -e "\n7. 网络延迟:"
ping -c 3 192.168.1.100 | tail -1
echo -e "\n=== 检查完成 ==="周期维护任务
| 任务 | 频率 | 说明 |
|---|---|---|
| 检查日志 | 每天 | 查看 /var/log/messages |
| 备份配置 | 每周 | 备份 targetcli 和 LVM 配置 |
| 测试故障转移 | 每月 | 模拟路径故障 |
| 性能审查 | 每月 | 分析 IO 和延迟趋势 |
| 容量规划 | 每季度 | 评估存储增长 |
常见问题
1. GFS2 无法同时挂载
否
是
否
是
挂载失败
DLM 运行?
启动 dlm 服务
锁表一致?
检查锁表名称
检查集群状态
解决步骤:
bash
# 1. 检查 DLM
systemctl status dlm
# 2. 检查锁表
gfs2_tool journals /shared
# 3. 查看集群状态
pcs status2. LVM 操作卡住
bash
# 1. 查看锁状态
lvm dumpconfig global | grep -A 10 cluster
# 2. 清理锁
lvchange --refresh shared_vg/shared_lv
# 3. 重置锁
lvchange --clear lock_shared_vg/shared_lv💡 最佳实践
配置建议
- 使用专用网络:iSCSI 流量与业务流量分离
- 配置多路径:提高可用性
- 定期备份:GFS2 不是备份的替代
- 监控延迟:网络延迟影响性能
- 测试故障恢复:确保高可用正常
性能优化
bash
# 1. 调整 iSCSI 超时
iscsiadm -m node -T iqn.2025.com.example:server -p 192.168.1.100 \
--op update -n node.session.timeo.replacement_timeout -v 120
# 2. 调整 GFS2 参数
gfs2_tool settune /shared quota_scale 0.9
gfs2_tool settune /shared statfs_slow 0
# 3. 使用 jumbo frames(如果网络支持)
# MTU 9000📊 存储与方案选型对比速查
下表汇总前文各对比,便于按场景快速选型。
| 你要的效果 | 更合适的方案 | 参考对比小节 |
|---|---|---|
| 多机同时读写同一份数据 | 共享存储(iSCSI + cLVM + GFS2) | 共享存储 vs 复制存储;GFS2 vs 单机 FS |
| 主挂了备机接管,一次只有一台用 | HA-LVM + 单机文件系统(ext4/XFS) | cLVM vs HA-LVM;GFS2 vs 单机 FS |
| 用现有 IP 网络、低成本块存储 | iSCSI | iSCSI vs 传统存储;网络块存储协议对比 |
| 多机共享目录、不需集群 FS | NFS/SMB | 块级 vs 文件级 vs 对象存储 |
| 主从复制、异地容灾 | DRBD 等复制存储 | 共享存储 vs 复制存储 |
| 生产环境 iSCSI 安全 | 开启 CHAP + ACL | CHAP 认证 vs 无认证 |
| 存储高可用、不断路径 | 多路径(multipath) | 单路径 vs 多路径 |
🎯 总结
iSCSI + cLVM + GFS2 组成了完整的共享存储解决方案,是构建高可用集群的重要组件。
核心要点记忆口诀:
- iSCSI 传 SCSI,IP 网络变存储
- cLVM 管集群卷,多机共享同一卷
- GFS2 允并发,多机同时读写好
- DLM 管集群锁,谁用谁锁少不了
- 三者配合用,共享存储真正妙
生活类比总结:
- iSCSI = 快递系统,把存储送到你面前
- cLVM = 灵活货架,可大可小随意调
- GFS2 = 共享仓库,多人同时用
- DLM = 货架管理员,协调大家的使用
📚 官方文档与规范
以下为与 iSCSI、GFS2、cLVM、DLM 相关的官网与规范,便于查阅权威说明与支持策略。
标准与协议
| 项目 | 说明 | 链接 |
|---|---|---|
| iSCSI 协议 | RFC 7143(Consolidated,取代 RFC 3720/3980/4850/5048) | RFC 7143 |
| iSCSI 命名与发现 | RFC 3721 | RFC 3721 |
Red Hat 文档(RHEL)
| 主题 | 说明 | 链接 |
|---|---|---|
| GFS2 总览与支持限制 | 64 位对称集群文件系统、100TB/16 节点限制、单节点不支持说明 | GFS2 Overview (RHEL 7) |
| GFS2 管理与维护 | 创建、挂载、配额、扩展、修复、atime 等 | Global File System 2 (RHEL 7) |
| GFS2 节点锁与性能 | glock、缓存一致性、锁竞争 | GFS2 Node Locking |
| 存储管理(含 iSCSI) | iSCSI target/initiator、targetcli、iscsiadm | Managing storage devices (RHEL 10) |
| LVM / cLVM | 集群 LVM、clvmd、locking_type、HA-LVM 对比 | LVM in a Red Hat High Availability Cluster |
| DLM | 分布式锁管理、锁模式、集群通信 | Lock Management (HA Add-On) |
| GFS2 挂载策略 | 支持策略、挂载条件与流程 | Support Policies for RHEL Resilient Storage |
| HA 集群 LVM 支持 | CLVM 支持策略与用法 | Support Policies for RHEL High Availability Clusters |
内核与上游
| 项目 | 说明 | 链接 |
|---|---|---|
| GFS2(Linux 内核文档) | 内核内 GFS2 说明 | Linux kernel --- GFS2 |
| CLVM 项目 | 上游 Cluster LVM | sourceware.org/cluster/clvm |
使用 RHEL 时,以 Red Hat 官方文档和支持策略为准;版本差异(如 RHEL 8/9/10)请查阅对应版本的 Storage / HA 文档。
最后提醒:共享存储是集群的基础,但也要做好数据备份!集群防硬件故障,备份防人为错误!