1. 缓存在订单系统的局限性
Redis 作为 MySQL 前置缓存,适合无用户关联的系统 (商品、搜索系统),这类系统数据全局一致,缓存命中率极高,能有效挡掉绝大部分查询请求。而用户关联系统(订单、账户、购物车系统)因数据与用户强绑定(如 "我的订单" 仅展示个人数据),缓存命中率低,大量查询会穿透到 MySQL,无法仅通过缓存解决高并发问题。
2. 读写分离的核心价值与适用场景
- 核心定位 :提升 MySQL 并发能力的首选扩容方案,单个 MySQL 无法支撑高并发时的最优解(优于分库分表,实施更简单)。
- 适用场景:读写比例严重不均衡的互联网系统(读写比通常 9:1~ 几十比 1),绝大部分请求为只读查询。
- 核心优势 :
- 分布式读实现简单,只需将数据实时同步到只读实例即可分担查询压力;
- 实施成本低,无需修改业务逻辑,仅需调整 DAO 层代码;
- 并发能力提升显著,多从库可使数据库并发量提升数倍至十几倍。
3. 读写分离的实现原理(MySQL)
(1)数据库层:主从同步机制(基于 Binlog)
MySQL 通过Binlog+RelayLog实现主从数据同步,是读写分离的底层基础,流程如下:
- 主库开启 Binlog 日志,记录所有数据操作(增删改);
- 从库开启 RelayLog 日志,主动跟踪主库 Binlog 的变化,将主库的操作同步记录到自身 RelayLog;
- 从库重演 RelayLog中的数据操作,实现与主库的数据一致。
(2)应用层:SQL 路由与框架实现
- 核心逻辑:将读写请求分离,写请求路由到主库 ,读请求路由到从库;
- 代码修改:仅需调整 DAO 层(数据访问对象),无需改动业务逻辑;
- 主流框架:电商项目中常用ShardingSphere实现读写分离(Java 开发主流方案)。
(3)整体架构流程
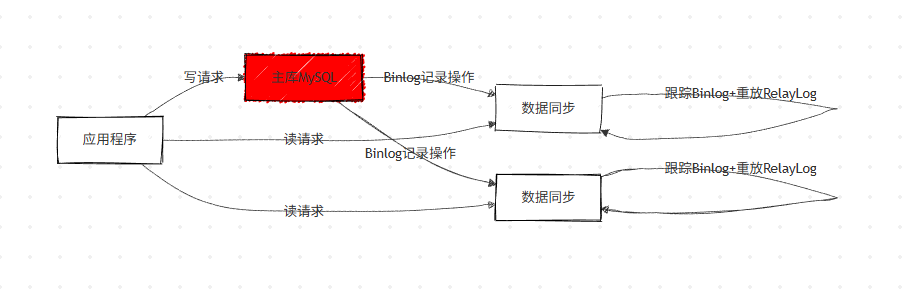
4. 读写分离的核心问题:主从数据不一致
(1)问题根源
主库完成数据更新后,数据以异步方式 同步到从库,存在毫秒级的主从延迟,导致某一时刻主从库数据不一致。
(2)典型业务场景(订单系统)
用户支付订单后,主库订单状态已更新为 "已支付",但从库仍为 "未支付",若支付完成后立即自动跳转到订单页(从库查询),会展示错误的订单状态。
(3)解决方案
无通用技术方案 解决主从延迟问题,核心思路为业务规避 + 技术兜底,具体方案:
| 解决方案 | 适用场景 | 实现方式 |
|---|---|---|
| 增加中间页 | 电商支付等用户交互场景 | 支付完成后跳转至 "支付成功页",而非直接跳订单页,由用户手动查询订单(规避立即查询) |
| 主库强制查询 | 数据更新后需立即查询的业务 | 单独指定查询请求路由到主库,绕过从库 |
| 数据库事务绑定 | 同事务内的更新 + 查询 | 将更新和查询放入同一个数据库事务,事务内查询自动路由到主库 |
| 业务逻辑重设计 | 所有主从延迟场景 | 尽量避免 "更新后立即从从库查询该数据" 的业务逻辑 |