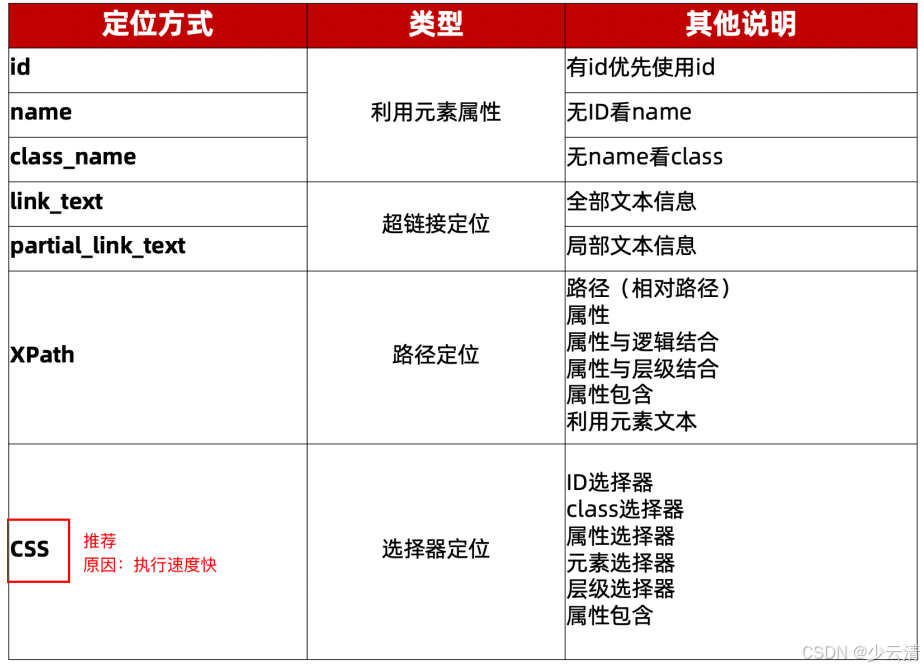
文章目录
- 一、元素定位概念
- 二、WebDriver-元素定位
-
- [2.1 ① id定位](#2.1 ① id定位)
- [2.2 ②name定位](#2.2 ②name定位)
- [2.3 ③class_name定位](#2.3 ③class_name定位)
- [2.4 ④tag_name定位-不建议](#2.4 ④tag_name定位-不建议)
- [2.5 ⑤link_text定位](#2.5 ⑤link_text定位)
- [2.6 ⑥partial_link_text定位](#2.6 ⑥partial_link_text定位)
- [2.7 扩展-定位一组元素](#2.7 扩展-定位一组元素)
- 三、Xpath、CSS元素定位方式(重点)
-
- [3.1 ⑦Xpath定位](#3.1 ⑦Xpath定位)
-
- [3.1.1 Xpath定位-策略**(**方式)](#3.1.1 Xpath定位-策略**(**方式))
-
- [3.1.1.1 路径定位(绝对路径、相对路径)](#3.1.1.1 路径定位(绝对路径、相对路径))
- [3.1.1.2 属性定位](#3.1.1.2 属性定位)
- [3.1.1.3 属性与逻辑结合](#3.1.1.3 属性与逻辑结合)
- [3.1.1.4 属性与层级结合](#3.1.1.4 属性与层级结合)
- [3.1.2 Xpath定位-延伸](#3.1.2 Xpath定位-延伸)
- [3.1.3 Xpath-总结](#3.1.3 Xpath-总结)
- [3.2 ⑧CSS定位](#3.2 ⑧CSS定位)
-
- [3.2.1 CSS定位-策略 (方式)](#3.2.1 CSS定位-策略 (方式))
- [3.2.2 CSS定位-延伸](#3.2.2 CSS定位-延伸)
- [3.2.2 CSS-总结](#3.2.2 CSS-总结)
- [3.3 XPath与CSS类似功能对比](#3.3 XPath与CSS类似功能对比)
- 四、元素定位的另一种写法
- 五、元素定位方式的选择
一、元素定位概念
yacas
什么是元素定位?
- 通过代码调用方法查找元素- UI界面本质上就是HTML直接体现,脚本通过HTML标签信息来找到具体的元素
- 浏览器开发者工具就是给专业的web应用和网站开发人员使用的工具,包含了对HTML查看和编辑、Javascript控制台、网络状况监视等功能。
- HTML是由前端开发编写的,测试人员没有办法去修改以及决定一个元素的标签到底会有哪些信息,只能根据所看到的信息来决定选择什么样的定位方式。
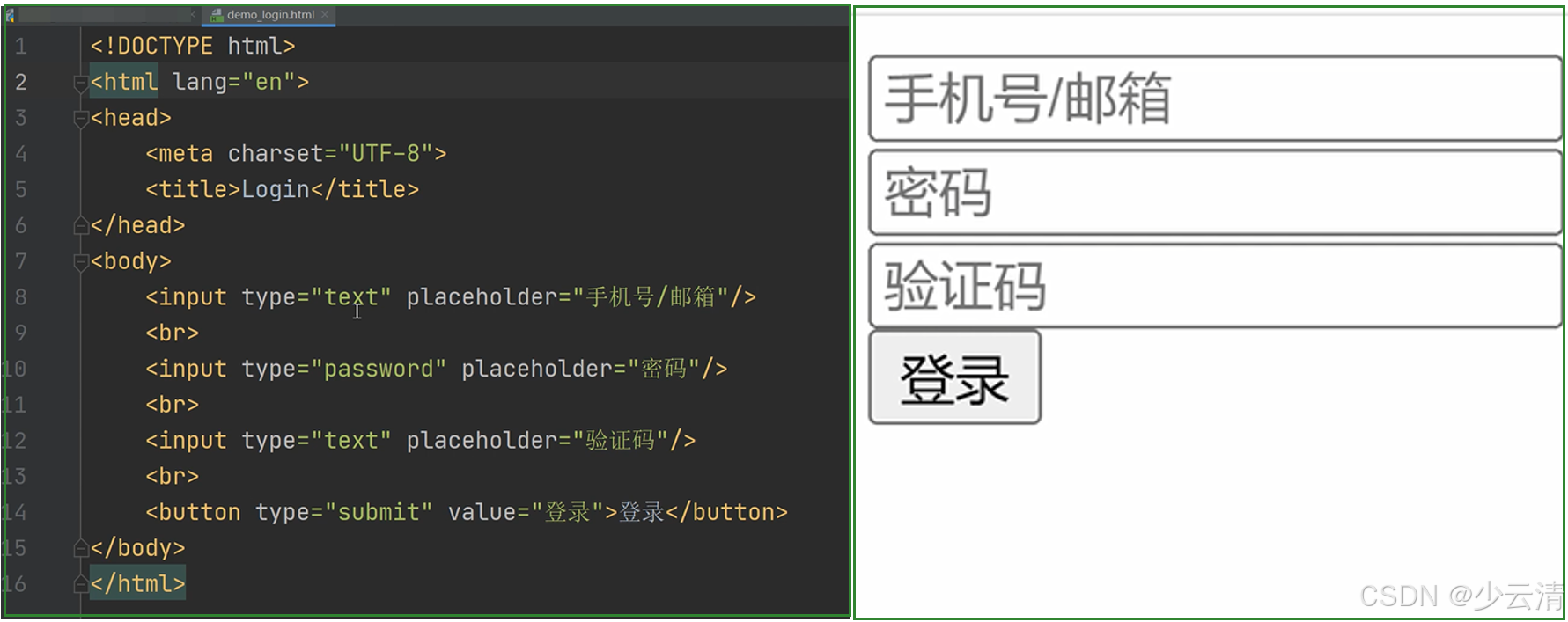
二、WebDriver-元素定位
1、WebDriver元素定位方式-8种
yacas
1、id
2、name
3、class_name
4、tag_name
5、link_text
6、partial_link_text
7、Xpath
8、CSS2、定位方式分类**-**汇总:
yacas
1、id、name、class_name:为元素属性定位
2、tag_name:为元素标签名称
3、link_text、partial_link_text:为超链接定位(a标签)
4、Xpath:为元素路径定位
5、CSS:为CSS选择器定位2.1 ① id定位
- 概念:利用元素<标签元素>的id属性值来进行定位;
- 前置条件:所要定位的元素必须有id属性。
- 优先级:所要定位的元素有id时,优先使用id定位,因为HTML规定id属性在整个HTML文档中必须是唯一的。
- 方法:
python
driver.find_element_by_id("id属性值").send_keys("具体输入内容")
driver.find_element_by_id("id属性值")
return: 找到了,则返回元素对象;
没找到,NoSuchElementException(找不到元素对象异常)
python
from selenium import webdriver
from time import sleep
# 1. 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("http://www.baidu.com")
# 3. 找到搜索框,使用send_keys()方法模拟输入:我爱你
driver.find_element_by_id("kw").send_keys("我爱你")
# 4. 模拟点击搜索按钮
driver.find_element_by_id("su").click()
# 5. 暂停3秒
sleep(3)
# 6、关闭浏览器
driver.quit()2.2 ②name定位
- 概念:利用元素<标签元素>的name属性值来进行定位。
- 前置条件:所要定位的元素必须有name属性 。
- 优先级:有id看id,没id看name。
- 方法:
python
driver.find_element_by_name("name属性值").send_keys("具体输入内容")
driver.find_element_by_name("name属性值")
return: 找到了,则返回元素对象;
没找到,NoSuchElementException(找不到元素对象异常)
yacas
注意:在HTML中Name属性值可能存在重复,在定位时默认返回第一个。
如果想找第二个怎么办?
- 换其他的定位方式
- 后续学习定位一组元素(将所有符合条件的对象全部找回来,再根据自己想要的去挑)
python
from selenium import webdriver
from time import sleep
# 1. 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("http://www.baidu.com")
# 3. 找到搜索框,使用send_keys()方法模拟输入:我爱你
driver.find_element_by_name("wd").send_keys("我爱你")
# 4. 模拟点击搜索按钮
driver.find_element_by_id("su").click()
# 5. 暂停3秒
sleep(3)
# 6、关闭浏览器
driver.quit()2.3 ③class_name定位
- 概念:利用元素class的属性来进行定位。
- 前置条件:所要定位元素必须有class属性。
- 注意:class属性可以存在多个属性值(多个类名),每个类名以空格分隔,再挑选类名时尽量挑选所要定位的元素所特有的。
- 方法:
python
driver.find_element_by_class_name("class其中一个类名")
# 说明:HTML规定了class来指定元素的类名;用法和name、id类似。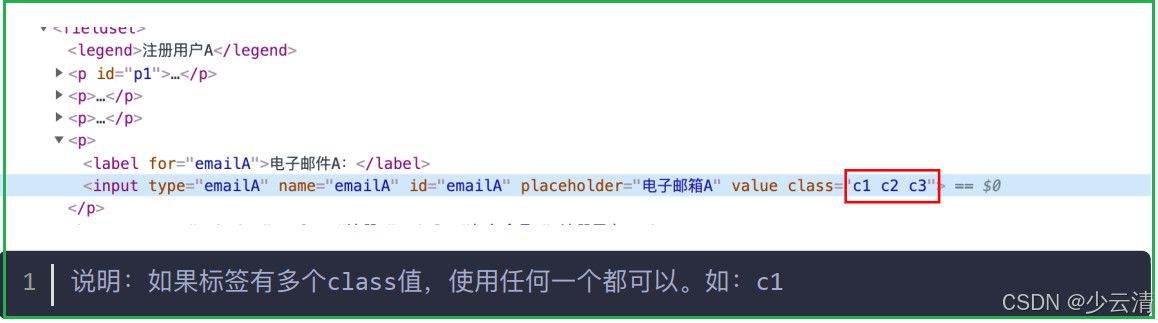
python
from selenium import webdriver
from time import sleep
# 1. 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("http://www.baidu.com")
# 3. 定位class属性,使用send_keys()方法模拟输入:我爱你
driver.find_element_by_class_name("s_ipt").send_keys("我爱你")
# 4. 模拟点击搜索按钮
driver.find_element_by_id("su").click()
# 5. 暂停3秒
sleep(3)
# 6、关闭浏览器
driver.quit()2.4 ④tag_name定位-不建议
- 概念:通过元素的标签名来定位元素
- 注意:HTML本质就是由不同的tag(标签)组成,而每个tag都是指同一类,所以tag定位效率低, 一般不建议使用;
- 方法:
python
# 如果页面存在多个相同标签,默认返回第一个
# 1、返回:符合条件的第一个标签,element
driver.find_element_by_tag_name("标签名") # 返回:符合条件的第一个标签
# 2、如何获取第二个元素? 说明:使用tag_name获取第二个元素(密码框), elements
driver.find_elements_by_tag_name("input")[1].send_keys("123456")案例:
python
# 案例运行不成功,因为find_element_by_tag_name() 返回符合条件的第一个标签
from selenium import webdriver
from time import sleep
# 1. 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("http://www.baidu.com")
# 3. 找到搜索框,使用send_keys()方法模拟输入:我爱你
driver.find_element_by_tag_name("input").send_keys("我爱你")
# 4. 模拟点击搜索按钮
driver.find_element_by_id("su").click()
# 5. 暂停3秒
sleep(3)
# 6、关闭浏览器
driver.quit()2.5 ⑤link_text定位
- 概念:link_text定位与前面4个定位有所不同,它专门用来定位超链接文本(标签 )。
- 注意: link_text是利用全部的文本内容,不能少任何的字符。partial_link_text是利用局部的文本内容,挑选局部时尽量挑选文本中比较特殊的一截。
- 方法:
python
driver.find_element_by_link_text("超链接的全部文本内容")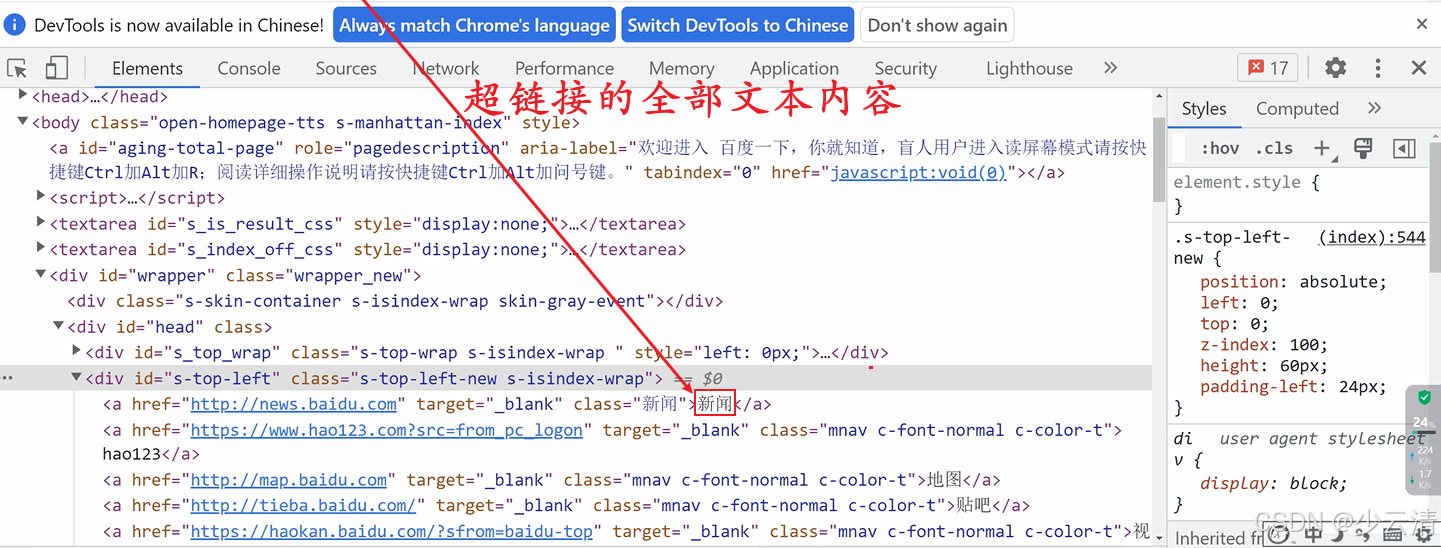
案例:
python
from selenium import webdriver
from time import sleep
# 1. 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("https://top.baidu.com/board?platform=pc&sa=pcindex_entry")
# 3. link_text定位,传入定位元素的全部文本
driver.find_element_by_link_text("变形金刚").click()
# 4. 暂停3秒
sleep(3)
# 5、关闭浏览器
driver.quit()2.6 ⑥partial_link_text定位
-
说明:partial_link_text定位是对 link_text定位的补充,partial_like_text为模糊匹配;
-
link_text 全部匹配
-
方法
python
driver.find_element_by_partial_link_text("超链接的局部文本内容")
说明:需要传入a标签局部文本-能表达唯一性(变形)
driver.find_element_by_link_text("变形").click()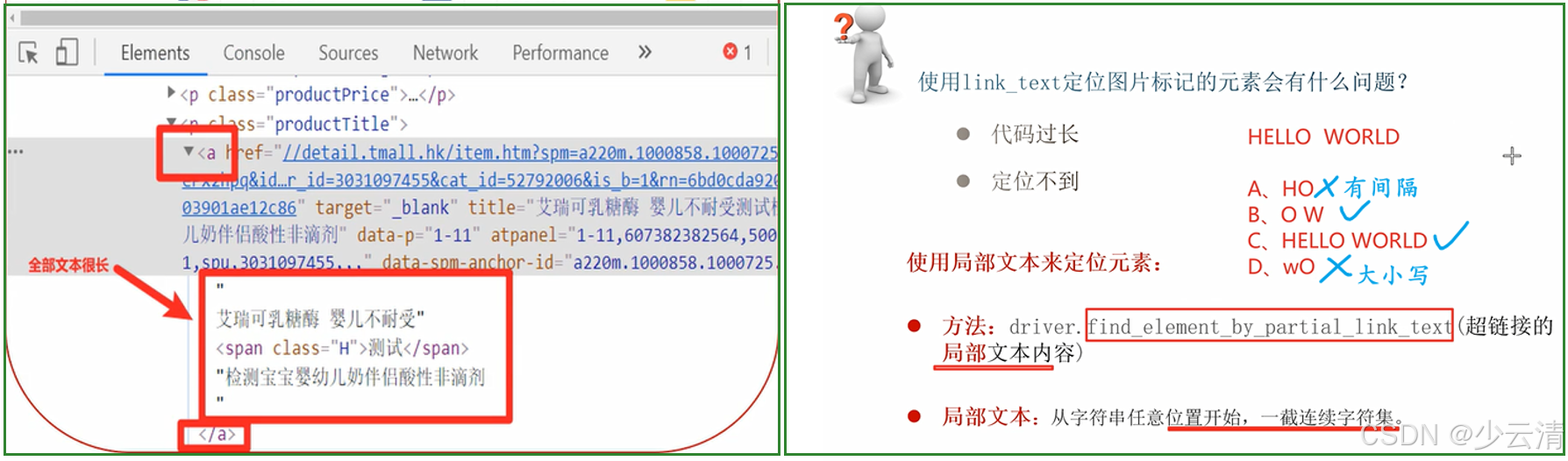
python
from selenium import webdriver
from time import sleep
# 1. 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("https://top.baidu.com/board?platform=pc&sa=pcindex_entry")
# 3. partial_link_text定位,局部匹配,必须是具有代表性的局部文本
driver.find_element_by_partial_link_text("变形").click()
# 4. 暂停3秒
sleep(3)
# 5、关闭浏览器
driver.quit()2.7 扩展-定位一组元素
- 概念:利用元素定位方法定位出所有符合条件的元素。
python
By 是selenium提供的一个类,通过调用类属性来确定选择哪种定位方式,8种常用的元素定位方式都有对应属性
方式一:
els = driver.find_elements_by_XXX("XXX方式对应所要求的参数")
方式二:
els = driver.find_elements(By.ID,"userA")
备注:需要两个参数,第一个参数为定位的类型由By提供,第二个参数为定位的具体方式
1、定位一组元素返回的不是元素对象,返回的是一组符合条件的元素对象,类型为列表
2、需要获取具体的某一个元素对象,需要加上下标(下标从0开始)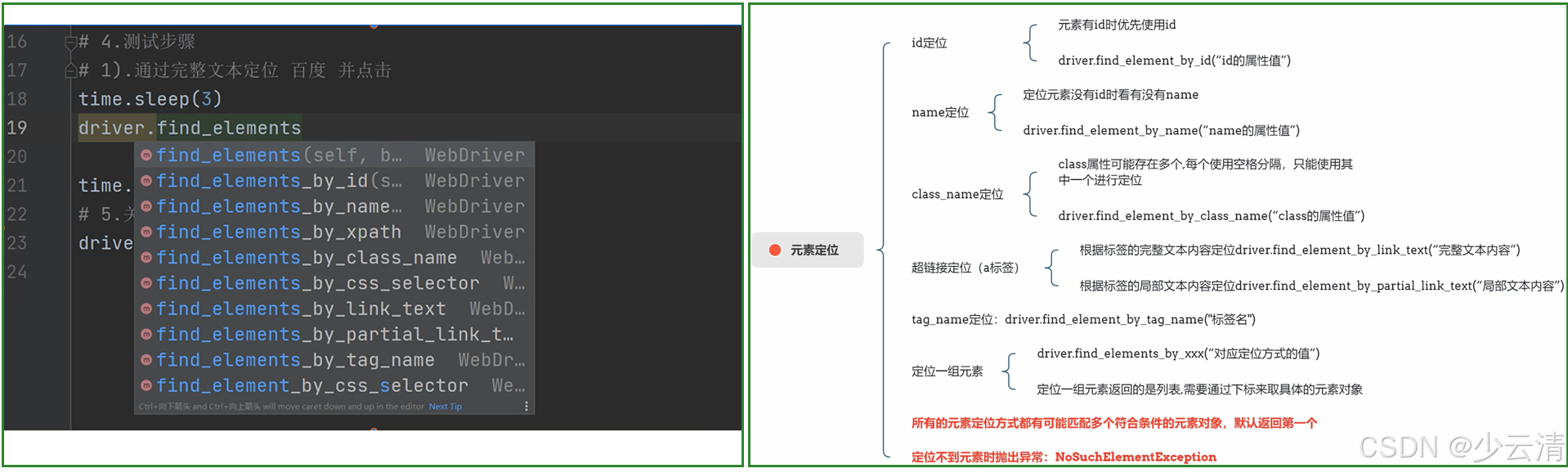
三、Xpath、CSS元素定位方式(重点)
1、为什么要学习Xpath 、CSS定位?
yacas
1、如果标签没有(id\name\class_name) 3个属性,也不是链接标签,只能使⽤tag_name定位,⽐较麻烦。
2、方便在工作用中查找元素,使⽤xpath和css⽐较方便(支持任意属性、层级)来找元素3.1 ⑦Xpath定位
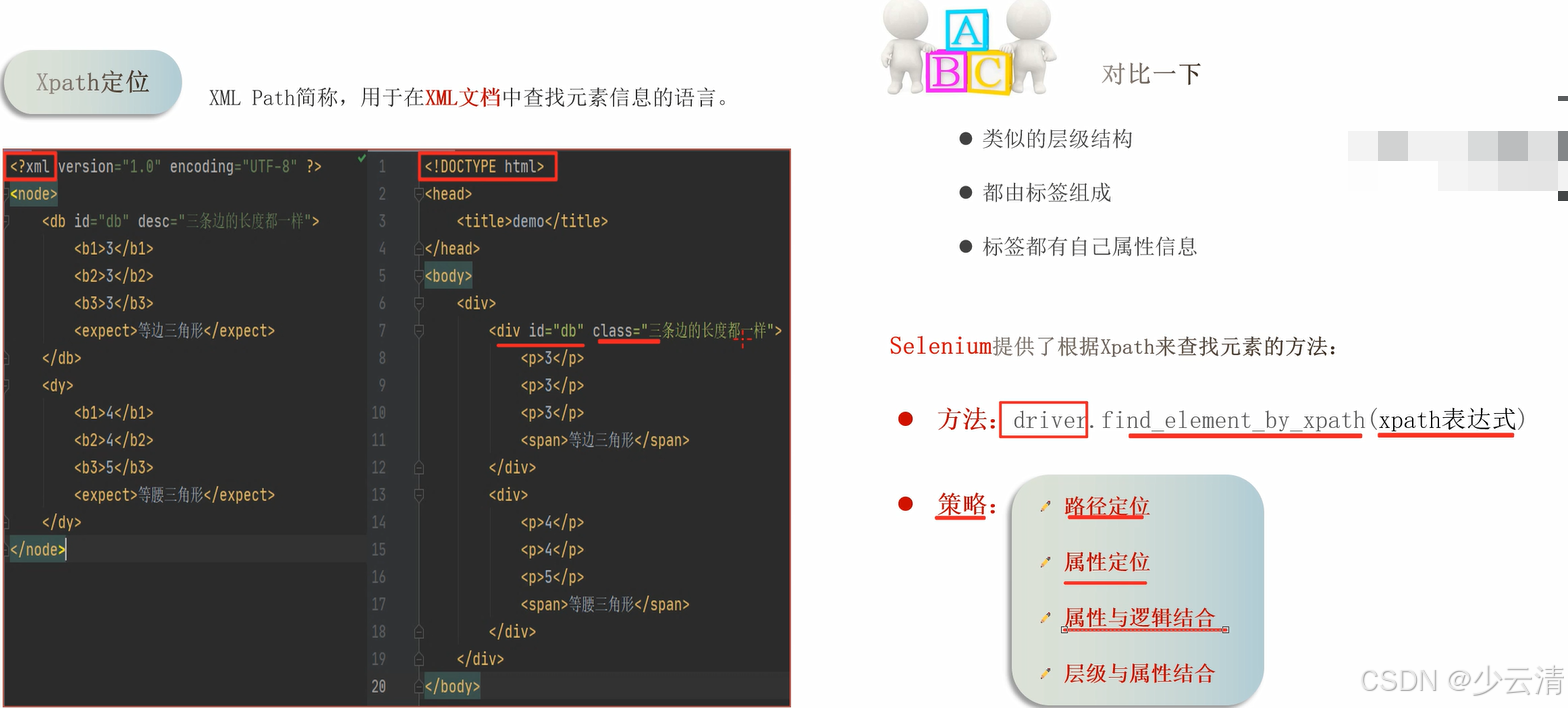
1、XPath即为XML Path 的简称,用于在XML文档中查找元素信息的语言 。
2、HTML可以看做是XML的一种实现,所以Selenium用户可以使用这种强大的语言在Web应用中定位元素。
XML:一种标记语言,用于数据的存储和传递。 后缀.xml结尾
提示:Xpath为强大的语言,那是因为它有非常灵活定位策略;
3.1.1 Xpath定位-策略**(**方式)
1、路径定位
- 绝对路径
- 相对路径
2、属性定位
3、属性与逻辑(多个属性)
4、属性与层级(路径)
3.1.1.1 路径定位(绝对路径、相对路径)
1、绝对路径:从最顶级标签到指定(所要定位的元素)所经过的所有层级
xml
案例:tpshop搜索输入框绝对路径
/html/body/div/fieldset/form/p[1]/input
->注意:绝对路径在实际工作中用的比较少,对于页面的结构过于依赖,一般不用2、相对路径:从目标元素的任意祖辈元素开始查找,缩小查找范围
xml
//form 表示找到页面中所有标签名为form的元素
//form/p[1]/input 表示找到页面中标签名为form,且该form标签元素下有一个p[1]标签元素,p[1]标签元素有一个input标签儿子元素
注意:以 // 开始,后续每个层级都使用/来分隔
yacas
注意:XPATH中可以使用下标来选择第几个元素,但是计数是从1开始。和列表的下表区分开,列表是从0开始
提示:为了方便练习Xpath,可以在FireBug内安装扩展插件-FireFinder插件;
- 火狐浏览器-->组件管理器-->搜索FireFinder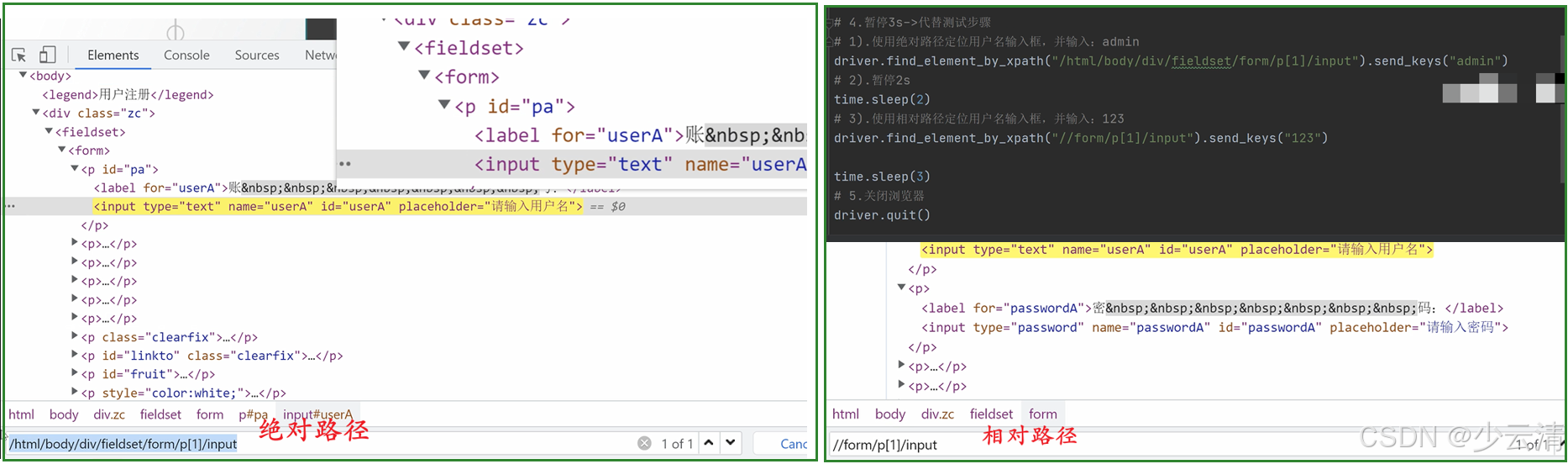
3.1.1.2 属性定位
- 概念:利用所要定位的元素自身任意的属性信息来进行定位
python
- 任意元素定位都有可能定位到多个符合条件的元素对象,所以在挑选属性时一般挑选特有的
- 怎么知道是特有的: id->name->class->value->其他(一个个试)
- 可以支持使用id、class、name
表达式:
<a name="zs" id="123456" class="t1" type='password' style="123">
//*[@id='123456'] //*匹配界面上所有元素,条件该元素必须有id属性且id的属性值必须为123456
//a[@class='t1' ] //a匹配界面上所有的a标签元素,条件该a标签必须有class属性且class属性值必须为t1
//*[@style='123']
python
from selenium import webdriver
from time import sleep
# 1. 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("http://www.baidu.com")
# 3. 找到搜索框,使用send_keys()方法模拟输入:我爱你
driver.find_element_by_xpath("//input[@id='kw']").send_keys("我爱你") # 使用相对路径
# 4. 模拟点击搜索按钮
driver.find_element_by_id("su").click()
# 5. 暂停3秒
sleep(3)
# 6、关闭浏览器
driver.quit()3.1.1.3 属性与逻辑结合
- 概念:当元素自身的一个属性无法精准定位时,可以同时使用多个属性来进行限制。

python
from time import sleep
from selenium import webdriver
# 1、获取浏览器
driver = webdriver.Chrome()
# 2、打开url
driver.get("file:///Users/lgy/Documents/fodder/web/%E6%B3%A8%E5%86%8CA.html")
# 3、查找操作元素
# 多属性
driver.find_element_by_xpath("//input[@placeholder='账号A' and @id='userA']").send_keys("admin")
# 4、关闭浏览器
sleep(3)
driver.quit()3.1.1.4 属性与层级结合
- 概念:元素自身属性无法精准定位时,可以先定位其父级元素再定位子元素。

python
from time import sleep
from selenium import webdriver
# 1、获取浏览器
driver = webdriver.Chrome()
# 2、打开url
driver.get("file:///Users/lgy/Documents/fodder/web/%E6%B3%A8%E5%86%8CA.html")
# 3、查找操作元素
# 层级
driver.find_element_by_xpath("//p[@id='p1']/input").send_keys("admin")
# 4、关闭浏览器
sleep(3)
driver.quit()3.1.2 Xpath定位-延伸
python
- ①文本定位: //*[text()='元素的全部文本信息']
- ②局部属性值: //*[contains(@属性名,'局部属性值')]
- ③局部文本: //*[contains(text(),'局部文本')]
- 属性名称id,包含kw字符 //*[contains(@id,'kw')]
提示:contains包含的意思
- 属性以xxx开头的元素,attribute属性的意思 //*[starts-with(@attribute,'xxx')]
- 属性名称id,以kw开头的字符 //*[starts-with(@id,'kw')] 
python
# 1.局部属性定位:用户名输入框输入admin
driver.find_element_by_xpath("//*[contains(@placeholder,'用户')]").send_keys("admin")
time.sleep(2)
# 2.文本定位:定位百度超链接,并点击
driver.find_element_by_xpath("//*[text()='百度']").click()
time.sleep(2)
# 3.局部文本定位:定位hao123,并点击
driver.find_element_by_xpath("//*[contains(text(),'hao')]").click()3.1.3 Xpath-总结
1、绝对路径以 / 开始,中间不能跳跃元素
2、相对路径以 // 开始,后边必须跟标签名或者*
3、所有属性名必须以@修饰
3.2 ⑧CSS定位
1、CSS
-
概念:(Cascading Style Sheets)是一种语言,用来描述HTML和XML元素的显示样式。
-
选择器:一种表达式,可以找到HTML中的标签元素。
-
CSS语言书写两个格式:
html
写在HTML语言中<style type="text/css">...
写在单独文件中,后缀.css2、CSS定位
- 概念:selenium利用选择器定位元素的定位方式。
- 方法:driver.find_element_by_css_selector(选择器表达式)
yacas
Xpath基本可以定位所有的元素干嘛还学习CSS?
- 速度更快
- 写法更简洁3.2.1 CSS定位-策略 (方式)
1、id选择器(id属性值)
- 说明:根据元素id属性来选择
- 格式:#id
- 如:#userA (选择id属性值为userA的所有元素)
- 注意:id选择器必须以 # 修饰
2、class选择器
- 说明:根据元素class属性来选择
- 格式:.class
- 如:.telA (选择class属性值为telA的所有元素)
- 注意:以 .修饰,必须有class属性
3、元素选择器(通过标签名)
- 说明:根据元素的标签名选择
- 格式:element
- 如:input <选择所有input元素>
4、属性选择器
- 说明:根据元素的属性名和值来选择
- 格式:attribute=value
- 如:type="password" (选择所有type属性值为password的值)
5、层级选择器
- 说明:根据元素的父子关系来选择
- 格式:element>element
- 如:p>input <返回所有p元素下所有的input元素>
python
1.ID选择器: #id的属性值
2.class选择器(类选择器): .class其中一个属性值
3.属性选择器: [属性名='属性值'] 标签名[属性名='属性值']
4.元素选择器: 标签名
# 1).使用CSS定位方式中id选择器定位用户名输入框,并输入: admin
driver.find_element_by_css_selector("#userA").send_keys("admin")
time.sleep(2)
# 2).使用CSS定位方式中class选择器定位电话号码输入框,并输入:18600000000
driver.find_element_by_css_selector(".telA").send_keys("18600000000" )
time.sleep(2)
#3).使用CSS定位方式中属性选择器定位密码输入框,并输入:123456
driver.find_element_by_css_selector("input[placeholder='请输入密码']").send_keys( "123456")
time.sleep(2)
#4).使用CSS定位方式中元素选择器定位注册按钮,并点击
driver.find_element_by_css_selector("button").click()
5.层级选择器
- 父子关系:定位父级元素>子元素
- 后代关系:定位祖辈元素 后代元素
# 父子关系:定位用户名输入框,输入admin
driver.find_element_by_css_selector("#pa>input").send_keys("admin ")
time.sleep(2)
# 后代关系:定位用户名输入框,输入admin
driver.find_element_by_css_selector("#pa input").send_keys("admin")
3.2.2 CSS定位-延伸
input[type^='p'] 说明:type属性以p字母开头的元素
input[type$='d'] 说明:type属性以d字母结束的元素
input[type*='w'] 说明:type属性包含w字母的元素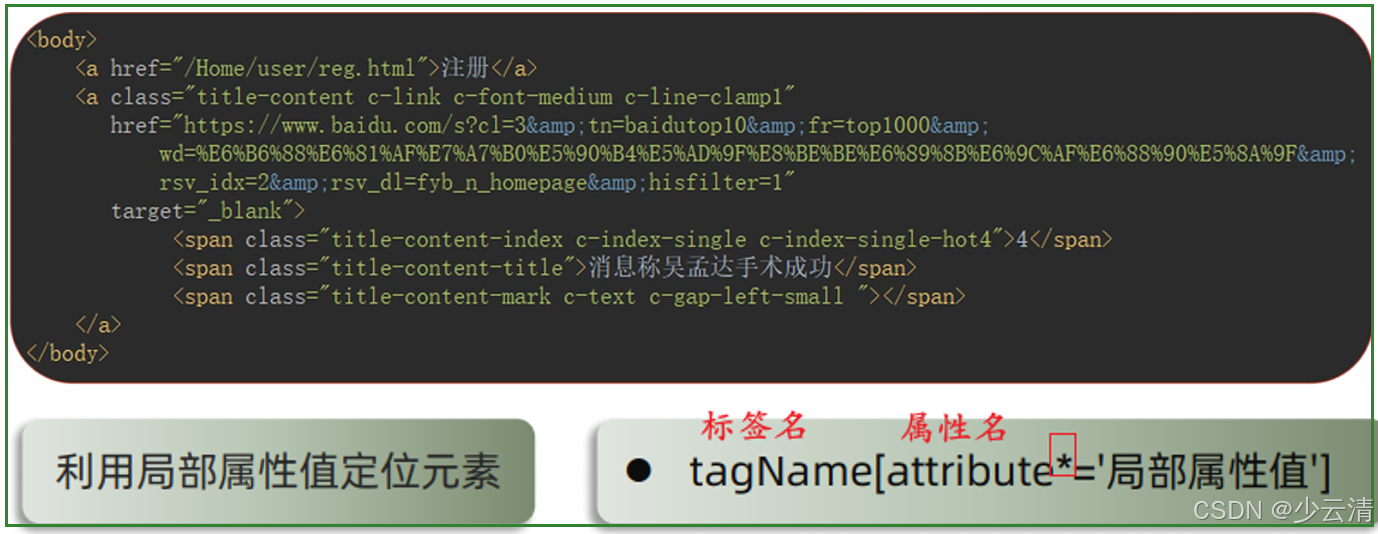
3.2.2 CSS-总结
| 选择器 | 例子 | 描述 |
|---|---|---|
| #id | #userA | id选择器,选择id="userA"的所有元素 |
| .class | .telA | class选择器,选择class="telA"的所有元素 |
| element | input | 选择所有input元素 |
| attribute=value | type="password" | 选择type="password"的所有元素 |
| element>element | p>input | 选择所有p元素下所有的input元素 |
3.3 XPath与CSS类似功能对比
| 定位方式 | XPath | CSS |
|---|---|---|
| 元素名(标签名称) | //input | input |
| id | //input@id='userA' | #userA |
| class | //*@class='telA' | .telA |
| 属性 | 1. //*[text()="xxx"] 2. //*[starts-with(@attribute,'xxx')] 3. //*[contains(@attribute,'xxx')] |
1. inputtype\^='p' 2. inputtype$='d' 3. inputtype\*='w' |
四、元素定位的另一种写法
- 8种元素定位的另外一种实现方式,也是selenium提供的固定方法。
- 注意:在最新版本selenium 4.1只有下面的写法了:
python
from selenium.webdriver.common.by import By # 导包
8种元素定位方式底层都是调用driver.find_element(by=通过By来指定定位方式,value='选中的定位所对应的值')By需要导包,快捷导包方式, ALT+ENTER回车
快捷导包:
- ①写好类名,千万别写错
- ②光标放置到类名后,按alt+回车 ---> 选择import 包
python
方法:find_element(By.ID,"userA")
备注:需要两个参数,第一个参数为定位的类型由By提供,第二个参数为定位的具体方式
示例:
driver.find_element(By.CSS_SELECTOR,'#emailA').send_keys("123@126.com")
driver.find_element(By.XPATH,'//*[@id="emailA"]').send_keys('234@qq.com')
driver.find_element(By.ID,"userA").send_keys("admin")
driver.find_element(By.NAME,"passwordA").send_keys("123456")
driver.find_element(By.CLASS_NAME,"telA").send_keys("18611111111")
driver.find_element(By.TAG_NAME,'input').send_keys("123")
driver.find_element(By.LINK_TEXT,'访问 新浪 网站').click()
driver.find_element(By.PARTIAL_LINK_TEXT,'访问').click()
"""
目标:讲解find_element使用
场景:后期项目封装中,使用元素查找方法
目的:对后期封装元素查找方法
"""
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 1. 创建一个Chrome浏览器实例
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("http://www.baidu.com")
# 3. 使用By类,使用send_keys()方法模拟输入:我爱你
driver.find_element(By.CSS_SELECTOR, "#kw").send_keys("我爱你")
# 4. 模拟点击搜索按钮
driver.find_element_by_id("su").click()
# 5. 暂停3秒
sleep(3)
# 6、关闭浏览器
driver.quit()五、元素定位方式的选择
- 有ID优先使用ID定位,无ID--->看Name属性--->无Name属性--->看class属性。
- 无CLASS属性--->看其他属性(能代表唯⼀的属性 )
- 单个属性不行--->使用多个属性。
- 属性都不能精准定位--->层级
- 看文本
- 定位一组元素,通过下标来选择
- copy表达式(●注意:分析copy出来的表达式为什么可以找到对应的原因)
yacas
建议:如果记忆有一些混淆的情况,降低记忆的工作量,可以直接全部都使用XPATH定位