第一阶段:小白入门 ------ 为什么会有分布式事务?
- 以前的世界(单体应用)
在单体应用时代(一个 Spring Boot 连接一个 MySQL),事务非常简单。
ACID:数据库(DB)帮你搞定了一切。
原子性(A):要么全成功,要么全失败。
原理:依赖数据库的 Connection,开启事务 -> 执行 SQL -> 提交/回滚。
结论:本地事务(Local Transaction) 是完美的。
- 现在的世界(微服务)
我们将系统拆分成了:订单服务(Order DB)、库存服务(Stock DB)、账户服务(Account DB)。
场景:用户下单。
订单库:创建订单。
库存库:扣减库存。
账户库:扣减余额。
问题:这三个库在不同的服务器上。
如果 1 和 2 成功了,3 失败了(余额没扣),怎么办?
此时,数据库的本地事务只能管自己,管不了别人。
结论:我们需要一种机制,能跨越网络,保证这三个操作要么一起成功,要么一起失败。这就是分布式事务。
第二阶段:进阶理解 ------ 两大流派(刚性 vs 柔性)
根据 CAP 定理(一致性、可用性、分区容错性不可兼得),分布式事务分为了两个流派:
- 刚性事务 (CP):死磕一致性
口号:"为了数据绝对对,我宁愿把系统卡死。"
代表:XA / 2PC。
特点:
强一致:用户看到的永远是对的。
性能差:因为要等待所有节点确认,期间数据库资源被锁死(阻塞)。
场景:银行核心系统、并发极低的后台管理。 - 柔性事务 (AP):追求高可用
口号:"允许短暂的不一致,只要最终对就行。别卡住我的业务!"
代表:TCC、Saga、事务消息、本地消息表。
特点:
最终一致:中间可能看到"扣了款但没发货"的状态,但过一会就好了。
性能高:不锁数据库资源,业务跑得快。
场景:互联网高并发业务(电商、支付、社交)。
第三阶段:高手拆解 ------ 主流方案深度剖析
这里是面试和架构设计的核心战场。
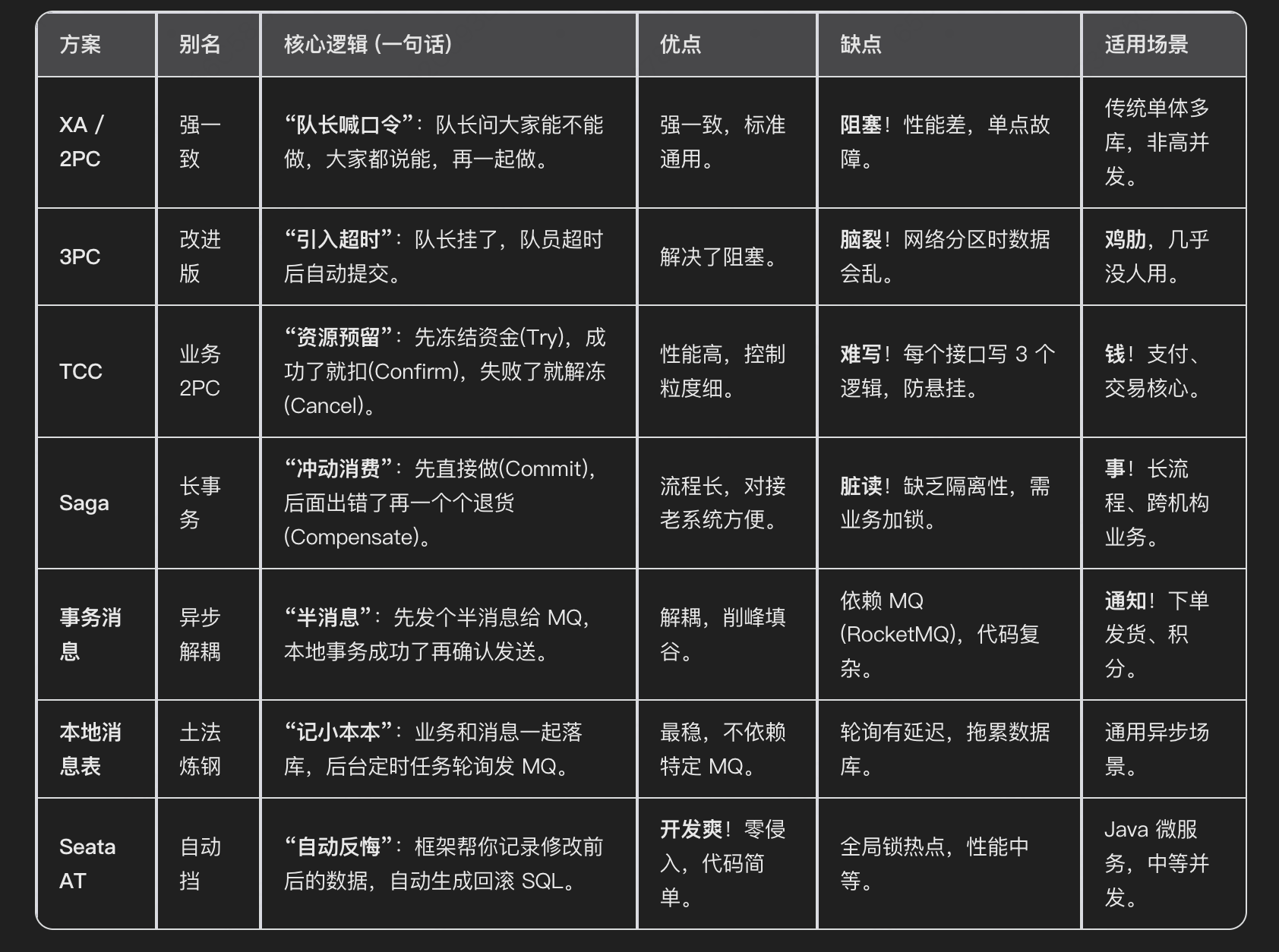
第四阶段:架构师视角 ------ 深度思考与选型 - 为什么 3PC 是个"伪命题"?
它试图用"超时自动提交"来解决 2PC 的阻塞。
但在分布式网络中,超时不代表对方挂了,可能只是网络慢。
后果:一旦"猜错",数据就乱了(脑裂)。在金融场景下,数据错比系统卡死更可怕。所以 3PC 被工业界抛弃。 - Saga 的"脏读"怎么解?
Saga 是直接提交本地事务的,所以中间状态(如扣了库存但还没扣款)对别人是可见的。
解法:必须在业务层面加**"语义锁"**。
比如:库存扣减后,打个标 status = FREEZING。
别的事务看到这个标,就绕道走,或者只读不改。 - TCC 的"空回滚"与"悬挂"
空回滚:Try 没收到(丢包),Cancel 却到了。Cancel 必须能识别并返回成功。
悬挂:Cancel 比 Try 先到(网络乱序)。Cancel 执行完后,Try 才到。Try 必须能识别并拒绝执行。
结论:写 TCC 不仅仅是写业务逻辑,更多是在处理网络异常。 - 终极选型决策树 (Cheat Sheet)
当你面临技术选型时,问自己三个问题:
涉及到钱吗?(强一致性)
是 -> TCC(最稳,但最贵)。
是(但开发资源不足) -> Seata AT(Java 栈首选)。
流程很长吗?(涉及第三方)
是 -> Saga(因为你没法让第三方配合你做 TCC)。
允许延迟吗?(非核心链路)
是(如发短信、送积分) -> 事务消息 / 本地消息表(RocketMQ 是神器)。
总结
分布式事务没有"银弹",只有取舍(Trade-off)。
ACID 是单机的童话。
BASE(基本可用、软状态、最终一致性)是分布式的现实。
从 2PC 到 TCC 再到 Saga,我们一直在用 "业务复杂度的上升" 来换取 "系统吞吐量的提升"。