本文分享我真实的技术演进案例:从一个高性能定时器库,到成为一款零信任网络接入产品,这个过程历经四个阶段,每一步都建立在前一个阶段的技术积累之上。
阶段一:定时器
什么是定时器
定时器(Timer)是计算机系统中用于在指定时间触发某个动作或事件的基础工具。从硬件到应用层,定时器贯穿整个计算机系统,是构建可靠软件系统的基础设施。
在服务端和嵌入式系统中,定时器广泛用于:
- 任务调度 - 周期性执行任务(如日志轮转、缓存清理)
- 超时控制 - 连接空闲超时、请求超时、重试超时
- 延迟执行 - 延迟操作或重试逻辑(如退避重连)
- 时间同步 - 系统时间校准、分布式系统时钟同步
- 性能监控 - 统计任务执行时间、性能分析
看似简单的定时器,一旦进入高并发场景,就会成为系统瓶颈的根源。
定时器栈
bash
┌───────────────┐
│ Hardware │
│ (TSC/HPET) │
└───────┬───────┘
│ interrupt
▼
┌───────────────┐
│ hrtimer │
│ (RB-Tree) │
└───────┬───────┘
│ wakeup
▼
┌───────────────┐
│ epoll/nanosleep
└───────┬───────┘
│ return
▼
┌───────────────┐
│ Timer Heap │
│ / Time Wheel │
└───────┬───────┘
│ callback
▼
┌───────────────┐
│ Your Code │
└───────────────┘定时器的实现涉及多个层次,从硬件到应用层,每一层都提供了不同的能力:
硬件层能力
硬件定时器是计算机系统最底层的定时能力,通常由以下组件提供:
- CPU 定时器(TSC - Time Stamp Counter):CPU 内置的高精度计数器,提供纳秒级时间戳
- HPET(High Precision Event Timer):高精度事件定时器,提供微秒级精度
- RTC(Real-Time Clock):实时时钟,提供系统时间基准
- APIC Timer(Advanced Programmable Interrupt Controller):可编程中断控制器定时器,用于多核调度
硬件定时器的特点:
- 精度极高:纳秒到微秒级精度
- 低延迟:硬件中断,响应速度快
- 系统级:由操作系统内核管理,应用层通过系统调用使用
操作系统层能力
操作系统在硬件定时器基础上,提供了多种定时器接口:
Linux 系统:
-
timerfd:基于文件描述符的定时器,可集成到 epoll/select 事件循环
cint timerfd_create(int clockid, int flags); int timerfd_settime(int fd, int flags, const struct itimerspec *new_value, struct itimerspec *old_value); -
hrtimer(High Resolution Timer):内核高精度定时器,支持纳秒级精度
-
POSIX Timer:标准化的定时器接口,支持多种时钟源
-
alarm / setitimer:传统定时器接口,精度较低(秒级)
应用层实现方式
| 类型 | 实现特点 | 优缺点 |
|---|---|---|
| 最小堆 / 红黑树 | 每个 timer 按时间戳排序,堆顶即最近到期 | 精度高,插入 O(log N),海量任务开销大 |
| 时间轮(Timing Wheel) | 将时间划分为固定 tick,任务放到对应槽位 | O(1) 插入/删除,适合海量定时器,精度受 tick 限制 |
| OS sleep / nanosleep | 挂起线程,内核计时器到期唤醒 | 简单,但阻塞线程,不适合大量并发 |
| timerfd / epoll | 基于文件描述符的定时器,集成到事件循环 | 高效,适合事件驱动模型,需要系统支持 |
| 用户态轮询 | 应用层循环检查时间,主动触发 | 实现简单,但占用 CPU,精度受轮询间隔影响 |
定时器实现
指标
评估一个定时器实现是否适合高并发场景,需要关注以下指标:
- 精度 - 纳秒、微秒、毫秒级,不同场景要求不同
- 并发容量 - 可同时管理的定时器数量
- 插入/删除复杂度 - O(1) vs O(log N),直接影响高并发性能
- goroutine/线程开销 - 每个定时器是否需要独立的执行线程
- 可扩展性 - 是否支持分层管理长超时(秒→分→时)
技术方案对比
在确定 go-timer 的技术路线之前,我们对主流的定时器实现做了详细对比:
| 特性 | Go 标准库 Timer(最小堆) | 时间轮(go-timer) | timerfd / epoll | OS sleep |
|---|---|---|---|---|
| 数据结构 | 最小堆 | 时间轮槽链表 | 内核红黑树 + epoll | 内核计时器 |
| 插入复杂度 | O(log N) | O(1) | O(log N) | O(1) |
| 删除复杂度 | O(log N) | O(1) | O(log N) | O(1) |
| 精度 | 高(纳秒/微秒级) | Tick 粒度(毫秒级) | 高(纳秒级) | 低(秒级) |
| 并发 goroutine | 每个回调可能 spawn goroutine | 少量 goroutine 扫描槽位 | epoll + goroutine | 阻塞线程 |
| 适用场景 | 少量定时任务、高精度 | 海量长连接、批量定时任务 | 事件驱动、高精度 | 简单延迟任务 |
| 内存占用 | 堆结构 + channel | 固定 slot + 链表 | 内核对象 + fd | 内核对象 |
| 可扩展性 | 大规模任务受限 | 支持多层时间轮(秒→分→时) | 受系统限制 | 不适合大量任务 |
| 系统调用 | 无 | 无 | 需要 | 需要 |
Go大量长连接场景
在10万长连接场景中,如果继续使用 Go 标准库的方式,每个连接通常需要至少一个定时器(心跳检测、空闲超时等):
go
// 典型的 per-connection 超时模式
go func() {
<-time.After(timeout)
closeConn()
}()会产生严重的系统问题:
- 大量 goroutine → 内存和调度压力大。100 万连接意味着至少 100 万个 goroutine 仅用于超时检测
- 最小堆频繁调整 → CPU 开销随连接数增长。每次插入/删除都是 O(log N),N = 100 万时堆调整代价显著
- 回调延迟波动大 → 任务触发不可预测。高负载下 goroutine 调度延迟可能从微秒级恶化到毫秒级
我的实现:go-timer
go-timer 用时间轮算法实现,舍弃了高精度而加强其他指标。
时间轮算法原理
时间轮的核心思想是:将时间划分为固定长度的 tick(如 10ms),用一个环形数组(wheel)表示时间槽位。每个 tick 推进一个槽位,将该槽位上的所有到期任务取出执行。
- 插入 :计算
delay / tick得到目标槽位,O(1) 挂入链表 - 删除:直接从链表摘除,O(1)
- 触发:指针到达槽位时,遍历链表触发所有到期任务
对于超过一圈的长超时,使用多层时间轮(类似时钟的秒针、分针、时针),将长超时任务逐级降级到更细粒度的轮上。
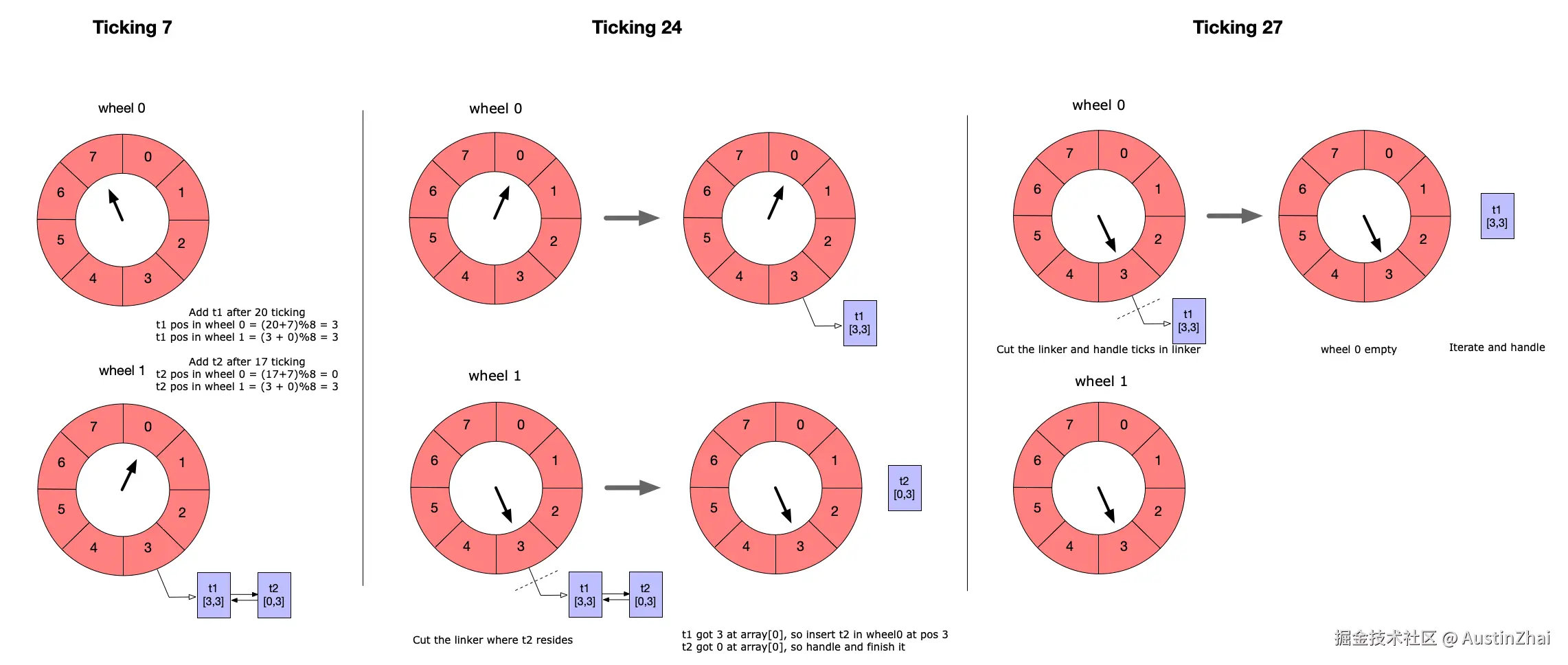
这个图展示了一个多层时间轮定时器,每层有8个tick。
- 第7tick:添加从现在开始第20个tick的t1和第17个tick的t2,按照计算,t1和t2都插入在第2层时间轮的第3 slot里。
- 第24tick:t2时间到了,从链表摘除;t1还剩3个tick,插入在第1层时间轮的第3 slot里。
- 第27tick:t1时间到了,从链表摘除。
我实现的特性
- O(1) 插入/删除 - 适合海量长连接,不会随连接数增长而退化
- 少量 goroutine 驱动 - 一个或少量扫描 goroutine 即可处理所有超时,资源消耗极低
- 精度可控 - 通过 tick 设定精度,毫秒级 tick 足以满足心跳和空闲超时需求
- 可扩展分层 - 支持秒、分、小时级长超时任务,不浪费内存
- 统一事件循环 - 避免每连接单独 goroutine,大幅提高 CPU 和内存效率
- 异步回调支持 - 高效的事件驱动模型,回调函数在工作 goroutine 池中执行
- 循环定时支持 - 原生支持周期性任务,到期后自动重新插入时间轮
使用示例
go
// 创建定时器
t := timer.NewTimer()
// 添加1秒到期后异步处理
t.Add(time.Second, timer.WithData(time.Now()), timer.WithHandler(func(event *timer.Event) {
log.Printf("time elapsed: %fs\n", time.Now().Sub(event.Data.(time.Time)).Seconds())
}))对比效果:同样管理 10 万个连接超时
| 指标 | Go 标准库方案 | go-timer 方案 |
|---|---|---|
| goroutine 数量 | 10 万+ | 2(固定工作池) |
| 内存开销 | ~200MB(goroutine 栈) | ~4KB(时间轮 + 链表) |
| 插入/删除 | O(log N) | O(1) |
| CPU 开销 | 高(堆调整 + goroutine 调度) | 低(线性扫描当前槽位) |
应用场景
- 长连接心跳检测 - 每个连接设置心跳定时器,超时未收到心跳则断开
- 请求超时控制 - RPC 请求、HTTP 请求的超时管理
- 重试退避 - 连接断开后的延迟重连,支持指数退避策略
- 缓存过期 - TTL 缓存的过期清理
- 事件驱动系统 - 延迟事件、定时触发
技术积累
go-timer 看似只是一个基础库,但它奠定了整个技术体系的根基:
- 高并发资源管理 - 如何用固定资源处理海量任务,这个思路贯穿了后续所有阶段
- 事件驱动模型 - 统一事件循环的设计模式直接影响了 geminio 的架构
- 工程化的性能优化 - 不是追求理论最优,而是在精度和性能之间找到工程上的最佳平衡点
简而言之,go-timer 是在 Go 生态中为海量长连接和高并发定时任务提供的必需工程方案,弥补了标准库 timer 在大规模场景下的短板。它不仅解决了定时器本身的问题,更重要的是形成了一套用有限资源管理海量任务的技术理念,这个理念成为后续每一个阶段的设计基石。
阶段二:网络框架
从定时器到网络
有了高性能的定时器,下一个自然的问题出现了:如何构建一个高效、可靠的网络通信框架?
什么是长连接
长连接(Long Connection / Persistent Connection)是指客户端和服务器之间建立的连接在完成一次数据交换后不立即关闭,而是保持连接状态,以便后续的数据传输可以复用这个连接。
与短连接(每次请求都建立新连接)相比,长连接具有以下优势:
- 减少连接建立开销 - TCP 三次握手、TLS 握手等只在建立连接时执行一次
- 降低延迟 - 复用已有连接,无需等待连接建立
- 提高吞吐量 - 避免频繁的连接建立和关闭,减少系统资源消耗
- 支持双向通信 - 服务端可以主动推送数据,无需客户端轮询
- 状态保持 - 连接可以维护会话状态,适合有状态的应用场景
长连接广泛应用于:
- 实时通信 - WebSocket、即时消息、推送服务
- IoT 设备管理 - 设备与云端保持连接,实时监控和控制
- 微服务通信 - 服务间长连接,减少网络开销
- 边缘计算 - 边缘设备与中心节点的持续连接
- 游戏服务器 - 玩家与游戏服务器的实时交互
长连接框架的关键指标
评估一个长连接框架的能力,可以关注以下核心指标:
| 指标 | 含义 |
|---|---|
| 全双工 | 是否客户端和服务端都可随时主动发送数据 |
| 序列化 | 是否有强约束的编码格式(如 Protobuf、JSON、自定义二进制) |
| 多路复用 | 单连接是否支持多个独立逻辑流(Stream/Channel) |
| 一致性 | 是否内建顺序保证 / 流级顺序保证 |
| 消息语义 | 是否偏消息驱动(Pub/Sub、消息队列模式) |
| RPC语义 | 是否天然支持请求-响应、方法调用 |
| 流语义 | 是否支持流式传输(Streaming)、双向流、流控 |
主流框架对比
在确定技术方案之前,我们对主流的长连接框架进行了详细对比:
| 框架 | 全双工 | 序列化 | 多路复用 | 一致性 | 消息语义 | RPC语义 | 流语义 | 适用场景 |
|---|---|---|---|---|---|---|---|---|
| gRPC | 支持 | Protobuf | 支持 (HTTP/2) | 支持 | 不支持 | 支持 | 支持 | 微服务、RPC调用 |
| WebSocket | 支持 | 自定义 | 不支持 | 不支持 | 不支持 | 不支持 | 支持 | 浏览器实时通信 |
| MQTT | 支持 | 二进制 | 不支持 | 不支持 | 支持 (Pub/Sub) | 不支持 | 不支持 | IoT、消息推送 |
| HTTP/2 | 支持 | HTTP | 支持 | 支持 | 不支持 | 支持 | 支持 | Web、API网关 |
| QUIC | 支持 | 自定义 | 支持 | 支持 | 不支持 | 不支持 | 支持 | 低延迟传输 |
各框架的特点:
- gRPC - 基于 HTTP/2,支持多路复用和流式传输,但主要面向 RPC 场景,消息语义较弱
- WebSocket - 浏览器原生支持,但缺乏多路复用和一致性保证
- MQTT - 专为 IoT 设计,支持 Pub/Sub,但不支持 RPC 和多路复用
- HTTP/2 - 支持多路复用,但主要面向请求-响应模式,双向推送能力有限
- QUIC - 基于 UDP 的传输协议,支持多路复用和低延迟,但主要面向传输层,应用层协议需要自行实现
为什么我不直接使用主流框架,我的需求是:
我需要一个复合的长连接框架,它能够:
- 既支持多路复用和全双工 - 单连接承载多个逻辑流,客户端和服务端都可主动发送
- 满足一致性要求 - 流级顺序保证,确保消息可靠传递
- 同时支持多种语义 :
- 消息语义 - Pub/Sub、消息队列模式
- RPC语义 - 请求-响应、方法调用
- 流语义 - 双向流、流式传输
- 能够同时支持控制面和数据面 - 在同一个连接上,控制信令和业务数据可以并行传输,通过不同的 Stream 隔离
这样的框架可以让我在一个连接上同时处理:
- 控制面的 RPC 调用(如设备注册、配置更新)
- 数据面的消息推送(如状态通知、事件上报)
- 流式数据传输(如文件传输、视频流)
这就是我选择开发 geminio 的原因 - 它在一个复合框架内,同时满足了所有这些需求。
我的方案:geminio
geminio 是一个专注于长连接场景的网络框架,它的设计充分利用了前一阶段的技术积累,并针对上述指标进行了优化。
| 指标 | geminio 实现 |
|---|---|
| 全双工 | 支持 - 客户端和服务端完全对等,都可主动发送 |
| 多路复用 | 支持 - 单连接支持多个独立 Stream,每个 Stream 独立管理 |
| 一致性 | 支持 - 流级顺序保证,每个 Stream 内消息有序 |
| 消息语义 | 支持 - 原生支持 Messaging 模式(Pub/Sub、队列) |
| RPC语义 | 支持 - 原生支持 RPC 调用(请求-响应、方法调用) |
| 流语义 | 支持 - 原生支持双向流、流式传输、流控 |
分层设计
为了降低设计复杂度,我对geminio进行了分层设计,每个层级只专注处理自己层级的逻辑:
- 传输层:建立和维持长连接,所有的包识别处理、重连机制都在这里实现
- 会话层:多路复用,管理不同会话
- 应用层:在会话层之上抽象出消息、RPC和流
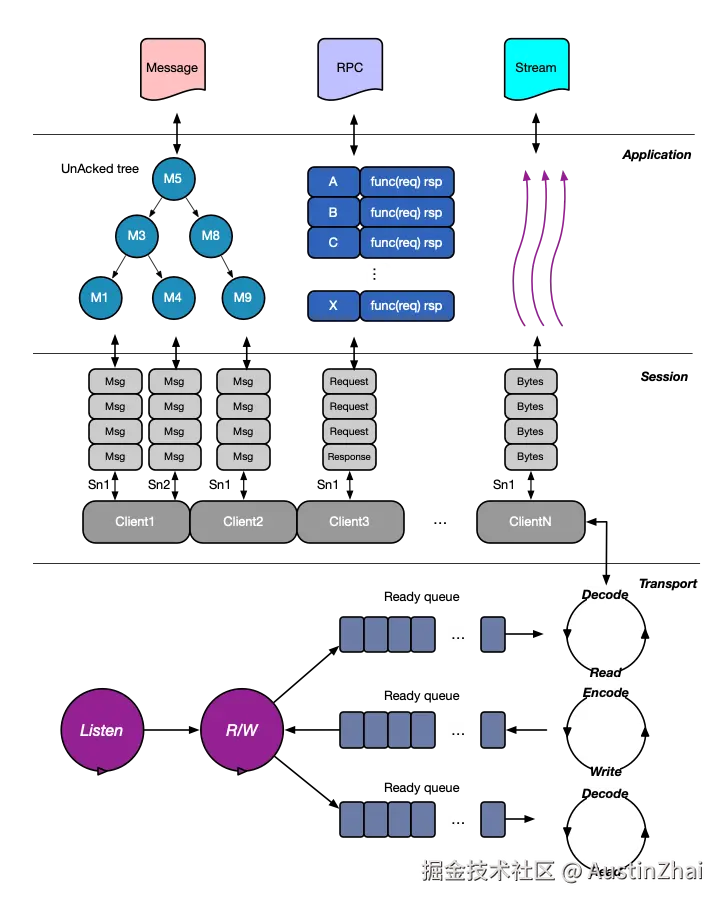
多路复用
为了实现多路复用,我在传输层之上设计了会话层,所有的数据包都携带SessionID来分区会话,这也是geminio能够在一个长连接里能够同时看电影、传文件、访问网站的原因。
我把会话层设计为Initiator和Recipient,意思是客户端或服务端,都可以主动发起会话。例如服务端打开一个会话后,主动向客户端推送文件,完成后关闭这个会话。
握手和挥手:
两次握手:为什么是两次握手,因为我们连接默认是在TCP之上构建,不需要考虑网络层包不稳定带来的丢包问题。
sql
Initiator Recipient
| |
|-- SessionPacket ------------->|
| (negotiatingID) | Create new Dialogue
| | Add to negotiatingDialogues
| |
|<-- SessionAckPacket ----------|
| (dialogueID) | Assign dialogueID
| | Move to dialogues
| |
|-- DataPacket(dialogueID) ---> |
| | Route to corresponding Dialogue四次挥手:为什么是四次挥手,因为我们是全双工语义,Initiator和Recipient是分开终结自己的生命周期。
sql
Initiator Recipient
| |
| State: SESSIONED | State: SESSIONED
| |
|-- DismissPacket ------------->|
| State: DISMISS_SENT | State: DISMISS_RECV
| | Send DismissAckPacket
| | Call Close() -> Send DismissPacket
| |
|<-- DismissAckPacket ----------|
| State: DISMISS_HALF | State: DISMISS_SENT
| |
|<-- DismissPacket -------------|
| State: DISMISS_HALF | (waiting for DismissAckPacket)
| Send DismissAckPacket |
| |
|-- DismissAckPacket ---------->|
| State: DISMISSED | State: DISMISS_HALF
| |
| Close Complete | State: DISMISSED
| | Close Complete一致性
在所有的端到端系统或通信,都会涉及到两个问题:
- 顺序的一致性,我发送的消息和我接收的消息,顺序是否一致
- 消息的到达语义,最多一次、至少一次和准确处理一次
顺序一致性的解决:
-
Channel FIFO 保证:
- 所有数据包通过 Go channel 传递
- Channel 是 FIFO(先进先出)的,天然保证顺序
- 数据包在 channel 中按发送顺序排队
-
状态机顺序处理:
- 状态机按顺序处理事件,确保状态转换的一致性
- 防止乱序事件导致的状态不一致
-
阻塞发送保证顺序:
- 数据包通过阻塞 channel 发送,确保按顺序发送到网络
- 发送方必须等待前一个数据包发送完成才能发送下一个
-
单线程处理:
- 每个 Dialogue 有独立的
handlePkt()goroutine - 单线程处理接收的数据包,保证处理顺序
- 每个 Dialogue 有独立的
ini
发送方顺序: Packet1 → Packet2 → Packet3
↓ ↓ ↓
Channel: [P1][P2][P3] (FIFO队列)
↓ ↓ ↓
接收方顺序: Packet1 → Packet2 → Packet3 (顺序一致)消息到达一致性的考虑:
我没有采用MQTT的QoS的设计类型,而是把语义传递的一致性给到应用层:
- 消息:接收方必须显示的Done()或者Error(),这样发送方能够显示的明确对方已经收到;如果超时或者错误,但是实际接收方已经完成,那是否再发送或者再处理,用户可以根据自己的场景处理。
- RPC:原生就有接收语义,因为一定会有Response或错误。
scss
发送方 接收方
| |
|-- MessagePacket(PacketID) -->|
| | 处理消息
| | 发送确认
|<-- MessageAckPacket(PacketID)|
| | 返回成功
| |应用层的抽象
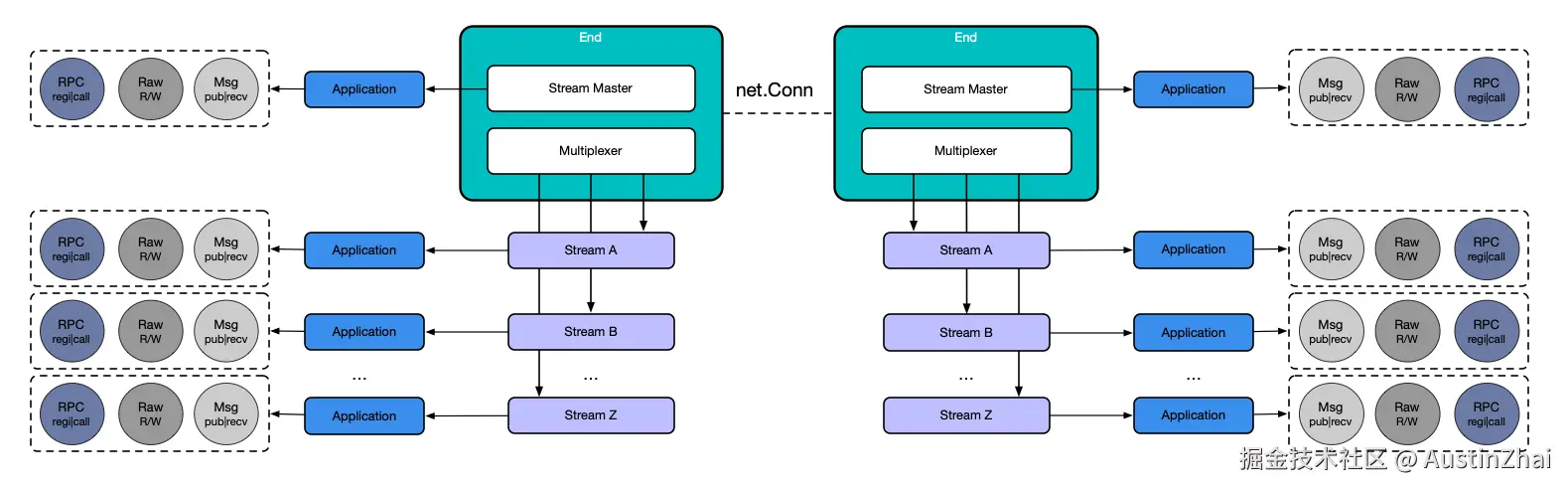
这些能力,我要怎么提供给用户使用,本质是个API设计问题。在应用层,我把net.Conn提供方法转换为End,在geminio看来,Server和Client的net.Conn都是对等的End,于是在两边我都使用End来提供Messaging、RPC和Raw读写能力:
与 go-timer 的集成
geminio 充分利用了 go-timer 的能力:
- 连接心跳 - 使用定时器实现高效的心跳检测,保持连接活跃
- 超时控制 - RPC 请求超时、连接空闲超时等都依赖定时器
这种技术复用大大降低了开发成本,同时保证了系统的稳定性和性能。
应用场景
- 数据面+控制面 - 同一连接同时处理业务数据和控制信令,通过不同的 Stream 隔离
- 长连接网关 - 支持百万级长连接,每个连接可承载多个逻辑流
- 双向通信 - P2P 通信、推送服务,客户端和服务端完全对等
- 文件/多媒体传输 - 大文件传输、视频流,利用 Stream 模式
- 混合协议 - 在同一个连接上同时使用 RPC、消息队列、流式传输等多种模式
阶段三:长连接网关
有了可靠的网络框架,我们开始面对更大的挑战,不论你是客户端推送、IM、边缘计算和控制、IoT管理等,对于实时通信来说,**如何管理百万级的长连接设备?**这不再只是一个技术框架的问题,而是一个完整的产品级挑战。
什么是长连接网关
长连接网关是一种专门用于管理和维护大量长连接的中间件系统。它位于业务服务和边缘设备之间,负责:
- 连接管理 - 维护大量设备的长连接,处理连接建立、保持、断开
- 消息路由 - 在业务服务和边缘设备之间路由消息和数据
- 负载均衡 - 将连接和请求分发到多个网关实例,实现水平扩展
- 状态管理 - 跟踪设备在线状态、连接健康度
- 协议转换 - 在不同协议之间进行转换和适配
长连接网关的关键指标
评估一个长连接网关的能力,可以关注以下核心指标:
| 指标 | 含义 |
|---|---|
| 并发连接 | 单个网关实例能同时管理的最大连接数 |
| 水平扩展 | 是否支持多实例部署,通过增加实例提升总容量 |
| 高可用 | 单实例故障时,连接能否自动迁移到其他实例 |
| 连接保持 | 连接断开后是否支持自动重连,重连策略如何 |
| 消息路由 | 是否支持消息路由、广播、组播等能力 |
| 协议支持 | 支持哪些应用层协议(RPC、消息、流等) |
| 设备抽象 | 如何抽象和管理设备,是否支持设备分组、标签 |
| 云原生 | 是否支持 Kubernetes、服务发现等云原生能力 |
| 安全性 | 是否支持 TLS 加密、设备认证、权限控制 |
网关对比
在确定技术方案之前,我们对相关的网关和中间件进行了调研。需要说明的是,互联网上专门针对长连接场景的网关产品相对较少,大多数是:
- API 网关 - 主要面向 HTTP 短连接,如 Kong、Traefik、Envoy
- 消息中间件 - 主要面向消息队列,如 RabbitMQ、Kafka、RocketMQ
- 服务网格 - 主要面向微服务间通信,如 Istio、Linkerd
这些产品虽然功能强大,但都不是专门为长连接场景设计的。我们对比了一些可能相关的方案:
| 方案 | 连接容量 | 水平扩展 | 高可用 | 连接保持 | 协议支持 | 适用场景 |
|---|---|---|---|---|---|---|
| Kong / Traefik | 高(HTTP连接池) | 支持 | 支持 | 不支持 | HTTP/1.1, HTTP/2 | API网关、反向代理 |
| Envoy | 高 | 支持 | 支持 | 不支持 | HTTP/2, gRPC | 服务网格、API网关 |
| MQTT Broker | 中(单实例万级) | 有限 | 有限 | 支持 | MQTT | IoT消息推送 |
| WebSocket Gateway | 中 | 支持 | 支持 | 支持 | WebSocket | 实时通信 |
| 自研方案 | 高(百万级) | 支持 | 支持 | 支持 | 自定义协议 | 长连接网关 |
各方案的特点:
- Kong / Traefik - 优秀的 API 网关,但主要面向 HTTP 短连接,不支持长连接管理
- Envoy - 功能强大的代理,但主要面向服务网格场景,长连接管理能力有限
- MQTT Broker - 专为 IoT 设计,但只支持 MQTT 协议,不支持 RPC 和多路复用
- WebSocket Gateway - 支持 WebSocket 长连接,但缺乏多路复用和一致性保证
为什么需要专门的长连接网关:
现有的网关和中间件主要面向:
- 短连接场景 - HTTP 请求-响应模式
- 消息队列场景 - 异步消息传递
- 服务网格场景 - 微服务间通信
而长连接网关需要:
- 连接生命周期管理 - 维护连接状态,处理重连
- 双向通信 - 服务端和客户端都可主动发送
- 多协议支持 - 同时支持 RPC、消息、流等多种语义
- 设备抽象 - 将连接抽象为设备,支持设备管理
这就是为什么我需要专门的长连接网关解决方案。
我的方案:frontier
frontier 是支持rpc、消息和流,微服务和边缘节点/客户端互相直达,在geminio之上构建。
特性支持
| 指标 | frontier 实现 |
|---|---|
| 水平扩展 | 支持 - 多实例部署,通过负载均衡分发连接 |
| 高可用 | 支持 - 无状态设计,单实例故障不影响整体服务 |
| 连接保持 | 支持 - 基于 go-timer 实现智能重连,支持指数退避策略 |
| 协议支持 | 支持 - 继承 geminio 的能力,支持 RPC、消息、流等多种语义 |
| 设备抽象 | 支持 - Service 和 Edge 抽象,清晰的服务端与边缘设备分离 |
| 可观测性 | 支持 - 提供连接状态监控、流量统计、健康检查 |
| 云原生 | 支持 - 提供 Kubernetes CRD,与云原生生态无缝集成 |
| 安全性 | 支持 - TLS 加密、设备认证、权限控制 |
网关设计
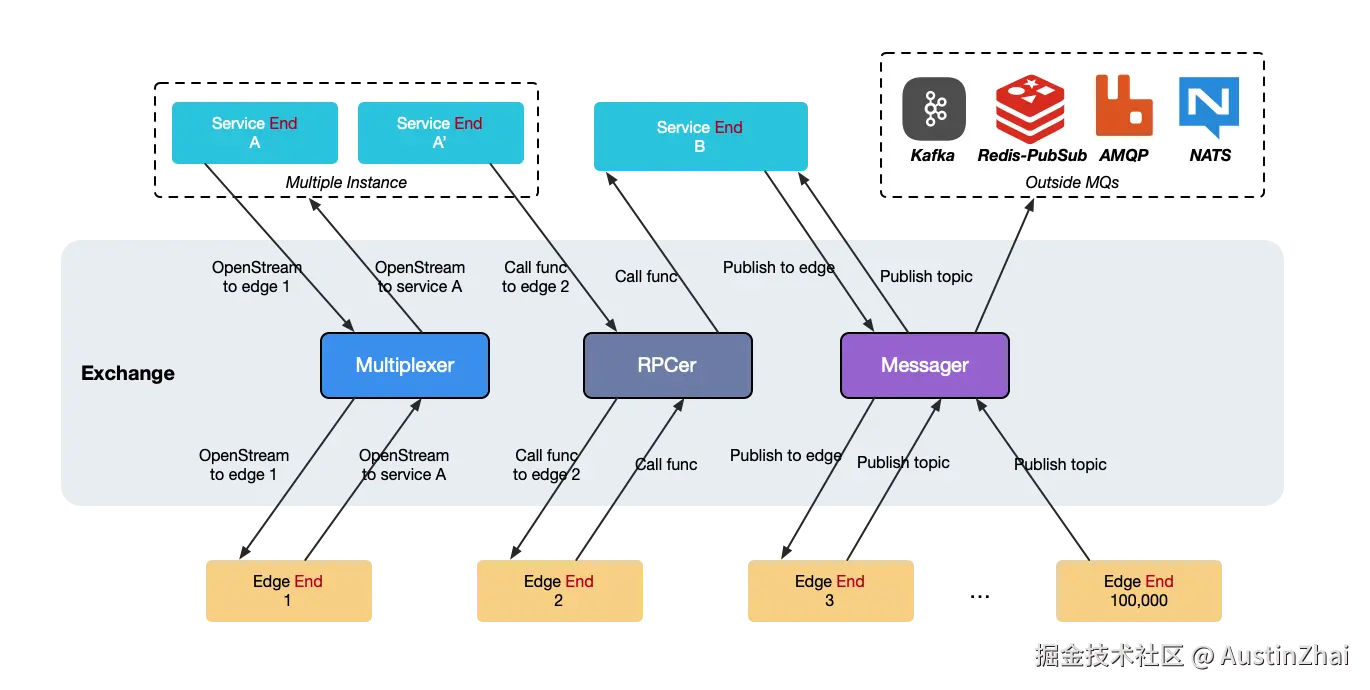
我把网关抽象为Service、Exchange、Edge和外部MQ。对于服务,连接到Frontier之后,会获取到代表自己的Service,对于客户端,连接到Frontier之后,会获取到代表自己的Edge。Service和Edge之间的协议,支持从geminio带过来的能力,包括RPC、消息、流语义。除此之外对于消息类型,还支持额外向Kafka、Redis、RabbitMQ和NATS Publish消息。
Frontier支持的非常神奇的能力是:Servie可以直接OpenStream到Edge,相当于直达Edge,你可以让Service直接上传文件到Edge。
客户端认证
Edge 客户端连接时通过 Meta 传递元数据(通常是用户标识等信息):
连接流程:
- Edge 客户端建立 TCP 连接
- 通过 Geminio 协议握手,携带
Meta信息 - Frontier 通过 Exchange 向 Service 请求分配
EdgeID- 如果 Service 不在线,根据配置决定是否自动分配 ID,这个ID用于后续Service找到Edge
- 注册 Edge 到内存缓存和数据库
EdgeID 分配机制:
go
func (em *edgeManager) GetClientID(_ uint64, meta []byte) (uint64, error) {
// 优先从 Exchange 获取 EdgeID(通过 Service)
if em.exchange != nil {
edgeID, err := em.exchange.GetEdgeID(meta)
if err == nil {
return edgeID, nil
}
}
// 如果 Service 不在线,根据配置决定是否自动分配
if em.conf.Edgebound.EdgeIDAllocWhenNoIDServiceOn {
return em.idFactory.GetID(), nil
}
return 0, err
}客户端上下线
如果Service设置了上下线 RPC,那么Edge的上下线都会通知到服务。
时序图:
lua
Edge Client Edgebound Manager Exchange Service
| | | |
|---- TCP Connect ---->| | |
| | | |
|---- Geminio -------->| | |
| Handshake | | |
| | | |
|<--- Get EdgeID ------| | |
| |---- GetEdgeID ------>| |
| | |---- RPC ------->|
| | |<--- EdgeID -----|
| |<--- EdgeID ----------| |
|<--- EdgeID ----------| | |
| | | |
| |---- Register Edge -->| |
| |---- ConnOnline ----->| |
| |---- Forward Setup -->| |
| | | |详细步骤:
-
连接建立 (
handleConn)- 接受 TCP 连接
- 创建 Geminio End
-
EdgeID 分配 (
GetClientID)- 优先通过 Exchange 向 Service 请求 EdgeID
- 如果 Service 不在线,根据配置决定是否自动分配
-
上线处理 (
online)- 检查是否存在旧连接,如果存在则关闭
- 添加到内存缓存
edges[edgeID] = end - 创建数据库记录
Edge - 触发
ConnOnline事件 - 通知 Exchange Edge 上线
-
设置转发 (
forward)- 调用 Exchange 设置 Edge -> Service 的转发
转发
Exchange 是 Frontier 的核心组件,负责在 Service 和 Edge 之间转发消息、RPC 调用和 Stream。它实现了 Service 和 Edge 的解耦,使得两者可以独立扩展。由于Service知道Edge的ID,Service可以直接给某个Edge发送消息、RPC调用或打开流;而Edge如果知道Service Name,也可以做到同样的效果。
yaml
Exchange
|
+--------------+--------------+
| |
Edgebound Servicebound
| |
Edge Clients Service Clients下面是转发的原理:
RPC转发流程:
- Service 发起 RPC 调用,在
Custom字段末尾携带目标EdgeID - Exchange 拦截 RPC(通过 Hijack)
- 提取
EdgeID并查找 Edge - 转发 RPC 调用到 Edge
- 将响应返回给 Service,并在
Custom中携带EdgeID
lua
Service Exchange Edgebound Edge
| | | |
|--Call RPC------>| | |
| | | |
| |--GetEdgeByID--->| |
| | | |
| |<--Edge End------| |
| | | |
| |-----------------|--Call RPC--->|
| | | |
| |<----------------|--Response----|
| | | |
|<--Response------| | |
| | | |
或者(Edge不在线):
Service Exchange Edgebound Edge
| | | |
|--Call RPC------>| | |
| | | |
| |--GetEdgeByID--->| |
| | | |
| |<--nil-----------| |
| | | |
|<--Error---------| | |Stream转发流程:
- Service 创建 Stream,在字段中指定目标
EdgeID - Exchange 解析
EdgeID - 查找对应的 Edge
- 在 Edge 端创建对应的 Stream
- 双向转发 Stream 数据(Raw、Message、RPC)
lua
Service Exchange Edgebound Edge
| | | |
|--OpenStream---->| | |
| | | |
| |--GetEdgeByID--->| |
| | | |
| |<--Edge End------| |
| | | |
| |-----------------|--OpenStream->|
| | | |
| |<----------------|--EdgeStream--|
| | | |
|<--Connected-----| | |
| | | |
|<==============Bidirectional Data================>|
| | | |
说明: Service 创建 Stream,Peer=EdgeID
Exchange 解析 EdgeID 并查找 Edge
如果 Edge 在线,建立双向 Stream 并转发数据
如果 Edge 不在线,关闭 Stream
或者(Edge不在线):
Service Exchange Edgebound Edge
| | | |
|--OpenStream---->| | |
| | | |
| |--GetEdgeByID--->| |
| | | |
| |<--nil-----------| |
| | | |
|<--Close Stream--| | |集群
Frontier 集群模式通过引入 Frontlas(Frontier Atlas)组件实现多 Frontier 实例的协调管理。Frontlas 是一个无状态的集群管理组件,使用 Redis 存储 Frontier、Service 和 Edge 的元数据信息。
核心组件:
- Frontier: 无状态的数据平面组件,可以水平扩展
- Frontlas: 无状态的集群管理组件,使用 Redis 存储元数据
- Redis: 存储 Frontier、Service、Edge 的元数据和存活信息
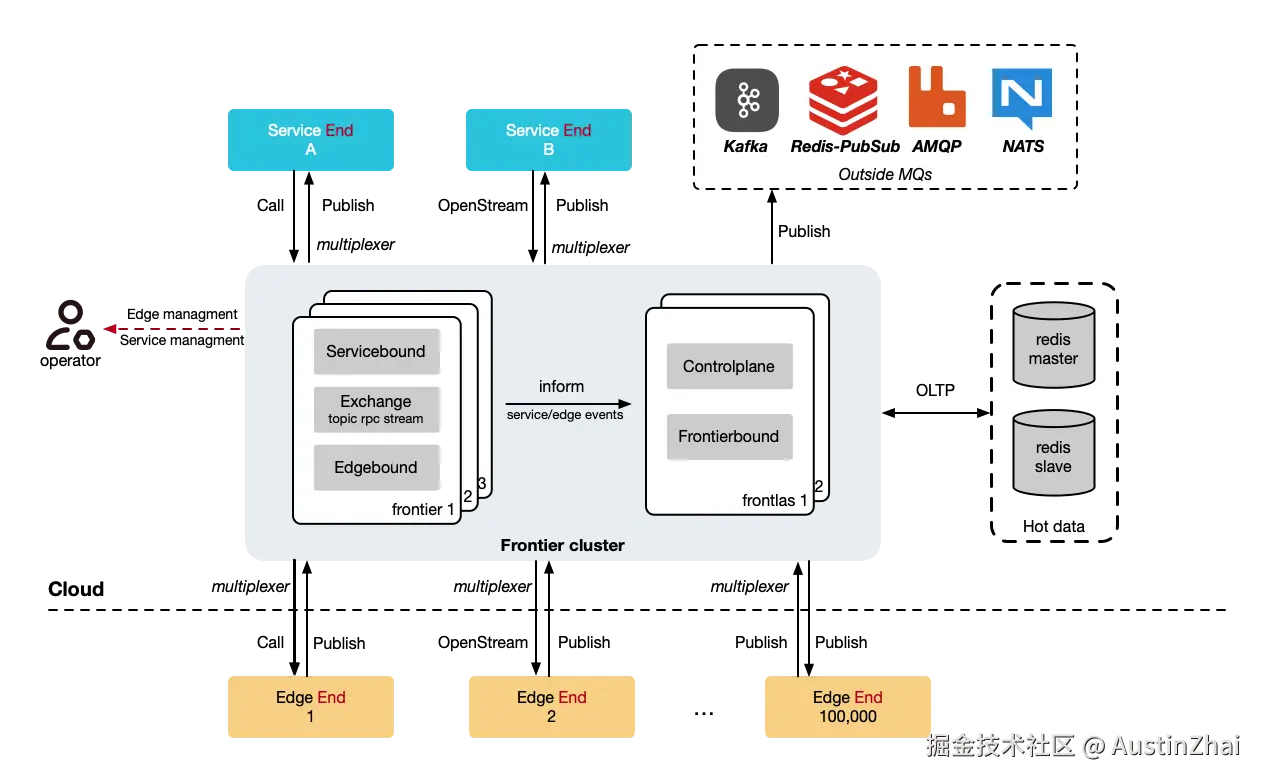
多frontier实例下的连接管理
在集群模式下,Edge 直接连接到 Frontier 实例。Edge 可以连接到任意 Frontier,当连接失败时可以重试或切换到其他 Frontier。
连接流程:
-
Edge 初始连接
- Edge 通过 Dialer 连接到指定的 Frontier 地址
- Frontier 接受连接并分配 EdgeID
- Edge 上线处理
-
Edge 上线通知
- Frontier 在本地注册 Edge
- Frontier 通过 Exchange 通知 Service(如果 Service 在线)
- Frontier 向 Frontlas 报告 Edge 上线
-
心跳续期
- Edge 每 30 秒向 Frontier 发送心跳
- Frontier 转发心跳到 Frontlas
- Frontlas 续期 Edge 的存活标记
-
连接失败处理
- Edge 连接失败时,根据配置决定是否重试
- 使用
NewRetryEdge时,会自动重连 - 可以配置连接到不同的 Frontier 地址
时序图:
css
Edge Frontier-1 Exchange Frontlas Redis
| | | | |
|--Connect------->| | | |
| |--Allocate EdgeID->| | |
| |<--EdgeID----------| | |
|<--Connected-----| | | |
| |--EdgeOnline------>| | |
| | | | |
| | |--EdgeOnline--->| |
| | | |-SetEdgeAndAlive->|
| | | |<-----Success-----|
| | |<--Success------| |
| |<----Success-------| | |
|--Heartbeat----->| | | |
| |--EdgeHeartbeat--->| | |
| | |--EdgeHeartbeat>| |
| | | |---ExpireEdge---->|
| | | |<----Success------|
| | |<--Success------| |
| |<----Success-------| | |
| | | | |水平扩展流程
-
添加 Frontier 实例
- 新 Frontier 启动并连接 Frontlas
- 在 Redis 中注册 Frontier 信息(FrontierID、地址等)
- 设置存活标记(TTL 30秒)
-
Service 发现新 Frontier
- Service 定期调用
ListFrontiers获取最新列表 - 检测到新 Frontier,自动创建连接
- 新连接加入连接池
- Service 定期调用
-
Edge 连接分配
- 新 Edge 可以连接到任意 Frontier 实例
- 通过负载均衡或随机选择
- Edge 信息记录到 Redis(关联 FrontierID)
-
流量自动分配
- 新 Edge 的请求自动路由到对应的 Frontier
- Service 通过
lookup查找 Edge 所在的 Frontier - 实现负载均衡
时序图:
scss
NewFrontier Frontlas Redis Service
| | | |
|--Connect------>| | |
| (geminio) | | |
| | | |
|--ConnOnline--->| | |
| (FrontierID, | | |
| Addr) | | |
| |-SetFrontierAlive->| |
| | (Hash + TTL) | |
| |<----Success-------| |
|<--Registered---| | |
| |<----ListFrontiers-|----------------|
| |-----FrontierList--|--------------->|
| | |--Compare Pool->|
| | |--New Frontier->|
| <--------------|-------------------|--Connect-------|
| ---------------|-------------------|-Connected----->|Redis数据模型
使用Redis来存储整个集群的在线状态,例如Edge的存储:
-
元数据(String/JSON)
-
Key:
frontlas:edges:{edgeID} -
Type: String
-
Value: JSON 格式
json{ "frontier_id": "frontier01", "addr": "192.168.1.30:54322", "update_time": 1234567890 } -
TTL: 由配置的
edge_meta决定(默认 30 秒)
-
-
存活标记(String)
- Key:
frontlas:alive:edges:{edgeID} - Type: String
- Value:
1 - TTL: 30 秒(通过心跳续期)
- Key:
示例:
ini
# Edge 元数据
frontlas:edges:67890 = '{"frontier_id":"frontier01","addr":"192.168.1.30:54322","update_time":1234567890}' (TTL: 30s)
# Edge 存活标记
frontlas:alive:edges:67890 = "1" (TTL: 30s)K8S Controller实现
我实现了一个 FrontierCluster 资源的Controller,它通过 Reconcile 函数实现声明式配置管理。
工作流程:
- 监听 CRD 变更 : Controller 监听
FrontierCluster资源的创建、更新、删除 - Reconcile 触发: 当 CRD 变更时,触发 Reconcile 函数
- 状态对比: 对比期望状态(Spec)和实际状态(Status)
- 资源创建/更新: 创建或更新 Deployment、Service 等资源
- 状态更新: 更新 CRD 的 Status 字段
时序图:
css
用户 K8s API Controller Deployment&Service
| | | |
|--Apply CRD---->| | |
| |-------Event-------->| |
| | |--Reconcile--------->|
| | |--Ensure Service---->|
| | |--Create/Update----->|
| |<--Create Service----| |
| | |--Ensure Deployment->|
| | |--Create/Update----->|
| |<--Create Deployment-| |
| | |--Check Ready------->|
| | |<-------Ready--------|
| | |--Update Status----->|
| |<--Status Update-----| | 阶段四:零信任访问产品
最后一公里的挑战
有了强大的网关系统,我就可以快速开发我想实现的网络产品,我考虑了例如SDWAN、VPN Mesh、SASE等,还是先从ZTNA访问开始,这个产品对于我自己而言也有大量使用场景。
开源产品:liaison
liaison 是一个零信任网络访问平台,将前三个阶段的技术能力整合成一个易用的产品。
核心亮点
- 不暴露内网端口(连接器) - 采用反向连接模式,内网设备主动连接到云端,无需开放端口
- 限制访问 - 基于策略的访问控制,细粒度权限管理
- 一键安装 - Web 界面操作,自动化部署脚本
- 自动发现 - 自动扫描设备上的应用和服务
- 监控数据 - 实时监控连接状态、流量统计
架构设计
目前我把liaison分为3部分:
- Liaison:主服务进程,包括了管理后台和网络数据面访问
- Frontier:阶段三的开源网关
- 连接器:从家庭等机器上反向连接到Frontier的连接器
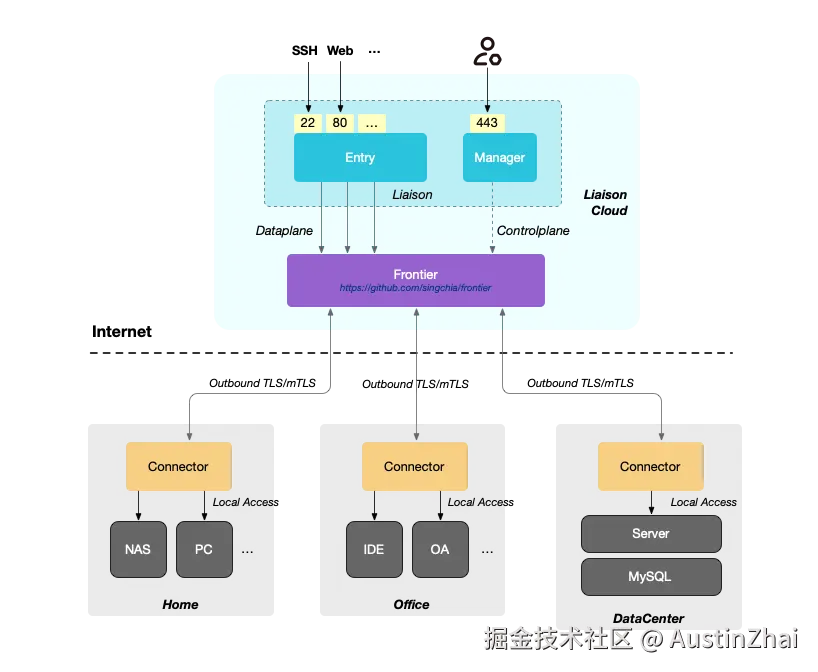
从网络框架到零信任的转变
liaison 的独特之处在于它改变了传统的网络访问模式:
传统模式(端口暴露):
markdown
Internet → 防火墙 → NAT → 内网服务
(需要配置端口转发,安全风险高)liaison 模式(反向连接):
arduino
内网服务 → Edge 连接器 → TLS 隧道 → Liaison Server ← 用户访问
(内网无需开放端口,零信任架构)应用扫描
扫描器(Scanner)是 liaison 实现自动应用发现的核心组件,它能够自动检测设备上运行的服务。
工作原理:
-
任务分发机制
- Manager 通过 RPC 调用向 Edge 发送扫描任务
- Edge 的 Scanner 组件注册了
scan_applicationRPC 处理器 - 扫描任务包含:网络范围(Nets)、端口范围(Port)、协议类型(Protocol)
-
并发扫描实现
- 使用 Worker Pool 模式,限制最多 100 个并发 worker
- 将 IP 和端口的组合放入任务队列(带缓冲的 channel)
- 每个 worker 从队列中取任务,独立执行扫描
-
端口检测方法
- 使用 TCP 连接尝试 检测端口是否开放
- 设置 2 秒超时,快速判断端口状态
- 如果连接成功,说明端口开放,记录为可用服务
-
协议识别
- 对于 HTTP 协议,尝试发送 HTTP 请求,解析响应头
- 通过响应头判断服务类型(如 Jellyfin、Plex 等)
- 对于其他协议,仅记录端口开放状态
-
结果上报
- 扫描过程中实时上报"running"状态
- 扫描完成后上报"completed"状态和结果列表
- 结果包含:IP、端口、协议、服务类型等信息
时序:
lua
Manager Edge Scanner
| |
|-- RPC: scan_application -->|
| | 创建扫描任务
| | 启动 goroutine
| |
| | 任务队列 (channel)
| | ↓
| | Worker Pool (100个)
| | ↓
| | TCP 连接尝试
| | ↓
| | 协议识别
| | ↓
|<-- RPC: report_task -------| 结果上报代理WebSocket
WebSocket比较特殊,是在HTTP基础上Hijack net.Conn获得的连接,可以额外介绍一下。liaison 通过 geminio Stream 实现了 WebSocket 的透明代理。
WebSocket 升级流程:
-
检测升级请求
- 检查 HTTP 请求头:
Connection: upgrade和Upgrade: websocket - 如果检测到 WebSocket 升级请求,进入 WebSocket 处理流程
- 检查 HTTP 请求头:
-
建立 Stream 连接
- 打开到 Edge 的 geminio Stream
- 写入目标地址信息(Dst)
- 将 HTTP 升级请求转发到 Edge
-
升级响应处理
- 从 Stream 读取 Edge 返回的 HTTP 升级响应
- 将响应写回客户端,完成 WebSocket 握手
-
双向数据转发
- 移除所有超时限制(WebSocket 需要保持长连接)
- 启动两个 goroutine 进行双向数据转发:
io.Copy(stream, clientConn)- 客户端 → Edgeio.Copy(clientConn, stream)- Edge → 客户端
- 任一方向关闭时,关闭整个连接
时序图:
lua
客户端 Entry Edge 内网应用
| | | |
|-- HTTP Upgrade ------->| | |
| |-- Open Stream -------->| |
| |-- Write Dst Info ----->| |
| |-- Forward Request ---->| |
| | |-- HTTP Upgrade --->|
| | |<-- 101 Switching --|
| |<-- Upgrade Response ---| |
|<-- 101 Switching ------| | |
| | | |
|<======== WebSocket====>| | |
| |<======== Stream ======>| |
| | |<== WebSocket =====>|技术栈整合
liaison 是前面三个阶段技术的集大成者:
| 组件 | 技术来源 | 作用 |
|---|---|---|
| 连接管理 | frontier | 管理所有 Edge 连接器的连接 |
| 通信协议 | geminio | 提供可靠的双向通信能力 |
| 心跳检测 | go-timer | 检测连接器在线状态,自动重连 |
| HTTP 代理 | 新增 | 自动 TLS 加密,HTTP 应用升级为 HTTPS |
| Web 管理 | 新增 | 可视化界面,降低使用门槛 |
| 应用发现 | 新增 | 自动扫描内网服务,零配置 |
使用场景
-
NAS 外部访问
- 家里的 NAS 不暴露端口,从任何地方安全访问
- 自动 TLS 加密,无需手动配置证书
-
Home as a Service
- 将家庭设备(Mac mini、台式机)变成个人云服务
- 运行 AI Agent、开发环境、媒体服务器等
-
小团队/个人工作室
- 无需购买昂贵的企业级 VPN
- Web 界面统一管理所有设备和服务
-
成本低廉
- 只需一台低配云服务器(1核1G,约40元/月)
- 开源免费,无授权费用
未来展望
这个技术演进的故事还在继续。基于现有的技术积累,未来可能的方向包括:
🔐 更强的安全能力
- 设备指纹识别
- 行为异常检测
- 端到端加密
🤖 AI 增强
- 智能流量分析
- 自动故障诊断
- 预测性运维
🌐 边缘计算深化
- 边缘函数计算
- 数据本地处理
- 边缘 AI 推理
📊 可观测性提升
- 分布式追踪
- 性能分析
- 智能告警
总结
从一个简单的定时器库到一个完整的零信任网络接入平台,这个技术演进历程展示了:
- 技术积累的重要性 - 每一步都为下一步奠定基础
- 解决实际问题 - 技术服务于场景,而非为了技术而技术
- 开源的力量 - 开放协作带来更好的产品
- 从框架到产品 - 易用性是产品成功的关键
- 持续迭代 - 没有完美的产品,只有不断进化的产品
这就是一个技术演进的真实故事。
相关资源
开源项目
- go-timer : github.com/singchia/go...
- geminio : github.com/singchia/ge...
- frontier : github.com/singchia/fr...
- liaison : github.com/singchia/li...
文档与教程
社区
如果你对这个技术演进过程感兴趣,欢迎:
- ⭐ 给项目点个 Star
- 💬 参与 Discussions 讨论
- 🐛 提交 Issues 报告问题
- 🔧 贡献代码和文档