这篇文章是我三篇系列文章的第一篇,记录一个完整的产品开发过程。起因是我最近接了个小项目------在内部系统中实现自然语言数据分析。趁春节假期,我打算把这个过程完整记录下来:从需求分析、技术调研,到产品构思,再到用 Vibe Coding 快速落地。希望能给同样在探索"如何快速实现一个需求"的朋友一些启发。
一、先说说这个需求是怎么来的
事情是这样的:我们内部系统有个数据分析的后台,运营同学经常跑过来问,"能不能帮我看看上周的付费用户留存?""按渠道分一下行不行?"
这类需求本身不复杂,但如果每次都手动写 Python 或 SQL 脚本,其实挺烦的------数据得导出来,代码得写,跑完还得把结果发回去。一次两次还好,多了就变成重复劳动。
观察下来,我发现需要这类功能的人大概分两类:
第一类是临时查询的用户。他们可能不会写代码,或者觉得为了一次性的需求去写脚本太不划算。对他们来说,最理想的方式是在系统里直接输入"上周各渠道付费用户的留存率",然后系统自动把数据跑出来。
第二类是策略分析师。他们不仅想查一次,还想把查出来的逻辑固定下来,以后可以反复用,甚至给别人用。比如写好一个"用户留存分析"的脚本,以后选个时间范围就能直接跑。
这两类需求其实指向同一个方向:自然语言生成数据分析代码。
你可能想说,这不就是让 LLM 写代码吗?Vibe Coding 不是很火吗?但 Vibe Coding 更多是帮程序员写代码,我的场景是需要一个能被集成到系统里的组件,让业务人员也能用,这完全是两回事。
正好,我 leader 之前在用一个商业 BI 工具叫 Basedash(BI 就是商业智能,简单说就是帮企业分析数据的工具),功能确实强,但我们想自己做一个轻量的版本。我有一些 Agent 开发的经验,觉得这事不难,就决定自己试试。
二、我的开发范式:先找轮子,再造轮子
我的思路很简单:先看看有没有现成的轮子,别一上来就自己写。
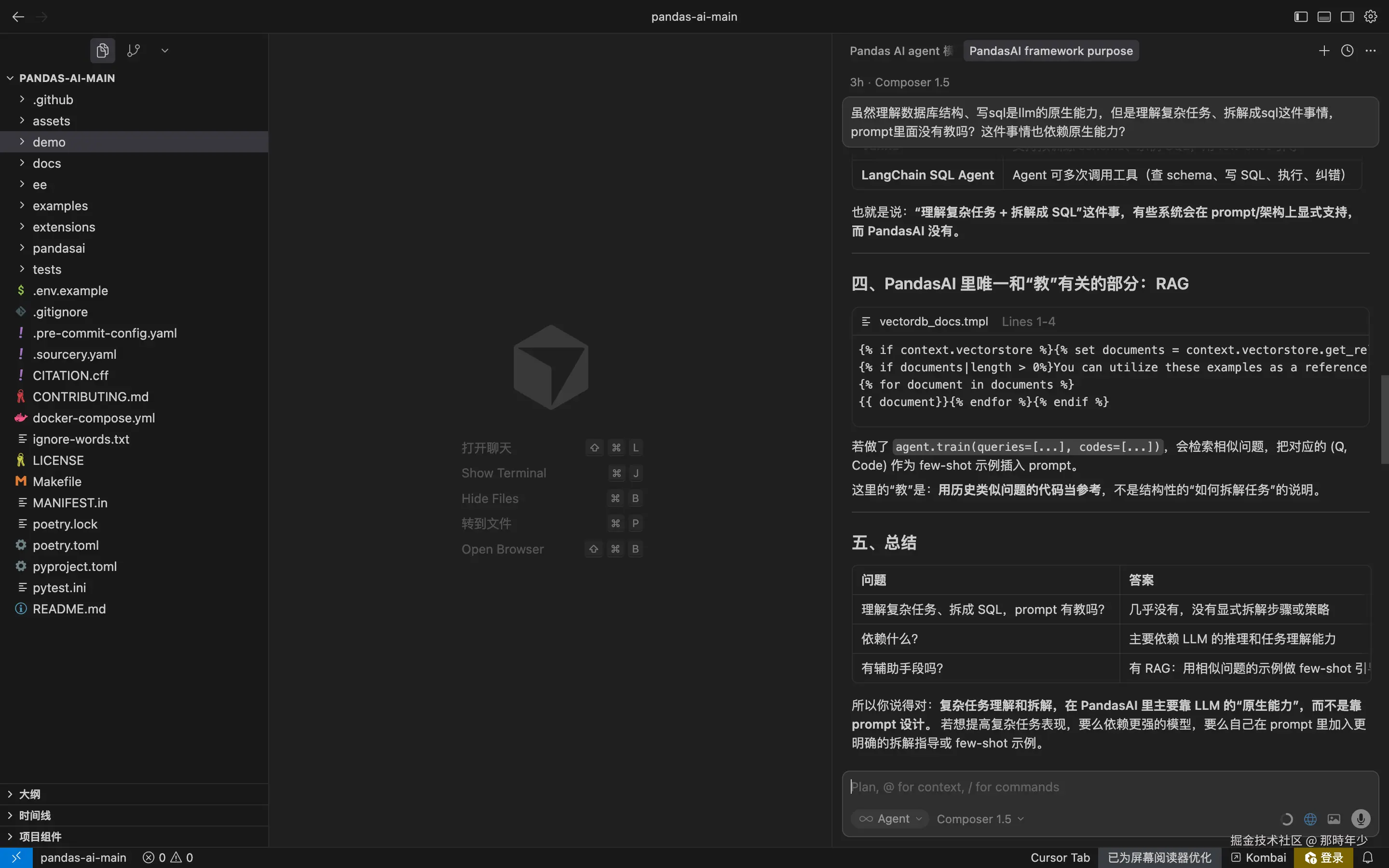
于是我去 GitHub 逛了一圈,锁定了一个项目:PandasAI。名字就很直白------Pandas + AI,数据分析方向,完美契合我的想象。
PandasAI 初体验
我把代码拉下来跑了一遍,效果确实可以。比如我丢给它"计算各部门平均工资,画个柱状图",它真的能跑出结果,还能把图画出来。对于简单的查询,几乎没什么毛病。
但用着用着,问题就出来了。它的工作方式是:用户输入 → 生成一段 Python 代码 → 执行 → 返回结果。一次生成,没有重试,错了就是错了。
对于第一类用户(临时查询)来说,这其实够用。出错了重新问一遍就是了。但对于第二类用户(想固化逻辑的策略分析师)来说,这就很尴尬------我想要的是能稳定复用的东西,不是每次都要碰运气。
那 PandasAI 到底做了什么?
带着这个问题,我去翻了翻它的源码。发现它的核心其实不复杂:把 DataFrame 的结构(列名、前几行数据)塞进 Prompt,让 LLM 生成 pandas 代码,然后执行。如果连的是数据库,那就生成 SQL。
本质上,它就是一个 NL2SQL(自然语言转 SQL)的工具,最大的亮点是能直接连 Excel 文件------这对很多数据分析师来说确实很实用,因为第一手数据经常是 Excel,还没空导入数据库。
但问题也在这里:它过度依赖模型的原生能力。模型会写 SQL,它就写 SQL;模型会画图,它就画图。一旦遇到复杂需求,模型能力就是天花板。而且没有重试机制,出错了也没办法自己修复。
带着这些不满,我继续找下一个项目。
三、Vanna:一个更对味的框架
这次我找到了 Vanna。上手一试,发现它解决了我最头疼的几个问题。
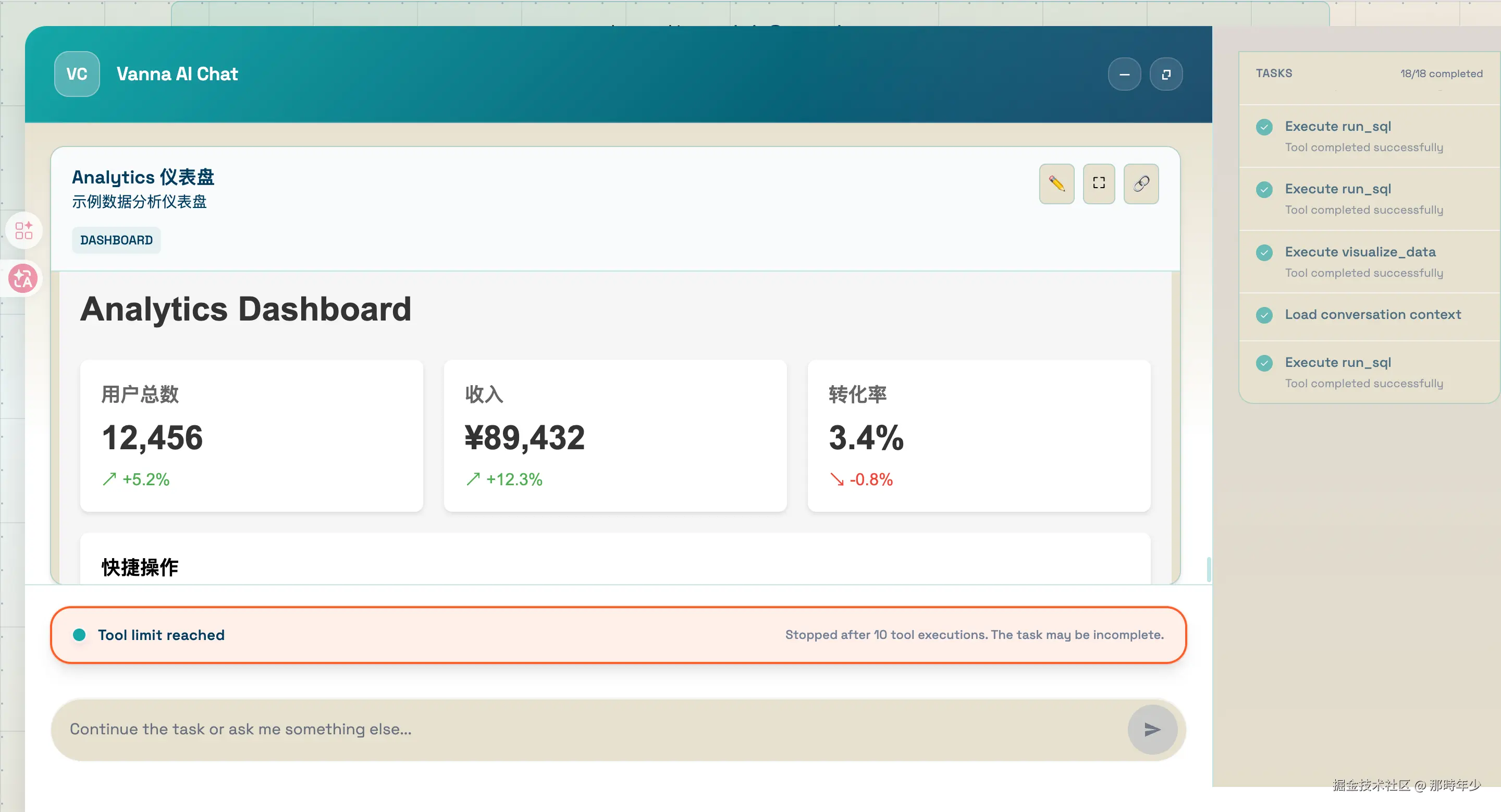
首先,它支持真正的多轮对话。我可以先问"上周的销售情况",它返回结果;然后接着问"按地区分一下",它记得上下文,能接着上一轮继续分析。这在 PandasAI 里体验不太好。
其次,它有记忆机制。Vanna 会把成功的问题-工具调用模式存下来,下次遇到相似的问题,可以直接参考之前的成功经验。这对策略分析师来说太重要了------好的分析逻辑可以被沉淀下来,不用每次都从头开始。
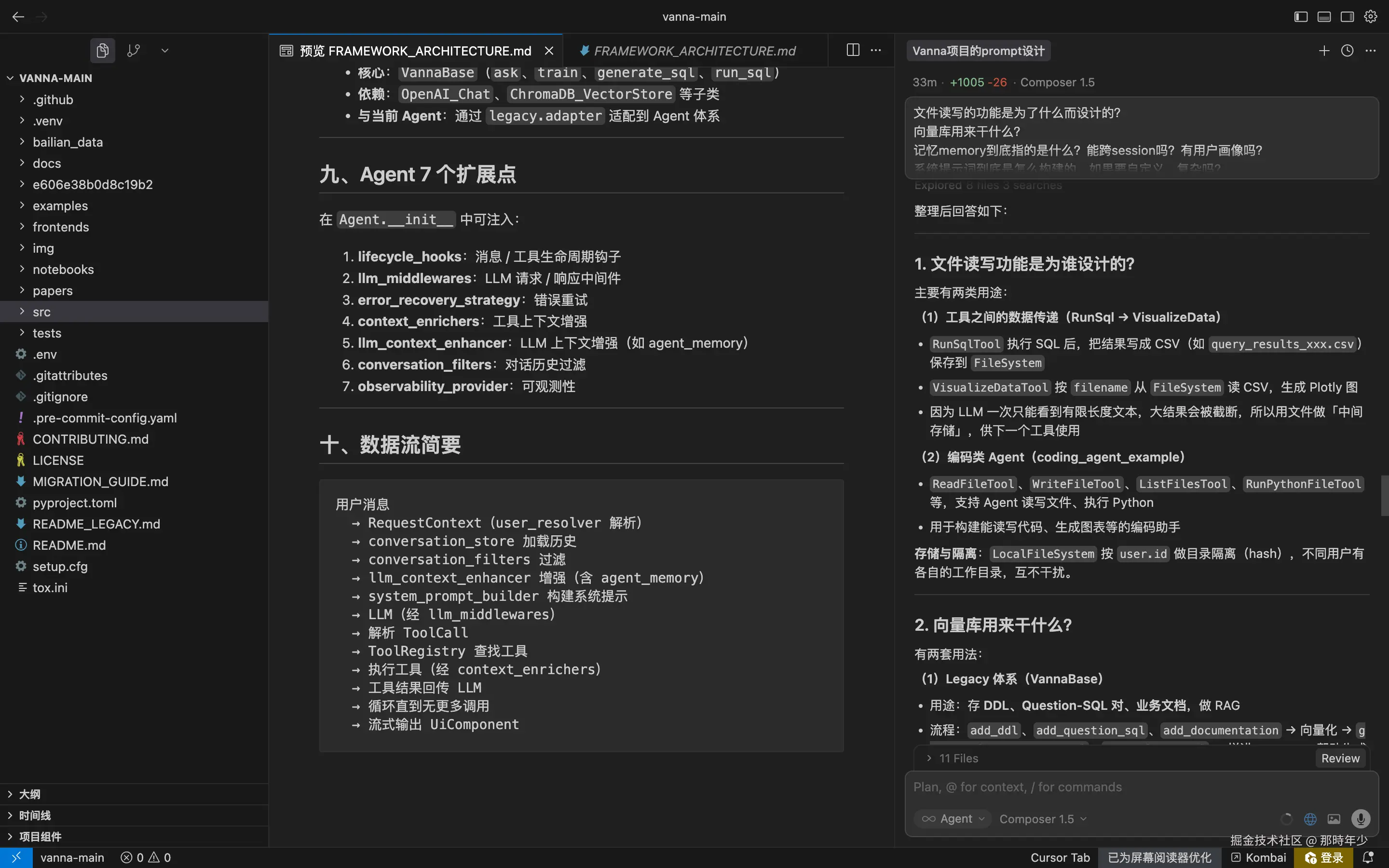
再看架构,Vanna 比 PandasAI 成熟得多。它不是简单的 NL2SQL,而是一个完整的 Agent 框架:
- 工具调用:内置了 SQL 执行、数据可视化、Python 执行等工具,LLM 只需要决策调用哪个工具,不用自己写展示代码
- UI 组件:工具执行后返回结构化的数据 + 组件类型,前端按类型渲染,前后端解耦很清晰
- 扩展性:LLM、数据库、向量库、记忆存储都可以替换,想改哪里改哪里
更关键的是,Vanna 的设计承认了 LLM 的局限,用系统设计来弥补。比如它的文件读写机制------SQL 查询结果太大怎么办?存成 CSV,下个工具读文件去画图,这样就不会被上下文窗口卡住。
四、技术选型定了:Vanna 就是我要的那个轮子
跑了一圈下来,结论很明确:
- PandasAI:适合一次性探索,简单场景够用,但不适合作为系统组件
- Vanna:有上下文、有记忆、可扩展,符合我对"可复用的数据分析组件"的想象
下面是一些验证过程的截图,多轮对话、复杂查询、图表生成,基本都覆盖到了。
既然技术栈得到了验证,我愿意称之为一个 MVP(最小可行产品)。下一步就是基于 Vanna,构思我们真正需要的产品功能------需求引导、结果验证、策略复用,这些是 Vanna 还没做的,也是我们可以创造价值的地方。
但那是第二篇文章的事了。
五、写在最后
这篇文章是我三篇系列的第一篇,记录的是技术调研和选型的过程。
说实话,我对产品思维还在入门阶段,不指望能做出 80 分的产品。我的目标很简单:能用。能解决我自己的需求,能给团队带来一点效率提升,这个系统对我来讲就是成功的。
下一篇,我会基于 Vanna 的边界,构思我们真正需要的产品功能。如果你也在做类似的事情,欢迎留言交流。
项目代码后续会放在 GitHub,链接见第三篇文章文末。