文章目录
- [01|核心概念:chosen / rejected 到底是什么?](#01|核心概念:chosen / rejected 到底是什么?)
-
- [🔬 研究结论(很"工程友好"):Chosen 质量才是第一生产力](#🔬 研究结论(很“工程友好”):Chosen 质量才是第一生产力)
- 02|四大偏好优化算法:怎么选才不踩坑?
-
- DPO:经典、稳,但更吃显存
- ORPO:把偏好"揉进"SFT,一次训完
- [SimPO:更轻的 DPO 思路,隐式奖励更贴近生成](#SimPO:更轻的 DPO 思路,隐式奖励更贴近生成)
- KTO:你只有"好/坏标签",也能对齐
- 03|企业级标注准则:四层门禁(把"审美"变成"可检查项")
- [04|Pair 采样策略:配对质量 = 训练信号质量](#04|Pair 采样策略:配对质量 = 训练信号质量)
- 05|难例挖掘:真正的"涨分点"在这里
- [06|一致性标注 + 审计:不做这步=白训](#06|一致性标注 + 审计:不做这步=白训)
-
- [6.1 一致性量化:IAA + Kappa](#6.1 一致性量化:IAA + Kappa)
- [6.2 审计三件套(建议写进制度)](#6.2 审计三件套(建议写进制度))
- 07|工具链推荐(能直接落地)
- [✅ 交付物 1:Pair 数据格式(TRL 显式 prompt 推荐)](#✅ 交付物 1:Pair 数据格式(TRL 显式 prompt 推荐))
-
- JSONL(推荐)
- [Chat Messages(对话型管线)](#Chat Messages(对话型管线))
- [✅ 交付物 2:标注规范 SOP(强制执行版)](#✅ 交付物 2:标注规范 SOP(强制执行版))
-
- [2.1 判定顺序(不允许跳步)](#2.1 判定顺序(不允许跳步))
- [2.2 reason_tags(强制填写)](#2.2 reason_tags(强制填写))
- [📚 参考(按本文使用顺序)](#📚 参考(按本文使用顺序))
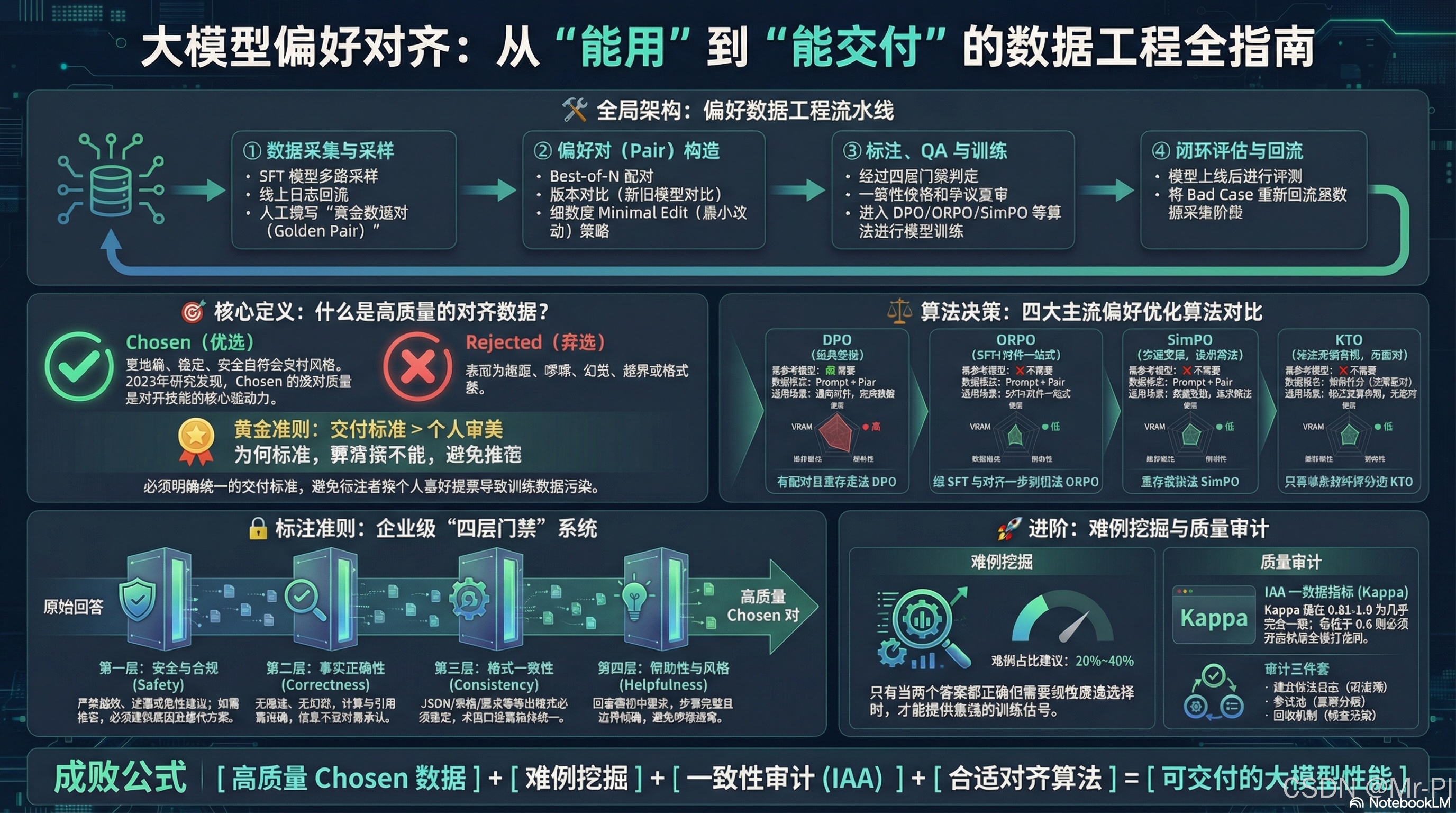
SFT 做完,很多团队会遇到同一个坑:口径不稳、风格漂移、越用越像"随机选项" 。
偏好对齐不要求你写"标准答案",它只问一句:两种回答里,你更偏好哪一种?------然后把你的"交付标准"固化进模型。
本文把 DPO / ORPO / SimPO / KTO 四条主流路线讲清楚,并把 pair 数据工程全流程 + 企业可落地标注规范 + 一致性审计体系一次性给到你:可复制、可上线、可追溯。
01|核心概念:chosen / rejected 到底是什么?
✅ chosen :你更希望模型输出的版本
更准确、更稳定、更安全、更符合交付风格
❌ rejected :你不希望模型输出的版本
跑题、啰嗦、幻觉、越界、格式差
🔬 研究结论(很"工程友好"):Chosen 质量才是第一生产力
2025 的系统研究指出:chosen 回答的绝对质量,是 DPO 性能的首要驱动因素 ;rejected 只要保持基本"对比度",边际贡献就会迅速变小。换句话说:很多"拉大差距"的技巧之所以有效,根因是把 chosen 质量拉上去了。(arXiv)
💡 不要把预算砸在"造更烂的 rejected"。
把资源集中到 chosen 的人工精修 / 多轮迭代 / 专家审核,回报更稳、更可控。:contentReferenceoaicite:1{index=1}
02|四大偏好优化算法:怎么选才不踩坑?
| 维度 | DPO | ORPO | SimPO | KTO |
|---|---|---|---|---|
| 需参考模型(ref model) | ✅ 需要 | ❌ 不需要 | ❌ 不需要 | ❌ 不需要 |
| 数据形态 | prompt + chosen + rejected | prompt + chosen + rejected | prompt + chosen + rejected | prompt + response + label(无需配对) |
| 核心思路(口径) | 偏好损失 + 锚定参考模型 | SFT 与偏好合成一个目标 | 序列平均对数概率做隐式奖励 | 前景理论(Prospect Theory),从好/坏二值学习 |
| 显存开销 | 🔴 较高(多加载一个模型) | 🟢 低 | 🟢 低 | 🟢 低 |
| 典型适用 | 通用、成熟管线 | 想"一站式"把 SFT+对齐做掉 | 资源紧张、想更轻 | 只有打分/好坏标签,难组织 pair |
配对 pair
单条打分
分开(两阶段)
一站式
有
紧张
你的数据是
配对(pair)还是
单条打分?
需要和 SFT
分开训练吗?
✅ KTO
无需配对
有足够显存
加载 ref model?
✅ ORPO
SFT+对齐合一
✅ DPO
经典稳健
✅ SimPO
无 ref,更省
DPO:经典、稳,但更吃显存
DPO 用一个偏好损失把 RLHF 的奖励建模+PPO 简化掉,同时用 参考模型 做锚点来抑制分布漂移。训练数据三列:prompt + chosen + rejected。(Hugging Face)
ORPO:把偏好"揉进"SFT,一次训完
ORPO 的关键是:在 SFT 的 NLL 目标上加一个 odds ratio 约束 ,不需要参考模型,适合你想把"风格约束"从一开始就焊死在模型里。(arXiv)
SimPO:更轻的 DPO 思路,隐式奖励更贴近生成
SimPO 用 序列平均对数概率 当隐式奖励,并用 reward margin 拉开 winner/loser 间距,不用参考模型,训练更省。(arXiv)
KTO:你只有"好/坏标签",也能对齐
KTO 基于前景理论,把"人类的损失厌恶/非线性效用"纳入目标函数,**只需要二值信号(desirable / undesirable)**就能学偏好,不需要 pair。(arXiv)
03|企业级标注准则:四层门禁(把"审美"变成"可检查项")
越权/泄漏/危险
通过
编造/错误
通过
JSON/表格/要点
不满足
通过
更简洁/清晰/
步骤完整/边界明确
啰嗦/绕弯/
缺乏行动建议
收到 pair
开始评判
🔒 门禁1
安全/合规
❌ 直接 rejected
🔍 门禁2
事实正确性
❌ 直接 rejected
📐 门禁3
格式门禁
❌ 直接 rejected
💡 门禁4
帮助性 & 风格
✅ chosen
❌ rejected
- 门禁1 安全/合规:越权、泄漏、危险指导 → 直接拒
- 门禁2 正确性:编造/算错/张口就来 → 直接拒
- 门禁3 格式一致:JSON/要点数/字段齐全度 → 不满足就拒
- 门禁4 帮助性与风格:切中问题、可执行、边界清晰 → 才比"文风"
04|Pair 采样策略:配对质量 = 训练信号质量
偏好训练最浪费的一种数据:一个答案烂到离谱、另一个好到爆 。
这种 pair 好标,但对模型提升往往不大------因为模型早就知道"哪个更烂"。
| 策略 | 做法 | 优点 | 适合阶段 |
|---|---|---|---|
| A. Best-of-N 双采样 | 同一 prompt 生成 2~4 个候选,选最好/最差 | 成本低、堆量快 | 冷启动、快速迭代 |
| B. 版本对比(SFT vs Aligned) | chosen=新版/人工优化;rejected=旧版/未对齐 | 最贴近闭环,能抓回归 | 持续迭代 |
| C. Minimal Edit(编辑式对比) | 只在关键点不同(引用/拒答/步骤) | 训练信号最强 | 精调、补难例 |
05|难例挖掘:真正的"涨分点"在这里
想要 DPO/ORPO 提升明显,难例建议占 20%~40% :
两个答案都不明显错,但你必须做细粒度选择。
难例的典型长相:
- 都正确,但一个更稳:有依据/边界/更少幻觉
- 都可用,但一个更简洁:结构更可扫读
- 都安全,但一个更会拒答:拒得体 + 给替代方案
- 都按格式,但一个字段更齐:缺失策略一致
06|一致性标注 + 审计:不做这步=白训
偏好数据最大的风险不是"少",而是"乱"。
标准不一致,训出来就是"随机口味模型"。
6.1 一致性量化:IAA + Kappa
工程上常用 Cohen's Kappa / Fleiss' Kappa 衡量标注一致性;不少实践会把 0.8 左右 作为"比较可靠"的门槛参考(具体阈值可按业务风险调整)。(PMC)
最低配做法(现在就能上):
- 每周抽 5% 样本做双人复标
- Kappa 低于你设定门槛 → 强制开"校准会",回写 guideline
6.2 审计三件套(建议写进制度)
- 标注日志:谁标的、何时、用的哪版准则
- 争议池:分歧样本必须复审(不可直接丢弃)
- 回放机制:线上发现口径变坏,能追到"哪一批 pair 污染"
07|工具链推荐(能直接落地)
| 环节 | 推荐工具 | 说明 |
|---|---|---|
| 标注平台 | Argilla / Label Studio | Argilla 适合快速上手标注流程;Label Studio 有现成的 pairwise 模板可改造(docs.argilla.io) |
| 数据格式化 | Hugging Face Datasets | 与 TRL 训练管线对接顺滑 |
| 训练框架 | TRL(DPO/ORPO/...) | TRL 文档明确支持显式 prompt,并约定数据列名(prompt/chosen/rejected)(Hugging Face) |
✅ 交付物 1:Pair 数据格式(TRL 显式 prompt 推荐)
TRL 的 DPOTrainer 支持显式/隐式 prompt;工程上更推荐 显式 prompt ,方便审计、也更可控。(Hugging Face)
JSONL(推荐)
json
{
"id": "p_000102",
"prompt": "请基于材料总结三条要点,每条不超过18字。",
"chosen": "1. 建回归集防止能力回退\n2. 评测门禁不过不准上线\n3. 版本可追溯便于回滚",
"rejected": "回归测试很重要,它可以让系统更好更稳定,也能提升用户体验,所以我们应该做回归测试。",
"meta": {
"task": "summarize_bullets",
"domain": "mlops",
"difficulty": "hard",
"labeler": "ann_07",
"guideline_ver": "pref_v1.2",
"reason_tags": ["format", "conciseness", "helpfulness"]
}
}Chat Messages(对话型管线)
json
{
"id": "p_000221",
"messages": [
{"role":"user","content":"请输出可解析JSON:{name, price, material}。材料:..."}
],
"chosen": "{\"name\":\"...\",\"price\":29.99,\"material\":\"TPU\"}",
"rejected": "这款产品的名称是...,价格是29.99美元,材质是TPU。",
"meta": {"reason_tags":["format_json","json_parse"]}
}✅ 交付物 2:标注规范 SOP(强制执行版)
2.1 判定顺序(不允许跳步)
- 安全/合规 → 有风险直接 rejected
- 事实正确 → 编造/错误直接 rejected
- 格式门禁 → JSON/要点/表格不满足直接 rejected
- 帮助性与风格 → 简洁、步骤清晰、边界明确者 chosen
2.2 reason_tags(强制填写)
correctness/hallucinationformat_json/format_table/format_bulletsconciseness/verbosityrefusal_good/refusal_badpolicy/privacytone/style
💡 为什么必须要 tags?
因为上线后你要能回放:到底是"格式类数据污染",还是"拒答类过多",还是"事实门禁松了"。这决定你修数据还是换策略。
📚 参考(按本文使用顺序)
- What Matters in Data for DPO? (2025)(arXiv)
- ORPO: Monolithic Preference Optimization without Reference Model (2024)(arXiv)
- SimPO: Simple Preference Optimization with a Reference-Free Reward (2024)(arXiv)
- KTO: Model Alignment as Prospect Theoretic Optimization (2024)(arXiv)
- TRL DPOTrainer 文档(显式/隐式 prompt、列名约定)(Hugging Face)
- Label Studio Pairwise / RLHF Human Preference 模板(Label Studio)
- Kappa 与一致性实践参考(McHugh, 2012 等)(PMC)