文章目录
- [一、背景:为什么需要 RAG?](#一、背景:为什么需要 RAG?)
-
-
- [1. 大模型知识冻结](#1. 大模型知识冻结)
- [2. 大模型幻觉问题](#2. 大模型幻觉问题)
-
- [二、什么是 RAG?](#二、什么是 RAG?)
-
- [RAG 开发中的核心难点](#RAG 开发中的核心难点)
-
- [RAG 中大模型的三个关键使用位置](#RAG 中大模型的三个关键使用位置)
一、背景:为什么需要 RAG?
随着大模型(LLM)在各类应用中的普及,人们逐渐发现,仅依赖模型本身并不能满足真实业务需求,主要存在两个问题:
1. 大模型知识冻结
大模型的知识来自训练阶段的数据,一旦训练完成,模型的知识便被"冻结"。
如果需要模型了解新数据或企业私有知识,重新训练模型成本极高。
2. 大模型幻觉问题
当模型面对不确定或未知领域的问题时,往往会"编造"答案,使回答看起来合理但实际上是错误的。
可以用考试来类比:
当一个学生面对陌生领域的试题时,如果没有资料参考,就只能靠猜测作答,正确率有限。
而 RAG 的作用类似于:
在考试时提供可查询的资料和提示,使学生可以根据资料作答,从而显著提高正确率。
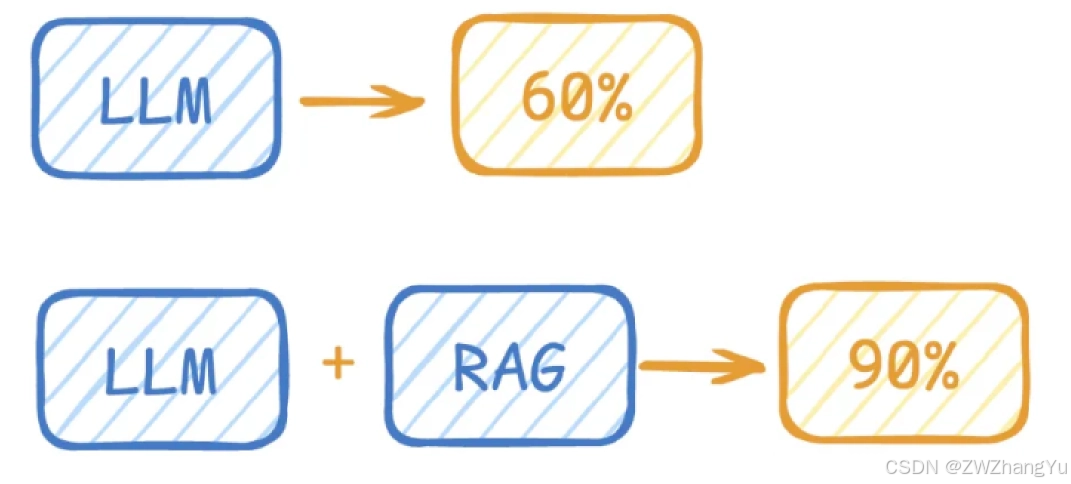
假设原本正确率为 60%,引入 RAG 后可提升至 90% 甚至更高。
因此,RAG 成为构建知识问答系统的重要技术方案。
二、什么是 RAG?
RAG,全称:
Retrieval-Augmented Generation(检索增强生成)
它的核心思想是:
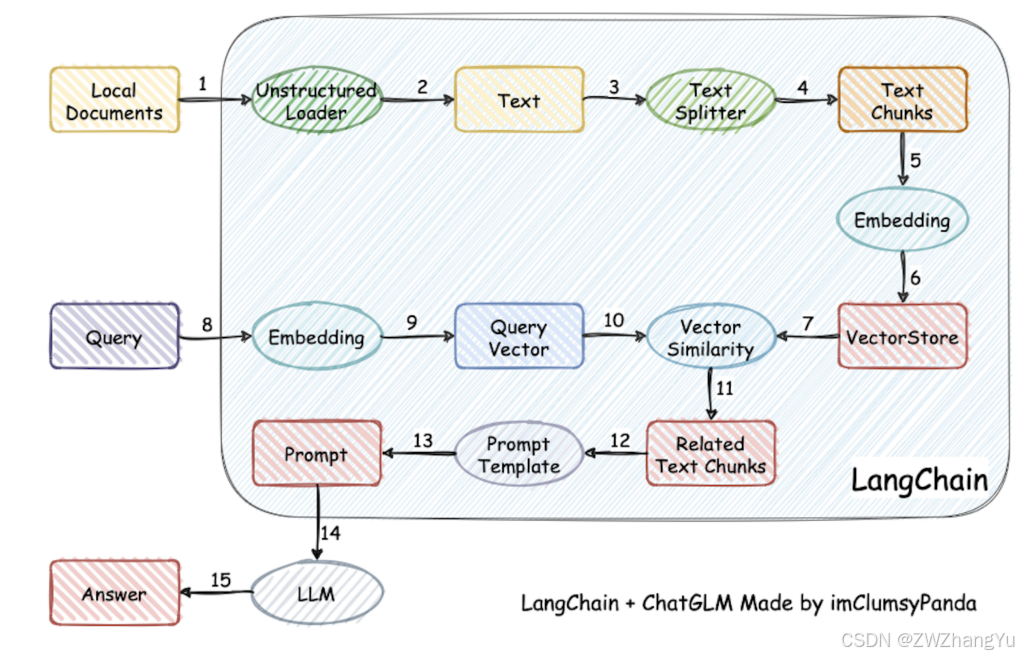
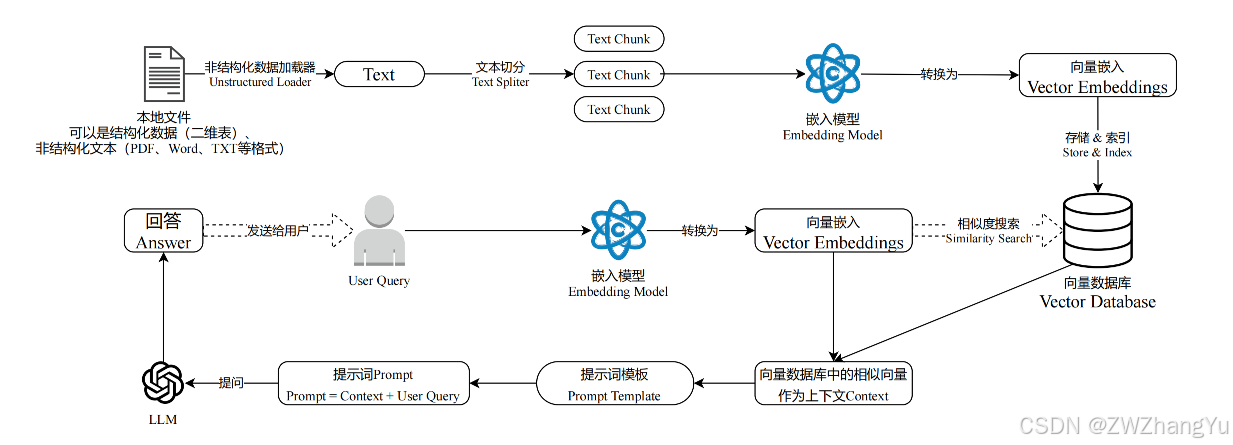
在大模型生成回答之前,先从外部知识库中检索相关信息,再将这些信息作为上下文提供给模型进行回答生成。
整个过程可以理解为:
- 检索(Retrieval)
- 增强(Augmentation)
- 生成(Generation)
简单来说:
用户问题 → 检索知识 → 提供给模型 → 模型生成答案
RAG 开发中的核心难点
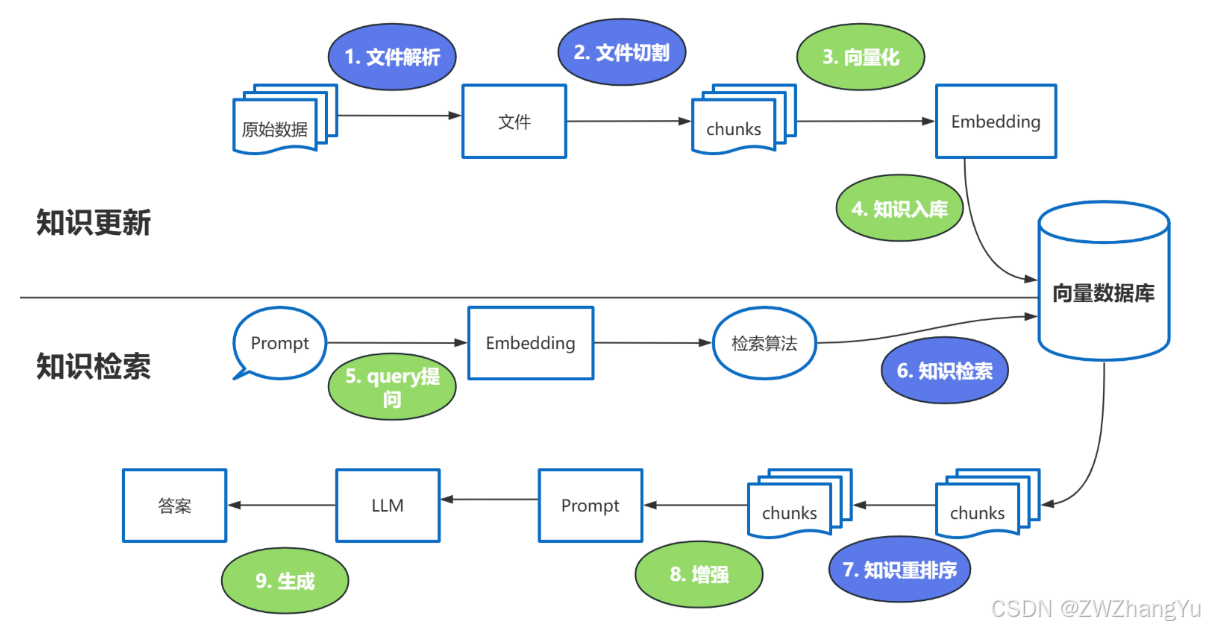
- 文件解析
企业知识往往来源复杂:
• PDF
• Word
• Excel
• Markdown
• HTML
• 数据库内容
• 扫描图片
解析质量直接影响后续检索效果。
- 文档切割策略
如果文本切割不合理:
• 切太小 → 上下文丢失
• 切太大 → 检索不精准
常见策略:
• 固定长度切割
• 按段落切割
• 滑动窗口切割
• 语义切割
-
知识检索
向量检索阶段需平衡:
• 召回率
• 查询速度
• 向量精度
通常会结合:
• 向量检索
• 关键词检索
• 混合检索
-
知识重排序(Rerank)
初步检索结果中可能存在"相关但不精确"的内容,需要进一步排序优化。
Reranker 是用于对检索结果进行二次排序的模型。
适合使用场景:专业知识问答系统;企业内部知识库;客服系统;医疗/法律问答;技术支持系统
这些场景对答案的准确性和相关性要求较高。
不适合使用场景
Reranker 会带来:查询时间增加;检索延迟增加;系统成本上升
因此,在以下场景可能不合适:
实时对话系统;高频调用接口;对延迟极为敏感的服务
RAG 中大模型的三个关键使用位置
在一个标准 RAG 流程中,大模型并不只出现一次,而是可能在多个阶段参与:
-
向量化阶段
用于文本向量化的模型:
Embedding Models
作用:
将文本转换为向量,便于相似度搜索。
-
重排序阶段
用于排序优化的模型:
Rerank Models
作用:
判断哪个结果更符合用户问题。
-
答案生成阶段
最终生成答案的模型:
LLM(大语言模型)
作用:
基于检索结果生成自然语言回答。